1. なぜ検証と再学習が必要なの?
前回の記事UiPath Document Understanding 第1回 基礎編 複数種類のドキュメントからデータ抽出しようでは、複数のドキュメントから定義された情報を抽出することができました。
しかし、データの抽出精度が100%であることは保証されていません。そのため、必要に応じて人間による検証を行い、その結果を元に再学習することで、後続の分類と抽出のパフォーマンスを向上させます。
UiPath Document Understandingで提供されている分類器と抽出器の関連アクティビティには、検証したデータに基づいて自己学習することができるアルゴリズムがあります。ユーザーは既存のワークフローを更新する必要はありません。
以下の処理フロー図のように、四つの処理を追加することで、分類結果と抽出した結果の確認・修正・再学習ができます。
- 人間による分類結果の検証
- 分類結果の再学習
- 人間による抽出結果の検証
- 抽出結果の再学習

UiPath Document Understanding では、それぞれのアクティビティが用意され、結果の検証及び再学習をすることができます。
2. 有人オートメーションでの結果検証
UiPath Document Understanding では、分類ステーションと検証ステーションを利用することで、分類結果の検証と抽出結果の検証ができます。
分類ステーションと検証ステーションを利用する際には、有人オートメーションと無人オートメーションそれぞれの場合で利用するアクティビティが異なります。
それでは、まず有人オートメーションでの検証を確認しましょう!
第一回で作成したワークフローでは、複数のドキュメントを分類して、定義された情報の抽出ができました。
これから前回のワークフローDU_Basic_Sample.zipのベースで、分類結果の検証と抽出した結果の検証を追加します。
有人オートメーションの場合には、以下のようなアクティビティが利用されます:
- 分類結果の検証:[分類ステーションを提示] アクティビティ
- 抽出した結果の検証:[検証ステーションを提示] アクティビティ
2.1分類結果の検証
前回のワークフローを開いて、以下の手順通りで[分類ステーションを提示] アクティビティの追加と設定をします。
手順:
- アクティビティ検索欄にPresentClassificationStationを検索します。
- 分類ステーションを提示アクティビティをドキュメント分類スコープアクティビティの下に配置します。
-
入力設定:
- タクソノミー:taxonomy
- ドキュメント オブジェクトモデル:dom
- ドキュメント テキスト:strDocumentText
- ドキュメントパス:CurrentFile.FullName
- 自動分類結果:classficationResults
-
出力設定:
- 検証済みの分類結果:classficationValidatedResults(変数新規作成)
上記の追加と設定をしたら、ワークフローを実行して、実行時にウィンドウ(以下の図)が開き、分類ステーションが表示されます。これにより、ユーザー側からの操作が可能になります。

人間が確認して、分類が間違っていれば、正しい種類を選択して、保存してください。

こちらで人間が修正した分類結果(出力変数のclassficationValidatedResults)が、次の処理(データ抽出)に利用されます。
こちらの分類ステーションで、故意に誤った種類を選択して保存したら、最終的にどんなデータが抽出されるかを確認してみてください。
データ抽出スコープでの分類結果変更
人間による検証済の分類結果を次の抽出スコープにも反映する必要がありますので、データ抽出スコープ アクティビティでの分類結果を変更します。
- 変更前:自動分類結果の「classficationResults」
- 変更後:検証済みの分類結果の「classficationValidatedResults」

2.2 抽出した結果の検証
次は抽出器を通して抽出した結果の検証をします。以下の手順通りで[検証ステーションを提示] アクティビティの追加と設定をします。
手順:
- アクティビティ検索欄にPresentValidationStationを検索します。
- 検証ステーションを提示アクティビティをデータ抽出スコープアクティビティの下に配置します。
-
入力設定:
- タクソノミー:taxonomy
- ドキュメント オブジェクトモデル:dom
- ドキュメント テキスト:strDocumentText
- ドキュメントパス:CurrentFile.FullName
- 自動抽出結果:extractionResults
-
出力設定:
- 検証済みの抽出結果:extractionValidatedResults(変数新規作成)
上記の追加と設定をしたら、ワークフローを実行して、実行時にウィンドウ(以下の図)が開き、検証ステーションが表示されます。これにより、ユーザー側からの操作が可能になります。

