今年初め、Googleが考案した音楽生成AI「MusicLM」を、関連研究から順に追って解読する記事を書きました。
実はGoogleがSoundStreamやAudioLMを発表するのを後追いするように、Meta AIもEnCodecやAudioGenと名付けた音生成モデル研究発表を出してきました。そして今回、MusicLMと比肩するtext-to-audio音楽生成モデルのMusicGenを発表しました。
Googleの先行研究と敢えて張り合うような名前を付けるのは何か意図があるのでしょうか…
MusicGenはMusicLMと比較して以下の特徴があります。
- 文脈特徴量を使わず、音響特徴トークン列を直接推定する。
- 音響特徴トークン列の推定に並列化手法を導入している。
- テキスト条件付けのほかに、無条件・メロディー条件付け生成もできる。
- オープンソースである(ソースコードはMIT、学習済みモデルの重みはCC-BY-NCライセンス)。
MusicGenのソースコードは、audiocraftというライブラリの一部として公開されています。いち音楽生成モデルだけでなく、音生成モデルの研究に使われる汎用的なライブラリを目指しているようなので、モデル学習機能の追加など、今後の展開にも注目です。
本記事はMusicGenの特徴をさらってみます。
Encodec:ほぼSoundStream
SoundStreamと同じく、「音響データ圧縮用のニューラルコーデック」です。オートエンコーダー構造・RVQ量子化・敵対的学習による高品質化手法まで、ほぼ全く同じ。
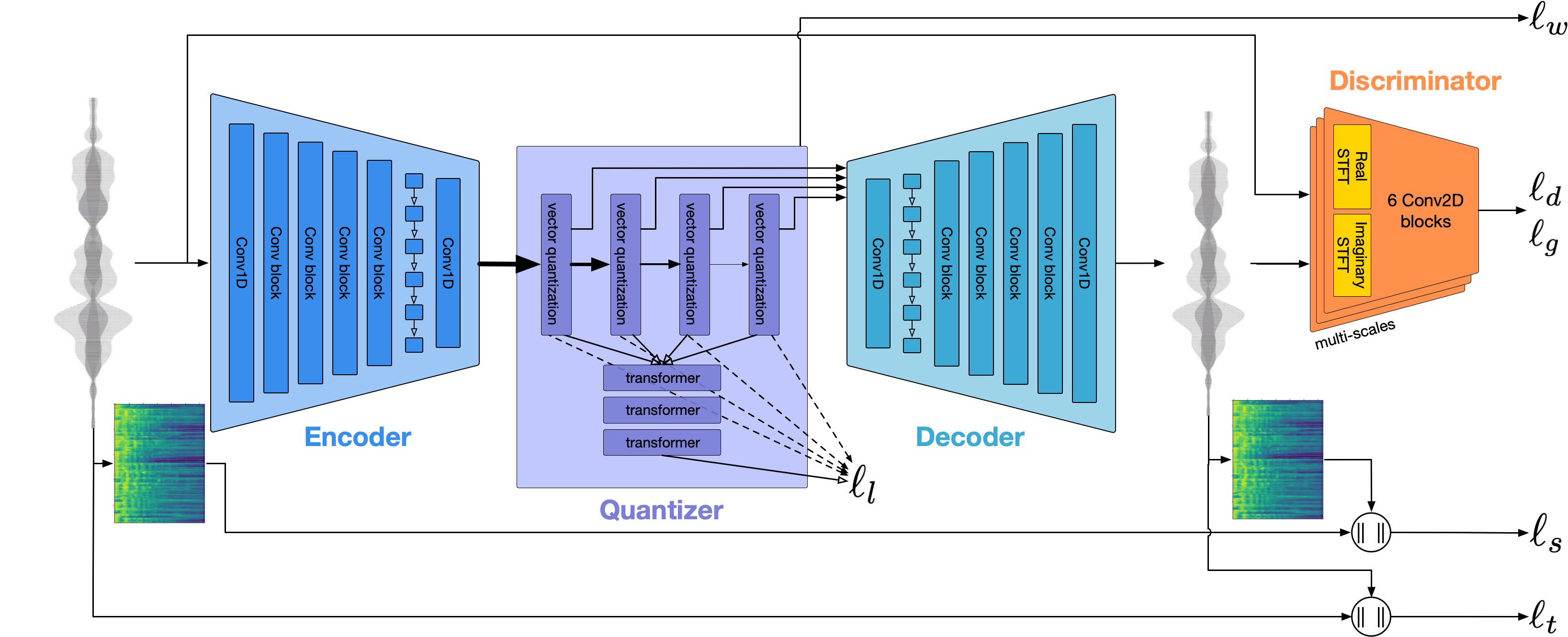
Encodec独自の特徴として、軽量Transformerを用いたRVQトークンの再圧縮手法が提案されており、これによりさらに40%の圧縮率向上を実現したとしていますが、音生成モデルにとっては特に関係ありません。
更にEncodec論文では、敵対的学習の過程で独自に考案したloss balancerを使っており、敵対的学習の安定性を大きく改善したそうです。
GoogleがSoundStreamを利用したように、Meta AIの音生成モデルはEnCodecを音響信号のトークナイザとして使います。
AudioGen:音響特徴トークンだけの自己回帰生成モデル
