TungstenのShuffleまでカバーされていて、感動してしまったので、翻訳(意訳)してみました。
元記事: Spark Architecture: Shuffle
Spark Architecture: Shuffle
これは Apache Spark のアーキテクチャに関する2本目の記事です。今回は、Spark デザインの中で、もっと面白い Shuffle について詳しく紹介します。前回の記事は、Spark のアーキテクチャとメモリ管理についてでした。
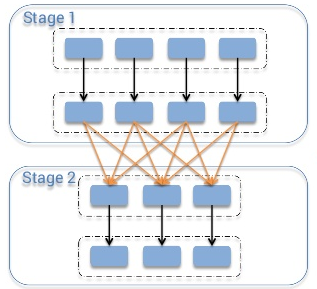
一般的に Shuffle とはなんでしょうか? 電話の履歴リストがテーブルにあり、それぞれの日にどのくらい電話があったかを数える場合を考えてください。この場合は、各レコードを"day"をキーにして(それぞれの電話の回数として)バリューを"1"として変換します。この処理の後、各キーごとのバリューを合計することでそれぞれの日の電話の回数が得られます。しかし、データがクラスタに分散して保存されている場合、どのように同じキーで違うマシンに保存されたバリューを足し合わせるでしょうか?たった一つの方法は、同じキーを持つデータを同じマシンに集めることです。この処理の後、データは足し合わせることができるようになるでしょう。
クラスターをまたがってデータを shuffle するには、様々なタスクが必要とされます。たとえば、"id"というフィールドで2つのテーブルをジョインするとき、同じidの値を持つすべてのデータが同じチャンクに保存されていないといけません。テーブルに1から1000000の範囲で整数のキーが存在するときを考えましょう。キーが1-100のデータがパーティションとして一つのチャンクに保存されていると仮定しましょう。そして、同じチャンクのデータをソートすることによってパーティション同士を直接ジョインすることができます。なぜならキーが1-100のデータはこれらの2つのパーティションに保存されていることがわかっているからです。これを実現されるには、2つのテーブルに同じだけのパーティションがなければなりません。この方法によって、ジョインは計算コストが少なくできます。さて、これで Shuffle の重要性がわかったと思います。
このトピックを議論するにあたり、MapReduce の命名規則に従い話します。Shuffle の命令では、source executor として、データを放出するものを"mapper"と呼び。そのデータを消費する target executor を"reducer"と呼びます。これらの mapper と reducer の間で行われるのが"shuffle"です。
Shuffle は一般的に2つの重要なパラメータを取ります。 spark.shuffle.compress Shuffleのアウトプットを圧縮するかどうか。 spark.shuffle.spill.compress Shuffleでメモリからあふれた中間ファイルを圧縮するかどうか。両者ともデフォルトで"true"になっています。 spark.io.compression.codec を両者とも使っています。データを圧縮するためのcodecはデフォルトではsnappyです。
