本記事は、 Quick Draw!データセットに基づいて学習し、りんご (apple) の手描き風イラストを出力するGAN (Generative Adversarial Network : 敵対的生成ネットワーク) の実装と学習方法 について解説します。本記事で紹介するネットワークは生成AIのうち画像を生成するものであり、画像と相性のよい 畳み込み層/逆畳み込み層を利用するため「DCGAN(Deep Convolutional-Generative Adversarial Network)」とも呼ばれるモデル になります。
GANにより解決する問題
GANは生成AIを実装するためのテクニックのひとつです。 判別器と呼ばれる、入力された画像が自然なもの(データセット由来のもの)かAIにより生成されためものかを判別するネットワーク と、 生成器と呼ばれるノイズデータ(乱数の配列)からデータセットに近いであろう画像を生成するネットワーク を利用します。GANにおける生成器は、判別器を騙せる画像を生成する事を試みます。そして、判別器は、賢くなった生成器により作成された画像とデータセットの画像を分類することを試みます。GANはこのように2つのネットワークを対立させることにより、 最終的に、判別器も人間ですら判断がつかないような画像を生成できる生成器を獲得 します。
本記事では りんごの手書き風イラストを生成できるGANを実装 します。学習用のデータセットには、Quick Draw!の提供する apple.npy を利用しました。

GAN (Generative Adversarial Network : 敵対的生成ネットワーク) とは
GANについては多くのWebサイトが、これに言及しています。より理解を深めたい方は、そちらも合わせてご覧ください。
本記事の実装により実現できる生成AIの出力
本記事で実装するAIモデルを学習することにより、以下のような 手書き風イラストを出力できる生成器を入手することができます。 左から100epochsの学習時、200epochs、400epochs、1000epochs、2000epochsの結果となります。ほぼ、人間による手書き画像(学習用データセット)と一致していると言っても良いのではないでしょうか。

生成AIと著作権に関するガイドライン
生成AIは特定の学習用データセットに基づいてAIモデルをチューニングし、出力を得るシステムです。このとき 「学習用データセット」の著作権と、「出力されたデータ」の著作権を理解しておく ことは非常に重要です。AIをビジネスで利用されている日立ソリューションズ・クリエイト社が、著作権に関するガイドラインを抜粋した記事を作成されていますので、ここで紹介しておきます。 ビジネスに生成AIを利用される方は十分にご注意ください。
参考文献
本記事は、下記の資料を参考にさせていただきました。
はじめてTensorFlowを扱われる方へ
TensorFlowではじめてニューラルネットワークを実装される方にむけて、TensorFlowの基本的な使い方を以下の記事にて紹介しております。
GAN (Generative Adversarial Network : 敵対的生成ネットワーク) を使ってりんごの手書き風イラストを生成するまでのステップ
今回はTensorFlow.kerasプラットフォーム上でGANを実装します。実装までの流れは次の通りです。順番に見ていきましょう。
- GANの学習に使うデータセットの入手
- 判別器と生成器の実装
- GANの実装と学習
- 学習結果の確認
開発用のディレクトリを準備する
まず作業ディレクトリを作成し、Python仮想環境を定義した後に、Pythonの実行に必要なパッケージをインストールしていきます。今回はTensorFlowの開発環境を準備しました。
$ cd ~
# 作業ディレクトリを作成する
$ mkdir ./cgan_test
$ cd ./cgan_test
# Pythonの仮想環境を作成する
$ conda create -n quickdraw_gan python=3.10
# Pythonの仮想環境にログインする
$ conda activate quickdraw_gan
# 必要なパッケージをインストールする
$ pip3 install tensorflow
$ pip3 install -U numpy==1.26.4
$ pip3 install matplotlib
$ pip3 install pandas
新しいソースコード 「quickdraw_gan.py」を作成 後、Visual Studio Codeの右下にあるPythonのバージョン表示部をクリックし、 Pythonの仮想環境「quickdraw_gan」 を選択します。
学習用データセット「Quick Draw!」を取得する
開発ディレクトリ内に、datasetディレクトリを作成し、Quick Draw!のnumpy形式のデータセットをダウンロードします。Quick Draw!のデータセットはGoogle Cloud Storageに格納されているため、 ローカルPCからGoogle Cloud Storageを操作するために必要な「gcloud CLI」をインストール します。
gcloud CLIをインストールする
まず、次のWebサイトを参考にgcloud CLIをインストールします。
# ホームディレクトリへ移動する
$ cd ~
# curlコマンドでインストーラを取得する
$ curl -O https://dl.google.com/dl/cloudsdk/channels/rapid/downloads/google-cloud-cli-linux-x86_64.tar.gz
# インストーラーを展開する
$ tar -xf google-cloud-cli-linux-x86_64.tar.gz
# 展開後のディレクトリを確認
ls google-cloud-sdk/
# LICENSE VERSION completion.zsh.inc install.bat path.bash.inc platform
# README bin data install.sh path.fish.inc properties
# RELEASE_NOTES completion.bash.inc deb lib path.zsh.inc rpm
# インストールする
$ ./google-cloud-sdk/install.sh
# Do you want to help improve the Google Cloud CLI (y/N)? <enter>
# Do you want to continue (Y/n)? <enter>
# Enter a path to an rc file to update, or leave blank to use [/home/shino/.bashrc]: <enter>
# ==> Start a new shell for the changes to take effect.
# ...
###
# 端末を開きなおす or source ~/.bashrc
###
gcloud CLIをセットアップする
gcloud CLIをインストールした後 gcloud init を実行し、Google Cloud Storageへのアクセス権限を設定 します。
# gcloud CLIでの操作を開始する
$ gcloud init
