ISMIR2023のProceedingsから論文をピックアップします。
yamathcy氏がISMIR2023の全発表をまとめてくれています。便利なので活用してください。
Automatic Piano Transcription with Hierarchical Frequency-Time Transformer
ピアノ自動採譜手法。
MIRの根幹タスクの一つとして、これまで様々な手法でアタックされてきたピアノ自動採譜タスク。
ソニーの人たちが提案した「hFT-Transformer」は、それぞれ「周波数軸」と「時間軸」に注目(attention)するTransformerを重ねることで、ノートのタイミングをより正確に識別させることを目指しました。
提案されたネットワークの計算手順を辿ってみます。
- ピアノ曲の音響信号をlog-mel spectrogramに変換する。採譜対象となるspectrogramの長さはNフレーム、周波数軸の長さはFとする。
- 時間軸上に長さ$(M+1+M)$の窓を滑らせながら、spectrogramの断片をN個切り出し、新しい次元に重ねる。$(N,F,M+1+M)$サイズの行列になり、これがネットワークへの入力になる。
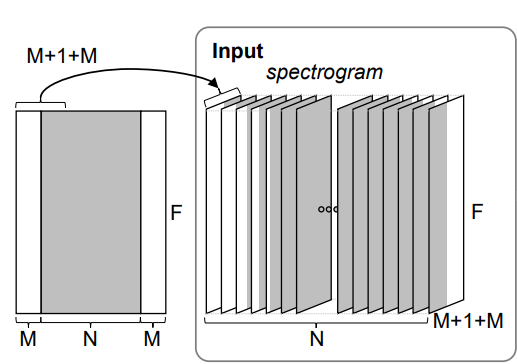
- 第1層のTransformerネットワークに入力される。ネットワークの入り口でまず、時間軸方向の1-D Convolution層を通してから、周波数軸上でSelf-attentionをかけるTransformer Encoderに入力する。
- Transformer Encoderの出力は、Transformer DecoderのAttention層に繋がれる。TransformerのEncoder-Decoder構造を通して、周波数軸の長さFは音高数Pに変換される。
- Transformer Decoderの出力は全連結層に繋がれ、ノート情報を表す確率分布行列が出力される。
- Transformer Decoderの出力はさらに、第2層のTransformerネットワークに入力される。このTransformerは時間軸上でSelf-attentionをかけるTransformer Encoderである。
- 第2層Transformer Encoderの出力は全連結層に繋がれ、もう一つの確率分布行列が出力される。
全体を見ると、spectrogram行列が入力され、ピアノのノート・ノートオン・ノートオフ・ベロシティを表す確率分布行列を2組出力するネットワークになっています。出力行列はそれぞれの正解分布とのクロスエントロピーを計算し、Onset&Framesライクな、マルチタスク学習の目標関数を最適化することになります。
このネットワークを使って教師あり学習をしたピアノ採譜モデルは、音符識別やノートオン・オフ位置、およびベロシティ推定等の指標においてSOTAを達成したとのことです。
感想:
ByteDanceの人たちが考えた「SpecTNT」も似たようなことをしてましたが、時間軸と周波数軸の両方にattentionするモデルは自動採譜に強いと言えるのかもしれません。
余談
