1. UiPath Document Understanding って何?
UiPath Document Understandingとは、様々なドキュメントから情報抽出・解釈するドキュメント処理のフレームワーク(機能群) です。
以下のようにDocument Processing,AI,RPAの三つが重なる部分 にDocument Understandingがあります。

UiPath Document Understandingに関するより詳細な情報、以下の記事をご参照ください。
2. UiPath Document Understanding 処理の流れ
本例では、以下の手順を利用して、一番簡単なUiPath Document Understanding 処理を構築します。
上記1-5までの役割は以下の通り。
- タクソノミー:処理対象ドキュメントのタイプ・フィールドを定義
- デジタル化:OCRを使用してドキュメントをデジタル化
- 分類:ファイルをドキュメントタイプに分類
- 抽出:タクソノミーの定義を元にドキュメントから情報を抽出
- エクスポート:別プロセスと連携するため、抽出したデータをエクスポート
3. ドキュメントからデータ抽出しよう
以下の処理で、2種類(InvoiceとW-9 Form)のPDFファイルから必要な情報をExcelファイルにエクスポートします。PDFサンプルファイルはこちらからダウンロードしてください。
それでは、手元のUiPath Studioを起動して始めましょう!
以下の例で利用しているUiPath StudioがStudio 2023.4.0 Community Editionです。関連アクティビティのUiPath.System.Activitiesが22.10.4のを利用しています。
3.1 空のプロセスを作成する
- UiPath Studio を起動します。
- [ホーム] の Backstage ビューで [プロセス] をクリックして、新しいプロジェクトを作成します。
- [新しい空のプロセス] ウィンドウが表示されます。このウィンドウで、新しいプロジェクトの名前を入力します。プロジェクトを簡単に見つけられるように、必要に応じてプロジェクトの説明を追加することもできます。
- [作成] をクリックします。新しいプロジェクトが Studio で開きます。
3.2 必要なアクティビティ パッケージをインストールする
既定でプロジェクトに追加されるコア アクティビティ パッケージ に加えて、リボンの [パッケージを管理] ボタンから、次のアクティビティ パッケージをインストールします。
- UiPath.DocumentUnderstanding.ML.Activities v1.18.0
- UiPath.IntelligentOCR.Activities v6.6.0
必要なパッケージがインストールされたら、DU関連アクティビテやデザインのリボン欄にタクソノミーマネージャーが表示されます。

3.3 タクソノミー_タイプとフィールド定義
タクソノミーマネージャを使って、請求書のドキュメントタイプを定義します。
手順:
- Studio のリボンメニューから [タクソノミーマネージャー] をクリックします。
- [新しいドキュメントの種類を追加] をクリックします。
- [新しい名前] で名前を入力して、保存します。
本例では、次のInvoiceとW-9 Formの二つドキュメントタイプを定義します。
- ドキュメントの種類名:Invoice の定義

上の図のように、Invoiceから必要な情報を抽出するので、必要なフィールドを定義します。
| No | フィールド名 | 種類 | 列-フィールド名 | 列-種類 |
|---|---|---|---|---|
| 1 | Company Name | Name | ||
| 2 | Invoice Number | Text | ||
| 3 | Date | Date | ||
| 4 | Items | Table | ||
| 4.1 | Description | Text | ||
| 4.2 | Total | Number | ||
| 5 | Total | Number |
- ドキュメントの種類名:W-9 Form の定義

上の図のように、W-9 Formから必要な情報を抽出するので、必要なフィールドを定義します。
| No | フィールド名 | 種類 |
|---|---|---|
| 1 | Person Name | Name |
| 2 | Business Name | Name |
| 3 | Address | Address |
| 4 | Signature | Boolean |
タクソノミーマネージャーで、2種類のドキュメントの定義が以下のようなイメージです:

タクソノミーマネージャーで上記2種類ドキュメントの定義:ドキュメントタイプの定義が完了したら、ワークフローのプロジェクトフォルダ内に、[DocumentProcessing\taxonomy.json] の定義ファイルが作成されます。
3.4 タクソノミー_タクソノミーを読み込み
次は、先程作成したタクソノミーファイルを利用するため、タクソノミーを読み込みアクティビティをWorkflowに追加します。
手順:
- Main.xaml を開きます。
- アクティビティ検索欄に Load Taxonomyを検索します。
- タクソノミーを読み込み アクティビティを Main.xaml にドロップします。
-
出力設定:
- タクソノミー:taxonomy

