厳密にはトラブルというよりは、AmazonLinux2のDocker周りで仕様変更が見られたので、さかのぼって色々調べてみた話です。
システム構成はこんな感じ
スタンダードな構成でWebサービスを構成しています。
- インフラ
- AWS
- EC2/AmazonLinux2
- ALB
- AutoScaling
- CodePipeline/CodeDeploy/ECR
- アプリ・ミドルウェア
- PHP
- Laravel(Laradock)
- node.js
- vue.js
- Docker/docker-compose
- DB・データソース
- Aurora RDS
Dockerは18.06と19.02の混在、docker-composeは1.18で、ともにamazon-linux-extrasのパッケージを使用(なのでまぁまぁ古い)。
運用はざっくりこんな感じ
- AutoScalingにて早朝06:00、夕方17:00、深夜12:00、02:00に自動スケーリングを行っている。
- AMIからインスタンスを起動する際に、systemdでdockerを起動している
- デプロイは週1~2回ほど、まとめてリリースする。
- CD構成は手作業のデプロイから自動化するにあたり、当初CircleCI+CodeBuild+ECR+ECSで組んだものの、リードタイムが長くなってしまい、リリース時の時間短縮のためECR+CodeDeploy(ある程度バージョンを固定したAMIを使い、AfterInstallイベント時にdocker buildするという力技)でしのいでいる。
- インスタンスやPHP、dockerを始めとしたフレームワークのアップデートは不定期で行うが、今年はタスクが押しててあまり実施できていない(RDSのアップデートとnginxのコンテナイメージを上げたくらい)。
トラブルの概要
とある日の夕方、監視ツールやデプロイ系のログチェックを行っていたところ、AutoScalingでの自動スケーリングにおいて、デプロイエラーが大量に繰り返されているのを確認し、調査。
幸いAutoScalingでの構成は常時稼働しているインスタンス(Docker18.06)と、自動スケーリングで短時間起動するインスタンス(Docker19.02)の2グループに分けていたので、スケーリングが出来ずデグレード状態になったが、サービスダウンは回避できた(とはいえ、少しロードが増えた…)

AfterInstallイベント時に実行しようとしていたコマンドライン(一部)
/usr/bin/docker-compose -f /path/to/apps/docker-compose.yml run --rm php-fpm-as-workspace npm install
/usr/bin/docker-compose -f /path/to/apps/docker-compose.yml run --rm composer ash -c "composer install"
CodeDeployのエラーメッセージ抜粋
[stderr]Couldn't connect to Docker daemon at http+docker://localunixsocket - is it running?
[stderr]
[stderr]If it's at a non-standard location, specify the URL with the DOCKER_HOST environment variable.
実際のログ
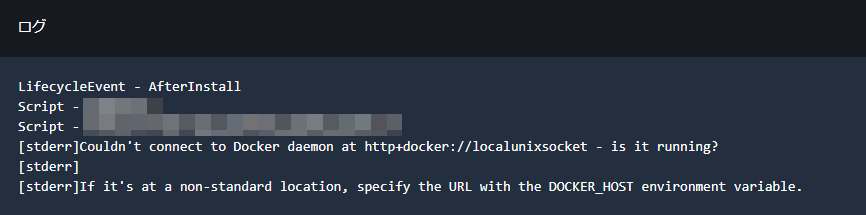
InstallイベントでEC2上にソースを展開し、AfterInstallイベントのところでdocker-composeを実行しているが、ここで "Couldn't connect to Docker daemon at~"が発生。
メッセージから察するに、
- インスタンス起動時にdockerデーモンが起動できなかった(なにかしらの起動できない原因が出来た)?
- 環境変数が反映できていない?
