はじめに
DatabricksのAuto Loaderは、データがクラウドストレージに到着すると、それらをストリーミングソースとして自動的に処理する。Auto Loaderにはファイルの検出モードとしてディレクトリ一覧とファイル通知の2つのモードがサポートされている。ファイル通知モードはクラウドの中で提供されている他のサービスの上に構築されている。今回はこのファイル通知モードをAzure上で動作させる方法をここに記録する。
Azure上でのAuto Loaderのファイル通知モードの構成
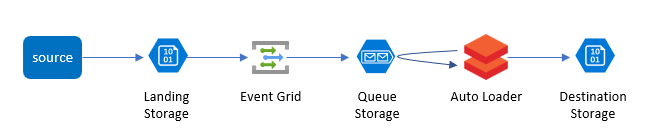
Azure上でAuto Loaderのファイル通知モードを構成すると、ファイルが到着したことを検知して配信するサブスクリプションサービスとしてAzure Event Gridが作成される。また、配信先のキューサービスとしてAzure Queue Storageが作成される (これは自分で作成してマニュアルで指定することも可能)。実際に構成されるイメージは下図の通り。Event GridとQueue StorageがLanding Storageに関連付けられて構成される。
Auto Loaderのファイル通知モードの構成方法
前述の通り、ファイル通知モードはいくつかのサービスに依存して動作するため、いくつかの準備が必要となるが、実際の構成はAuto Loaderを起動させたときに自動的に構成されるため、上の図のアーキテクチャの見た目とは違って方法は結構シンプル。
事前準備
Auto Loaderを実行する前に事前にデータが到着するストレージと書き出し先のストレージへのアクセスができるようにしておく。今回テスト用にどちらのストレージも同じADLS Gen2のファイルシステムに指定した。いろいろな方法があるが今回はサービスプリンシパルでのアクセスを構成した。
実際の設定方法は上記のドキュメントに書いてあるが、サービスプリンシパルの準備とシークレットを格納するKey Vaultができたら、以下のようにマウントする。
configs = {"fs.azure.account.auth.type": "OAuth",
"fs.azure.account.oauth.provider.type": "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider",
"fs.azure.account.oauth2.client.id": "{サービスプリンシパルのアプリケーションID}",
"fs.azure.account.oauth2.client.secret": dbutils.secrets.get(scope="{Databricksのスコープ名}",key="{KeyVaultに格納したシークレット名"),
"fs.azure.account.oauth2.client.endpoint": "https://login.microsoftonline.com/{Azure Active DirectoryのテナントID}/oauth2/token"}
# Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "abfss://{ファイルシステム}@{ストレージアカウント}.dfs.core.windows.net/",
mount_point = "{マウントポイント}",
extra_configs = configs)
Auto Loaderはいくつかのサービスを設定して動作させる必要があるので、サービスプリンシパルにはデータが到着するストレージに対していくつかの権限付与が必要となる。以下のドキュメントに従ってデータが到着するストレージへの共同作成者、ストレージキューデータ共同作成者のロールと、リソースグルーへのEventGrid EventSubscription共同作成者ロールを付与した。
https://docs.microsoft.com/ja-jp/azure/databricks/ingestion/auto-loader/file-detection-modes#permissions
サンプルデータの生成
今回のテスト用にAuto Loaderが取得するためのサンプルデータをストレージに吐き出すためのスクリプトを準備する。以下のスクリプトはこのチュートリアルで紹介されているものをそのままコピペしたもの。 path のところだけ、実際にファイルを書き出すストレージのPATH (上記でマウントしたところ+INPUTフォルダとして変更。
https://docs.microsoft.com/ja-jp/azure/databricks/ingestion/auto-loader/tutorial#--step-1-create-sample-data
import csv
import uuid
import random
import time
from pathlib import Path
count = 0
path = "/{マウントポイント}/AL/INPUT}"
