はじめに
こんにちは。ABEJAのAdvent Calendar3日目を担当している大田黒です。最近、IoTxAIのパワーで会社でキノコ![]() を育てているABEJAのエンジニアです。
を育てているABEJAのエンジニアです。
会社でしいたけ育ててます pic.twitter.com/WhraaF0GCz
— たぐろまる@ABEJA Inc (@xecus) November 20, 2019
突然ですが、ある日仕事(きのこ育成)をしていたら某プロダクトの開発メンバーから**「将来的に、数千万〜億の数の特徴量データにクエリーをかけて厳密近傍を数十msecで探してくれるマイクロサービスがほしい」**みたいな話がポロッと聞こえてきました。「問題設定エグくない?大丈夫?」と思いつつも、ちょっと真剣な顔をしていたので、色々思いを巡らせてみる事にしました。![]()
※ここでは詳しく語りませんが、社のTechBlogのTechStack紹介記事等をご覧いただくと背景がわかるかもしれません。
Ref: ABEJAの技術スタックを公開します(2019年11月版)
これが一般的なWebアプリケーションの世界の話だと、「大量のデータ?BigQueryがいいよ!」みたいな声が聞こえてきそうなんですが、今回相手にするデータは高次元ベクトルである特徴量。doubleとかfloat型の配列(ベクトル)が超大量あって、配列(ベクトル)を引数に検索をかけて近傍の配列を探してきたり、みたいな感じです。※もしかしたら、BQならUDF(user-defined function)を使えばワンちゃん実装できるかもしれませんが。。
この手の分野の技術は、類似した写真検索等のアプリケーションで使われている事が多く、ある程度精度を犠牲にしつつも高速化された検索アルゴリズムが使用されている事が多いです。※類似検索であれば多少精度が劣化しても実利用に大きな影響が出ない
問題設定を若干疑いつつも、色々と思いを馳せながらノリ&ゆるふわで設計・開発をしてみようと思います。「厳密近傍が得られる1億オーダーの特徴量検索を50msecでできる事」を目標性能として目指しつつ、いつか社内で使ってくれたら嬉しいな..![]() って感じの心構えでいきます。
って感じの心構えでいきます。
※ゆるふわな気持ちでお付き合いくださいませ ![]()
設計
ゆるくいきます ![]()
ゆるふわ要件整理 
-
API経由で特徴量の検索ができる (基本機能
 )
)-
厳密近傍が返却できる事 - プロダクトの中にマイクロサービス的な位置づけで組み込む事を想定する
-
-
特徴量は新規に登録ができる(基本機能
)- 検索するデータが登録できないと意味がないので、超大事機能
-
ニアリアルタイムな特徴量検索の実施 (基本機能
)- オフラインじゃなくてオンライン。後でバッチで流そうではなく、結果がはよほしい。
-
増え続ける特徴量データや検索コストに対して、改善できる手段を持つ (開発/運用観点
 )
)- ここがスケールできないと、プロダクトもスケールできない
-
Design for failure (開発/運用観点
)- ネットワークは常に安定的とは限らない。瞬断や帯域枯渇とかするかも。
- 物理サーバー・インスタンスは途切れたり、落ちることが予想される。(IaaS側のHW故障・メンテナンス等)
-
メンテナンスレス (運用観点
)- 完全なメンテナンスレスは難しいが、なにかあっても自動復旧してくれる事を期待
- HW面から攻めるのもありだが、可能であればクラウド上で組みたい気持ち
-
メトリクスを基軸とした開発・運用ができる (開発/運用観点
)- 何が原因でパフォーマンスがでないのか、科学的に考察しながらKAIZENできるようにする。
ゆるふわ作戦会議
一旦、クラウド上で実装する事を前提にしつつアーキテクチャ観点でザクッと考えてみました。 ![]()
(個人的には、特徴量検索を行列演算に帰着させてGPUやFPGAに解かせたり、複数台のNVMe SSDを束ねて専用のハード組んだりとかしてみたいですが。。)
作戦1: RAMサイズの大きな特徴量検索DBをインメモリで運用

- 概要
- 比較的RAMサイズの大きなインスタンスを1台用意して、特徴量検索エンジンと特徴量プールをドカっと乗っける
- PROS
- システム構成が非常にシンプル
- 開発や運用がしやすいのは非常に良い
- 利用できるOSSの特徴量検索フレームワークが多くある
- OSSの特徴量検索フレームワークが世の中にいくつか存在しているので、後はAPIを生やすだけ
