簡単な分析環境がすぐできるらしいので試してみました
※ちなみにAzure Data Lake Storage Gen2 はまだプレビューだそうです。
そもそもAzure Data Lake Storage Gen2 ってなによ
Azure Blob ストレージと Azure Data Lake Storage Gen1 という、既存の 2 つのストレージ サービスの機能を集約したもの。
ファイル システム セマンティクス、ディレクトリ、ファイル レベルのセキュリティおよびスケーリングなど、Azure Data Lake Storage Gen1 に由来する機能が、Azure Blob ストレージの低コストの階層型記憶域、高可用性/ディザスター リカバリー機能と組み合わされています。
公式引用
よくわかりません
※翻訳してみました※
前身のAzure Data Lake Store がもともとサイズ無制限であらゆる種類のデータを保存することができ、高セキュリティ(AzureADとの連携)・高可用性(3重のレプリカ構造)、WebHDFS互換(Hadoop Distributed File System)の分散型ファイルシステムでした。
要するに大量のログなどをとりあえず生のまま保存することができ、複数の(HDFS接続のできる)分析基盤との接続もできるので多角的にデータを有効活用できるようになるようです。
またGen2でBlob Strageの機能も加わったため、価格がBlob Strageベースの安価なものになり、使いやすくなりました
という理解
Azure Data Lake Storage G2 を使うと何がうれしいの?
大量のログなどを容量を気にすることなく、とりあえず生のまま安価に高機能なストレージに突っ込むことができる
またHadoop互換のシステムとの連携もできるので分析だけではなく機械学習や他の分野にもデータを活用することができる。
あと生データが保存できるので、後で別のシステムで活用することも可能
とりあえず使ってみる
