スコア推移からみるKaggleコンペのプロセス
この記事は、AI道場「Kaggle」への道 by 日経 xTECH ビジネスAI① Advent Calendar 2019のアドベントカレンダー6日目の記事です。
この記事はどうKaggleに取り組んでいいかわからないKaggle初心者に向けた記事です。コンペのスコア推移を見ながらある時期にkaggler達がいったい何をやっているのかを記事にします。
レベルとしてはKaggleに登録したら次にやること ~ これだけやれば十分闘える!Titanicの先へ行く入門 10 Kernel ~あたりで機械学習とKaggleの基本を学んだ後、実際に開催中のコンペに挑戦してみようと思っている人ぐらいの人を対象としています。
※この記事に書かれている内容は自分の経験と見聞きした話であり、全ての人がそうしているわけではありません。
スコア推移
まずは、kaggle api を利用して、リーダーボードから参加者のスコア推移を抜き出します。
kaggle competitions leaderboard コンペ名 --download
上記コマンドで、各参加者がスコアを更新したときのSubmissionDateとPublic Scoreがcsvファイルとしてダウンロードできます。
先日終了したNFLコンペの私のスコア推移です。残念ながら何かに気付けなかったこのコンペでの私のプロセスは4つの時期に分けられます。
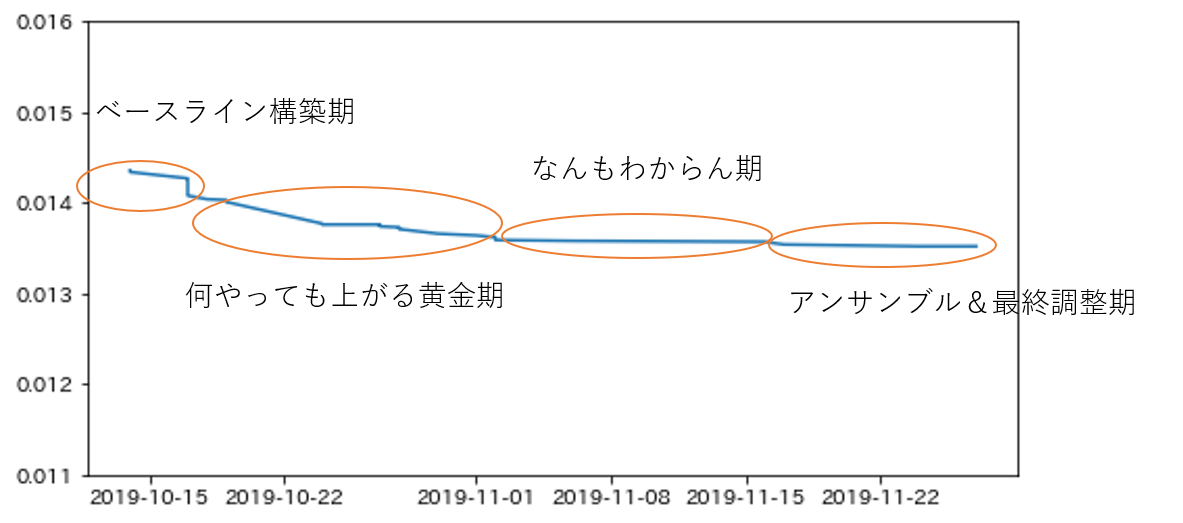
こちらはpublic上位5チームのスコア推移です。これも想像でプロセスを分けるとこんな感じでしょうか。
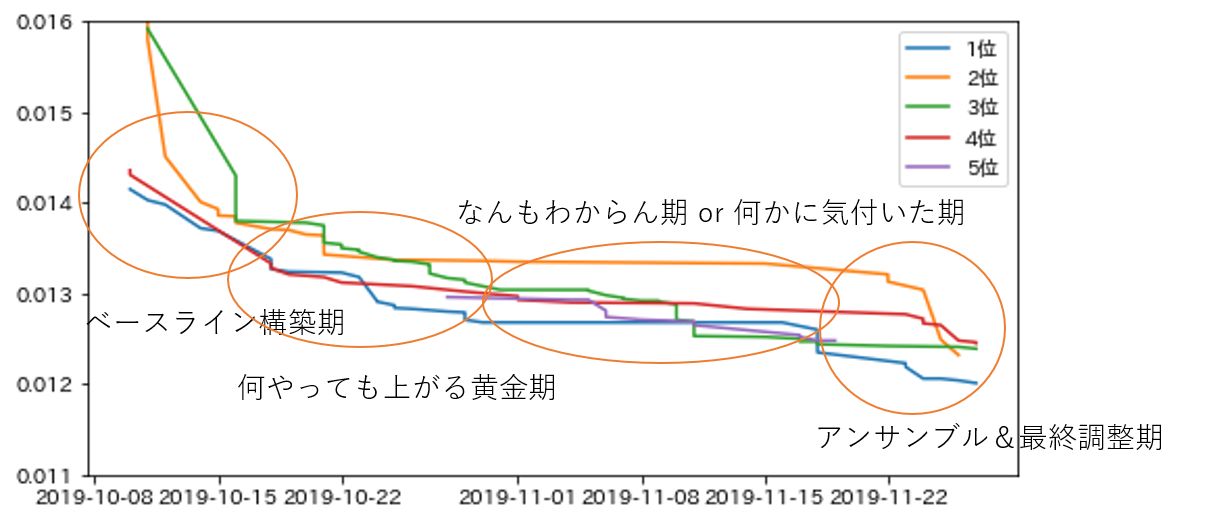
コンスタントにスコアを上げ続けているチームもあります。
ベースライン構築期
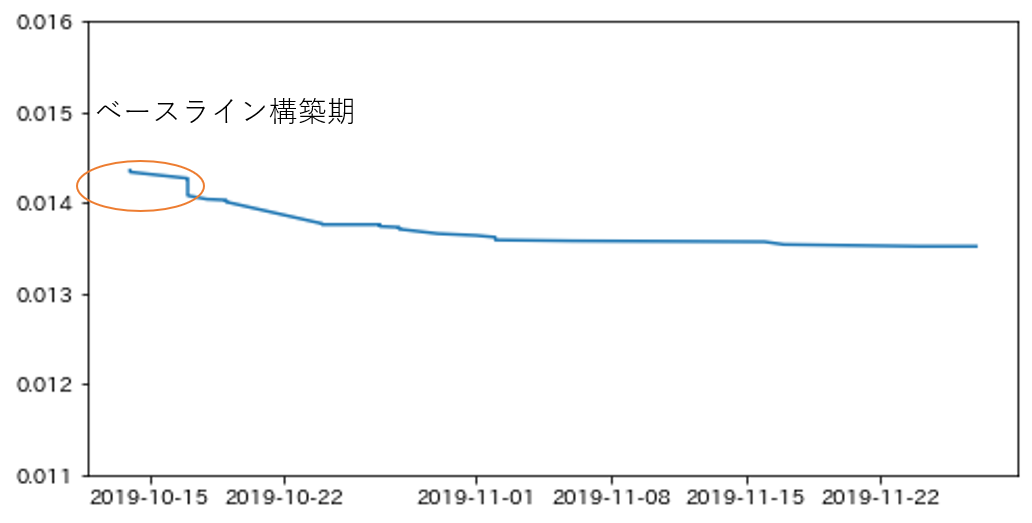
