【2020/12/7 追記】初版から約2年経った今でも見られてるらしいので文章を整理したりしました。
1.はじめに
1.1 前置き
学校のとある調査で気象庁のデータが大量に必要になりました。気象庁ではここでscvファイルでダウンロードすることができます。しかし、それには容量制限があるので一都市ずつファイルを合成するなど人間の労力が必要になります。2,3都市ならまだしも40都市以上必要なので今回はスクレイピングすることにしました。
1.2 今回目指すもの
札幌, 室蘭, 函館, 青森, 秋田, 盛岡, 山形, 仙台, 福島, 新潟, 金沢, 富山, 長野, 宇都宮, 福井, 前橋, 熊谷, 水戸, 岐阜, 名古屋, 甲府, 銚子, 津, 静岡, 横浜, 松江, 鳥取, 京都, 彦根, 広島, 岡山, 神戸, 和歌山, 奈良, 松山, 高松, 高知, 徳島, 下関, 福岡, 佐賀, 大分, 長崎, 熊本, 鹿児島, 宮崎
以上46都市の
年月日, 陸の平均気圧(hPa), 海の平均気圧(hPa), 降水量(mm), 平均気温(℃), 平均湿度(%), 平均風速(m/s), 日照時間(h)
をcsv形式でスクレイピングします。
2.サイトの解析
2.1 注意事項
まずは、対象にするサイトや組織からAPIが提供されているか?ということを調べましょう。TwitterなどはAPIが提供されており簡単に好きなデータを取ることができます。この場合スクレイピングは不必要ということです。気象庁では当然のようにAPIはありません。一般人が作ったAPIはたくさんありますが(Githubにあると思う)、必要なデータが果たしてとれるのかということを吟味しなければなりません。
