1.はじめに
先日12/4にSeeed Wio LTE ユーザーイベントがあり、こちらで「WioLTEで始める生体計測」というタイトルで発表をしてきました。ザクッとですが、脈拍データをWioLTE経由でクラウドに上げ、データ蓄積&監視SaaSの活用で異常検知をしてみたという内容でお話させていただきました。この記事では、回路作成やクラウド側の基盤づくりのお話がより詳細にできればと思います。
発表スライド → Wio LTEで始める生体信号計測
本当は「血中酸素飽和度」がリアルタイムに計測・異常検知できる事を前提に進めていたのですが・・・
思わぬドジにより2つあるうちの1つの測定用LEDを壊してしまった為、脈拍データを取ること一旦ゴールとします。
2.システム全体感

ざっくりとですが、各ブロックの役割・仕事内容について説明します。
-
パルスオキシメーター+計測回路
- 生体に光を照射し、吸光度の変化を計測する
- 測定した吸光度を増幅&ノイズ除去(周波数帯域ベースのフィルタリング)をする
-
WioLTE
- 前段の計測回路から出力された信号をA/D変換する
- 計測した信号をバッファリングしつつ、後段に送信する
-
Fluentd (Open Source Data Collector)
- HTTPでListenしてデータを受け取る
- データの整形を実施する
- 後段のKinesis Firehorseにデータをパイプする
-
Kinesis Firehorse + Amazon S3
- 受けとったデータをバッファリングしつつ、S3(ストレージ)に保存する
-
Lambda関数
- 計測した吸光度データから血中酸素飽和度を計算する
- 計算した血中酸素飽和度をDatadogに送信する
-
Datadog (監視SaaS)
- データの可視化
- Anomaly Detecionを活用してデータに異常があればメール/slackで発報する
「Fluentdいらなくない?」「WioLTE側で血中酸素飽和度計算すればよくない?」と思われた方もいらっしゃると思います。そのように構築することも可能ですが、今回は下記を前提にシステム設計を行いました。
-
もしかしたら設計・運用途中でKinesis以外にもデータを送る可能性があるかも
- データの経路・フォーマットが変わった時にデバイス側(WioLTE側)を変更するのがめんどくさい
- 柔軟なデータ整形・経路が設定できるOpen Source Data CollectorであるFluentdを採用
-
パルスオキシメーターのデータ処理は試行錯誤したい
- データ処理ロジックが変わった時にデバイス側(WioLTE側)を変更するのがめんどくさい
- ロジック変更に柔軟性を持たせるために、データ処理はクラウド側で持たせる (Lambda Function)
ラピッドプロトタイピングを考えた結果、最終的にこんな感じの構成になった次第です。
3.構築手順(デバイスまわり)
3.1 パルスオキシメーター+計測回路の準備
※ At your own risk
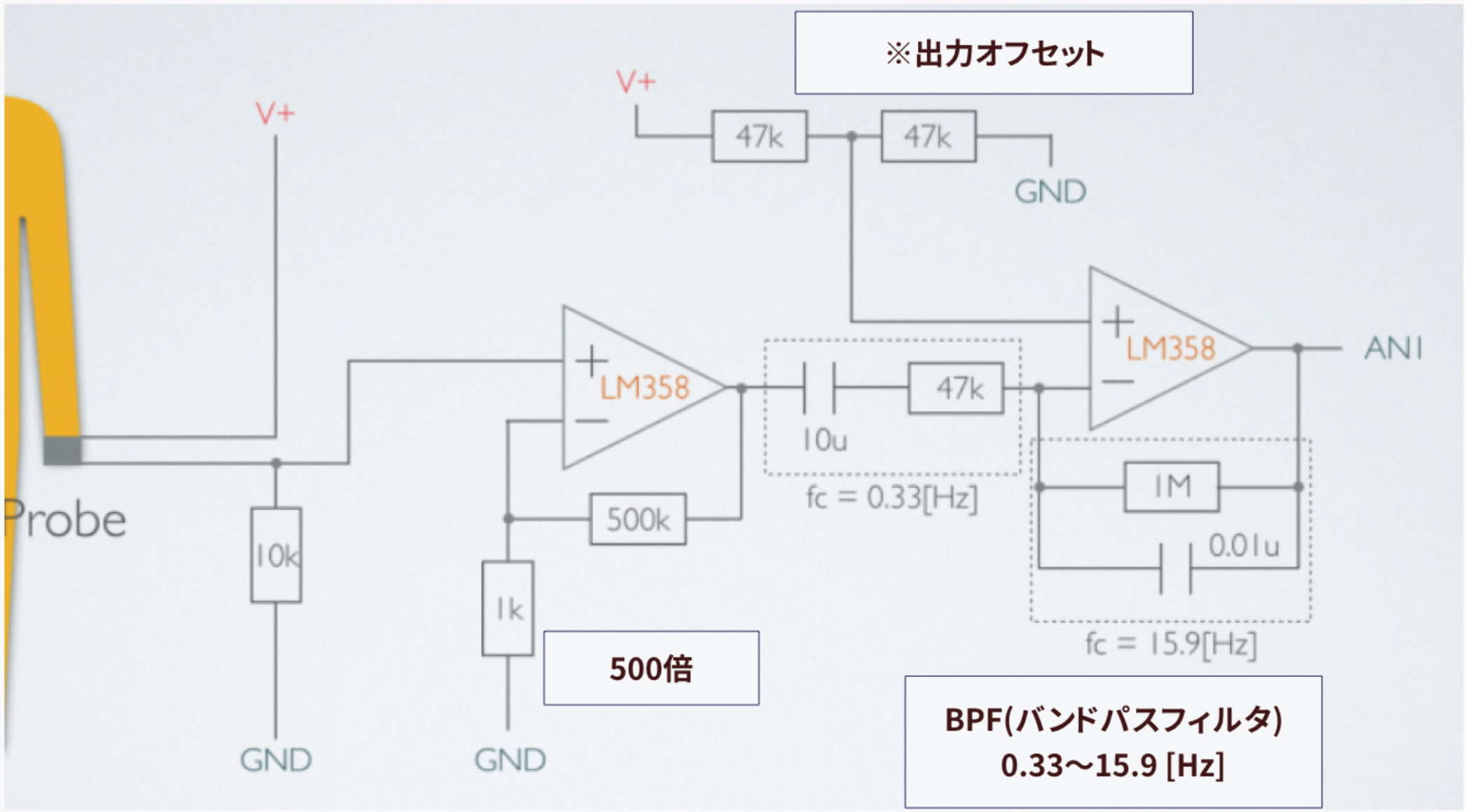
今回、運良く日本光電のパルスオキシメータープローブを手に入れることができました。プローブの先端をニッパーで切って、そこに無理やり増幅回路+フィルター回路を接続しています。プローブ(センサー)によっては、増幅部等の回路定数を変化させる必要性があります。
回路図上で入れ忘れてしまっているのですが、実際の回路作成にはパスコン等のコンデンサーが必要です。
それと、調べたらこういうのがありました。これを使うと良いかもしれません。
http://akizukidenshi.com/catalog/g/gK-09433
3.2 WioLTEの準備
先程の回路からの出力をA/D変換(ボードへ取り込み)してFluentdに送る為のWioLTE側コードです。
3秒間(10msecおきに300points)データ取得を行い、取得したデータArrayをJSONに変換し、HTTP Postをします。
APN,USERNAME,PASSWORDは、利用するSIMカードに依存しているのでsoracom以外のSIMカードをお使いになる場合は変更が必要です。
FLUENTD_URLは、実際にデータを飛ばす先のアドレスになりますので、環境に合わせて変更が必要です。
※筆者の環境で300points以上にすると、JSONの生成で変な文字列が含まれるようになり、動作が不安定になってしまいした。バッファオーバーフローが起きている予感。。
