第1回、第2回、第3回を通して、UiPath Studioを使用してゼロからワークフローを作成し、英語と日本語のドキュメントの分類や抽出、そして結果の検証ができました。しかし、このワークフローにはエラー処理やログ出力、無人オートメーションなどが考慮されておらず、実際の業務にはまだ耐えられないという問題があります。
今回の記事では、UiPath Studioに付属しているDocument Understanding Processのテンプレートを利用して、ドキュメントの処理を行います。
1. テンプレートの概要紹介
Document Understanding Process(テンプレート)は、ドキュメント処理のフローをベースにしたUiPath Studioのプロジェクトテンプレート です。
このテンプレートには、ログ出力、例外処理、リトライなど、Document Understandingワークフローで必要なすべてのメソッドが、オプションとして提供されています。
UiPath Studioを起動して、[スタート]パネル右側の[テンプレートから新規作成]より[Document Understanding Process]を選択して利用可能です。
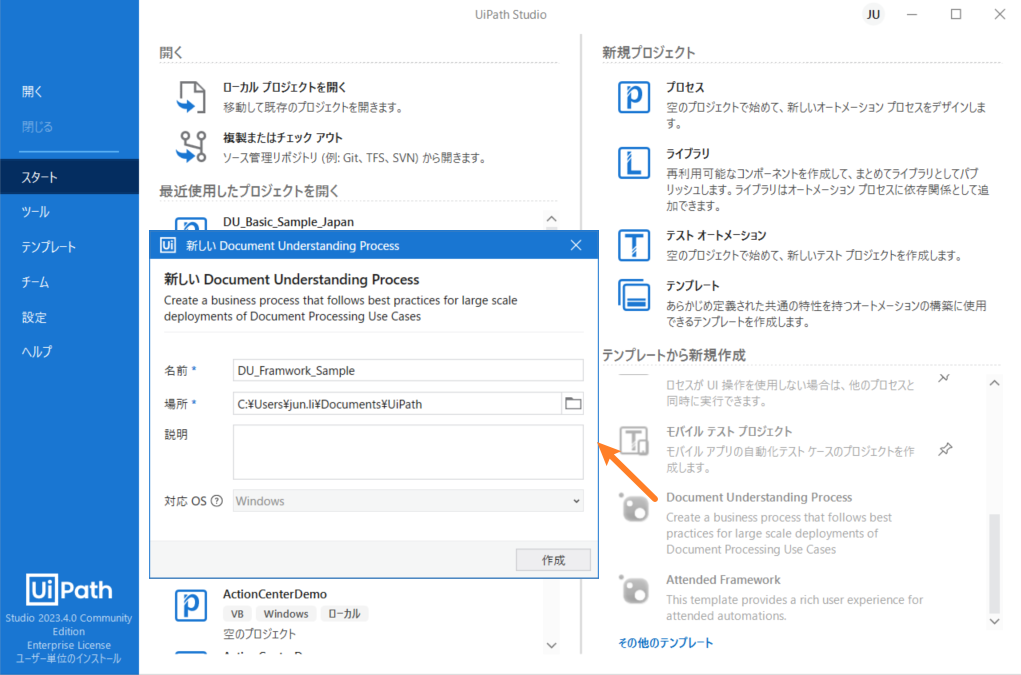
UiPath Document Understanding Processのテンプレートの構成を見る前に、先にドキュメント処理のフローを見ましょう。
2. ドキュメント処理フロー
第1回から第3回まで、以下の処理フローで実装しました。

これから紹介するテンプレートでは、以下の図のようなフローを提供し、必要な処理ロジックが全て含まれています。赤い枠の処理は、上記のフローには含まれていない追加の処理です。(*画像をクリックすると、別ページで大きな画像が表示されます)

