-
この記事は自分用の備忘録です。解説用ではないです
-
追記2: 結果だけ先に発表すると、OpenCVが約16ms、C++ with asmが約3msまで高速化されました。最後のコメント欄まで読んでいただければと思います。
きっかけ
カメラから画像を取得して、それを反転させて表示するプログラムを開発しています。
画像の反転をOpenCVを使っているのですが、画素数が大きいのでもう少しなんとか早くならないものかと、取り組んでみました。
cv::flip(img, img, 1);
残念ながら、私が使っているデバイスのCPUは、OpenCLをサポートしていない、ので、GPUにデータを乗っける方法が使えないのです。
使えたら、OpenCV3で、高速化してしまうんですけどね。
ということで、イバラの道としりながら、アセンブリ言語に進んでいきます。
NEON命令
NEON命令とは、arm系CPUにおいて、1命令で複数データをまとめて処理できる命令だそうです。
どうゆうことか、というのは、下のスライドが分かりやすいです。
組み込み関数(intrinsic)によるSIMD入門
単純に話をすると、**128bitでまとめて計算できるのに、8bitしか使わないのはもったいなくない?**という話。

それをarm cpuで巧く使う命令が、NEON命令だそうです。
ベクトル処理
ベクトル処理とは、複数のデータを並列に扱う処理だそうです。
(AndroidNDKネイティブプログラミング第2版 より)

ベクトル化するのは、c++コンパイラがやってくれます。
Androidの場合、Android.mkに指定しておけばいいです。
LOCAL_CPPFLAGS += -O3 # optimize level
LOCAL_CPPFLAGS += -mfpu=neon # use NEON
LOCAL_CPPFLAGS += -ftree-vectorize # use NEON
LOCAL_CPPFLAGS += -march=armv7-a
LOCAL_CPPFLAGS += -mvectorize-with-neon-quad # Use Q register(128bit) instead of D register(64bit)
LOCAL_CPPFLAGS += -mcpu=cortex-a9
LOCAL_CFLAGS += -mcpu=cortex-a9
LOCAL_ARM_MODE := arm
LOCAL_ARM_NEON := true
ARCH_ARM_HAVE_NEON := true
LOCAL_CPPFLAGS += -funwind-tables
ベクトル化されやすいコード
NEON命令を利用して、ベクトル化されやすいコードは、こんな感じらしいです。
大きいループよりも小さいループを作るのがコツらしいです。
int a[256], b[256], c[256];
foo () {
int i;
for (i = 0; i < 256; i++) {
a[i] = b[i] + c[i];
}
}
typedef int aint __attribute__ ((__aligned__(16)));
foo (int n, aint * __restrict__ p, aint * __restrict q) {
while (n--) {
**p++ = *q++;
}
}
横方向反転をさせる(c++)
c++で画像を横反転させるプログラムはこんな感じです。
typedef struct {
unsigned char *data;
int width;
int height;
int bpp;
int size;
} image_t;
void hflip_c(image_t *image) {
uint32_t *left;
uint32_t *right;
uint32_t tmp;
int x, y, width;
int half = image->width / 2;
left = (uint32_t*)image->data;
right = left + image->width - 1;
for (y = 0; y < image->height ; y++) {
for (x = 0; x < half; x++) {
tmp = *right;
*right = *left;
*left = tmp;
left++;
right--;
}
left += half;
right = left + image->width - 1;
}
}
左半分のピクセルを右半分と入れ替えていくだけです。
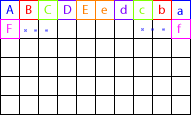
A ⇔ a
B ⇔ b
C ⇔ c
...
