1. 日本語帳票を識別するため何が必要?
第一回と第二回では、英語の帳票を利用してデータの抽出を実施しました。第三回では、日本語の帳票(請求書と源泉徴収票)からもデータを抽出していきましょう。サンプルデータはこちらより取得してください。
日本語の帳票を分類・抽出するために、日本語に特化したOCRエンジンとエンドポイントが必要になります。例えば、分類器の設定が以下のように異なっています。
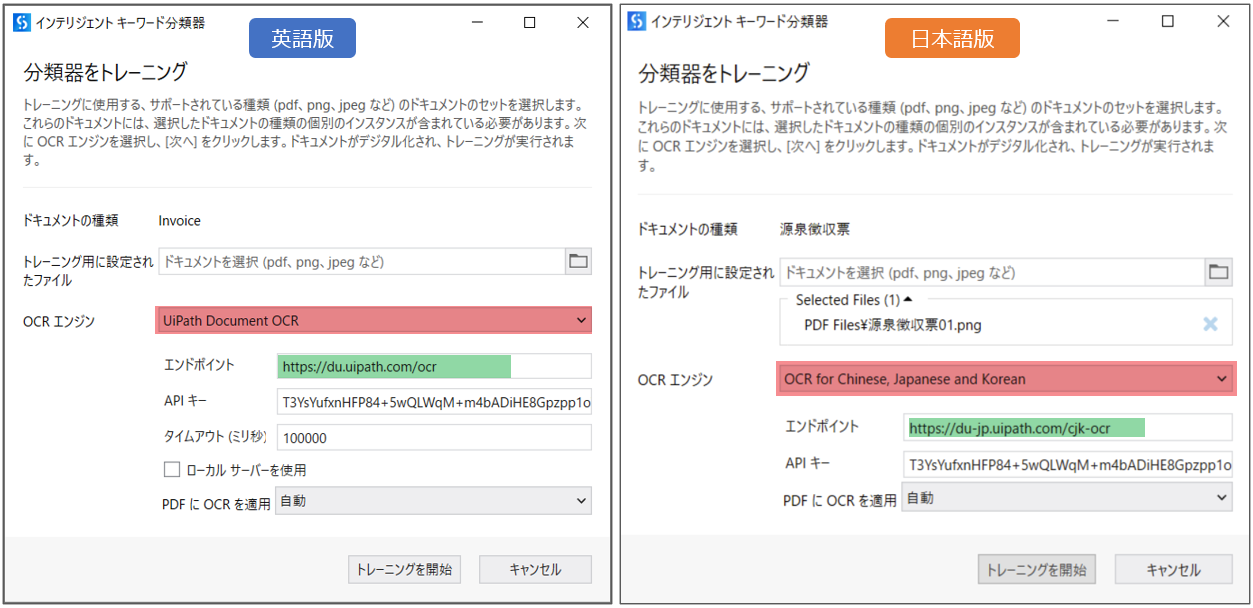
今回の解説は、UiPath Document Understanding 第1回 基礎編 複数種類のドキュメントからデータ抽出しよう をベースにしています。こちらでは、第一回との差分の部分だけを解説します。 第一回をまだ読んでいない方は、そちらを先にチェックしてください。
それでは、第一回のワークフローをDU_Basic_Sample_第一回.zipからダウンロードして、日本語帳票の分類と抽出ができるように改修していきましょう!