ご存知かも知れませんが、Spark には数種類の Shuffle の実装がされています。 spark.shuffle.managerのパラメータによってそれらの Shuffle を使うことができます。使えるShuffleの実装はhash, sort, tungsten-sortです。1.2.0 からのデフォルトは"sort"になっています。
Hash Shuffle
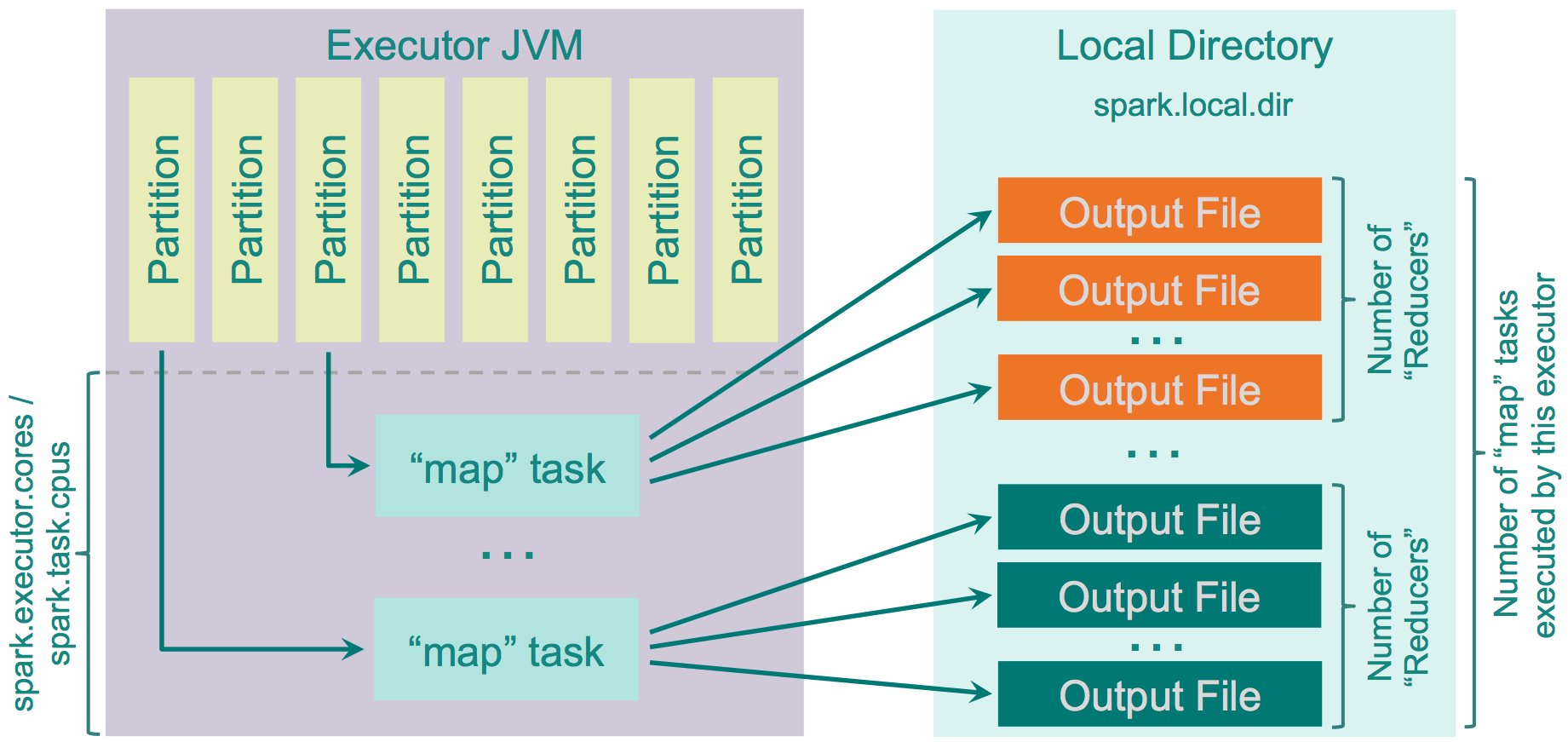
Spark 1.2.0より前は、hash がデフォルトでした。しかし、hashは多くの欠点がありました。それらは、生成されるファイルの多さに起因するものです。それぞれの mapper タスクがそれぞれの reducer のために作る分割ファイルの量は、クラスターのなかの M * R だけの数になります。( M : mapper の数、 R : reducer の数)多くの mapper と reducer は大きな問題を生じます。mapper と reducer の buffer サイズ、ファイルシステムの中でオープンされているファイルの数、それらのファイルを作成、削除する速さの問題などです。いい例としては Yahoo が実際にこの問題に直面した時の例です。彼らは46kのmapperと46kのreducerを使い20億のファイルをクラスターの中で作成しました。
この Shuffle の仕組みは賢いものではありません。reducer の数をreduce 側でパーティションの数として数え、それらに対して別々のファイルを作成しファイルをアウトプットするために必要なレコードをループし、それぞれのレコードのための target partiition を数え、対応したファイルに結果を書き出します。
このように動きます。
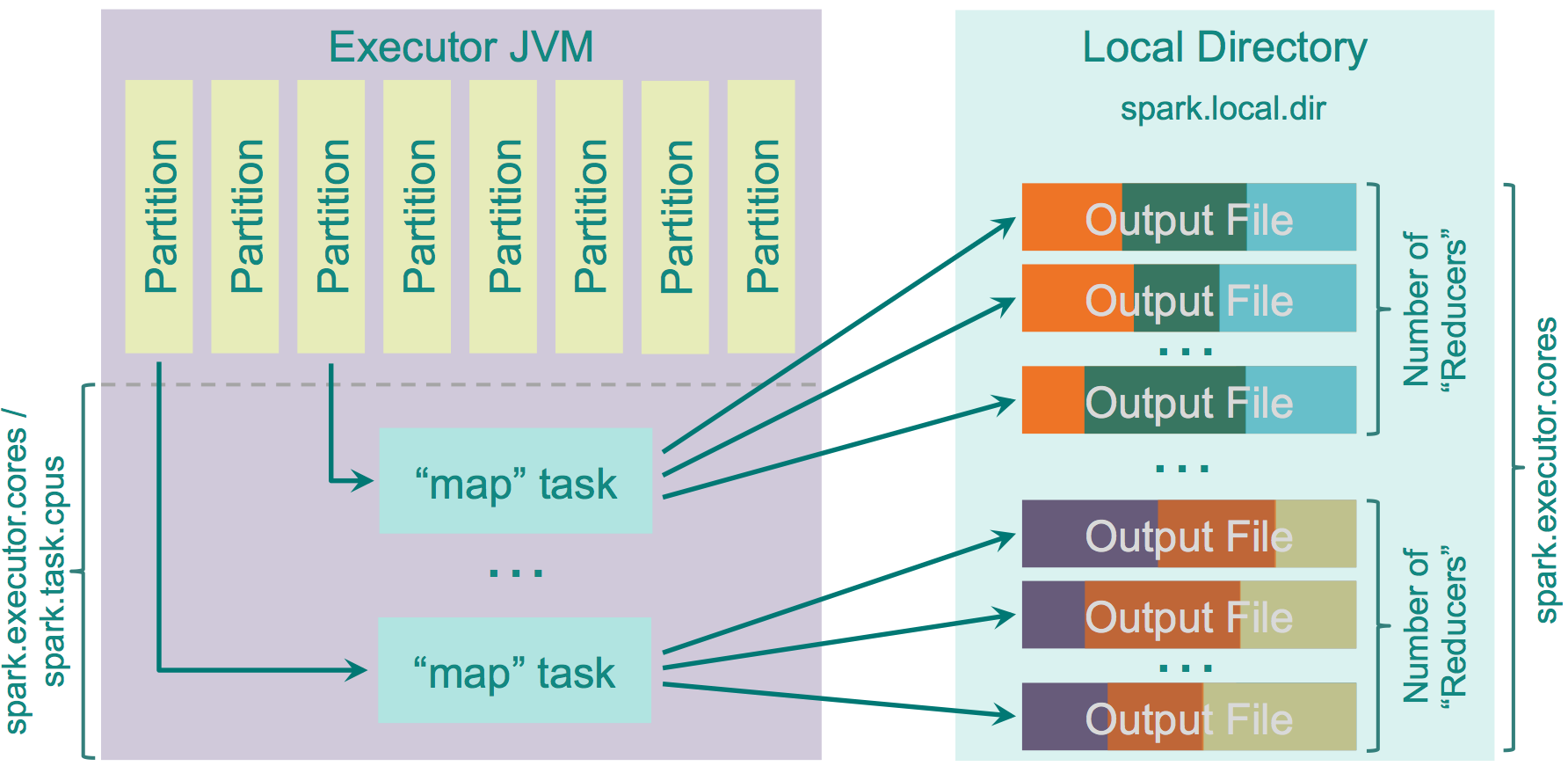
このShuffleには最適化した実装があります。それは、 spark.shuffle.consolidateFiles というパラメータで管理することができます。(デフォルトでは "false") それが "true" になった時、"mapper" の出力ファイルは統合されます。もしクラスターが E 個のエグゼキューター( YARN では -num-executors) とそれらが持つ C 個のコア(spark.executor.cores か YARNでは"-executor-cores")と、それぞれのタスクのための T 個CPU( spark.task.cpus) とするとクラスターの実行されるスロットの数は E * C / T になります。そして Shuffle の間に作られるファイルは E * C / T * R となります。10個のコアと100個のエグゼキュータで、それぞれが1コアあたりそれぞれのタスクに割り当てると46000の"reducers"では20億のファイルから4600万のファイルまで減らすことができます。