1920x1080の画像を反転してみると、約13ms
おっ、OpenCVよりもちょっとだけ早くなった。
インラインアセンブリ言語で書いてみる
ret = a + bのアセンブリコード
そもそもc++からアセンブリ言語を呼び出す方法が分かりませんでした。
c++で ret = a + bを行うコードはこんな感じです。
int test() {
int ret = 0;
// ret = a + b
__asm__ __volatile__ ( // <---(1)
"add %[result], %[val1], %[val2]\n\t" // <---(2)
: [result]"=r"(ret) // <---(3)
: [val1]"r"(a), [val2]"r"(b) // <---(4)
);
return ret;
}
(1) インラインアセンブリ言語は、__asm__()関数として記述するそうです。asm()でもいいみたい。
__volatile__宣言は、コンパイラに**最適化しないで!**という宣言だそうです。これをしないと、コンパイラに無駄!と判断されたコードが自動的に排除されることがあるそうです。
__volatile__宣言については、C++ volatile調査。局所的な最適化阻止が分かりやすかったです。
(2) アセンブリ言語の命令を書いていく。通常はレジスタを指定して演算を行うが、上記のサンプルコードでは分かりやすくするためにラベルを指定しています。ラベルはコンパイラ(or アセンブラ)によってレジスタに置き換えられます。
(3) 出力するラベルと変数名を指定します。[result]"r="(ret)は、c++の変数であるretの値をインラインアセンブリ言語のラベル"result"に割り当てるように指定しています。"r"はレジスタに出力する指定で、"="は、書き込み専用の変数という意味だそうです。
(4) 入力の変数とラベルを指定しています。ここでは変数aをラベル"val1"として参照、変数bはラベル"val2"として参照可能だということを指定しています。
もう少し解説
上記のサンプルと説明は、AndroidNDKネイティブプログラミング第2版 より引用しています。
さて上記を読むと分かったつもりになりますが、いまいちよく分かりません。
追加で調べたので書いておきます。
__asm_()関数
__asm__関数は、次のような引数を取ります。
__asm__ (
"アセンブリコード1"
"アセンブリコード2"
"アセンブリコード3"
"アセンブリコード4"
"アセンブリコード5"
: // 出力用変数を指定する
: // 入力用変数を指定する
: // 上書きレジスタ
「上書きレジスタ」とは、アセンブリコード中で使用するレジスタを宣言しています。
ここで指定しておくと、アセンブリコードが実行される前にその内容がスタックに退避されて、実行終了後にもとの値に戻されます。
実はこれ、かなりハマリポイントでした。
コンパイラはc++のコードを最終的には機械語に翻訳します。
機械語はアセンブリコードと1対1です。
c++コンパイラが、なにかのコードを実行するときは、当然ながらレジスタと呼ばれるCPU内部にあるメモリを使用します。
そこにインラインアセンブリ言語のコードが実行されて、レジスタを上書きしてしまうと、本来の値とは違う値が入っているので不具合が発生してしまうのです。
イメージで言うと、こんな感じ。

アセンブリコード
アセンブリ言語のフォーマットは、空白で区切られます。
基本的には1行に1命令だけを書きます。
(ラベル) 命令 オペランド1, オペランド2
具体的にはこんな感じです。
int total = 0;
int limit = 10;
__asm__ (
" MOV r0, #0\n" // レジスタr0 に 数値 0 をコピーする
" MOV r1, %[Rs1]\n" // レジスタr1 に マクロ[Rs1] の内容をコピーする
"loop:\n" // ジャンプするためのラベル
" ADD r0, r0, r1\n" // r0 = r0 + r1
" SUBS r1, r1, #1\n" // r1 = r1 - 1
" BGE loop\n" // if (r1 > 0), loopに行く
" MOV %[Rd], r0\n" // ラベル[Rd]に レジスタr0 の内容をコピーする
: [Rd] "=r" (total) // コンパイラに ラベル[Rd] は、c++変数のtotalであると教える。
// "=r"で書き込み専用であることを宣言する
: [Rs1] "r" (limit) // コンパイラに マクロ[Rs1] は、c++変数のlimitであると教える
: "r0, "r1" // レジスタr0 とr1を使用する旨を宣言しておいて、レジスタを保護する
);
return total;
っていうかレジスタってなに?