もう一つ。それは、サイトがしっかりスクレイピングできる構造になっているかどうかです。僕自身、スクレイピングをするのは初めてでしたので、適しているかどうかをはっきり区別できるわけではありませんが。(区別の仕方は次項で)
2.2 サイトの解析
今回は気象庁のデータサイトを例にします。データが**見れる(表示されている)**サイトにアクセスしてください。(気象庁ではここ)
やることは二つあります。
2.2.1 やること①:URLの解析
試しに札幌の2017年の1月の日ごとのデータを見てみましょう。URLは以下の通りです。
http://www.data.jma.go.jp/obd/stats/etrn/view/daily_s1.php?prec_no=14&block_no=47412&year=2017&month=1&day=&view=
URLの中の?より前の部分はサーバーへアクセスるための住所ですが、?より後ろはQueryと言われサイトに主に文字を渡すことができます。つまり、気象庁のサーバーは自らにアクセスしてきたURLからQueryを取り出しサイトを表示しているのです。
よって、後ろのQueryを編集すればほかのサイトが取れるはずです。Queryはkey=valueの形になっており、&で区切って複数付けることができます。検証してみたところ都市はprec_no(都道府県の番号)とblock_no(都市?エリア?の番号)の二つで管理され省略は不可でした。年月日などはyear(年)、month(月)とday(日にち)の三つで管理され日にち以外の二つは省略不可でした。最後にサイトのテンプレートです。このサイトは複数のプリセットが用意されており、必要なデータだけを表示することができます。これはviewで表され、省略するとs1が与えられています。s1のViewは一番多くのデータを表示していたので今回はこれを使います。下の画像は順にs1とa1の表示の様子です。
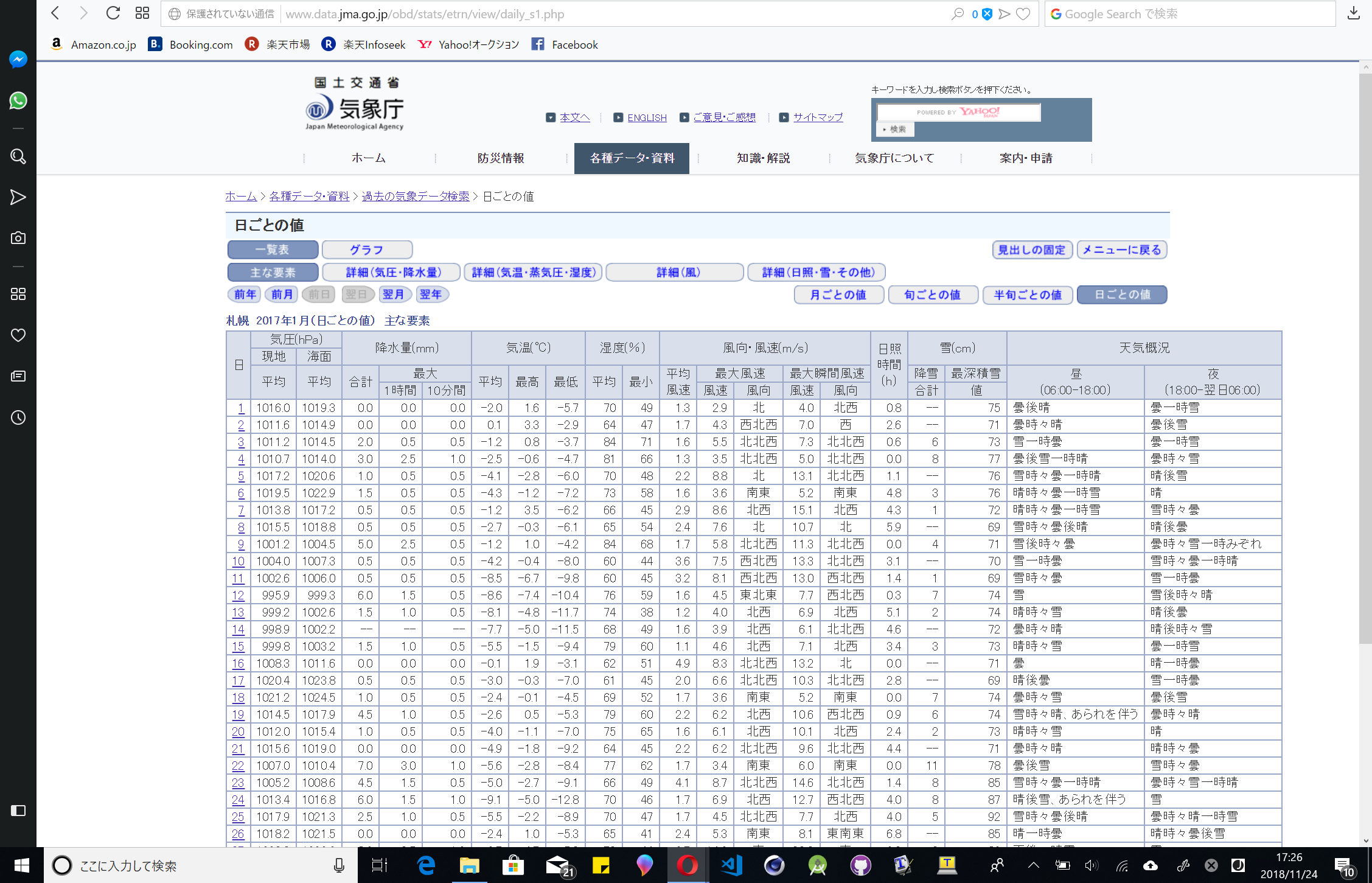
2.2.2 やること②:Webページの解析
試しに札幌の2017年の1月の日ごとのデータを見てみましょう。
http://www.data.jma.go.jp/obd/stats/etrn/view/daily_s1.php?prec_no=14&block_no=47412&year=2017&month=1&day=&view=s1
次に、アクセスしているブラウザで開発者モードにしてください。サイトのソースコードが見えるやつです。HTMLを見ると最初は折りたたまれていると思いますが三角を押すことで展開できます。ソースコードにカーソルを合わせるとその該当部分が変色します。
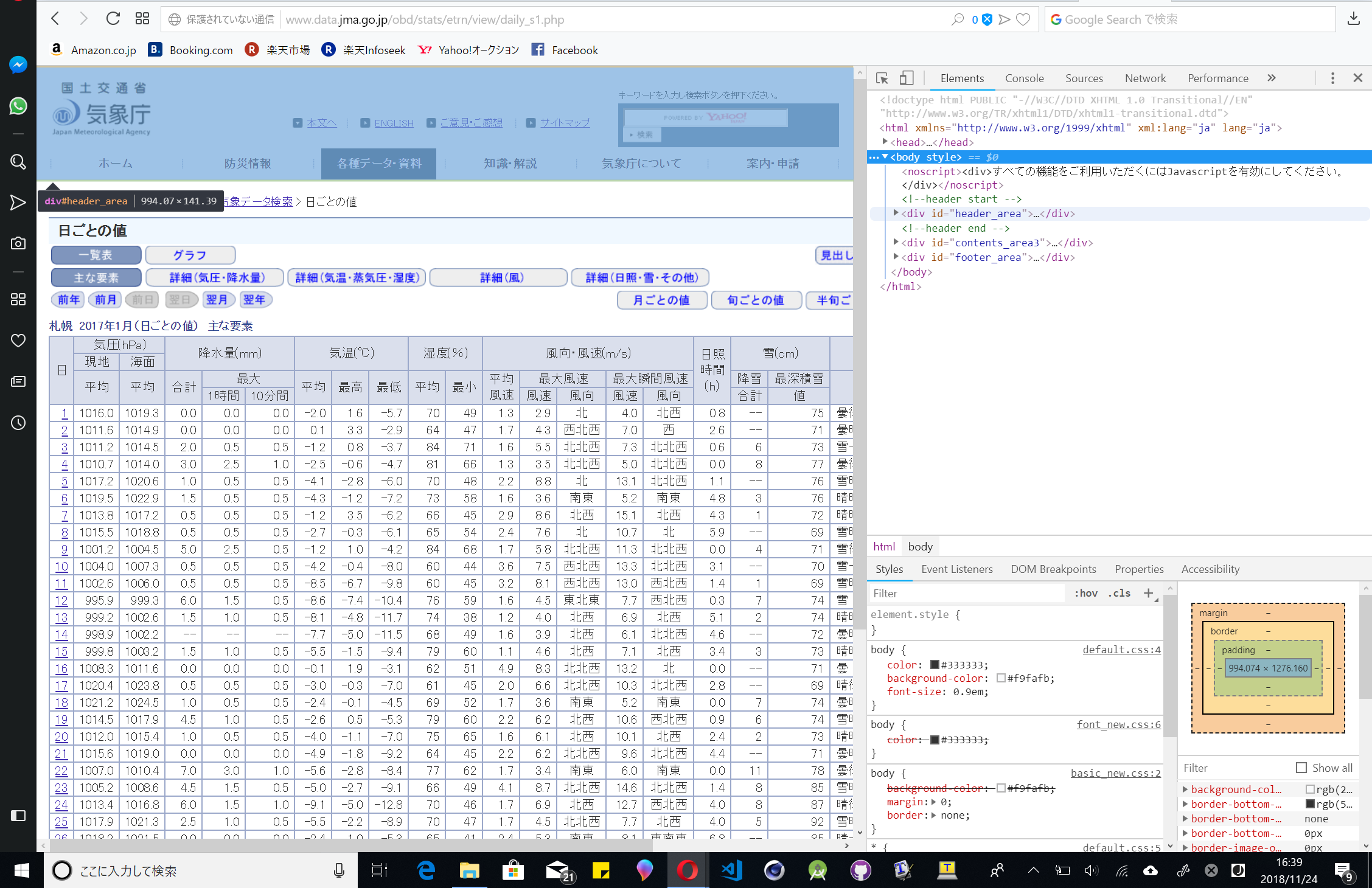
これを見て真ん中の表が光ったら展開、真ん中の表が光ったら展開と繰り返していくと...