- 分散システムの闇に触れなくて済む
- システム構成が非常にシンプル
- CONS
- 検索パフォーマンスが改善しづらそう。
- 検索パフォーマンスはCPUの性能やアプリの作り方(並列処理等)に大きく依存
- 性能を上げるためには、SIMDで計算させるとかのチューニングが必要
- メンテナンスコストが地味に高い
- 増え続ける特徴量に対してメモリが枯渇する日がくるので、常にRAM割当サイズを上げ続ける必要性
- N/W・インスタンスの障害に弱い。溢れ出るSPOF感。
- 1台のインスタンスしかないので、これが死ぬとすべて死ぬ。
- 検索パフォーマンスが改善しづらそう。
- 個人メモ
- SPOFまつりのシステムの男気デプロイは避けたい
- バックエンド側がつらい思いをする
- パフォーマンス改善に関してはPQ(直積量子化)の適用や、GPU利用みたいな話はありえる。
- そっちに問題設定を落として、システムサイドは楽にしたほうがいいかもしれない。
- RAMの代わりに、NVMe SSDを使ってもいいかもしれない。
- CPUの高速化命令セットを使ったチューニングは、IaaS起因のインスタンスガチャあるかも。
- 過去に辛いことがあった
- SPOFまつりのシステムの男気デプロイは避けたい
作戦2: 複数台の特徴量検索エンジン + 1つの共有特徴量プール

-
概要
- 特徴量検索エンジンの乗っかったインスタンスを複数用意してN/W的に結合する
- 全ての特徴量は、1つのN/W的にアクセスできるプール(例: NFS..?)等で保持する
- 検索クエリーを受け取ったインスタンスは、外部プールにその都度問い合わせに行く
-
PROS
- 開発部分は多そうだが、世の中の特徴量検索フレームワークはまだありそう
- 検索クエリー増加時のスケーリングは簡単そう
- インスタンス増やすだけで、検索クエリーは分散できそう
-
CONS
- クエリーごとに、エンジンから特徴量プールにデータを問い合わせる必要性がある
- N/WやI/Oまわりのレイテンシが毎回発生するので、数十msecのオーバーヘッドが発生するかも
- 検索対象である登録された全ての特徴量を毎回プールから引っ張ってこないと行けない
- クエリーの度に、エンジンとプール間でそこそこのトラフィックが発生しそう
- プール側が、厳密解を含む小規模な解候補を返却できる場合、かなり改善はできるかも
- クエリーごとに、エンジンから特徴量プールにデータを問い合わせる必要性がある
-
個人メモ
- WEB・APP・DBのレイヤーを分けていくあの構成に感覚的には近いかも
- 検索時間のオーバーヘッドはあるが、設計・やり方次第でスケールはかなりしやすそう(主観)
作戦3: 複数の特徴量検索エンジン + 分散特徴量保持

- 概要
- 特徴量検索エンジンと(小規模な)特徴量プールが乗っかったインスタンスを複数用意する
- 巨大な特徴量プールを、複数台がある程度重複しながら保持する前提
- LoadBalancerが検索リクエストを受け取ったら、特徴量を保持しているクラスター全台に問い合わせに行く
- 各クラスターの結果を集計して、クライアントサイドに返却する
- 特徴量検索エンジンと(小規模な)特徴量プールが乗っかったインスタンスを複数用意する
- PROS
- インスタンスを増やしてクラスターにJOINさせるだけで、検索性能も特徴量保持性能(容量)もスケールできる
- 特徴量の検索性能・特徴量の保持性能の限界がインスタンス数に対して線形に伸びていく。
- インスタンスを増やしてクラスターにJOINさせるだけで、検索性能も特徴量保持性能(容量)もスケールできる
- CONS
- システムが複雑。開発も運用もかなり苦戦しそう。
- クラスターの1台が故障しデータロストすると、今後一切の適切な結果が返せなくなる可能性がある
- 保持している特徴量データはなんとしても守り抜かないといけない
- エンジン部分とプール部分が密結合なので、それぞれを個別にスケールさせづらい
- 特徴量のWriteQueryが過半数を占める場合、プール部分だけスケールしたい気持ちが高まりそう
- 個人メモ
- RAID1の特徴量ストレージ(特徴量検索エンジン付き)みたいな感じ。
- Control PlaneとData Planeは分離したほうが良いかも
- 検索バックエンドとしてFPGAとかGPUが使えれば、楽しそう。ベンダーロックインかっちりするけど。
余談: 特徴量保持に必要なキャパシティの計算