2. タクソノミー定義の変更
利用する帳票が変ったので、抽出したい値も異なってきます。そのため、タクソノミーでの定義を変更する必要があります。
以下の処理はタクソノミーマネージャーから行います。
- 元の英語版帳票の定義を削除します。
- 日本語帳票と合わせて、フィールド名と種類の定義を追加します。
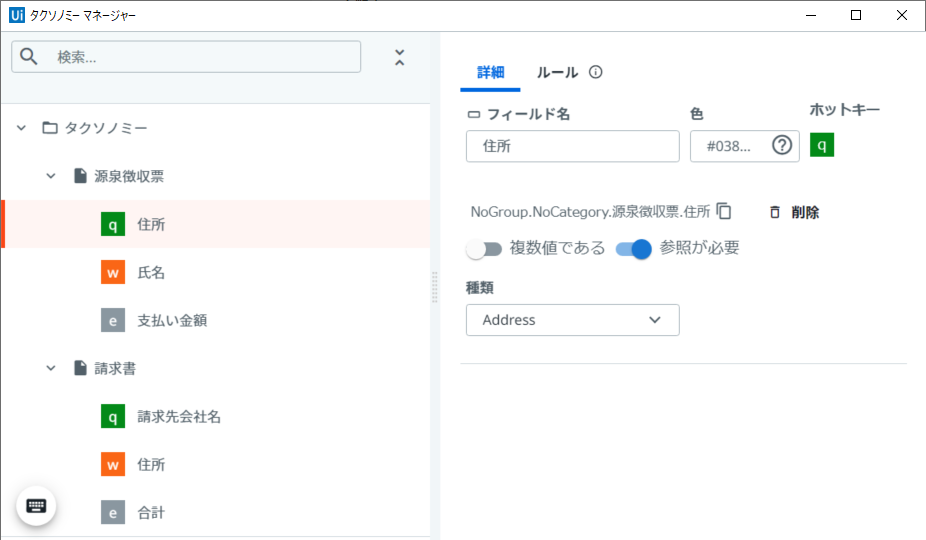
処理完了したら、タクソノミー マネージャーでの設定は以下の通りになります。
-
ドキュメント種類名:源泉徴収票
No フィールド名 種類 1 住所 Address 2 氏名 Name 3 支払い金額 Number -
ドキュメント種類名:請求書
No フィールド名 種類 1 請求先会社名 Name 2 住所 Address 3 合計 Number
3. 読み込みファイルのフォルダ変更
繰り返し (フォルダー内の各ファイル) アクティビティでのフォルダのパスは、ダウンロードした日本語帳票が保存されているフォルダのパスに設定します。
4. デジタル化の変更
日本語帳票をデジタル化するために、OCRエンジンの変更及びエンドポイントの変更が必要です。
手順:
- アクティビティ欄からドキュメントをデジタル化アクティビティを元のドキュメントをデジタル化アクティビティの下に配置します。
- 入力と出力パラメータの値を元のアクティビティからコピーします。
- デフォルトのOCRエンジンのUiPath ドキュメント OCRからOCR - 日本語、中国語、韓国語へ変更します。