これはパフォーマンス的にはかなりよい結果となります。この機能は新しくファイルを reducer のために作るのではなく、作られたファイルをプールすることによって実装されています。この処理が終わると、 R 個のファイルグループをプールに返します。それぞれのエグゼキュータでは C / T 個のタスクが並列で実行されます。それらは各グループには R 個のファイルがある C / T 個のグループのを作ります。 最初の C / T の"map"処理が終わったあと次の"map"タスクが行われ、すでにあるグループのファイルを再利用します。
このように動きます。
長所:
- 高速である。ソートは必要ない。ハッシュテーブルを維持する必要が無い。
- ソートするためのメモリオーバーヘッドがない。
- IO のオーバーヘッドがない。データは HDD に1回だけwriteとreadが行われるだけである。
短所:
- パーティションの数が大きくなると、膨大な出力ファイルのせいでパフォーマンスが低下していく。
- 多くのファイルがファイル・システムに書かれると、IO skew が発生しランダムIOが起こる。ランダムIOは一般的にはシーケンシャル IO の100倍遅いと言われている。参考としてこちらのリンクを挙げます。
IOの遅さの参考にとして One Billion Files
そしてもちろん、データがファイルに書かれるとき、データはシリアライズされ、オプションとして圧縮されるかもしれません。データを読むときは、逆のことが起きます。解凍されデシリアライズされます。この fetch するときに重要なパラメータは、 spark.recuder.maxSizeInFlight(デフォルト: 48MB)それぞれの reducer によってリモートプロセスからアクセスされるデータの量を決定するパラメータです。処理の高速化のために違うエグゼキューターから5個の並列リクエストによってこのサイズが等しく分割されます。もしこのサイズを増加させると、 reducer は "map" タスクからのデータを大きなチャンクでとりにいくでしょう。これはパフォーマンスを増加するかもしれませんが、reducer プロセスのメモリ使用量を増加させます。
もし reduce 側でレコードの順番が重要でないのなら、"reducer" は "map" の出力に依存したイテレータを返すだけです。しかし、もし順番が必要であれば、"reduce"側で ExternalSorter を使いすべてのデータを取得し、ソートします。
Sort Shuffle