PowerShellとかやり方はいろいろあるみたいだけど、今回はAzureポータルから使用開始してみたいと思います
(1)Azure Data Lake Storage Gen2 対応のストレージ アカウントを作成するため
Azure Portal の左側のメニューから「リソース グループ」 をクリック

(2)「追加」をクリック
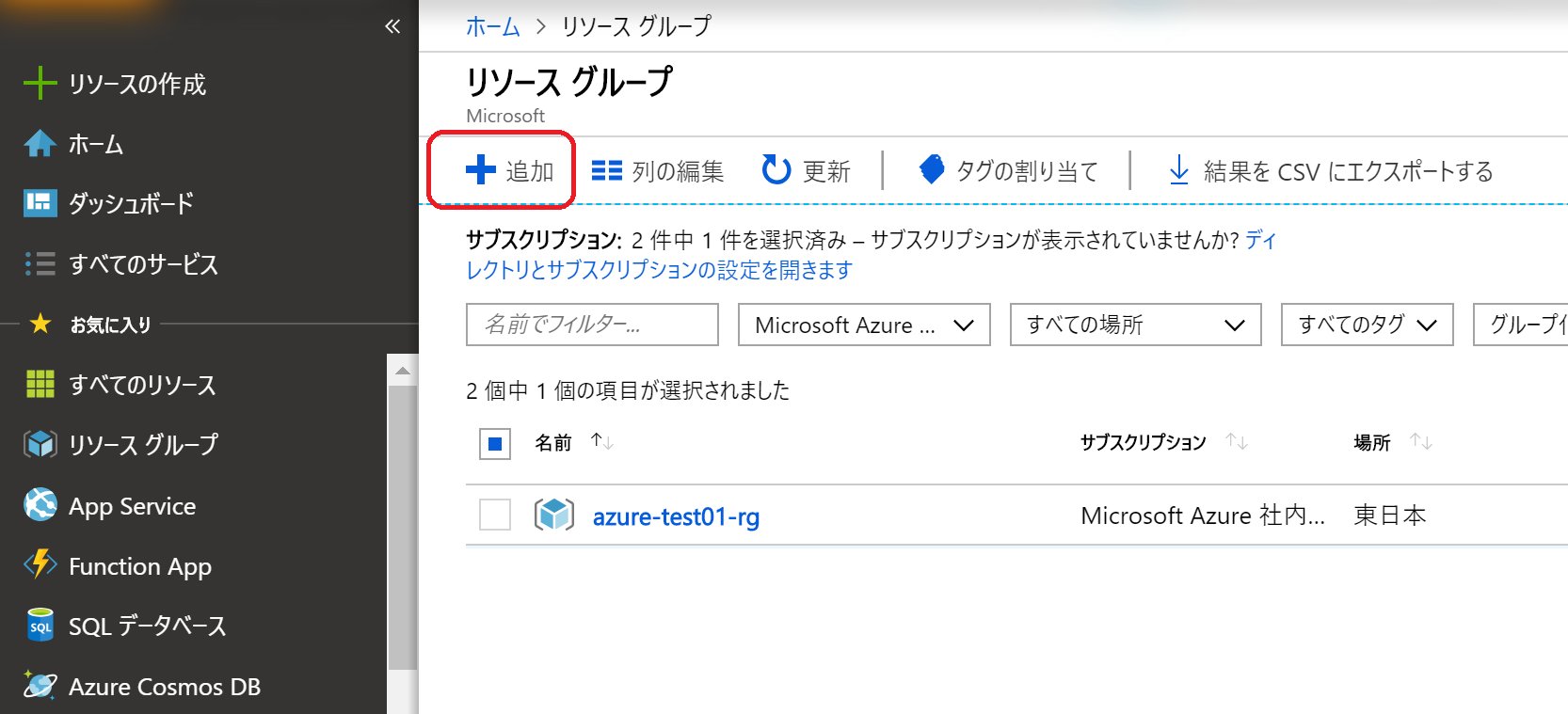
(3)サブスクリプション、リソースグループ、リージョンを適宜選択し、「確認および作成」をクリック
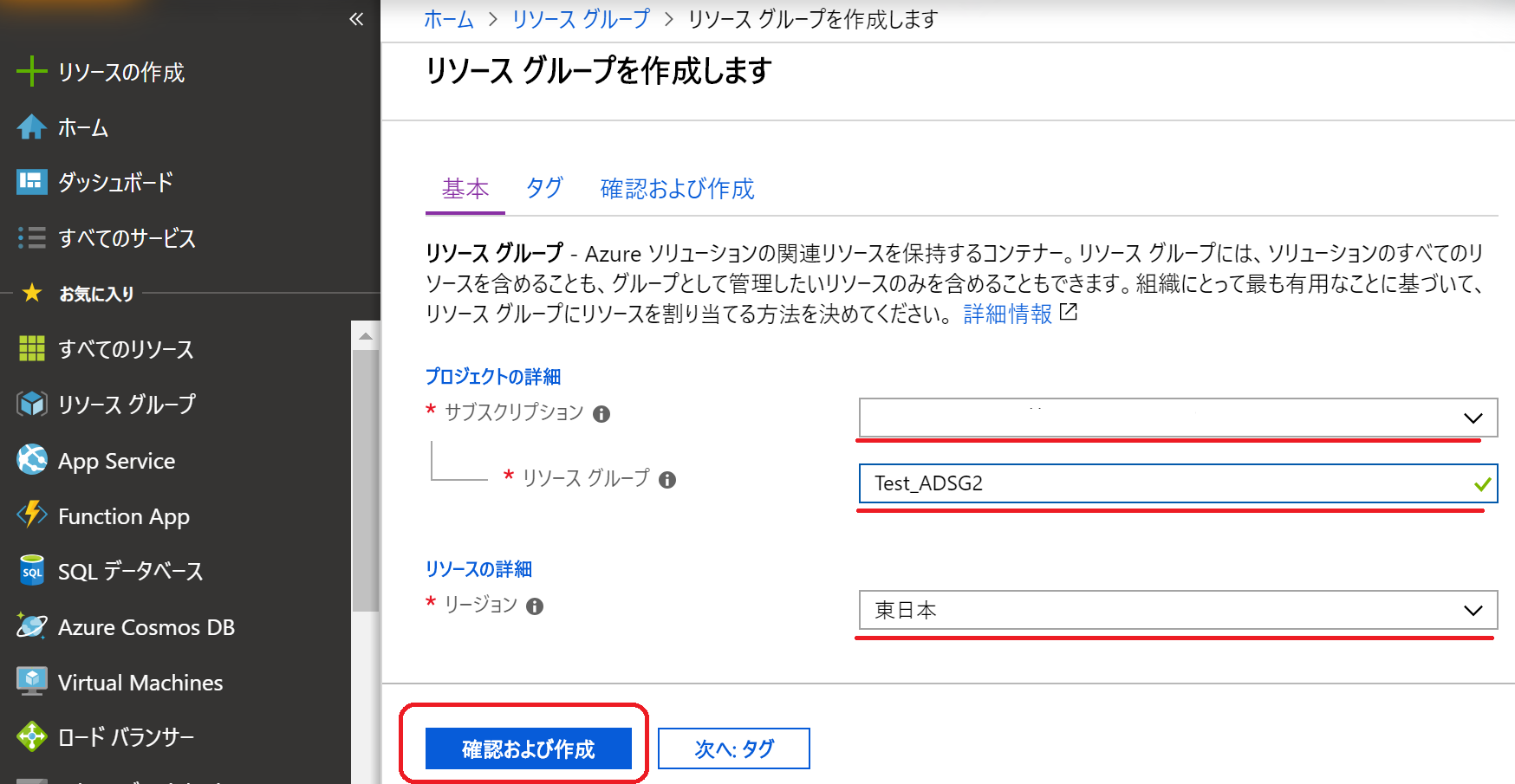