レジスタとは、CPU内部にある高速だけど小容量のメモリです。
CPU内部、つまりチップの中にあります。
CPUから見て、外部のメモリ(RAMとか)にアクセスするのは遅いです。
DDR3を使っていようがなんであろうが、とにかく遅いんです。
レジスタは、CPUの中にあるから早いのです。
レジスタは arm CPUの場合、
- 自由に使える
r0〜r12、 - 用途が決まっている
r13〜r15、 - CPUの状態を示す特別なレジスタ
cpsr
があります。
この他に、arm CPUでNEON命令をサポートしている場合、NEON命令で使用するためのQレジスタ、Dレジスタがあります。
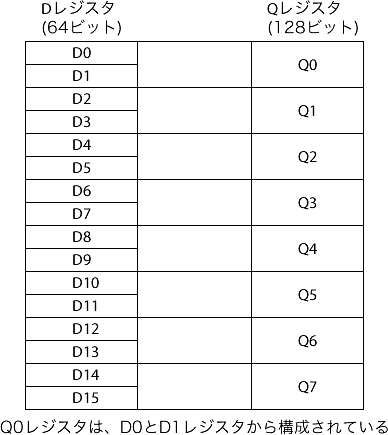
NEON命令ってなんのか、っていうと、「このQレジスタをまとめて計算してくれる命令」なんです。
このQレジスタをうまく活用することが、高速化に繋がります。
本気で知りたいと思う方は、ARMで学ぶ アセンブリ言語入門 が分かりやすかったです。
横方向反転をさせる(c++ + アセンブリコード)
話を元に戻して、画像の反転をしてみます。
といっても、最初はよくわからなかったので、いろいろ読み漁りました。
最終的には、ARM NEON命令を使って画像の回転 が参考になりました。
void hflip_neon(image_t *image)
{
int width = image->width;
int i = width / 16;
uint32_t *left = (uint32_t *)image->data;
uint32_t *right = left + image->width - 8;
int y = image->height;
__asm__ __volatile__ (
"loop_y:\n"
" mov r4, %[width]\n" // r4 = %[width]
" lsr r1, r4, #4\n" // i(r1) = r4 / 2
" lsl r3, r4, #1\n" // nextLine = width(%2) * 2
" lsl r2, r3, #1\n" // offsetRight = nextLine(r3) * 2
" sub r2, r2, #32\n" // offsetRight = offsetRight - 32
"loop_x:\n"
" pld [%[left], #64]\n" // preload 64bits(8bytes) from %[left]
" pld [%[right], #64]\n" // preload 64bits(8bytes) from %[right]
" vld1.64 {d0-d3}, [%[left]]\n" // %[left] -> {d0-d3}
" vld1.64 {d4-d7}, [%[right]]\n" // %[right] -> {d4-d7}
// for debug
//" vmov.i64 d4, #0xFF0000FFFF00FF00\n" //Red-Green
//" vmov.i64 d5, #0xFFFF0000FF000000\n" //Blue-Black
//" vmov.i64 d6, #0xFFFFFFFFFFFFFFFF\n" //white
//" vmov.i64 d7, #0xFF00FFFFFF00FFFF\n" //yellow
" vrev64.32 d8, d3\n"
" vrev64.32 d9, d2\n"
" vrev64.32 d10, d1\n"
" vrev64.32 d11, d0\n"
" vrev64.32 d12, d7\n"
" vrev64.32 d13, d6\n"
" vrev64.32 d14, d5\n"
" vrev64.32 d15, d4\n"
" vst1.64 {d8-d11}, [%[right]]\n" // {d0-d3} -> [%[right]]
" vst1.64 {d12-d15}, [%[left]]\n" // {d4-d7} -> [%[left]]
" add %[left], %[left], #32\n" // %[left] = %[left] + 32
" sub %[right], %[right], #32\n" // %[right] = %[right] - 32
" subs r1, r1, #1\n" // i(r1) = i(r1) - 1
" bne loop_x\n" // if i(r1) > 0, then goto 1:
" add %[left], %[left], r3\n" // %[left] = %[left] + nextLine(r3)
" add %[right], %[left], r2\n" // %[right] = %[left] + offsetRight(r2)
" subs %[y], %[y], #1\n" // %[y] = %[y] - 1
" bne loop_y\n" // if %[y] > 0, then goto 0:
:
: [left]"r"(left), [right]"r"(right), [width]"r"(width), [y]"r"(y)
: "q0","q1","q2","q3", "q4","q5","q6","q7", "r1", "r2", "r3", "r4");
}
1920x1080の画像を反転してみると、約8ms
おおっ!早いね!
