きっかけ
写真の色分析をするのに、RGBA形式の画像をHSV形式に変換しています。
いつもはOpenCV(c++)を使っているのですが、どうもその処理が遅いようなので、ARMアセンブリ言語の勉強を兼ねて作ってみました。
(というか、ネット上に無かったので自分で作らざるを得なかった)
前回、c++とアセンブリ言語で画像を反転させてみるをやったので
できるだろ、とか思ったら、甘かった。。。。
RGBA画像をHSVに変換するコード(c++)
Googleで検索するといくつかでてきますが、
今回はそのなかでConvert RGB to HSV and back with a micro controllerのコードを参考にしました。
理由は unsigned char型を使っていたので、アセンブリ言語に落とし込みやすかったから。
コードはこんな感じです。
最後の部分の 0.71って数字は、Hの値の範囲を0〜360から、0〜256に変換しているだけです。
(0.71 ≒ 256/360)
typedef struct {
unsigned char *data;
int width;
int height;
int bpp;
int size;
} image_t;
void rgba2hsvx_c(image_t *rgba, image_t *hsv) {
unsigned char *src = (unsigned char *)rgba->data;
unsigned char *dst = (unsigned char *)hsv->data;
unsigned char min, max, delta;
unsigned char r,g,b,a;
unsigned char s,v;
signed int h;
int x, y;
for (y = 0; y < rgba->height; y++) {
for (x = 0; x < rgba->width; x++) {
r = *src++;
g = *src++;
b = *src++;
a = *src++;
min = r < g ? r : g;
min = b < min ? b : min;
max = r > g ? r : g;
max = b > max ? b : max;
v = max;
delta = max - min;
if (!(max == 0 || delta == 0)) {
s = (int)(delta * 255) / max;
if (r == max) {
h = (60 * (g - b)) / delta;
} else {
if (g == max) {
h = 120 + ((60 * (b - r)) / delta);
} else {
h = 240 + ((60 * (r - g)) / delta);
}
}
if (h < 0) {
h += 360;
}
} else {
h = 0;
s = 0;
}
*dst++ = (unsigned int)(h * 0.71); // In real value range is 0-359, but for rgba image, down scale to 0-255
*dst++ = s;
*dst++ = v;
*dst++ = a;
}
}
}
アセンブリコード
めちゃくちゃ苦労しました。5日間、脳みそ使用率120%って感じw
(ARMアセンブリコードを書き始めてから、まだ2週間ですので)
void rgba2hsvx_neon(image_t *rgba, image_t *hsv) {
unsigned char *src = (unsigned char *)rgba->data;
unsigned char *dst = (unsigned char *)hsv->data;
__asm__ __volatile__(
" vmov.i32 d0, #0\n" // d0 (s0, s1) = 0x0000000000000000
" lsr %[total], %[total], #5\n" // %[size] = %[size] / 32 ; The number '32' means 4bytes * 8pixels
" mov r9, %[src]\n"
" mov r10, %[dst]\n"
" mov r0, #60\n"
" vmov.u32 s31, r0\n" // (d15) s31 = 60
" vcvt.f32.u32 s31, s31\n"
" mov r0, #255\n"
" vmov.i32 s30, r0\n" // (d15) s30 = 255
" vcvt.f32.u32 s30, s30\n"
" mov r0, #256\n"
" vmov.s32 s29, r0\n" // (d14) s29 = 256
" vcvt.f32.u32 s29, s29\n"
" mov r0, #360\n"
" vmov.u32 s28, r0\n" // (d14) s28 = 360
" vcvt.f32.u32 s28, s28\n"
" mov r0, #120\n"
" vmov.s32 s27, r0\n" // (d13) s27 = 120
" vcvt.f32.u32 s27, s27\n"
" mov r0, #240\n"
