導入
今回紹介する内容は、
ゲーム画面をOCRする その1
と似たような内容ですが、対象画像が多いため、
OCRはGoogleドライブではなく、Tesseractを使用します。
プリコネで、クランメンバーのキャラ所持状況を把握するために、
Googleスプレッドシートに入力などして貰うなどが考えられますが、
キャラ数が多いと入力が手間になります。
これを解消するためにPythonとTesseractでプログラムを試作しましたが、
そのノウハウの共有になります。
プログラムが完成版ではないため、コードは部分的な記載です。
手順としては、
- スマホでキャラ動画撮影
- Pythonで動画を画像に分解
- Python/Tesseractで画像解析
- 所持キャラ一覧作成
を行います。
動画自体はこのようなものを想定します。
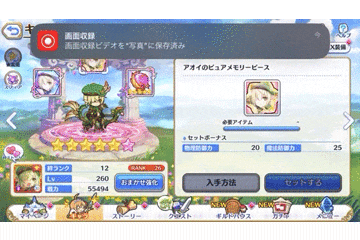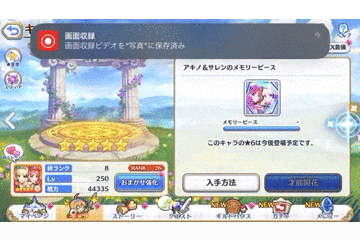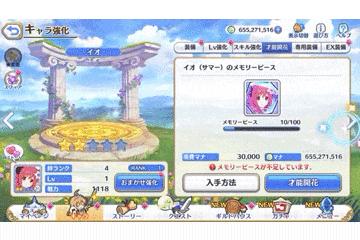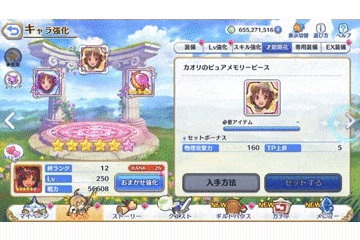
ゲームの仕様上、ページめくりボタンを連打しても、
ページ抜けなく次ページになります。
それぞれのキャラ情報が一瞬しか写っていませんが、
動画をフレームごとに画像として分解するため、
一瞬でも写っていれば十分です。
課題
- 動画から画像を取得するので、解像度が低いかつ画質が悪く、OCR時に支障がでます
- スマホの機種によって、対象項目の位置が変わります
- スマホの機種によって、色が変わります
スマホの機種ごとに様々な動画が作成されるため、
それらに対応できるようにしなければなりませんが、
どのような動画になるかの予測や、
ネットで公開されているような情報でもないため、