# You must sign in to continue. Would you like to sign in (Y/n)?
# Go to the following link in your browser, and complete the sign-in prompts:
#
# https://accounts.google.com/o/oauth2/auth?response_type=code&client_id=32555940559.apps.googleusercontent.com&redirect_uri=https%3A%2F%2Fsdk.cloud.google.com%2Fauthcode.html&scope=openid+https%3A%2F%2Fwww.googleapis.com%2Fauth%2Fuserinfo.email+https%3A%2F%2Fwww.googleapis.com%2Fauth%2Fcloud-platform+https%3A%2F%2Fwww.googleapis.com%2Fauth%2Fappengine.admin+https%3A%2F%2Fwww.googleapis.com%2Fauth%2Fsqlservice.login+https%3A%2F%2Fwww.googleapis.com%2Fauth%2Fcompute+https%3A%2F%2Fwww.googleapis.com%2Fauth%2Faccounts.reauth&state=ZJm8uJMoE1a9e6cUvmLNnaWaSKzLdS&prompt=consent&token_usage=remote&access_type=offline&code_challenge=Ak-ECdJ9ZzXK-HS3ohM9B4yjsBlqNssThLQl4IqFd18&code_challenge_method=S256
######
### 上のリンクをブラウザで開く
######
gcloud initの途中でWebブラウザを使ってログイン情報を取得することが求められますので、 リンクURLをコピーしてブラウザからGoogleアカウントにログインし、下記のようなパスフレーズを取得 します。
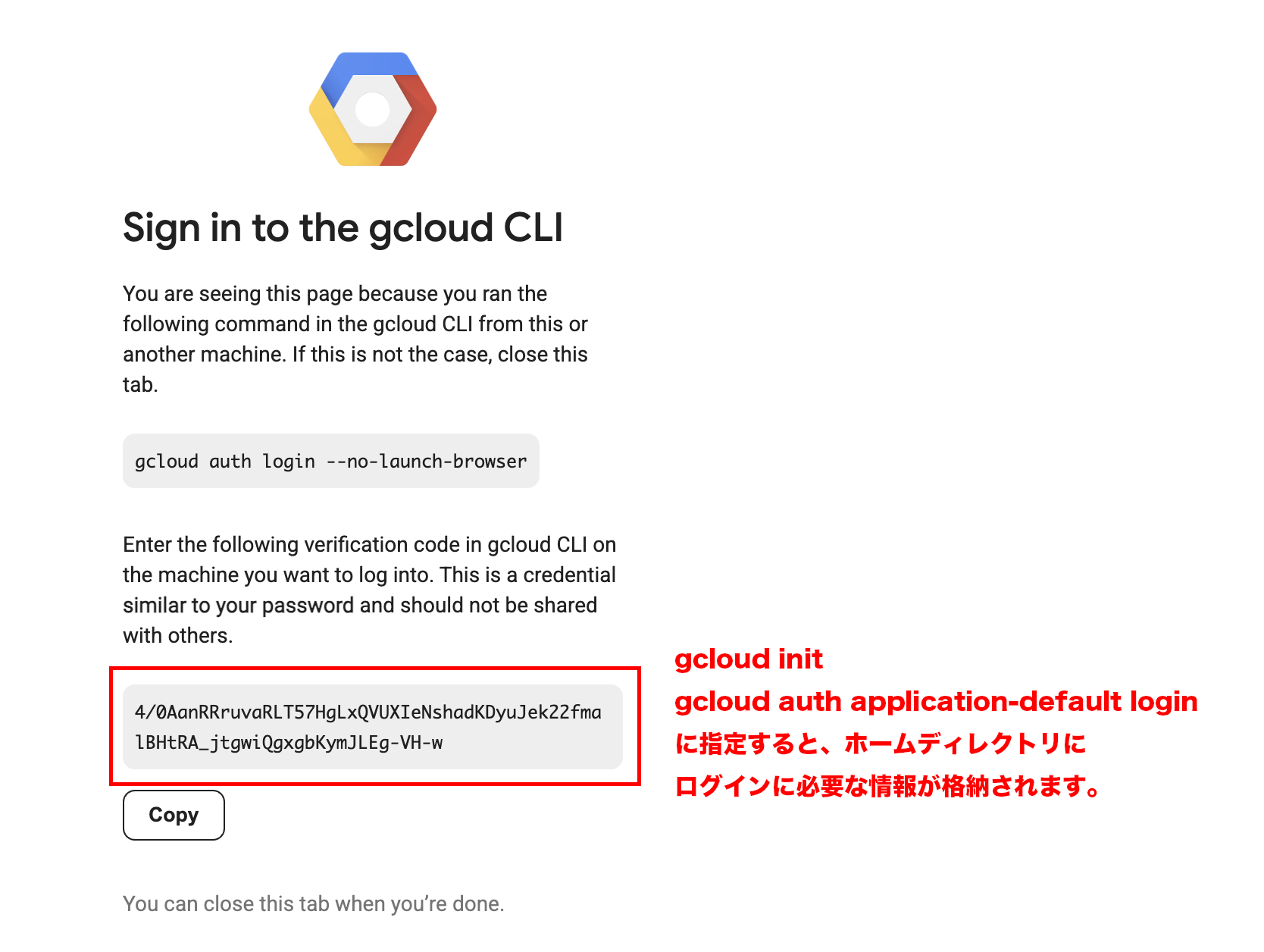
パスフレーズを取得した後 gcloud init へ取得したパスフレーズを入力し、セットアップを再開 します。ユーザー名の選択や、操作に利用するプロジェクト名の選択を行い(今回は「Create a new project」で「gcs-contents-download」プロジェクトを作成しました)、セットアップを完了させます。
# Once finished, enter the verification code provided in your browser:
# -->> ブラウザを操作することで得ることのできるパスフレーズを入力する
### 4/0AanRRruvaRLT57HgLxQVUXIeNshadKDyuJek22fmalBHtRA_jtgwiQgxgbKymJLEg-VH-w
######
### アカウントを選択する
######
# Select an account:
# [1] ixiv2015@gmail.com
# [2] Sign in with a new Google Account
# [3] Skip this step
# Please enter your numeric choice: 1
### You are signed in as: [ixiv2015@gmail.com].
######
### Cloud Projectを作成するか確認
######
# Pick cloud project to use:
# [1] ixydesign-webform
# [2] Enter a project ID
# [3] Create a new project
### Create a new projectを選択
# Please enter numeric choice or text value (must exactly match list item): 3
# Enter a Project ID. Note that a Project ID CANNOT be changed later.
# Project IDs must be 6-30 characters (lowercase ASCII, digits, or
# hyphens) in length and start with a lowercase letter.
# -->> gcs-contents-download を入力
# Waiting for [operations/cp.8699767152410418838] to finish...done
# * Commands that require authentication will use ixiv2015@gmail.com by default
# * Commands will reference project `gcs-contents-download` by default
# Run `gcloud help config` to learn how to change individual settings
# ...
application_default_credentials.jsonを作成する
gcloud initの後、 ログイン情報をホームディレクトリに保存するために gcloud auth application-default login を実行 します。この時もブラウザにてGoogleアカウントへログインすることが求められますので、指示に従ってください。
######
### 認証情報を再度取得するには以下を実行
######
$ gcloud auth application-default login
# Go to the following link in your browser, and complete the sign-in prompts:
#
# https://accounts.google.com/o/oauth2/auth?response_type=code&client_id=764086051850-6qr4p6gpi6hn506pt8ejuq83di341hur.apps.googleusercontent.com&redirect_uri=https%3A%2F%2Fsdk.cloud.google.com%2Fapplicationdefaultauthcode.html&scope=openid+https%3A%2F%2Fwww.googleapis.com%2Fauth%2Fuserinfo.email+https%3A%2F%2Fwww.googleapis.com%2Fauth%2Fcloud-platform+https%3A%2F%2Fwww.googleapis.com%2Fauth%2Fsqlservice.login&state=3Fm0hlyqFJCZwTnlMSrVqp3fSUO9eY&prompt=consent&token_usage=remote&access_type=offline&code_challenge=vJrnn99LhoEMPsxEy6Wtmmwe5pi-E9B4PRODqgtsAZs&code_challenge_method=S256
#
# Once finished, enter the verification code provided in your browser:
# -->> ブラウザを操作することで得ることのできるパスフレーズを入力する
# 4/0AanRRrsfwoJ726vUdosRRNzMIZFjVXnf3m9sxZIAq_QDNt49sFpCUSW17MxXS1_wUclZxg
#
# Credentials saved to file: [/home/shino/.config/gcloud/application_default_credentials.json]
# These credentials will be used by any library that requests Application Default Credentials (ADC).
# Quota project "gcs-contents-download" was added to ADC which can be used by Google client libraries for billing and quota. Note that some services may still bill the project owning the resource.
