要約
始めてのQiita投稿
とりあえず知っている知識を共有
強化学習がどういったものなのか、簡単に説明
大まかな流れ
- 機械学習
- 強化学習の枠組みの説明
- 強化学習で用いられる記号などの意味の説明
- マルコフ決定過程(Markov Decision Process: MDP)
- 収益
- 状態価値
- 行動価値
この記事ではとりあえず1,2を。
機械学習
機械学習分野のうちの1つの分野である。メジャーなものをあげると
- 教師あり学習
- 教師なし学習
- 強化学習
があげられる。
それぞれの説明を軽く挙げると以下のようになる。
教師あり学習
分類わけなどで使われている。学習するためのデータに教師(答え、正解)が存在しており、その答えを毎回確認しながら学習していく手法になる。
例えば、犬の種類を教えてくれるAIを作るなら、学習データにはそれぞれどのデータがどの犬種かをラベル付けして学習させる。ただ、学習データに存在しない犬種は正確な答えを教えてくれない。
教師なし学習
教師あり学習と異なり、学習データに正解のラベルを付けないで学習する手法。AIが自律的に学習をし、正解を認識するようになる。例えるなら、小さい子供が毎日いろいろなものを見ていくうちに、自然と認識していくようになる、みたいな学習の仕方をしている。
強化学習
今回のメイン。上2つと違うのは、正解を与える代わりに、「価値」というものを計算し、「収益」を最大化するモデルになる。有名な強化学習モデルだと、AlphaGoなどがあげられる。本記事では、この強化学習で出てくる様々なものをあっさり説明し、これから強化学習をやろうと思っているひとにも分かるような説明をしていこうと思う。
まず枠組み
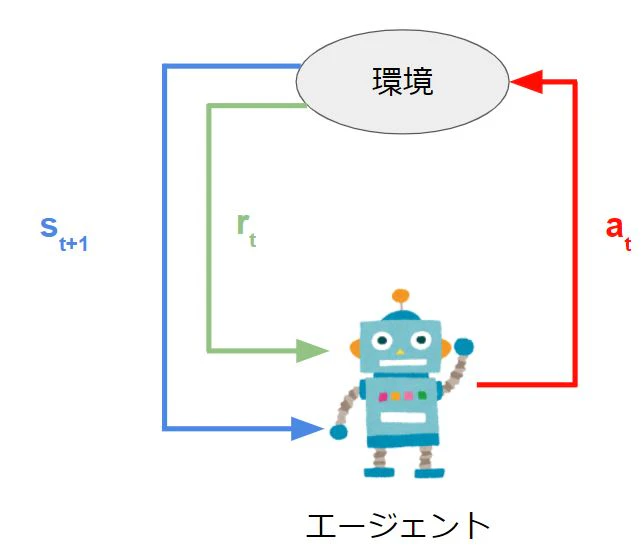
強化学習はエージェントと環境が存在する。
エージェントは実際に学習するプレイヤーになる。環境はそのプレイヤーがやるゲームだと思ってもらえばよい。
下にある画像は強化学習の枠組みである。
- エージェントが行動をする
- 状態が変わる(遷移)する
- 遷移先の状態にある報酬と、遷移先の状態の情報をエージェントに渡す
1,2,3をずっと行うことで学習することができる。
ここで具体的な例をあげようと思う。例えば、マインクラフトで迷路をやるとする。
状態になるのはマインクラフトの1ブロックで、行動は前後左右の4方向になる。
エージェントは実際に迷路を解くプレイヤーとなり、エージェントは実際に迷路を解きながらその状態がどれくらい良い場所なのかを評価しながらゴールを目指す。
報酬とはエージェントに与えられる褒美のようなもので、報酬によってエージェントは学習をしてくと言っても過言ではない。報酬の設定の仕方は様々あり、行動をするごとに報酬を与えることもできれば、ゲームをクリアしたときのみに与えることもできる。
強化学習の目的は、この報酬の合計、すなわち収益を最大化するために、行動選択を学習することになる。
次回の記事では実際にどうやって学習していくのかを表していこうとおもう。
参考文献
https://www.irasutoya.com/
https://collegestudenttextbook.org/product/reinforcement-learning-an-introduction-2nd-edition-pdf-ebook/
https://qiita.com/PlanetMeron/items/63ac58898541cbe81ada
https://qiita.com/Qiita/items/c686397e4a0f4f11683d