所持していない機種への個別対応は不可能です。
そのため、画像を調整し、ある程度同じ条件になるようにします。
動画から画像取得
cv2#VideoCaptureで動画をフレーム単位(秒間30か60コマ)で画像にできます。
想定している動画が60秒未満、それの秒間60コマで、
360枚以下の画像数になりますが、
メモリを圧迫するほどでもないため、
ファイル書き出しは不要です。
動画が長い場合や、秒間のコマ数が多い場合、
総画像数が多くなるため、
ファイルに書き出した方が良い場合もあります。
画像加工
画像をこのままでもOCRをすることができますが、
「様々なスマホから作成される動画」に対応するためには、
画像加工し、どの動画からでも同じような画像になるよう加工します。
余白の削除

Pixel6a(Android)で作成した動画の1コマです。
画面左右に黒い余白があります。
iPhoneの動画では余白がないので、
これを検知、削除します。
threshold = 100
maxval = 255
image_threshold = cv2.threshold(image, threshold, maxval, cv.THRESH_BINARY)

閾値で黒い余白と内側の境界を分け、
PIL#image#crop
で、黒い余白を切り落とします。
[Pixel6a(黒い余白を切り落とし後)]
左右の黒い余白が消えています。
トリミング
[iPad mini4]
端末により画面解像度も異なりますが、機種ごとに縦横比も異なります。
OCRするための座標が機種ごとに違ってしまうため、
画面比率を合わせます。
画面の構成が、画面中央から16:9が基準になっているようなので、
画面中央から、横か縦を基準に16:9で収まりが良い方を計算して採用します。
[Pixel6a(黒い余白を切り落とし、トリミング後)]