3.5 デジタル化_OCRエンジンでPDFをデジタル化
デジタル化する必要があるファイルを読み込んでから、OCRエンジンを使って、イメージデータ(JPEG、PDFなど)からデジタルデータを読み出します。
① デジタル化するファイルの読み込み
デジタル化する必要があるファイルを読み込みます。
手順:
- アクティビティ検索欄にForEachFileを検索します。
- 繰り返し (フォルダー内の各ファイル) アクティビティを タクソノミーを読み込みアクティビテの下にドロップします。
-
入力設定:
- フォルダ内:デジタル化ファイルの保存フォルダのパス
② デジタルデータの読み出し
OCRを使って、イメージデータ(JPEG、PDFなど)からデジタルデータを読み出します。
手順:
- アクティビティ検索欄にDigitalize Documentを検索します。
- ドキュメントをデジタル化 アクティビティを繰り返し (フォルダー内の各ファイル) アクティビテの中にドロップします。
-
入力設定:
- PDFにOCRを適用:ApplyOcrOnPdfArgument.Auto
- ドキュメント パス : CurrentFile.FullName
-
出力設定:
- ドキュメント オブジェクト モデル : dom
- ドキュメント テキスト: strDocumentText
ドキュメントをデジタル化アクティビティの詳細はドキュメントをデジタル化をご参照ください。
補足:
処理の進捗を把握するために、メッセージをログアクティビテを利用して、進捗をログに出力するのがおすすめです。
ログメッセージ例:"ドキュメントのデジタル化処理が開始しました:" + CurrentFile.Name
③ UiPath ドキュメントOCRの設定
UiPath ドキュメントOCRがドキュメントをデジタル化 アクティビティのデフォルトOCRです。UiPath StudioがUiPath Cloudと接続している場合には、APIキーが自動的設定されます。
エンドポイントにhttps://du.uipath.com/ocrを設定してください。
全てのパブリックエンドポイントはパブリック エンドポイントをご参照ください。
本例では、APIキーをワークフローにハードコーディングしていますが、Orchestratorのアセットに保存するのがおすすめです。
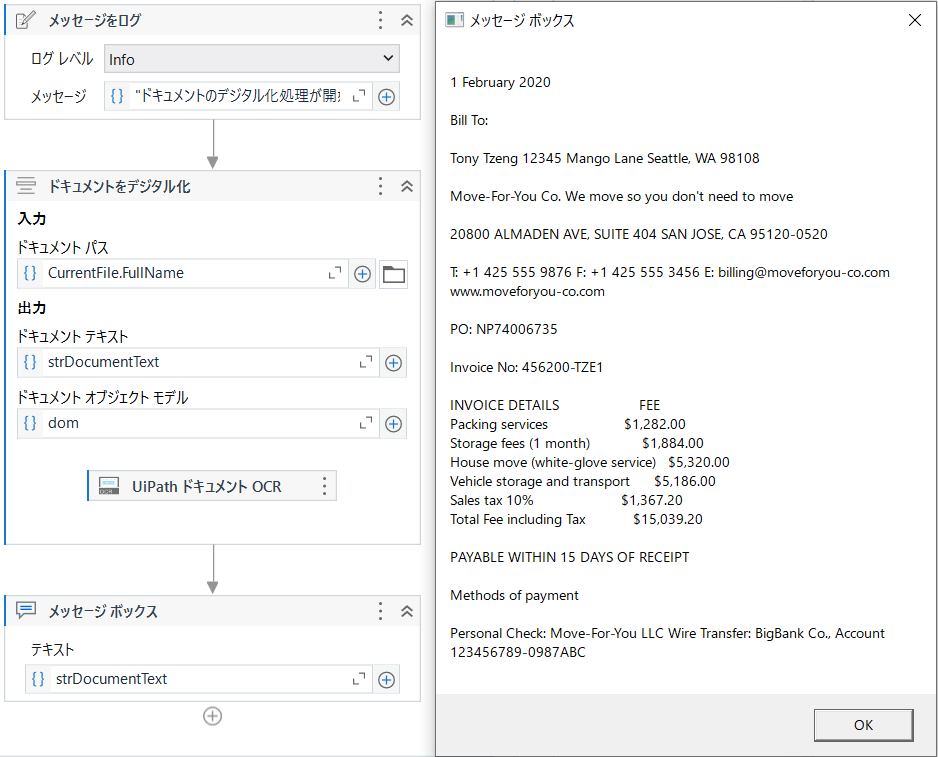
④ デジタル化結果の確認
デジタル化した結果を一旦確認してみましょう。
手順:
- メッセージボックスアクティビテを利用して、デジタル化した結果のstrDocumentText 変数を出力して確認します。
- 確認したら、メッセージボックスアクティビテを削除します。
3.6 分類_ファイルをドキュメントタイプに分類