抽出結果を確認して、抽出結果が間違っていれば修正して(例:上記画像での456200-T231から 456200-TZE1 への修正)、送信してください。
こちらで人間が修正した抽出結果(出力変数のextractionValidatedResults)が、次の処理(抽出結果をエクスポート)に利用されます。
2.1と2.2を通して、分類結果と抽出した結果両方とも人間によるダブルチェックが完了したため、正しいデータを次の業務システムへ投入していることが保証できます。
ご参考までに、上記のワークフローはこちらのDU_Basic_Sample_Validation_Attended_第二回.zipです。
抽出結果をエクスポートでの抽出結果変更
上記の検証済分類結果と同じように、抽出結果をエクスポート アクティビティでの抽出結果を変更します。
- 変更前:自動抽出結果の「extractionResults」
- 変更後:検証済みの抽出結果の「extractionValidatedResults」

3. 無人オートメーションでの結果検証
無人オートメーションは人間の監視や操作なしで実行されるオートメーションです。ロボット実行中にユーザーが途中結果の確認と修正ができないので、ロボットによって開始された Action Centerでのタスクを人間が完了することで、有人オートメーションを実現します。
Action Centerに関する情報は、Action Center(人間とロボットのコラボレーション)をご参照ください。
Action Centerを利用した検証は、UiPath Automation CloudでのアクションのカタログやOrchestratorでのストレージバケットなども関連しています。
UiPath StudioでのDocument Understanding Processのテンプレートを利用して開発するのが便利ですので、UiPath Document Understanding 第4回 基礎編 テンプレートを使おう記事で解説しています。
4. 分類結果及び抽出結果の再学習
4.1 分類結果の再学習
上記の2.1 分類結果の検証では、自動的な分類結果を人間に提示して、確認・修正の実装を行いました。こちらで、この修正した結果を再学習して、分類結果の精度を高められるように実装します。
まずは分類器トレーニング スコープ アクティビティの追加と設定をします。
手順:
- アクティビティ検索欄にTrainClassifiersScopeを検索します。
- 分類器トレーニング スコープ アクティビティを分類ステーション アクティビティを提示 の下に配置します。
-
入力設定:
- タクソノミー:taxonomy
- ドキュメント オブジェクトモデル:dom
- ドキュメント テキスト:strDocumentText
- ドキュメントパス:CurrentFile.FullName
- 人間が検証済みの分類データ:classficationValidatedResults
次はスコープに、インテリジェント キーワード分類器トレーナー アクティビティの設定をします。
手順:
- アクティビティ検索欄にIntelligentKeyWordClassifierTrainerを検索します。
- インテリジェント キーワード分類器トレーナー アクティビティを分類器トレーニング スコープ アクティビティの中に配置します。
-
入力設定:
- ラーニング ファイルのパス:作成したインテリジェントキーワード分類器jsonファイルのパス(例:インティジェントキーワード分類器の設定での
"DocumentProcessing\classifierLearning.json")
- ラーニング ファイルのパス:作成したインテリジェントキーワード分類器jsonファイルのパス(例:インティジェントキーワード分類器の設定での
最後に分類器を設定します。
手順:
- 分類器トレーニング スコープアクティビティの一番下の分類器を設定をクリックします。
- 分類器を設定画面に、インティジェントキーワード分類器トレーナーをチェックし保存します。

4.2 分類結果再学習の確認
上記の4.1で分類結果を再学習するために、必要な設定をしました。こちら、実行して再学習の効果を確認します。
Studioの実行ボタンをクリックして、実行します。
-
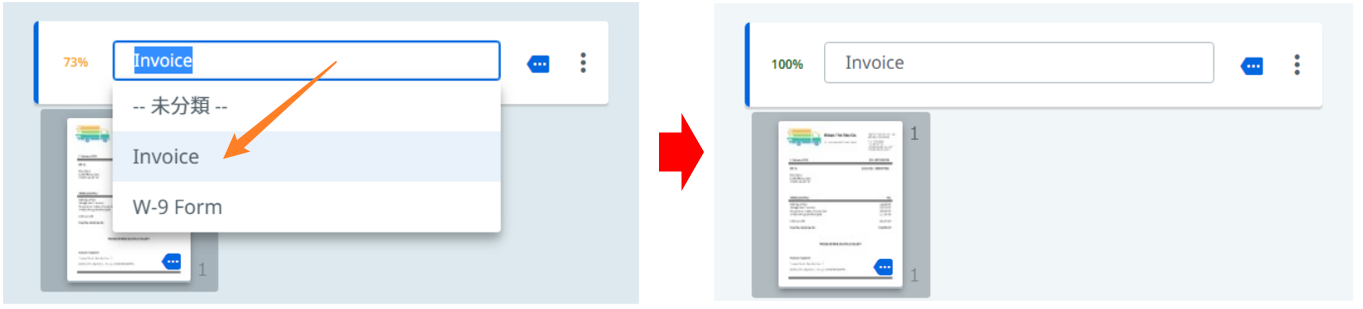
実行一回目
一回目の実行で、該当Invoiceの分類信頼度が73% です。人間による確認して、これが間違いないので、手動でInvoiceを確認します。人間の確認があったので、信頼度が100%になって、下の送信ボタンをクリックします。
-
実行二回目
二回目を実行する際に、信頼度が73% から 84% まで上がりました。