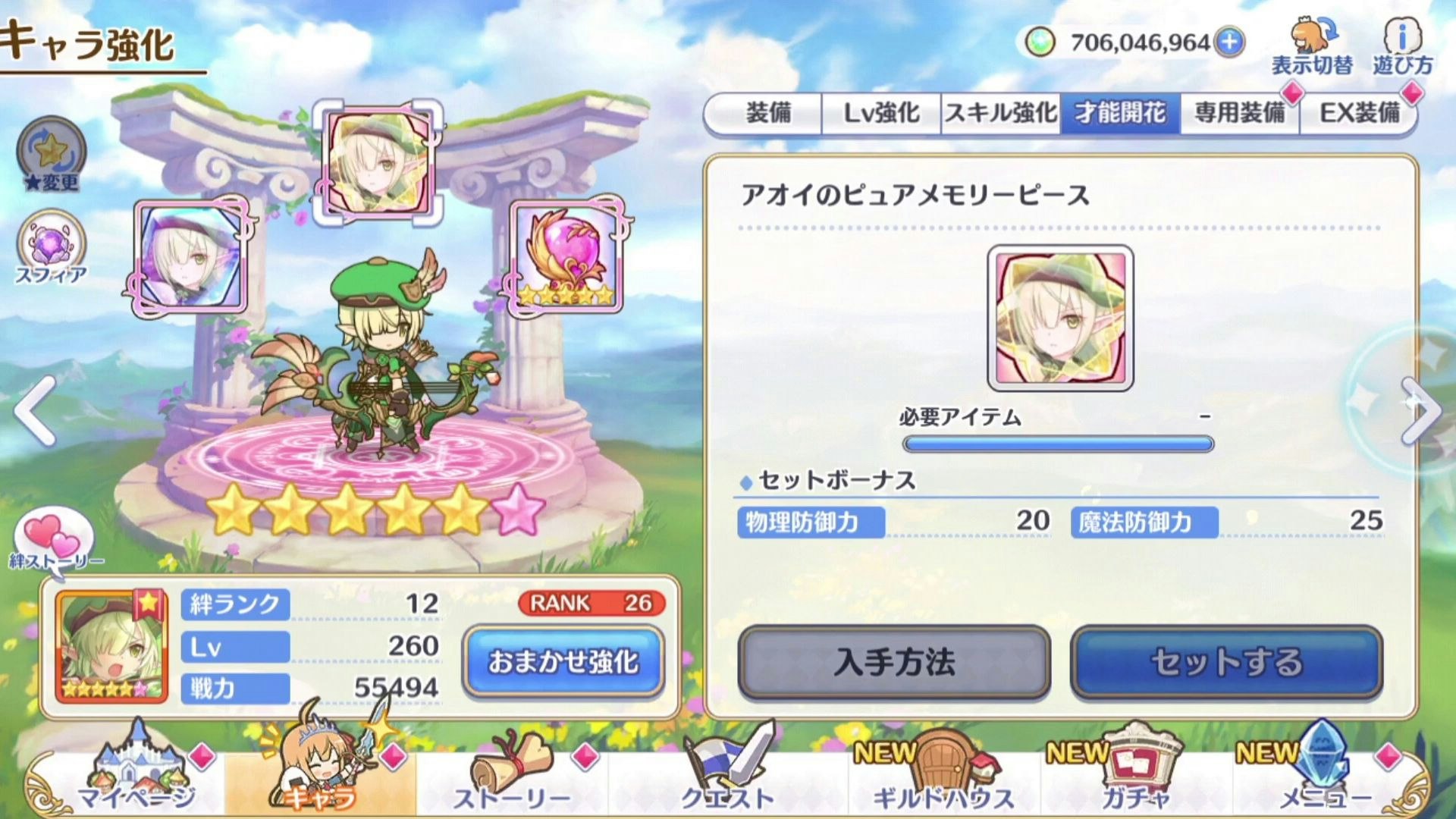
Pixel6aでは、短辺が1080のため、
1920x1080(16:9)の画像がトリミングにより取得できます。
iPadのような横長でない端末からも、
iPhoneSE2のような画面サイズが小さい端末からも、
16:9の画像が取得できます。
上下反転
iPhone/iPadの動画からの画像は、上下逆になっている場合があります。
[iPhoneSE2]
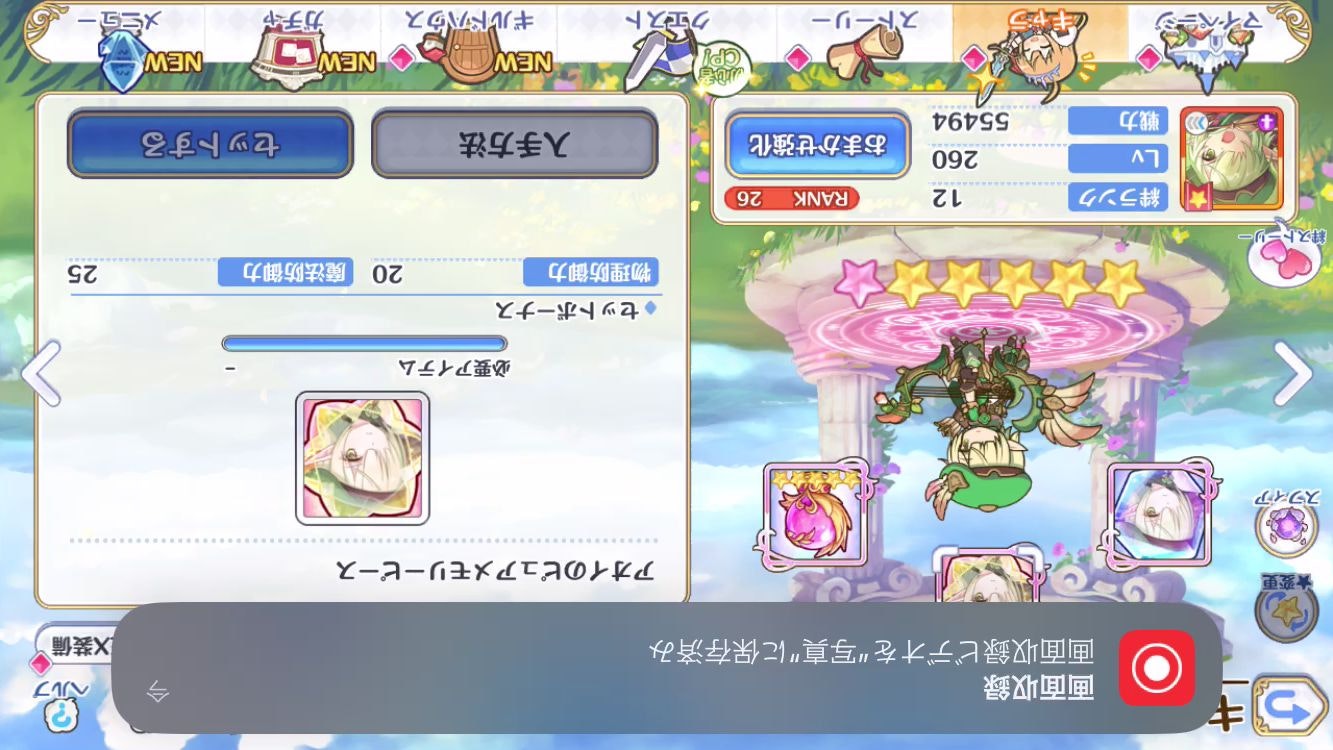
これは、上下逆にすれば対応できますが、
元から正常な場合や、Androidからの動画では問題ないため、
上下逆であることを見分ける必要があります。
今回は、上下が正常な画像を基準に「絆ランク」ラベルがあるXY座標を直接指定し、
「絆ランク」ラベルの左側辺りが水色であるかを判定基準としました。
上下逆なら水色以外となる想定です。


import cv2
images = [動画から取得した画像群]
if not 青色か(images[0]):
images = list(map(lambda image: cv2.rotate(image, cv.ROTATE_180), images))
上下逆にするには、このようなコードになりました。
XY座標のスケーリング補正
XY座標指定してのトリミングは、画面解像度が異なると位置がズレます。
それを補正するため、スケーリングを考慮します。
1920x1080での座標は「X:243,Y:782」としましたが、
iPhoneSE2での画像は、1333×750のため、
スケーリングは、約0.694(750/1080)で、
座標は、「X:168,Y:542」のように補正します。
色の指定
指定座標から水色が取れるか取れないかを判定基準としますが、