# ...
設定が終わると .config/gcloud/application_default_credentials.json にGoogle Cloud Storageでファイルを操作するために必要なアクセス権限がに保存 され、ローカルPCからGoogle Cloud Storageを操作できるようになります。
Quick Draw! データセットをダウンロードする
Quick Draw!の Google Cloud Storage「quickdraw_dataset」バケット にアクセスし、「full」-「numpy_bitmap」の全ての項目を選択した後に「ダウンロード」をクリックし、学習用データをダウンロードするためのコマンドラインを取得 します。

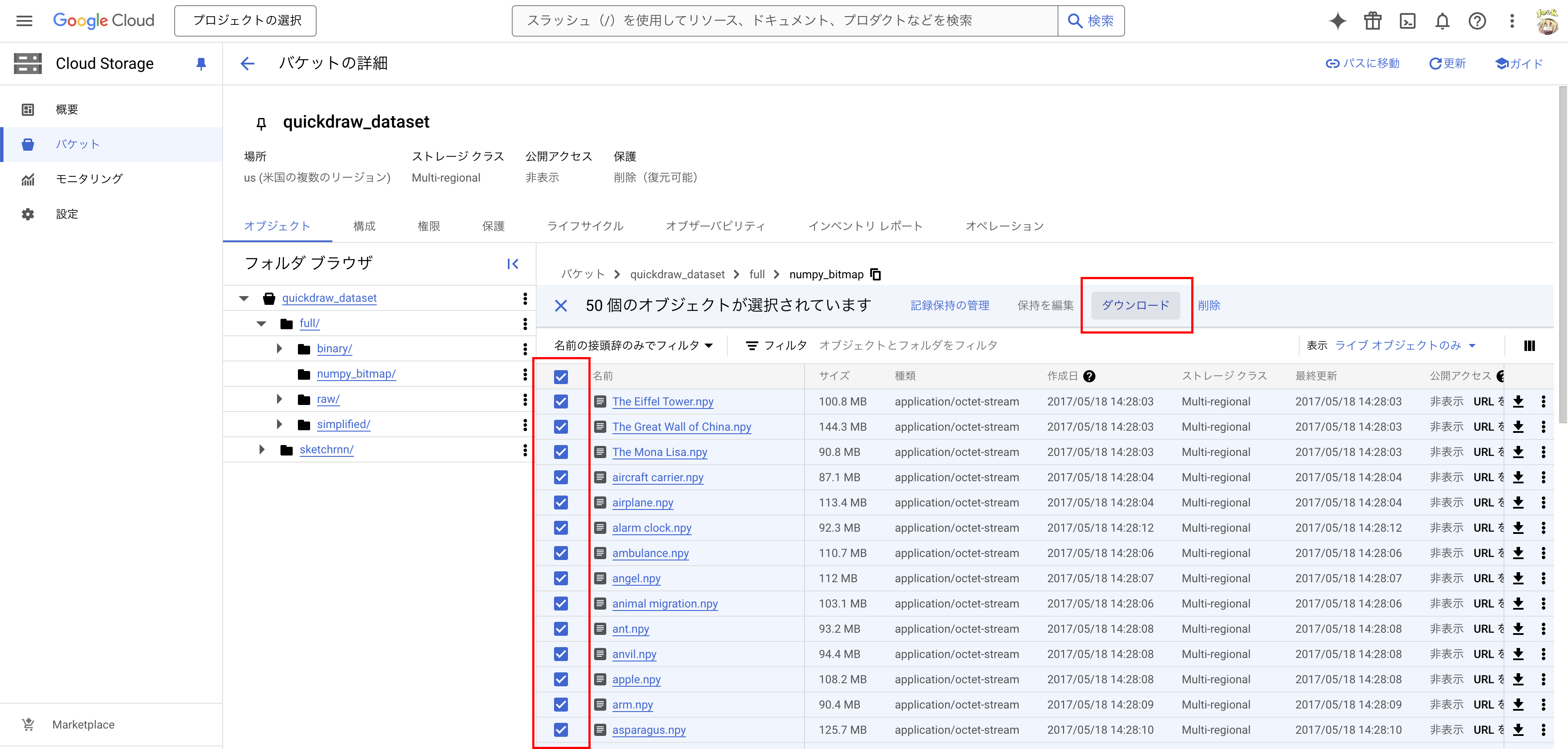

コマンドラインをgcloud CLIにより実行すると、上記で指定した学習用データをダウンロードすることができます。ダウンロードした後、以下のように 作業ディレクトリ以下の「datasetディレクトリ」に「numpy形式 (.npy)」のファイルが格納されている ことを確認してください。
$ ls ./dataset/
# 'The Eiffel Tower.npy' ant.npy barn.npy beard.npy blackberry.npy bridge.npy
# 'The Great Wall of China.npy' anvil.npy 'baseball bat.npy' bed.npy blueberry.npy broccoli.npy
# 'The Mona Lisa.npy' apple.npy baseball.npy bee.npy book.npy broom.npy
# 'aircraft carrier.npy' arm.npy basket.npy belt.npy boomerang.npy bucket.npy
# airplane.npy asparagus.npy basketball.npy bench.npy bottlecap.npy bulldozer.npy
# 'alarm clock.npy' axe.npy bat.npy bicycle.npy bowtie.npy download.py
# ambulance.npy backpack.npy bathtub.npy binoculars.npy bracelet.npy
# angel.npy banana.npy beach.npy bird.npy brain.npy
# 'animal migration.npy' bandage.npy bear.npy 'birthday cake.npy' bread.npy
以上で、開発用のディレクトリの準備は完了です。
TensorFlow.kerasでGAN (Generative Adversarial Network : 敵対的生成ネットワーク)を定義する
データセットが準備できましたので、続いてGANを実装していきます。
モデルの概要
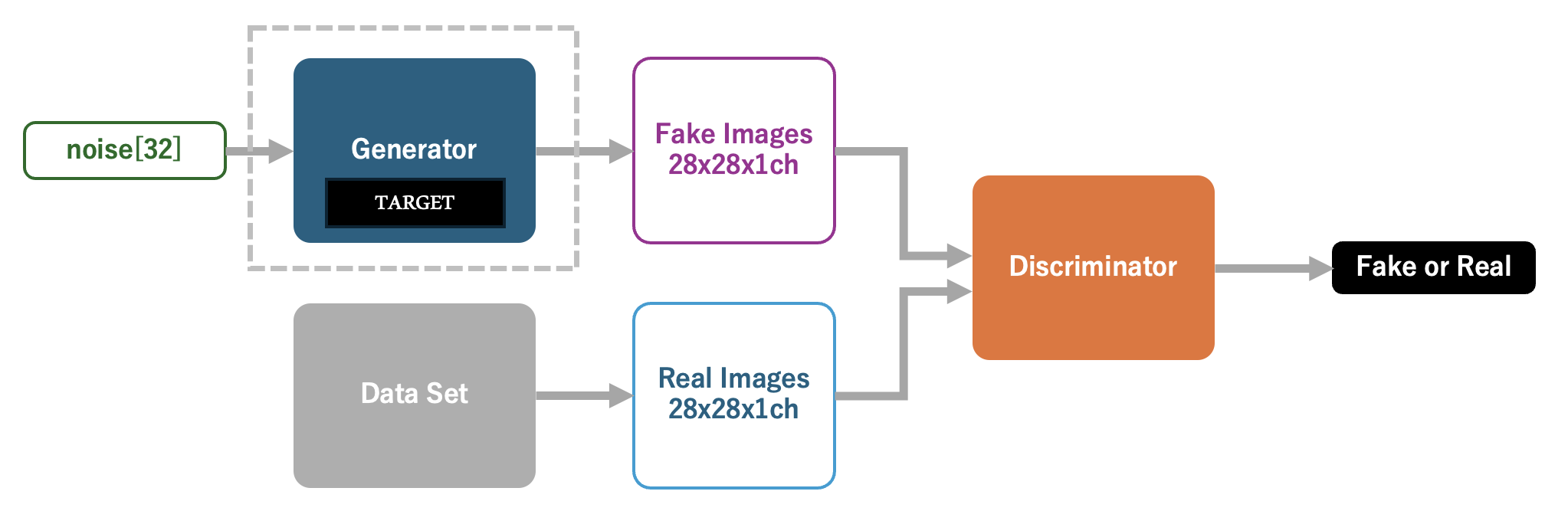
今回実装するAIモデルを以下に示します。最終的に 入手したいのは、高い精度でりんごの手書き風イラストを生成できる生成器(Generator) です。これを学習するためにAIが生成した画像(Fake Images)と、データセットからの画像(Real Images)を識別する判別器(Discriminator)を定義します。本モデルの学習を推進し、結果として 判別器(Discriminator)が本物と間違えるようなイラストを生成器(Generator)が出力できるようになれば、学習成功 と言えます。

学習用データを準備する
今回の生成AIは、Quick Draw!の提供する apple.npy (下図) と同等の手描きイラストを生成できるものとします。そのため apple.npy を読み込んだ後、縦横28pxのグレースケール画像(1ch)へと変形させ、学習用データセットとします。以下のプログラムは apple.npy を読み込み、先頭の16要素を inputs.png へ出力するものです。
from matplotlib import pyplot as plt
import numpy as np
# 学習用データセットのnumpyファイル
INPUT_IMAGE_PATH = './dataset/apple.npy'
# 学習用データセットを画像化して保存するファイルパス
INPUT_IMAGE_SAVEFIG = './inputs.png'
######
### Numpy配列の先頭16要素を画像へ書き出す
######
def image_plot(imgs, path_savefig):
output_imgs = imgs[:16,]
plt.figure(figsize=(5, 5))
for k in range(output_imgs.shape[0]):
plt.subplot(4, 4, k+1)
plt.imshow(output_imgs[k, :, :, 0], cmap='gray')
plt.tight_layout()
plt.savefig(path_savefig)
print("Save images to :", path_savefig)
plt.clf()
plt.close()
# 学習用データセットを読み込む
data = np.load(INPUT_IMAGE_PATH)
# 0.0 - 1.0 へ正規化する
data = data / 255
# 28px x 28px の2次元データに変形する
data = np.reshape(data, [data.shape[0], 28, 28, 1])
# 画像の縦横サイズを取得する
img_w, img_h = data.shape[1:3]
# 学習用データセットを画像化する
image_plot(data, INPUT_IMAGE_SAVEFIG)
######
### これ以降に学習用データセットを利用するGANを実装します
######
以下の画像ファイルが inputs.png として保存されます。
判別器を定義してコンパイルする
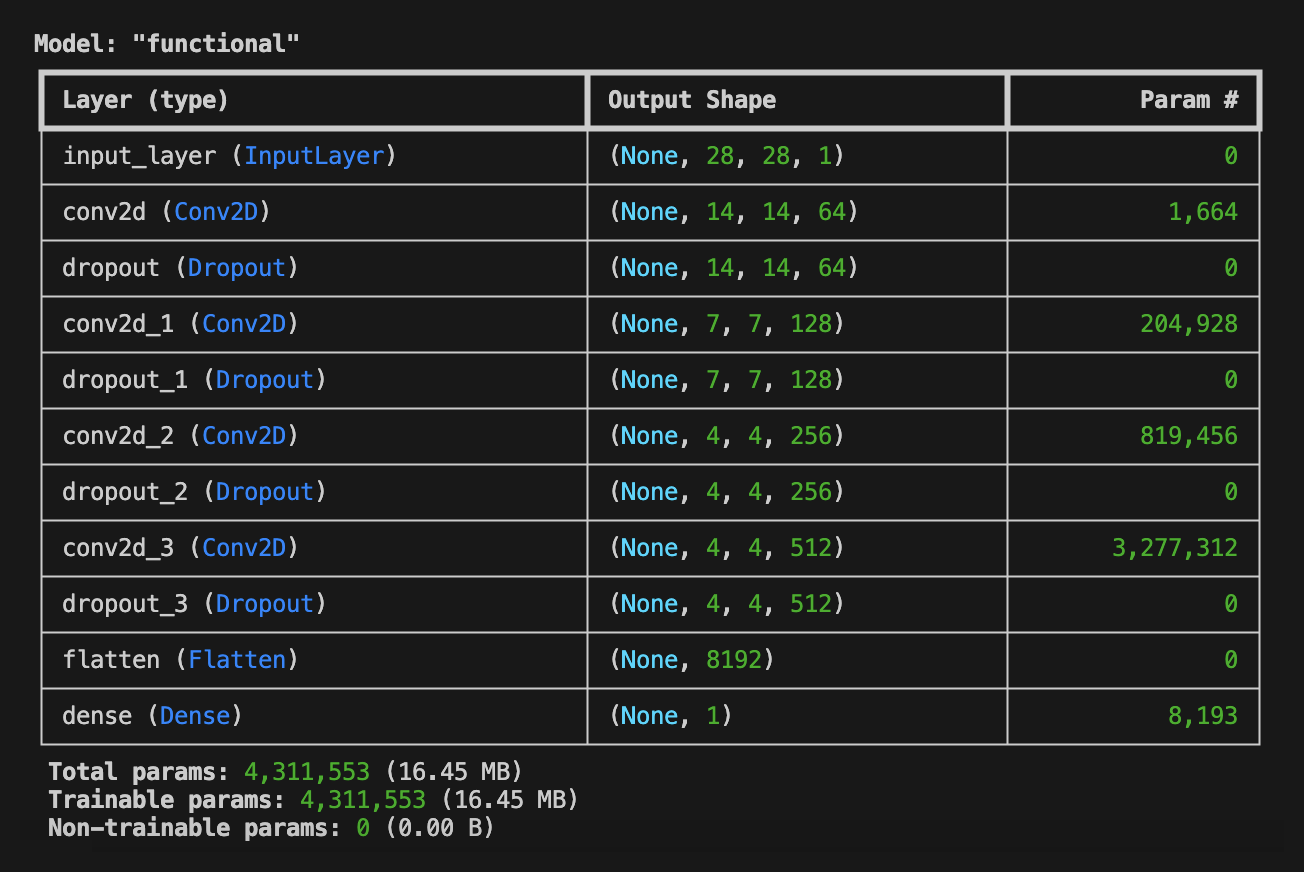
続いて判別器(Discriminator)を定義します。 Discriminatorは、1枚の画像 (ここでは28px x 28px x 1ch(Gray-Scale))を入力とし、それがFake Imagesと思えば'0'、Real Imagesと思えば'1'のバイナリ値を出力します。 画像を扱いますので、畳み込み層 (Conv2D) を利用し、28px x 28pxの画像を14x14x64、7x7x128、4x4x256、4x4x512、1x1x8192にダウンサンプリングし、最終的に全結合層を用いて、ひとつのバイナリ値を求めます。このように 畳み込み層や逆畳み込み層(Convolution)を利用したGANのことを「DCGAN(Deep Convolutional-Generative Adversarial Network)」 と呼びます。

本実装の参考とした書籍では、最適化を行うoptimizerである 「RMSprop」 に「decay」というパラメータを渡していましたが、これは廃止されたようです。そのため、 Learning Rateを調整するためのスケジューラ「D_lr_schedule」を定義して、decayに代わるパラメータとなる「decay_steps」と「decay_rate」を指定 しました。RMSpropの実装には、下記のサイトが参考になりました。
以上に基づいた判別器のソースコードは、以下のとおりです。
import tensorflow as tf
import tensorflow.keras as keras
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input
from tensorflow.keras.layers import Dense, Conv2D, Dropout
