はじめに
Apache Sparkはデータの高速な処理能力や、汎用性の高さから、昨今ではクラウドのPaaS型のデータ処理エンジンに搭載されるようになってきた。たとえばAzureのサービスでは従来からAzure HDInsightにPure 100% OSSのSparkが以前から搭載されている。Azure DatabricksはSparkのクラスター管理を大幅にクラウド側に寄せ、Notebookやジョブのインターフェース等を提供する形態も出てきて多くのユーザーに利用されているようである。また、2019年のMicrosoft Igniteで発表されたAzure Synapse Analyticsは従来のAzure SQL Data Warehouseに、Sparkエンジンを搭載してオンデマンドクエリ機能を提供するとの事。さらには、Azure Data Factory内にMapping Data Flowという機能があるが、GUIでデータのマッピング、結合、計算処理を定義し、それがSparkで実行されるという仕組みになっている。
このようにSparkはクラウドでの採用が増え、クラスター自体の管理から解放されて、Spark自体を意識せずに利用できる世界ができてきている。しかし裏側では結局Sparkが動いているのだから、やはりちゃんと理解しておきたいところである。ここではApache Sparkの再入門的な形で基本的なことをまとめていく。冒頭にAzureのいくつかのサービスを挙げているが、この一連の記事では特定のクラウドのサービスに特化せずにApache Sparkそのものを対象とする。トピックによって粒度がだいぶ異なるので、この記事は一度発行した後に必要に応じてブラッシュアップ・修正することを考えている。
Apache Spark Overview
Apache Sparkは公式サイトで紹介されているように、大規模なデータ処理のための統合分析エンジンである。特徴として主要なものは以下の通りである。
- 大規模なデータセットに対してバッチおよびストリーミングの両方のワークロードで高い性能を発揮できる。
- 高レベルのインターフェースを備えており、使いやすい。Java, Scala, Python, R, SQLでアプリケーション開発ができる。
- Spark Coreに加え、SQL, Spark Streaming, MLlib, GraphXといったライブラリを使用することで、多様なワークロードを実行することができる汎用的なデータ処理エンジンである。
- Hadoop, YARN, Mesos, Kubernetes, Standalone, クラウド等、いろいろなプラットフォームで動作させることができる。
 From: http://spark.apache.org/
From: http://spark.apache.org/
以下のAzure HDInsightのドキュメントに掲載されているMapReduceとの比較を示した図からわかるように、Sparkはデータをメモリに読み込み、キャッシュする。そしてジョブのステップ間でメモリ内でデータを共有して処理を行っていくことで高速化している。
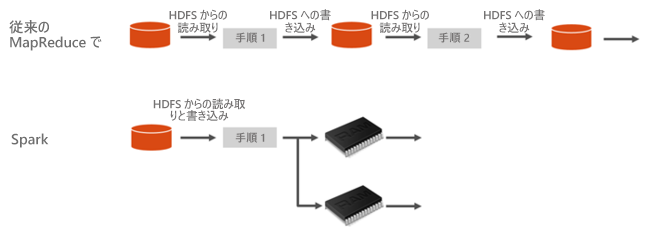
From: https://docs.microsoft.com/ja-jp/azure/hdinsight/spark/apache-spark-overview
Spark Cluster Architecture Overview
Apache Sparkは大規模なデータ処理のための統合分析エンジンであり、実態は分散処理システムとなる。通常分散処理システムはアプリケーションの各パーツがそれぞれ同時並列に複数のコンピューターで実行されて処理を行うため、複雑な仕組みであるが、Sparkは高レベルのAPIとフレームワークにより、その複雑さを意識せずに利用することができる設計である。しかし、実際にSparkを利用する場合、Sparkが動作するコンピューターを構成しSparkをセットアップする必要があるし、プロダクション環境での運用やトラブルシューティング、アプリケーションを開発するうえで、処理の複雑さ、データのサイズ、並列化度合い、性能などを考えると、Sparkの基本的な仕組みを理解しておいたほうがよさそうである。
アプリケーション実行時の流れ
以下のダイアグラムはSpark公式ドキュメントに掲載されている、SparkのCluster Modeの構成である。
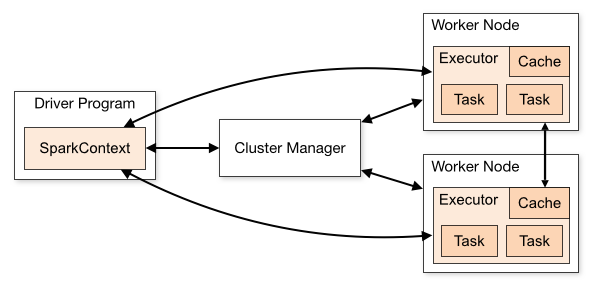