MusicGenの音生成手法はほぼAudioGenがベースになっています。
前出のQiita記事で書いた通り、GoogleのAudioLMやMusicLMは文脈特徴トークン(W2V-BERT)と音響特徴トークン(SoundStream)の組合せで生成モデルを定義していました。音響特徴トークンだけでは、音の内容の文脈をうまく表現することができない、としています。
しかしMeta AIはお構いなしに、Encodecトークンだけの自己回帰Transformerを作り、テキスト条件付けによる音生成に成功しました。それがAudioGenです。
AudioLM(およびMusicLM)が採用してた、階層的なSequence-to-sequenceなTransformerでもなく、単純なDecoder-onlyモデルです。
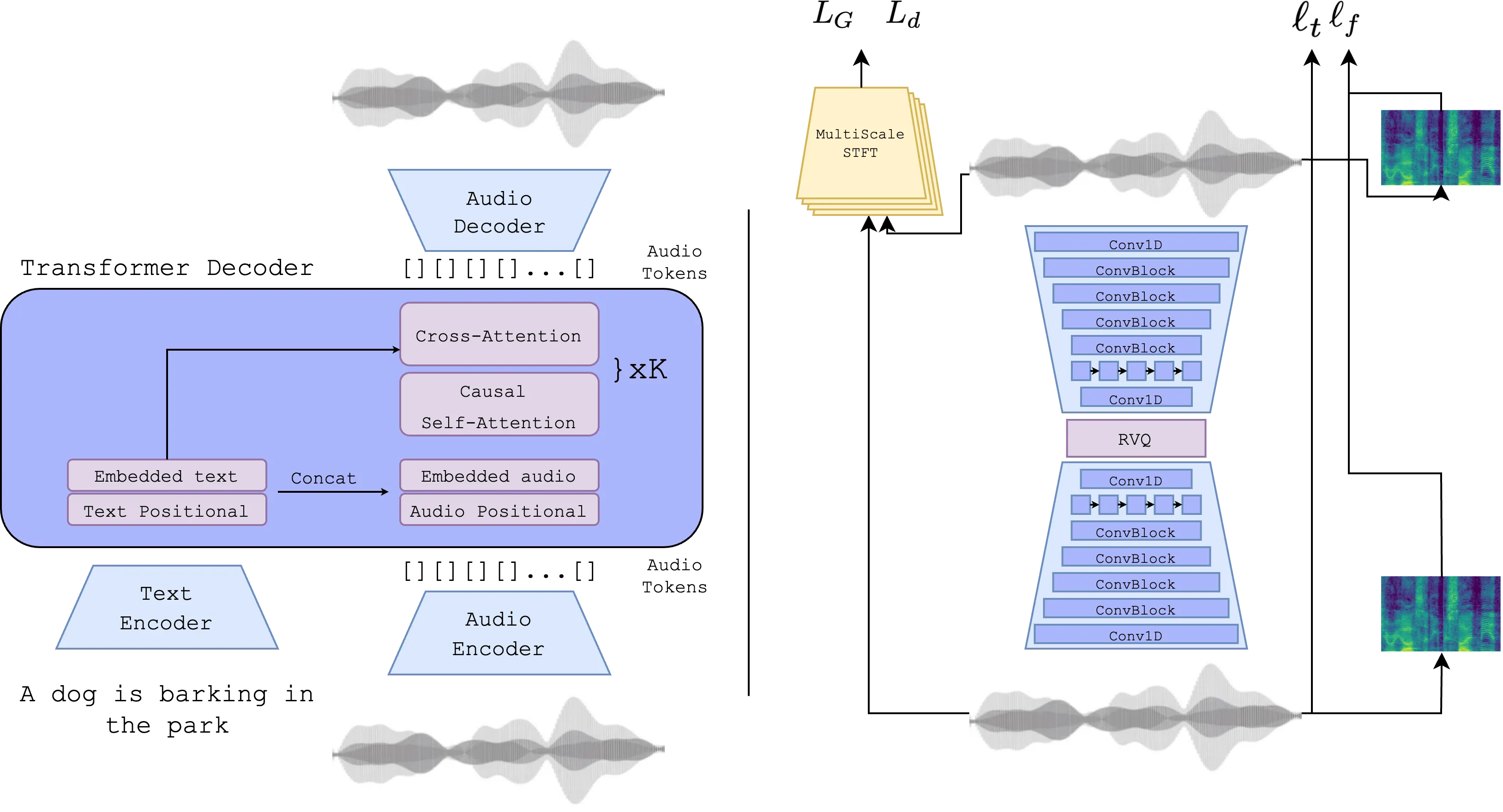
$j$時刻、$i$階層の音響トークンを$v_j^i$、そして条件付けをざっくり$U$とし、$v_j$の分布は$p_\theta(v_j^i|v_1^1,...,v_{j-1}^i, U)$とします。$v_j^i$以前の音響トークン全体を条件として、$v_j^i$の分布が求まるというモデルです。このモデルを利用し、$v_1^1 ... v_N^K$を逐次サンプルしたものを生成モデル全体のサンプルとするのが、自己回帰生成モデルです。
図で示されているように、Text Encoderを通して求めた条件付け情報は、Transformer DecoderのCross-Attention層に入力することで、Transformerが出力する確率分布に影響を与えています。
Classifier Free Guidance (CFG)
AudioGenの主な特徴として、最近の拡散モデルベースの生成手法でよく使われるClassifier Free Guidance (CFG) を適用しています。
まず学習時は、条件付きモデル$p_\theta(v_j^i|v_1^1,...,v_{j-1}^i, U)$と、条件無しモデル$p_\theta(v_j^i|v_1^1,...,v_{j-1}^i)$を同時に学習します。学習ループ中で条件付け$U$を一定確率でオミットすることで、条件無しモデルを学習させています。