from tensorflow.keras.layers import BatchNormalization, Flatten
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Reshape
from tensorflow.keras.layers import Conv2DTranspose
from tensorflow.keras.layers import UpSampling2D
from tensorflow.keras.optimizers import RMSprop
######
### 画像がAI生成のものか学習用データセットのものかを識別する
### 判別器(discriminator)を生成する関数を定義する
######
def build_discriminator(img_w=28, img_h=28, depth=64, dropout_p=0.4):
# 入力は1枚の画像
input = Input((img_w, img_h, 1))
# 28x28に対する5x5で深さdepthの畳み込み層 -> 14x14
x = Conv2D(depth*1, 5, strides=2, padding='same', activation='relu')(input)
# Dropout
x = Dropout(dropout_p)(x)
# 14x14に対する5x5で深さdepthx2の畳み込み層 -> 7x7
x = Conv2D(depth*2, 5, strides=2, padding='same', activation='relu')(x)
# Dropout
x = Dropout(dropout_p)(x)
# 7x7に対する5x5で深さdepthx4の畳み込み層 -> 4x4
x = Conv2D(depth*4, 5, strides=2, padding='same', activation='relu')(x)
# Dropout
x = Dropout(dropout_p)(x)
# 4x4に対する3x3で深さdepthx8の畳み込み層 -> 4x4
x = Conv2D(depth*8, 5, strides=1, padding='same', activation='relu')(x)
# Dropout
x = Dropout(dropout_p)(x)
# 1次元配列に展開する
x = Flatten()(x)
# 全結合して結果を出力する
output = Dense(1, activation='sigmoid')(x)
# モデルを生成する
model = Model(inputs=input, outputs=output)
# モデルを返す
return model
# 判別器を取得する
D_model = build_discriminator(img_w=img_w, img_h=img_h, depth=64, dropout_p=0.4)
# 判別器の学習に使うLearning Rateを算出する関数を定義する
D_lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate=8e-4,
decay_steps=20000,
decay_rate=6e-8)
# 判別器をコンパイルする
D_model.compile(loss='binary_crossentropy',
optimizer=RMSprop(learning_rate=D_lr_schedule),
metrics=['accuracy'])
# modelを表示する
D_model.summary()
構築されたネットワークを model.summary() により表示すると、以下のような出力を得ることができます。このとき、 Trainable param と Total params が一致していることを確認しておいてください。
生成器を定義する
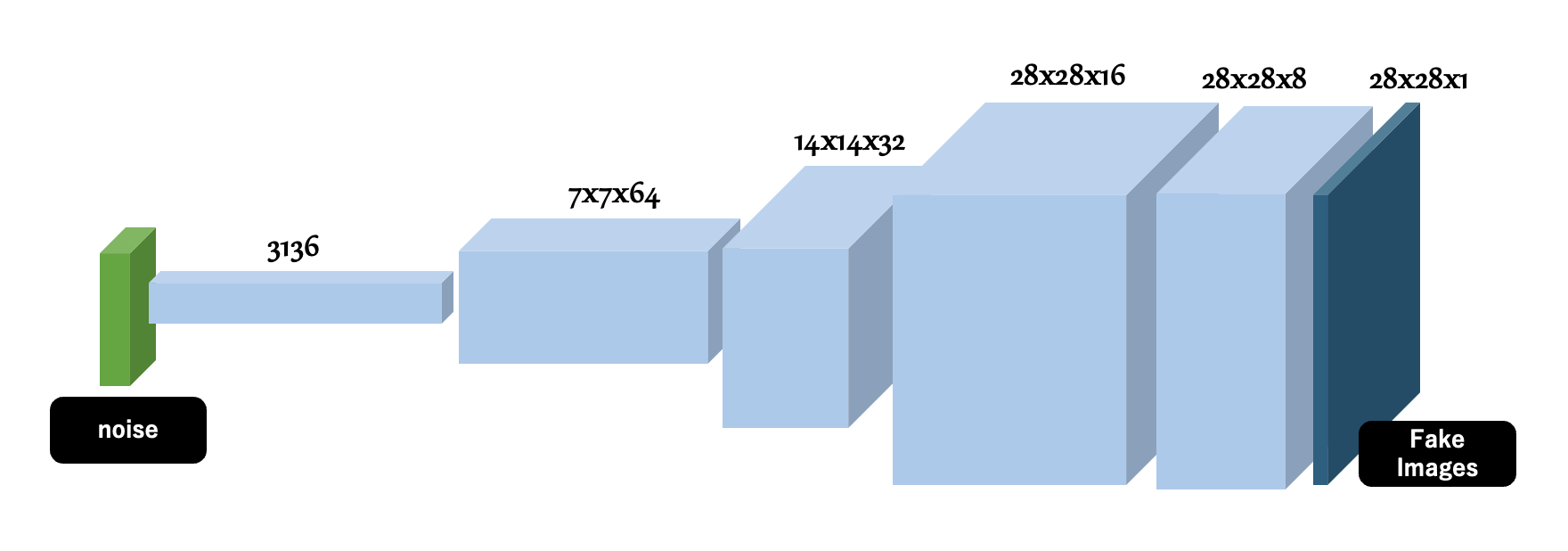
次に生成器(Generator)を定義します。 Generatorはランダムな値を含んだ「noise配列 (出力画像のバリエーションを決めるためのランダムな値)」を入力として、UpSamplingとConv2DTransposeにより、1x3136、7x7x64、14x14x32、28x28x16、28x28x8といったアップサンプリングを経て、28px x 28px x 1ch(Gray-Scale)の画像を生成 します。Generatorの生成した画像は、Fake Imagesと呼ばれ、前に定義したDescriminatorによりFakeと判断されるはずです。しかし、これを見事にRealと判定させることができれば、人の力を借りず りんごの手書き風画像をnoiseから生成することのできる生成器 を実現できるというわけです。これの実現は、後の節で定義するGAN全体による学習にて達成されます。
以上に基づいた生成器のソースコードは、以下のとおりです。
import tensorflow as tf
import tensorflow.keras as keras
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input
from tensorflow.keras.layers import Dense, Conv2D, Dropout
from tensorflow.keras.layers import BatchNormalization, Flatten
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Reshape
from tensorflow.keras.layers import Conv2DTranspose
from tensorflow.keras.layers import UpSampling2D
from tensorflow.keras.optimizers import RMSprop
######
### 乱数から学習用データと見分けの付かない画像を生成する
### 生成器(generator)を生成する関数を定義する
######
Z_DEMENSIONS = 32
def build_generator(img_w=28, img_h=28, latent_dim=Z_DEMENSIONS, depth=64, dropout_p=0.4):
# 入力は複数要素を持ったノイズデータとする
input_noise = Input((latent_dim,))
# 全結合層に展開する
x = Dense(int(img_w / 4) * int(img_h / 4) * depth)(input_noise)
x = BatchNormalization(momentum=0.9)(x)
x = Activation(activation='relu')(x)
x = Reshape((int(img_w / 4), int(img_h / 4), depth))(x)
x = Dropout(dropout_p)(x)
# アップサンプリングと逆畳み込みを適用する
# 7x7xdepthに対するアップサンプリングと逆畳み込み -> 14x14
x = UpSampling2D()(x)
x = Conv2DTranspose(int(depth/2), kernel_size=5, padding='same', activation=None,)(x)
x = BatchNormalization(momentum=0.9)(x)
x = Activation(activation='relu')(x)
# 14x14xdepth/2 に対するアップサンプリングと逆畳み込み -> 28x28
x = UpSampling2D()(x)
x = Conv2DTranspose(int(depth/4), kernel_size=5, padding='same', activation=None,)(x)
x = BatchNormalization(momentum=0.9)(x)
