はじめに
本稿はR Advent Calendar 2020, 16日目の記事です。
昨日は@statdittoさんによる「[R] [Shiny] 情報処理技術者試験の合格率simulatorを作りました!」という記事でした。Shinyでのwebアプリ開発。憧れます。
さて、以前次元削減の手法としてt-SNEについての記事を投稿したのですが、
以下の記事によると、新たに**UMAP(Uniform Manifold Approximation and Projection)**という手法が2018年に登場していたんだそうです。
なんでも生成までの速度が速いんだとか。
最新の次元圧縮法"UMAP"について
pythonでの使い方は何件か見つかったものの、Rでの例は見受けられなかったので、今回はggplotを使った実行例をまとめてみたいと思います。
UMAPについて
Leland McInnes氏らによるUMAPの論文はこちらで読むことができます。
提出が18年、閲覧時点で最後のリバイスが20年9月とホントに出来立てホヤホヤですね。
概要を見てみると、UMAPはリーマン幾何学と代数トポロジーに基づいて構築された次元削減の為のminifold学習手法とあります。
(´Д` )?
筆者曰く
- tSNEにひけをとらない可視化の品質(基データの特徴をできるだけ失わないということ)
- 実行時間の短さ
- 埋め込み次元数に制限がない
というのが強みらしいです。
パッケージ
こちらによると、Rではumapとuwotの2つのパッケージがあるようです。
今回はumapを使用します。
使用データ
以前作ったt-SNEと比較したかったので、同じmtcarsのデータセットを使用します。
詳細は下記記事を参照してください。
Rでt-SNEを使ってみた(高次元データの圧縮)
使ってみよう
使い方は超シンプルです。
library(umap)
mt<- read.csv("mtcars.csv")#データ読み込み
mt.umap<- umap(mt[,2:12])#データフレームから解析する部分だけ選択
これでほぼ終わりです。
データ入れるだけで色々とチューニングが必要ないのは有難いですね。
再現性を気にする場合はpreserve.seed = TRUEにするようです。
UMAPの座標データは生成されたリストmt.umapのlayoutに格納されています。
head(mt.umap$layout,3)#3行目まで表示
[,1] [,2]
[1,] -1.489809 -0.9945762
[2,] -1.138094 -1.2561847
[3,] -2.525882 -0.5043327
それでは可視化してみます。
library(ggplot2)
library(dplyr)
mt.cord<-mt.umap$layout %>% as.data.frame()#座標取得してdfに変換
# 作図
p<- ggplot(mt.cord,mapping = aes(V1,V2,color = mt$Region))+
geom_point()+
stat_ellipse(type = "norm",linetype=1)
p
できた図がこちら。
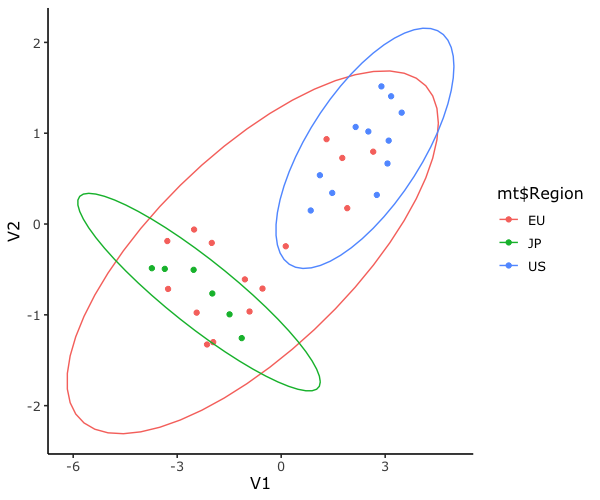
なかなかよさそうですね。
やはり日本車(JP)とアメ車(US)の集団が異なっています。
せっかくなのでいくつかの手法と比べてみます(コードは省略)。
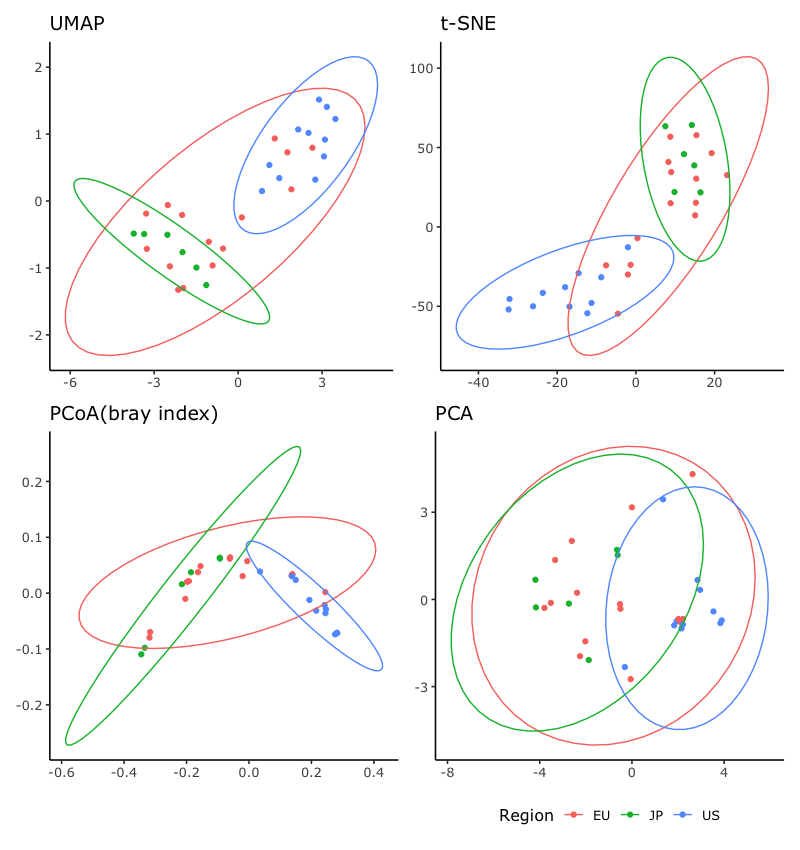
こうしてみるとUMAP(左上)とt-SNE(右上)はほぼ遜色ない結果が得られていますね。
(距離の問題なので軸が反転しているのは大きな問題ではないと思われます。)
左下はバイオインフォマティクス分野で使われるBray-Curtis indexを用いた主座標分析(PCoA)です。
さらに右下は主成分分析(PCA)の結果です。
どのプロットが最も基データの特徴を表現できているのかというのは難しいのですが、少なくともUMAPを使うのは問題ないように感じます。
最期に
使い方が簡単な点でUMAPはとても良かったです。色々と活用できそうですね。
生命科学分野の論文でも色々と使われているようなので、今後使用を検討される場合は以下も参考にしてくださいませ。
Scientific Papers
12月も折り返しましたね。年末に向けて頑張りましょう!!
明日は@Ringa_hyjさんです。