端末によって、取得される色が異なります。
端末でブルーカットやナイトモードのように
色味が変わるようなフィルタが使われているような場合も、
色が変わってしまいます。
フィルタはグレースケールフィルタなど、
対策してもキリがないため諦め、
端末ごとの色のみ判定することにしました。
color = image[0][0]
r = color[2]
g = color[1]
b = color[0]
ret = 80 <= red <= 130 and 130 <= green <= 170 and 200 <= blue <= 255
RGBそれぞれで大きく判定基準の幅を持ち、
青っぽい〜うすい青色ぐらいの幅にしました。
色の幅が大きいですが、
幅を取らないと複数端末に対応できません。
iPhone/ホームボタンなしのサイズ補正
[iPhone XS Max(トリミング、上下反転後)]
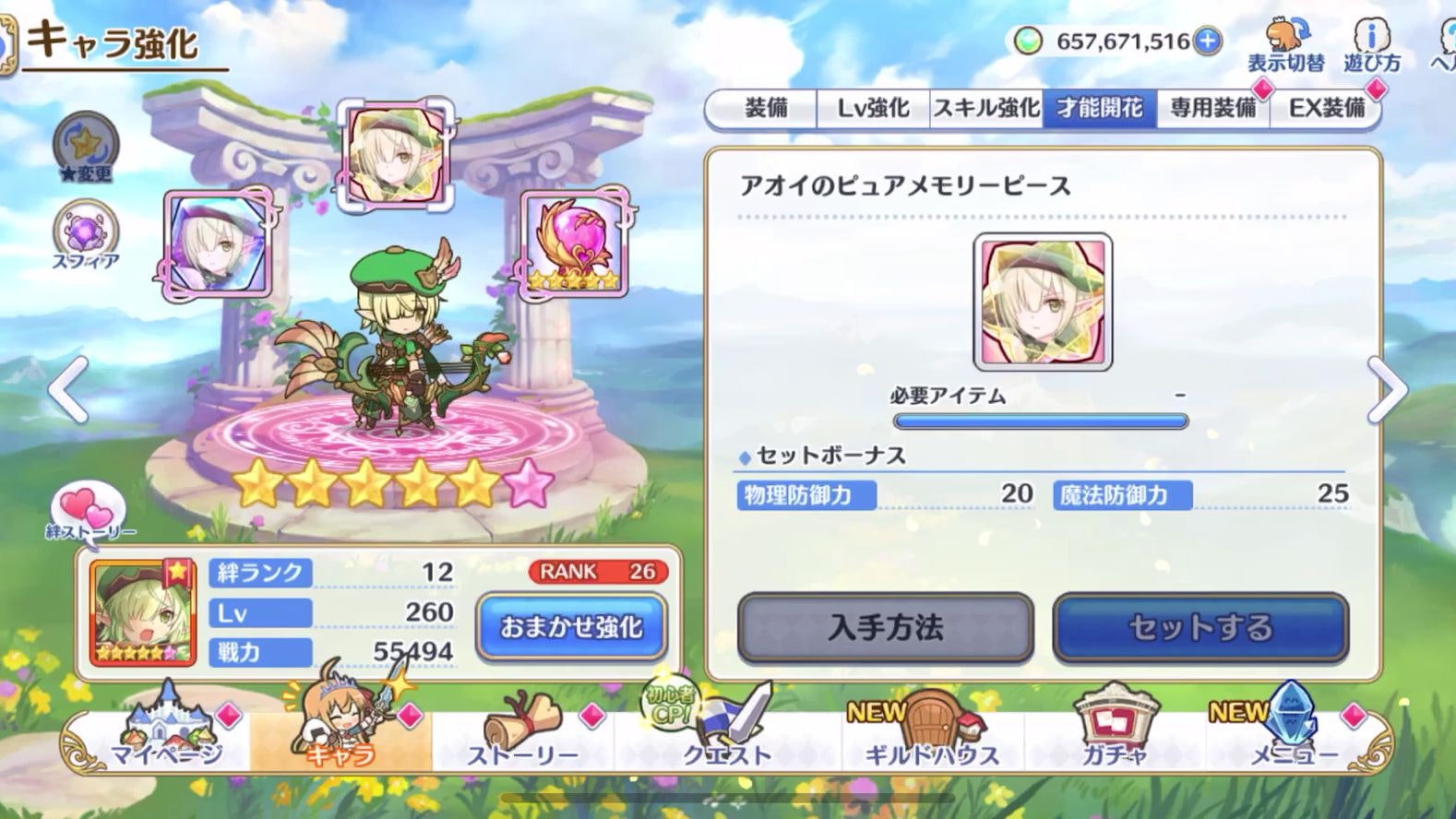
iPhone X以降のホームボタンがないiPhoneで、
画面下部に隙間ができます。
これをトリミングするため、
下部を47px削りました。
そして縦横比を16:9にするため、
左右を41pxずつ削りました。
「iPad/ホームボタンなし」で必要な補正値は違っているかもしれません。
この補正有無も、
「絆ランク」の左側辺りが水色であるかを判定基準としました。
[iPhone XS Max(トリミング、上下反転後、ホームボタンなしのサイズ補正後)]
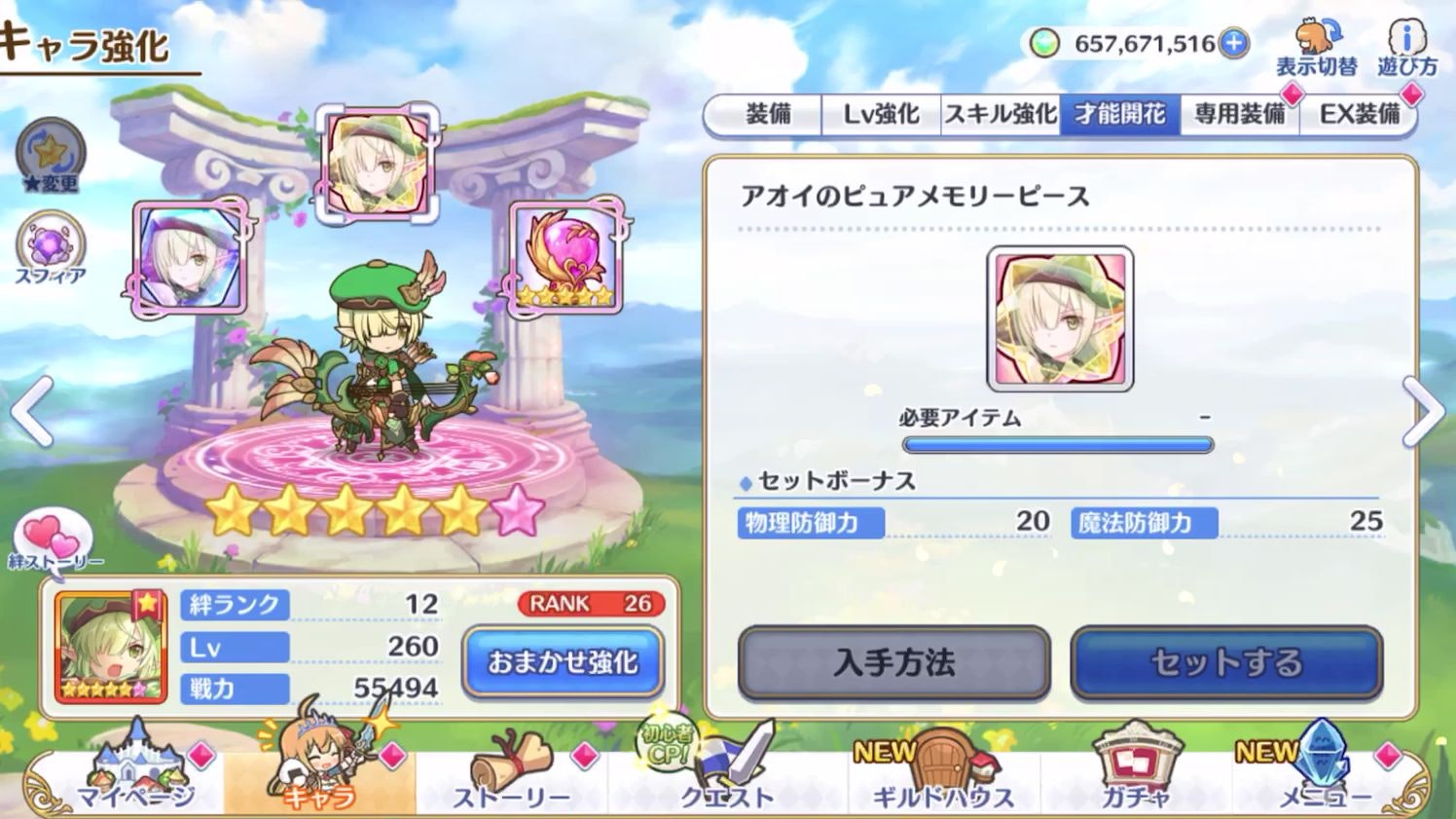
補正後は、画面下部、左右の隙間が無くなります。
不要画像の除去
1分=60秒の動画から秒60コマで360枚の画像が取得されますが、
動画の撮影終了操作など、不要な画像がありますので、
