はじめに
こんにちは。
前回に引き続き、SparkInternalsを訳していきます。
前回と同じく以後は下記の判例となります。
SparkInternals訳文
コメント
SparkInternals
Architecture
既に3章でSparkジョブについて記述しているが、本章では全体のアーキテクチャと、Master、Worker、Driver、Executorといった要素が如何に協調してジョブを終了させるかについて記述する。
図を用いて理解したい場合はコードの部分は読み飛ばしてもらって構わない。
Deployment diagram
概要章にて、下記の図を用いて概要説明を行った。
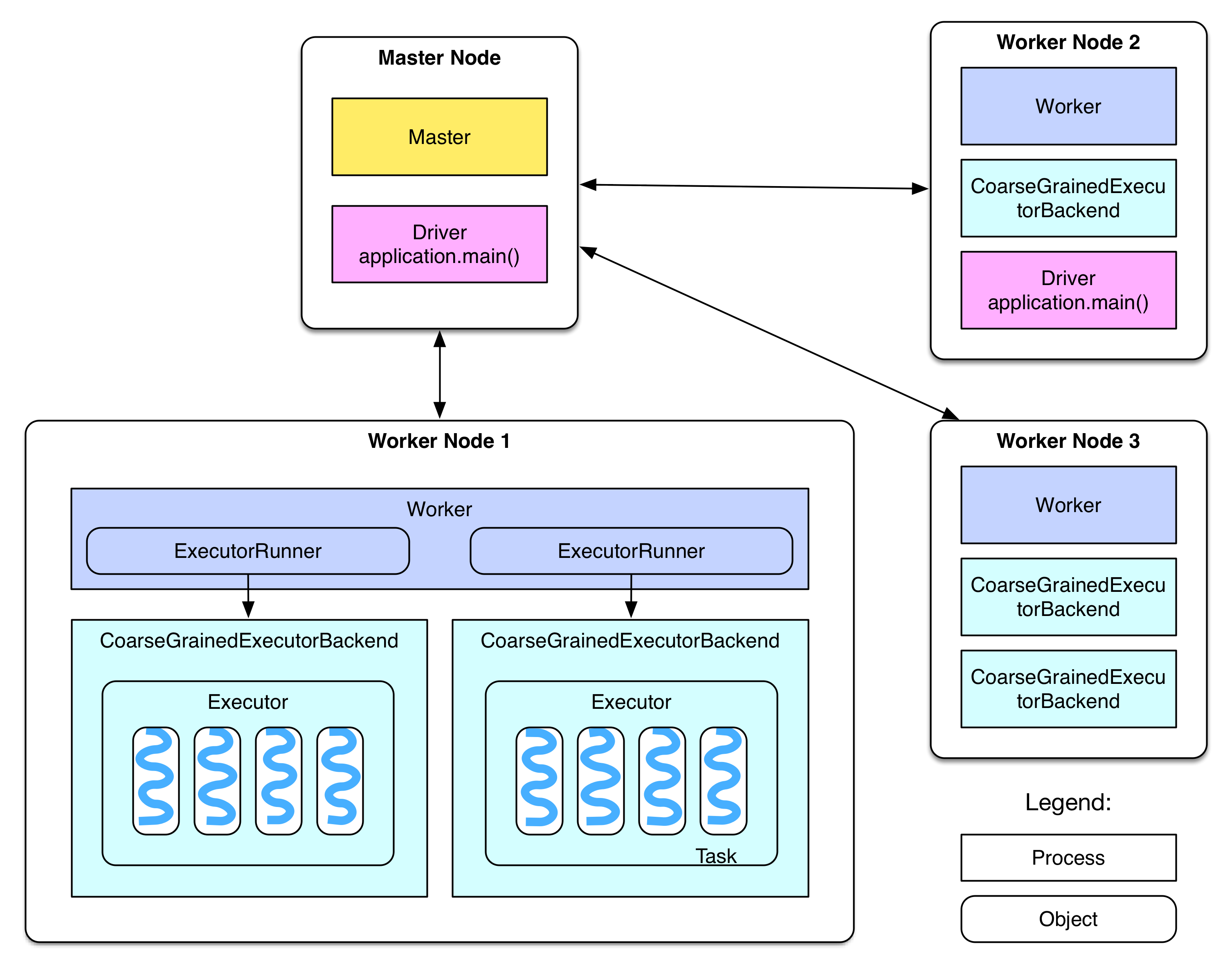
次はこの図の詳細についてみていく。
Job submission
この図はどのようにMasterノード上に存在するDriverプログラムがジョブを生成し、Workerノードに登録するかを示している。

Driver側の振る舞いは下記のコードの流れとなっている。
finalRDD.action()
=> sc.runJob()
// generate job, stages and tasks
=> dagScheduler.runJob()
=> dagScheduler.submitJob()
=> dagSchedulerEventProcessActor ! JobSubmitted
=> dagSchedulerEventProcessActor.JobSubmitted()
=> dagScheduler.handleJobSubmitted()
=> finalStage = newStage()
=> mapOutputTracker.registerShuffle(shuffleId, rdd.partitions.size)
=> dagScheduler.submitStage()
=> missingStages = dagScheduler.getMissingParentStages()
=> dagScheduler.subMissingTasks(readyStage)
// add tasks to the taskScheduler
=> taskScheduler.submitTasks(new TaskSet(tasks))
=> fifoSchedulableBuilder.addTaskSetManager(taskSet)
// send tasks
=> sparkDeploySchedulerBackend.reviveOffers()
=> driverActor ! ReviveOffers
=> sparkDeploySchedulerBackend.makeOffers()
=> sparkDeploySchedulerBackend.launchTasks()
=> foreach task
CoarseGrainedExecutorBackend(executorId) ! LaunchTask(serializedTask)
解説:
下記のコードが評価されたタイミングで、プログラムはDriver用の通信を開始する。(例:ジョブ用のExecutor、スレッド、Actor等)
val sc = new SparkContext(sparkConf)
Job logical plan
Driverプログラムにおいてtransformation()を実行することで処理の連鎖(つまりはRDDの系列)が構築される。
各RDDに対して下記のことが実行される。
-
compute()関数はPartition中のレコード群に対する処理を定義する。 -
getDependencies()関数はRDD Partitionを跨いで依存関係を定義する。
Job physical plan
各action()はジョブを起動する。
-
dagScheduler.runJob()において、異なるStage群が定義される。 - During
submitStage()において、Stageの実行に必要となるResultTasksとShuffleMapTasks群が生成され、TaskSetにまとめられた上でTaskSchedulerに送信される。TaskSetが実行されたタイミングで実Task群がsparkDeploySchedulerBackendに登録され、実際のTaskの分散実行が行われる。
Task distribution
sparkDeploySchedulerBackendがTaskSetを受け取ったらDriver Actorはシリアライズ化したTaskをWorkerノードに存在するCoarseGrainedExecutorBackend Actorに送信する。
Job reception
Task群を受信後、Workerは下記のことを行う。
coarseGrainedExecutorBackend ! LaunchTask(serializedTask)