清華大学の研究者らは、最近発表した論文で「多変量時系列データ推定タスクをTransformerに解かせる場合、従来的な使い方は間違っている」という説を提唱しました。同一時間の変量を1つのベクトルに埋め込み、時間軸方向にAttentionをかける方式は、時系列推定において様々な悪影響をもたらすと主張しています。その解決策として、系列データの入力を倒置し、「いち変量の全時間範囲の数値をベクトルに埋め込み、変量間にAttentionをかける方式」に変更したところ、それだけで各種時系列データ推定タスクでSOTAを達成したとのこと。なので、変量次元と時間次元を交換することが、このタスクにおけるTransformerの「正しい使い方」であるというのです。
https://arxiv.org/abs/2310.06625
ピアノ自動採譜や、ほかの音楽自動採譜タスクも多変量時系列推定タスクとみなすことができます。hFT-TransformerやSpecTNTが高い性能を示しているのも、時間軸ではなく周波数軸上でAttentionをかけたことが主な要因であるかもしれません。
また、コード採譜やビート推定でも散々確認されている「マルチタスク学習が強い」という事実が、改めてピアノ採譜で再確認されました。Onset&Frames未だ死なず。
近年のピアノ採譜研究では、MIDI-Likeトークンの推定に転換したり、Semi-CRFを使うなど「frame-level脱却」の流れが来てる気がしていたのですが、ここにきて古典的な枠組みが再びSOTAを攫りにきたのは意外でした。果たして自動採譜は何処へ向かうのか。
VampNet: Music Generation via Masked Acoustic Token Modeling
非自己回帰モデルに基づく音楽オーディオ生成手法の提案。
近頃話題になったMusicLMやMusicGen等の音楽生成手法は自己回帰(autoregressive)モデルに基づいたものが多いです。MusicGenの記事で、「個人的に非自己回帰的(Non-autoregressive) な生成モデルに期待している」的なことを書きましたが、VampNetはその非自己回帰的な音楽生成に取り組んだ研究です。
新しい学習・生成メカニズムだけでなく、非自己回帰モデルの特性を生かした面白い応用を色々提案しています。
論文で言及されているように、GoogleからもSoundStormという非常に類似した手法が提案されています。
VampNetはMusicLMやMusicGenと同じく、EnCodecなどで音声波形を多階層な音響トークン列に変換してから、音響トークンの生成過程をモデリングする作戦をとっています。(以降の図はISMIR発表のポスターから引用)
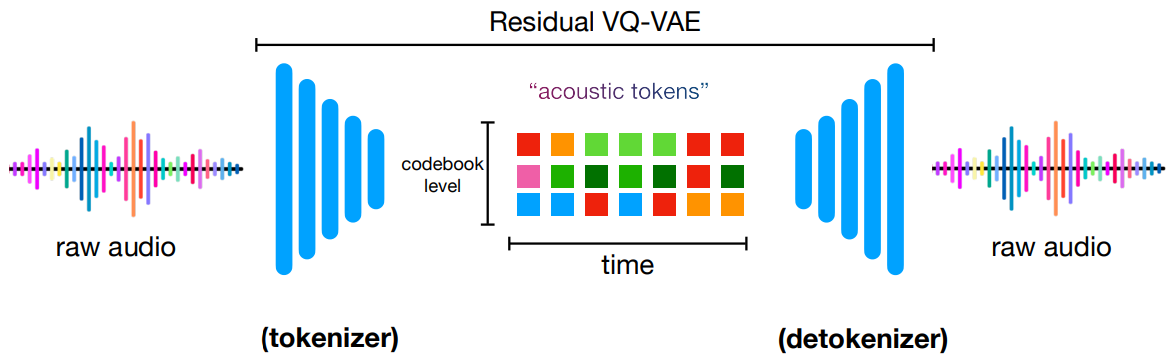
VampNetは未来の音響トークンを逐次的に推定するのではなく、マスクされたトークンを反復的に推定することで音楽を生成します。この手法はGoogleが提案した画像生成手法「MaskGIT」が元になっています。
学習時は、ランダムに一部のトークンをマスクし、マスクされたトークンの確率分布を推定するようにDNNを学習させます。
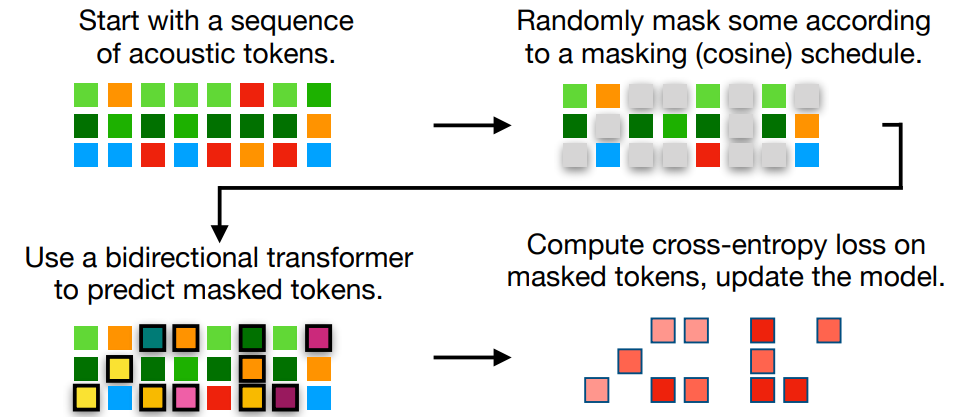
推論時は、マスクされたトークンが全て置き換えられるまで、以下のステップを繰り返します。
- マスク付きのトークン列をDNNに入力し、マスク位置のトークン確率分布を求める
- マスク位置のうち、確率が一番高いN個のマスク位置を音響トークンに置き換える(Nが大きければ推論速度が速く、小さいほど高音質)
推論時、マスクは任意の位置にかけることができるので、前・後方向に継ぎ足したり、音声の一部を消して再生成するなど、自己回帰的な生成モデルだと不可能な事ができます。