特徴量の数 × ベクトルの次元 × 型サイズ(float/double)
すごく単純にですが、上記の計算式で計算ができます。(※アライメントやパディングは一旦無視しています)。
例えば、512次元からなる1000個の特徴量がdouble(8byte)であったとすると、1000 × 512 (dim) × 8 (byte/dim) = 4096000 byteと計算ができる為、およそ4 MByteとなります。(※512次元はかなりの高次元ですが。。)
本記事の最初にあったように、特徴量の数が数千万〜億になった場合の事を考えます。仮に、1億の特徴量データがあった場合、前の計算式に当てはめると410GB近くになります。
※ 仮に、インメモリで載せようとおもった場合、ラフに起動できるEC2インスタンスのプランは既に存在しない。
Ref:Amazon EC2 High Memory インスタンス
※ 特徴量の数が膨大になってくると非常に大きなメモリ消費が生じる。データを次元圧縮して、近似解を得るソリューションが現実的。
Ref: 映像奮闘記: 直積量子化(Product Quantization)を用いた近似最近傍探索についての簡単な解説
全体設計 (v1初期設計) 
ゆるく全体設計してみました。今回は、作戦3をベースに考えてみました。一旦作ってみてヤバそうであれば、作戦2とかにしようかなっていう感じです。

-
用語説明
- Node: アプリの動いているサーバーインスタンス
- Brick: 小規模な特徴量の集合体
- State: 全クラスターが知っておくべきステート情報
- 例: クラスター内のノード情報などの情報。
-
各NodeのRole(役割)としては、
CalcとProxyに分かれる。- Calc: 計算&データ保持
- Proxy: Calcへの検索クエリProxy&集計
-
各Nodeは、Gossip Protocolを用いて
Stateを共有する- お互いのノード情報(IPアドレス・通信に必要なポート番号...)
- お互いの保持している特徴量のBrick一覧など
- Gossip Protocol: 分散システムにおける情報交換の仕組みの一つ
- State-Based CRDT: Convergent Replicated Data Type(CvRDT)なStateのやり取りを実施
-
各Nodeは、
Stateを取得する為のAPIを持つ-
CalcやProxyなどのRoleに関係なく、そのNodeが持っている現時点でのステート情報が返却される - 通常時は全Node同じ情報を持つが、ネットワーク分断等が発生すると持っているステートに差分が発生する
- ただし、復旧後は正しい情報をもつ (結果整合性)
-
※本気で特徴量検索エンジン(DB)と言い張るには、ある程度、トランザクション特性(RDBMSであるようなACID特性の話)の事とか、システム全体としての特性(BASE特性みたいな)話を設計に混ぜる必要性がありそうですが、、今回は特に触れていないので、「ゆるふわ」とタイトルに変えさせていただいています。
Role: CalcNode
役割: 特徴量検索の実施及び内部の特徴量プールに操作インターフェースの提供
- 特徴量を登録及び検索するためにAPIを持つ
- 特徴量検索は、GoRoutineを用いて並列処理(※試しに)
- 検索処理は、総当たりでクエリーと登録済み特徴量(ベクトル)の距離をL2ノルムを使って計算し、厳密近傍を返却する
d(\vec{x}, \vec{y})=\sqrt{(x_1-y_1)^2+(x_2-y_2)^2+...+(x_n-y_n)^2}
-
自分自身のノード情報を定期的に送信する機能を持つ (GossipProtocol経由)
- IPアドレス、保持しているBrickの情報
-
(未実装) Replication設定がされた場合、自動で他ノードの特徴プールを自身にコピーする
Role: ProxyNode
役割: 各Nodeへの特徴量検索のProxy&集計
- 特徴量検索クエリーを受け取ったら、後段の各CalcNodeへ問い合わせ & 集計
- 各Nodeが保持する特徴量プールで検索を行い、全Nodeが返却する近傍値をソートしてさらにクライアントへの返却
開発物
※ まだまだ全然必要コンポーネントができていませんが、一旦公開だけ。
※ 本記事を書くために、短時間でだいぶ書き散らかしています。
※ 単一Packageだし、コードも汚いです。
※ 随時リファクタリングしたり、機能実装していきます。
試験用環境構築メモ (自分用の忘備録)