From: http://spark.apache.org/docs/latest/cluster-overview.html
SparkアプリケーションはDriverとExecutorで構成されている。アプリケーションはDriverプログラムでSparkContextオブジェクトを生成し、そのSparkContextがSparkアプリケーション全体を通して状態を管理して、様々なAPIをユーザーに提供する。Cluster Modeにおいては、アプリケーションがsubmitされてSparkContextが生成されると、SparkContextはCluster Managerに処理を実行するためのコンピュートリソースをリクエストする。Cluster Managerはリソースを割り当て、Worker NodeでExecutorを起動する。SparkがExecutorリソースを得たら、アプリケーションコード (JARとかPythonとか) をExecutorに送って、taskを実行する。
RDDの場合は以下のようにしてSparkContextを生成する。
val conf = new SparkConf().setAppName(appName).setMaster(master)
new SparkContext(conf)
DataFrameやDataset APIの場合は以下のようにSparkSessionを生成する。
val spark = SparkSession.builder.appName("Simple Application").getOrCreate()
Local Mode & Cluster Mode
上記の説明でCluster Modeと書いたが、アプリケーションをSubmitする際に、spark-submitで--masterパラメータで指定することができ、どのように動作させるかを指定することができる。
| Mode | Description |
|---|---|
| Local | Sparkアプリケーションを実行するにあたってLocal ModeとCluster Modeというのがある。Local Modeは名前の通り、ローカルコンピュータ上でSparkアプリケーションを実行するモードである。 |
| Cluster | Cluster ModeはCluster Managerを使用してクラスター上でアプリケーションを実行するモード。この場合にはCluster ManagerのMasterとなるサービスを指定する必要がある。 |
Driver & Executor
SparkアプリケーションはDriverとExecutorというもので構成されているが、それぞれが強調して動作することでアプリケーションが実行される仕組みになっている。
Driverには以下のような役割がある。
- Spark Shellのエントリーポイント
- SparkContextが作られる場所
- RDDを実行グラフに翻訳する
- 実行グラフをステージに分割する
- 実行のタスクをスケジュールして制御する
- RDDとパーティションのメタデータを保存
- Spark WebUIを提供
Executorには以下のような役割がある。
- JVM HeapまたはDiskのキャッシュにデータを保存
- 外部データソースからデータを読み込む
- データを書き出す
- すべてのデータ処理を実行する
Cluster Manager
Cluster Managerはクラスターのリソースなどを管理するためのフレームワークである。現在Sparkは以下のCluster Managerとともに動作させることができる。
| Cluster Manager | Description |
|---|---|
| Standalone | Spark自身が持っているシンプルなCluster Manager |
| Apache Mesos | 汎用的なCluster Manager |
| YARN | Hadoop 2.xから追加されてクラスターリソース管理の仕組み |
| Kubernetes | コンテナーアプリをデプロイ、したり管理したりする仕組み*今はまだ実験的機能 |
(例)Cluster ManagerにYARNを選択した場合の構成
Cluster Managerの中でも、現在はYARNが使われることが多いと思われるが、YARNの場合の動作の概要についてまとめておく。
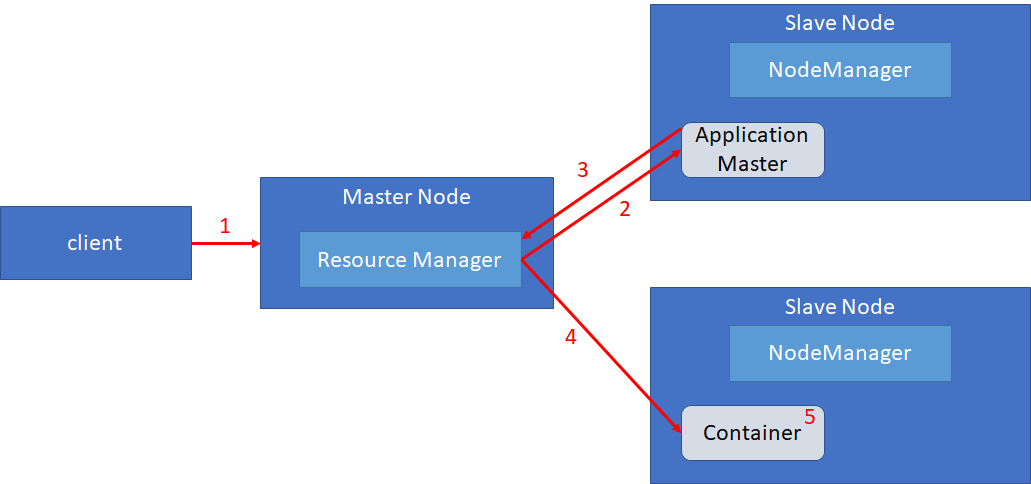
