はじめに
- 画面はJava(SpringBoot) + DynamoDBでWebアプリケーション、クライアントツールはGo、API部分はAPIGateway+Lambda(Python)とかなり節操がない構成で構築しています。
- 今回はそのアーキテクチャの中でSpringBoot + DynamoDBを使ったWebアプリケーションのテストとデプロイの自動化をどのようにやっているかについて一部ですがご紹介してみたいと思います。
- Javaエンジニアじゃなくても参考になる部分があるかな。と思いますので良ければ記事のサマリだけでも読んでみてください。
記事のサマリ
何を自動化しているのか
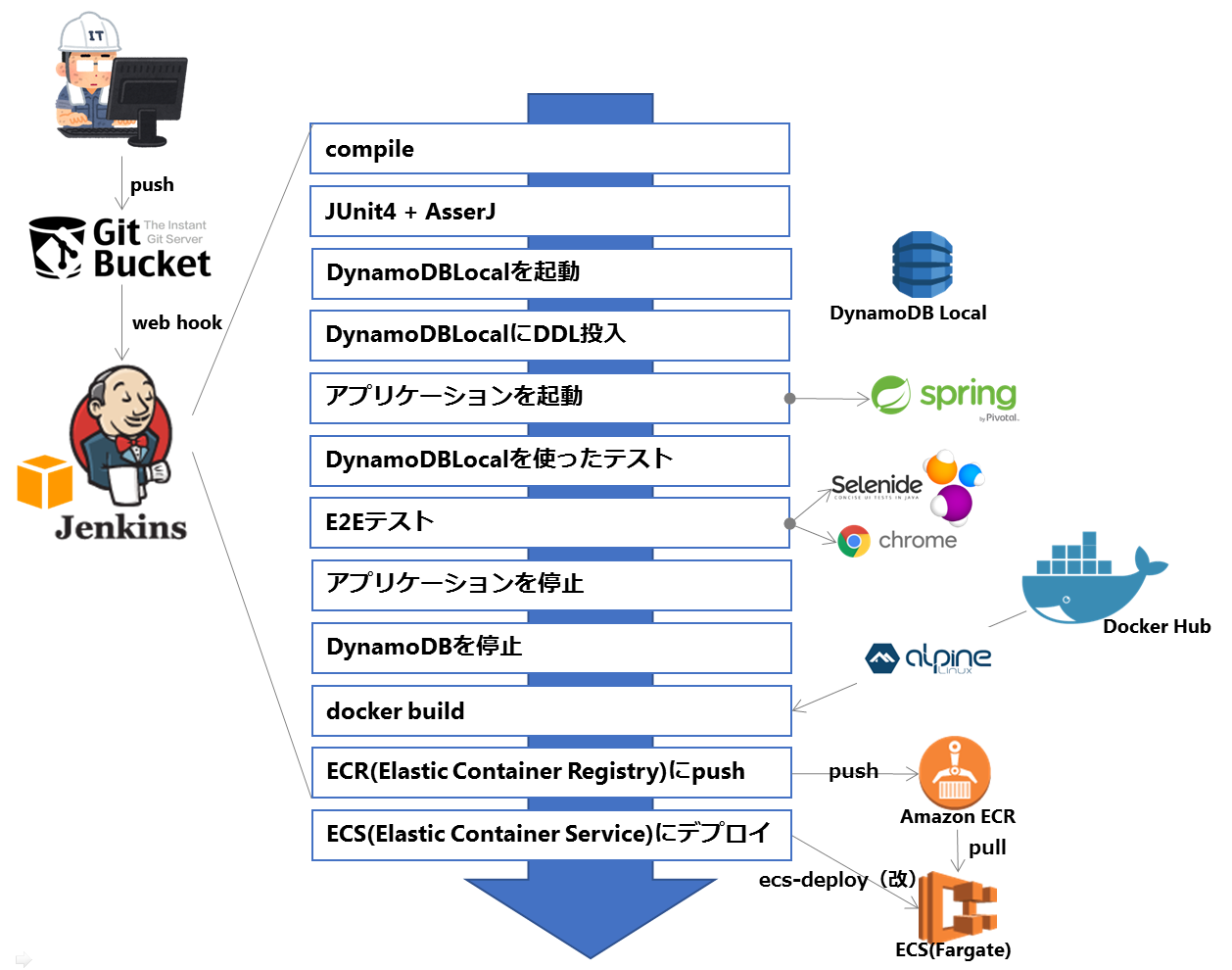
どんな技術を使っているのか
-
WEBアプリケーション
- SpringBoot 1.5.6 + Thymeleaf
- DBはDynamoDBだけ使っています。DynamoDBアクセスのフレームワークは自前で実装しました。
-
DynamoDBLocal
- DynamoDBをローカルで起動することができます。
- インメモリで起動できるので、CIで起動して最後に落とすことでデータの後始末をする必要が無くなるのも良いですね。
-
Selenide
- Seleniumのラッパーライブラリです。こんなところが気に入って使っています。
- CSSSelectorで書ける(とにかく記述量が減る)
- テストコードとCSS Selectorの記述がスパッと分離できる
- 環境変数でDriverなどが簡単に切り替えられる。(一部は自前で実装)
- 画面ロード時の細かいWaitやテスト失敗時の画面キャプチャとか自前で拡張していた部分が不要
- Seleniumのラッパーライブラリです。こんなところが気に入って使っています。
-
E2Eテストのためのブラウザ
- PhantomJSのメインコミッタが抜けるってニュースをみて、思い切ってChrome Headlessを使い始めました
- chromedriverは2.33を利用してますが特に問題なく使えてます。
- 後でも出てきますが、よいこのみんなはAmazonLinuxでchrome headlessを動かそうとすると面倒だからやめておこう。
-
コンテナで使うOSイメージ
- ビルド時間が長くなることからもCentOSとか使ってられないなーと思ったのでAlpine Linuxに乗り換えました。
- 開発環境はopenjdkのalpine linuxをベースにしてロケールの設定をいれてるくらいです。
- ログドライバの設定(fluentd)も入れていたけど開発環境だからFargateが勝手に設定してくれるCloudWatchLogsを利用してます。
-
Dockerリポジトリ
- **ECR**を利用
- DockerHubはprivateリポジトリ1つだけしか持てないし。automation buildするわけでもないし。
- EC2にartifactory立てたりもしたんだけど、それも運用しないといけないのかと思うとちょっとバカバカしくなって辞めました。
- 決め手は、これら外部のコンテナを使うとID/PWの管理をしないといけないんだけど、AWSにはSTSという素晴らしい仕組みがあるので乗っかった方が良いと判断しました。
-
コンテナオーケストレーションソフトウェア
- **AWS Fargate**を使い始めました。
- 先月まではECS(EC2)をSpot Fleetで使っていたんだけどFargateを使いたいという好奇心に負けた。(もちろん価格はFargateの方が高くつきます)
- ECS(Fargate)はus-east-1で動かしている。
- ap-northeast-1は本番で利用しようとしていますが、DynamoDBにはスキーマみたいな概念がないので、同一リージョンに同じテーブルをのせることができないため仕方なく。でもこれがきっかけでFargate触れたし良いかなという気がしてる。