=> executor.launchTask()
=> executor.threadPool.execute(new TaskRunner(taskId, serializedTask))
Executorは各TaskをtaskRunnerにまとめ、空いているスレッドをTask実行のために取得する。CoarseGrainedExecutorBackendプロセスは1Executorと対応している。
Task execution
下図はWorkerノードに受信されたタスクがどう実行されるかと、どのようにDriverプロセスがそのTaskの実行結果を処理するかを示している。

Executerはシリアライズ化されたTaskを受信したら復元を行い、Taskを実行することでdirectResultというDriverに対して結果送信用オブジェクトを取得する。但し、Actorに対して送信可能なデータはそんなに大きく出来ないということに留意する必要がある。
- もし結果が
groupByKeyの結果のように大きすぎた場合、blockManagerを用いてメモリとディスク上に保存を行う。その結果、DriverプログラムはindirectResultという結果格納場所を示したオブジェクトを取得するのみとなる。もしその実行結果が必要になったタイミングでDriverはHTTPリクエストで実際の結果の取得を行う。 - もし結果が大きすぎなかった場合(
spark.akka.frameSize = 10MB未満の場合)、直接結果をDriverプログラムに送信する。
blockManagerに対しての詳細は下記の通り。
directResultのサイズがakka.frameSizeより大きかった場合、BlockManagerのmemoryStoreは結果を保持するためのLinkedHashMapを生成し、そこに結果を保持する。ただし、その全体サイズはRuntime.getRuntime.maxMemory * 設定**spark.storage.memoryFraction(デフォルト0.6)**に収まっている必要がある。もしLinkedHashMapに入力データを保存するだけの領域が存在しない場合、データはdiskStoreに送信され、ディスクに保存される。(但し、storageLevelにdiskが含まれている必要がある)
In TaskRunner.run()
// deserialize task, run it and then send the result to
=> coarseGrainedExecutorBackend.statusUpdate()
=> task = ser.deserialize(serializedTask)
=> value = task.run(taskId)
=> directResult = new DirectTaskResult(ser.serialize(value))
=> if( directResult.size() > akkaFrameSize() )
indirectResult = blockManager.putBytes(taskId, directResult, MEMORY+DISK+SER)
else
return directResult
=> coarseGrainedExecutorBackend.statusUpdate(result)
=> driver ! StatusUpdate(executorId, taskId, result)
ShuffleMapTaskとResultTaskで出力される結果は下記のように違う。
-
ShuffleMapTaskは下記の2要素を含むMapStatusを出力- Taskの
BlockManagerのBlockManagerId:(executorId + host, port, nettyPort) - Task出力結果の各
FileSegmentのサイズ
- Taskの
-
ResultTaskはあるPartitionに対するfunctionの実行結果を出力-
count()ならPartition中のレコード数
-
ShuffleMapTaskはファイル出力にFileSegmentを必要としている関係上、OutputStream Writerオブジェクトがっ必要となる。これらのwriterオブジェクトはshuffleBlockManagerによって生成、管理される。
In task.run(taskId)
// if the task is ShuffleMapTask
=> shuffleMapTask.runTask(context)
=> shuffleWriterGroup = shuffleBlockManager.forMapTask(shuffleId, partitionId, numOutputSplits)