ほんとに早いの?(結果発表)
さて、c++ユーザーならお気づきでしょう。そう、最適化オプションです。
やはりこいつを有効にして比較しないと、意味ないでしょう。
コンパイラの最適化なし (-O0)
| 方法 | 時間 |
|---|---|
| OpenCV(3.1) | 約16ms |
| c++ | 約13ms |
| assembly (neon) | 約8ms |
コンパイラの最適化あり (-O3)
| 方法 | 時間 |
|---|---|
| OpenCV(3.1) | 約16ms |
| c++ | 約7ms |
| assembly (neon) | 約8ms |
あれ、c++のが早くない。。。
何度も試しましたが、c++とアセンブリコードと同等か、c++のがちょっとだけ早いです。
なんで?
組み込み関数(intrinsic)によるSIMD入門の9枚目のスライドで解説されてますが、メモリコピーだけならc++と比較しても差がないようです。
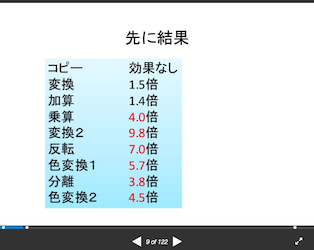
まとめ
ということで、「あえて無理にインラインアセンブリコードを書かなくても、c++でベクトル化を意識してコードを書けば、
十分に早くなる」という結果になりましたね。
インラインアセンブリコードを書くと、アセンブリ言語が読めないとコードのデバッグが出来ない、ということで
求められるスキルレベルが一気に上がります。
なので一般のプロジェクトで使うには向かないかも。
でもスライドによると、「色変換で数倍の高速化(色変換1 5.7倍)」となってますね。
引き続き、後日検証してみます。
追記1: コードの解説
書いておかないとたぶん忘れそうなので、自分のために書いておきます。
armのアセンブリ言語はこれが初めてなので、分かっていないところも多分にあります。
反転させている部分
データを読み込んでいる部分の説明は一旦飛ばして、まずどうやっているかの説明から。
1ピクセル単位でどこに何が保存されるかを調べるために、こんなコードを作りました。
// for debug
" vmov.i64 d0, #0xFF0000FFFF00FF00\n" //Red-Green
" vmov.i64 d1, #0xFFFF0000FF000000\n" //Blue-Black
" vmov.i64 d2, #0xFFFFFF00FFFFFF00\n" //lightblue
" vmov.i64 d3, #0xFF00FFFFFF00FFFF\n" //yellow
" vst1.64 {d0-d3}, [%[left]]\n" // {d0-d3} -> left
VMOV命令は、Dレジスタに値をコピーしています。
VST命令は、Dレジスタからメモリに値をコピーします。
実行すると、こうなります。
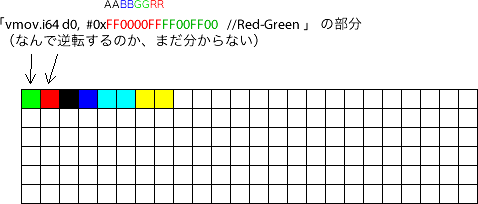
image->data には RGBAの並びでピクセルデータを保存してあるんですけどね。
なぜか逆転します。なぜかは分からないので、今は放置。
とりあえず先に進んで、次のvrev64.32のところです。
テストするために、先程のコードに付け加えてみました。
// for debug
" vmov.i64 d0, #0xFF0000FFFF00FF00\n" //Red-Green
" vmov.i64 d1, #0xFFFF0000FF000000\n" //Blue-Black
" vmov.i64 d2, #0xFFFFFF00FFFFFF00\n" //lightblue
" vmov.i64 d3, #0xFF00FFFFFF00FFFF\n" //yellow
" vrev64.32 d8, d0\n"
" vrev64.32 d9, d1\n"
" vrev64.32 d10, d2\n"
" vrev64.32 d11, d3\n"
" vst1.64 {d8-d11}, [%[left]]\n" // {d8-d11} -> left
これを実行すると、こうなります。

VREV64命令は、ベクタの各ダブルワード内の8ビット、16ビット、または32ビット要素の順序を逆にして、対応するデスティネーションベクタに結果を返します。
だそう。
つまり、vrev64.32 d8, d0は、D0レジスタ内で上下32ビットを入れ替えてくれるということだそうです。
実際のコード中では、VREV64命令に与えるDレジスタの順番を逆にして、入れ替えしています。
" vrev64.32 d8, d3\n"