推定時は、条件付分布と条件無し分布をそれぞれ推定し、その重み付き和で推定分布を求めます。
\gamma \log p_\theta(v_j^i|v_1^1,...,v_{j-1}^i, U)+(1-\gamma) \log p_\theta (v_j^i|v_1^1,...,v_{j-1}^i)
CFGを使うことで、「テキスト条件付けをどの程度強く生成結果に反映させるか」をハイパラ$\gamma$で制御することができます。
MusicGen:AudioGen+音楽+α
AudioGenを大規模な音楽データで学習させたのがMusicGenですが、AudioGenをベースにいくつかの細かいトリックを追加しています。
音響トークン推定の並列化
AudioLMや上述のAudioGenは、多層構造を持つ音響トークン(1時刻ごとに複数のトークンがある)を直列化して取り扱っています。論文ではFlattening Patternと呼んでいます。
一回に複数の分布を出力できるモデルを使えば、音響トークン推定の並列化が可能になり、推定を高速化させることができます。MusicGen論文では以下の並列化パターンを検討しました。
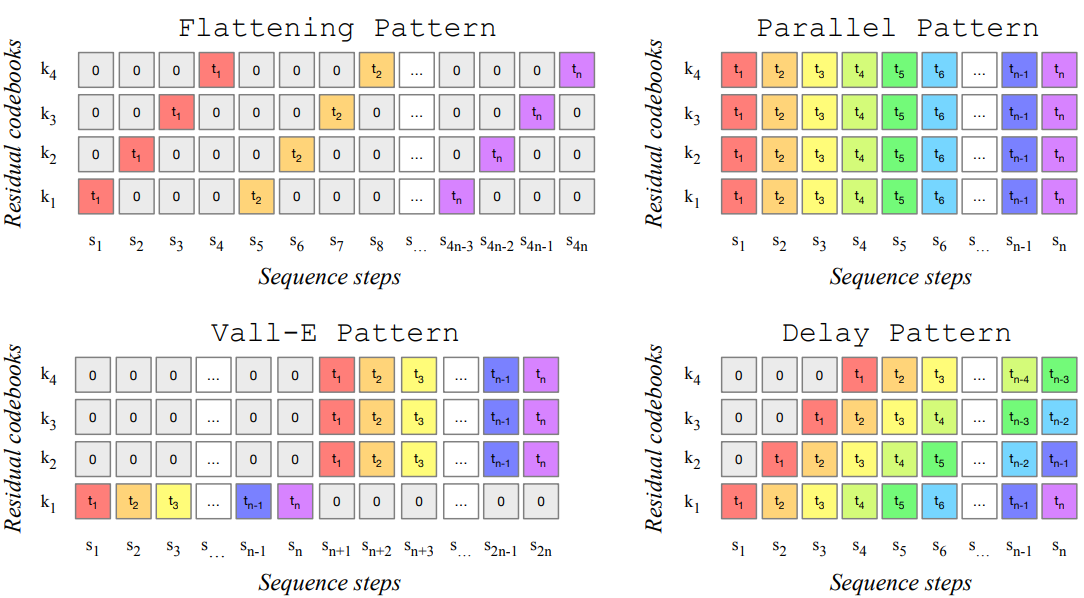
- Parallel Pattern:一回推定ごとに同時刻全階層の音響トークンを推定するする。
- Vall-E Pattern:まず最上階層の音響トークンを直列的に推定した後、残りの層の音響トークンをParallel Pattern的に推定する。
- Delay Pattern:Parallel Patternに比べて音響トークンの並びを時間方向にずらすことで、一回推定ごとに異なる時刻の音響トークンを推定する。
以上のパターンによる生成結果を比較したところ、Flatterning Patternの品質が最も高かった一方、Delay Patternの品質も十分良く、計算コストを考慮したコスパ的にはDelay Patternが一番良かったとのことでした。
メロディーによる条件付け
MusicGenにはテキストプロンプトだけでなく、ほかの楽曲のメロディーを条件付けとする機能も付いています。MusicGenのプロジェクトページでも、面白い例をいくつか載せています。