# include <stdio.h>
# include <WioLTEforArduino.h>
# define POINTS (300)
# define APN "soracom.io"
# define USERNAME "sora"
# define PASSWORD "sora"
# define FLUENTD_URL "http://xx.xx.xx.xx:8888/test.http.json"
# define ANALOG_SINAGL (WIOLTE_A4)
static char data[POINTS*5 + 20];
static short int points[POINTS];
WioLTE Wio;
void infity_loop() {
while (1) {
// Do Nothing
}
}
void setup_pin() {
pinMode(ANALOG_SINAGL, INPUT_ANALOG);
return;
}
void setup_modem() {
SerialUSB.println("### I/O Initialize.");
Wio.Init();
SerialUSB.println("### Power supply ON");
Wio.PowerSupplyLTE(true);
Wio.PowerSupplyGrove(true);
delay(5000);
SerialUSB.println("### Turn on or reset.");
if (!Wio.TurnOnOrReset()) {
SerialUSB.println("### Device Init ERROR! ###");
Wio.LedSetRGB(255,0,0);
infity_loop();
}
delay(5000);
SerialUSB.println("### Connecting to \""APN"\".");
if (!Wio.Activate(APN, USERNAME, PASSWORD)) {
SerialUSB.println("### APN Init ERROR! ###");
Wio.LedSetRGB(255,0,0);
infity_loop();
}
delay(5000);
return;
}
void sync_time() {
SerialUSB.println("### Sync time.");
if (!Wio.SyncTime("ntp.nict.jp")) {
SerialUSB.println("### ERROR! ###");
}
return;
}
void setup() {
delay(200);
setup_pin();
setup_modem();
sync_time();
}
void pushToFluentd () {
int status;
int p=0;
p += sprintf(data + p, "{\"val\":[");
for(int i=0;i<POINTS-1;i++) {
p += sprintf(data + p, "%d,", points[i]);
}
p += sprintf(data + p, "%d]}", points[POINTS-1]);
data[p] = 0;
if (!Wio.HttpPost(FLUENTD_URL, data, &status)) {
SerialUSB.println("### ERROR! ###");
Wio.LedSetRGB(255,0,0);
delay(1000);
} else {
SerialUSB.println("Status=" + status);
}
}
void loop() {
Wio.LedSetRGB(0,255,0);
for(int i=0;i<POINTS;i++) {
points[i] = analogRead(ANALOG_SINAGL);
delay(10);
}
Wio.LedSetRGB(0,0,255);
pushToFluentd();
}
3.3 WioLTEとアンテナ・回路を結合する

今回、計測回路とWioLTEをA4コネクタ経由で接続し、ボードへの電源供給(3.3V,GND)及びポートWIOLTE_A4と計測回路の出力をつなげています。
参考:SeeedJP/WioLTEforArduino wiki ハードウェア
4.構築手順(クラウド側まわり)
4.1 Fluentdの準備
※ここからの作業はEC2上もしくはグローバルIPを持つ任意のホストでの作業を想定しています。自分はUbuntu16.04で実施しました。
このstepの作業では、FluentdをDockerを活用してサクッと準備していきたいと思います。
本記事ではDockerの詳しい説明は省きますが、Dockerを活用し既存のコンテナイメージを活用する事で、準備作業が圧倒的に楽になります。
参考:第1回 Dockerとは:超入門Docker
4.1.1 Dockerインストール
ubuntu@test:~$ curl -fsSL get.docker.com -o get-docker.sh