" vrev64.32 d9, d2\n"
" vrev64.32 d10, d1\n"
" vrev64.32 d11, d0\n"
" vst1.64 {d8-d11}, [%[right]]\n" // {d8-d11} -> right
そうすれば、8ピクセルまとめて反転して保存できるわけです。

次の部分にアドレスを進めているのは、ここの部分。
これは単にポインタのアドレスを進めているだけなので、説明は省略
" add %[left], %[left], #32\n" // left = left(%0) + 32 (1ピクセル=4バイト * 8ピクセル)
ループしている部分
あとはc++の for文の2重ループをアセンブリ言語で書いているだけです。
int half = image->width / 2;
left = (uint32_t*)image->data;
right = left + image->width - 1;
for (y = 0; y < image->height ; y++) {
for (x = 0; x < half; x++) {
}
left += half;
right = left + image->width - 1;
}
アセンブリ言語だと、この部分。
"loop_y:\n"
" mov r4, %[width]\n" // r4 = %[width]
" lsr r1, r4, #4\n" // i(r1) = r4 / 2
" lsl r3, r4, #1\n" // nextLine = %[width] * 2
" lsl r2, r3, #1\n" // offsetRight = nextLine(r3) * 2
" sub r2, r2, #32\n" // offsetRight = offsetRight - 32
"loop_x:\n"
<反転させている部分のコード>
" subs r1, r1, #1\n" // i(r1) = i(r1) - 1
" bne 1b\n" // if i(r1) > 0, then goto 1:
" add %[left], %[left], r3\n" // left = left + nextLine(r3)
" add %[right], %[left], r2\n" // right = left + offsetRight(r2)
" subs %[y], %[y], #1\n" // y = y - 1
" bne 0b\n" // if y > 0, then goto 0:
データをロードしている部分
ループ内でデータをロードしている部分のコードです。
" pld [%[left], #64]\n" // preload 64bits from left
" pld [%[right], #64]\n" // preload 64bits from right
" vld1.64 {d0-d3}, [%[left]]\n" // left -> {d0-d3}
" vld1.64 {d4-d7}, [%[right]]\n" // right -> {d4-d7}
VLDn命令は、全レーンへの 1 つの n 要素構造体をベクタロード。 1 つの n 要素構造体の複数のコピーをメモリから 1 つまたは複数の NEON レジスタにロードします。
だそうです。
つまり、1つのDレジスタをn個(ここではn=1)として分割して、それぞれに.dataTypeビット(ここでは.dataType=64ビット)ずつ読み込む、ということらしい。
(この理解であっているかな)
とりあえず、まとめてデータを読み込めるので便利だな。
その前にあるPLD命令はなんだろう。
参考にしたコードに書いてあったから、そのまま使ったわけなんだが。
ちなみになくても動作します。
//" pld [%[left], #64]\n" // preload 64bits from left
//" pld [%[right], #64]\n" // preload 64bits from right
" vld1.64 {d0-d3}, [%[left]]\n" // left -> {d0-d3}
" vld1.64 {d4-d7}, [%[right]]\n" // right -> {d4-d7}
結果は、約7ms。
あれ、c++にちょっと近づいたぞ。プリロードというくらいだから、キャッシュのためのものだろうけど、コードを抜いたほうが早いなら、キャッシュが効いてないんじゃないの?