 (Fig. 試験用環境のインスタンス/NW構成)
(Fig. 試験用環境のインスタンス/NW構成)
計算ノード群の準備 (さくらクラウド利用例)
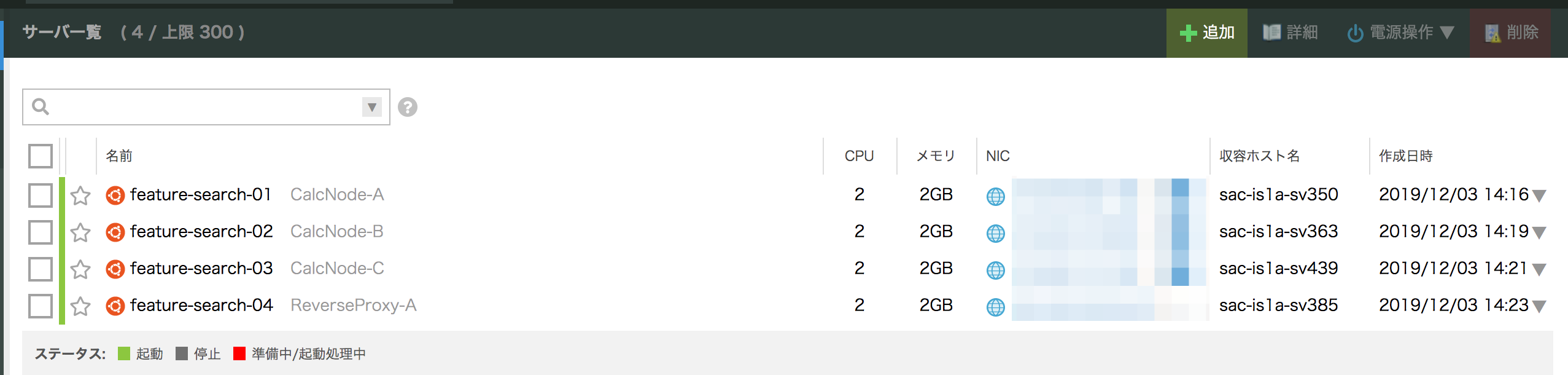
インスタンスの調達
さくらクラウドを用いて、2Core 2GB RAMのVMを4台調達。(CalcNode3台、ProxyNodeで1台)
- 実験環境
- CPU: Intel(R) Xeon(R) CPU E5-2650 v3 @ 2.30GHz
- RAM: 2GB
NICの設定 (管理画面側)
 (Fig. インスタンスの作成)
(Fig. インスタンスの作成)
 (Fig. 追加のスイッチの作成)
(Fig. 追加のスイッチの作成)
 (Fig. NICの作成&追加したスイッチNWへの割当作業)
(Fig. NICの作成&追加したスイッチNWへの割当作業)
SWAPをOFFにしておく
メモリに乗り切らない特徴量がSWAPとしてファイルシステムに乗っかるとパフォーマンス劣化しそうなので。
ubuntu@feature-search-01:~/feature-serach-db$ sudo swapoff -a
IPアドレスの固定化作業
NICが認識されているか確認 (※試験環境では3つNICがあるため、3つ表示されている)
ubuntu@feature-search-01:~$ sudo lshw -short -class network
H/W path Device Class Description
==================================================
/0/100/3 eth0 network Virtio network device
/0/100/4 eth1 network Virtio network device
/0/100/5 eth2 network Virtio network device
ネットワーク設定ファイルを編集
追加したNIC(eth1, eth2)には、IPアドレスがないので設定する必要性がある
ubuntu@feature-search-01:~$ cat << 'EOF' | sudo tee -a /etc/network/interfaces > /dev/null
auto eth1
iface eth1 inet static
address 172.30.0.2
netmask 255.255.0.0
auto eth2
iface eth2 inet static
address 172.31.0.2
netmask 255.255.0.0
EOF
下記は今回のインスタンスの各NICとIPアドレスのマッピング
- CalcNode-A
- eth1(State通信用):172.30.0.2/16
- eth2(特徴量検索・登録用):172.31.0.2/16
- CalcNode-B
- eth1(State通信用):172.30.0.3/16
- eth2(特徴量検索・登録用):172.31.0.3/16
- CalcNode-C
- eth1(State通信用):172.30.0.4/16
- eth2(特徴量検索・登録用):172.31.0.4/16
- Proxy-A
- eth1(State通信用):172.30.0.1/16
- eth2(特徴量検索・登録用):172.31.0.1/16
インターフェース立ち上げ
ifupを使っているが、networkサービスのリブートでも可
ubuntu@feature-search-01:~$ sudo ifup eth1
RTNETLINK answers: File exists
Failed to bring up eth1.
ubuntu@feature-search-01:~$ sudo ifup eth2
RTNETLINK answers: File exists
Failed to bring up eth2.
各種ソフトウェアのインストール作業
必要パッケージのインストール
$ sudo apt update
$ sudo apt upgrade
$ sudo apt install -y curl wget vim htop tmux git
Go環境の構築
goenvを使って、goの開発環境を整える (楽なので)
$ git clone https://github.com/syndbg/goenv.git ~/.goenv