" vmov.u32 s26, r0\n" // (d13) s26 = 240
" vcvt.f32.u32 s26, s26\n"
"loop_hsv:\n"
" pld [r9, #256]\n"
" vld4.8 {d1, d2, d3, d4}, [r9]\n" // Load elements from %[src] and store to each D registers:
// [RED] d1 = [r7, r6, ... r0]
// [GREEN] d2 = [g7, g6, ... g0]
// [BLUE] d3 = [b7, b6, ... b0]
// [ALPHA] d4 = [a7, a6, ... a0]
" vmin.u8 d5, d1, d2\n" // min = MIN(r, g);
" vmin.u8 d5, d5, d3\n" // min = MIN(b, min);
" vmax.u8 d6, d1, d2\n" // max = MAX(r, g);
" vmax.u8 d6, d6, d3\n" // max = MAX(b, max);
" vqsub.u8 d7, d6, d5\n" // delta = max - min
//if (!(max == 0 || delta == 0))
" vceq.u8 d4, d7, d0\n" // d4 = max == 0 ? 0xFF : 0
" vceq.u8 d8, d6, d0\n" // d8 = delta == 0 ? 0xFF : 0
" vorr.u8 d8, d4, d8\n" // d8 = d4(0 or 0xFF) | d8(0 or 0xFF)
" vst4.8 {d5, d6, d7, d8}, [r10]\n" // (min) : (max) : (delta) : (flag)
" mov r0, #0\n" // H = 0
" mov r1, #0\n" // S = 0
" mov r2, #0\n" // V = 0
" mov r8, #8\n" // r8 (i) = 8
//------------
// if (!(max == 0 || delta == 0)) {
//------------
"calc_hsv:\n"
" pld [r10, #32]\n" // Preload 32bit data from the main memory
" ldrb r3, [r10]\n" // flag = *r10++
" cmp r3, #0xFF\n" // if (flag == 0xff)
" beq calc_hsv_end\n" // goto calc_s
//------------
// s = (int)(delta * 255) / max;
//------------
"calc_s:\n"
" pld [r9, #32]\n" // Preload 256bit data from the main memory
" ldrb r5, [r9]\n" // red(r5) = *r9
" ldrb r6, [r9, #1]\n" // green(r6) = *(r9 + 1)
" ldrb r3, [r9, #2]\n" // blue(r3) = *(r9 + 2)
" vmov.u32 s2, r5\n" // s2 = red
" vmov.u32 s3, r6\n" // s3 = green
" vmov.u32 s4, r3\n" // s4 = blue
" vcvt.f32.u32 s2, s2\n" // convert unsigned int to floating point
" vcvt.f32.u32 s3, s3\n"
" vcvt.f32.u32 s4, s4\n"
" ldrb r2, [r10, #1]\n" // max(V) = *(r10 + 1)
" ldrb r3, [r10, #2]\n" // delta = *(r10 + 2)
" vmov.u32 s5, r3\n" // s5 = delta
" vmov.u32 s6, r2\n" // s6 = max
" vcvt.f32.u32 s5, s5\n" // unsigned int 32 bits -> float 32 bits
" vcvt.f32.u32 s6, s6\n"
" vmul.f32 s7, s5, s30\n" // s7 = s5(delta) * s30(#255)
" vdiv.f32 s7, s7, s6\n" // s7 = s7 / s6(max)
" vcvt.u32.f32 s7, s7\n" // float 32 bits -> unsigned int 32 bits
" vmov r1, s7\n" // r1(S) = s7
//---------------
// s6(offset) = 0
// if (r == max) {
// s7 = (g-b)
// } else {
// if (g == max) {
// s7 = (b - r)
// s6 = 120
// } else {
// s7 = (r - g)
// s6 = 240
// }
// }
// s7 = s7 * 60