これを取り除きます。
この補正有無も、
「絆ランク」の左側辺りが水色であるかを判定基準としました。
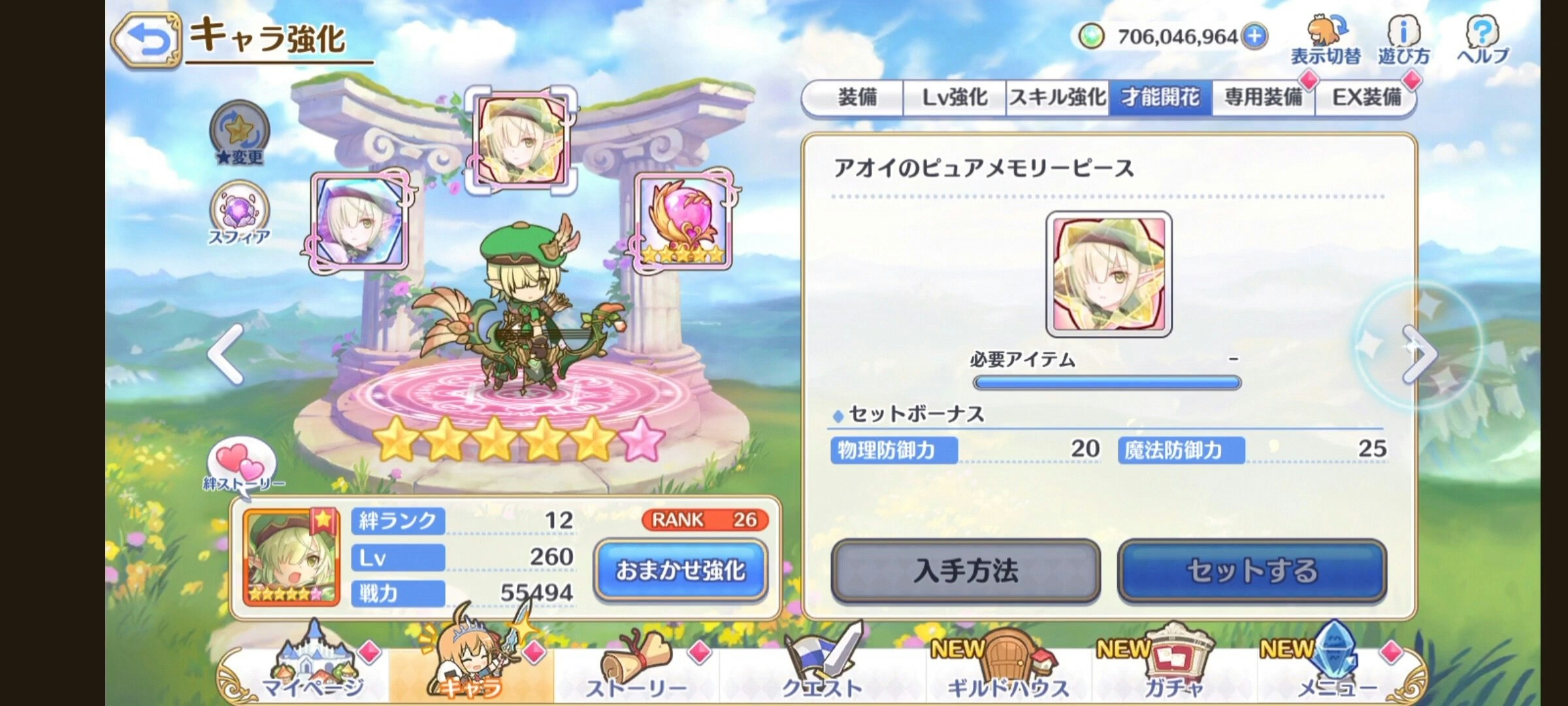
画像からのキャラデータ取得
「才能開花」タブからは、
- キャラ名
- 星
- ランク
- 絆ランク
- Lv
- 戦力
これらが参照できますが、
キャラ名、星だけを対象とします。
理由としては、
- 星の情報だけあれば、キャラの所持有無が分かる
- 星以外は、動画から作成した画像だと解像度が悪く、誤検知が多い
- 星以外は、更新頻度が高く、いつでも上げやすいため、把握する必要がない
- 戦力は、ペコ画像が重なっているため、人が見ても数値が読み取れない
などがあり、現段階では抽出する労力の割にメリットがないため諦めました。
キャラ名の取得
画像から切り出し位置を指定し、キャラ名画像を作成します。
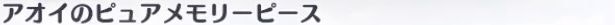 

キャラ名画像からTesseractで文字列を抽出すると
「アオ イ の ピュ アメ モリ ー ピ ピース」
のような文字列が取得されます。
文字列を加工し、キャラ名を取得します。
- 半角スペースを除去
- mojimojiで半角を全角に変換
- 「の」の検出精度が高いため、「の」より前をキャラ名とする
文字列を加工すると、キャラ名っぽい文字列になりますが、
微妙に怪しいキャラ名も混ざります。
| 誤 | 正 |
|---|---|
| コニ(聖学宗) | ユニ(聖学祭) |
| ミフスユ(作業用) | ミフユ(作業服) |
| コユキ(オーエド) | ユキ(オーエド) |
| レイ(プブプリンセス) | レイ(プリンセス) |
- 画像解像度が低く、文字も小さいため、画数が多い漢字が間違いやすい
- カタカナの「コ」「ユ」など似てるものを誤検知しやすい