$ vim ~/.bashrc
export GOENV_ROOT=$HOME/.goenv
export PATH=$GOENV_ROOT/bin:$PATH
eval "$(goenv init -)"
$ goenv install 1.13.4
$ goenv global 1.8.3
Datadogの導入(APM)
パフォーマンス分析をして科学的に進める為の土壌として。
Agentのインストール
今回はDatadog APMを使って、アプリケーションのボトルネック分析の土壌を作ります。今回は、UbuntuベースのVMを使っており、下記の用にエージェントのインストールを行いました。
DD_API_KEY=XXXXXXXXXXXXXXX bash -c "$(curl -L https://raw.githubusercontent.com/DataDog/datadog-agent/master/cmd/agent/install_script.sh)"
正しく設定ができると、下記のようにDatadog上でインスタンスの情報が見れるようになります。


APMの組み込み方法
下記は、Golangを使ったWebアプリケーションサーバー + Datadog APM連携のサンプルコードです。
Tracerを初期化し、HandleFuncするインスタンスを差し替える事で準備完了です。
(引用元: https://docs.datadoghq.com/ja/tracing/setup/go/)
package main
import (
"net/http"
"strings"
"log"
httptrace "gopkg.in/DataDog/dd-trace-go.v1/contrib/net/http"
"gopkg.in/DataDog/dd-trace-go.v1/ddtrace/tracer"
)
func sayHello(w http.ResponseWriter, r *http.Request) {
message := r.URL.Path
message = strings.TrimPrefix(message, "/")
message = "Hello " + message
w.Write([]byte(message))
}
func main() {
// start the tracer with zero or more options
tracer.Start(tracer.WithServiceName("test-go"))
defer tracer.Stop()
mux := httptrace.NewServeMux() // init the http tracer
mux.HandleFunc("/", sayHello) // use the tracer to handle the urls
err := http.ListenAndServe(":9090", mux) // set listen port
if err != nil {
log.Fatal("ListenAndServe: ", err)
}
}
アプリケーション準備
リポジトリCLONE & ビルド
※全台で実施
ubuntu@feature-search-01:$ git clone git@github.com:xecus/yuruhuwa-feature-db.git ~/feature-serach-db
ubuntu@feature-search-01:~/feature-serach-db$ go build
立ち上げ
CalcNode-A
-
ポート設定
- State関連APIをポート8001番で初期化
- 特徴量クエリー関連APIをポート8081番で初期化
-
Gossip Protocol関連の設定 (State共有用)
- State同期用Gossip Protocol用ポートを6001番で初期化
-
1万の特徴量データを初期brickとして投下する
- 各特徴量ベクトルを構成する各要素の初期値は、一旦乱数で初期化。Denseな構造になる。
-
state通信用のpeerとして、Proxy-Aとやり取りをする
ubuntu@feature-search-01:~/feature-serach-db$ ./feature-search-db -hwaddr 00:00:00:00:00:01 -nickname a -mesh :6001 -state_api 0.0.0.0:8001 -feature_api 0.0.0.0:8081 -node_role calc -ipaddress 172.31.0.2 -peer 172.30.0.1:6004 -size_of_init_brick 10000
