ここでの述べられているメモリモデルはSpark 1.6+ではdeprecatedとなっています。新しいメモリモデルは、 UnifiedMemoryManager をベースにしていて厳密なexecution と storage memory の境界がありません。
最近、私はSparkのアーキテクチャに関しての質問にStackOverflowで解答していました。それらの質問はインターネット上におけるSparkのアーキテクチャに対するよい説明がないのが原因であるように見えました。オフィシャルのガイドでさえ、詳細について書かれていなく、よいダイアグラムももちろんありません。”Learning Spark”のような幾つかの本や公式のワークショップの資料に関しても同じことがいえます。
この記事では上記の問題に対する解答と Spark のアーキテクチャに対するガイドと Spark アーキテクチャに対する疑問の幾つかの頻出する質問に対する網羅的なガイドを提供します。この記事は、全くの初心者を対象にしていません。RDD と DAG のような Spark のプログラミングの抽象化に対する話はこの記事では扱いません。ですがそれらの前提知識が必要になります。
これはSpark Architectureシリーズの最初の記事です。2本目のShuffleに関する記事はここ
翻訳にあります。
http://spark.apache.org/docs/1.3.0/cluster-overview.html:
まずはオフィシャルサイトにある画像から見ていきましょう。

見てわかる通り、"executor", "task", "cache", "Worker Node"などの単語が見て取れます。少し前にSparkのコンセプトについて学び始めましたが、インターネットで公開されているSparkのアーキテクチャに関する図はこれだけでした。そして今もその現状は変わっていません。個人的には、このような状態はとても好きではありません。なぜなら、それは重要な情報を見せないか、適切な方法で見せていないからです。
まずは基本的なことから始めていきましょう。すべての Spark のプロセスは、クラスタかローカルマシンで JVM のプロセスとして動きます。JVM のプロセスに関しては、そのヒープサイズを -Xmx -Xms で設定することができます。なぜこの JVM のプロセスはヒープメモリを使い、必要とするのでしょうか?これが Spark の JVM のヒープのメモリアロケーションです。
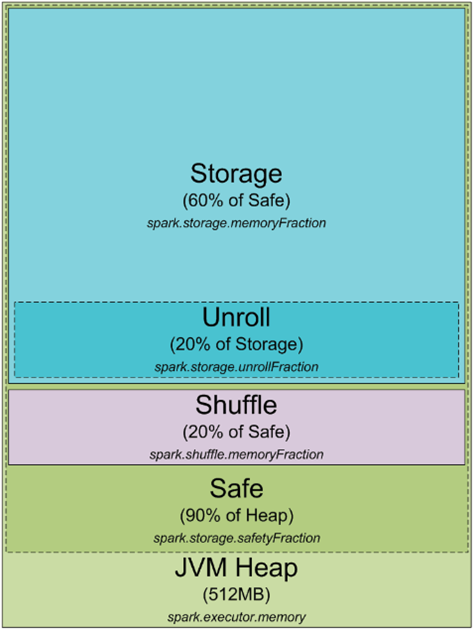
デフォルトとして、Spark は 512 MB の JVM のヒープを使います。Safe side を使い、 OOM error を避けるために90%のヒープのみを使います。この割合は spark.storage.safetyFraction パラメータで調整できます。Spark はインメモリのツールであると聞いているとおり、Spark はいくつかのデータをメモリに保存します。もしあなたが、この記事を読んだなら、Spark はインメモリだけのツールではないということがわかるでしょう。Spark はメモリを LRU キャッシュとして有効活用しています。いくつかのデータは計算したデータをキャッシュするために使われます。これはたいていの場合60%の safe heap です。この割合は spark.storage.memoryFraction のパラメータで変更することができます。もし Spark でどのくらいのデータがキャシュできるか知りたい場合は、すべてのエグゼキュータのヒープサイズを足しあわせて、 safetyFraction と memoryFraction を掛けあわせてみましょう。デフォルトでは0.9 * 0.6 = 0.54 or 54%の合計のヒープサイズが Spark によって使うことができます。
では Shuffle のメモリについてすこし詳しく見ていきましょう。Shuffle のメモリサイズは"Heap Size" * spark.shuffle.safetyFraction * spark.shuffle.memoryFraction で計算できます。spark.shuffle.safetyFraction のデフォルトの値は 0.8, 80%です。 spark.shuffle.memoryFraction のデフォルトの値は0.2 or 20%です。最終的に Shuffle には0.8 * 0.2 = 0.16, 16%のJVMのヒープが使われます。しかし、Sparkはどのようにこのメモリをつかうのでしょうか?詳細はここで見る事できます。