=> shuffleWriterGroup.writers(bucketId).write(rdd.iterator(split, context))
=> return MapStatus(blockManager.blockManagerId, Array[compressedSize(fileSegment)])
//If the task is ResultTask
=> return func(context, rdd.iterator(split, context))
処理自体はTaskの実行結果をDriverプログラムが取得後行われる。
TaskSchedulerがTaskが終了したことを受信した後、その結果の処理が行われる。
- もし結果が
indirectResultだった場合、BlockManager.getRemotedBytes()を実行して実際の結果を取得する。 will be invoked to fetch actual results.- もし結果が
ResultTaskだった場合、ResultHandler()がDriverプログラム側の処理を行う(例えば、count()の場合、ResultTaskの値を合計する) - もし結果が
ShuffleMapTaskのMapStatusだった場合、MapStatusはmapOutputTrackerMasterのmapStatusesに投入され、ReduceフェーズのShuffleで利用しやすいようにハンドリングする。
- もし結果が
- もしDriverプログラムが受信したTaskの結果がStageでの最後のTaskのものだった場合、次のStageの登録が行われる。もし終了したStageが既に最後のStageだった場合、
dagSchedulerがジョブ完了したことを通知する。
After driver receives StatusUpdate(result)
=> taskScheduler.statusUpdate(taskId, state, result.value)
=> taskResultGetter.enqueueSuccessfulTask(taskSet, tid, result)
=> if result is IndirectResult
serializedTaskResult = blockManager.getRemoteBytes(IndirectResult.blockId)
=> scheduler.handleSuccessfulTask(taskSetManager, tid, result)
=> taskSetManager.handleSuccessfulTask(tid, taskResult)
=> dagScheduler.taskEnded(result.value, result.accumUpdates)
=> dagSchedulerEventProcessActor ! CompletionEvent(result, accumUpdates)
=> dagScheduler.handleTaskCompletion(completion)
=> Accumulators.add(event.accumUpdates)
// If the finished task is ResultTask
=> if (job.numFinished == job.numPartitions)
listenerBus.post(SparkListenerJobEnd(job.jobId, JobSucceeded))
=> job.listener.taskSucceeded(outputId, result)
=> jobWaiter.taskSucceeded(index, result)
=> resultHandler(index, result)
// If the finished task is ShuffleMapTask
=> stage.addOutputLoc(smt.partitionId, status)
=> if (all tasks in current stage have finished)
mapOutputTrackerMaster.registerMapOutputs(shuffleId, Array[MapStatus])
mapStatuses.put(shuffleId, Array[MapStatus]() ++ statuses)
=> submitStage(stage)
Shuffle read
既に前の説において、Taskの実行と結果の処理について記述したが、本節ではReducerがどのようにしてShuffle時の入力データを取得するかを記述する。前章のShuffle Read節において、既にReducerがどのように入力データを処理するかについては記述されているため、ここで記述するのは入力データの取得方法のみとなる。
Reducerは取得データの場所をどのように知るのか?