- ドキュメントをデジタル化 アクティビティでのUiPath ドキュメント OCRを削除します。
- アクティビティ欄からOCR - 日本語、中国語、韓国語アクティビティを入れてください。
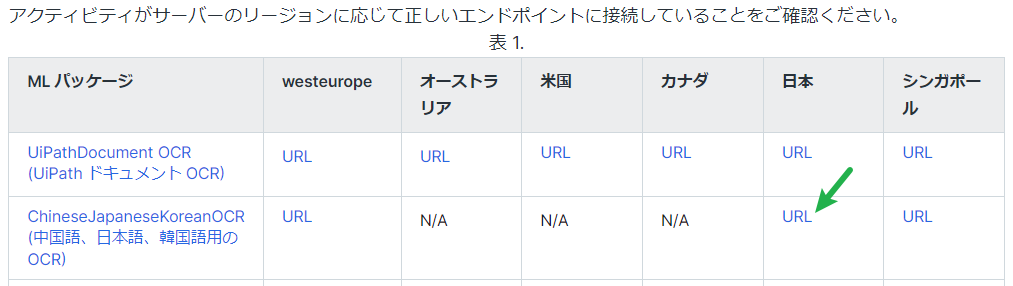
- 次はOCR - 日本語、中国語、韓国語アクティビティのエンドポイントに
"https://du-jp.uipath.com/cjk-ocr"補足を設定します。 - 元のドキュメントをデジタル化アクティビティを削除します。
補足
エンドポイントはこちらのパブリック エンドポイントから取得しています。
以上の設定ができたら、一旦Write Lineアクティビティを入れて、出力結果のstrDocumentTextを出力して、日本語帳票のデジタル化ができているかどうか確認してみてください補足。
補足:
分類器や抽出器などの設定がまだ英語版帳票になっているので、ワークフローを実行するとエラーになります。そのため、エラーになったアクティビティ(ドキュメント分類スコープ、データ抽出スコープ)をコメントアウトしてから実行してください。
5. 分類器の変更
利用するドキュメントが変ったため、分類する際のキーワードも変わってきます。インテリジェント キーワード分類器でのトレーニングも再度実施する必要があります。
手順:
-
