この記事は社内kibelaに共有した比較記事を社外向けに編集したものです。
社内でのMLにinputするデータの形式は、Avro/csv/jsonlなどが多いですが、画像を含む場合はTFRecode形式も有用そうだったので、比較検討しました。
目的
TFRecordはTensorflow + tf.data.Dataset APIを使うとき、CSVライクにデータを読める。
圧縮やバイナリ格納、型保持機能などがあり、便利。
分散処理やクラウドからの処理でIOを節約したいケースとかではこういうフォーマットを使うと
効率が上がるケースがあるので活用方法を見出す。
TFRecordとは?
mnistのデータをTFRecordに入れる
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# mnistデータ(numpy画像+label)をダウンロードする。
# 初回は時間かかる。
mnist = input_data.read_data_sets("/tmp/data/", one_hot=False)
# TFRecordは各行情報はExampleという単位で保存する。
# 型情報もつけたマップみたいな構造。listもいける。
# 使える型はtf.train.Int64List, tf.train.FloatList, tf.train.BytesList
def make_example(image, label):
return tf.train.Example(features=tf.train.Features(feature={
'image' : tf.train.Feature(float_list=tf.train.FloatList(value=image)),
'label' : tf.train.Feature(int64_list=tf.train.Int64List(value=label))
}))
# TFRecordWriterを介して各行書いていく。書くのはExampleをserializeしたもの。
def write_tfrecord(images, labels, filename):
writer = tf.python_io.TFRecordWriter(filename)
for image, label in zip(images, labels):
ex = make_example(image.ravel().tolist(), [int(label)])
writer.write(ex.SerializeToString())
writer.close()
write_tfrecord(mnist.train.images, mnist.train.labels, 'mnist_train.tfrecord')
write_tfrecord(mnist.test.images, mnist.test.labels, 'mnist_test.tfrecord')
比較のため、CSVと画像ファイルに保存
速度比較のためにCSVと画像ファイルに保存してみました。
from PIL import Image
import pandas as pd
dir_name = 'imgs'
def save_images(images, prefix):
max_num = len(str(len(images)))
for idx, i in enumerate(images):
img = Image.fromarray((i.reshape(28,28) * 255).astype(np.uint8))
fn = f'{prefix}_{idx:0{max_num}d}.jpg'
img.save(fn)
save_images(mnist.train.images, f'{dir_name}/train')
save_images(mnist.test.images, f'{dir_name}/test')
pd.concat([