ちゃんと調べてみよう。
PLD命令
データと命令をプリロードする命令です。 プロセッサは、アドレスからデータまたは命令のロードが実行されることをメモリシステムに事前に通知することができます。
別のページには、こうも書いてあります。
すべてのPLD命令は、専用リソースを持つCortex-A9プロセッサの専用ユニットで処理されます。これによって、整数コアまたはロードストア ユニットのリソースを使用することが回避されます。
AndroidNDKネイティブプログラミング第2版では、こう解説しています。
インストラクションキャッシュ、データキャッシュを活かすために、ARMにはPLI(PreLoad Instruction)命令、PLD(PreLoad Data)命令があります。これらの命令は、予めインストラクションキャッシュ/データキャッシュにどれだけの命令を予め読み込んでおく(プリロードしておく)かを指定します。これによって、CPUはその都度メインメモリから命令/データを読み取って実行するのではなく、キャッシュにある命令/データを取得して処理を継続していきます。PLD命令を利用してデータ転送を行う手法は、Androidのソースコードの中でも行われています(memcpyなど)。
なるほど、なんとなく分かった気がするけど、もうちょっとちゃんと調べてみよう。
CPUからアクセスできるメモリ
一口に「メモリ」と言っても、様々なメモリがあります。
一般的に「このAndroidのメモリは2GB RAMで...」とか言っているのは、メインメモリ。
この他にもCPU内部に、L1キャッシュ、L2キャッシュがあります。
AndroidNDKネイティブプログラミング第2版の解説を引用していきます。
L1キャッシュ
L1キャッシュは、CPUに直接接続されているメモリ(キャッシュメモリ)で、CPUと同じクロックで動作できるので高速にアクセスできます。ただしメモリの記憶容量は少なく、最大64kバイト(Cortex-A9の場合)だそうです。L1キャッシュは、プログラムから明示的に利用することはできず、CPUが必要に応じて利用します。またL1キャッシュは、キャッシュする情報によって2つの領域が用意されています。1つはインストラクションキャッシュでCPUの命令をキャッシュする領域、もう1つがデータキャッシュでCPUが参照したデータをキャッシュする領域です。
なるほど。なるほど。CPU専用の作業領域というわけだ。
L2キャッシュ
L2キャッシュは、CPUがL1キャッシュ(データキャッシュ)から命令/データを取得することに失敗した場合、次に参照するキャッシュメモリです。L1キャッシュより9クロックの遅延(レイテンシ)が発生しますが、メインメモリよりはずっと早くデータを取得することが出来ます。
L1キャッシュの予備ってわけだね。
メインメモリ
メインメモリは、プログラムやデータを実行するためのRAMPAGEのことです。アプリケーションのファイルやデータは、メインメモリに記録されており、CPUはそれらのアプリケーション、データを参照してアプリケーションを実行します。これはプログラムによって、明示的にアドレスなどを指定して利用します。
通常、アプリのコードやデータがロードされる部分だ。
補助記憶(外部メモリ)
microSDカードなどの補助記憶装置です。メモリ容量が一番大きいですが、アクセス速度は最も遅くなります。
これはわかります。
キャッシュの仕組み
近年CPUのクロックは向上していますが、メモリの動作速度はCPUほど早くならず、その動作速度は差が開いたままです。とAndroidNDKネイティブプログラミング第2版では解説しています。その結果、CPUがメインメモリからデータを取得する際には、どうしても遅延が発生します。どのくらい遅いかというと、200クロックの遅延が発生します。
どのくらいの遅延が発生するかは、CPUとメモリの関係で変わってきますが、とりあえず遅いわけで。
そこでCPUにキャッシュメモリを搭載して、そこを一時バッファにすることでこの問題を解決するようになりました。
なるほど。
この後、読んでいくと更にいろいろと説明してくれていますが、とりあえず省略。
ふたたびPLD命令
PLD命令に話を戻すと、要約すれば、メインメモリからL1/L2キャッシュにデータをプリロードしてくれる命令、ということのようだ。
しかも、Cortex-A9なら専用ユニットで処理されるから早くなることが期待されるらしい。
" pld [%[left], #64]\n" // preload 64bits from left
" pld [%[right], #64]\n" // preload 64bits from right
" vld1.64 {d0-d3}, [%[left]]\n" // left -> {d0-d3}
" vld1.64 {d4-d7}, [%[right]]\n" // right -> {d4-d7}
つまり上記コードは、「64ビットのデータをメインメモリから読み込む前にL1/L2キャッシュにデータをプリロードしてくれるから、その後に続くVLD命令が早くなるはず!」ということのようだ。
でもPLD命令をコメントアウトした方が早かった。何故に・・・?
仮説:キャッシュサイズが小さいんじゃないの?