-
ECS(Fargate)へのデプロイスクリプト
- ECS(EC2)の時はsilinternational/ecs-deployを使ってデプロイしていたが、Fargateには対応していなかったのでforkして直して使っています。
- ecs-deployはただのshellなので持ち運び便利ですよ。Fargate対応版はこちら。
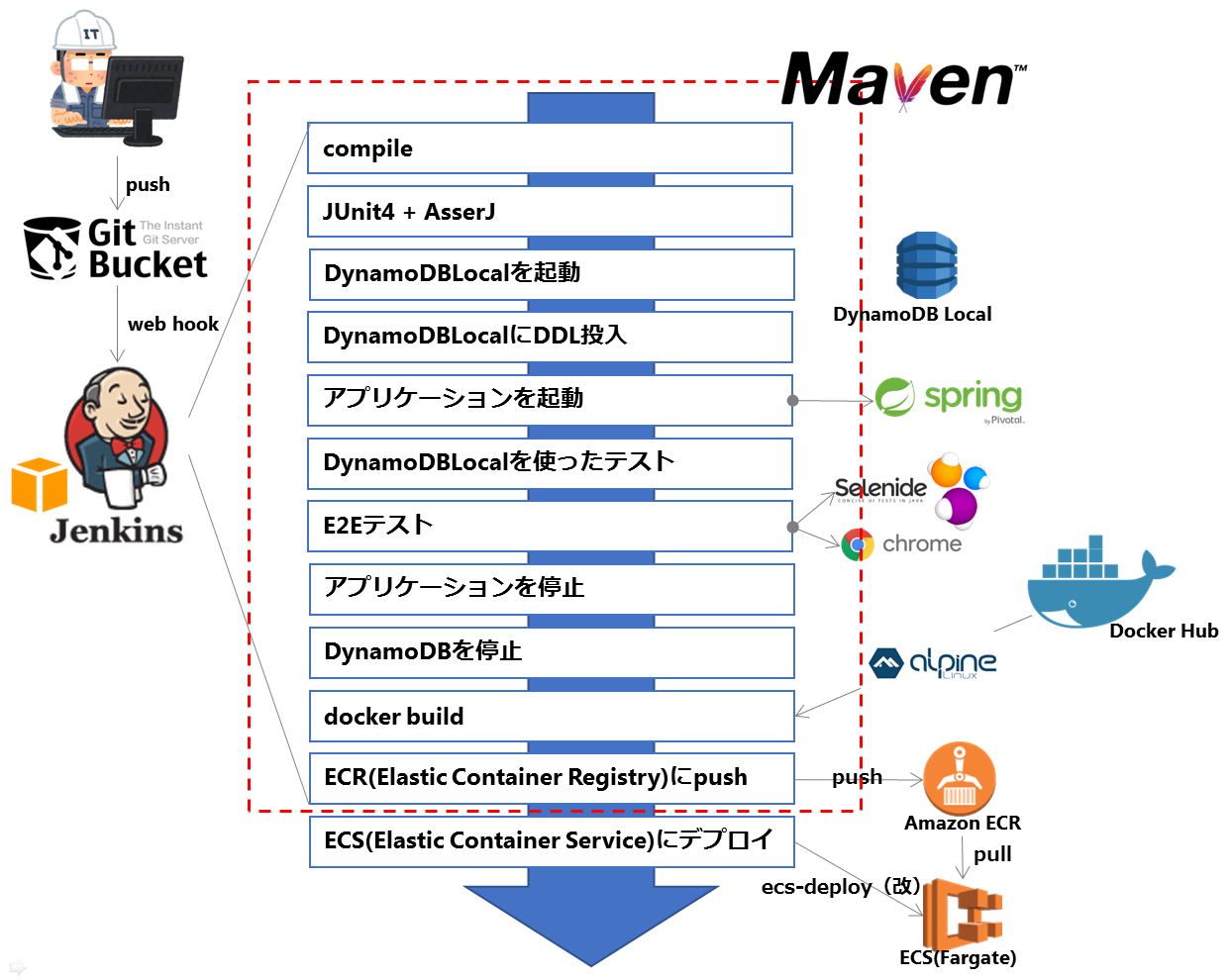
どうやってやってるのか
- Jenkinsからこれらのタスクを動かす時に初めはshellでゴリゴリ書いてましたが思ったよりメンドクサイです。
- 色々試行錯誤しましたけどFargateへのデプロイ以外は、
mvn installだけでできます。
実践編
DynamoDBをローカルで利用する
- DynamoDBをローカルで利用するにはDynamoDBLocalという公式のモジュールを利用します。
- 私はDocker上に浮かべて使っています。このへんはググると色々な記事が出てきますし、特にハマるポイントもないので割愛します。
- ちなみにGUIもついてくるんですがnodeで書かないといけないので使ってません。
DynamoDBへアクセスするテストを自動化する
- DynamoDBLocalのAWSのマニュアルを見ているとH2のようにインメモリで動かせるようです。
- インメモリで動かせるとデータの消し忘れとかないのでこれは使わない手はないですね。
- このような手順で動かせないかなと考えました。
- 1.DynamoDBをインメモリで起動
- 2.テーブルを作成
- 3.テストを動かす
- 4.DynamoDBを停止(データも消える)
- 利用する環境がWindowsとLinuxが混じるので、起動したりテーブル定義の作成にshellやbatで強引になんとかするってのは避けたいなーなんて思っていました。
- おとなしくmavenのプラグインを作り始めてたんですが、ダルイ、ダルすぎる。ということで。。
jcabi-dynamodb-maven-plugin
- こんなことができます。
- pre-integrationタスクでDynamoDBLocalの起動ができる
- DynamoDBLocal起動後に指定したテーブル定義のスクリプトを実行できる
- post-integrationタスクでDynamoDBLocalの停止ができる
- DynamoDBの起動時に各種パラメータを設定可能(起動場所、inMemoryモード、ポート番号とか)
- ライセンスおよび著作権表示をすれば、個人利用も商用利用も可能なようです
DynamoDBLocalのダウンロード・起動・DDL投入・テスト・停止までの流れ
- 少し詳しく解説するとこんな感じの流れになります。
- 1.maven-dependency-pluginでDynamoDBLocalをダウンロードしてdynamodb-distに配置
- 2.jcabi-dynamodb-maven-pluginを使ってdynamodb-distからDynamoDBを${dynamodb.port}で指定されたポートで起動する
- 3.起動後、
<tables>に書いてあるテーブル作成のスクリプトが動きます。
- テーブルのjsonが手っ取り早く欲しい人はこんなのを使ってみてください
pom.xml
<plugins>
<plugin>
<artifactId>maven-dependency-plugin</artifactId>
<version>2.8</version>
<executions>
<execution>
<id>unpack-dynamodb-local</id>
<goals>
<goal>unpack</goal>
</goals>
<configuration>
<artifactItems>
<artifactItem>