複数種類のドキュメントが存在する場合には、分類器を利用してドキュメントを分ける必要があります。
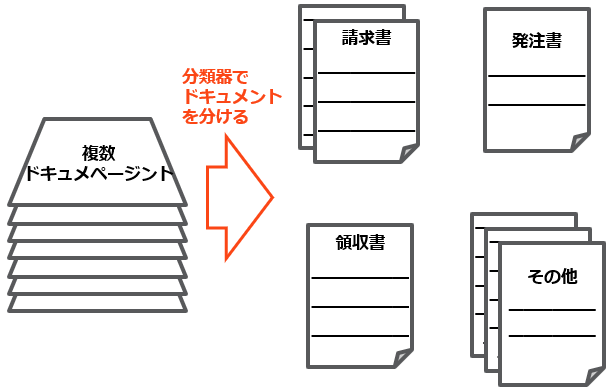
本例では、InvoiceとW-9 Formの2種類のドキュメントがありますので、今処理しているのはどんなタイプのドキュメントなのか、ドキュメント分類子(Document Classifier)を使って、ドキュメントを分類する必要があります。
こちらでインティジェントキーワード分類器を利用して分類します。
① 分類スコープの追加
ドキュメント分類器を追加する前に、ドキュメント分類スコープを追加します。
手順:
- アクティビティ検索欄にClassify Document Scopeを検索します。
- ドキュメント分類スコープをドキュメントをデジタル化の下にドロップします。
-
入力設定:
- タクソノミー:taxonomy
- ドキュメント オブジェクト モデル:dom
- ドキュメント テキスト:strDocumentText
- ドキュメントパス:CurrentFile.FullName
-
出力設定:
- 分類結果:classficationResults
② インティジェントキーワード分類器の設定
手順:
- アクティビティ検索欄にIntelligent Keywordを検索します。
- インティジェントキーワード分類器アクティビティをドキュメント分類スコープの中に配置します。
上記 3.5 デジタル化_OCRエンジンでPDFをデジタル化の③ UiPath ドキュメントOCRの設定 と同様に、APIキーとエンドポイントが自動的設定されます。
学習したデータを保存するために、classifierLearning.jsonという名前の空ファイルを作成して保存します。保存したら、インティジェントキーワード分類器アクティビティの入力を設定します:
- ラーニングファイルのパス:上記
classifierLearning.jsonファイルの保存パス
③ ドキュメント分類器の事前学習
ドキュメント分類器の事前学習の設定方法です。
手順(Invoice):
- インティジェントキーワード分類器の学習を管理をクリックします。
- Invoiceのトレーニング開始… を押して、次に分類器をトレーニング のウィンドウが表示さます。
- トレーニング用に設定されたファイルにデジタル化必要なファイル(例:Invoice.pdf,Invoice1.pdf)を選択します。
- その以外の設定(エンドポイント、APIキー、タイムアウト、PDFにOCRを適用)がデフォルトのままで変更しません。
- トレーニングを開始をクリックします。
W-9 Formも上記同様な手順で実施してください。
InvoiceとW-9 Form両方学習ができたら、保存をします。