// s7 = s7 / delta
// s7 += offset
// H = s7 < 0 ? s7 + 360 : s7
//---------------
" cmp r2, r5\n" // if ( r2(max) == r5(red) )
" beq r_equal_max\n" // goto r_equal_max
" cmp r2, r6\n" // if ( r2(max) == r6(green) )
" beq g_equal_max\n" // goto g_equal_max
"b_equal_max:\n"
" vsub.f32 s7, s2, s3\n" // s7 = s2(red) - s3(green)
" vmov s6, s26\n" // s6 = s26(#240)
" bal calc_h\n" // goto calc_h
"g_equal_max:\n"
" vsub.f32 s7, s4, s2\n" // s7 = s4(blue) - s2(red)
" vmov s6, s27\n" // s6 = s27(#120)
" bal calc_h\n" // goto calc_h
"r_equal_max:\n"
" vmov s6, s0\n" // s6 = s0(#0)
" vsub.f32 s7, s3, s4\n" // s7 = s3(green) - s4(blue)
"calc_h:\n"
" vmul.f32 s7, s7, s31\n" // s7 = s7 * s31(#60)
" vdiv.f32 s7, s7, s5\n" // s7 = s7 / s5(delta)
" vadd.f32 s7, s7, s6\n" // s7 += s6(offset)
" vaddlt.f32 s7, s28\n" // s7 = s7 < 0 ? s7 + s28(#360) : 0
" vmul.f32 s7, s7, s29\n" // s7 = s7 * s29(#256)
" vdiv.f32 s7, s7, s28\n" // s7 = s7 / s28(#360)
" vcvt.u32.f32 s7, s7\n" // float 32bit -> unsigned int 32bit
" vmov r0, s7\n" // r0(H) = s7
"calc_hsv_end:\n"
" mov r3, #0xFF\n"
" strb r0, [r10]\n" // H
" strb r1, [r10, #1]\n" // S
" strb r2, [r10, #2]\n" // V
" strb r3, [r10, #3]\n" // A = 0xFF
" add r9, r9, #4\n"
" add r10, r10, #4\n"
" subs r8, r8, #1\n" // r8--
" bne calc_hsv\n" // if (r8 != 0) goto calc_hsv
" subs %[total], %[total], #1\n" // %[total]--
" bne loop_hsv\n" // if (%[total] != 0) goto loop_hsv
:
: [src]"r"(src) , [dst]"r"(dst), [total]"r"(rgba->size)
: "q0", "q1", "q2", "q3", "r0",
"r1", "r2", "r3", "r5", "r6", "r4", "r8", "r9", "r10",
"s0", "s1", "s2", "s3", "s4", "s5", "s6", "s7", "s26", "s27",
"s28", "s29", "s30", "s31", "memory", "cc"
);
}
結果どうなった
1920x1080の画像をRK3288 CPUで試してみました。
たぶん使用しているメモリとかの関係だと思いますが、他のデバイスでテストすると結果が変わります。
| 方法 | 時間 |
|---|---|
| OpenCV(3.1) | 約84ms |
| c++ (-O3) | 約193ms |
| assembly (neon) | 約80ms |
うーん、苦労した割には大差がない。
バグ?
どうゆうわけか、OpenCVでHSVに変換したときと出力される画像が微妙に違うんですよね。
でもc++とは同じになるので、(とりあえず)良し、とはしていますが。
元画像はこれ。使用しているデバイスの中にサンプル画像としてあったものを1920x1080にリサイズして使用。

※ (画像をクリックすればダウンロードできます)
OpenCVで変換すると、こうなります。なんかシュール...

アセンブリコードで変換するとこうなります。

どうも鳥の胸のあたりが結果が違うんですよね。
理由はいまのところ不明です。
VFPレジスタ、Dレジスタ、Qレジスタ
やっている途中でハマったのが、レジスタのマップ。
s0 = 360とコードの前方で定義して、後半になるとぜんぜん違う値が入っていて、最初は計算が全然合わない謎の現象が発生して、随分悩まされました。
調べたところ、VFPレジスタはD/Qレジスタと同じ空間なのだと。
なぬぅ!!
そんなことは、AndroidNDKネイティブプログラミング第2版には書いてなかった!