<groupId>com.jcabi</groupId>
<artifactId>DynamoDBLocal</artifactId>
<version>2015-07-16</version>
<type>zip</type>
<outputDirectory>${project.build.directory}/dynamodb-dist</outputDirectory>
<overWrite>false</overWrite>
</artifactItem>
</artifactItems>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>com.jcabi</groupId>
<artifactId>jcabi-dynamodb-maven-plugin</artifactId>
<version>0.9.1</version>
<executions>
<execution>
<goals>
<goal>start</goal>
<goal>create-tables</goal>
<goal>stop</goal>
</goals>
<configuration>
<port>${dynamodb.port}</port>
<dist>${project.build.directory}/dynamodb-dist</dist>
<arguments>
<argument>-inMemory</argument>
<argument>-sharedDb</argument>
</arguments>
<tables>
<table>${basedir}/src/main/resources/ddl/Asset.json</table>
<table>${basedir}/src/main/resources/ddl/AssetGroup.json</table>
<table>${basedir}/src/main/resources/ddl/AssetRole.json</table>
<table>${basedir}/src/main/resources/ddl/Contract.json</table>
<table>${basedir}/src/main/resources/ddl/Invitation.json</table>
<table>${basedir}/src/main/resources/ddl/Member.json</table>
<table>${basedir}/src/main/resources/ddl/Organization.json</table>
<table>${basedir}/src/main/resources/ddl/OrgKey.json</table>
<table>${basedir}/src/main/resources/ddl/OrgMember.json</table>
<table>${basedir}/src/main/resources/ddl/Role.json</table>
<table>${basedir}/src/main/resources/ddl/Service.json</table>
<table>${basedir}/src/main/resources/ddl/Tag.json</table>
</tables>
</configuration>
</execution>
</executions>
</plugin>
<plugins>
- integrationタスクで動くので以下のコマンドを実行するとDynamoDBの起動~テスト~停止ができちゃいます。
mvn verify
- integration testはデフォルトではITと名前が付くクラスしか動きません。私はテストクラスにITという名前を付けるのが嫌だったので、Categoryを使って指定しています。
E2Eテストの自動化