- Clientによってアプリケーションを登録すると、Cluster ManagerであるYARNのResource Managerは、Slave Node上のNode Managerと調整してApplication Masterを起動する。
- Application MasterはResource Managerに対してアプリケーションを実行するためのコンテナ (Executorのためのリソース) を要求する。
- Resource ManagerはSlave Node上のNode Managerにコンテナを要求し、Node Managerはコンテナをアサイン、Executorを起動する
- 起動したExecutorでアプリケーションを実行する。
ここでDriverはSparkジョブの実行方法によって配置が異なる。Clientモードの場合はClient上でDriverプログラムが実行され、Clusterモードの場合はApplication Master上でDriverプログラムが実行される。これはspark-submitの--deploy-modeオプションで指定することができる。
また、アプリケーション実行時はDriverとExecutorは直接通信を行い状態を管理したり、必要に応じてデータをDriverに集約したりする。
※将来的には Spark 2.3 以降、実験的に対応を介したKubernetesが重要な位置づけになっていくと思われる。
データセットとSpark API
現在Sparkで使われている、RDD, DataFrame, Datasetについて本セクションにてまとめる。開発者の生産性や安全性を求めてRDD → DataFrame → DatasetとAPIが進化している。本記事ではScalaコードをベースにしているが、PythonやRは現在はDatasetを利用できないことに注意。
RDD (Resilient Distributed Data)
RDDはSparkのための耐障害性分散データセットで、パーティションに区切られて分散されたJVMオブジェクトの中に保存されるデータコレクションである。RDDはExecutorのノードに分散配置されていて、それにより並列処理ができるようになっている。データを変換するとき、その変換の記録を行うようにしており、すべての変換を常に再現できるようにデータリネージを提供している。データ変換操作は遅延評価される。これはDAG SchedulerがTask Schedulerにsubmitする前にジョブのStageとTaskを最適化するためにこのような仕組みになっている。
例えば下記のようにテキストデータを読み込むとRDDが生成される。
val fruits = spark.textFile("fruits.txt")
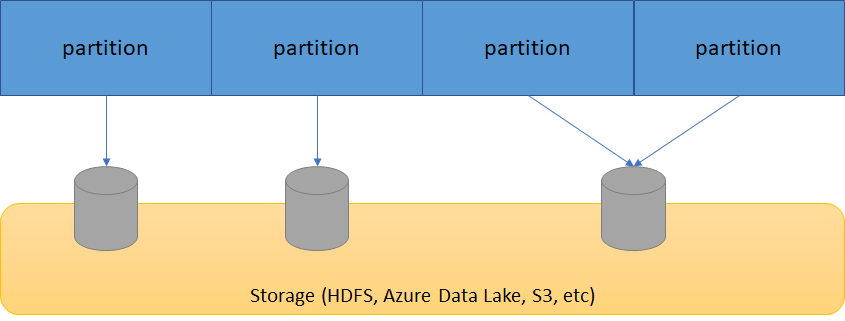
RDDは以下のように、パーティション単位で分割され、ノードをまたがり分散配置される。この図では3つのworkerノードに分散配置されており、これらのworkerノードごとに並列でデータを処理することができることを意味する。パーティションは分散する単位になるため、パーティション数の調整をすることはデータを効率的に処理するために重要となる。
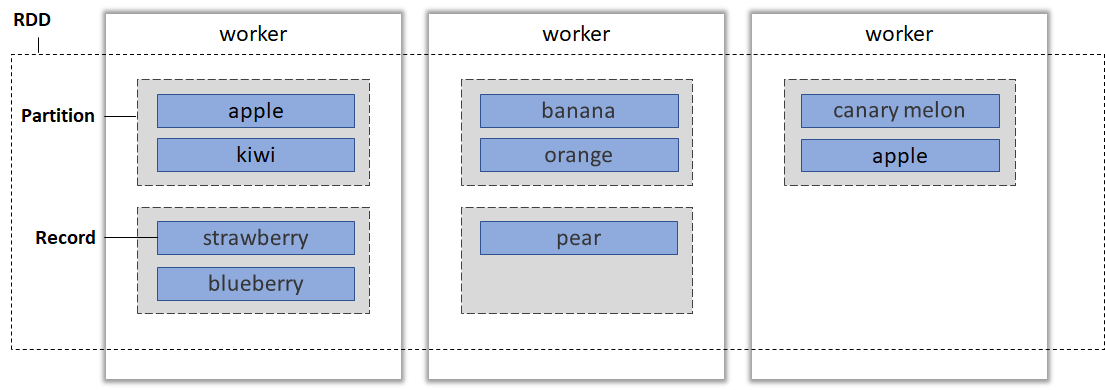
StorageとPartition
実際のデータはRDDのパーティションとしてストレージに分散配置されている。パーティションごとに別々のサーバに保存されており、データを処理するときはパーティション単位で処理される。各Executorは自分にアサインされたパーティションの処理を実行する。これによって並列分散処理が行われる仕組みとなっている。
DAG
SparkのジョブはRDDのリネージから有行非循環グラフ(Directed Acyclic Graph)が作成される。DAG schedulerがDAGをstageに変換してステージの各パーティションを1つずつのtaskに変換する。この時、RDDの変換(Transform)とアクション(Action)を分けることによって、データの不要なシャッフルをできるだけ回避するようにしたりしてクエリを最適化する。
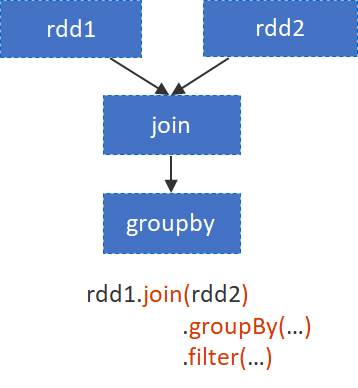
RDDの操作
RDDには変換(Transformation)とアクション(Action)の2つのタイプの操作がある。
Transformationsは遅延評価となり、Actionsは実際の処理を引き起こす。このデータ処理操作ではいつでも分散データをメモリかディスクに永続化できる。
val file = spark.textFile("hdfs://...")