データ理解と軽くEDAを行い、特徴量作成やその他の工夫を行わないプレーンなモデルを作成する時期。適切なcross validationも(できるなら)ここで構築します。
ここはサブミットしない人多い気がしますが、比較のために私は必ずサブミットします。プレーンなモデルと上位モデルにどれぐらい差があるのかも知見の一つなので。
途中参戦の場合はベースラインとしてkernelで代替することもあります。
何やっても上がる黄金期

テーブルコンペの場合、ここから特徴量作成を開始します。ここで比較的容易に思いつく、これは上がるだろうなと思う特徴量から優先的に入れていきます。1回目のパラメータチューニングもここで行います(ちなみに私は温かみのある手動チューニング派です)。
ここからテーブルと画像に分けて記載します。
テーブル
- ドメイン知識に基づく誰もが思いつきそうな特徴量作成(大体kernelに載ってる)
- パラメータチューニング(1回目)
- 集約系の特徴量
- frequency encoding
- target encoding
- clipping
- binning
- 時系列のshift, diff, averaging
画像
- 比較的軽いネットワーク(resnet34をよく使う)で訓練
- learning rateとバッチサイズの調整
- スケジューリングをいくつか試す
- 画像に応じた効きそうなAugmentation(変換後、目で見てラベルが変わってしまいそうなものはここでは試さない)
- 前処理の工夫(リサイズ、ノイズ除去、背景処理など)
- 閾値の最適化(segmentation)
なんもわからん期
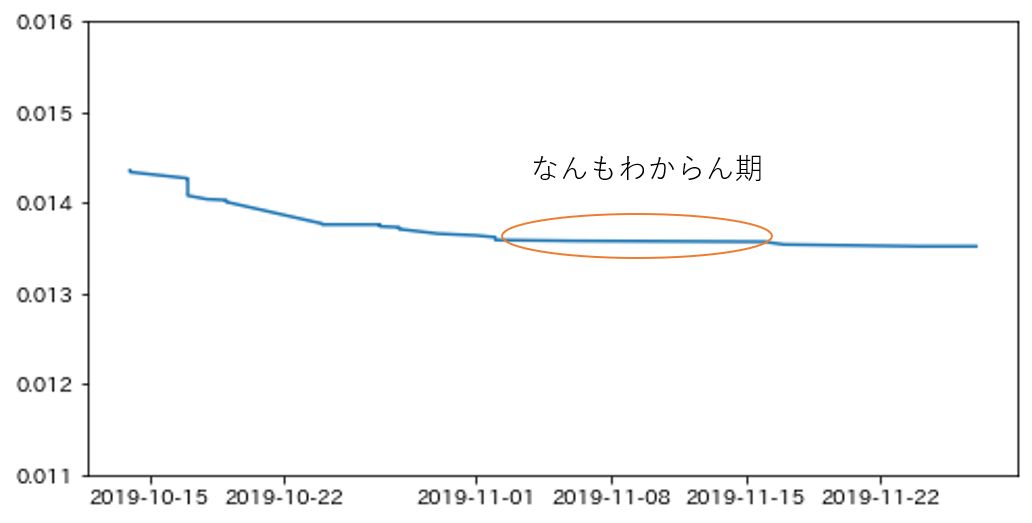
とにかく何をしてもうまくいかない時期。
効くと思った特徴量が効かなかったり、cvは上がるがLBが上がらない、cvは上がらないのにLBが上がるなど、何もわからなくなる時期。ある程度特徴量が作れてくると既に考慮されている特徴量を作成してしまってoverfitしがちになってくる(気がする)。
テーブル