公式サイトの解説によると、次のように書いてあります。
VFP コプロセッサには、s0 〜 s31 の 32 本の単精度レジスタがあります。各レジスタは、単精度浮動小数点値または 32 ビット整数を保持できます。
これら 32 本のレジスタは、d0 〜 d15 の 16 本の倍精度レジスタとしても使用されます。dn は、s(2n) および s(2n+1) と同じハードウェアを使用します。
図解すると、こうらしい。
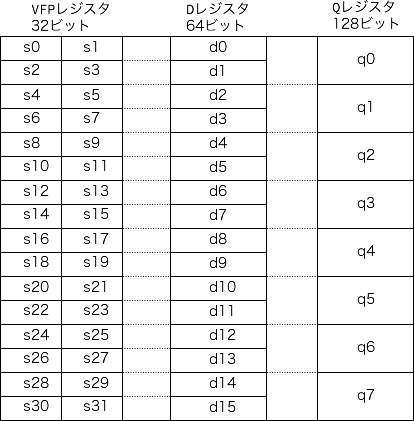
つまり、d0レジスタに値を保存してあるのに、s3レジスタに値をうっかり保存すると、d0レジスタは影響を受けるのです。
これを念頭にいれて、コードを読んで下さい。
コードの解説
将来の自分のために、残しておきます。
まぁコメントを読めばわかる気がするけど。
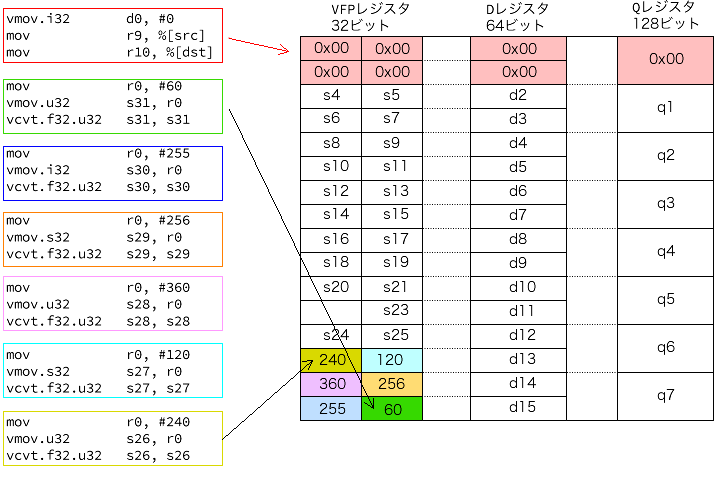
定数の宣言
コード中で計算のための定数をsレジスタに定義しておきます。
うっかり上書きしないようにするために、定数をsレジスタの後ろの方に入れておきます。
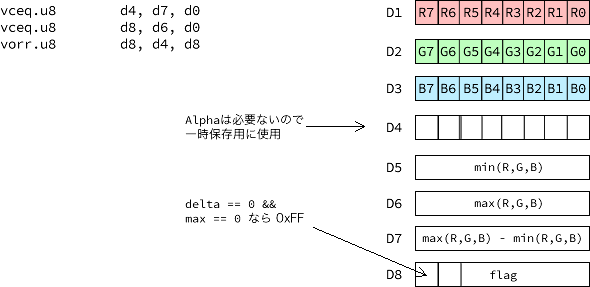
min, max, deltaの計算
NEON命令を使って、8ピクセル分をまとめて計算してしまいます。

max == 0 && delta == 0 の判定
2つの値を比較するif文は面倒だったので、NEON命令を使って、8ピクセル分をまとめて判定しておきます。
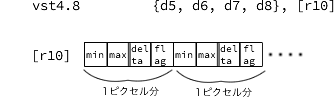
計算結果を一時保存
そしてこれらの値を 書き出し領域の%[dst] (r10)に一時保存します。
(※メインメモリを使わなかったら、もっと早くなるかも...)