val errors = file.filter(line => line.contains("ERROR"))
// errorsをキャッシュ
errors.cache()
// errorsをカウント
errors.count()
// errorsにWebが含まれているのをカウント
errors.filter(line => line.contains("Web")).count()
// Errorを含むものをを文字列の配列として取得
errors.filter(line => line.contains("Error")).collect()
上記のコードだと以下のように分類される。
Transformation : textFile(), filter()
Action : count(), collect()
- Cache() はmethod
DataFrame
DataFrameはApache Spark 1.0でSchemaRDDという名前で実験的な機能として導入されて、Spark 1.3の時にDataFrameとして改名されて登場した。DataFrameもRDDと同じように各ノードに分散配置されたデータのコレクションであるが、DataFrameは名前付きのカラムで構成されている。DataFrameはRDBMSにおけるテーブルに似ており、このようにデータを構造化することによってSpark SQLを使ってクエリを実行したりできる。
DataFrame APIではラムダ式ではなく、メソッドを使うことができる。
val df = spark.read.json("examples/src/main/resources/people.json")
df.select($"name", $"age")
.filter($"age" > 21)
Spark SQLによってクエリを実行することもできる。
SELECT * FROM people WHERE age > 21
PythonでRDDを使う場合、ScalaやJavaと比べると速度が遅いことがあるが、DataFrameの場合は、オプティマイザによって最適化されたコードを生成して実行するモデルになるので、RDDの際のPythonとJVMのコミュニケーションのオーバーヘッドようなパフォーマンス低下の原因を改善させることができる。
Catalyst Optimizer
Spark SQLのコアになるのがCatalyst Optimizer。Sparkのエンジンが論理的な実行プランを作成して、そのあとにOptimizerによって物理プランを作成し、コストオプティマイザがプランを選択し、最適化されたコードを生成する。
Catalyst Optimizerは今後簡単に新しい最適化技術を追加できるようにしたり、ディベロッパーがオプティマイザを拡張できるように設計されている。
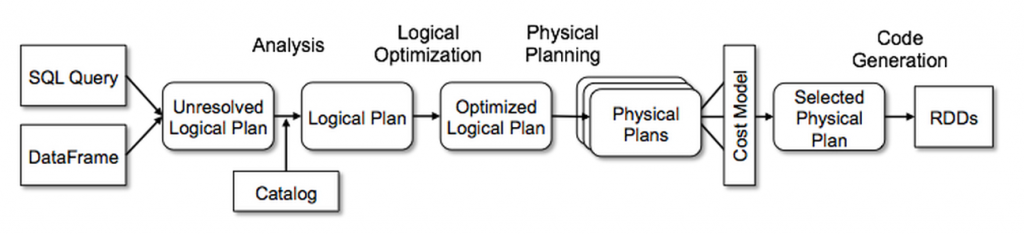
From: https://databricks.com/glossary/catalyst-optimizer
Dataset
DatasetはSpark 2.0で導入されたRDDの強力な型、オブジェクトの変換機能などのメリットとSpark SQLの最適化された実行エンジンのパフォーマンスのメリットを併せ持つ。 Dataset APIを使用すると、ユーザーはJavaクラスをDataFrame内のレコードに割り当て、Java ArrayListやScala Seqと同様に、型付きオブジェクトのコレクションとして操作できる。Dataset使用可能なAPIは型安全。つまり、最初に入力したクラスとは別のクラスであるデータセットのオブジェクトを誤って表示することはできる。残念ながらPythonやRでは今のところ使用できない。2016年にDataFrameとDatasetをDataset APIとして統合し、その中でUntyped API (DataFrame), Typed API (Dataset)という風に2つの種類のAPIを提供している。
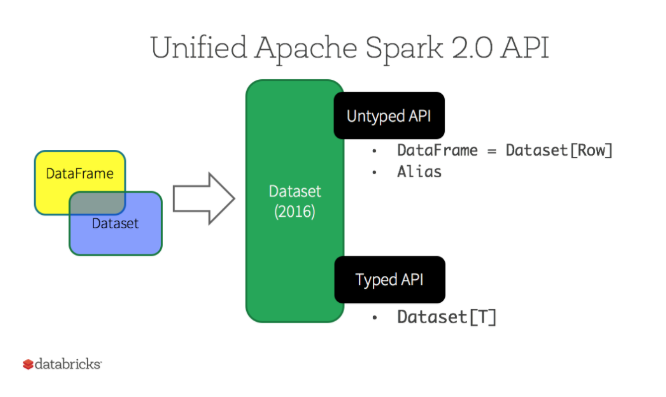
From: https://databricks.com/glossary/what-are-datasets
Datasetの作成と操作
DatasetはJavaやKyroではなく独自のエンコーダーを使ってシリアライズしてネットワーク転送したりする。
case class Person(name: String, age: Long)
// classを型として指定してDatasetを作成
val caseClassDS = Seq(Person("Andy", 32), Person("Justin", 19)).toDS()
// ファイル読み込み時にclassを指定することによってDataFrameがDatasetに変換される