一例として、ビート位置周辺のトークン以外をマスクすることで、元の曲のリズム感を保持したまま新しい音楽を生成するという応用が挙げられています。
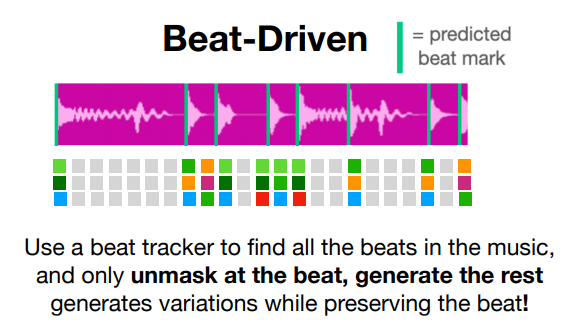
この方法に基づき、VampNetの著者は「ループしないLooper」という不思議なアプリ「unloop」をリリースしています。元ループの雰囲気を維持しながら毎回微妙に違うフレーズを繰り返す、まるでセッションの奏者みたいなムーヴをしてくれる非常に面白い音楽ツールです。
感想:
自己回帰モデルの制約に縛られない任意位置の生成といえば、拡散モデルを使うことも考えられます。VampNetも、反復的に未知のトークンを推定する仕組みは拡散モデルと似ている所がありますね。
機械学習モデル自体の進化だけでなく、「unloop」のような、音楽生成AIの賢い活用法の発明にも大きな意義があると思います。
PESTO: Pitch Estimation with Self-supervised Transposition-equivariant Objective
自己教師あり学習でDNN音高推定モデルを作る手法。ISMIR2023ベストペーパーに選ばれました。
単音高(monophonic)音響信号の音高推定タスクは、DNN時代が来る以前からSOTAの精度が十分高く、基本解決された問題だと考える人もいました。しかしDNN時代にCREPEという教師あり学習モデルが公開され、DNN系手法のSOTAを確立しました。
大規模なアノテーション付き音響信号から学習したCREPEと異なり、提案手法PESTOはアノテーションに頼らず音響信号データだけで高精度なピッチ推定DNNを鍛える手法です。
自己教師ありピッチ推定に関しては、2020年にSPICEという手法が提案されており、この論文でもベースラインとして提案手法と比較されています。
https://arxiv.org/abs/1910.11664
自己教師あり学習を行うために、PESTOはピッチ推定モデルの移調に対する同変性(equivariance)に着目します。
ここでの同変性とは、「音響信号をピッチ推定モデルに入力して得られたピッチ分布をNステップ分移調した分布=音響信号をNステップ分移調してからピッチ推定モデルに入力して得られたピッチ分布」という性質です。
あるいは簡単に、「ピッチ推定モデルの入力音が移調すると、出力のピッチ分布も同じ量移調する」と説明することもできます。そりゃそうだろという感じですが、データから情報を分離するのに役立つ、とても重要な性質です。
同変性とは別に、音色に対する不変性(invariance) も考慮しています。これは、「入力音の音色だけを変えても、出力のピッチ分布は変化しない」という性質です。
上記の性質を利用して、目標関数を設計します。
PESTOは音声波形そのものではなく、CQTスペクトログラムをNNへの入力にしています。目標関数は以下の手順で計算されます。
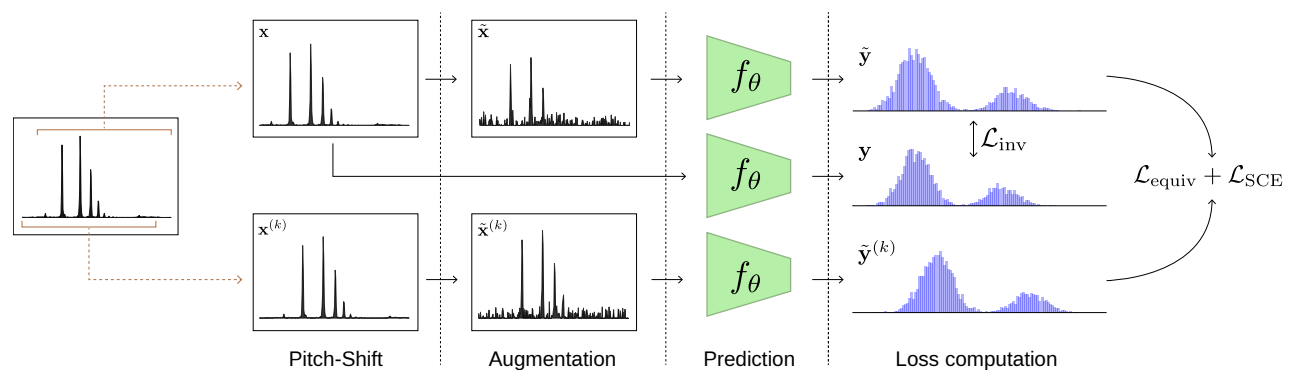
- スペクトログラム$\mathbf{x}$を$k$ステップ分ピッチシフトし、$\mathbf{x}^{(k)}$を得る。
- $\mathbf{x}$と$\mathbf{x}^{(k)}$にランダムなノイズやゲインを加え、$\tilde{\mathbf{x}}$と$\tilde{\mathbf{x}}^{(k)}$を得る。