表のみが光るようになり、タグを見てみるとtableとなっています。これはHTML語で「表」という意味になります。
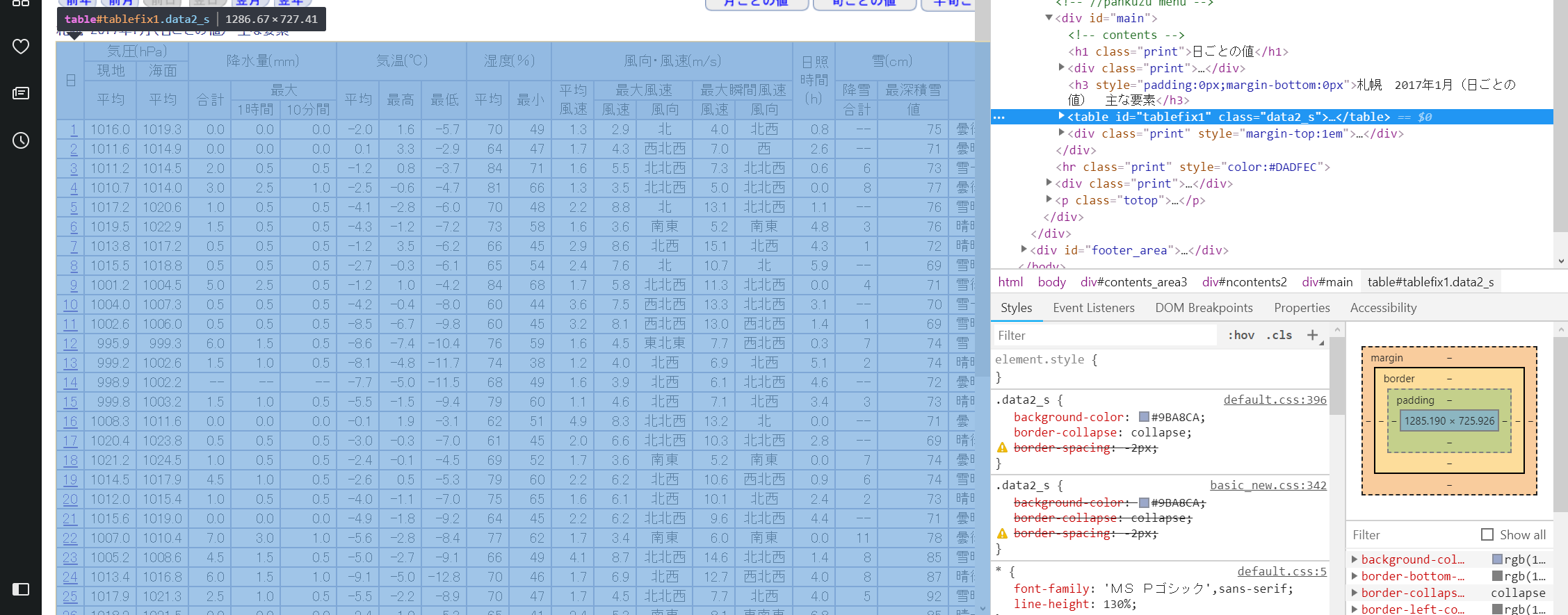
さらに中に入ると横一列のデータがタグで囲まれているというおぞましい光景がみえます。
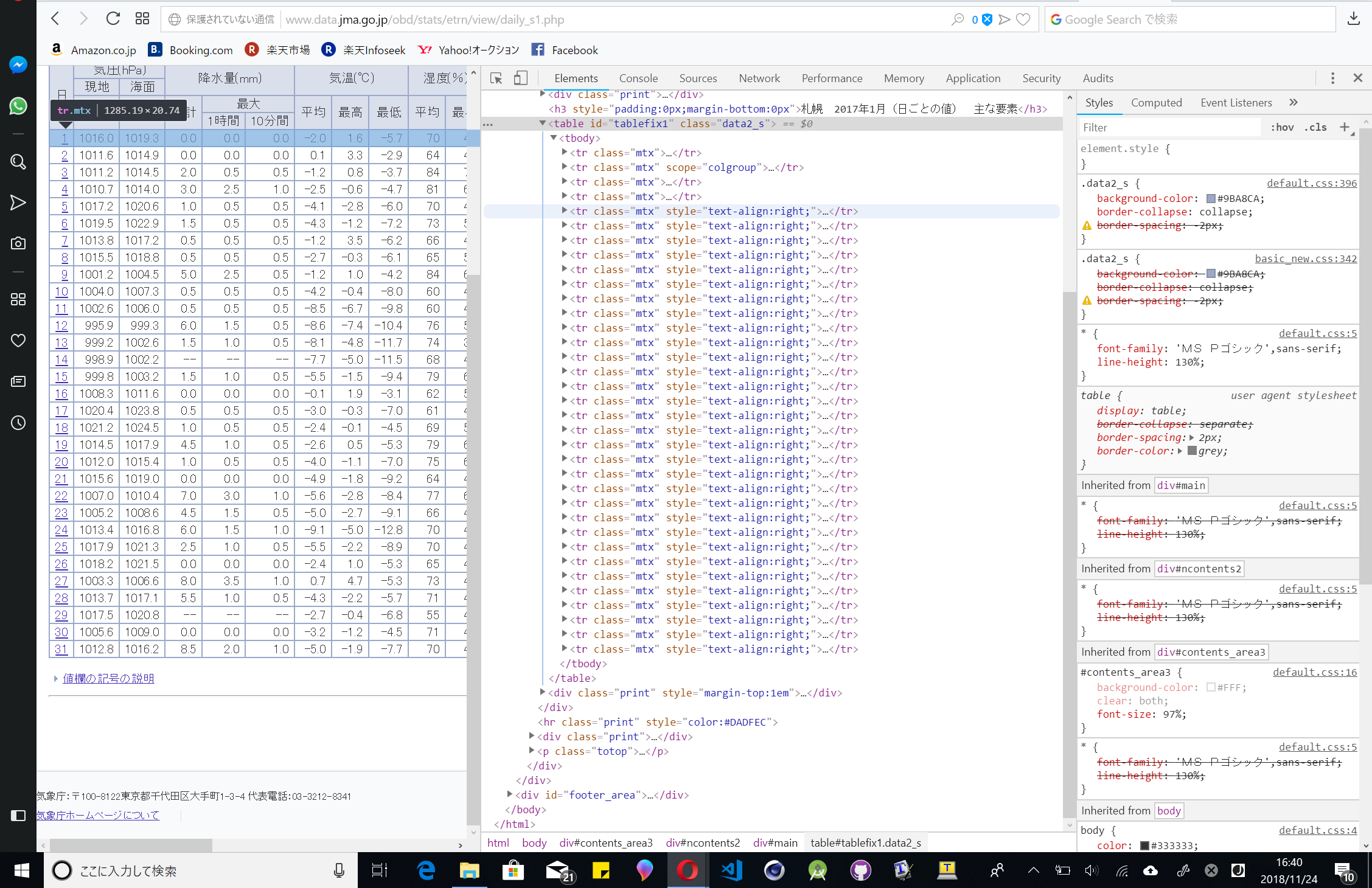
カーソルを移動すると表示されている表の列も移動します。非常に楽しいです。
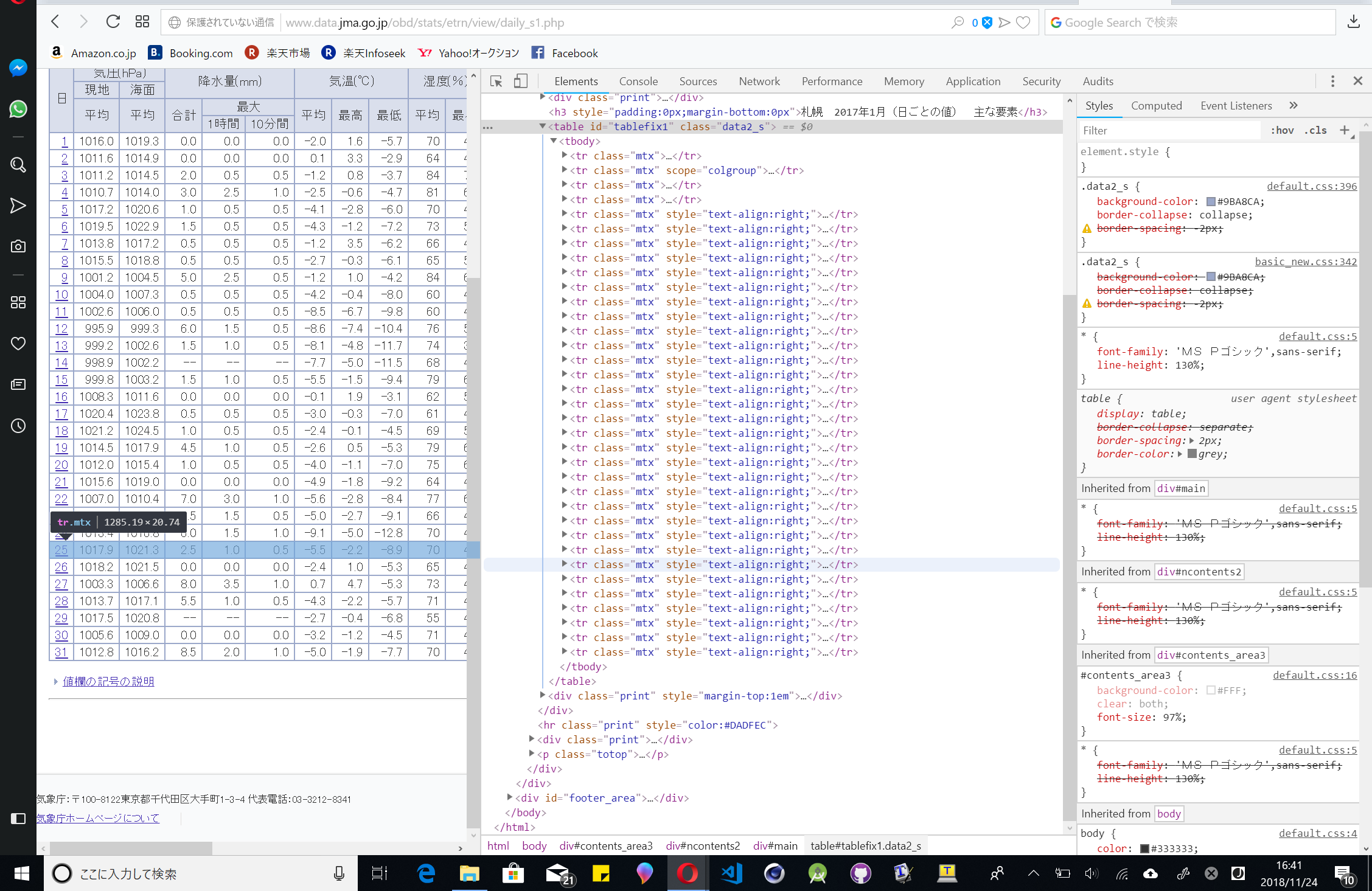
さて、table内のtrタグが表の一列をなしているのがわかります。classは"mtx"だそうです。matrixの略ですね。最初の四列は横軸なので不必要です。ちなみにtrタグの中は下のようにtdタグになっています。
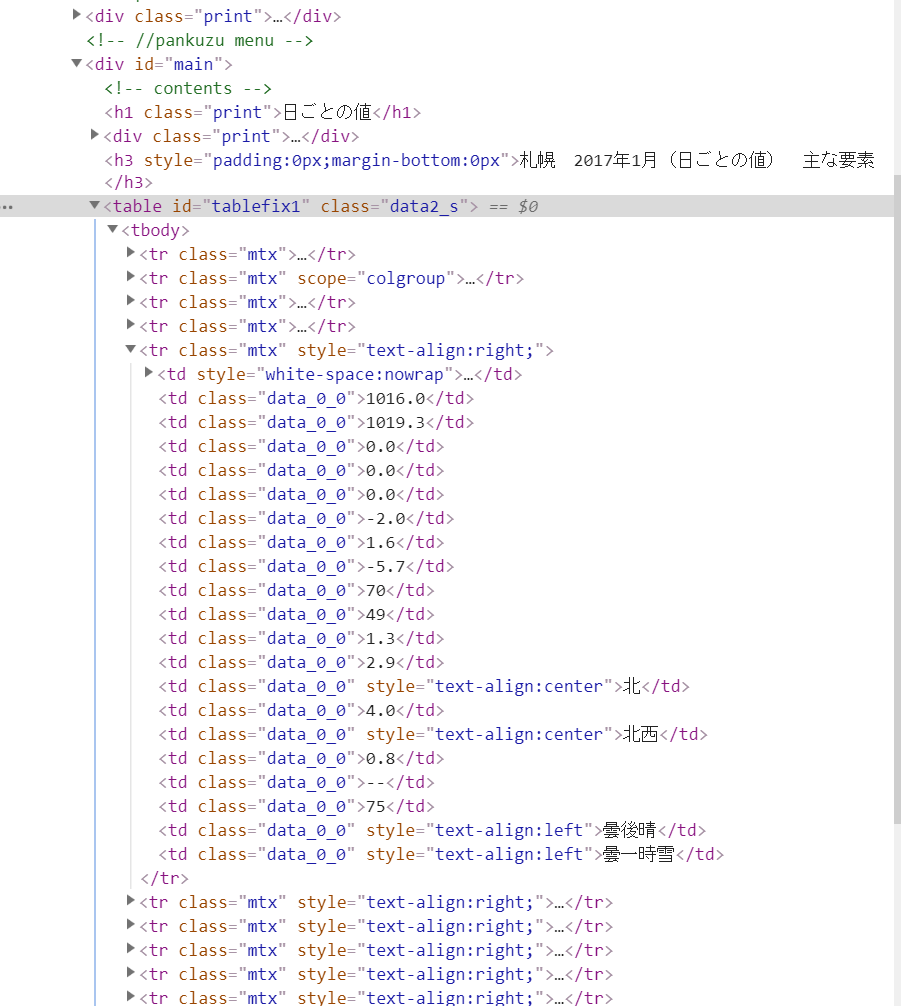
さて、仕組みが分かったところで実装しましょう。
4.実装
まずは、都市名、prec_no、block_noを調べ上げてlistにしましょう。以下の通りです。
place_codeA = [14, 21, 23, 31, 32, 33, 35, 34, 36, 54, 56, 55, 48, 41, 57, 42, 43, 40, 52, 51, 49, 45, 53, 50, 46, 68, 69, 61, 60, 67, 66, 63, 65, 64, 73, 72, 74, 71, 81, 82, 85, 83, 84, 86, 88, 87]
place_codeB = [47412, 47423, 47430, 47575, 47582, 47584, 47588, 47590, 47595, 47604, 47605, 47607, 47610, 47615, 47616, 47624, 47626, 47629, 47632, 47636, 47638, 47648, 47651, 47656, 47670, 47741, 47746, 47759, 47761, 47765, 47768, 47770, 47777, 47780, 47887, 47891, 47893, 47895, 47762, 47807, 47813, 47815, 47817, 47819, 47827, 47830]