L1キャッシュは、最大64KBもあるんだから、もっと豪華に使えばいいじゃん!ということで、一行をまるごとプリロードさせてみる。
"loop_y:\n"
" mov r4, %[width]\n" // r4 = width(%2)
" lsr r1, r4, #4\n" // i(r1) = r4 / 2
" lsl r3, r4, #1\n" // nextLine = width(%2) * 2
" lsl r2, r3, #1\n" // offsetRight = nextLine(r3) * 2
" sub r2, r2, #32\n" // offsetRight = offsetRight - 32
"loop_x:\n"
" pld [%[left], #64]\n" // preload 64bits from left
" pld [%[right], #64]\n" // preload 64bits from right
" vld1.64 {d0-d3}, [%[left]]\n" // left -> {d0-d3}
" vld1.64 {d4-d7}, [%[right]]\n" // right -> {d4-d7}
PLD命令を外側のループに移動させる。
ついでにいうと、r4とかr5の計算って一回でいいじゃん。
" mov r4, %[width]\n" // r4 = %[width]
" lsl r3, r4, #1\n" // nextLine = width(%2) * 2
" lsl r2, r3, #1\n" // offsetRight = nextLine(r3) * 2
" sub r2, r2, #32\n" // offsetRight = offsetRight - 32
" lsl r5, r4, #3\n" // r5 = r4(width) * 8
"loop_y:\n"
" lsr r1, r4, #4\n" // i(r1) = r4 / 2
" pld [%[left], r5]\n" // preload 64bits(8bytes) from %[left]
"loop_x:\n"
" vld1.64 {d0-d3}, [%[left]]\n" // %[left] -> {d0-d3}
" vld1.64 {d4-d7}, [%[right]]\n" // %[right] -> {d4-d7}
結果は、約6ms。おーー!
追記1の最終的なコード
void hflip_neon(image_t *image)
{
int width = image->width;
int i = width / 16;
uint32_t *left = (uint32_t *)image->data;
uint32_t *right = left + image->width - 8;
int y = image->height;
__asm__ __volatile__ (
" mov r4, %[width]\n" // r4 = %[width]
" lsl r3, r4, #1\n" // nextLine = width(%2) * 2
" lsl r2, r3, #1\n" // offsetRight = nextLine(r3) * 2
" sub r2, r2, #32\n" // offsetRight = offsetRight - 32
" lsl r5, r4, #3\n" // r5 = r4(width) * 8
"loop_y:\n"
" lsr r1, r4, #4\n" // i(r1) = r4 / 2
" pld [%[left], r5]\n" // preload width * 8bits from %[left]
"loop_x:\n"
" vld1.64 {d0-d3}, [%[left]]\n" // %[left] -> {d0-d3}
" vld1.64 {d4-d7}, [%[right]]\n" // %[right] -> {d4-d7}
// for debug
//" vmov.i64 d4, #0xFF0000FFFF00FF00\n" //Red-Green
//" vmov.i64 d5, #0xFFFF0000FF000000\n" //Blue-Black
//" vmov.i64 d6, #0xFFFFFFFFFFFFFFFF\n" //white
//" vmov.i64 d7, #0xFF00FFFFFF00FFFF\n" //yellow
" vrev64.32 d8, d3\n"
" vrev64.32 d9, d2\n"
" vrev64.32 d10, d1\n"
" vrev64.32 d11, d0\n"
" vrev64.32 d12, d7\n"
" vrev64.32 d13, d6\n"
" vrev64.32 d14, d5\n"
" vrev64.32 d15, d4\n"
" vst1.64 {d8-d11}, [%[right]]\n" // {d0-d3} -> [%[right]]
" vst1.64 {d12-d15}, [%[left]]\n" // {d4-d7} -> [%[left]]
" add %[left], %[left], #32\n" // %[left] = %[left] + 32
" sub %[right], %[right], #32\n" // %[right] = %[right] - 32
" subs r1, r1, #1\n" // i(r1) = i(r1) - 1
" bne loop_x\n" // if i(r1) > 0, then goto 1:
" add %[left], %[left], r3\n" // %[left] = %[left] + nextLine(r3)
" add %[right], %[left], r2\n" // %[right] = %[left] + offsetRight(r2)
" subs %[y], %[y], #1\n" // %[y] = %[y] - 1
" bne loop_y\n" // if %[y] > 0, then goto 0:
:
: [left]"r"(left), [right]"r"(right), [width]"r"(width), [y]"r"(y)
: "q0","q1","q2","q3", "q4","q5","q6","q7", "r1", "r2", "r3", "r4", "r5");
}
これだけなのに、丸一日かかってしまった...
いろいろアドバイスをもらったけど、まだ何も試せてない...