(https://github.com/apache/spark/blob/branch-1.3/core/src/main/scala/org/apache/spark/shuffle/ShuffleMemoryManager.scala) しかし、Spark はこのメモリを後で呼ばれるShuffleのためだけに使います。Shuffleが行われる時、データをソートしなければ行けない場合があります。データをソートするときにソートされたデータを保存するためのバッファが必要となります。(重要: 後でデータがそのまま使われるので LRU キャッシュのデータを変更することができません。)なので、ソート済みのデータのチャンクを保存するためのいくらかのRAMが必要となります。もしもデータをソートするために十分なメモリがなかったらどうするのでしょう。データをチャンクごとにソートし、最後の結果をマージするさまざまなアルゴリズムがあり、よく"external sorting" (http://en.wikipedia.org/wiki/External_sorting) として引用されます。
RAMについてまだカバーしていないのが、"unroll" メモリです。unroll プロセスによって使うことが許されたRAMのメモリの量は、 spark.storage.unrollFraction * spark.storage.safetyFraction デフォルトでは、0.2 * 0.9 = 0.18 or 18%のヒープです。データブロックをメモリに unroll する場合にこのメモリがつかわれます。なぜこの unroll が必要なのでしょうか? Spark はデータをシリアライズされた状態とデシリアライズされた状態で保存することができます。シリアライズされたデータは直接操作することができません。使う前にどこかで unroll しなければらなりませ。この unroll のためにこの RAM を使います。これは storage RAM と共有をしていて、もしデータを unroll するためにメモリが必要になった場合、Spark の LRU キャッシュの幾つかのパーティションをドロップする可能性があります。
すばらしい!あなたはこれで、正確に Spark のプロセスを理解し、JVM のプロセスのメモリをどのように活用しているのかがわかりました。それではクラスタの場合に話を移しましょう。Spark クラスタをスタートしたとき本当はどのように見えるでしょうか? 私は YARN が好きなので Spark クラスタが YARN の中でどのように動いているかを説明します。しかし、一般的にほかのクラスタマネージャを使っても同じです。
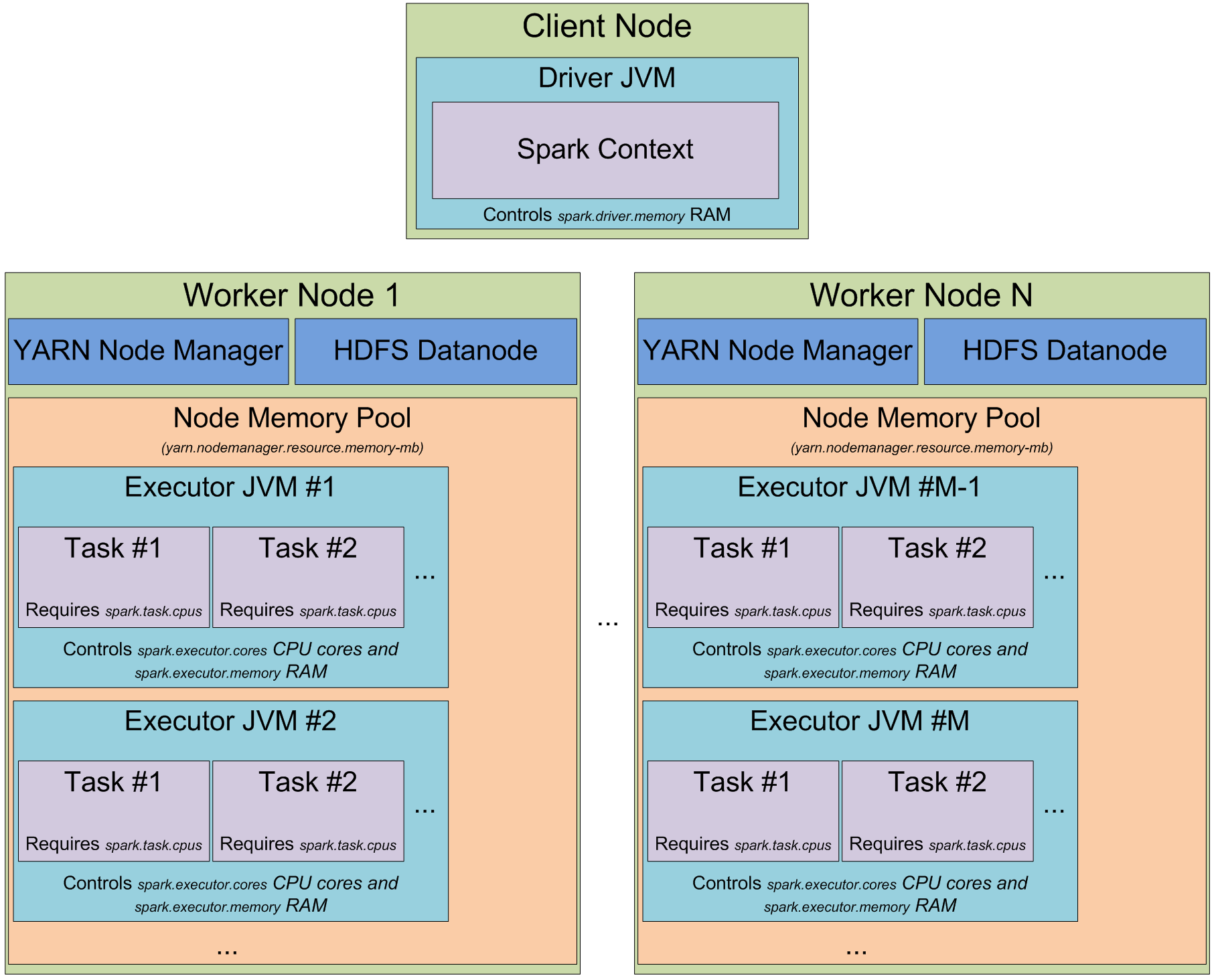
YARN を使うとき、Spark はクラスタのリソース(実質的にメモリ)管理する YARN Resource Manager daemon と クラスタノードで走り、ノードのリソース利用を管理する一連のYARN Node Manager を持っています。 YARN の視点からすると、それぞれのノードはメモリをコントロールできる RAM のプールとみなすことができます。あなたが YARN Resource Manager からリソースをリクエストした時、YARN Resource Manager はどの Node Manager が execution containers を立ち上げるためにコンタクトできるnodeの情報を返してくれます。 JVM ロケーションは YARN Resource Manager によって選ばれ、あなたはコントロールすることができません。 もしもノードが YARN によって 64GB のRAM( yarn.nodemanger.resource.memory-mb ) をコントロールし、それぞれ 4GB RAM の executor を10個リクエストすると、すべての executor はあなたが大きなクラスタを持っていたとしても、一つの YARN node で簡単にうごくでしょう。
YARN 上で Spark クラスタをスタートした時、executor の数(-num-executors フラグか spark.executor.memory パラメータ)と それぞれの executorで使われるメモリの量(-executor-memory フラグか spark.executor.memory パラメータ) とそれぞれの executor が使えるコアの数( -executor-cores フラグか、spark.executor.cores パラメータ)と それぞれのタスクの実行のために使うコアの数 (spark.task.cpus パラメータ)で指定できます。 また driver アプリケーションによって使われる メモリの量(-driver-memory フラグと spark.driver.memoory パラメータ)で指定することもできます。