place_name = ["札幌", "室蘭", "函館", "青森", "秋田", "盛岡", "山形", "仙台", "福島", "新潟", "金沢", "富山", "長野", "宇都宮", "福井", "前橋", "熊谷", "水戸", "岐阜", "名古屋", "甲府", "銚子", "津", "静岡", "横浜", "松江", "鳥取", "京都", "彦根", "広島", "岡山", "神戸", "和歌山", "奈良", "松山", "高松", "高知", "徳島", "下関", "福岡", "佐賀", "大分", "長崎", "熊本", "鹿児島", "宮崎"]
インデックス番号で等しくなっています。例えば札幌はplace_nameのなかの0番ですから、prec_codeはplace_codeAの0番。また、place_codeBの0番です。まぁ、順序が同じってことです。追加したい都市を後ろに追加すればいいだけです。(prec_noとblock_noはサイトにアクセスすればURLに書いてあります。ちゃんと追加してくださいね。)
実装に移りましょう。
# さっきの
place_codeA = [14, 21, 23, 31, 32, 33, 35, 34, 36, 54, 56, 55, 48, 41, 57, 42, 43, 40, 52, 51, 49, 45, 53, 50, 46, 68, 69, 61, 60, 67, 66, 63, 65, 64, 73, 72, 74, 71, 81, 82, 85, 83, 84, 86, 88, 87]
place_codeB = [47412, 47423, 47430, 47575, 47582, 47584, 47588, 47590, 47595, 47604, 47605, 47607, 47610, 47615, 47616, 47624, 47626, 47629, 47632, 47636, 47638, 47648, 47651, 47656, 47670, 47741, 47746, 47759, 47761, 47765, 47768, 47770, 47777, 47780, 47887, 47891, 47893, 47895, 47762, 47807, 47813, 47815, 47817, 47819, 47827, 47830]
place_name = ["札幌", "室蘭", "函館", "青森", "秋田", "盛岡", "山形", "仙台", "福島", "新潟", "金沢", "富山", "長野", "宇都宮", "福井", "前橋", "熊谷", "水戸", "岐阜", "名古屋", "甲府", "銚子", "津", "静岡", "横浜", "松江", "鳥取", "京都", "彦根", "広島", "岡山", "神戸", "和歌山", "奈良", "松山", "高松", "高知", "徳島", "下関", "福岡", "佐賀", "大分", "長崎", "熊本", "鹿児島", "宮崎"]