val path = "examples/src/main/resources/people.json"
val peopleDS = spark.read.json(path).as[Person]
RDD同様の操作が可能となる。下記はMap操作を実行する例。
// SeqからDatasetを作成しmap操作
val primitiveDS = Seq(1, 2, 3).toDS()
primitiveDS.map(_ + 1).collect()
DataFrameと同じように利用することも可能。
peopleDS.select($"name", $"age" + 1).filter($"age" > 21).show()
+----+---------+
|name|(age + 1)|
+----+---------+
|Andy| 33|
+----+---------+
Spark SQLも実行可能。
// Spark SQLの実行
peopleDS.createOrReplaceTempView("people")
val sqlDS = spark.sql("SELECT * FROM people")
sqlDS.show()
+------+---+
| name|age|
+------+---+
| Andy| 32|
|Justin| 19|
+------+---+
Sparkアプリケーションの実行
Sparkアプリケーションを実際に実行するためのいくつかのスクリプトが用意されている。これらの使い方といくつかの実行モードについて理解しておく。
また、Sparkのジョブが実行されるときのプロセスについてもここにまとめておく。
spark-shellとspark-submit
Sparkアプリケーションを実行するためにspark-sql, spark-shell, spark-submitといった実行スクリプトがある。
spark-shellはSparkの命令をコマンドラインから受け付け、インタラクティブに操作することができる。APIを学ぶときやデータを分析するときなどに使いやすい。spark-shell (Scala), pyspark (Python)等がある。
spark-submitはアプリケーションを起動するために使用されるスクリプト。アプリケーションはコードや依存関係を含むJARをパッケージする必要がある。Pythonの場合は依存する複数のファイルを引数で指定するか、.zipや.eggにパッケージングして実行する。
spark-submitの使い方について公式ドキュメントに詳しく書いてあるが、メモのためにこちらにもまとめておく。
./bin/spark-submit \
--class <main-class> \
--master <master-url> \
--deploy-mode <deploy-mode> \
--executor-memory <Memory size> \
--num-executors <num>
--conf <key>=<value> \
... # other options
<application-jar> \
[application-arguments]
オプションの一部
| オプション | 説明 |
|---|---|
| --class | アプリケーションのメインクラス名 (e.g. org.apache.spark.examples.SparkPi) |
| --master | クラスターのMasterのURL (e.g. spark://23.195.26.187:7077) ※下の表を参照 |
| --deploy-mode | Driverをワーカーノードにデプロイ(cluster)するか、クライアント自身にデプロイ(client)するか (default: client) |
| --executor-memory | Executorに割り当てるメモリを指定 |
| num-executors | Executor数を指定 |
| --conf | key=value形式で任意のSparkのConfigを指定 |
| application-jar | アプリケーションとすべての依存関係を含むJARのPATHを指定。このURLはクラスター内全体から見えるものである必要がある。たとえばすべてのノードから見えるhdfs://やfile://のPATH |
| application-arguments | アプリケーションのメインクラスのメインメソッドに渡す引数をここに指定 |
Master URLの指定
| Master URL | 説明 |
|---|---|
| local | ローカルマシンで1ワーカースレッドで実行する。並列処理にはならない |