CalcNode-B
-
ポート設定
- State関連APIをポート8002番で初期化
- 特徴量クエリー関連APIをポート8082番で初期化
-
Gossip Protocol関連の設定 (State共有用)
- State同期用Gossip Protocol用ポートを6002番で初期化
-
1万の特徴量データを初期brickとして投下する
- 各特徴量ベクトルを構成する各要素の初期値は、一旦乱数で初期化。Denseな構造になる。
-
state通信用のpeerとして、Proxy-Aとやり取りをする
ubuntu@feature-search-02:~/feature-serach-db$ ./feature-search-db -hwaddr 00:00:00:00:00:02 -nickname b -mesh :6002 -state_api 0.0.0.0:8002 -feature_api 0.0.0.0:8082 -node_role calc -ipaddress 172.31.0.3 -peer 172.31.0.1:6004 -size_of_init_brick 10000
CalcNode-C
-
ポート設定
- State関連APIをポート8004番で初期化
- 特徴量クエリー関連APIをポート8083番で初期化
-
Gossip Protocol関連の設定 (State共有用)
- State同期用Gossip Protocol用ポートを6003番で初期化
-
1万の特徴量データを初期brickとして投下する
- 各特徴量ベクトルを構成する各要素の初期値は、一旦乱数で初期化。Denseな構造になる。
-
state通信用のpeerとして、Proxy-Aを選択
ubuntu@feature-search-03:~/feature-serach-db$ ./feature-search-db -hwaddr 00:00:00:00:00:03 -nickname c -mesh :6003 -state_api 0.0.0.0:8003 -feature_api 0.0.0.0:8083 -node_role calc -ipaddress 172.31.0.4 -peer 172.31.0.1:6004 -size_of_init_brick 10000
Proxy-A
-
APIポート設定
- State関連APIをポート8004番で初期化
- 特徴量クエリーのProxyAPIをポート8084番で初期化
-
Gossip Protocol関連の設定 (State共有用)
- State同期用Gossip Protocol用ポートを6004番で初期化
-
state通信用のpeerはなし (今回のクラスターでは、親的な立ち位置になる)
ubuntu@feature-search-04:~/feature-serach-db$ ./feature-search-db -hwaddr 00:00:00:00:00:04 -nickname d -mesh :6004 -state_api 0.0.0.0:8004 -feature_api 0.0.0.0:8084 -node_role reverseProxy
各種テスト
ステート共有状況の確認
State関連APIを叩くと、対象のNodeが保持しているステートを取得できます。前述の通り、State-Based CRDTを用いてステートの共有を行っている為、基本的には全Nodeが同一の情報を持っています。※N/W分断が発生していない場合
ステートを持つAppサーバーを落として立ち上げても、Peer指定したNodeからStateを引っ張ってきてくれるのでステートがうまく復旧できている事が確認できます。
※下記の応答例はCalcNode-Aが保持しているステートです。今回の例では、172.31.0.2:8001を叩くと取得できます。CalcNode-Bのステートは、172.31.0.3:8002, CalcNode-Cのステートは172.31.0.4:8003, Proxy-Aの持つステートは、172.31.0.1:8004から確認が可能です。
ubuntu@feature-search-01:~$ curl http://172.31.0.2:8001/ | jq .