前回作成したDocumentProcessing\classifierLearning.jsonでの中身を全て削除します。
-
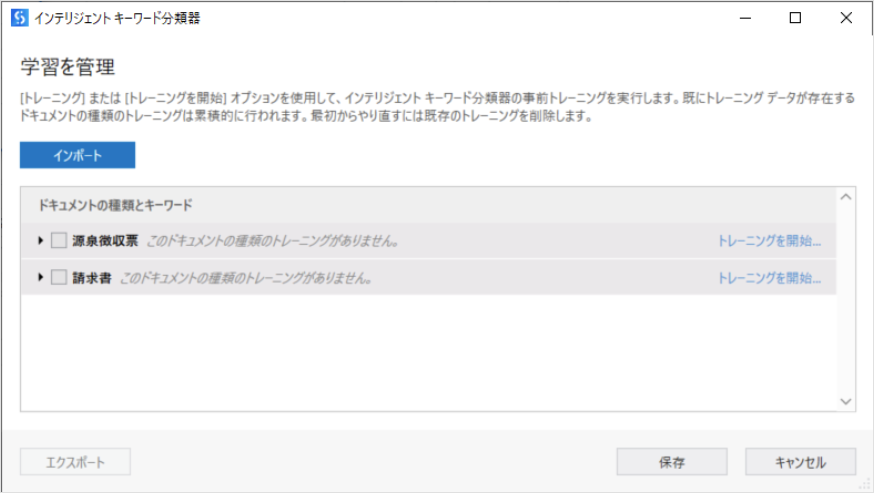
学習を管理をクリックします。
-
表示された以下の画面で、源泉徴収票のトレーニングを開始... をクリックします。
-
表示されたインテリジェントキーワード分類器画面では、以下のように設定します。
- トレーニング用に設定されたファイルに、源泉徴収票の帳票を選択してください。
- OCRエンジンをOCR for Chinese,Japanese and Koreanに変更してください。
- エンドポイントを
https://du-jp.uipath.com/cjk-ocrに変更してください。
-
設定が完了したら、以下の画面になり、トレーニングを開始をクリックします。
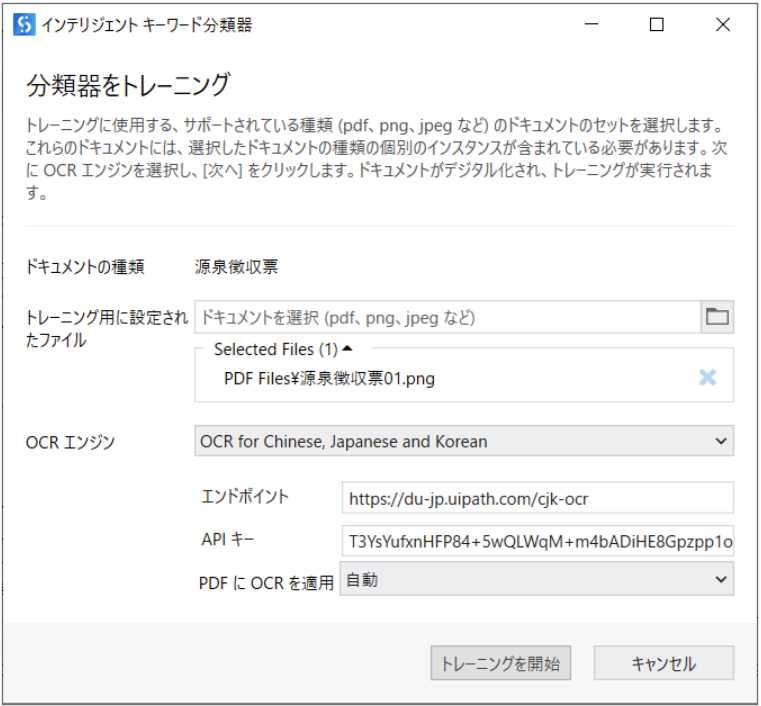
-
請求書も同じように、請求書帳票を選択してトレーニングをしてください。トレーニングが完了したら、それぞれ帳票のキーワードが抽出され、画面が以下のようになります。
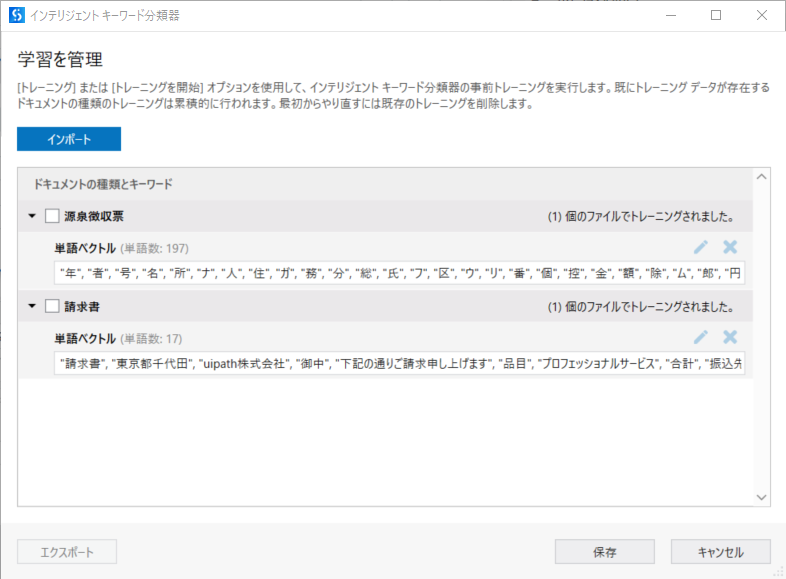
-
上記のインテリジェントキーワード分類器の保存をクリックします。
-
再度DocumentProcessing\classifierLearning.jsonを確認してみます。以下のように、日本語帳票の分類情報が記載されています。