Spark 1.2.0から Spark の Shuffle のアルゴリズムはsortがデフォルトで使われています。( spark.shuffle.manager = sort) 一般的には、これはHadoop MapReduceで使われているロジックと似たようなShuffleのロジックを実装したものです。Hash shuffleではそれぞれの"reducer"のために別々のファイルを出力しましたが、一方 Sort shuffle はもっと賢い方法で行います。"reducer"の id でインデックス化された一つのファイルを出力します。この方法により、"reducer x" に紐付いたデータの塊はファイルの中のデータブロックの位置の情報を取得し、そして fread の前に fseek を一回だけ行うことにデータを取得することができます。しかしながら、もちろん少ない数の”reducer”では hash でファイルを分けたほうが sort より速く処理をします。なので、sort shuffleは "reducer" が spark.shuffle.sort.bypassMergeThreshold (デフォルト: 200)より少なければ、hashをファイル分割するために使いそれらのファイルを一つのファイルにまとめるという"fallback" planを持っています。このロジックはBypassMergeSortShuffleWriterというクラスに分けて実装されています。
この実装で興味深いのは、"map" 側でデータをソートし、"reduce" 側では、このソートの結果をマージしないところにあります。もし、データの順番が必要であれば、再びソートしなおします。Cloudera はこの興味深いアイデイアに対する意見をここで述べています。http://blog.cloudera.com/blog/2015/01/improving-sort-performance-in-apache-spark-its-a-double/ 彼らは、再びソートする代わりに予めソートしてある "mapper" の出力を "reduce" 側でマージするために有効活用するロジックを考え始めました。ご存知かもしれませんが、Spark の reduce 側でのソートはTimSort を使っています。 minruns を計算し、それらをマージしていくことによって予めソートしてある入力に対しては有用性がある素晴らしいソートアルゴリズムです。すこし数学の話です。これは読み飛ばしても構いません。 N 個の要素の M 個のソート済みアレイをマージする複雑さはもっと効率のいい Min Heap を使った場合 O(MNlogM) です。TimSort を使うと MinRuns を探すためにデータを舐めてそれらの組同士をマージしていきます。今回の場合は明らかに M MinRuns です。最初の M/2 のマージは M/2 ソート済みのグループになります。次の M/4 のマージは M/4 のソート済みのグループになります。その次の場合も同様です。このようにすべてのマージが最終的に O(MNlogM) になるのは簡単に理解できます。ここでの違いは一定さだけです。一定になるかどうかは実装によります。なのでCloudera エンジニアのパッチは1年以上も承認がとれずにいます。しかし、これはCloudera managementからの圧力がなくともマージされるでしょう、この実装パフォーマンスへの影響は、とても少ないか、ないほどです。JIRA のチケットの議論を見てみるといいでしょう。彼らはShuffleの改善ではなく、別の実装として導入しようと試みることでしょう。