| local[K] | ローカルマシンでK個のワーカースレッドで実行する。マシンのコア数に合わせてセットするのが理想的 |
| local[K,F] | ローカルマシンでK個のワーカースレッドとF回のタスクの失敗のリトライ(spark.task.maxFailures)設定で実行する |
| local[*] | ローカルマシンでマシンの論理コア分のワーカースレッド数で実行する |
| local[*,F] | ローカルマシンでマシンの論理コア分のワーカースレッド数でF回のタスクの失敗のリトライ(spark.task.maxFailures)設定で実行する |
| spark://HOST:PORT | SparkのスタンドアロンクラスターのMasterに接続する。ポート番号を省略すると7077がデフォルトで使用される |
| spark://HOST1:PORT1,HOST2:PORT2 | SparkのスタンドアロンクラスターのMasterに接続する。ZooKeeperとともにセットアップされたスタンバイMasterとともに設定することで高可用性構成となる。ポート番号を省略すると7077がデフォルトで使用される |
| mesos://HOST:PORT | Mesosクラスターに接続する。ポート番号を省略すると5050がデフォルトで使用される。またはZooKeeperを使用したMesosクラスターをでは"mesos://zk://...."と指定する。"--deploy-mode cluster"でジョブをSubmitする場合は"HOST:PORT"はMesosClusterDispatcherに接続されるように設定する必要がある |
| yarn | ClientまたはClusterモード(--deploy-mode)でYARNクラスターに接続する。クラスターの場所はHADOOP_CONF_DIR値かYARN_CONF_DIR値をもとにしてセットされる |
| k8s://HOST:PORT | ClusterモードでKubernetesクラスターに接続する。Clientモードは現在は非サポートだが、将来的にサポートされるはず。HOSTとPORTはKubernetesのAPI Serverを指す。デフォルトではTLSを使用して接続する |
Sparkジョブ単位の概念
SparkジョブをSubmitするとプログラムをStageに分割されて実行される。
Application -> Jobs -> Stages -> Tasksのツリー構造。
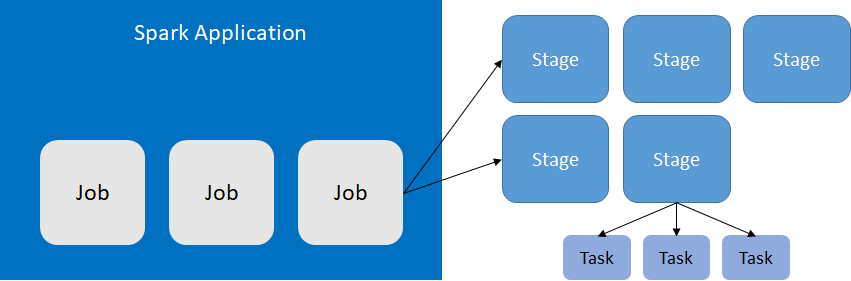
| 単位 | 説明 |
|---|---|
| Application | Submitする単位。spark-submitで実行する単位 |
| Job | 独立した実行アクション。collectやsaveなどのSparkアクションに応じて遅延評価されて構成される単位 |
| Stage | 最後にキャッシュされたアクションまたはシャッフルイベントをベースとしたジョブの分割単位 |
| Task | 最小実行単位 |
ジョブスケジューリングのプロセス
Sparkジョブが実行されたあとのジョブスケジューリングのプロセスは以下の通り。
全体の流れ
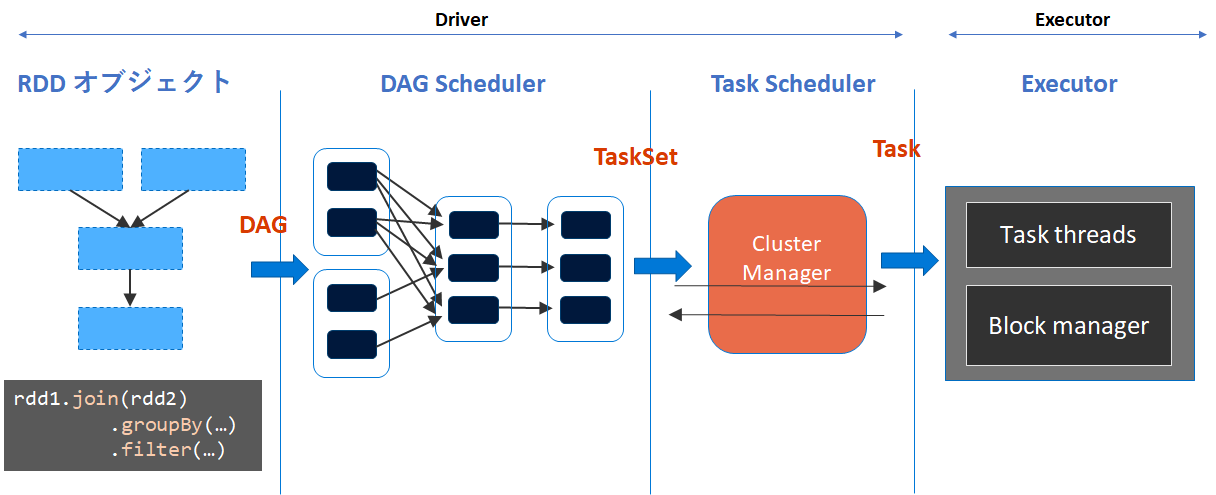
From: https://www.slideshare.net/michiard/introduction-to-spark-internals
- SparkアプリケーションがSubmitされると、DriverでTransformationの遅延評価によってRDDオブジェクトの操作の論理的な実行プランとしてDAGを構築する。
- Actionによってジョブが起動された後、DAGSchedulerがDAGをTaskのStageに変換しTaskSetとしてまとめる。
- TaskSchedulerによって個別のタスクを起動を開始する。失敗したりうまくいっていないTaskはリトライされる。TaskSetはシリアライズ化されてWorkerノードに送信する
- ExecutorでTaskを実際に実行する。Block managerはデータのブロックを保存したり提供したりする。
ExecutorがTaskを受け取った後のジョブの実行
- ExecutorがTaskを受信したら、シリアライズ化されているので、これを復元する。
- Taskを実行して結果を得る。
- 結果サイズが小さい場合は直接Driverに結果を送信できるが、大きい場合はBlock manager管理下のメモリまたはディスクに保存しておき、後でDriverが取得しにくる。
※spark.rpc.message.maxSizeで定義されている数値が直接Driverに結果を送信できるサイズっぽい
※こちらの記事にかなり詳細な内容が記載されている。