Reducerは親StageのShuffleMapTaskが生成したFileSegmentsがどのノードに存在するかを知る必要がある。
それらの情報はShuffleMapTask終了時にDriverプログラムのmapOutputTrackerMasterに通知される。それらの情報はmapStatusesとしてHashMap[stageId, Array[MapStatus]]の形で保持される。stageIdを基に、ShuffleMapTasksが生成したFileSegmentsについての情報を保持するArray[MapStatus]が取得可能となっている。 Array[MapStatus]はblockManagerIdと各FileSegmentのサイズを保持している。
Reducerがデータの取得が必要になったタイミングで、入力データのFileSegmentsの場所を取得するためにblockStoreShuffleFetcherを実行する。blockStoreShuffleFetcherは実際はローカルに存在しているMapOutputTrackerWorkerへ問い合わせを行う。MapOutputTrackerWorkerはmapOutputTrackerMasterActorからMapStatusを取得するためにmapOutputTrackerMasterActorRefを用いて通信を行う。blockStoreShuffleFetcherはMapStatusを処理し、Reducerがどうやって取得対象のFileSegmentを取得すればいいかの情報である、 blocksByAddressを取得する。
rdd.iterator()
=> rdd(e.g., ShuffledRDD/CoGroupedRDD).compute()
=> SparkEnv.get.shuffleFetcher.fetch(shuffledId, split.index, context, ser)
=> blockStoreShuffleFetcher.fetch(shuffleId, reduceId, context, serializer)
=> statuses = MapOutputTrackerWorker.getServerStatuses(shuffleId, reduceId)
=> blocksByAddress: Seq[(BlockManagerId, Seq[(BlockId, Long)])] = compute(statuses)
=> basicBlockFetcherIterator = blockManager.getMultiple(blocksByAddress, serializer)
=> itr = basicBlockFetcherIterator.flatMap(unpackBlock)

basicBlockFetcherIteratorがTaskからのデータを受信後、いくつかのfetchRequestが生成される。上記の図からわかるように、reducer-2は3個のWorkerノードからFileSegment(白)の取得が必要となる。データ取得時はblockByAddressという形で表される値を用いてデータの取得を行う。Node 1からは4ブロック、Node 2からは3ブロック、Node 3からは4ブロックの取得を行う。
データ取得プロセスを高速化するためにデータ取得Taskはtasks(fetchRequest)という形でSubTaskに分割され、各SubTaskは別々の取得スレッドを用いて取得を行う。Sparkは各Reducerに対して5個の並列スレッドを起動してデータの取得を行う(Hadoop MapReduceと同じ構成)。取得したデータはメモリ上に保持されるため、そんなに大きなデータを一度に取得することはできない。(設定spark.reducer.maxMbInFlight、デフォルト48MB) ここで注意するべきなのは、この48MBのバッファは**5個の取得スレッドで共有されるということ。**そのため、各SubTaskは1回の取得量を48MB / 5 = 9.6MB以内に抑える必要がある。図中のNode 1においては、図中のNode 1からのデータ取得において、size(FS0-2) + size(FS1-2)は9.6MB以内に収まっているが、 size(FS2-2)が加わると9.6MBを超過してしまう。そのため、t1-r2とt2-r2の間で取得処理を分割する必要が出てくる。結果として、Node 1においては2個のデータ取得リクエストを用いることとなる。fetchRequestのサイズが9.6MBを超過することはあるのか?答えはもちろんYesで、 FileSegmentのサイズが非常に大きい場合、1取得で埋め尽くされてしまう場合もある。他にも、ReducerがFileSegmentを取得する際に既にそれがローカルにデータが存在している場合、ローカルからデータを読み込むという対処が行われている。Shuffle Read終了時、取得したFileSegmentのデシリアライズが行われ、RDD.compute()にレコード用のIteratorが渡される。
In basicBlockFetcherIterator:
// generate the fetch requests
=> basicBlockFetcherIterator.initialize()
=> remoteRequests = splitLocalRemoteBlocks()
=> fetchRequests ++= Utils.randomize(remoteRequests)
// fetch remote blocks
=> sendRequest(fetchRequests.dequeue()) until Size(fetchRequests) > maxBytesInFlight
=> blockManager.connectionManager.sendMessageReliably(cmId,
blockMessageArray.toBufferMessage)
=> fetchResults.put(new FetchResult(blockId, sizeMap(blockId)))
=> dataDeserialize(blockId, blockMessage.getData, serializer)
// fetch local blocks
=> getLocalBlocks()
=> fetchResults.put(new FetchResult(id, 0, () => iter))
もう少し詳細に見てみる。
どのようにReducerは対象となるデータが存在しているノードに対してfetchRequestを送信しているのか?どのように対象となるデータを保持するノードは受信したfetchRequestを受信し、結果を返しているのか?