また、分類器のjsonファイル(DocumentProcessing\classifierLearning.json)も比較してみて、トレーニングが発生したら、このファイルの中身も更新されます。
補足:
現在は自動分類結果の信頼度を見ずに、分類器の検証及び再学習を実施しています。信頼度を考慮して、検証及び再学習を実施するとしたら、分類結果の信頼度情報で判断する必要があります。
例:信頼度が80%以上かの判断がclassficationResults(0).Confidence < 0.8
4.3 抽出結果の再学習
分類結果の再学習と同じように、まずは抽出器トレーニング スコープ アクティビティの追加と設定をします。
手順:
- アクティビティ検索欄にTrainExtractorsScopeを検索します。
- 抽出器トレーニング スコープ アクティビティを検証ステーションを提示 アクティビティの下に配置します。
-
入力設定:
- ドキュメント オブジェクトモデル:dom
- ドキュメント テキスト:strDocumentText
- ドキュメントパス:CurrentFile.FullName
- 人間が検証したデータ:extractionValidatedResults
次はスコープに、マシン ラーニング抽出器トレーナー アクティビティの設定をします。
手順:
- アクティビティ検索欄にMachineLearningExtractorTrainerを検索します。
- マシン ラーニング抽出器トレーナー アクティビティを抽出器トレーニング スコープ アクティビティの中に配置します。
- 表示されたマシン ラーニング抽出器のエンドポイントに、
https://du.uipath.com/ie/invoicesを設定して、機能を取得ボタンをクリックします。 - プロジェクトフォルダのDataフォルダに、トレーニング済データの保存用フォルダとしてInvoiceTrainingフォルダを作成します。
-
ローカル ストレージ:
- 出力フォルダ:"Data\InvoiceTraining" (上記作成したトレーニング済みデータ保存用フォルダ)
設定後のマシン ラーニング抽出器トレーナーが下記の通りです:

最後に抽出器を設定します。
手順:
- 抽出器トレーニング スコープ アクティビティの一番下の抽出器を設定をクリックします。
- 抽出器を設定画面に、Invoiceのマシンラーニング抽出器トレーナーをチェックし、以下のように各フィールドも選択して保存をします。

4.4 抽出結果再学習の確認
上記の4.3で抽出結果を再学習するために、必要な設定をしました。こちら、実行して再学習の効果を確認します。
Studioの実行ボタンをクリックして、実行します。
-
実行一回目
一回目の実行で、以下の図で示したような信頼度でデータが抽出されました。確認して問題なければチェックをして送信します。

-
実行二回目
2回目を実行して、一回目と同じ信頼度でデータが抽出されます。
マシン ラーニング抽出器トレーナーの実行で、Data\InvoiceTrainingフォルダに以下のようなファイルが作成されます。
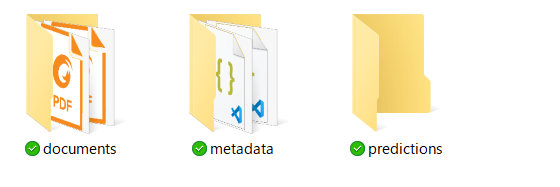
これが収集された人間検証後のデータです。このデータを利用して、マシンラーニングのモデルを再トレーニングします。
なぜ二回目抽出の信頼度が上がらなかったのか?
現在のマシン ラーニング抽出器トレーナーでは、出力フォルダしか設定していないので、再学習用の検証後データを収集しているだけです。

マシンラーニング抽出器の信頼度を高めるために、収集したデータをマシンラーニング抽出器でのML モデルを再トレーニングする必要があります。
この再トレーニングを実施するため、UiPath AI Centerを利用する必要があるので、別の記事で解説します。
最後に
実装済のサンプルワークフローはこちら(DU_Basic_Sample_Validation_Training_APIキー消した_2回目_検証済データ)です。ご参照ください。
参考情報
- ドキュメント分類の検証
- データ抽出の検証
- ドキュメント分類トレーニング関連のアクティビティ
- 抽出器トレーニング スコープ
- データ抽出トレーニングの概要
- 優れたパフォーマンスのモデルをトレーニングする
- マシン ラーニング抽出器トレーナー