※この記事は、ゲームのチート行為を目的としていません。
また、人が手で行えること以上は行えず、ゲーム内データの解析や改造も行なっていません。
(追記)この記事の続きがあります。
ゲーム画面をOCRする その2
導入
ゲーム内からは参照できるが、
テキストデータとして欲しい文字列、数値があった場合、
量が少なければ、手打ちで賄えますが、
量があった場合は手間がかかり、
日々繰り返すような場合、負担になり続けます。
これをOCRによって軽減しようという試みです。
(ゲーム以外にも、書類など定型があるものに応用できると思われます。)
対象
この記事では、
「プリンセスコネクト!Re:Dive」の
「クランバトルのバトルログ」を対象とします。
月末のクランバトルにて数百行分のバトルログが貯まりますが、
テキストデータとしてエクスポートする手段がないため、
バトルログを活用するためには、
手打ちでスプレッドシートへのデータ入力が必須となります。
素材取得
素材となる画像として、下記リンク内の画像を使います。
https://priconne-redive.jp/news/update/14173/
実際には、ゲームでログを表示し、
3行ごとにスクリーンショットを撮ることになります。
スクリーンショットを撮る際は、
1行目は、なるべく同じ位置になるようにして撮影します。
試しにOCRしてみる
安く簡単に画像をOCRするため、
Googleドライブを利用します。
OCRを試すだけなら簡単で、
Googleドライブに画像をアップロード後、
PCのブラウザからGooglドライブにアクセス。
画像を右クリックし、「アプリで開く > Googleドキュメント」を選択すると、
画像とOCRされたテキストで
構成されたドキュメントが開かれます。
画像からOCRされたテキスト
クランバトル バトルログ アップデート
OOOOOOOOOOバトルログ
一覧
)
(絞り込みし
1 体目 | 2体目 | 3体目 | 4体目 | 5体目)(ダメージ)(降順 クランメンバーのバトルと、マイログに保存したバトルのログが確認できます。
(全て
バトルログの お気に入り登録も可能!
6000000
お気に入り
「バトルTL
(トレーニングの1段階目与えたダメージ] とソウタ [日時 2021/07/26 12:33
ゴブリンクレット
レポート
6000000
お気に入り
REINTL
本戦
1段階目与えたダメージ ユウキ 日時 2021/07/26 13:37
「ゴブリングレート
「レポート
6000000
お気に入り
「バトルTL
模擬戦1段階目与えたダメージ] なダイチ 日 時 2021/07/26 13:01
・メンバーの本戦 ・自分のマイログ ・チャット投稿バトル が表示されます
ゴブリングレート
日時 20210726 13:01
レポート
閉じる マイページ45ストーリークラフトギルドパラス
欲しい情報としては、
- ボス名
- n段階目
- ダメージ値
- プレーヤー名
- 日時
ですが、
OCRにより正確にテキスト化されたものもありますが、
誤ったテキストや、
不要なテキストも多く、
このままテキストを使用するには、
手間がかかってしまいます。
OCRの精度を上げるための画像加工
OCRの精度を上げるため、
画像をトリミングやマスク加工し、
OCR時、余計なテキストを出力しないようにします。
画像最適化
非破壊(推奨)
非破壊の画像最適化ツールを使用し、
画像のファイルサイズを軽減します。
大量の画像ファイルを扱う場合、
アップロード時間の短縮、各種処理で効率が改善されます。
 

元画像 :365KB
画像最適化後:339KB
素材がWebに掲載されている画像のため、
すでに十分な最適化済みだったようです。
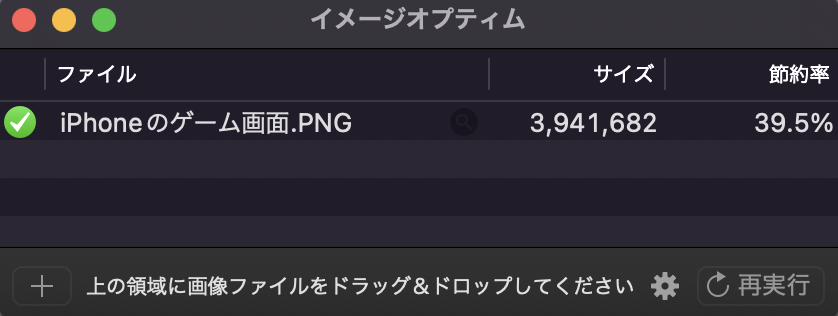
実際は、スクリーンショット撮影した画像が対象となるため、
ファイルサイズがMB単位になり、
画像最適化の効果は大きくなります。

iPhoneからのスクリーンショットでは、
6.5MBのファイルサイズが、3.9MBになりました。
破壊的(非推奨)
画像のファイルサイズを小さくするだけなら、
破壊的な画像最適化やJPEG形式への変換もありますが、
画質が劣化し、OCR精度が落ちる可能性があるため、
適していません。
画像最適化ツール
ImageOptim(Mac)
https://imageoptim.com/mac
偽アプリがあるらしいので注意
PNGGauntlet(Windows)
トリミング
素材画像をトリミングします。
OCRが背景や模様から余計なテキストを検出しなくなります。
また、画像自体のファイルサイズも小さくなります。
トリミングの処理サンプル(Python)
Pythonでのコードと、処理サンプルです。
import cv2 as cv
sourceImagePath = './002.png'
# 画像と画像サイズを取得
sourceImage = cv.imread(sourceImagePath)
height, width, channel = sourceImage.shape
# トリミング後の画像サイズを調整しやすいように100分割
newHeight = height // 100
newWidth = width // 100
# トリミング時の座標
positionXStart = newWidth * 11
positionXEnd = newWidth * 54
positionYStart = newHeight * 39
positionYEnd = newHeight * 91
# [開始Y座標:終了Y座標, 開始X座標:終了X座標]
trimmedImage = sourceImage[positionYStart : positionYEnd,
positionXStart : positionXEnd]
cv.imwrite('./trimming.png', trimmedImage)