ubuntu@test:~$ sh get-docker.sh
4.1.2 Dockerイメージの生成
fluent/fluentdというDockerイメージを元にして、Kinesisを使うためのプラグイン(fluent-plugin-kinesis)の入ったコンテナを作ります。
ubuntu@test:~$ vi Dockerfile
FROM fluent/fluentd
RUN gem install fluent-plugin-kinesis
ubuntu@test:~$ docker build -t kinesis-fluentd .
Sending build context to Docker daemon 32.26 kB
Step 1/2 : FROM fluent/fluentd
---> a55ed34954ae
Step 2/2 : RUN gem install fluent-plugin-kinesis
---> Using cache
---> 2bd0c8d6d900
Successfully built 2bd0c8d6d900
4.1.3 fluentd.confの用意
Dockerコンテナに読み込ませる(マウントする)為のconfファイルを書きます。
一旦、Kinesis側がまだできていない為、受け取ったデータをstdout(標準出力)に流す設定をします。
ubuntu@test:~$ vi fluent.conf
<source>
@type http
port 8888
bind 0.0.0.0
body_size_limit 32m
keepalive_timeout 10s
add_remote_addr true
format json
</source>
<filter test.http.json>
@type record_transformer
enable_ruby true
<record>
host ${hostname}
timestamp ${time.strftime('%Y-%m-%dT%H:%M:%S%z')}
</record>
</filter>
<match test.http.json>
type stdout
</match>
4.1.4 Dockerコンテナの立ち上げ
先程作成したDockerイメージと設定を使って、実際にコンテナを立ち上げます。
ホストのTCPポート8888とコンテナ内のTCPポート8888を結合し、外からアクセス可能なオプションを追加しています。
# コンテナをバックグラウンドで立ち上げる
ubuntu@test:~$ docker run --rm -it -d --name fluentd -p 8888:8888 -v $(pwd)/fluent.conf:/fluentd/etc/fluent.conf:ro kinesis-fluentd
1f572c7cff0fbf1861505594018924448b37021ee2fe307214536c2bab890355
# 稼働中のコンテナステータスについて確認する
ubuntu@test:~$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
1f572c7cff0f kinesis-fluentd "/bin/entrypoint.s..." 4 seconds ago Up 4 seconds 5140/tcp, 0.0.0.0:8888->8888/tcp fluentd
4.1.5 Fluentdのテスト
WioLTEとFluentdを結合する前に、実際に作業マシンからテストで叩いて動作を確認します。
下記のようにコンテナのログにPostしたログが残っていれば、成功です。
(もし、curlでエラーがでる、ログに残っていない場合はファイアウォールの設定、ポート番号指定が間違えている可能性があります)
# テストデータをFluentdに送信
ubuntu@test:~$ curl -X POST -d '{"msg":"hello"}' http://<ServerIP>:8888/test.http.json
# コンテナのログ確認
ubuntu@test:~$ docker logs fluentd
2017-12-09 09:22:39 +0000 test.http.json: {"msg":"hello","REMOTE_ADDR":"xxx.xxx.xxx.xxx","host":"1f572c7cff0f","timestamp":"2017-12-09T09:22:39+0000"}
4.1.6 WIoLTEとFluentdの結合
先程のWioLTE側のコードのFLUENTD_URLを指定した後、電源をいれると
大量にデータが届いている事が確認できると思います!