この段階で、8ピクセル分の min, max(V), delta, flagが計算できました。
Sの計算
書き出し領域に保存した1ピクセル分のデータを読み出して、1ピクセルずつ処理していきます。
(* ホントはこれも並列化したい)
HSVのSの計算はこの部分です。
c++に書いてある計算をVFPを使って計算しているだけです。
//------------
// s = (int)(delta * 255) / max;
//------------
"calc_s:\n"
" pld [r9, #256]\n" // Preload 256bit data from the main memory
" ldrb r5, [r9]\n" // red(r5) = *r9
" ldrb r6, [r9, #1]\n" // green(r6) = *(r9 + 1)
" ldrb r7, [r9, #2]\n" // blue(r7) = *(r9 + 2)
" vmov.u32 s2, r5\n" // s2 = red
" vmov.u32 s3, r6\n" // s3 = green
" vmov.u32 s4, r7\n" // s4 = blue
" vcvt.f32.u32 s2, s2\n" // convert unsigned int to floating point
" vcvt.f32.u32 s3, s3\n"
" vcvt.f32.u32 s4, s4\n"
" ldrb r2, [r10, #1]\n" // max(V) = *r11++
" ldrb r3, [r10, #2]\n" // delta = *r11++
" vmov.u32 s5, r3\n" // s5 = delta
" vmov.u32 s6, r2\n" // s6 = max
" vcvt.f32.u32 s5, s5\n" // unsigned int 32 bits -> float 32 bits
" vcvt.f32.u32 s6, s6\n"
" vmul.f32 s7, s5, s30\n" // s7 = s5(delta) * s30(#255)
" vdiv.f32 s7, s7, s6\n" // s7 = s7 / s6(max)
" vcvt.u32.f32 s7, s7\n" // float 32 bits -> unsigned int 32 bits
" vmov r1, s7\n" // r1(S) = s7
Hの計算
HSVのHの計算はこの部分です。
(* ホントはこれも並列化したい)
//---------------
// s6(offset) = 0
// if (r == max) {
// s7 = (g-b)
// } else {
// if (g == max) {
// s7 = (b - r)
// s6 = 120
// } else {
// s7 = (r - g)
// s6 = 240
// }
// }
// s7 = s7 * 60
// s7 = s7 / delta
// s7 += offset
// H = s7 < 0 ? s7 + 360 : s7
//---------------
" cmp r2, r5\n" // if ( r2(max) == r5(red) )
" beq r_equal_max\n" // goto r_equal_max
" cmp r2, r6\n" // if ( r2(max) == r6(green) )
" beq g_equal_max\n" // goto g_equal_max
"b_equal_max:\n"
" vsub.f32 s7, s2, s3\n" // s7 = s2(red) - s3(green)
" vmov s6, s26\n" // s6 = s26(#240)
" bal calc_h\n" // goto calc_h
"g_equal_max:\n"
" vsub.f32 s7, s4, s2\n" // s7 = s4(blue) - s2(red)
" vmov s6, s27\n" // s6 = s27(#120)
" bal calc_h\n" // goto calc_h
"r_equal_max:\n"
" vmov s6, s0\n" // s6 = s0(#0)
" vsub.f32 s7, s3, s4\n" // s7 = s3(green) - s4(blue)
"calc_h:\n"
" vmul.f32 s7, s7, s31\n" // s7 = s7 * s31(#60)
" vdiv.f32 s7, s7, s5\n" // s7 = s7 / s5(delta)
" vadd.f32 s7, s7, s6\n" // s7 += s6(offset)
" vaddlt.f32 s7, s28\n" // s7 = s7 < 0 ? s7 + s28(#360) : 0
" vmul.f32 s7, s7, s29\n" // s7 = s7 * s29(#256)
" vdiv.f32 s7, s7, s28\n" // s7 = s7 / s28(#360)
" vcvt.u32.f32 s7, s7\n" // float 32bit -> unsigned int 32bit
" vmov r0, s7\n" // r0(H) = s7
最後に保存
あとは書き出し領域に保存して、次の8ピクセルの処理に移ります。
"calc_hsv_end:\n"
" mov r3, #0xFF\n"
" strb r0, [r10]\n" // H
" strb r1, [r10, #1]\n" // S
" strb r2, [r10, #2]\n" // V
" strb r3, [r10, #3]\n" // A = 0xFF
" add r9, r9, #4\n"
" add r10, r10, #4\n"
" subs r8, r8, #1\n" // r8--
" bne calc_hsv\n" // if (r8 != 0) goto calc_hsv
" subs %[total], %[total], #1\n" // sub--
" bne loop_hsv\n" // if (r11 != 0) goto calc_hsv
まとめ
記事を書くのに疲れたので、一旦まとめます。
このコードを書くのに、5日間フルで使いましたね。
朝も昼も夜も、寝ている間でさえもうなされながら、考えてました。
で、結果が、OpenCVと対して変わらない!!!! ... orz
でもSの計算を並列化できれば、たぶん早くなるはず。と思っているので、誰かヘルプしてください
追記1. Sの計算は並列化できない(たぶん)
ARM32ビットCPUの場合、除算を擬似的に行っているらしく、計算に32ビット幅を要します。
そして一回の命令で一つの値しか計算できないので、除算の部分はどうしても並列化はできないっぽい。
追記2. 3週間バトルしてみてその後...