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 1026 100 1026 0 0 641k 0 --:--:-- --:--:-- --:--:-- 1001k
{
"NodeInfos": {
"00:00:00:00:00:01": {
"bricks": [
{
"uniqueID": "bnju97gd9lkcka42b92g",
"brickID": "bnju97gd9lkcka42b930",
"groupID": 0,
"numOfBrickTotalCap": 1000,
"numOfAvailablePoints": 1000
}
],
"count": 463,
"ipAddress": "172.31.0.2",
"api_port": "0.0.0.0:8081",
"launch_at": "2019-12-05T01:53:50.747422525+09:00",
"last_updated_at": "2019-12-05T03:11:00.882586514+09:00"
},
"00:00:00:00:00:02": {
"bricks": [
{
"uniqueID": "bnju9i39q2vsgia9nc20",
"brickID": "bnju9i39q2vsgia9nc2g",
"groupID": 0,
"numOfBrickTotalCap": 1000,
"numOfAvailablePoints": 1000
}
],
"count": 459,
"ipAddress": "172.31.0.3",
"api_port": "0.0.0.0:8082",
"launch_at": "2019-12-05T01:54:32.198853263+09:00",
"last_updated_at": "2019-12-05T03:11:02.322481527+09:00"
},
"00:00:00:00:00:03": {
"bricks": [
{
"uniqueID": "bnju9ollgnpckpdc7vug",
"brickID": "bnju9ollgnpckpdc7vv0",
"groupID": 0,
"numOfBrickTotalCap": 1000,
"numOfAvailablePoints": 1000
}
],
"count": 456,
"ipAddress": "172.31.0.4",
"api_port": "0.0.0.0:8083",
"launch_at": "2019-12-05T01:54:58.492636101+09:00",
"last_updated_at": "2019-12-05T03:10:58.635806024+09:00"
}
}
}
特徴量検索クエリーの実行
対象: 単一Node (単一CalcNode上で計算)
512次元 20万特徴量における検索の実施
環境: Intel(R) Xeon(R) CPU E5-2650 v3 @ 2.30GHz , 2GB RAM (さくらクラウド)

Naive
$ while [ : ] ;do curl -s -XPOST -H "Content-Type: application/json" -d '{"vals": [(省略)]}' 'http://172.30.0.2:8081/api/v1/searchQuery?featureGroupID=0&calcMode=naive' | jq . ; done

単一Node上で単一プロセス上における検索の実施。特徴量の検索(各特徴量とクエリーの距離計算)は並列化せず、素直にfor分で距離の計算をしています。このモードをNaiveと名付けています。 160msec~220msecの間でレスポンスタイムが分布しているようです。 この条件で20万の特徴量データに対してクエリーをかけると、大体こんな感じみたいですね。ここから、並列化したり複数Nodeにクエリーを分散させたりしていきます。
GoRoutineによる並列計算 (n=2) ※実験
$ while [ : ] ;do curl -s -XPOST -H "Content-Type: application/json" -d '{"vals": [(省略)]}' 'http://172.30.0.2:8081/api/v1/searchQuery?featureGroupID=0&calcMode=goroutine_2' | jq . ; done

試しに、特徴量の検索部分をGoRoutineで並列化してみました。その結果、80msec~130msecの間でレスポンスタイムが分布するようになりました。Naiveに比べてレスポンスタイムが概ね1/2になりました。さすが並列処理って感じですね。(当たり前かもしれませんが)