ubuntu@test:~$ docker logs -f fluentd
2017-12-03 21:12:14 +0000 test.http.json: {"val": [2036,2039,2041,....],"REMOTE_ADDR":"xxx.xxx.xxx.xxx","host":"28d7f86b5905","timestamp":"2017-12-03T21:12:14+0000"}
 Fluentdに届いた測定データ (縦軸: WioLTEでAnalogReadした値(無次元), 横軸:タイムステップ)
Fluentdに届いた測定データ (縦軸: WioLTEでAnalogReadした値(無次元), 横軸:タイムステップ)
届いたデータをログファイルから抽出し、可視化する上記のような感じになりました。
4.2 Datadogの準備
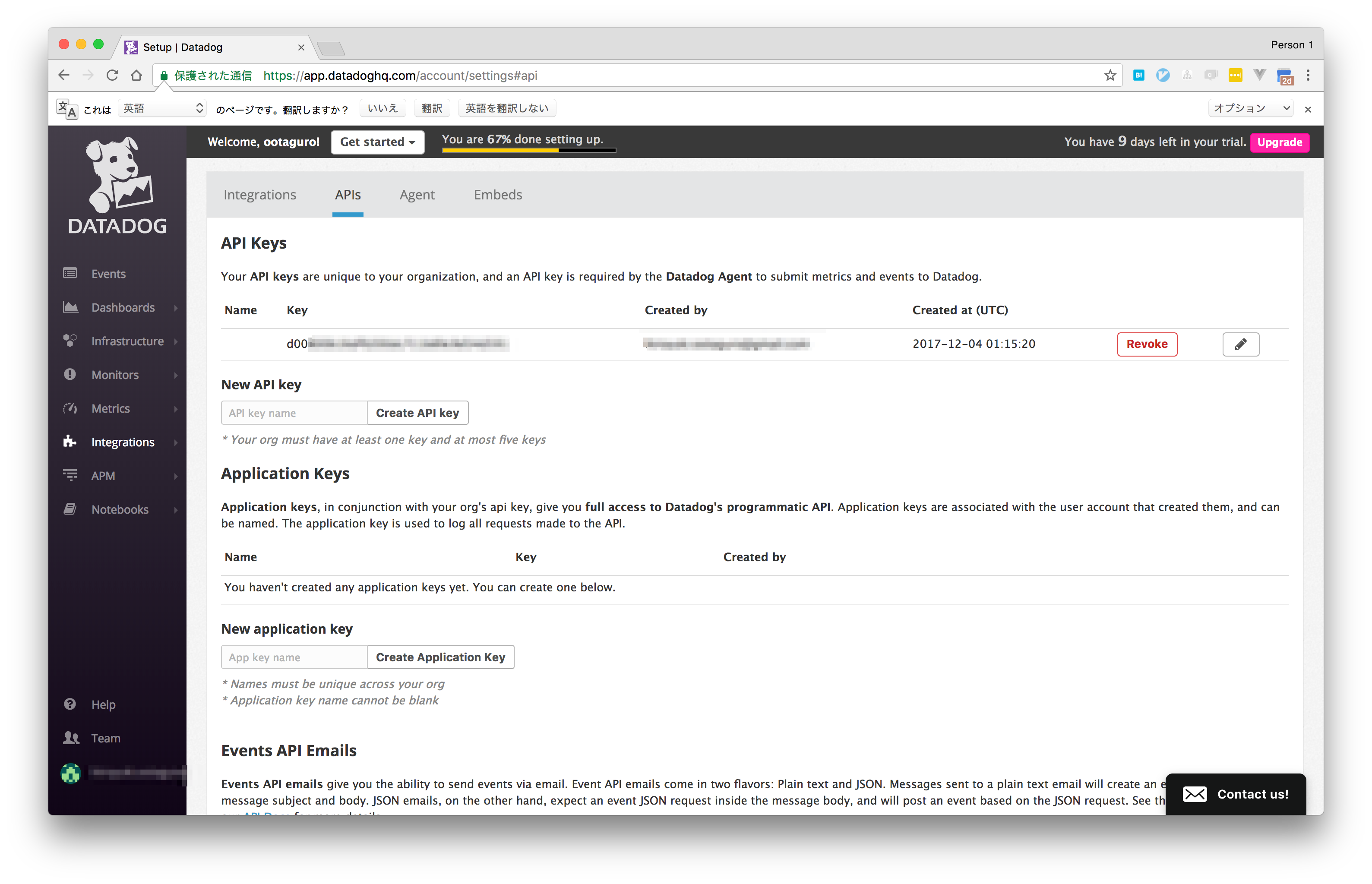
Datadogのアカウント登録後、Dashboard画面で「Integrations→ API」と進むと、APIキーの管理画面に移ります。
こちらのAPIキーを発行し、トークンを控えておいてください。
4.3 AWS上のサービス準備
4.3.1 Terraformのインストール
ここからは、作業用マシンからで問題ありません。
Download Terraformから各プラットフォーム用のパッケージが取得可能です。
ubuntu@test:~$ wget -O terraform_0.11.1_linux_amd64.zip https://releases.hashicorp.com/terraform/0.11.1/terraform_0.11.1_linux_amd64.zip
ubuntu@test:~$ unzip terraform_0.11.1_linux_amd64.zip
ubuntu@test:~$ sudo mv terraform /usr/local/bin/
ubuntu@test:~$ terraform version
Terraform v0.11.1
4.3.2 Terraform実行用のクレデンシャル設定
TerraformはAWS上のリソースを作成・編集・削除します。IAM,Kinesis,S3,Lambdaが作成・編集できるIAMユーザーを作成し、そのAccessKeyID及びSecretAccessKeyを環境変数にセットします。※リージョンは必要に応じて変更してください
export AWS_ACCESS_KEY_ID="AKIXXXXXXXXXXXXXX"
export AWS_SECRET_ACCESS_KEY="XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
export AWS_REGION="ap-northeast-1"
次のstepからは、HCL(HashiCorp configuration language)という言語を使ってTerraformが解釈可能な構成記述を行います。
書かれた定義内容は、AWS上のリソース(インフラ)に反映されますので、慎重にやる必要性があります。
4.3.3 Kinesisに関連するリソース定義 (kinesis.tf)
下記は、Kinesis Firehorseが実行可能なIAM Roleの定義、IAM Roleに紐づくポリシーの定義、Kinesis Firehorseの定義をしています。
※ 090XXXXXXXXX は適切なAWSのアカウントIDに変更する必要性があります。
# kinesis.tf
resource "aws_iam_role" "firehose_role" {
name = "firehose_test_role"
assume_role_policy = <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Action": "sts:AssumeRole",
"Principal": {
"Service": "firehose.amazonaws.com"
},
"Effect": "Allow",
"Sid": ""
}
]
}
EOF
}
resource "aws_iam_policy" "firehose_role_policy" {
name = "FirehoseExcutionPolicy"
description = ""
policy = <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "",
"Effect": "Allow",
"Action": [
"s3:AbortMultipartUpload",
"s3:GetBucketLocation",
"s3:GetObject",
"s3:ListBucket",
"s3:ListBucketMultipartUploads",
"s3:PutObject"
],
"Resource": [
"arn:aws:s3:::tf-test-bucket-taguro",
"arn:aws:s3:::tf-test-bucket-taguro/*",
"arn:aws:s3:::%FIREHOSE_BUCKET_NAME%",
"arn:aws:s3:::%FIREHOSE_BUCKET_NAME%/*"
]
},
{
"Sid": "",
"Effect": "Allow",
"Action": [
"lambda:InvokeFunction",