具体的には、テキストの代わりに二値化したChromagramで生成モデルに条件付けを行うことで、メロディー通りの音楽を生成させています。AudioGenと同様、条件付モデルの学習・推定にCFGの枠組みを使っています。
モデル学習時は、学習データの楽曲に対しまず音楽音源分離モデルを使い楽曲のベースとドラムパートを除去した後、Chromagramを計算し二値化したものをメロディー情報として扱っています。
音楽の「継ぎ足し(continuation)」
これは論文に書かれている内容ではないのですが、audiocraftに実装されているMusicGenには「continuation」という機能も備わっています。$v_1^1...v_i^j$に、既存の楽曲の音響トークンを与え、以降の音響トークンを推定していけば、既存楽曲の後ろに自然に継ぎ足していくように音楽を生成することができます。
テキストプロンプトと組み合わせれば、既存楽曲が別ジャンルに自然に切り替わっていくような展開を生成することも可能なので、DJとかで活用できるかもしれません。
まとめ & 今後の展開
MusicGenは、グーグルのMusicLMが提案した文脈特徴による条件付けや、階層的な生成過程を切り捨て、極めてシンプルなアプローチで制御可能な音楽生成に成功しました。
文脈特徴は実は意味が無かったということなのか、それとももっと良い使い方があるのか。更に検討が進んでほしいところです。
音楽生成AIの次の目標は、非自己回帰モデルで音響トークンを推定することではないかと思っています。MusicLMを作ったGoogleは最近、画像生成手法MaskGITにインスパイアされた非自己回帰な音生成手法SoundStormを発表しました。非自己回帰モデルを使用することで、推論速度を大幅に向上させたとのことです。
個人的に非自己回帰モデルのもう一つのメリットは、後ろだけでなく前方向にも「継ぎ足し」が出来たり、楽曲の間を「穴埋め」することが可能になることだと思います。それこそAdobeの画像編集AI「Firefly」みたいな、直感的で自由自在な編集機能が音楽制作でも可能になり、応用の幅が大きく広がりそうです。
これまでずっとGoogleの発明を追随してきたところを見ると、Meta AIもMusicGenの非自己回帰版をいずれ出してくるのではないでしょうか。