classifierLearning.json[{"DocumentKeywordVectors":[{"TotalDocumentLength":7052,"PageCount":1,"FirstPageVector": {"VectorId":"NoGroup.NoCategory.源泉徴収票_1.FirstPage","DocumentCount":1,"TermsWithScores": [{"Score":1.0,"Term":"年","LastUpdated":"2023-04-06T19:35:42.4376317+09:00"}, {"Score":1.0,"Term":"者","LastUpdated":"2023-04-06T19:35:42.4376428+09:00"}, {"Score":0.99,"Term":"号","LastUpdated":"2023-04-06T19:35:42.4376137+09:00"}, {"Score":0.99,"Term":"名","省略":"省略"}, {"...":"..."} -
次は分類器を設定をクリックして、再度源泉徴収票と請求書に[インテリジェント キーワード分類器]をチェックしてください。
6. 抽出器(フォーム抽出器)の変更
分類器と同じように、抽出器の設定や再トレーニングが必要になります。
手順:
-
元のフォーム抽出器を削除して、新しいフォーム抽出器アクティビティを追加してください。
-
フォーム抽出器アクティビティでのエンドポイントに
"https://du-jp.uipath.com/svc/formextractor"を設定します。(パブリック エンドポイントからForm Extractor (フォーム抽出器) の日本のURLを利用) -
次はテンプレートを管理をクリックして、テンプレート マネージャーの画面が表示されます。
-
テンプレートを作成をクリックして、表示されたテンプレートを作成画面にて以下のように設定します。
- ドキュメントの種類:源泉徴収票(源泉徴収票は定型のドキュメントですので、フォーム抽出器を利用します)
- テンプレート名:源泉徴収票テンプレート
- テンプレートドキュメント:ダウンロードした源泉徴収票ファイルを選択します
- OCRエンジン:OCR for Chinese,Japanese, and Koren
- エンドポイント:
https://du-jp.uipath.com/cjk-ocr
-
最後に設定をクリックして、ドキュメントのデジタル化が開始されます。
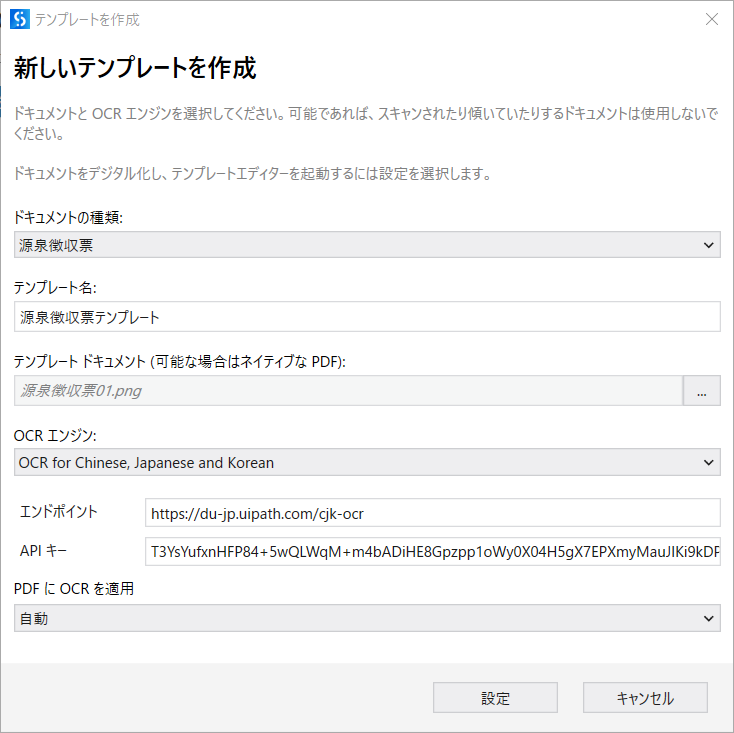
-
開始されたら、以下のようなテンプレート マネージャーが表示されます。
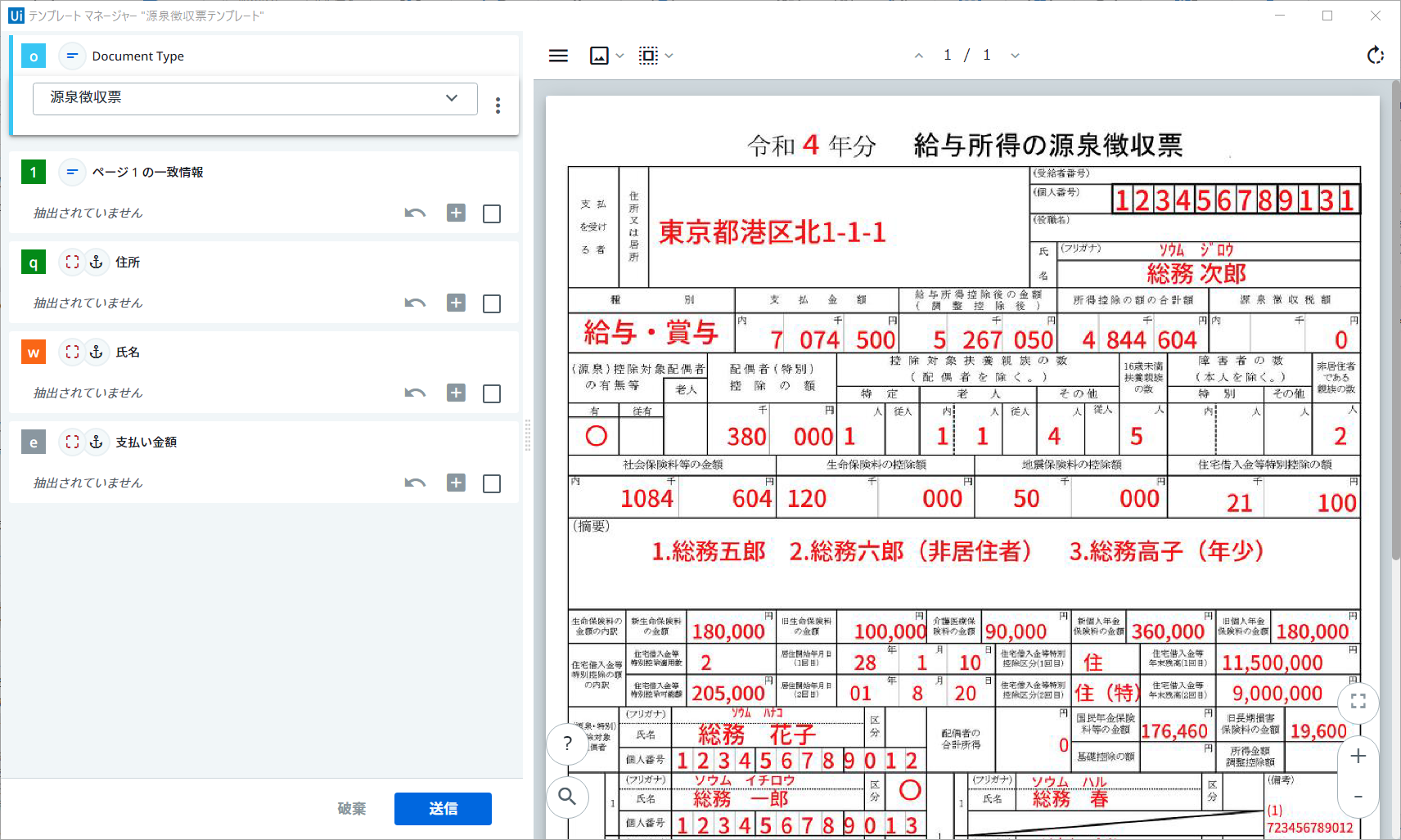
-
上記の設定方法は第一回のフォーム抽出器の追加と設定と同じですので、そちらを参照してください。
-
設定が完了したら、以下のような画面になります。