実際の処理では、ユースケースによって必要なロジックが異なり、複数のロジックが一つに統合されたり、不要となったりすることがあります。そのため、上記のフローチャートよりもシンプルになることがあります。
フロー図での処理の中身を見てみましょう。
| 処理名 | 処理内容 |
|---|---|
| タクソノミー定義 | ドキュメントの論理的な種類や特定のドキュメントの種類で検出・取得が期待される情報の定義です |
| デジタル化の前処理 | ドキュメントをデジタル化する前に必要な処理。例:グレースケールの適用、歪みの補正など。 |
| ドキュメントのデジタル化 | ドキュメントのデジタル版が作成されます。スキャンされたドキュメントの場合、指定されたOCRエンジンが使用されます。 |
| ドキュメントの分類 | ドキュメントが分類されます。 |
| 分類成功かの判断 | 分類が成功したかどうかを決定するために必要なビジネスロジックが含まれます。この決定に基づいて、分類の検証が必要になる場合があります。補足1 |
| 人間による分類結果の検証 | 自動分類が失敗した場合(または信頼性が低すぎる場合)、文書を人間のオペレーターに送信して、手動で分類/検証(または処理に適さない場合は拒否)します。 |
| 分類結果のフィードバック | 分類器の学習メカニズム(ある場合)の統合。補足2 |
| データ抽出の前処理 | 実際のデータ抽出が始まる前に必要な処理。例:同じ入力ファイル内に複数の文書がある場合、それらを適切に分割します。 |
| データ抽出 | 適切な抽出器を使用してデータを抽出します。 |
| 人間による検証するか | このステップには、抽出されたデータの人間による検証が必要かどうかを決定するために必要なビジネスロジックが含まれます(信頼度レベル/OCR信頼度/欠落データのチェックなど)。 補足1 |
| 人間による抽出結果の検証 | 人間のオペレーターが自動的に抽出されたデータを修正したり、欠落したデータを手動で抽出したりできます。 |
| 抽出結果のフィードバック | 抽出器の学習メカニズム(ある場合)の統合。補足2 |
| 抽出結果の後処理 | 抽出されたデータをエクスポートする前に、関連する処理を行います。例:データを特定のフォーマットに変換することです。 |
| データエクスポート | 他のプロセスまたはビジネスユーザーで使用できるように、データをエクスポートすることです。 |
| データエクスポートの後処理 | エクスポートされたデータを処理することを意味し、例えば、複数の文書から抽出されたデータを単一の結果にマージすることが挙げられます。 |
- 補足1: 人間の検証が必要かどうかを決定するのはビジネス上の決定です。
- 補足2: 人間によって検証されたデータだけでトレーニングすることが推奨されますが、必須ではありません。
3. テンプレートの全体構成
ドキュメント処理フローの全体像が理解できたら、それに対応したテンプレートの全体構成を確認しましょう。
先ほど作成したUiPath Studioのプロジェクトの「DU_Framwork_Sample」を開いて、左側のプロジェクトパンネルの各ファイルとファイルの中身は以下の通りです。

- Data フォルダ:処理対象のドキュメント、処理済みの出力ファイル、設定ファイル
- DocumentProcessing フォルダ:分類や抽出をする際に、利用される設定ファイル
- Framework フォルダ:上記のドキュメント処理フローに沿った各処理のワークフロー
- Main-ActionCenter.xaml:無人オートメーションとして実行する際のメインワークフロー(入口)
- Main-Attended.xaml:有人オートメーションとして実行する際のメインワークフロー(入口)
3.1 実行してみよう
テンプレートより作成したプロジェクトを実行して動作を確認します。先に必要最低限な環境設定をします。
環境設定
プロジェクトを実行する前に、設定する項目があります。[Data\Config.xlsx]を開いて、「Assets」シートを確認します。「Assets」シートで記載している項目は、Orchestratorに設定するアセット補足です。この中で必須設定になっているのはDocumentUnderstandingApiKeyです。以下の手順で設定します。
-
UiPath Cloudの管理ページ
https://cloud.uipath.com/**組織名**/portal_/adminへアクセスして、ライセンスボタンをクリックします。 -
ライセンスの管理画面で、ロボットとサービスタブに切り替えて、以下の画面のように、DocumentUnderstandingのAPIキーを取得して、メモに書きます。

-
次に、Orchestratorのフォルダに該当APIキーのアセットを作成しますので、Orchestratorの画面に遷移してください。
-
プロセスが実行するフォルダ(例:AIOCRフォルダ)を選択して、上のアセットタブをクリックして、次に新しいアセットを作成をクリックします。