- E2Eテストもintegration testの流れでやりたくなってきました。
- 私はSelenideを使っています。こんなところが気に入ってます。
- 設定がシステムプロパティで設定できる(Configuration)
- Headlessの切替はシステムプロパティの設定でできませんでしたが、できるように少し改良しました。
- staticインポートしておくと
$("#id")みたいにCSSSelectorで実装できるため記述量がSeleniumに比べて激減。 - Pageパターンが気に入った
- JUnitのテストクラスからCSSSelectorの記述を追い出すことができるので何をテストしているのかが分かり易い
- 設定がシステムプロパティで設定できる(Configuration)
SpringBootのアプリケーションを起動する
- spring-boot-maven-pluginを使うとpre-integrationで起動してpost-integrationで停止する。ということが簡単にできます。
pom.xml
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<mainClass>jp.gr.java_conf.uzresk.puzzle.web.WebApplication</mainClass>
<profiles>
<!-- application-integration.ymlを使ってアプリケーションを起動させる -->
<profile>integration</profile>
</profiles>
</configuration>
<executions>
<execution>
<id>pre-integration-test</id>
<goals>
<goal>start</goal>
</goals>
</execution>
<execution>
<id>post-integration-test</id>
<goals>
<goal>stop</goal>
</goals>
</execution>
</executions>
</plugin>
- integration用のprofileも合わせて用意しておき、integrationの場合はport 18080で起動するように設定しました。
application-integration.yml
server:
port: 18080
settings:
dynamodb:
host: localhost
port: 10000
region: ap-northeast-1
ローカル環境とCIの環境差分を吸収する
- JUnitでSelenideのコードを書いて実行すれば動きますが環境の差分がありますよね。
| 環境 | 起動ポート | Chrome |
|---|---|---|
| ローカル | 8080 | Headless=false |
| Jenkins | 1800 | Headless=true |
- Selenideを動かす前の
@BeforeClassでは-D(system property)で各種設定ができるようにしています。
@BeforeClass
public static void beforeClass() {
// ベースURLを変更する (デフォルト:http://localhost:8080)
String webApplicationPort = System.getProperty("webapp.port", "8080");
Configuration.baseUrl = String.format("http://localhost:%s/app/",webApplicationPort);
// デフォルトのDriverをChromeDriverにする