https://qiita.com/kimutansk/items/3496e5b139959e362f02
Storage & Cache
SparkではRAM, JavaのOff-Heap, Diskなど、様々なタイプのストレージを使用する。データがどんな時にどのようにどこに保存されて使用されるのかをこのセクションにまとめる。メモリをよく使う仕組みのため、今後のセクションの SparkのMemory ともよく関係する。
Storageモジュールの仕事
- 外部データソースへのアクセス: HDFS, Local Disk, RAM, Network越しのデータアクセス
- RDDのキャッシュ
主なストレージコンポーネント
- Cache Manager : キャッシュを実行する(実際の実行にはBlock Managerを使う)
- Block Manager : 分散 key/value ストア (LinkedHashMap)
- Shuffle dataやcacheされたRDDを提供する
- Storage level (RAM, Java Off-Heap, DISK)
- Memoryが不十分な場合はDISKにSpillする
- 必要時にはデータのレプリケーションをハンドルする
Cacheの仕事
- 繰り返し処理される大きすぎないデータがキャッシュされるのに向いている
- rdd.cache()を実行すればキャッシュ可能。Sparkが内部的に生成するRDDはキャッシュできない
- SparkContextがキャッシュされたRDDをトラッキングする
- Sparkがキャッシュすべきかを判断する場合はTaskがRDDの最初のレコードを取得したタイミングで確認する
Block manager
- Workerノード1つに1つ存在するWrite OnceなKey/Valueストア
- シャッフルデータをキャッシュされたRDDを保存して提供する
- ストレージレベル(Memory, Java Off-Heap, DISK)を管理する
- データのレプリケーションを管理する
例えばシャッフルデータに関しては下記のように、aggregateByKey(...)によってShuffledRDDが実行されるときに、Block Managerに生成されたRDDが保存される。

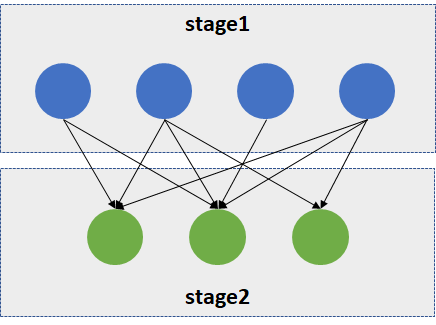
Shuffle
groupByKey(), reduceByKey(), sortByKey()などを実行する場合にShuffleが発生する。
以下のようにMapReduceと同じコンセプトとなっている。
- ローカルでの中間結果を保存
- 中間データのパーティショニング
- シリアライズ/デシリアライズ
- ネットワーク越しのデータ取得
Many to Manyのトラフィックが発生する。SparkではTaskのセットが他のTaskのセットにデータを送信する形になる。
SparkのMemory
Sparkはデータをメモリ内において動作するので、メモリのリソース管理は非常に重要である。このセクションではSparkのメモリがどのように使用されているのかをまとめておきたい。
ExecutorのMemory
Cluster ManagerにYARNを使用する場合、YARNのコンテナで使用するメモリを制御することになる。以下はYARN使用時におけるExecutorのメモリの概要を示している。
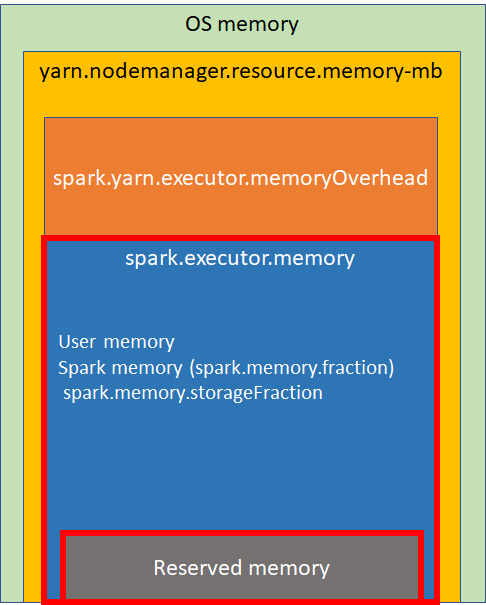
Memoryの内訳
Reserved Memory
システムによって予約されているメモリで、300MBで固定。直接使うことはできないが、多くのSparkの内部オブジェクトを格納する。
ここにRESERVED_SYSTEM_MEMORY_BYTESとしてハードコーディングされている。
https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/memory/UnifiedMemoryManager.scala#L198
spark.executor.memory
spark.memory.fractionの値によって内部のSpark MemoryとUser Memoryの割合を設定する。
Spark MemoryはSparkによって管理されるメモリプールで、spark.memory.storageFractionによってさらにStorage MemoryとExecution Memoryの2つの領域に分割される。Storage MemoryはSparkのキャッシュデータや、シリアライズされたデータを展開するためのテンポラリのデータや、ブロードキャスト変数が保存される。BlockManagerのmemoryStoreはここに収まる。Execution MemoryはSparkのタスクを実行する際に必要なオブジェクトを保存する。メモリが足りたい場合はディスクにデータが書かれるようになっている。これらはデフォルトで半々(0.5)に設定されているが、足りない時にはお互いに融通し合う。