- しらみつぶしにkernelやdiscussionの巡回をしてヒントを探す。
- interactionの特徴量を大量に作ってみる。
- 特徴量選択
- 一からモデルを作り直してみる
- 決定木の気持ちになって考える
- magic featureを探す
- 過去コンペのソリューションを漁る
画像
画像はあまり1回の学習に時間がかかることもあり、なんもわからん期が来る前に何かに気付いたり最終調整期に入ってしまう気もします。
- しらみつぶしにkernelやdiscussionの巡回をしてヒントを探す。
- mixup, cutmixなど混ぜる系のAugmentationや最新論文に出てきたものを試しだす
- 直感的に効きそうもないAugmentationもとりあえず試す
- ネットワークをおもむろにいじりだす(←画像だと大抵意味ない)
- Pseudo Labeling(効く場合が多いが、元の精度がある程度高くないといけないので、タイミングが難しい)
- Grad-CAMなどを用いて、NNが何を根拠に判断しているかを確認する
- lossを少し変えてみる
- 画像のリサイズの別バリエーションを試す
- NNの気持ちになって考える
LeaderBoard上でガンガン抜かれるので、この時期がひたすらつらいです。
金メダルを獲得したFreesound Audio Tagging 2019では、puclic kernelの精査が突破口になりました。
何かに気付いた期
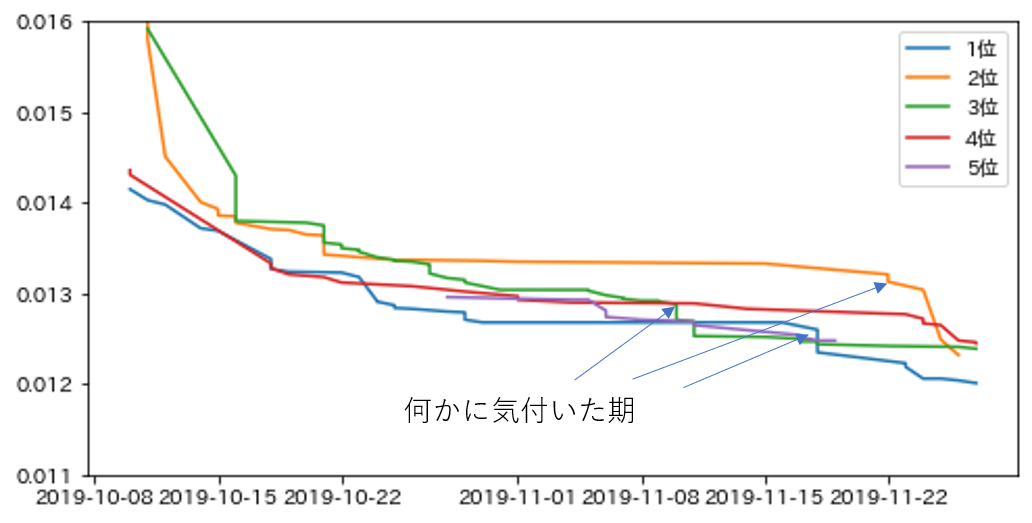
(上の矢印は妄想)
NFLコンペでは残念ながら私にはこの時期はなかったのですが、Leaderboardを見てると急にジャンプアップする人が結構います。
理由は様々だと思うのですが、ソリューションなどを読んでいると、共通して言えることは、やはりデータをよく見ていると思います。
- Leakを発見
- Leakに基づく特徴量作成や、最適化
- 深い洞察に基づく特徴量の作成
- train内、train/testの分布の違いを吸収するための正規化等