-
[Data\Config.xlsx]「Assets」シートでのアセット名
DocumentUnderstandingApiKeyをアセット名にして、アセット値のTextが先程メモしたAPIキーを入力して、作成します。

補足:
アセットとは通常、異なるオートメーション プロジェクトで使用可能な共有の変数または資格情報を意味します。アセットを使用して固有の情報を保存することで、ロボットがその情報に容易にアクセスできるようになります。詳細な情報はアセットについてをチェックしてください。
補足:
Studioで「デバッグ」モードで実行する際に、エラーが発生しますので、「Assets」シートで不要な項目を一旦削除します。

Studioで「実行」モードで実行すると、異常処理があるため、エラーが発生しないです。
ワークフロー実行
環境設定が完了したら、ワークフローを実行してみましょう。UiPath Studioから実行する際には、アセットを使用するため、UiPath Studioで選択しているフォルダはアセットの存在フォルダである必要があります。

- テンプレートでは、デフォルトとして、
Main-ActionCenter.xamlになっています、これが無人オートメーション実行時利用するワークフローです。今回のまず有人オートメーションで実行するので、以下のように変更して、Main-Attended.xamlをメインに設定してください。

Studio ワークフローアナライザーが有効化にしている場合は、ワークフロー実行する際に、Error ST-DBP-024 Persistenceのエラーが発生しますので、Main-ActionCenter.xamlファイルを「パブリッシュから除外」にしてください。
-
UiPath Studioからワークフローを実行します。
-
実行開始したら、次のようなファイル選択のダイアログが表示されますので、プロジェクトフォルダ内の[Data\ExampleDocuments\MergedDocuments.pdf]ファイルを選択してください。

-
UiPath Studioでの出力パネルを確認して、どんな処理がされているかを確認してみてください。
-
実行が進むと、UiPath 分類ステーションが表示されます。1つのPDFファイルに複数のページが含まれているため、ページ数の分が分類されます。分類が正しいか確認してください、問題なければ保存をクリックしてください。

-
次に、抽出結果の検証になるので、UiPath 検証ステーションが表示されます。分類ステーションと異なって、こちらは一回の表示で一ページのドキュメントです。抽出結果が正しいか確認して、問題なければ送信をクリックしてください。