User Memoryはユーザーに完全に使用をゆだねられているメモリプールで、RDDの変換で使用されるデータ構造を保存できる。Spark Memoryの不足時にはUser Memoryで補うことができる。このメモリ境界を超えるとOOMが発生する可能性がある。
spark.yarn.executor.memoryOverhead
Executorごとに割り当てられるoff-Heapサイズ。VMのオーバーヘッド等などのためのメモリ。これはExecutorサイズとともに大きくなる傾向がある(通常6~10%)。
※Spark2.3.0以降spark.yarn.executor.memoryOverheadではなくspark.executor.memoryOverheadが使われているようだ。
yarn.nodemanager.resource.memory-mb
各ノードマネージャが利用可能なメモリ総量
Memory Overhead
Executorのメモリには下記のようにいろいろなメモリオーバーヘッドがある。
- OSや他のサービスが使用するメモリ
- YARNのメモリオーバーヘッド (384MBまたはExecutorの10%) *YARN使用時
- Spark metadata (shuffles, long-running-jobs)
- Scala & Java typeオーバーヘッド
- Executor内のReserved memory (300MB)
Executorへのリソース割り当て
WorkerノードのリソースとExecutorに割り当てるリソースの設計によってパフォーマンスに影響を与えることができる。静的には主に下記の3つのパラメータによって調整する。Sparkジョブ実行時に指定することも可能。
-
spark.executor.instances: Executorの数を静的に指定。spark.dynamicAllocation.enabledを指定した場合、初期値がこの値になる -
spark.executor.cores: Executorに割り当てるコア数を指定 -
spark.executor.memory: Executorに割り当てるメモリを指定
これらを指定すると下図のようになイメージとなる。
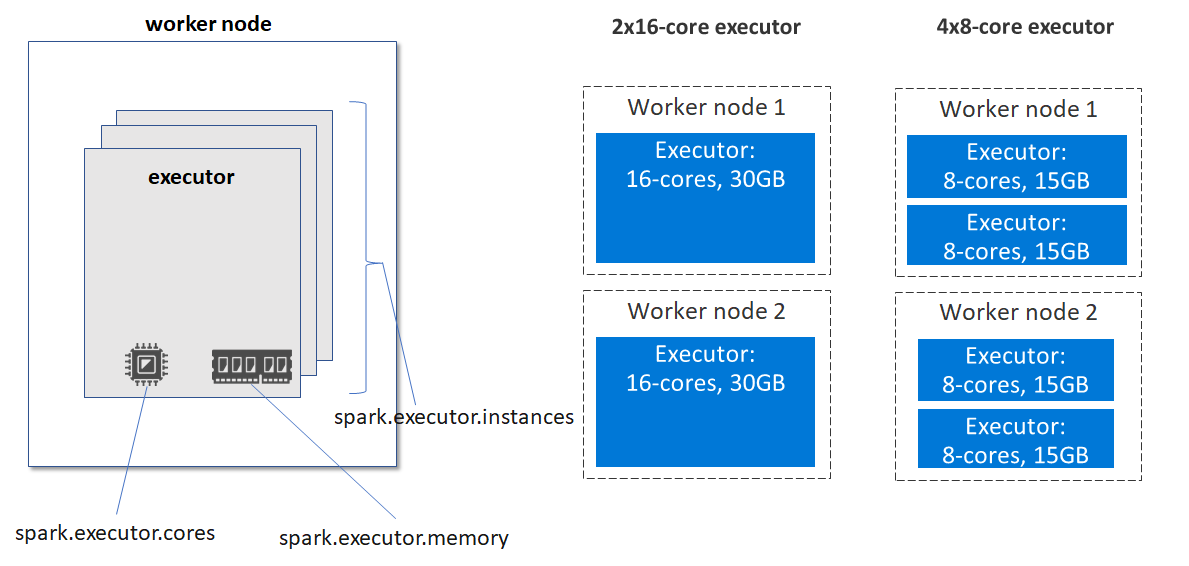
Executor数を増やすとExecutor間の通信オーバーヘッドが増えるが、1 Executorに割り当てるメモリ量が減りGCオーバーヘッドが減る。
Spark SQL
準備中
外部のデータベース、構造化ファイル、Hive テーブル等、様々なデータソースにクエリを実行することができる
- Python, Scala and Java からも実行できる
- Spark structured streaming もサポート
- Catalyst optimizer と Tungsten execution をオプティマイザとして採用
Streaming
準備中
参考にした資料
全般
http://spark.apache.org/docs/latest/index.html
https://qiita.com/kiszk/items/53ec7f0419d71790d9af
アプリケーション実行関連
https://github.com/JerryLead/SparkInternals
https://databricks.com/glossary/what-are-datasets
https://qiita.com/kimutansk/items/3496e5b139959e362f02
https://www.slideshare.net/michiard/introduction-to-spark-internals
Memory関連
https://www.slideshare.net/laclefyoshi/apache-spark-70339069
https://qiita.com/giwa/items/f284a83d8215024360c5
https://0x0fff.com/spark-memory-management/
https://docs.microsoft.com/ja-jp/azure/hdinsight/spark/apache-spark-perf
書籍
LearningSpark, 2nd Edition
詳解 Apache Spark
入門 PySpark - PythonとJupyterで活用するSpark 2エコシステム