- $\mathbf{x}, \tilde{\mathbf{x}}, \tilde{\mathbf{x}}^{(k)}$をそれぞれDNNに入力し、推定ピッチ分布$\mathbf{y}, \tilde{\mathbf{y}}, \tilde{\mathbf{y}}^{(k)}$を得る。
- 同変性ロスを計算:$\mathcal{L}_{equiv}(\tilde{\mathbf{y}}, \tilde{\mathbf{y}}^{(k)},k)=h(\frac{\phi(\mathbf{y}^{(k)})}{\phi(\mathbf{y})}-\alpha^k)$。$h$はHuber loss関数、$\phi(\mathbf{y})=\sum \alpha^iy_i$、これは$\mathbf{y}^{(k)}$が$\mathbf{y}$の$k$ステップ移調である場合、$\phi(\mathbf{\mathbf{y}^{(k)}})=\alpha^k\phi(\mathbf{y})$が成立するような関数です。
- 正則化ロスを計算:$\mathcal{L}_{SCE}(\tilde{\mathbf{y}}, \tilde{\mathbf{y}}^{(k)},k)=CrossEntropy(\mathbf{y},trans_k(\mathbf{y}^{(k)}))$。同変性ロスを最小化するだけでは「$\mathbf{y}^{(k)}$が$\mathbf{y}$の$k$ステップ移調」が成立するとは限らないので、正則化ロスで更に制約を強くするのが目的です。
- 不変性ロスを計算:$\mathcal{L}_{inv}(\mathbf{y},\tilde{\mathbf{y}})=CrossEntropy(\mathbf{y},\tilde{\mathbf{y}})$。これは上述の不変性を持たせるための損失関数です。
上述3つの損失関数の重み付き和が、最終的な最小化目標です。
目標関数のほかに、DNNの構造も工夫しています。構造自体は単純で、1次元畳み込み層を6層通してから、出口で全連結層を通し、softmaxをかけて離散確率分布を出力するものです。
これらのDNN部品のうち、畳み込み層は局所的な計算であるため移調に対して大まかに同変ですが、最後の全連結層だけそうではありません。DNN全体に同変性を持たせるため、全連結層の重みにToeplitz行列、すなわち対角線方向に沿って要素が一定であるような行列を使っています。
最終的なピッチは以下の式で決まります。
\tilde{p}(\mathbf{x})=\arg\max f_\theta(\mathbf{x})+p_0
$f_\theta$は学習済みのDNN、$p_0$は音高が既知なデータを使って決めた基準値です。
ablation studyによると、同変性ロスとToepliz行列が自己教師あり学習の実現に決定的に重要で、どちらかが抜けるとピッチ推定を全く学習できなくなります。
既存手法との比較実験では、音高推定のSOTAであるCREPEには及ばないものの、ほぼCREPEに迫る精度を、CREPEの千分の一程度のモデル規模で達成しています。自己教師あり学習手法に限ればベースライン手法のSPICEをかなり上回っており、SOTAを大幅に向上させました。
感想:
アノテーションが無くても音響信号データを集めるだけで学習できるし、軽いモデルでほぼCREPEと同性能のピッチ推定ができるので、実用面でも十分価値がある手法だと思います。どうせならCREPEと同レベルのモデルサイズまで拡大してもスケールするのかどうかも知りたいですね。
複数音高推定タスクにどこまで通用するのかも気になります。