import requests
from bs4 import BeautifulSoup #ダウンロードしてなかったらpipでできるからやってね。
import csv
# URLで年と月ごとの設定ができるので%sで指定した英数字を埋め込めるようにします。
base_url = "http://www.data.jma.go.jp/obd/stats/etrn/view/daily_s1.php?prec_no=%s&block_no=%s&year=%s&month=%s&day=1&view=p1"
# 取ったデータをfloat型に変えるやつ。(データが取れなかったとき気象庁は"/"を埋め込んでいるから0に変える)
def str2float(str):
try:
return float(str)
except:
return 0.0
if __name__ == "__main__":
#都市を網羅します
for place in place_name:
#最終的にデータを集めるリスト (下に書いてある初期値は一行目。つまり、ヘッダー。)
All_list = [['年月日', '陸の平均気圧(hPa)', '海の平均気圧(hPa)', '降水量(mm)', '平均気温(℃)', '平均湿度(%)', '平均風速(m/s)', '日照時間(h)']]
print(place)
index = place_name.index(place)
# for文で2007年~2017年までの11回。
for year in range(2007,2018):
print(year)
# その年の1月~12月の12回を網羅する。
for month in range(1,13):
#2つの都市コードと年と月を当てはめる。
r = requests.get(base_url%(place_codeA[index], place_codeB[index], year, month))
r.encoding = r.apparent_encoding
# まずはサイトごとスクレイピング
soup = BeautifulSoup(r.text)
# findAllで条件に一致するものをすべて抜き出します。
# 今回の条件はtrタグでclassがmtxになってるものです。
rows = soup.findAll('tr',class_='mtx')