"lambda:GetFunctionConfiguration"
],
"Resource": "arn:aws:lambda:ap-northeast-1:090XXXXXXXXX:function:%FIREHOSE_DEFAULT_FUNCTION%:%FIREHOSE_DEFAULT_VERSION%"
},
{
"Sid": "",
"Effect": "Allow",
"Action": [
"logs:PutLogEvents"
],
"Resource": [
"arn:aws:logs:ap-northeast-1:090XXXXXXXXX:log-group:/aws/kinesisfirehose/test_stream:log-stream:*"
]
},
{
"Sid": "",
"Effect": "Allow",
"Action": [
"kinesis:DescribeStream",
"kinesis:GetShardIterator",
"kinesis:GetRecords"
],
"Resource": "arn:aws:kinesis:ap-northeast-1:090XXXXXXXXX:stream/%FIREHOSE_STREAM_NAME%"
},
{
"Effect": "Allow",
"Action": [
"kms:Decrypt"
],
"Resource": [
"arn:aws:kms:region:accountid:key/DUMMY_KEY_ID"
],
"Condition": {
"StringEquals": {
"kms:ViaService": "kinesis.%REGION_NAME%.amazonaws.com"
},
"StringLike": {
"kms:EncryptionContext:aws:kinesis:arn": "arn:aws:kinesis:%REGION_NAME%:090XXXXXXXXX:stream/%FIREHOSE_STREAM_NAME%"
}
}
}
]
}
EOF
}
resource "aws_iam_role_policy_attachment" "test-attach" {
role = "${aws_iam_role.firehose_role.name}"
policy_arn = "${aws_iam_policy.firehose_role_policy.arn}"
}
resource "aws_kinesis_firehose_delivery_stream" "test_stream" {
name = "test_stream"
destination = "s3"
s3_configuration {
role_arn = "${aws_iam_role.firehose_role.arn}"
bucket_arn = "${aws_s3_bucket.bucket.arn}"
buffer_interval = "60"
buffer_size = "1"
}
}
4.3.4 Fluentdがアクセスする用のユーザー作成(fluentd_user.tf)
FluentdがKinesisにデータをPushするためには、IAMユーザーが必要となります。
ここでは、Kinesis Firehorseに対してのみレコード登録ができるユーザーを作り、AccessKeyID及びSecretAccessKeyを払い出します。
# fluentd_user.tf
resource "aws_iam_user" "fluentd" {
name = "fluentd"
}
resource "aws_iam_access_key" "fluentd" {
user = "${aws_iam_user.fluentd.name}"
}
resource "aws_iam_user_policy" "fluentd" {
name = "fluentd"
user = "${aws_iam_user.fluentd.name}"
policy = <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"firehose:PutRecord",
"firehose:PutRecordBatch"
],
"Effect": "Allow",
"Resource": "*"
}
]
}
EOF
}
output "fluentd_access_key_id" {
value = "${aws_iam_access_key.fluentd.id}"
}
output "fluentd_secret_access_key" {
value = "${aws_iam_access_key.fluentd.secret}"
}
4.3.5 Lambda Function用コードを含むzipファイルの作成
今回のLambda Functionは、吸光度の時系列信号→脈拍に変換し、Datadogに投げるものです。(本当は、血中酸素飽和度を取りたかった)
このLambda Functionは、Kinesis Firehorse→S3とデータが上がってきた時に自動で呼び出されるものです。
このコードのロジックは、下記のとおりです。
- Lambda Function呼び出し時に、S3に上がってきたデータを文字列として取得
- 文字列と改行コードでsplitし、行単位(WioLTEの送信イベント1回分)に分解
- 全イベントの測定データをconcat (WioLTE送信イベント一回分には、300ポイントの吸光度を反映した測定データが入っている)