x = Activation(activation='relu')(x)
# 28x28xdepth/4 に対する逆畳み込み -> 28x28
x = Conv2DTranspose(int(depth/8), kernel_size=5, padding='same', activation=None,)(x)
x = BatchNormalization(momentum=0.9)(x)
x = Activation(activation='relu')(x)
# 出力層
output_img = Conv2D(1, kernel_size=5, padding='same', activation='sigmoid')(x)
# モデルを生成する
model = Model(inputs=input_noise, outputs=output_img)
# モデルを返す
return model
# 生成器を取得する
G_model = build_generator(img_w=img_w, img_h=img_h, latent_dim=32, depth=64, dropout_p=0.4)
# modelを表示する
G_model.summary()
構築されたネットワークを model.summary() により表示すると、以下のような出力を得ることができます。このとき、 Trainable param が 177,329 であることを確認しておいてください。この値は後の説明で登場します。

敵対的ネットワークを定義する
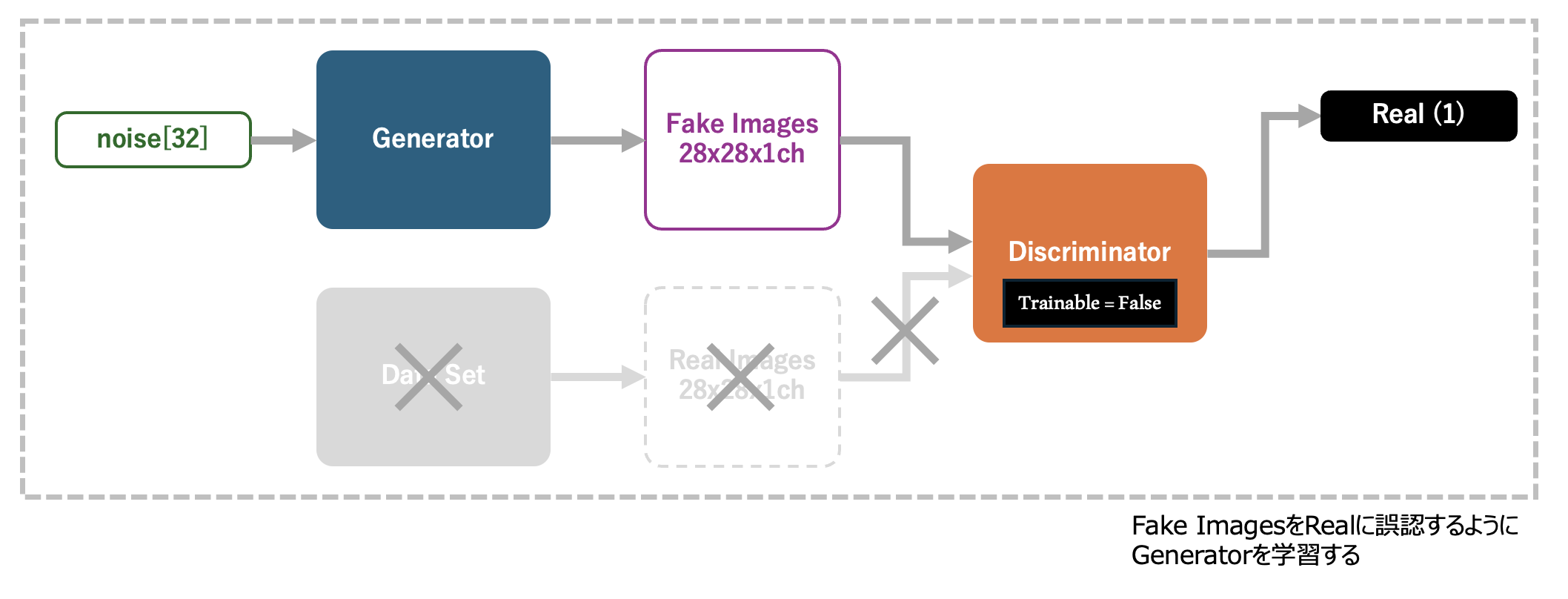
生成器と判別器を定義できたので、これらを組み合わせてGANを構築します。 GANは、生成器の入力である「noise」を入力とし、noiseからGeneratorにより生成された画像を、Discriminatorへと入力、結果、それがFakeであるかRealであるかを判別する、といった構造になっています。
Discriminatorは、GANとは別に学習を行うものとし、GANを学習させる際には、モデルの trainable 属性を False (学習によりモデルのパラメータを更新しない設定)に設定しておきます。 GANの学習は、このモデルが入力「noise」に対してGeneratorがデータセットと見分けが付かないレベルの画像を生成し、DiscriminatorがそれをReal (データセットからの画像である) と誤認できることを目的とします。
以上に基づいたGANのソースコードは、以下のとおりです。
######
### D_model と G_model を組み合わせて
### 敵対的ネットワークを構築する
######
# 入力はZ要素のノイズ
input_noise = Input(shape=(Z_DEMENSIONS,))
# ノイズからFake画像を生成する
imgs_fake = G_model(input_noise)
# 判別器の学習を止めておく
D_model.trainable = False
# 判別器でFake画像を判定する
output_pred = D_model(imgs_fake)
# ノイズを入力として、Fake判定を出力とするネットワークを構築する
A_model = Model(input_noise, output_pred)
# 判別器の学習に使うLearning Rateを算出する関数を定義する
A_lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate=4e-4,
decay_steps=20000,
decay_rate=3e-8)
# modelをコンパイルする
A_model.compile(loss='binary_crossentropy',
optimizer=RMSprop(learning_rate=A_lr_schedule),
metrics=['accuracy'])
# modelを表示する
A_model.summary()
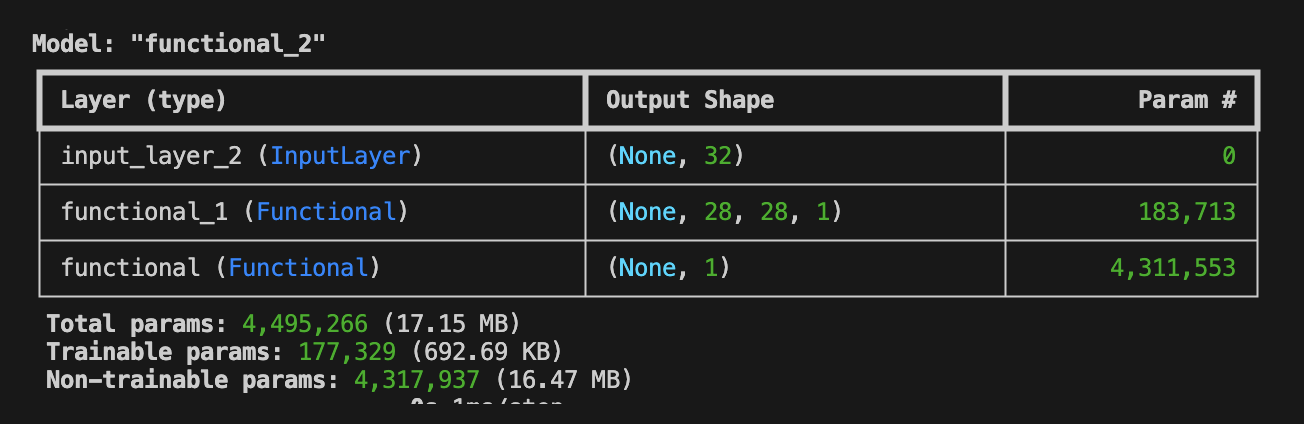
構築されたネットワークを model.summary() により表示すると、以下のような出力を得ることができます。 このとき、 Trainable param が 177,329 であることに注目してください。この値はGeneratorの Trainable param と一致 しており、このAIモデルの一部となっているDescriminatorのパラメータは Non-trainable prams として学習時に更新されないものとして扱われます。
モデルの学習処理を定義する
GANの学習は2つのフェーズから構成されます。
まず最初のフェーズでは判別器(Discriminator)の学習を行います。学習を停止させた生成器(Generator)から生成したbatchサイズ分の画像を準備し、データセットからそれと同数の画像を準備します。 Fake ImagesとReal Imagesを連結し、対象のデータが Fake Images / Real Images のいずれであるかのラベルを付与し、学習用データセットとします。 このデータセットにより学習を行うことで、 Descriminatorは対象とする画像がQuick Draw! から入手した画像の品質に達しているかどうかを識別できる ようになります。
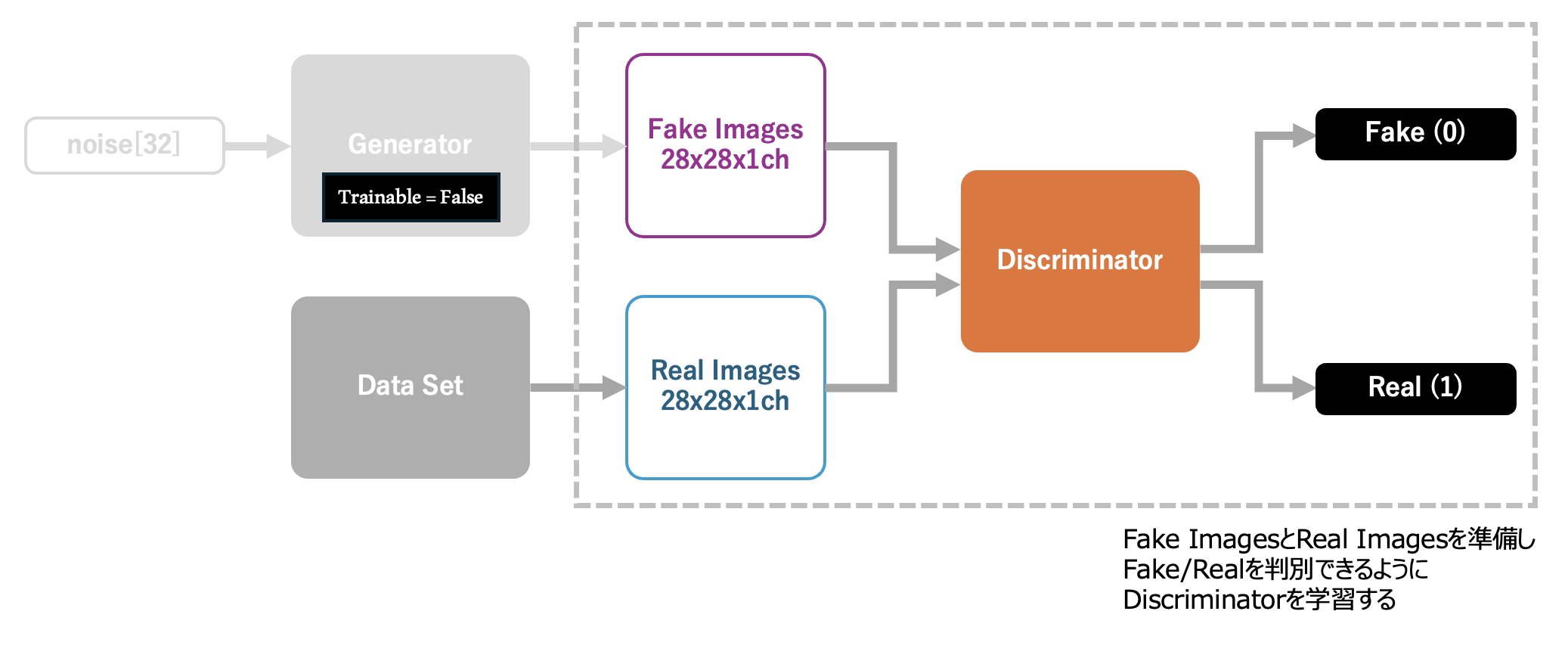
次のフェーズの学習では、前のフェーズで Fake Images / Real Images を判別できるようになったDiscriminatorの学習を停止 し、 入力であるnoiseから、Generatorが適当な画像を生成し、これが「本物である (Real(1))」と誤認 するようにGAN全体の学習を行います。この学習により、Generatorのパラメータが更新され、よりデータセットに近い画像を生成できるようになります。
以上に基づいたGANの学習を実施するためのソースコードは、以下のとおりです。
######
### これ以降にGANを学習するプログラムを実装します
######
def train(real, g_model, d_model, a_model, epochs=2000, batch=128, z_dim=Z_DEMENSIONS):
# 学習結果を出力するためのリスト
d_metrics = []
a_metrics = []
# Accuracyと損失を記録する
running_d_loss = 0
running_d_acc = 0
running_a_loss = 0
running_a_acc = 0
for epoch in range(epochs):
######
### 判別器の学習
# 本物の手描きイラストをbatchサイズ分集める
imgs_real = np.reshape(
real[np.random.choice(real.shape[0], batch, replace=False)],
(batch, 28, 28, 1)
)
# 生成器の入力は乱数
input_noise = np.random.uniform(-1.0, 1.0, size=[batch, z_dim])
# 生成器で偽物の手描きイラストをbatchサイズ分生成する
imgs_fake = g_model.predict(input_noise)
# 本物と偽物の画像をセットにする
x = np.concatenate((imgs_real, imgs_fake))
# 本物と偽物のラベルを作る(本物=1, 偽物=0)
y = np.ones([2 * batch, 1])
y[batch:,:] = 0
# 判別器の学習を有効にする
d_model.trainable = True
# 判別器のパラメータを確認する
if epoch == 0:
d_model.summary()
# 判別器の学習を実行する
d_metrics.append(
d_model.train_on_batch(x, y)
)
# 損失は終端要素の[0]に格納されている
running_d_loss += d_metrics[-1][0]