(4)確認画面が出るので問題なければ「作成」をクリック
(5)Azure Portal の左側メニューから「ストレージ アカウント」をクリック
(6)「追加」をクリック
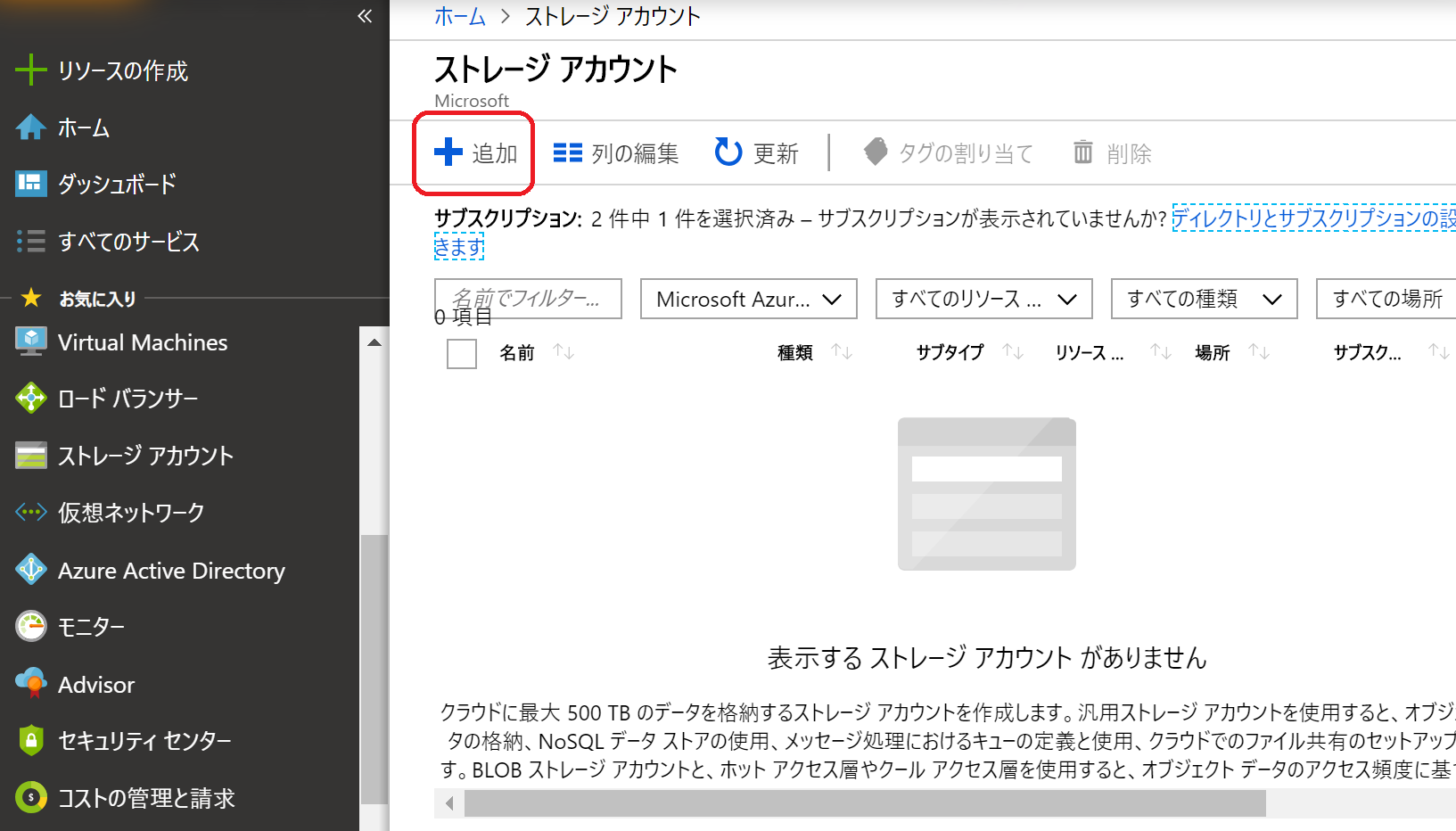
(7)必要項目を記入・選択し、「次:詳細」をクリック
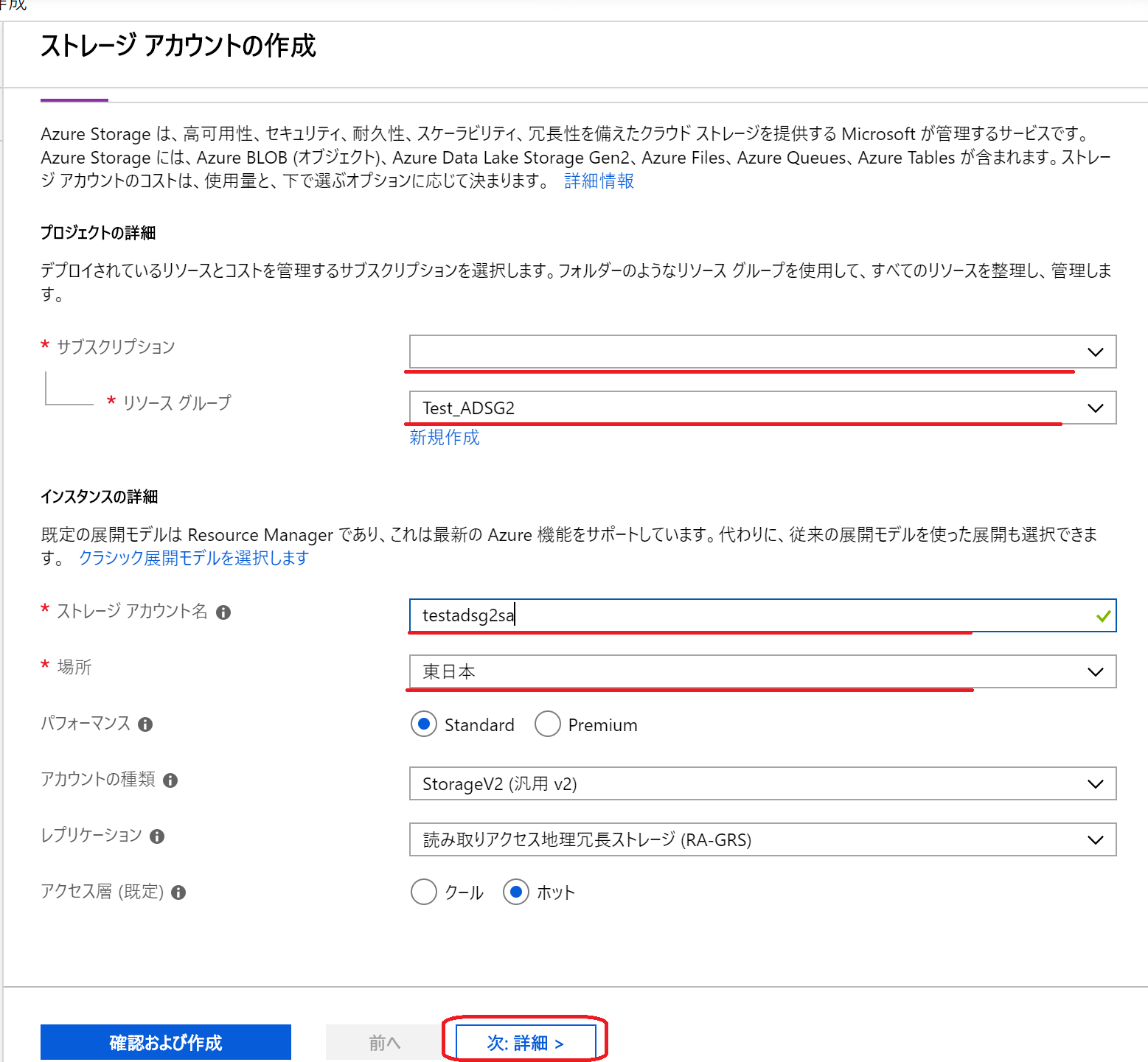
(8)DATA LAKE STORAGE GEN2(プレビュー)を「有効」に変更し、「確認および作成」をクリック
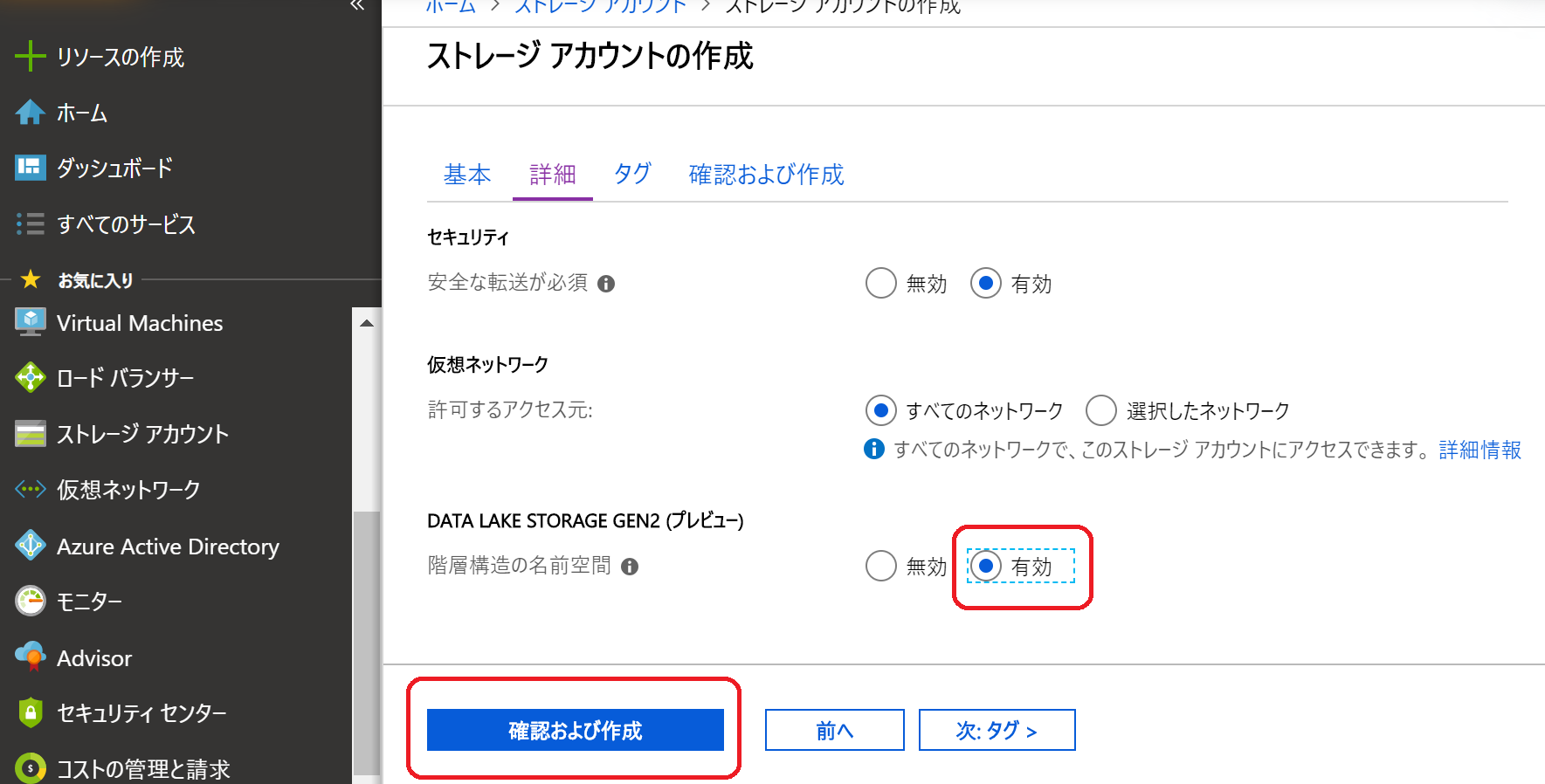