- 決定木の気持ちがわかる
- NNの気持ちがわかる
- magic featureを見つける
「深い洞察に基づく特徴量の作成」はコンペによるので一般的に表しにくいのですが、こちらの記事がとても参考になると思います。
(参考:普通のデータサイエンティストと世界トップクラスのデータサイエンティストの違い)
アンサンブル&最終調整期
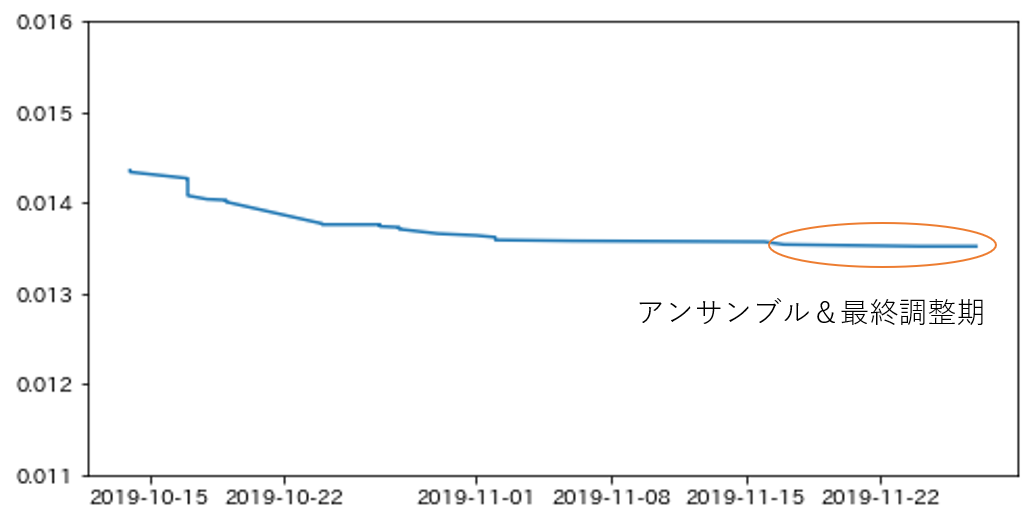
今回のNFLコンペでは打つ手がなくなって早めにアンサンブル&最終調整し始めてしまいましたが、通常は1week前ぐらいから行う人が多い印象です。
基本的に、スコアが上がると分かっているけど、計算量が増えるものに関しては最後に行うことが多いと思います。
アンサンブルは確実にスコアが上昇するので、kernelコンペなどで時間制限に引っかからない限り、サチるまで最大限やります。パラメータチューニングの2回目もここ。テーブルの場合たいてい特徴量を大量に追加しているのでここでもう一回調整すべき。learning rateも落とします。チームを組んで、それぞれ別のモデルを作成している場合はアンサンブルの効果が大きい場合が多いはずです。
テーブル
- パラメータチューニング(2回目)
- GBDTのlearning rateを落とす
- アンサンブル(seed averaging, xgboost/catboostと混ぜる, 違う特徴量を使ったモデルと混ぜる, チームメンバーのsubと混ぜる)
- スタッキング
画像
画像は1回の学習に時間がかかるので、アンサンブル用の訓練を始めるのはもっとはやいことが多いと思います。
- 重めのネットワークに移行(ResNet-101, Densenet-121~, inceptionv3, ResNeXt-50-32x4d~, Wide ResNet-50-2~)
- 様々なバリエーションのネットワークでアンサンブル
- tta(test time augmentation)