# Accuracyは終端要素の[1]に格納されている
running_d_acc += d_metrics[-1][1]
######
### 生成器の学習
# 生成器の入力は乱数
input_noise = np.random.uniform(-1.0, 1.0, size=[batch, z_dim])
# 全てが本物の画像だと誤認されるように学習する
y = np.ones([batch, 1])
# 判別器の学習を停止する
d_model.trainable = False
# GANのパラメータを確認する
if epoch == 0:
a_model.summary()
# GANの学習を実行する
a_metrics.append(
a_model.train_on_batch(input_noise, y)
)
# 損失は終端要素の[0]に格納されている
running_a_loss += a_metrics[-1][0]
# Accuracyは終端要素の[1]に格納されている
running_a_acc += a_metrics[-1][1]
# 100epochs毎に進捗状況と生成画像を出力する
if (epoch + 1) % 100 == 0:
print('Epoch #{}'.format(epoch+1))
### 損失とAccuracyを表示する
log_msg = "%d: [D loss: %f, acc: %f]" % (epoch+1, running_d_loss / (epoch+1), running_d_acc / (epoch+1))
log_msg = "%s [A loss: %f, acc: %f]" % (log_msg, running_a_loss / (epoch+1), running_a_acc / (epoch+1))
print(log_msg)
### 学習で利用した画像を記録する
save_path = os.path.join(EPOCH_INPUT_IMAGE_DIR, EPOCH_INPUT_IMAGE_SAVEFIG.format(epoch + 1))
os.makedirs(EPOCH_INPUT_IMAGE_DIR, exist_ok=True)
image_plot(imgs_real, save_path)
### 生成器が生成した画像を記録する
input_noise = np.random.uniform(-1.0, 1.0, size=[16, z_dim])
imgs_gen = G_model.predict(input_noise)
save_path = os.path.join(EPOCH_OUTPUT_IMAGE_DIR, EPOCH_OUTPUT_IMAGE_SAVEFIG.format(epoch + 1))
os.makedirs(EPOCH_OUTPUT_IMAGE_DIR, exist_ok=True)
image_plot(imgs_gen, save_path)
return a_metrics, d_metrics
a_metrics_complete, d_metrics_complete = train(real=data, g_model=G_model, d_model=D_model, a_model=A_model,
epochs=2000, batch=1024, z_dim=Z_DEMENSIONS)
学習中のAccuracyと損失を可視化する
最後にTensorFlowの学習メソッド train_on_batch 実行時に出力された Accuracy と Loss(損失) をグラフにまとめます。
# 損失のグラフを生成する
column_a = [metric[0] for metric in a_metrics_complete]
column_d = [metric[0] for metric in d_metrics_complete]
plt.plot(column_a)
plt.plot(column_d)
plt.yscale('log')
plt.savefig(GRAPH_IMAGE_LOSS)
plt.clf()
plt.close()
# Accracyのグラフを生成する
column_a = [metric[1] for metric in a_metrics_complete]
column_d = [metric[1] for metric in d_metrics_complete]
plt.plot(column_a)
plt.plot(column_d)
plt.savefig(GRAPH_IMAGE_ACCURACY)
plt.clf()
plt.close()
AccuracyとLossのグラフは以下のようになります。

学習結果
判別器(Discriminator)と生成器(Generator)を定義し、これを統合したGANを学習することにより、 Generatorは以下のようなりんごの画像を生成できるようになります。 各4列が、それぞれepoch毎の出力結果であり、学習を進めるにつれて、Generatorがぼやけた画像から、はっきりと特徴のわかる画像を生成できるようになっていることがわかります。
MNISTなどのデータセットに対しても、本手法は有効ですので、是非お試しください。
今後の拡張 (Conditional-GAN:CGAN)
今回は "りんご" の画像のみを生成できるネットワークを定義しました。今後は入力として "りんご"、"自転車"、"熊" といった入力を加えることにより、 カテゴリに準拠した画像を生成できるGeneratorを構築できる「Conditional-GAN」の実装を試してみようと思います。
CGAN/CTGANを実装しました!
以上が、TensorFlow.kerasのフレームワークを使ってGAN (Generative Adversarial Network : 敵対的生成ネットワーク) を実装する流れとなります。GANを使うことにより、簡単に生成AI(Generative AI)を定義できるようになります。是非参考にしてみてください。
ありがとうございました。
ソースコード全文
以下に今回実装したソースコード全文を掲載します。
import tensorflow as tf
import tensorflow.keras as keras
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input
from tensorflow.keras.layers import Dense, Conv2D, Dropout
from tensorflow.keras.layers import BatchNormalization, Flatten
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Reshape
from tensorflow.keras.layers import Conv2DTranspose
from tensorflow.keras.layers import UpSampling2D
from tensorflow.keras.optimizers import RMSprop
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
import os
# 学習用データセットのnumpyファイル
INPUT_IMAGE_PATH = './dataset/apple.npy'
# 学習用データセットを画像化して保存するファイルパス
INPUT_IMAGE_SAVEFIG = './inputs.png'
# 100epochs単位で生成される画像を格納するファイルパス
EPOCH_INPUT_IMAGE_SAVEFIG = './input_{}epochs.png'
EPOCH_OUTPUT_IMAGE_SAVEFIG = './output_{}epochs.png'
# 生成する画像を格納するフォルダ
EPOCH_INPUT_IMAGE_DIR = './gen/input'