- concatした時系列データにFFT(高速フーリエ変換)をかける
- 周波数空間上で一番強いピークをもつポイント(周波数)を取ってくる
- 周波数から脈拍の回数に変換する
- Datadogへ送信する
脈拍は安定しない&周期が定常ではない為、同じ信号が永遠に続くことを仮定したFFTを使うのは正直かなりナンセンスです。
今回、実装の時間の都合で、簡易的にFFTを使った算出方法としました。
脈拍の算出はいろんな方法がありますが、時間ができた時に、マシな実装に書き換えます。
// index.js
var metrics = require('datadog-metrics');
var aws = require('aws-sdk');
var s3 = new aws.S3();
var fft = require('jsfft');
exports.handler = function(event, context) {
var params ={
Bucket: event.Records[0].s3.bucket.name,
Key: event.Records[0].s3.object.key
};
s3.getObject({
Bucket: params.Bucket,
Key: params.Key
}, function(err, data) {
if (err) {
console.log('Make sure they exist and your bucket is in the same region as this function.');
return
}
// Parse
var lines = String(data.Body).split("\n").filter(function (x) { return x.length > 0 });
var vals = [];
for(var i=0;i<lines.length;i++) {
var obj = JSON.parse(lines[i]);
vals = vals.concat(obj.val);
}
// FFT
var data = new fft.ComplexArray(vals.length).map((value, i, n) => {
value.real = vals[i] * 1.0;
});
data.FFT();
var mags = []
for(var i=0;i<vals.length / 2;i++){
var mag = Math.sqrt(data.real[i] * data.real[i] + data.imag[i] * data.imag[i]);
mags.push(mag);
}
var maxIdx = 1;
var maxMag = mags[maxIdx];
for(var i=1;i<mags.length;i++) {
if (maxMag < mags[i]) {
maxMag = mags[i];
maxIdx = i;
}
}
const sampleIntervalTime = 0.01; // Sampling interval = 10msec
const targetTimeRange = sampleIntervalTime * vals.length;
const baseFreq = (1.0 / targetTimeRange)
const heartRateFreq = baseFreq * maxIdx;
var heartRate = heartRateFreq * 60;
metrics.init({ host: 'hiroyuki', prefix: 'mylife.' });
metrics.gauge('body.heartrate', heartRate);
});
};
上記ファイルをindex.jsと保存した後、npmによるライブラリインストール及びzip化をします。
ubuntu@test:~$ npm install jsfft datadog-metrics
ubuntu@test:~$ ls -l
total 16
-rw-r--r-- 1 taguro staff 2248 12 9 19:32 index.js
drwxr-xr-x 94 taguro staff 3196 12 4 13:07 node_modules
ubuntu@test:~$ zip -r lambda_function_payload.zip *
updating: index.js (deflated 59%)
updating: node_modules/ (stored 0%)
updating: node_modules/.bin/ (stored 0%)
updating: node_modules/.bin/dogapi (deflated 68%)
updating: node_modules/.bin/har-validator (deflated 58%)
updating: node_modules/.bin/rc (deflated 57%)
updating: node_modules/.bin/semver (deflated 67%)
updating: node_modules/.bin/sshpk-conv (deflated 65%)
updating: node_modules/.bin/sshpk-sign (deflated 66%)
updating: node_modules/.bin/sshpk-verify (deflated 67%)
...