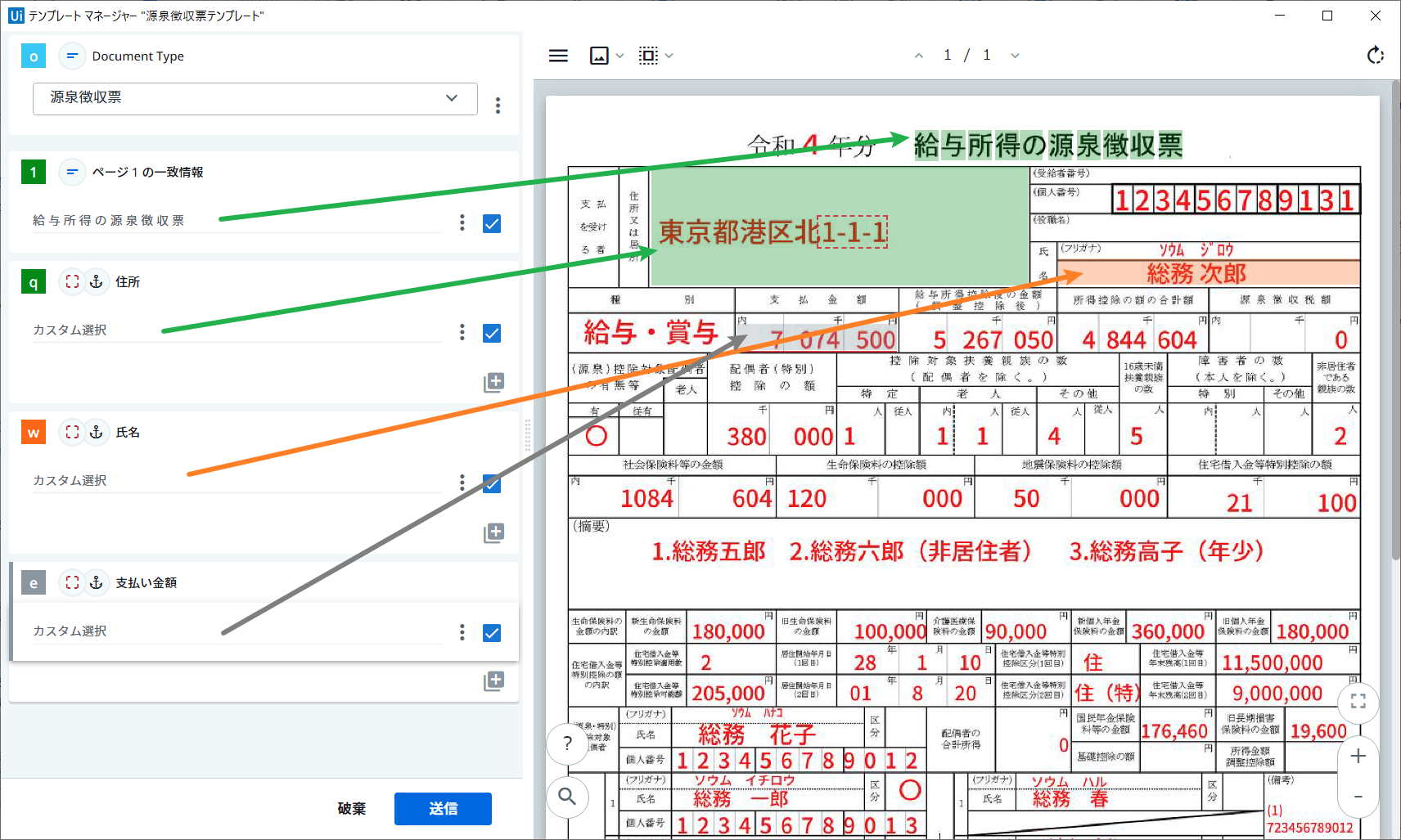
-
再度テンプレートマネージャー画面に戻ったら、源泉徴収票テンプレートをチェックして、閉じるをクリックします。
7. 抽出器(マシンラーニング抽出器)の変更
次に、日本語帳票に合わせてマシンラーニング抽出器の設定を変更します。
手順:
- 元のマシンラーニング抽出器を削除して、新しいマシンラーニング抽出器アクティビティを追加してください。
- 表示されたマシンラーニング抽出器画面でのエンドポイントに、
https://du.uipath.com/ie/invoices_japanを設定します。(パブリック エンドポイントより取得)補足
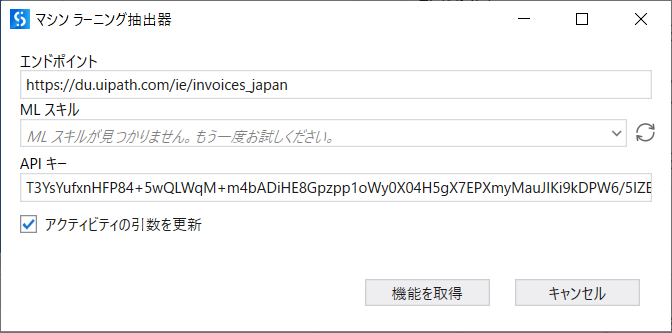
- 上記画面での機能を取得をクリックします。
- 次は、データ抽出スコープアクティビティの抽出器を設定をクリックします。
- 次の抽出器を設定画面にて、以下のように設定します。
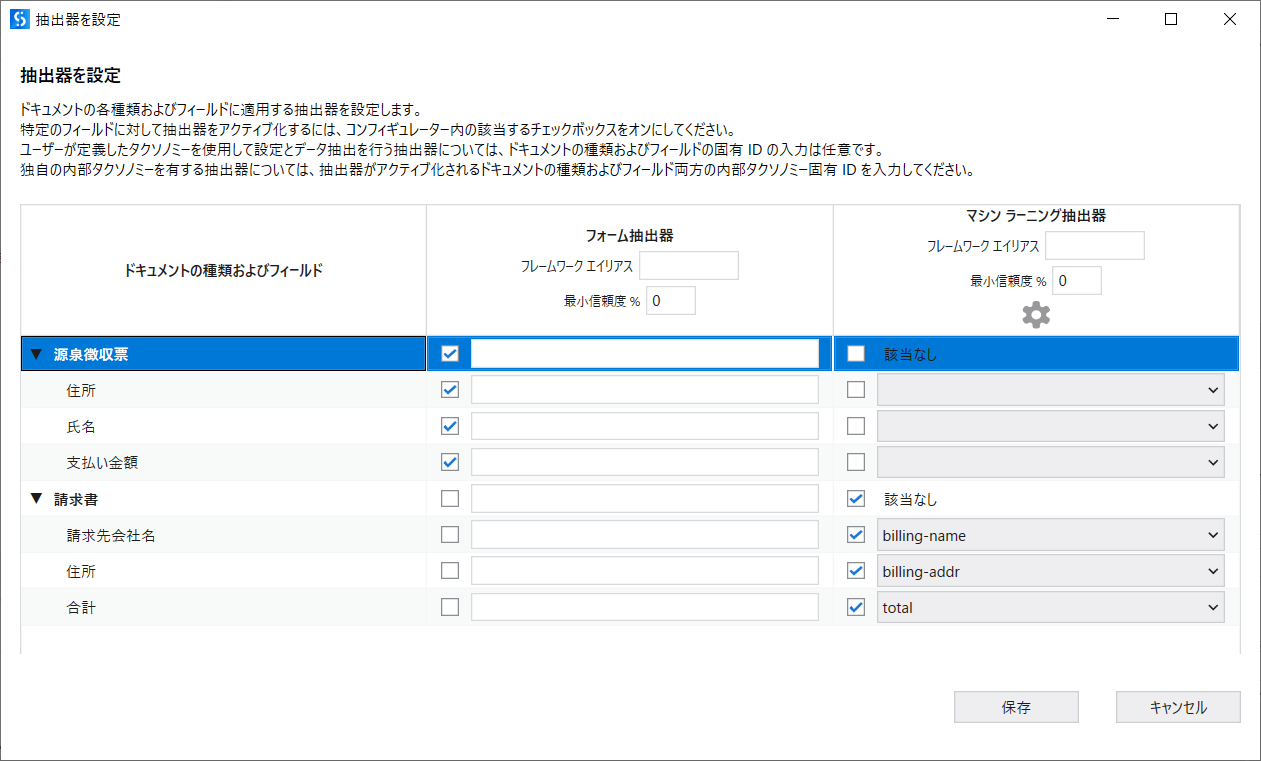
- マシンラーニング抽出器のフィールドの意味は以下のドキュメントをご確認してください。
補足
現時点(2023/4/7)、InvoicesJapan (請求書 - 日本)はプレビュー版(パブリック エンドポイント)ですので、精度についてご自身チェックしてから利用してください。)
8. 抽出結果の確認