最終的にはこんなコードにしました。でもOpenCVの方がちょっとだけ早い。。。のでギブアップ
void rgba2hsvx_neon(image_t *rgba, image_t *hsv) {
volatile unsigned char *src = (unsigned char *)rgba->data;
volatile unsigned char *dst = (unsigned char *)hsv->data;
__asm__ __volatile__(
" mov r0, %[src]\n"
" pld [r0]\n"
" mov r1, %[dst]\n"
" mov r7, %[size]\n"
" lsr r7, r7, #5\n" // size = size >> 5
" vmov.u32 d25, #255\n" //d25 = 255.0f
" vcvt.f32.u32 d25, d25\n"
" vmov.u32 q15, #0xff\n" //q15(d30, d31) = 0xFF
" vmov.u32 d29, #120\n" //d29 = 120
" vmov.u32 d28, #240\n" //d28 = 240
" vmov.u32 d27, #60\n" //d27 = 60.0f
" vadd.u32 d15, d29, d28\n" //d15 = 360.0f
" vcvt.f32.u32 d15, d15\n"
" vmov.u32 d14, #256\n" //d14 = 0.71f
" vcvt.f32.u32 d14, d14\n"
" vdiv.f32 s28, s28, s30\n"
" vmov s29, s28\n"
" vmov.u8 d23, #0xFF\n"
"loop_hsv:\n"
" vld4.8 {d0-d3}, [r0]\n" // r,g,b,a
//-----------------
// d4 = max
// d5 = delta
//-----------------
" vmin.u8 d5, d0, d1\n" // min = MIN(r, g);
" vmin.u8 d5, d5, d2\n" // min = MIN(b, min);
" vmax.u8 d22, d0, d1\n" // max = MAX(r, g);
" vmax.u8 d22, d22, d2\n" // max = MAX(b, max);
" vqsub.u8 d5, d22, d5\n" // delta = max - min
//--------------------------------
// zero clear of the store space
//--------------------------------
" mov r4, #4\n"
" vmov.u64 q10, #0\n" // For the final result of H and S values
" vmov d4, d22\n"
"calc_s:\n"
//------------------------------------------------
// Shift the store space for H and S (d20, d21)
//------------------------------------------------
" vshl.u32 q10, #8\n" // q10(d20,d21) = q10 << 8
//----------------------------------------
// Load values from d3(max), d4(delta)
//----------------------------------------
" vand.u32 q4, q2, q15\n" // d8(max) = d4(max) & d30(#0xff), d9(delta) = d5(delta) & d31(#0xff)
//----------------
// calculate H
//----------------
" vsub.u64 d11, d11, d11\n" // d11 = 0
" vmov.u32 d18, d31\n" // d18 = d31(0xFF)
//--------------------------------
// if (red == max) {
// op1 = green
// op2 = blue
// }
//--------------------------------
" vand.u32 d17, d31, d0\n" // d17 = red & 0xff
" vceq.u32 d7, d17, d8\n" // d7 = red == max ? 0xFF : 0
" vsub.u32 d18, d18, d7\n" // d18 = d18 - d7
" vand.u32 d7, d7, d31\n" // d7 = d7 & 0xff
" vand.u32 d10, d7, d1\n" // d10(op1) = d7 & green
" vand.u32 d12, d7, d2\n" // d12(op2) = d7 & blue
//--------------------------------
// if (green == max) {
// op1 = blue
// op2 = red
// offset = 120
// }
//--------------------------------
" vand.u32 d17, d31, d1\n" // d17 = green & 0xff
" vceq.u32 d7, d17, d8\n" // d7 = green == max ? 0xFF : 0
" vsub.u32 d18, d18, d7\n" // d18 = d18 - d7
" vand.u32 d7, d7, d31\n" // d7 = d7 & 0xff
" vand.u32 d7, d7, d18\n" // d7 = d7 & d18