元画像 :365KB
画像最適化後:339KB
トリミング後:161KB
画像最適化により、ファイルサイズも小さくなりました。
トリミング後のOCR結果
トリミング画像でのOCR結果です。
トレーニングの1段階目与えたダメージ6000000 とソウタ [日時 2021/07/26 12:33
ゴブリングレートン
与えたダメージ
6000000
本戦1段階目
ユウキ ゴブリングレートする 日時 2021/07/26 13:37
与えたダメージ
6000000
模擬戦1段階目 とダイチ |日時 2021/07/26 13:01
ゴブリングレートS
素材のままOCRした結果に比べ、
余計なテキストが減りました。
マスキング
素材は解像度が低く問題になっていませんが、
iPhoneで撮影したゲーム画像だと、
解像度が高く、キャラアイコンの上に表示されているレベルが、
不要な文字列や数値として検出されていました。
トリミングでは解決しないため、
マスキングをして、OCRの精度を上げます。
画像サイズは、素材画像と同じサイズのまま、
OCRされて欲しい箇所を透過した画像を作成します。
(GIMPでは、範囲選択後に「編集>消去」で透過にする)

目的のテキストの上下左右は大きめに透過します。
- スクリーンショット作成時に、スクロール位置の問題でずれる可能性がある
- 対象となるテキストの文字数が変わる
- OCR時にどこからどこまでが文章かを、余白で見ている(たぶん)
マスキング用の画像も画像最適化しておきます。
マスキングの処理サンプル(Python)
import cv2 as cv
sourceImagePath = './002.png'
maskImagePath = './004.png'
# 画像と画像サイズを取得
sourceImage = cv.imread(sourceImagePath)
height, width, channel = sourceImage.shape
maskImage = cv.imread(maskImagePath)
# 画像をグレー画像に変換
sourceImage = cv.cvtColor(sourceImage, cv.COLOR_BGR2GRAY)
maskImage = cv.cvtColor(maskImage, cv.COLOR_BGR2GRAY)
# トリミング後の画像サイズを調整しやすいように100分割
newHeight = height // 100
newWidth = width // 100
# トリミング時の座標
positionXStart = newWidth * 11
positionXEnd = newWidth * 54
positionYStart = newHeight * 39
positionYEnd = newHeight * 91
# [開始Y座標:終了Y座標, 開始X座標:終了X座標]
sourceImage = sourceImage[positionYStart : positionYEnd,
positionXStart : positionXEnd]
maskImage = maskImage[positionYStart : positionYEnd,
positionXStart : positionXEnd]
# マスキング
maskedImage = cv.absdiff(sourceImage, maskImage)
cv.imwrite('./masking.png', maskedImage)

元画像 :365KB
画像最適化後:339KB
トリミング後:161KB
マスキング後:15KB
ファイルサイズが、元画像に比べ、かなり小さくなりました。
このサイズなら、Googleドライブにアップロードしても、
アップロード時間、ストレージサイズ共に、負荷が減ります。
マスキング後のOCR結果
6000000
1段階目 ソウタ |2021/07/26 12:33
ゴブリンクルート
6000000
1段階目 ユウキ
2021/07/26 13:37
ゴブリングレートSE
6000000
1段階目 「ダイチ
|2021/07/26 13:01
ゴブリングレート
余計な記号や誤字が含まれていますが、
ほぼ目的のテキストになりました。
画像差分の抽出方法
マスキングのサンプルコードでは、
cv2#absdiff(素材画像, マスキング画像)
で画像差分を抽出していますが、
これは、素材画像のテキスト位置がマスキング画像に対して、
常に同じ場合に使用します。
素材画像を撮影時に、
スクロールの位置ずれなどにより、
多少のずれがある場合は、以下を使用します。
cv2#inpaint(素材画像, マスキング画像, 0, cv.INPAINT_NS)

まとめ
Python+TensorflowでのOCRも試してみましたが、
検出精度が悪く、特にひらがな/カタカナ/漢字がまともに検出できませんでした。
(設定や、学習をしてないのが原因かもしれません)
また、Arm系MacにTensorflowが対応していないため、
実行環境がIntel系MacかWindowsに制限されてしまいます。
GooglドライブでのOCRは、OCRに関する設定等はできませんが、
汎用性が高く、十分な精度を持ち、処理速度も高速です。
OCRが絶対的な精度ではないので、
OCR後のデータは、人の目で精査/補正を行う必要があり、
その辺りが残念な部分ではありますが、
それでも、全てを手打ちするよりかは労力が削減されます。
そんなGoogleドライブ/OCR+画像加工のOCR手法の紹介でした。