ここまでで、必要な変更(タクソノミー、デジタル化のOCRエンジン、分類器の設定、抽出器関連設定)が全て完了しました。
次はワークフローを実行して、出力された結果を確認します。
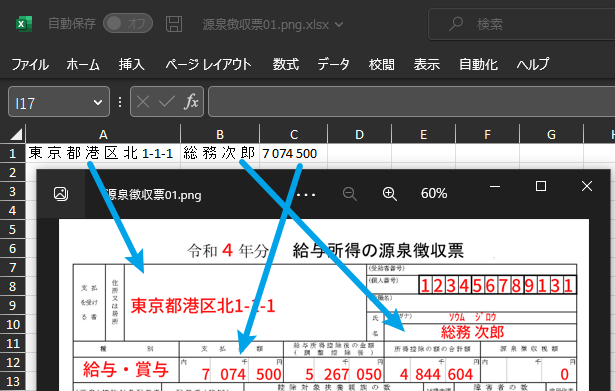
- 源泉徴収票(抽出結果のExcelファイルと元の源泉徴収票画像)
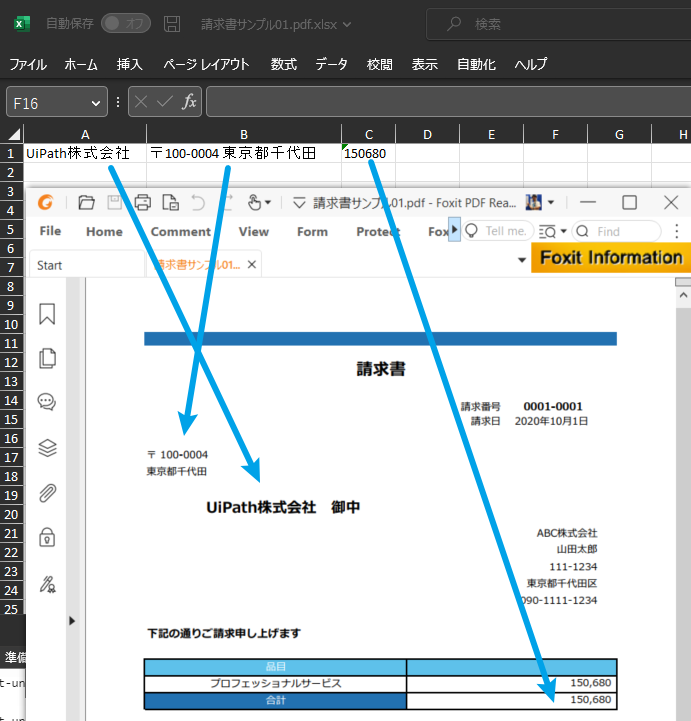
- 請求書(抽出結果のExcelファイルと元の請求書PDF)
今回日本語帳票の場合は、OCRエンジンやエンドポイントの変更を説明したかったので、源泉徴収票と請求書は一枚づつしか用意していませんでした、複数枚でも同じく動作できます。
ご参考までに、上記のワークフローはこちらのDU_Basic_Sample_日本語帳票_第三回.zipです。
9. 補足
第1回から第3回まで、UiPath Studioを使用してゼロからワークフローを作成し、ドキュメントの分類や抽出、そして結果の検証ができました。しかし、このワークフローには以下の問題点があります。
- 無人オートメーションの対応がしていない
- エラー処理が考慮していない
- 多様な種類のドキュメントが対応していない
これらの問題を解決するために、UiPath StudioにはDocument Understanding Processのテンプレートが用意されています。このテンプレートを活用するためには、全体の構成を理解する必要があります。次の記事では、その構成について解説します。