Path(path).mkdir(parents=True, exist_ok=True)
while True:
row_list = [ ["id", "x_axis", "y_axis"],
[uuid.uuid4(), random.randint(-100, 100), random.randint(-100, 100)],
[uuid.uuid4(), random.randint(-100, 100), random.randint(-100, 100)],
[uuid.uuid4(), random.randint(-100, 100), random.randint(-100, 100)]
]
file_location = f'{path}/file_{count}.csv'
with open(file_location, 'w', newline='') as file:
writer = csv.writer(file)
writer.writerows(row_list)
file.close()
count += 1
dbutils.fs.mv(f'file:{file_location}', f'dbfs:{file_location}')
time.sleep(30)
print(f'New CSV file created at dbfs:{file_location}. Contents:')
with open(f'/dbfs{file_location}', 'r') as file:
reader = csv.reader(file, delimiter=' ')
for row in reader:
print(', '.join(row))
file.close()
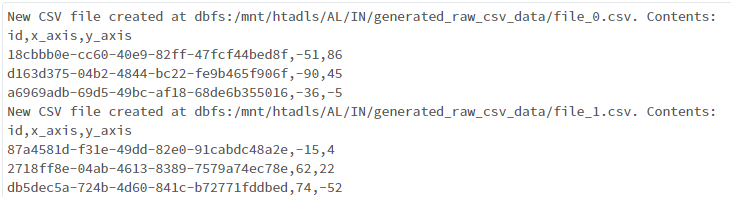
これを単独のノートブックとして実行したままにしておく。うまくデータが書かれている場合は以下のように表示される。
Auto Loaderの実行
Auto Loaderを実行するための各種ロケーションを指定する。
raw_data_location = "dbfs:/{マウントポイント}/AL/INPUT/generated_raw_csv_data"
target_delta_table_location = "dbfs:/{マウントポイント}/AL/OUTPUT/coordinates"
schema_location = "dbfs:/{マウントポイント}/AL/schema"
checkpoint_location = "dbfs:/{マウントポイント}/AL/checkpoint"
Auto Loaderを設定する。この設定では特にQueue Storageなどを設定していないので、自動的にデータが到着するストレージアカウントにEvent GridやQueue Storageが設定されるが、オプションとして、事前に作成したQueueストレージを指定することも可能。多くのオプションが提供されているのでこちらのリファレンスを参照すると良い。
stream = spark.readStream \
.format("cloudFiles") \
.option("cloudFiles.format", "csv") \
.option("header", "true") \
.option("cloudFiles.schemaLocation", schema_location) \
.option("cloudFiles.useNotifications", "true") \
.option("cloudFiles.subscriptionId", "{AzureサブスクリプションID}") \
.option("cloudFiles.tenantId", "{Azure Active DirectoryのテナントID}") \
.option("cloudFiles.clientId", "{サービスプリンシパルのアプリケーションID}") \
.option("cloudFiles.clientSecret", "{サービスプリンシパルのシークレット}") \
.option("cloudFiles.resourceGroup", "{データが到着するストレージのリソースグループ名}") \
.load(raw_data_location)
displayで読み取ったデータを表示する。このコマンドによって実際にストリーミングが起動する。
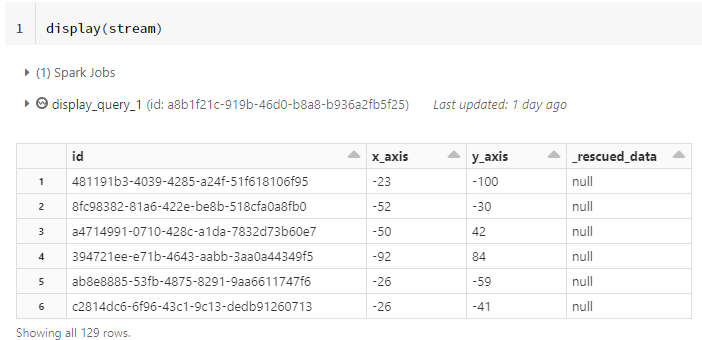
display(stream)
正常に動作すると以下のように実際に読み取ったデータが表示される。
今回はテスト目的なので、特にデータの変換などを行わずにそのままデータを書き出している。このコマンドも実際にストリーミングが起動する。
stream.writeStream \
.option("checkpointLocation", checkpoint_location) \
.start(target_delta_table_location)
ストレージの出力先のフォルダに以下のようにファイルが書き出されていれば成功。