" vand.u32 d17, d7, d2\n" // d17 = d7 & blue
" vorr.u32 d10, d10, d17\n" // d10(op1) = d10 | d17
" vand.u32 d17, d7, d0\n" // d17 = d7 & red
" vorr.u32 d12, d12, d17\n" // d12(op2) = d12 | d17
" vand.u32 d11, d7, d29\n" // d11(offset) = d7 & d29(#120)
//--------------------------------
// if (blue == max) {
// op1 = red
// op2 = green
// offset = 240
// }
//--------------------------------
" vand.u32 d17, d31, d2\n" // d17 = blue & 0xff
" vceq.u32 d7, d17, d8\n" // d7 = blue == max ? 0xFF : 0
" vand.u32 d7, d7, d31\n" // d7 = d7 & 0xff
" vand.u32 d7, d7, d18\n" // d7 = d7 & d18
" vand.u32 d17, d7, d0\n" // d17 = d7 & red
" vorr.u32 d10, d10, d17\n" // d10(op1) = d10 | d19
" vand.u32 d17, d7, d1\n" // d17 = d7 & green
" vorr.u32 d12, d12, d17\n" // d12(op2) = d12 | d17
" vand.u32 d17, d7, d28\n" // d17 = d7 & d28(#240)
" vorr.u32 d11, d11, d17\n" // d11(offset) = d11 | d17
//--------------------------------
// h = ((op1 - op2) * 60) / delta
//--------------------------------
" vand.u32 d10, d10, d31\n" // d10(op1) = d10 & d31(#0xFF)
" vand.u32 d12, d12, d31\n" // d12(op2) = d12 & d31(#0xFF)
" vsub.s32 d10, d10, d12\n" // d10 = d10(op1) - d11(op2)
" vmul.s32 d10, d10, d27\n" // d10 = d10 * d27(#60)
" vcvt.f32.u32 q5, q5\n" // unsigned int -> float
" vcvt.f32.u32 q4, q4\n" // (d8, d9, d10, d11)
" vdiv.f32 s20, s20, s18\n" // s20 = s20 / s18(delta)
" vdiv.f32 s21, s21, s19\n" // s21 = s21 / s19(delta)
" vadd.f32 d10, d10, d11\n" // d10 += d11(offset)
//-------------------------
// h += h < 0 ? 360.0f : 0
//-------------------------
" vclt.f32 d11, d10, #0\n" // d11 = d10 < 0 ? 0xFF : 0
" vand.f32 d11, d15\n" // d11 = d11 & d15(#360.0f)
" vadd.f32 d10, d11\n" // d10 = d10 + d11
//---------------------------------------
// downscale H value from 0-359 to 0-255
//---------------------------------------
" vmul.f32 d10, d10, d14\n" // d10 = d10 * 0.71
//------------------------
// s = delta * 255 / max
//------------------------
" vmul.f32 d11, d9, d25\n" // d11 = d9 * d25(#255.0f)
" vdiv.f32 s22, s22, s16\n" // s22 = s22 / s16(max)
" vdiv.f32 s23, s23, s17\n" // s23 = s23 / s17(max)
" vcvt.u32.f32 q5, q5\n" // float -> unsigned int (d10, d11)
" vorr.u64 q10, q5, q10\n" // H = H | d10, S = S | d11
" vshr.u64 q0, q0, #8\n" // q0(red, green) = q0 >> 8
" vshr.u64 d2, d2, #8\n" // d2(blue) = q1 >> 8
" vshr.u64 q2, q2, #8\n" // q2(delta, max) = q2 >> 8
" subs r4, r4, #1\n"
" bne calc_s\n"
" pldw [r1]\n"
" vrev32.8 q10, q10\n"
" vst4.8 {q10-q11}, [r1]\n" // r,g,b,a
" add r0, r0, #32\n"
" add r1, r1, #32\n"
" pld [r0]\n"
" subs r7, r7, #1\n"
" bne loop_hsv\n"
:
: [src]"r"(src), [dst]"r"(dst), [size]"r"(rgba->size)
: "memory", "cc", "r0", "r1", "r4", "r5", "r6", "r7"
);
}