# 表の最初の1~4行目はカラム情報なのでスライスする。(indexだから初めは0だよ)
# 【追記】2020/3/11 申し訳ございません。間違えてました。
rows = rows[4:]
# 1日〜最終日までの1行を網羅し、取得します。
for row in rows:
# 今度はtrのなかのtdをすべて抜き出します
data = row.findAll('td')
#1行の中には様々なデータがあるので全部取り出す。
# ★ポイント
rowData = [] #初期化
rowData.append(str(year) + "/" + str(month) + "/" + str(data[0].string))
rowData.append(str2float(data[1].string))
rowData.append(str2float(data[2].string))
rowData.append(str2float(data[3].string))
rowData.append(str2float(data[6].string))
rowData.append(str2float(data[9].string))
rowData.append(str2float(data[11].string))
rowData.append(str2float(data[16].string))
#次の行にデータを追加
All_list.append(rowData)
#都市ごとにデータをファイルを新しく生成して書き出す。(csvファイル形式。名前は都市名)
with open(place + '.csv', 'w') as file:
writer = csv.writer(file, lineterminator='\n')
writer.writerows(All_list)
コメントを雑ではありますが書いておいたので、半分はそれで理解を。
★ポイントの解説
BeautifulSoupは名前こそ面白いものの、HTML語のデータをわかりやすい形で抜き出します。そのデータをインデックスでとればいいのです。あとは左からn番目のtdを取得して配列に入れてあげます。
GoogleColaboratoryでのデータのダウンロード
GoogleColaboratoryではファイルを生成しても仮想サーバー上に生成されるだけです。仮想サーバー上にあるデータをダウンロードしましょう。