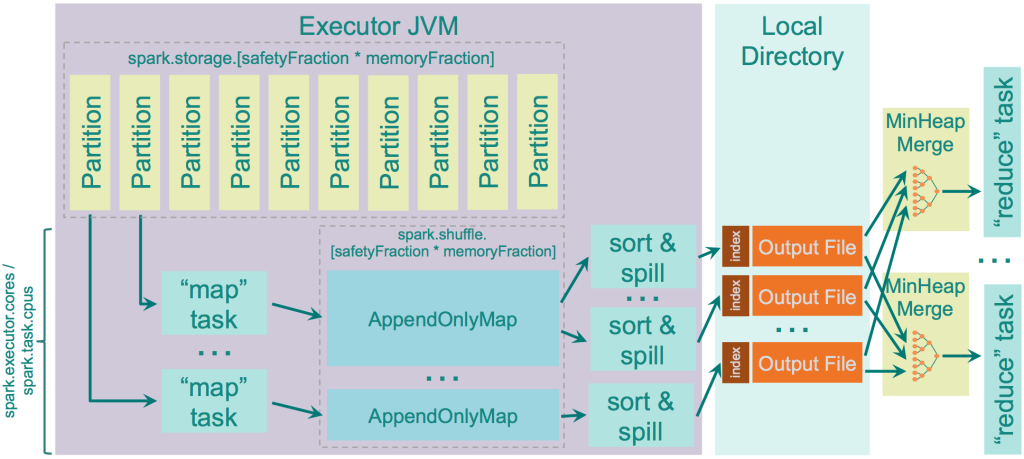
この方法でいいとします。では、"map"全体の出力に対して保存するだけのメモリがなかった場合はどうするのでしょうか?中間ファイルとしてディスクに書き込まないといけなくなるでしょう。 spark.shuffle.spill というパラメータによって有効にするかどうかが決まられます。デフォルトではディスクへの書き込みは有効になっています。もしも無効にしてしまった場合、"map"の出力がメモリに書ききれない場合はOOM エラーになる可能性があるので気をつけてください。
"map"がデータをディスクに書き込む前に使えるメモリの容量は JVM Heap Size * spark.shuffle.memoryFraction * spark.shuffle.safetyFraction です。デフォルトでは、"JVM Heap Size" * 0.2 * 0.8 = "JVM Heap Size" * 0.16です。同じエグゼキュータの中で多くのスレッドを上げる場合は気をつけてください。( spark.executor.cores / spark.task.cpus の割合が1以上になった場合)それぞれのタスクの"map"の出力を保存するのに必要なメモリの平均は “JVM Heap Size” * spark.shuffle.memoryFraction * spark.shuffle.safetyFraction / spark.executor.cores * spark.task.cpus になるでしょう。2コアでパラメータがデフォルトの値であれば、0.08 * "JVM Heap Size"になるでしょう。
Spark 内部では、AppendOnlyMap の構造を "map" の出力をメモリに保存するために使っています。興味深いことに Spark は自前の Scala 実装のHashテーブルを使用しています。それはopen hashing 使用し quadratic probing を使いキーとバリューを同じアレイに保存しています。hash としては MurmurHash3 の実装である Google Guava library の murmur3_32 を使っています。
この Hash テーブルは Spark に"combiner"のロジックを hashテーブルで実行することを可能にします。既存のキーに対して新しいバリューが追加されると既存のバリューと合わせて combine のロジックが適用されます。そして "combine" の出力が新しい値として保存されます。
データがメモリからあふれた時、Hash テーブルは、TimSort をこのAppendOnlyMap に保存されたデータに対して実行する "sorter" を呼びデータをディスクに書き込みます。