もしRDD.iterator()がShuffleDependencyに到達した場合、BasicBlockFetcherIteratorはFileSegmentを取得する。BasicBlockFetcherIteratorはblockMangerのconnectionManagerを用いて他ノード上のconnectionManagerに対してfetchRequestを送信する。connectionManager間の通信はNIOで行われる。他ノードにおいて、例えばNode 2のconnectionManagerがメッセージを受信した場合、blockManagerに対してメッセージを転送する。blockManagerはfetchRequestに指定されたFileSegment群をdiskStoreを用いて読み込み、結果をconnectionManagerに返す。もし設定spark.shuffle.consolidateFilesによってファイル集約機能が有効化されている場合、diskStoreはshuffleBolockManagerによって与えられるblockIdを用いて読み込みを行う。読み込み時、FileSegmentが設定spark.storage.memoryMapThreshold(デフォルト8KB)のサイズ内に収まっていた場合、diskStoreはメモリ上に保持する。そうでない場合、RandomAccessFileのFileChannelを取得する。このようにして巨大なFileSegmentをメモリ上にロードする。
BasicBlockFetcherIteratorがシリアライズ化されたFileSegmentsを別ノードから受信したらデシリアライズし、 fetchResults.Queueに投入する。ここで、fetchResults.QueueがShuffle detials章におけるsoftBufferと似ていると気づくかもしれない。BasicBlockFetcherIteratorが必要とするFileSegmentがローカルに存在した場合、ローカルのdiskStoreから取得可能であるため、そこから取得してfetchResultsに追加する。最終的にReducerは結果に保存されたFileSegmentからRecordを取得して処理を行う。
After the blockManager receives the fetch request
=> connectionManager.receiveMessage(bufferMessage)
=> handleMessage(connectionManagerId, message, connection)
// invoke blockManagerWorker to read the block (FileSegment)
=> blockManagerWorker.onBlockMessageReceive()
=> blockManagerWorker.processBlockMessage(blockMessage)
=> buffer = blockManager.getLocalBytes(blockId)
=> buffer = diskStore.getBytes(blockId)
=> fileSegment = diskManager.getBlockLocation(blockId)
=> shuffleManager.getBlockLocation()
=> if(fileSegment < minMemoryMapBytes)
buffer = ByteBuffer.allocate(fileSegment)
else
channel.map(MapMode.READ_ONLY, segment.offset, segment.length)
全ReducerはBasicBlockFetcherIteratorを保持しており、各BasicBlockFetcherIterator毎に48MBのfetchResultsを保持する。fetchResultsからFileSegmentが取得されたタイミングで次のFileSegment群の取得が行われ、48MBのサイズを満たすように動作する。
BasicBlockFetcherIterator.next()
=> result = results.task()
=> while (!fetchRequests.isEmpty &&
(bytesInFlight == 0 || bytesInFlight + fetchRequests.front.size <= maxBytesInFlight)) {
sendRequest(fetchRequests.dequeue())
}
=> result.deserialize()
まとめ
アーキテクチャ設計の章より、機能やモジュールが各々かなり独立した構成になっていることがわかると思う。BlockManagerはいい設計だとは思うが、いささか多くのものを管理しすぎているようにも思われる。(データブロック、メモリ、ローカルディスクと他ノードとのネットワーク通信)
この章ではどのようにSparkにおけるモジュールが協調し、ジョブを完了させているか、について記述してきた。(生成、登録、実行、結果集約、結果処理、シャッフル等)多くのコードと図を用いて記述してきたが、より詳細が知りたければソースコードを見て欲しい。
最後に
この章で実際に前章までの流れをモジュール同士がどのように協調して実現しているか概略が見えてきた感じですね。
章でも記述されている通り、詳細見たければソースコードを見るしかないわけですが、その足掛かりも多分に書かれているのはそれはそれでありがたい内容でした。