pd.Series([f'{dir_name}/train_{i:05d}.jpg'for i in range(mnist.train.num_examples)], name='image'),
pd.Series(mnist.train.labels, name='label'),
], axis=1).to_csv('mnist_train.csv',index=None)
pd.concat([
pd.Series([f'{dir_name}/test_{i:05d}.jpg'for i in range(mnist.test.num_examples)], name='image'),
pd.Series(mnist.test.labels, name='label'),
], axis=1).to_csv('mnist_test.csv',index=None)
ここではローカルに保存してますが、実際にはGCSにあげて試してます。
こんな感じ。CSVは小さくて、TFRecordは画像含むので大きいです。
読み込み
TFRecord
中身の型や長さがわからないとうまくパースできないので、注意ですね。
(jsonぽいのでdumpできますが。)
可変長配列も保存できますが、試してません。
def input_fn_from_tfrecord(fname, batch_size=1, num_epoch=None, shuffle=False):
def parse_features(example):
# generator形式での読み込み前提なのでここでは一行ずつパースする。
# 型とshapeをを指定してパースする必要がある。
features = tf.parse_single_example(example, features={
'image' : tf.FixedLenFeature([784], tf.float32),
'label' : tf.FixedLenFeature([1], tf.int64),
})
return {'images':features['image']}, features['label'][0]
# dataset APIで普通にgeneratorぽいのを作る。
dataset = tf.data.TFRecordDataset(filenames=fname)
dataset = dataset.map(parse_features)
if shuffle:
dataset = dataset.shuffle(batch_size * 10)
dataset = dataset.repeat(num_epoch)
dataset = dataset.batch(batch_size)
next_element = dataset.make_one_shot_iterator().get_next()
return next_element
CSV+画像
CSVだけならおそらく速度はほぼ変わらないかむしろ早いかもしれないですね。
画像を含むと都度画像を読むためか、だいぶ遅くなります。
最初にメモリに乗せる方法もあるのかもしれませんが、、うーん。
def input_fn_from_csv(fname, batch_size=1, num_epoch=None, shuffle=False):
def decode_csv(line):
# tf用のgeneratorで遅延実行するのでtf関数しか基本使いません。
# やってることはほぼ同じ、はず。。
img, lbl = tf.decode_csv(line, [[''], [1]])
img = tf.image.decode_jpeg(tf.read_file(img))
img = tf.cast(tf.reshape(img, (784,)), tf.float32)
return {'images':img}, lbl
dataset = (
tf.data.TextLineDataset(fname)
.skip(1) # Skip header row
.map(decode_csv)
)
if shuffle:
# Randomizes input using a window of 256 elements (read into memory)
dataset = dataset.shuffle(buffer_size=256)
dataset = dataset.repeat(num_epoch) # Repeats dataset this # times
dataset = dataset.batch(batch_size) # Batch size to use
iterator = dataset.make_one_shot_iterator()
batch_features, batch_labels = iterator.get_next()
return batch_features, batch_labels
速度(→料金)
Cloud MLで比較
このサンプルコードを使ってmnistへ簡単なCNNモデルを作成し、Cloud ML上で実行してみました。
def run()
# Build the Estimator
model = tf.estimator.Estimator(model_fn, model_dir=args.job_dir,
config=tf.estimator.RunConfig(session_config=config))
# csv版
model.train(
lambda: input_fn_from_csv('gs://aaida/mnist/mnist_train_gcs.csv',
batch_size=2, num_epoch=None, shuffle=True),
steps=num_steps)
model.evaluate(
lambda: input_fn_from_csv('gs://aaida/mnist/mnist_test_gcs.csv',
batch_size=100, num_epoch=1, shuffle=False))
# tfrecord版
model.train(
lambda: input_fn_from_tfrecord('gs://aaida/mnist/mnist_train.tfrecord',
batch_size=2, num_epoch=None, shuffle=True),
steps=num_steps)
model.evaluate(
lambda: input_fn_from_tfrecord('gs://aaida/mnist/mnist_test.tfrecord',
batch_size=100, num_epoch=1, shuffle=False))
gcloud ml-engine jobs submit training ${JOB_NAME} \
--job-dir=${MODEL_DIR} \
--runtime-version=1.5 \
--region=${REGION} \
--module-name=trainer.task \
--package-path=${PACKAGE_PATH} \
-- \
--train-files=${TRAIN_FILES} \
--eval-files=${EVAL_FILES} \
--num-steps=2000
TFRecord
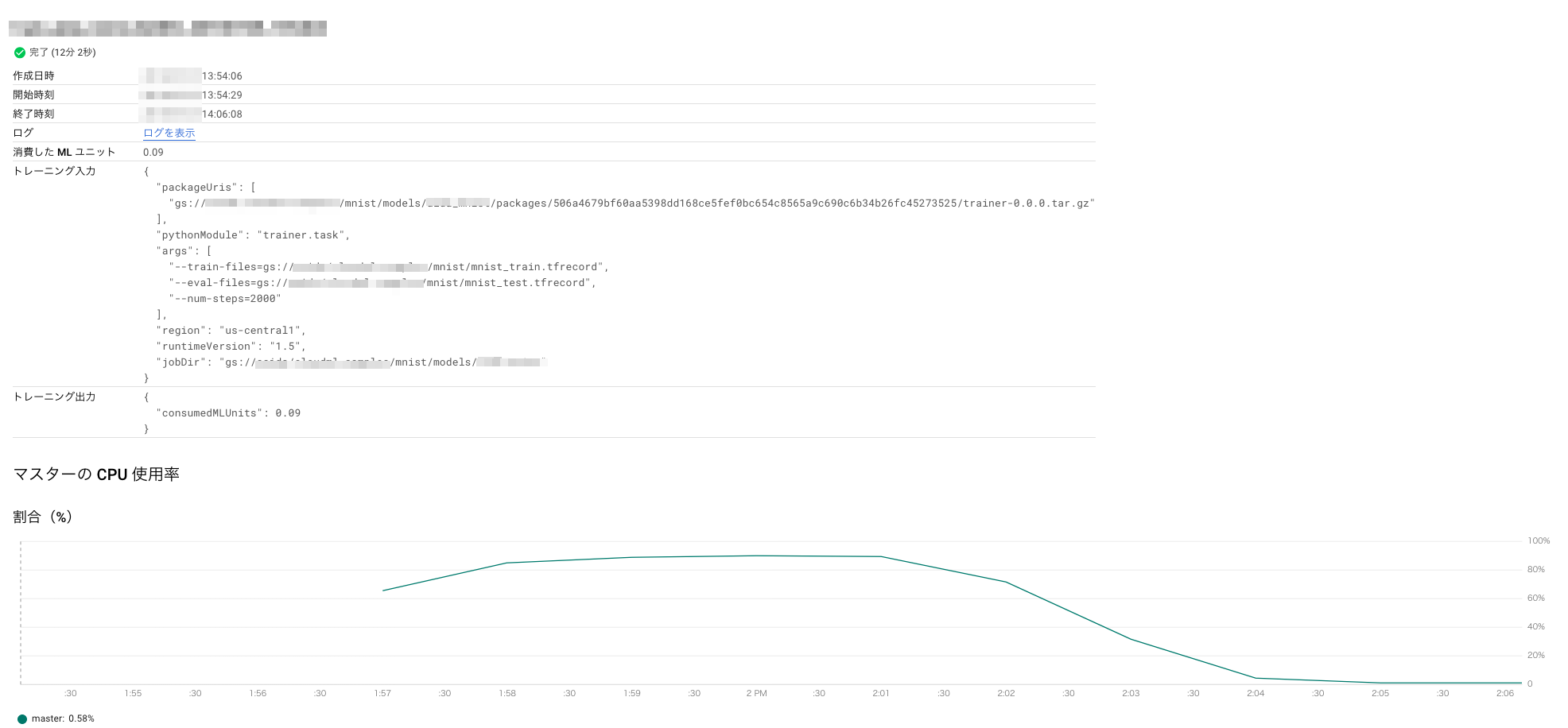
かかった時間: 12分
消費したMLユニット: 0.09
=> かかったお金: 5円
CSV
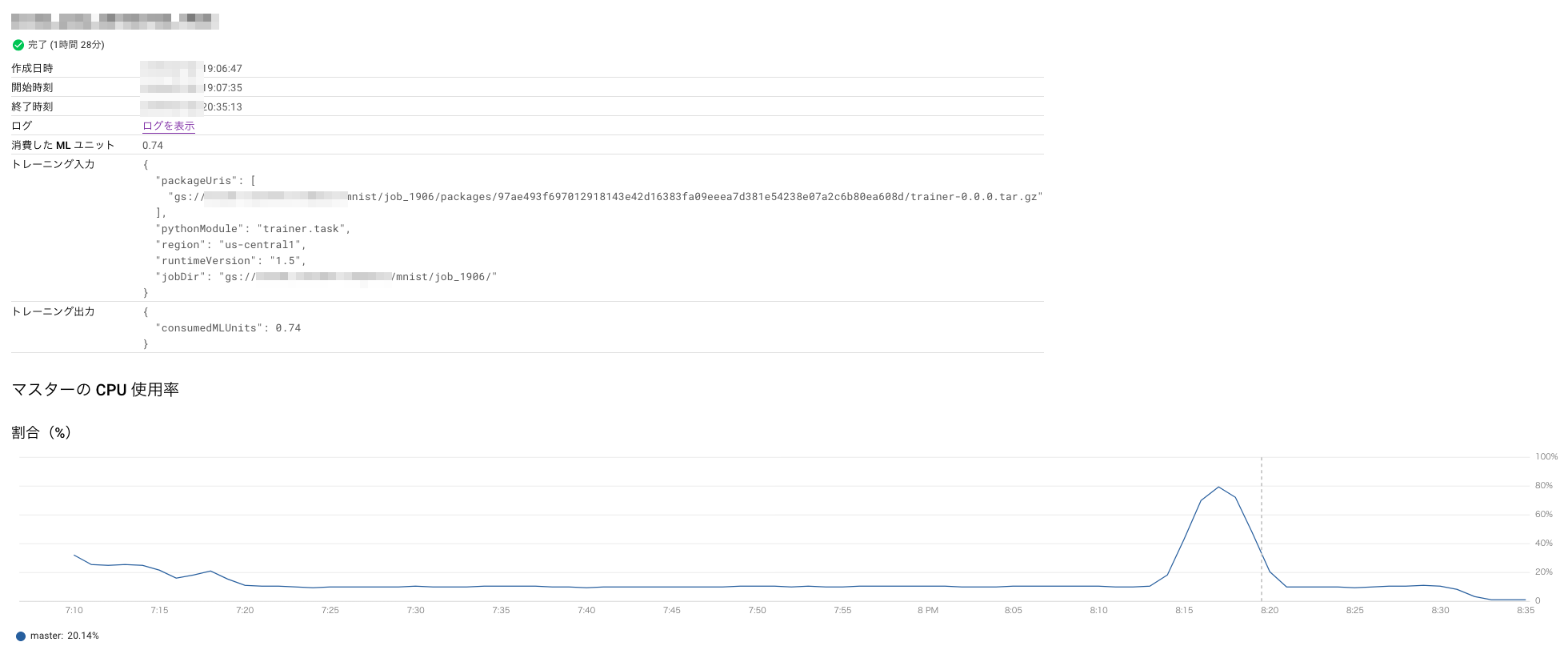
かかった時間: 1時間半
消費したMLユニット: 0.74
=> かかったお金: 40円
だいぶCSVの方が遅い。。
CPU使用率を見ると学習でCPU負荷が上がっているのは一瞬なので、画像のロードに時間がかかっているだけの可能性が高そう。
感想
純粋なCSVオンリーデータでの比較はできてないですが、サンプルでもCSVオンリーの場合は前処理していなそうなので、
画像とか付随情報を含む場合のみ注意すればいい気がします。
画像等がある場合は前処理でそういう工夫をすることでコストを減らせるかも、って話でした。