- 文字数があってないことがある
常に一定の間違え方なら対処しやすいですが、
動画によって、間違え方も異なるため、
特定文字や特定のキャラ名を対処するようなやり方では対処できません。
キャラ名の誤検知対策として、
事前に正確な全キャラ名を辞書として用意し、
画像から検知した文字列と、辞書で総当たりをし、
辞書のキャラ名に一番近いものを正解としました。
文字列同士の近似値を計るのには、
difflibを使用しました。
ratioの閾値は0.5と低くしています。
短いキャラ名で誤字があると、
ratioが0.55ぐらいになるため、
その対策になります。
import difflib
CHARACTER_DICTIONARY = "character.dic" # キャラ名辞書
name = “画像からTesseractで抽出した文字列”
characters = read_character_dictionary()
name_candidate = ""
ratio_max = 0
for character in characters:
ratio = difflib.SequenceMatcher(None, name, character).ratio()
if ratio == 1:
# 完全一致
name_candidate = character
break
if ratio >= 0.5 and ratio > ratio_max:
# 部分一致
ratio_max = ratio
name_candidate = character
if not name_candidate == "":
name = name_candidate
def read_character_dictionary():
f = open(CHARACTER_DICTIONARY, "r", encoding="UTF-8")
data = f.read()
f.close()
return data.split("\n")
重複キャラ名の排他
動画で撮影しているため、
同じキャラ名を1秒表示しているだけでも、
同じキャラ名の画像が60回処理対象となってしまうため、
キャラデータを取得済みの場合は、
配列にキャラ名を追加し、
次画像で再度同じキャラ名が出てきた際に、
処理をスキップするようにします。
Tesseract
日本語、数字のみのTesseractの設定値です。
検出対象の文字列が、一行にまとまっているため、
tesseract_layoutは6にしています。
# 日本語を対象
builder = pyocr.builders.TextBuilder(tesseract_layout=6)
lang = "JPN"
ランクやレベルなどを検出対象とする場合は、
以下の設定になります。
# 数字のみを対象
builder = pyocr.builders.TextBuilder(tesseract_layout=6)
builder.tesseract_configs.append("-c")
builder.tesseract_configs.append("tessedit_char_whitelist=\"0123456789\"")
lang = “ENG”
学習データ
Tesseractの学習データとして、
フォントファイルがあると精度が高くなるようです。
プリコネで使われているフォントは、
ハミング Std E
らしいです。
有料フォントのため、誰でもできる訳ではありませんが、
フォントファイルが入手可能な人は、
フォントファイルとjTessBoxEditorの組み合わせで、
学習データを作成できるようです。
学習データ(例:aaa.traineddata)を