Configuration.browser = System.getProperty("selenide.browser", WebDriverRunner.CHROME);
System.setProperty("webdriver.chromedriver", System.getProperty("webdriver.chromedriver", "./drivers/chromedriver.exe"));
// headless
Configuration.headless = Boolean.parseBoolean(System.getProperty("selenide.headless", "false"));
}
- integration testはmaven-failsafe-pluginで設定しますがここでポート、ChromeDriverの場所、Headlessか否かを切替えています。
pom.xml
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-failsafe-plugin</artifactId>
<version>2.11</version>
<configuration>
<includes>
<include>**/*.class</include>
</includes>
<groups>
jp.gr.java_conf.uzresk.puzzle.web.test.IntegrationTest
</groups>
<summaryFile>${report.dir}/failsafe-summary.xml</summaryFile>
<reportsDirectory>${report.dir}</reportsDirectory>
<!-- CI用の設定 -->
<systemPropertyVariables>
<webapp.port>18080</webapp.port>
<selenide.headless>true</selenide.headless>
<webdriver.chromedriver>./drivers/chromedriver</webdriver.chromedriver>
</systemPropertyVariables>
</configuration>
<executions>
<execution>
<goals>
<goal>integration-test</goal>
<goal>verify</goal>
</goals>
</execution>
</executions>
</plugin>
<plugins>
ChromeをAmazonLinuxにインストールする
- 実はこれに一番時間がかかりました。
- AmazonLinuxはCUIが前提となっているOSなのでGUI系のモジュールが全く入っておらず、Amazonのyumのリポジトリからも取れないので別のところから引っ張ってきたりして一つ一つ依存関係を解決していかなければならないです。あっちのモジュールの依存関係を解決するとこれが解決できない。の繰り返しでとても時間がかかりました。
-
結論は・・・
- AmazonLinuxでchrome動かそうとするとハマる。
- DebianかCentOS7/Redhat7を使っとけ。
- AmazonLinuxを使っている場合でも、クラウド使ってんだったらJenkinsのSlaveをCentOS7にしてJOBを動かしとけ。
- それでも挑戦したい人はこちらを参考にしながらやりましたのでどうぞ。
-
INSTALLING GOOGLE CHROME ON CENTOS, AMAZON LINUX, OR RHEL
- ここで紹介されているパッケージング化されているChromeは古いので結局HardWayを進むしかないです。
-
Having trouble installing Google Chrome -- where can I find dependencies?