データがメモリからあふれた時もしくは、mapper の出力がなくなった時、ソートされた出力はディスクに書き込まれます。たとえば、データがディスクに書き込まれることが保証されている場合です。データが書き込まれるかどうかは、ファイルバッファキャシュのようなOSの設定によります。Spark は単純に write の命令を発行するだけなのでOSによります。
メモリからあふれたファイルはディスクに分けてそれぞれ書きだされます。このファイルのマージは"reducer"がデータを要求した時にリアルタイムにマージされていきます。たとえば、Hadoop MapReduceで行われている"on-disk merger"を呼ぶわけではなく、分割されたメモリからあふれたファイルを動的にあつめ、Java PriorityQueue classで実装されているMin Heapを使い、それらをマージしていきます。
このように動きます。
Sort Shuffleに関して
長所:
- "map"側では少ない量のファイルが作られる。
random IOが少なくなりシーケンシャルなreadとwriteを使う。
短所:
-
Sort は Hash よりも低速である。一般的には、デフォルトの設定で十分であるが、bypassMergeThreshold のパラメータをあなたのクラスタの sweet spot を見つけるのにはチューニングする価値があるかもしれない。
-
SSD ドライブをSparkShuffleのテンポラリデータのストレージにつかっているならhash shuffleのほうが良い性能がでるかもしれない。
Unsafe Shuffle or Tungsten Sort
Sparkの1.4.0以上では、 spark.suffle.manager = tungsten-sortが有効にされているかもしれない。このコードはTungsten プロジェクトからポートされたものである。このアイディアはここで説明されている。それはとても興味深いものです。この最適化されたShuffleの実装の特徴は下記のとおりです。
- データをデシリアライズせずにシリアライズされたバイナリデータをそのまま扱います。これはunsafe(sun.misc.Unsafe) memory copy関数を直接データをコピーするために使用しています。この関数は、シリアライズされたデータ(実際は単なるbyte array)に対して有効に働きます。
2.複数のパーティション idと圧縮されたarrayのレコードのポインタをソートし、キャッシュに有効なUnsafeShuffleExternalSorterという特殊なsorterを使っている。たった8byteの領域を1レコードあたりにソートされたアレイを使用することにより、CPUキャッシュがより効率良く働く。
3.レコードはデシリアライスされていないので、メモリからあふれたシリアライズデータは直接処理されます。(deserialize-compare-serialize-spillのロジックは適応されることはありません)