※ 下記設定を初期化時に実行。今回の環境では、GOMAXPROCSは2に設定されているはずです。
cpus := runtime.NumCPU()
runtime.GOMAXPROCS(cpus)
対象: 複数Nodeによる分散クエリー処理 (Proxy経由)
512次元 20万特徴量における検索の実施
1Nodeあたり約7万特徴量を保持し、Proxy経由で各Nodeが分散クエリー実行をする状態
環境: Intel(R) Xeon(R) CPU E5-2650 v3 @ 2.30GHz , 2GB RAM × 3台のCalcNode (さくらクラウド)

Proxyにクエリーを投げることで、自動的にCalcNodeへの分散クエリー実行を行ってくれる。
Naive

3ノードでクエリーを分散実行して、Proxy側で集計して返すようにした結果、60msec~100msecの間でレスポンスタイムが分布するようになりました。3ノード+Proxyで分散処理した結果、単一ノード時に比べて2~3倍レスポンスタイムが改善しました。
各NodeでGoRoutineによる並列計算 (n=2) ※実験

3ノード+Proxyで分散クエリーの処理をしつつ、さらに各ノードがGoRoutineを使って特徴量の検索処理をするようにしました。その結果、30msec~90msecの間でレスポンスタイムが分布するようになりました。単一ノード + Naiveよりかは、だいぶ早くなりました。
わかったこと 
-
やっぱり分散でクエリーを処理するようになると早い。GoRoutineで並列処理もできそう
- 512次元 検索空間に20万の特徴量データが存在する場合
- 単一ノードにおける検索時間(Naive): 160msec~220msec
- 3ノードにおける検索時間(Naive): 60msec~100msec
- 512次元 検索空間に20万の特徴量データが存在する場合
-
GoRoutine使うと、マルチCPUで処理できそうな予感

- 512次元 検索空間に20万の特徴量データが存在する場合
- 単一ノードにおける検索時間(Naive): 160msec~220msec
- 単一ノードにおける検索時間(GoRoutine n=2): 80msec~130msec
- 512次元 検索空間に20万の特徴量データが存在する場合
-
今回の試験用環境では、目標性能には全然届かなかった

- 今回の目標 → 1億の特徴量データから50msecで厳密近傍を見つける
- 512次元 20万の特徴量データの場合、3ノードで分散させて30msec~90msecのクエリー処理時間がかかる
- 仮に、1億の特徴量があった場合、特徴量の検索空間は今回と比較して500倍
- 今のレスポンスタイムで良ければ500倍のクラスター規模があれば、目標達成できるかも
- 1500台のインスタンスを用意すれば目標達成できるかも
次回までの宿題
-
Datadog APMをちゃんと使いこなす
- 何がボトルネックになっているのか、もっと見えるかできるように。
- Spans,Metadataを適切に設定すると、リクエストタイムに加えて関数単位で処理時間が分解できる模様
- Ref: Trace View
-
より詳細なパフォーマンステストの実施
- インスタンスサイズ(CPU数、メモリ数)、次元数、検索空間の大きさ(特徴量の数)を変えながらやる
- 特徴量の検索時間に関わらず、特徴量のWrite系クエリーも対象にして調べる
-
パフォーマンスのボトルネックになりそうな所の仮説を洗い出す
-
多重コネクション・クエリーの同時実行について考える (クライアントは複数台あると思うので)
最後に
今回、ラフに色々試してみました。ちょっくら特徴量検索エンジンを作ってみたいというのが正直の本音でしたが、自分自身色々勉強になりました![]()

上記は、アルゴリズムのパフォーマンスを改善するシーンにおいてよく社内で話題になる呟きです。最初に呟かれてから既に2年以上が経過しますが、パフォーマンス改善の基本原理としてよく社内で話題になっています。最初からむやみに高速化しまくるのではなく、一旦ナイーブに実装し、そこから科学的にボトルネックと向き合いつつ、多角的なKAIZENでアプローチしようみたいな気持ちが込められているんだと勝手に解釈しています![]() 。これから社内外のメンバーとディスカッションしつつ、現実的なコストで目標性能まで達成できるようにちょくちょく頑張っていこうと思います
。これから社内外のメンバーとディスカッションしつつ、現実的なコストで目標性能まで達成できるようにちょくちょく頑張っていこうと思います![]()
ありがとうございました。