- AWSのアカウントが必要です。
-
INSTALLING GOOGLE CHROME ON CENTOS, AMAZON LINUX, OR RHEL
さて、ここまででDynamoDBをローカルで起動してテストして、画面周りのテストもできました。
じゃあ、デプロイしてみましょう。
デプロイ
Dockerfileを用意する
- Dockerfileを用意します。SpringBootの公式ブログを参考にするのが良いと思いますが最低限これだけかけば問題ないと思います。
FROM openjdk:8u131-jdk-alpine
LABEL maintainer "uzresk"
RUN apk --update add tzdata && \
cp /usr/share/zoneinfo/Asia/Tokyo /etc/localtime && \
apk del tzdata && \
rm -rf /var/cache/apk/*
VOLUME /tmp
ARG JAR_FILE
ADD ${JAR_FILE} xxx-web.jar
ENTRYPOINT ["java","-jar","/xxx-web.jar"]
docker buildとECRへのpush
- Dockerfileを使ってコンテナにするにはspotify / dockerfile-mavenを使います。
- buildで作られたjarをDockerfileの引数にしてコンテナを作成し、
<repository>に指定されているところにpushします。 - 認証が必要な場合はsettings.xmlに設定が必要ですが、私の環境はJenkinsが起動しているEC2インスタンスにECRへpush出来るようにするためのロールを振っていることと、docker loginは事前にJenkinsで実行しているため設定しなくても大丈夫です。
<!-- Dockerfileからコンテナを作ってECRにデプロイ -->
<plugin>
<groupId>com.spotify</groupId>
<artifactId>dockerfile-maven-plugin</artifactId>
<version>1.3.6</version>
<configuration>
<repository>xxxx.dkr.ecr.ap-northeast-1.amazonaws.com/xxx-web</repository>
<tag>${project.version}</tag>
<buildArgs>
<JAR_FILE>target/${project.build.finalName}.jar</JAR_FILE>
</buildArgs>
</configuration>
<executions>
<execution>
<id>default</id>
<phase>install</phase>
<goals>
<goal>build</goal>
<goal>push</goal>
</goals>
</execution>
</executions>
</plugin>
詰まったところ
-
Pushing to private registry fails with 'No basic auth' for older style config.json
- Jenkinsでdocker login後にsedしてhttps://を.docker/config.jsonにつけて一旦回避しています。
Fargateへのデプロイ
- ECS(LaunchTypeEC2)の時には、ecs-deployというshellを使っていましたが、Fargateに対応できていません。
- forkしてFargateへのデプロイに対応できるようにしてありますので良ければ使ってください。使い方はecs-deployと全く同じです。
Jenkinsの設定
- 事前準備としてdocker loginしておきましょう。
- aws ecs get-login・・・を打つことでdocker loginコマンドが返ってくるのでevalでそのまま実行しています。
- dockerの17.06以降は--no-include-emailオプションが必要ですのでお忘れなく。
docker logout xxxx.dkr.ecr.ap-northeast-1.amazonaws.com
eval $(aws ecr get-login --no-include-email --region ap-northeast-1)
# dockerfile-maven-pluginでconfig.jsonにhttps://がないと失敗する
sed -i 's/xxxx/https:\/\/xxxx/' ~/.docker/config.json
- mavenを実行します。
mvn install
- ecs-deployを実行します
chmod +x $WORKSPACE/web/bin/ecs-deploy
$WORKSPACE/web/bin/ecs-deploy -c web-cluster -n web-service -i xxxx.dkr.ecr.ap-northeast-1.amazonaws.com/xxxxxx-web:0.0.1-SNAPSHOT -t 600 -r us-east-1
- 新たにタグ付されたので、タグが外されたdocker imageを消しときます
docker images | grep "[image name]" | grep "<none>" | awk '{print $3}' | xargs docker rmi
さいごに
- pushされたタイミングでこのサイクルを動かしているのですがテスト完了までは約3分30秒くらいなので今のところ問題なく運用できています。
- もう少しアプリが育ってきたら時間がかかるE2Eテストの部分はJenkinsのSlaveで動かせないかと思っています。ここをFargate上で並列に動かせれば面白そうですね。