tessdataディレクトリに配置後のTesseractの設定値です。
# 学習データ
builder = pyocr.builders.TextBuilder(tesseract_layout=6)
lang = “aaa”
星の取得
星は、1-6個と違いはありますが、
表示のパターンは3種類です。
| 星 | 画像 |
|---|---|
| 星が最大6 |  |
| 星が最大5 |  |
| 星が最大6で現在5 |  |
星の判定には、まずは、画像を12分割します。

分割した番号の12から1の順に判定していき、
条件に該当したら星が確定します。
| 番号 | 条件 | 星 |
|---|---|---|
| 12 | 赤星 | 星6 |
| 10 | 黄星か星変更中で青星の場合 | 星5 |
| 8 | 黄星 | 星4 |
| 6 | 黄星 | 星3 |
| 4 | 黄星 | 星2 |
| 2 | 黄星 | 星1 |
| - | いずれにも該当しない場合は「まとめてセット」 | 星5 |
星の色は、上下反転と同じように色を判定しますが、
端末により色が異なるため、幅を設けて検出させます。
その他
動画の共有
動画ファイルの置き場所として、
Google Driveでフォルダを共有し、
そこにアップロードして貰うのが楽そうです。
SNSを経由すると、ファイルサイズに制限があり、
画質劣化に繋がります。
まとめ
今回の用途では、クラン内の情報共有専用とニッチなものかつ、
各所での手法が最適とは限りませんが、
共有したノウハウが何かの役に立てれば幸いです。
試作したコードは、将来的に公開を考えていますが、
現段階では、極一部のiPhone/iPad/Android対応と範囲が狭く、
幅広くスマホ/タブレットも対応できるよう、
情報、ノウハウを溜めている段階になります。