EPOCH_OUTPUT_IMAGE_DIR = './gen/output'
# 損失グラフの出力先
GRAPH_IMAGE_LOSS = 'graph_loss.png'
# Accuracyグラフの出力先
GRAPH_IMAGE_ACCURACY = 'graph_acc.png'
######
### Numpy配列の先頭16要素を画像へ書き出す
######
def image_plot(imgs, path_savefig):
output_imgs = imgs[:16,]
plt.figure(figsize=(5, 5))
for k in range(output_imgs.shape[0]):
plt.subplot(4, 4, k+1)
plt.imshow(output_imgs[k, :, :, 0], cmap='gray')
plt.tight_layout()
plt.savefig(path_savefig)
print("Save images to :", path_savefig)
plt.clf()
plt.close()
# 学習用データセットを読み込む
data = np.load(INPUT_IMAGE_PATH)
# 0.0 - 1.0 へ正規化する
data = data / 255
# 28px x 28px の2次元データに変形する
data = np.reshape(data, [data.shape[0], 28, 28, 1])
# 画像の縦横サイズを取得する
img_w, img_h = data.shape[1:3]
# 学習用データセットを画像化する
image_plot(data, INPUT_IMAGE_SAVEFIG)
######
### これ以降に学習用データセットを利用するGANを実装します
######
######
### 画像がAI生成のものか学習用データセットのものかを識別する
### 判別器(discriminator)を生成する関数を定義する
######
def build_discriminator(img_w=28, img_h=28, depth=64, dropout_p=0.4):
# 入力は1枚の画像
input = Input((img_w, img_h, 1))
# 28x28に対する5x5で深さdepthの畳み込み層 -> 14x14
x = Conv2D(depth*1, 5, strides=2, padding='same', activation='relu')(input)
# Dropout
x = Dropout(dropout_p)(x)
# 14x14に対する5x5で深さdepthx2の畳み込み層 -> 7x7
x = Conv2D(depth*2, 5, strides=2, padding='same', activation='relu')(x)
# Dropout
x = Dropout(dropout_p)(x)
# 7x7に対する5x5で深さdepthx4の畳み込み層 -> 4x4
x = Conv2D(depth*4, 5, strides=2, padding='same', activation='relu')(x)
# Dropout
x = Dropout(dropout_p)(x)
# 4x4に対する3x3で深さdepthx8の畳み込み層 -> 4x4
x = Conv2D(depth*8, 5, strides=1, padding='same', activation='relu')(x)
# Dropout
x = Dropout(dropout_p)(x)
# 1次元配列に展開する
x = Flatten()(x)
# 全結合して結果を出力する
output = Dense(1, activation='sigmoid')(x)
# モデルを生成する
model = Model(inputs=input, outputs=output)
# モデルを返す
return model
# 判別器を取得する
D_model = build_discriminator(img_w=img_w, img_h=img_h, depth=64, dropout_p=0.4)
# 判別器の学習に使うLearning Rateを算出する関数を定義する
D_lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate=8e-4,
decay_steps=20000,
decay_rate=6e-8)
# 判別器をコンパイルする
D_model.compile(loss='binary_crossentropy',
optimizer=RMSprop(learning_rate=D_lr_schedule),
metrics=['accuracy'])
# modelを表示する
D_model.summary()
######
### 乱数から学習用データと見分けの付かない画像を生成する
### 生成器(generator)を生成する関数を定義する
######
Z_DEMENSIONS = 32
def build_generator(img_w=28, img_h=28, latent_dim=Z_DEMENSIONS, depth=64, dropout_p=0.4):
# 入力は複数要素を持ったノイズデータとする
input_noise = Input((latent_dim,))
# 全結合層に展開する
x = Dense(int(img_w / 4) * int(img_h / 4) * depth)(input_noise)
x = BatchNormalization(momentum=0.9)(x)
x = Activation(activation='relu')(x)
x = Reshape((int(img_w / 4), int(img_h / 4), depth))(x)
x = Dropout(dropout_p)(x)
# アップサンプリングと逆畳み込みを適用する
# 7x7xdepthに対するアップサンプリングと逆畳み込み -> 14x14
x = UpSampling2D()(x)
x = Conv2DTranspose(int(depth/2), kernel_size=5, padding='same', activation=None,)(x)
x = BatchNormalization(momentum=0.9)(x)
x = Activation(activation='relu')(x)
# 14x14xdepth/2 に対するアップサンプリングと逆畳み込み -> 28x28
x = UpSampling2D()(x)
x = Conv2DTranspose(int(depth/4), kernel_size=5, padding='same', activation=None,)(x)
x = BatchNormalization(momentum=0.9)(x)
x = Activation(activation='relu')(x)
# 28x28xdepth/4 に対する逆畳み込み -> 28x28
x = Conv2DTranspose(int(depth/8), kernel_size=5, padding='same', activation=None,)(x)
x = BatchNormalization(momentum=0.9)(x)
x = Activation(activation='relu')(x)
# 出力層
output_img = Conv2D(1, kernel_size=5, padding='same', activation='sigmoid')(x)
# モデルを生成する
model = Model(inputs=input_noise, outputs=output_img)
# モデルを返す
return model
# 生成器を取得する
G_model = build_generator(img_w=img_w, img_h=img_h, latent_dim=32, depth=64, dropout_p=0.4)