残りのページの抽出結果の検証ステーションも同様ですので、ここで説明を省略します。 -
これで一通り実行が完了したら、プロジェクトの[Data\Exports]に抽出結果のExcelファイルが作成されますので、確認してみてください。
3.2 プロジェクトファイルの詳細
テンプレートを利用して、自身のビジネスケースに合わせてカスタマイズする前に、各プロジェクトファイルの中身や役割を理解する必要があります。
下記の各ファイルの説明はテンプレートの22.10版に基づいたものです。最新の説明はテンプレートのプロジェクトフォルダ内にある UserGuide\Document Understanding Process - User Guide.pdfをチェックしてください。
-
 Data\Config.xlsx
Data\Config.xlsx
プロジェクト全体の設定ファイルです。
必要に応じて設定してください。例えば、ActionCenterを利用する場合には、「Settings」シートでのStorageBucketNameを設定します。詳細に関しては、Config.xlsxファイルでのDescription欄をご参照ください。 -
Main-Attended.xaml
有人オートメーションのDocument Understandingプロセスのメインとして設定して使用するワークフローです。
設定するパラメータ:-
in_TargetFile: 処理するドキュメントのファイルパスです。デフォルトは
設定なしです。 -
in_UseQueue: Orchestratorでのキューを利用するかの設定です。デフォルトは
Falseです。Trueの場合は、in_TargetFileに値が設定されていても無視されます。処理するドキュメントファイルパスがOrchestrator キューから取得します。
-
in_TargetFile: 処理するドキュメントのファイルパスです。デフォルトは
-
Main-ActionCenter.xaml
無人オートメーションのDocument Understandingプロセスのメインとして設定して使用するワークフローです。
Action Centerを利用して人間による検証を行います。設定するパラメータ:-
in_TargetFile: 処理するドキュメントのファイルパスです。デフォルトは
設定なしです。 -
in_UseQueue: Orchestratorでのキューを利用するかの設定です。デフォルトは
Trueです。Trueの場合は、in_TargetFileに値が設定されていても無視されます。処理するドキュメントファイルパスがOrchestrator キューから取得します。
-
in_TargetFile: 処理するドキュメントのファイルパスです。デフォルトは
-
Framework\00_ReadConfigFile.xaml
実行時にConfigファイルの内容を辞書型の変数に読み込みます。(*Orchestratorでのアセットを取得しません。) -
Framework\00_ReadConfigFile.xaml
タクソノミとOrchestratorアセットをロードするワークフロー。プロセス固有の初期化コードはここに含まれます。 -
Framework\15_GetTransactionItem.xaml
Orchestratorキューを使用する場合にTransaction Itemを取得します。処理対象のドキュメントはTransaction ItemのSpecificContent内のTargetFileキーにあります。
また、Configの辞書型変数で使用しやすいように、すべてのTransaction ItemのSpecificContentをConfigの辞書型変数にロードします。 -
Framework\20_Digitize.xaml
デジタル化の前処理及びドキュメントのデジタル化のためのワークフローです。
ワークフローでUiPath Document OCRエンジンを使用しています。 -
Framework\30_Classify.xaml
ドキュメントの分類のためのワークフローです。
このワークフローでは、すべてのドキュメントタイプに対してインテリジェントキーワード分類器を使用しています。 -
Framework\35_ClassificationBussinessRuleValidation.xaml
分類成功かの判断のためのワークフローです。
分類成功を決定するためにカスタムロジックが必要であり、デフォルトではすべての結果が人間の検証に送信されます。 -
Framework\Framework\40_TrainClassifiers.xaml
分類結果のフィードバックのためのワークフローです。
このワークフローでは、すべての文書タイプに対してインテリジェントキーワード分類器トレーナーを使用しています。また、学習ファイルを更新する際のアクセスを調整するために、LockFile/UnlockFile再利用可能なワークフローも使用しています。 -
Framework\50_Extract.xaml
データ抽出の前処理とデータ抽出のためのワークフローです。
このワークフローでは、以下の四つの抽出器を利用しています。- 正規表現ベースの抽出器:定型証明書の抽出用
- インテリジェントフォーム抽出器:定型W-9書類の抽出用
- マシンラーニング抽出器:Receiptsの抽出用、既にトレーニング済のReceiptsのエンドポイントを利用してます
- マシンラーニング抽出器:Invoicesの抽出用、既にトレーニング済のInvoiceのエンドポイントを利用してます
抽出器の設定が以下の通りです。