4.その他のメモリからあふれたデータのマージに対しての最適化はshuffleの圧縮codecがシリアライズストリームの結合をサポートするときに自動的に適用されます。(たとえば、メモリからあふれた出力をマージするのにただ結合させるだけ) この機能は、 SparkのLZF serializer だけでしかサポートされていなく、そして fast mergeが shuffle.unsafe.fastMergeEnabled パラメータにより有効にされた時に使用されます。
最適化の次のステップとして、このアルゴリズムはは off-heap ストレージのバッファを導入します。
このShuffleの実装は、下記の条件が満たされた時のみ実行されます。
- Shuffle の依存関係に集約がない。集約を行うということは、デシリアライズされた値を新しく入ってきたデータとしてデシリアライズされたデータに集約しないといけない。この方法ではシリアライズデータに対するその命令はこの Shuffle の主な優位性を失う。
- Shuffleのシリアライザがシリアライズされたバリューの関係性をサポートしていること。(これは KryoSerializertoSpark SQL のカスタムシリアライザでサポートされています。)
- Shuffle が16777216より少ないパーティションの出力を生成すること
- すべてのレコードが 128MB を超えないシリアライズされたデータであること
現在のこの Shuffle の実装はパーティション idにのみ実行されており、"reduce"側でのソート済みデータをマージする最適化と TimSort によって得られるソート済みのデータをソートするを"reduce"側での最適化は使えなくなっております。この処理のソートでは、それぞれのバリューがシリアライズされたデータをパーティションの番号の両方に紐付いている8byteの値をつかって行われているため、約16億のパーティションしか扱うことができません。
このように動きます。
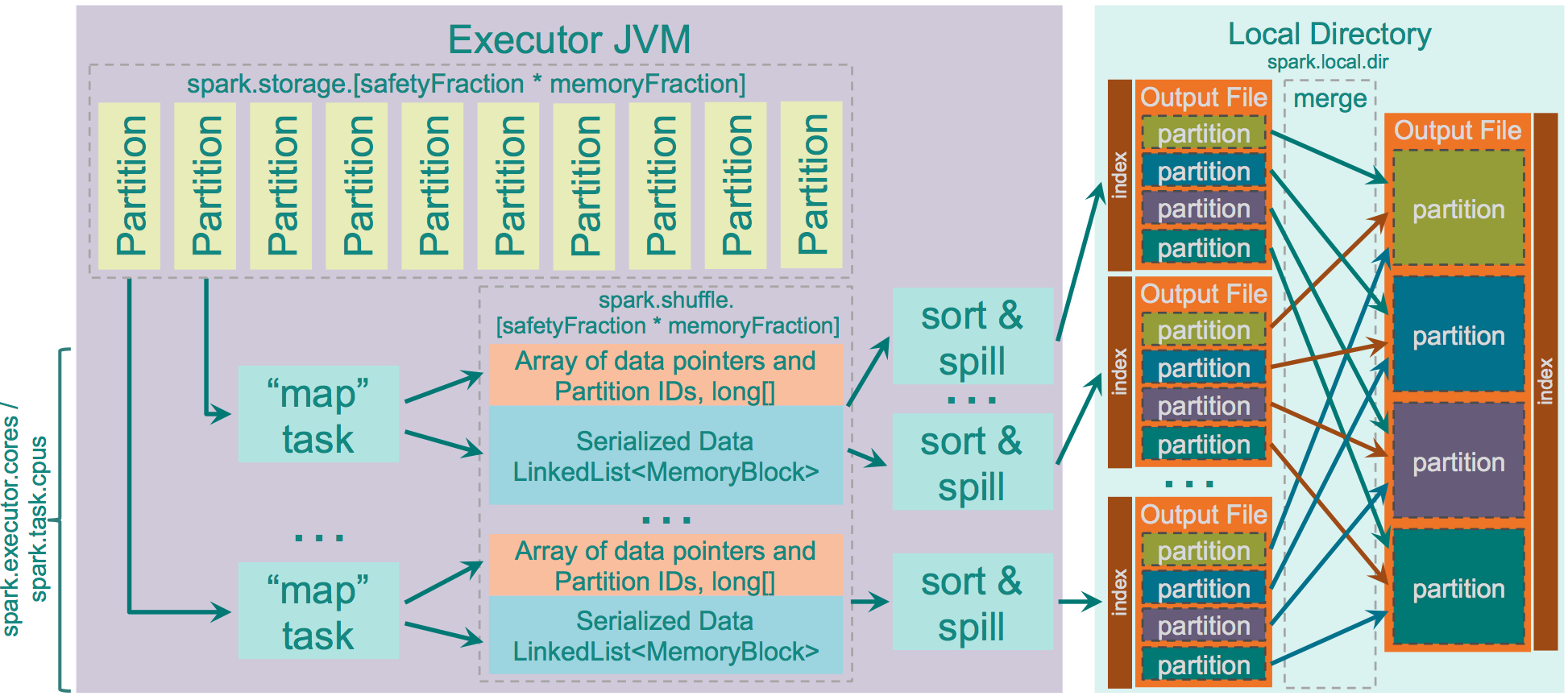
最初にメモリからあふれたデータそれぞれに対してアレイのポインタをソートし、インデックスしたパーティションファイルを出力します。そしてそれらのパーティションファイルは一つのインデックス化された出力ファイルへとマージされます。
長所:
- 上記で述べたようなパフォーマンスへの最適化がされている。
短所:
- まだ mapper 側でオーダリングされたデータを扱えない.
- まだ off heap のソーティングバファを提供していない
- まだ安定していない。
しかし、個人的な意見として、このソートはSparkのデザインにとってとても大きな成果です。私は、Databricks チームがこの新しい特徴によって得られたパフォーマンスの素晴らしさを見せるために提供する新しいベンチマークがどうなるか、今後どうなっていくのかが見てみたいです。
これが私のSparkのShuffleについて言いたかったことの全てです。とても興味深いコードでした。もしもあなたが時間があるのなら、自分でコードを読んでみることをおすすめします。