学習が完了したら、先程作成した空ファイルのclassifierLearning.jsonに、学習したデータが保存されます。
[{"DocumentKeywordVectors":[{"TotalDocumentLength":1240,"PageCount":1,"FirstPageVector":
{"VectorId":"NoGroup.NoCategory.Invoice_1.FirstPage","DocumentCount":2,"TermsWithScores":
[{"Score":1.45,"Term":"invoice","LastUpdated":"2023-04-02T21:35:36.285069+09:00"},
{"Score":0.93,"Term":"fee","LastUpdated":"2023-04-02T21:35:36.2850732+09:00"},{"省略","省略"}
]
④ 分類器を設定
分類子スコープの分類子設定はどのドキュメントをどの分類子を使えるかを設定できます。
手順:
- ドキュメント分類スコープアクティビティの一番下の分類器を設定をクリックします。
- 分類器を設定画面に、インティジェントキーワード分類器をチェックし保存します。

本例では、インティジェントキーワード分類器の一種類を利用していますが、ドキュメントタイプによって複数の分類器を設定することが可能です。
分類器に関する詳細な説明はドキュメント分類関連のアクティビティをご参照ください。
3.7 抽出_定義した項目の情報の抽出
ドキュメントの分類ができたら、抽出器使って、タクソノミーマネージャで定義した項目の情報を抽出します。
ルールベース抽出器とモデルベース抽出器を組み合わせて、情報を抽出することができます。
① データ抽出スコープの追加
抽出器を追加する前に、データ抽出スコープを追加します。
手順:
- アクティビティ検索欄にDataExtractionを検索します。
- データ抽出スコープアクティビティをドキュメント分類スコープの下にドロップします。
-
入力設定:
- タクソノミー:taxonomy
- ドキュメント オブジェクト モデル:dom
- ドキュメント テキスト:strDocumentText
- ドキュメント パス:CurrentFile.FullName
- 分類結果:classficationResults(0) 補足
-
出力設定:
- 抽出結果:extractionResults
補足
classficationResultsが「ドキュメント分類スコープ」アクティビティの出力です。一つのドキュメントには複数ページが存在されている場合あるので、classficationResultsが配列型です。
本例でのInvoiceとW-9 Formドキュメントには1ページしかないので、1ページ目の分類結果classficationResults(0)を使います。
② フォーム抽出器の追加と設定
手順:
- アクティビティ検索欄にFormExtractorを検索します。
- フォーム抽出器アクティビティをデータ抽出スコープの中にドロップします。
- StudioがUiPath AutomationCloudと接続されているので、エンドポイントとAPI キーが自動的に設定されます。
- 次はテンプレートを管理をクリックして、テンプレートマネージャーのウィンドウが表示されます。
-
テンプレートを作成をクリックして、次に表示されたテンプレートを作成で以下のように設定して、設定をクリックします:
- ドキュメントの種類:W-9 Form
- テンプレート名:W-9
- テンプレート ドキュメント:W-9 FormのPDFを選択します(例:W9-Form_1.pdf)
次に表示されたテンプレート マネージャー W-9に、ページの一致情報や定義された情報の指定を実施します。
- ページ1の一致情報の指定と抽出
こちらで、右のW-9 PDFから五つのW-9を特定できる識別情報を指定します。
- 左側のページ1の一致情報を選択します。
-
Ctrlキーを押しながら、右側のPDFから五つのW-9識別情報を選択します。 - 選択が完了したら、左側ページ1の一致情報での✙をクリックして、値を抽出します。
詳細は以下の画像の通りです。

- Person Nameの指定と抽出
- 左側のPerson Nameを選択します。
- 右側のPDFでPerson Nameのエリアを選択して、カスタム領域参考図にします。
- 選択が完了したら、左側Person Nameでの+をクリックして、値を抽出します。
カスタム領域の選択参考図:

その以外の定義された情報(Business Name,Address,Signature)も上記のPerson Nameと同様な方法で指定と抽出をして、完了したら、送信ボタンをクリックします。
再度テンプレートマネージャー画面に戻ったら、以下のを設定して、閉じるをクリックします。
- 署名フィールド:Signature
③ マシン ラーニング抽出器の追加と設定
手順:
- アクティビティ検索欄にMachineLearningExtractorを検索します。
- マシン ラーニング抽出器アクティビティをデータ抽出スコープの中にドロップします。
- マシン ラーニング抽出器に以下の設定をします。
- エンドポイント:
https://du.uipath.com/ie/invoices
- エンドポイント:
- 機能を取得をクリックします。
全てのパブリックエンドポイントはパブリック エンドポイントをご参照ください。
④ 抽出器を設定
上記の②と③でフォーム抽出器とマシンラーニング抽出器の追加と設定をしましたので、次にどのタイプのドキュメントがどの抽出器を利用するのかを指定します。
手順:
- データ抽出スコープの抽出器を設定をクリックし、抽出器を設定ダイアログを開きます。
- W-9 Formが定型のドキュメントですので、ルールベースのフォーム抽出器を利用します。フォーム抽出器欄での▢をチェックします。
- Invoiceが非定型のドキュメントですので、モデルベースのマシンラーニング抽出器を利用します。Invoiceでの各フィールドごとに、マシンラーニング抽出器でのフィールドを指定します。
- Company Name: name
- Invoice Number: invoice-no
- Date: date
- Items: items
- Description: description
- Total: line-amount
- Total: total
- 最後に、保存をします。
参照画面:

上記の設定で、invoiceとW-9 Formドキュメントでの定義された情報を抽出して、抽出結果の変数 extractionResultsに保存しました。
抽出器に関する詳細な情報はデータ抽出の概要をご参照ください。
3.8 エクスポート_抽出したデータをExcelファイルにエクスポート
ドキュメントから必要な情報だけ抽出しデータをExcelファイルにエクスポートします。後続の処理にシームレスに連携が可能です。
先ずは抽出結果のオブジェクト(extractionResults)を複数の表を含むデータセット(dataset_extractions)にエクスポートします。
手順:
- アクティビティ検索欄にExportExtractionResultsを検索します。
- 抽出結果をエクスポート*アクティビテをデータ抽出スコープアクティビテの下に配置します。
-
入力設定:
- 抽出結果:extractionResults
-
出力設定:
- データセット:dataset_extractions
次は、繰り返しでデータセットでの表をExcelファイルに書き込みます。
手順(繰り返し(コレクションの各要素)):
- アクティビティ検索欄にForEachを検索します。
- 繰り返し(コレクションの各要素) アクティビテを抽出結果をエクスポートアクティビテの下に配置します。
- データセットに含まれているのは表ですので、TypeArgumentをSystem.Data.DataTableに変更します。
- 命名を分かりやすくするため、繰り返し要素名のcurrentItemをtableに変更します。
- 次のコレクション内の各要素に変数のdataset_extractions.Tablesを設定します。
手順(範囲に書き込み(ワークブック)):
- 次はアクティビティ検索欄にWriteRangeを検索します。
- 範囲に書き込み(ワークブック) アクティビテを繰り返し(コレクションの各要素)の中に配置します。
-
入力設定:
- データテーブル:table
- ブックパス:"Extractions"+CurrentFile.Name + ".xlsx"
-
ターゲット設定:
- シート名:table.TableName
3.9 実行して結果確認
上記の3.1から3.8までの操作で、複数種類の画像ベースのドキュメントから必要な情報を抽出して、Excelファイルに書き込みできました。
該当ワークフローを実行して、結果を確認しましょう!
実行完了したら、上記のExcel書き込みで設定したフォルダExtractions内に、複数のExcelファイルが作成されます。