- snapshot ensemble
- epochを伸ばす(学習不足の場合)
- パラメータ微調整
以上でKaggleのコンペスタートから、最後のサブミットまでのプロセスは終わりです。
もちろん全員がこのプロセスでやっているわけではないと思いますし、コンペの課題によって取り組む順番は違ってくるのですが、コンペを複数経験するとある程度プロセスは収斂してくるような気はします。もっと強い人たちのプロセスを私も知りたいです。
最後にオマケです。
これからKaggleを始める人のベストプラクティス
私見ですが、これからKaggleを始める人はこのルートを通るのがおすすめです。
①Kaggleに登録したら次にやること ~ これだけやれば十分闘える!Titanicの先へ行く入門 10 Kernel ~
こちらは2020年3月に講談社からKaggle入門書として出版予定だそうです(https://upura.hatenablog.com/entry/2019/12/04/220200)

②過去コンペ/現行コンペのvote数の多いkernelを写経する
素晴らしいkernelは知見の宝庫です。特に初心者向けのものには大量のvoteがつく傾向にあるので、vote数が多く、最初から丁寧に解説してくれていそうなものを選びましょう。スコアがついているものであればsubmissionの流れまで学べます。私はHome CreditコンペのStart Here: A Gentle Introductionから始めた気がします。
③Kaggleで勝つデータ分析の技術
言わずもがなの鉄板書籍。全くの初心者向けの書籍ではないため、上記のプロセスを踏んでからのほうがいいと思います。
コードも載っているのでテーブルコンペであればこれを片手に現行コンペに参加すれば力がつきそう。

終わりに
各方面に散らばっていたり、Kagglerの中で暗黙知だった情報が、書籍でまとまってきたのでKaggleを始めるのに絶好の機会だと思います。
もしこの記事が、Kaggleを始めたい人の助けになれば幸いです。