クラスタ上でなにかを実行するとき、ジョブの実行過程はステージに分割され、そしてステージはタスクに分割されます。JVM は タスクのための slot のプールとして考えることができ、タスクのためにそれぞれの executor slotは spark.executor.cores / spark.task.cpus 分だけ与えられます。 例としては、12 nodes の YARN Node Managers がはしり、64 GB の RAM とそれぞれ 32 CPU コア(物理 16コアの hyper threading)がそれぞれあります。この方法では、それぞれのノードで 26 GB の executorを2つスタートできます。(system process、YARN NM と DataNode のために幾つかのコアをのこします。) なので、合計では、12 machines * 2 executors per machine 12 cores per executor / 1 core for each task = 288 task slot を扱うことができます。これは、Spark クラスタが288のタスクを平行に実行でき、クラスタほとんどすべてのリソースを有効活用できることを意味します。このクラスタでキャッシュのため使えるメモリの量は 0.9 spark.storage.safetyFraction * 0.6 spark.storage.memoryFraction * 12 machines * 2 executors per machine * 26 GB per executor = 336.96 GB です。そこまで多くありませんが、ほとんど場合では十分です。
これまでで、Spark がどのように memory を使い、クラスタ上の execution slot が何であるかがわかりました。すでにお気づきかもしれませんが、"task" の詳細については触れていません。 これは次の記事の題とします。 しかしながら、基本的に task は Spark によって実行される 一つの 仕事の単位であり、 JVM の executor の中で thread として実行されます。 これは、Sparkの 短い job startup timeの秘訣です。thread を JVM の中でフォークすることは、Hadoopの MapReduce job をスタート時に行われる JVM 自体を立ち上げるよりとても高速です。
次は "partition" と呼ばれる Spark の抽象化について話しましょう。 Spark のなかではすべてのデータは partition に分割されます。 一つの partition とはなんであり、どのように決定されるのでしょうか? Partition の数はデータソースに完璧に依存します。ほとんどのSparkのデータを読み込むオペレーションでは、RDD の中に何個の partition を持つかを指定できます。ファイルを HDFS から読み込む場合には、Hadoop の InputFormat が RDD の partition を作るために使えます。デフォルトでは、それぞれの InputFromat によって返ってくる input split は RDD の single partition にマップされます。 HDFS のほとんどのファイルの single input split は HDFSに保存される 一つのblock(近似的に64 MBか 128MB のデータ)のために生成されます。近似的にといったのは、 HDFS では byte サイズで厳密に block の境界が指定されていますが、処理されるときにはレコードで分割されるからです。text ファイルでは、分割文字は新しい行を示す文字です。連続したファイルでは block の終わりで分割されます。このルール例外は、圧縮されたファイルです。全体のテキストが圧縮されているものはレコードに分割することができず、すべてのファイルが一つの input split となります。なので、Spark の中では、一つの partition になり手動でrepartition しなければなりません。
そして、ここからはとても単純です。一つの partition のデータを処理するために Spark はデータの近く(Hadoop block location, Spark cached partition location)にある task slot で実行される一つの task を生成します。
この情報は一つのブログの記事としてはとても十分です。次に私が書く文章は、Spark がどのように 処理を stage 分割し更に task に分割するか、Spark がどのようにクラスタの中でshuffleを行うのかなどと有益な情報です。