# さっきの(セルを新たに作ってやれば簡単)
place_codeA = [14, 21, 23, 31, 32, 33, 35, 34, 36, 54, 56, 55, 48, 41, 57, 42, 43, 40, 52, 51, 49, 45, 53, 50, 46, 68, 69, 61, 60, 67, 66, 63, 65, 64, 73, 72, 74, 71, 81, 82, 85, 83, 84, 86, 88, 87]
place_codeB = [47412, 47423, 47430, 47575, 47582, 47584, 47588, 47590, 47595, 47604, 47605, 47607, 47610, 47615, 47616, 47624, 47626, 47629, 47632, 47636, 47638, 47648, 47651, 47656, 47670, 47741, 47746, 47759, 47761, 47765, 47768, 47770, 47777, 47780, 47887, 47891, 47893, 47895, 47762, 47807, 47813, 47815, 47817, 47819, 47827, 47830]
place_name = ["札幌", "室蘭", "函館", "青森", "秋田", "盛岡", "山形", "仙台", "福島", "新潟", "金沢", "富山", "長野", "宇都宮", "福井", "前橋", "熊谷", "水戸", "岐阜", "名古屋", "甲府", "銚子", "津", "静岡", "横浜", "松江", "鳥取", "京都", "彦根", "広島", "岡山", "神戸", "和歌山", "奈良", "松山", "高松", "高知", "徳島", "下関", "福岡", "佐賀", "大分", "長崎", "熊本", "鹿児島", "宮崎"]
from google.colab import files
for place in place_name:
files.download(place + '.csv')
途中で「このサイトからの連続のファイルダウンロードを許可しますか?」みたいのが出てくるので許可を押してください。これでローカルにダウンロードできたはずです。
4.まとめ
こんかいは特定のサイトがスクレイピングできるかどうかを判断しそのサイトの規則性を見出して連続でスクレイピングしてみました。急いで書き上げたので至らなかったところもあるかと思います。ぜひ、質問してください。
Twitter: https://twitter.com/CyberHacnoshuke (フォローしてくださいお願いします。)
Github: https://github.com/CyberHacnoshuke