ubuntu@test:~$ ls -l lambda_function_payload.zip
-rw-r--r-- 1 taguro staff 4918152 12 9 19:37 lambda_function_payload.zip
4.3.6 Lambda Functionの定義(lambda.tf)
Lambda Functionの環境変数DATADOG_API_KEYは、DatadogのAPIキーを正しく入力してください。
# lambda.tf
resource "aws_iam_role" "iam_for_lambda" {
name = "iam_for_lambda"
assume_role_policy = <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Action": "sts:AssumeRole",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Effect": "Allow",
"Sid": ""
}
]
}
EOF
}
resource "aws_iam_policy" "lambda_execution" {
name = "LambdaExecutionRole"
description = ""
policy = <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "logs:CreateLogGroup",
"Resource": "arn:aws:logs:ap-northeast-1:090XXXXXXXXX:*"
},
{
"Effect": "Allow",
"Action": [
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": [
"arn:aws:logs:ap-northeast-1:090XXXXXXXXX:log-group:/aws/lambda/s3_trigger_lambda:*"
]
},
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject"
],
"Resource": ["arn:aws:s3:::tf-test-bucket-taguro/*"]
}
]
}
EOF
}
resource "aws_iam_role_policy_attachment" "attach-lamba-excution" {
role = "${aws_iam_role.iam_for_lambda.name}"
policy_arn = "${aws_iam_policy.lambda_execution.arn}"
}
resource "aws_lambda_function" "s3_trigger_lambda" {
filename = "lambda_function_payload.zip"
function_name = "s3_trigger_lambda"
role = "${aws_iam_role.iam_for_lambda.arn}"
handler = "index.handler"
source_code_hash = "${base64sha256(file("lambda_function_payload.zip"))}"
runtime = "nodejs4.3"
timeout = "60"
environment {
variables = {
DATADOG_API_KEY = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
DEBUG = "metrics"
}
}
}
resource "aws_lambda_permission" "allow_bucket" {
statement_id = "AllowExecutionFromS3Bucket"
action = "lambda:InvokeFunction"
function_name = "${aws_lambda_function.s3_trigger_lambda.arn}"
principal = "s3.amazonaws.com"
source_arn = "${aws_s3_bucket.bucket.arn}"
}
4.3.7 S3バケットの作成とNotification設定(s3.tf)
バケットの作成、ACLの設定、オブジェクト作成時に前述のLambdaが起動するようにしています。
もし、個人でお試しになられる場合は、衝突しない別のバケット名に変えていただけますと幸いです。
# s3.tf
resource "aws_s3_bucket" "bucket" {
bucket = "tf-test-bucket-taguro"
acl = "private"
}
resource "aws_s3_bucket_notification" "bucket_notification" {
bucket = "${aws_s3_bucket.bucket.id}"
lambda_function {