元のドキュメントInvoice.pdfを開いて、こちらの抽出結果と確認しましょう!
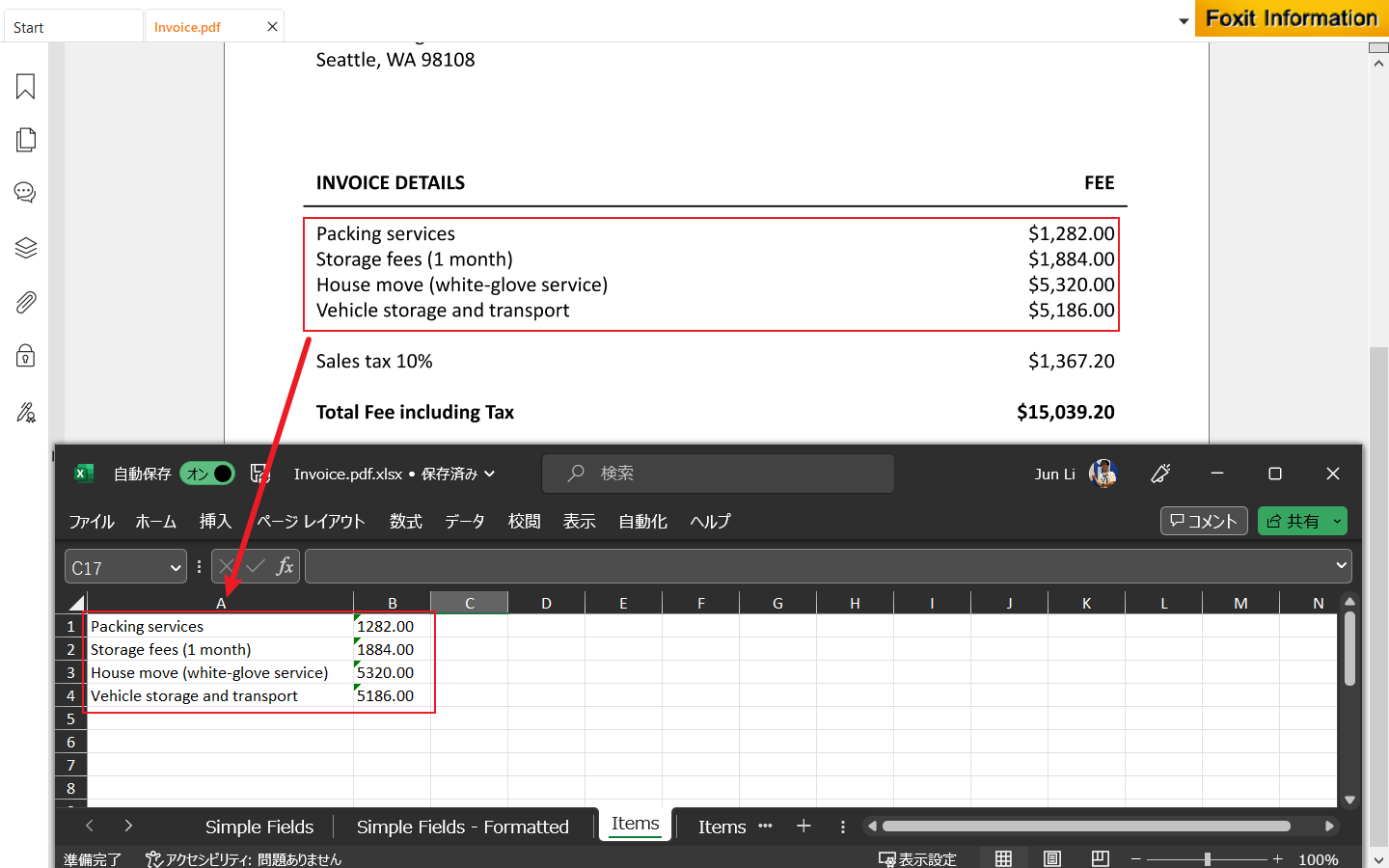
上記の画像のように、各明細とも正しく抽出できました。
W-9 Formも開いて確認しましょう!

上記の画像のように、署名ありなしも含めて定義された情報が正しく抽出されました。
これで、一つ簡易なドキュメントから情報抽出のワークフローの構築ができました。
ご参考までに、上記のワークフローはこちらです。
4. 検証ステーション
上記3.9での結果確認で、必要な情報が正しく抽出できましたが、全てが正しいとは限らないので、人間による抽出結果の確認・修正になるケースがあります。
UiPath Document Understandingには、検証ステーションの機能が用意され、分類や抽出結果の確認・修正ができます。
- 分類器の検証ステーションを使って、ドキュメントの分類結果を確認・修正します。
- 抽出器の検証ステーションを使って、抽出した情報を確認・修正します。
分類器と抽出器は、それぞれ分類ステーションと検証ステーションで補正・検証されたデータから、再教育することができます。
検証ステーションの実装方法は第二回の記事で詳しく説明します。
5. 参考情報