# modelを表示する
G_model.summary()
######
### D_model と G_model を組み合わせて
### 敵対的ネットワークを構築する
######
# 入力はZ要素のノイズ
input_noise = Input(shape=(Z_DEMENSIONS,))
# ノイズからFake画像を生成する
imgs_fake = G_model(input_noise)
# 判別器の学習を止めておく
D_model.trainable = False
# 判別器でFake画像を判定する
output_pred = D_model(imgs_fake)
# ノイズを入力として、Fake判定を出力とするネットワークを構築する
A_model = Model(input_noise, output_pred)
# 判別器の学習に使うLearning Rateを算出する関数を定義する
A_lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate=4e-4,
decay_steps=20000,
decay_rate=3e-8)
# modelをコンパイルする
A_model.compile(loss='binary_crossentropy',
optimizer=RMSprop(learning_rate=A_lr_schedule),
metrics=['accuracy'])
# modelを表示する
A_model.summary()
######
### これ以降にGANを学習するプログラムを実装します
######
def train(real, g_model, d_model, a_model, epochs=2000, batch=128, z_dim=Z_DEMENSIONS):
# 学習結果を出力するためのリスト
d_metrics = []
a_metrics = []
# Accuracyと損失を記録する
running_d_loss = 0
running_d_acc = 0
running_a_loss = 0
running_a_acc = 0
for epoch in range(epochs):
######
### 判別器の学習
# 本物の手描きイラストをbatchサイズ分集める
imgs_real = np.reshape(
real[np.random.choice(real.shape[0], batch, replace=False)],
(batch, 28, 28, 1)
)
# 生成器の入力は乱数
input_noise = np.random.uniform(-1.0, 1.0, size=[batch, z_dim])
# 生成器で偽物の手描きイラストをbatchサイズ分生成する
imgs_fake = g_model.predict(input_noise)
# 本物と偽物の画像をセットにする
x = np.concatenate((imgs_real, imgs_fake))
# 本物と偽物のラベルを作る(本物=1, 偽物=0)
y = np.ones([2 * batch, 1])
y[batch:,:] = 0
# 判別器の学習を止めておく
d_model.trainable = True
# 判別器のパラメータを確認する
if epoch == 0:
d_model.summary()
# 判別器の学習を実行する
d_metrics.append(
d_model.train_on_batch(x, y)
)
# 損失は終端要素の[0]に格納されている
running_d_loss += d_metrics[-1][0]
# Accuracyは終端要素の[1]に格納されている
running_d_acc += d_metrics[-1][1]
######
### 生成器の学習
# 生成器の入力は乱数
input_noise = np.random.uniform(-1.0, 1.0, size=[batch, z_dim])
# 全てが本物の画像だと誤認されるように学習する
y = np.ones([batch, 1])
# 判別器の学習を止めておく
d_model.trainable = False
# GANのパラメータを確認する
if epoch == 0:
a_model.summary()
# GANの学習を実行する
a_metrics.append(
a_model.train_on_batch(input_noise, y)
)
# 損失は終端要素の[0]に格納されている
running_a_loss += a_metrics[-1][0]
# Accuracyは終端要素の[1]に格納されている
running_a_acc += a_metrics[-1][1]
# 100epochs毎に進捗状況と生成画像を出力する
if (epoch + 1) % 100 == 0:
print('Epoch #{}'.format(epoch+1))
### 損失とAccuracyを表示する
log_msg = "%d: [D loss: %f, acc: %f]" % (epoch+1, running_d_loss / (epoch+1), running_d_acc / (epoch+1))
log_msg = "%s [A loss: %f, acc: %f]" % (log_msg, running_a_loss / (epoch+1), running_a_acc / (epoch+1))
print(log_msg)
### 学習で利用した画像を記録する
save_path = os.path.join(EPOCH_INPUT_IMAGE_DIR, EPOCH_INPUT_IMAGE_SAVEFIG.format(epoch + 1))
os.makedirs(EPOCH_INPUT_IMAGE_DIR, exist_ok=True)
image_plot(imgs_real, save_path)
### 生成器が生成した画像を記録する
input_noise = np.random.uniform(-1.0, 1.0, size=[16, z_dim])
imgs_gen = G_model.predict(input_noise)
save_path = os.path.join(EPOCH_OUTPUT_IMAGE_DIR, EPOCH_OUTPUT_IMAGE_SAVEFIG.format(epoch + 1))
os.makedirs(EPOCH_OUTPUT_IMAGE_DIR, exist_ok=True)
image_plot(imgs_gen, save_path)
return a_metrics, d_metrics
a_metrics_complete, d_metrics_complete = train(real=data, g_model=G_model, d_model=D_model, a_model=A_model,
epochs=3000, batch=1024, z_dim=Z_DEMENSIONS)
# 損失のグラフを生成する
column_a = [metric[0] for metric in a_metrics_complete]
column_d = [metric[0] for metric in d_metrics_complete]
plt.plot(column_a)
plt.plot(column_d)
plt.yscale('log')
plt.savefig(GRAPH_IMAGE_LOSS)
plt.clf()
plt.close()
# Accracyのグラフを生成する
column_a = [metric[1] for metric in a_metrics_complete]
column_d = [metric[1] for metric in d_metrics_complete]
plt.plot(column_a)
plt.plot(column_d)
plt.savefig(GRAPH_IMAGE_ACCURACY)
plt.clf()
plt.close()
# 終了
quit()
記事は以上です。