-
Framework\55_ExtractionBussinessRuleValidation.xaml
人間による抽出結果の検証のためのワークフローです。
抽出成功を決定するために、プロセス固有のビジネスルールに基づくカスタムロジックが必要です。すべてのドキュメントを手動検証するためにフラグを設定することもできます。デフォルトでは、すべての結果は人間の検証に送信されます。 -
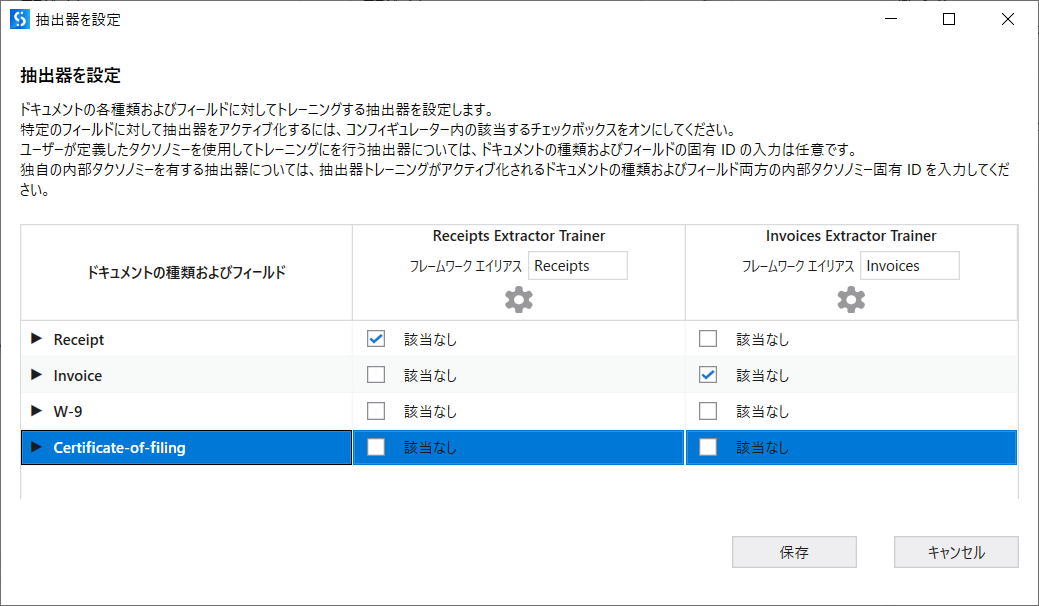
Framework\60_TrainExtractors.xaml
抽出結果のフィードバックのためのワークフローです。
このワークフローでは、以下の二つ抽出器トレーナーを利用しています。- マシンラーニング抽出器トレーナー:Receiptsの抽出用、既にトレーニング済のReceiptsのエンドポイントを利用してます
- マシンラーニング抽出器トレーナー:Invoicesの抽出用、既にトレーニング済のInvoiceのエンドポイントを利用してます
抽出器の設定が以下の通りです。
-
Framework\70_Export.xaml
抽出結果の後処理とデータエクスポートのためのワークフローです。
このワークフローでは、抽出したデータをExcelファイルに書き込むシンプルな仕組みを使用していますが、データサービス、データベース、CSV、JSON形式などに書き込みも可能です。 -
Framework\80_EndProcess.xaml
データエクスポートの後処理や片付けのためのワークフローです。 -
Framework\ReusableWorkflows\InvoicePostProcessing.xaml
デフォルトのOOTBモデルを使用して請求書の後処理のためのワークフローです。
チェックするルールセットは、Configファイルの専用シートに定義されています。ルールセットとロジックは、ビジネスプロセスに応じて必要に応じて更新する必要があります。 -
Framework\ERR_HandleDocumentError.xaml
分類された文書の処理中に例外が発生した場合に実行されるワークフローです。 -
Framework\ERR_AbortProcess.xaml
プロセスが終了する例外が発生した場合に実行されるワークフローです。ここには、エラーのクリーンアップやエラー通知を送信するためのコードが含まれます。 -
Framework\ReusableWorkflows\GetWritePermission.xaml
分類器トレーニングファイルへの書き込みアクセスを調整するセマフォメカニズムとして、単一のキューアイテムを使用するヘルパーワークフローです。 -
Framework\ReusableWorkflows\GiveUpWritePermission.xaml
分類器トレーニングファイルへの書き込みアクセスを調整するセマフォメカニズムとして、単一のキューアイテムを使用するヘルパーワークフローです。 -
Framework\ReusableWorkflows\LockFile.xaml
簡易なロック/アンロック機能を使用して、分類器トレーニングファイルへの書き込みアクセスを制御するヘルパーワークフローです。 -
Framework\ReusableWorkflows\UnlockFile.xaml
簡易なロック/アンロック機能を使用して、分類器トレーニングファイルへの書き込みアクセスを制御するヘルパーワークフローです。 -
Framework\ReusableWorkflows\SetTransactionProgress.xaml
処理中のトランザクションアイテムのTransactionProgressを更新するワークフローです(キューを使用する場合)。 -
Framework\ReusableWorkflows\SetTransactionStatus.xaml
トランザクションのステータスを設定し、ログに記録するワークフローです。
4. 終わりに
本記事では、以下の点を説明しました。
- ドキュメント処理に必要な全てのステップ
- テンプレートを利用したプロジェクトを有人オートメーションとして実行する際に、必要な最低限環境設定
- 有人オートメーションとして実行する際の動き
- テンプレートでのファイル構成
次回では、テンプレートを利用して、日本語ドキュメントを処理する際に(有人オートメーション)、どのように修正するかを解説していきます。
参考情報