辺りが考えられるが、AutoScalingでデプロイに失敗したインスタンスはそのままTerminateしてしまい、インスタンスにアクセスして調べることが出来ないため、AutoScalingの起動設定に指定しているAMIから手動でインスタンスを起動し、稼働中のインスタンスのdockerと比較してみることに。
調べてみたところ…
まずdockerのバージョン確認
インスタンス起動直後にデプロイでコケてるのでcloud-initでバージョンアップとかしてるかも、と思って調べたら、まずはビンゴ。
稼働中インスタンス
(以降インスタンスAとします)
長期稼働しているインスタンスなので、特に変わらず。
$ sudo docker -v
Docker version 18.06.1-ce, build e68fc7a215d7133c34aa18e3b72b4a21fd0c6136
$ docker-compose -v
docker-compose version 1.18.0, build 8dd22a9
検証用に立ち上げたインスタンス
(以降インスタンスBとします)
$ sudo docker -v
Docker version 20.10.7, build f0df350
$ docker-compose -v
docker-compose version 1.18.0, build 8dd22a9
cloud-init-output.logを確認したところ、インスタンス起動時にyum updateが走ってバージョンアップされていることも確認。これはOK。
ソケットエラーの確認
続けて、エラーメッセージの"Couldn't connect to Docker daemon at http+docker://localunixsocket"部分の確認のため、ソケット周りを調べてみたところ…
▼インスタンスA(Docker18.06.1)
1)docker.sock
$ sudo ls -al /var/run/docker.sock
srw-rw---- 1 root docker 0 Mar 23 2021 /var/run/docker.sock
$ sudo ls -al /run/docker.sock
srw-rw---- 1 root docker 0 Mar 23 2021 /run/docker.sock
2)docker-containerd.sock
$ sudo ls -al /var/run/docker/containerd/docker-containerd.sock
srw-rw---- 1 root root 0 Mar 23 2021 /var/run/docker/containerd/docker-containerd.sock
$ sudo ls -al /run/docker/containerd/docker-containerd.sock
srw-rw---- 1 root root 0 Mar 23 2021 /run/docker/containerd/docker-containerd.sock
▼インスタンスB(Docker20.10.7)
1)docker.sock
$ sudo ls -al /var/run/docker.sock
srw-rw---- 1 root docker 0 Dec 8 11:48 /var/run/docker.sock
$ sudo ls -al /run/docker.sock
srw-rw---- 1 root docker 0 Dec 8 11:48 /run/docker.sock
→docker.socketは変わっていなかったで問題なし。
2)docker-containerd.sock
$ sudo ls -al /var/run/docker/containerd/docker-containerd.sock
ls: cannot access /var/run/docker/containerd/docker-containerd.sock: No such file or directory
$ sudo ls -al /run/docker/containerd/docker-containerd.sock
ls: cannot access /run/docker/containerd/docker-containerd.sock: No such file or directory
→docker-containerd.sockがいない!どこ行った?
と思ったら…ここにいた↓
$ sudo ls -al /var/run/containerd/containerd.sock
srw-rw---- 1 root root 0 Dec 8 11:49 /var/run/containerd/containerd.sock
$ sudo ls -al /run/containerd/containerd.sock
srw-rw---- 1 root root 0 Dec 8 11:49 /run/containerd/containerd.sock
さらにソケット名から"docker-"が消えてcontainerdに変わっている、ということでパッケージを見てみたら…
→docker20.10.7へのアップデート時に、コンテナラインタイムがcontainerdに変わってた。
▼コンテナランタイムの非推奨化の話が1年たって実装に?
ここでも似たようなトラブルについてディスカッションされていた。
https://github.com/docker/for-linux/issues/517
ここを見ると、Dockerバージョンは20.04、2020年の12月頃
https://github.com/docker/for-linux/issues/517#issuecomment-749197818
1年ほど前にKubernetes界隈で話題になっていたDockershimランタイムの非推奨化→今後はcontainerdにするよ、の話が話題になったが、その後1年たってkubernetes/EKSに対応するため、amazon-linux-extras管理下のdockerにも適用された、といったところかな。
https://kubernetes.io/blog/2020/12/02/dockershim-faq/
https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG/CHANGELOG-1.20.md#deprecation
上記では
『Kubernetes 1.22より前では削除されません。つまり、dockershimを使用しない最も早いリリースは2021年後半に1.23になります。』
となっており、その後
https://github.com/kubernetes/enhancements/tree/master/keps/sig-node/2221-remove-dockershim
では
『(dockershim削除の)ターゲットリリース:1.24(1年に3回、または2022年4月以降にリリースを想定)』
となっているので気持ち余裕がある一方、Amazon EKSでは12/08時点で対応している最新バージョンは1.21なので、amazon-linux-extrasのパッケージでもいよいよ対応、ということかも知れない?(タイミング的にはわかる)
但しソースは無いので推測です(汗)
コンテナ関連の実装はECS+FargateだけでKubernetesは使ってないから影響ないかな、と思っていたらバージョンアップで対応され、そしてランタイムがcontainerdに切り替わったことでソケットが変わってエラーが出た、ということだったw
確認できたこと
- AutoScalingでのEC2インスタンスの初回起動時のyum updateの実行によりdockerがバージョンアップされた
- 使ってないので影響は無いと思っていたkubernetesのコンテナランタイム変更の影響を地味に受けた
- kubernetes公式の仕様変更(dockershim廃止)の影響というよりはAWSの対応の影響だった、という認識で相違無さそう
- バージョンアップ後にdockerデーモンを再起動すれば特に問題にならない話だったが、CodeDeployのAfterInstallイベントでdockerのデーモンを再起動する、という発想はさすがになかった
(やるならApplicationStartイベントだろうし、そもそもインスタンス上でdocker buildしてる古いやり方なので、dockerが止まってるとビルドできないトホホな仕様なので…)
今後やること
- AMI初回起動時のyum updateの方針見直し
Amazon Linux2のcloud-initはsecurityアップデートのみなので正直スルーしていた(汗)、という反省点も踏まえつつ、運用上の予想外のトラブルを無くすことと、バージョンアップはちゃんと手間をかけて検証することを目的に、仕切り直す。
- 実際のところ、コンテナランタイムの変更が本質的な問題だったわけではないが、まだ古いバージョンのコンテナが社内のあちこちで動いているので、このタイミングでアップデートを進めていく(ECSインスタンス、Fargateはともかく、EC2でコンテナを動かしているものも結構あるのでw)