lambda_function_arn = "${aws_lambda_function.s3_trigger_lambda.arn}"
events = ["s3:ObjectCreated:*"]
}
}
4.3.8 Terraform 確認作業
下記、コマンドでこれまで定義したリソースの確認ができます。
ubuntu@test:~$ terraform plan
4.3.9 Terraform 実行
下記、コマンドで実際にAWS上に定義したリソースを作成する事ができます。
ubuntu@test:~$ terraform apply
(省略)
Apply complete! Resources: XX added, 0 changed, 0 destroyed.
Outputs:
fluentd_access_key_id = AKIXXXXXXXXXXXXX
fluentd_secret_access_key = xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
以上のような画面がでてくれば、リソース生成が成功です。
4.4 Fluentd側にKinesis転送ロジック追加
現時点で、WioLTE→Fluentdの結合が終わっており、AWS上のリソース(Kinesis Firehorse,S3,Lambda)及びDatadogの準備ができました。
最後に、Fluentd→Kinesis Firehorseの結合を行い、デバイスからDatadogまで一連のデータフローを作っていきたいと思います。
Fluentdのconfファイルを下記にしたがって変更します。デバイスから受け取ったデータの出力をstdoutに加えて、kinesis_firehoseにも転送するという設定です。kinesis_firehoseプラグインのaws_key_id, aws_sec_keyは、Terraform apply時に払い出されたものを利用します。
(変更前)
<match test.http.json>
@type stdout
</match>
(変更後)
<match test.http.json>
@type copy
<store>
@type stdout
</store>
<store>
@type kinesis_firehose
region ap-northeast-1
delivery_stream_name test_stream
append_new_line true
aws_key_id AKIXXXXXXXXXXXXX
aws_sec_key xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
</store>
</match>
ファイルを変更後、コンテナを再起動して設定を変更させます。
ubuntu@test:~$ docker restart fluentd
うまくいくと、下記のようにデータがはいります。
データがWioLTE→Kinesis Firehorse→S3→Lambda→Datadogと渡り始め、Datadog上のDashboardでデータの可視化が可能になります。

4.5 Datadog側の異常検知機能を設定する
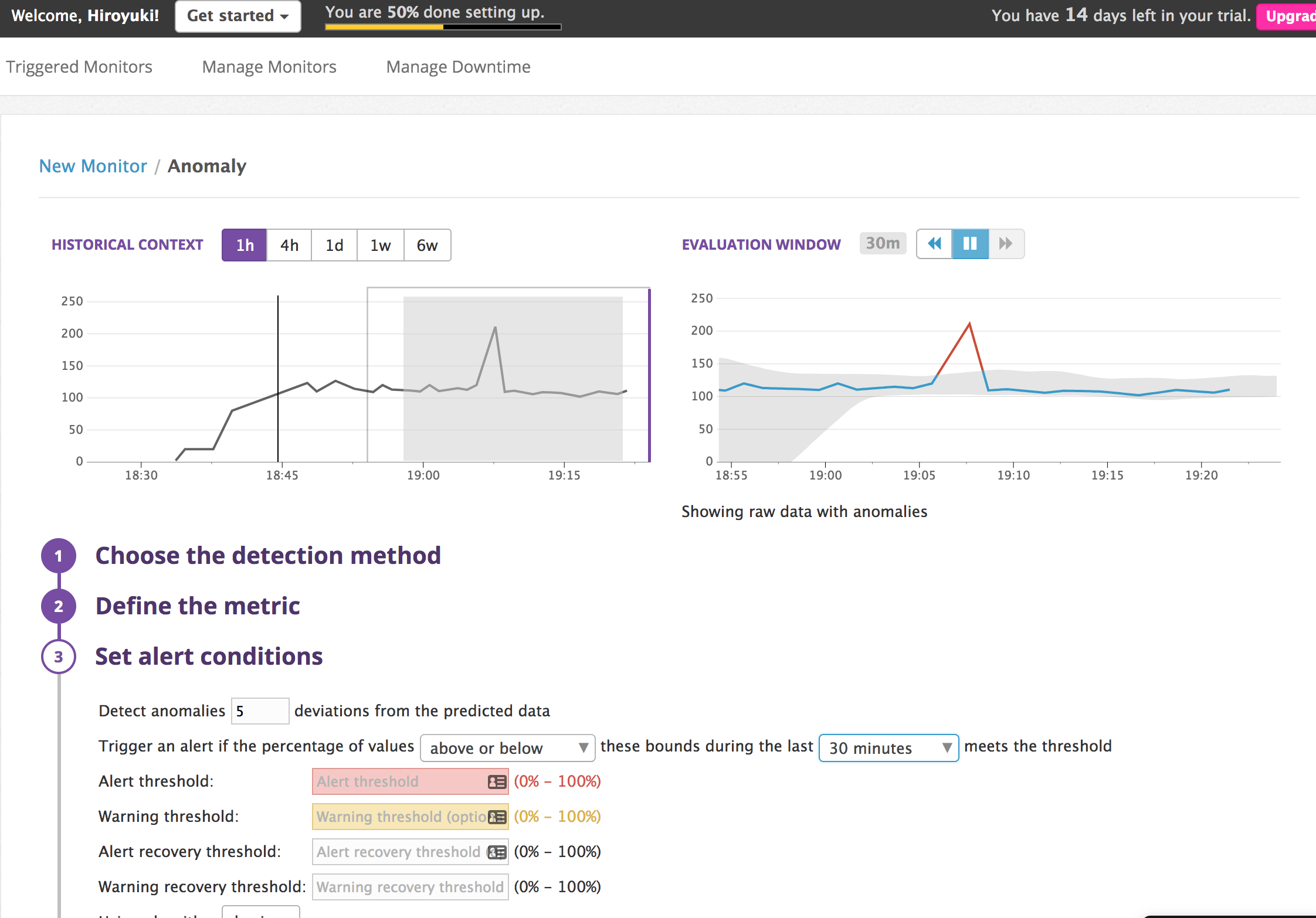
上記のように、Monitorsからグラフィカルな画面での異常検知設定が可能です。
異常検知アルゴリズムやパラメータを変更すると、正常とみなすグレーのゾーンが変わっていきます。

アラートコンディションでどれぐらい逸脱したら、どうアクションするか?という事が設定できるので、
一旦メール連携をしてみました。(プローブをわざと外して発報させてみました)
5.最後に
WioLTEの登場によりデバイス側のデータがクラウド上にサクッとあがるようにありました。個人的にはなかなか革命だと思っており、RaspberryPi+USBドングルで実装するIoTデバイスよりもサイズ的にも手間的にも格段に減っています。IoTでユーザーが試したいこと、やりたいことのバリューに集中できるいい時代になったなと思いました。
これは自分自身の信念?ですが、デバイス側と同じぐらいクラウド側もさくっと組み上げられないと意味が無いなと思っており、今回はInfrastructure as a codeを絡めて、システム構築を行いました。記事をご覧になられた方の中には、結構手間だな・・・と思う方もいらっしゃるかもしれません。一方で、もう一度同じもの似たようなものを作るのであれば、ここで構成をコード化しておくのはありでしょう。
参考までに、今回のTerraformコードは、一部Terraformingというツールを使って用意しています。既存のインフラからTerraformのコードを吐くことができるものです。
「何かセンサーデータをクラウドに上げてデータためて、分析してなんか異常検知とかやりたい!」というニーズがでてきた時に、この記事が役立てばと思います。
参考リンク
余談
実は、reInvent2017に参加しており、日本に帰国したのが12/3の夜20:00でした。帰国してから回路〜クラウド側基盤構築・スライド作成を始め、実は発表30分前まで発表に使う脈拍データの取得をやってました。(本当に、本当に間に合ってよかった...)