(9)「検証に成功しました」と表示されたら設定項目を確認し「作成」をクリック
データを取り込んでみる
(10)Azure Data Lake Strage Gen2 にログデータなどを取り込みたいので、今回はAzure Data Factoryを利用したいと思います
どうもいろんなタイプのログやデータを取り込んでアウトプットできるらしい(曖昧)
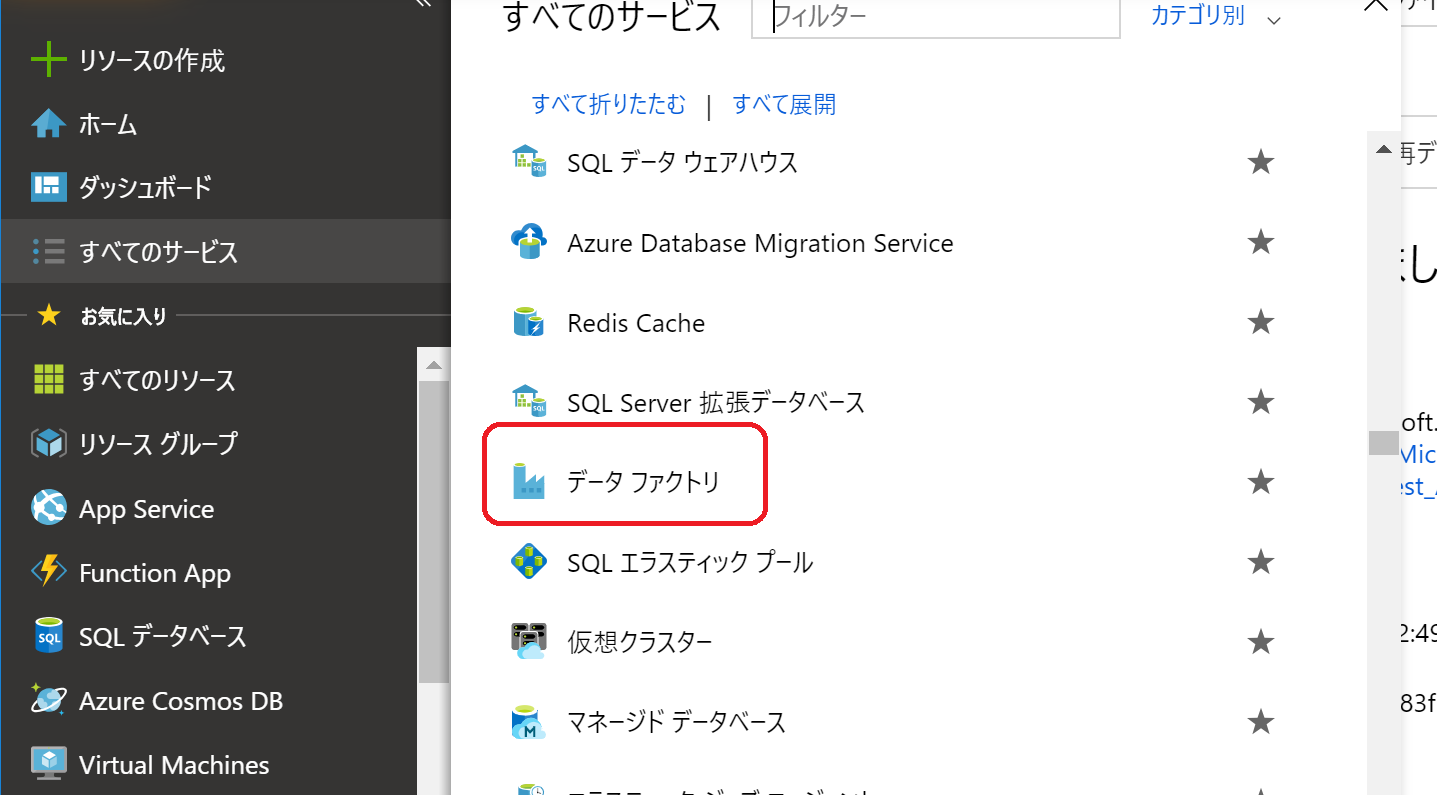
Azure Portal の左側のメニューから「すべてのサービス」-> 分析の「データ ファクトリー」 をクリック
(11)追加をクリック
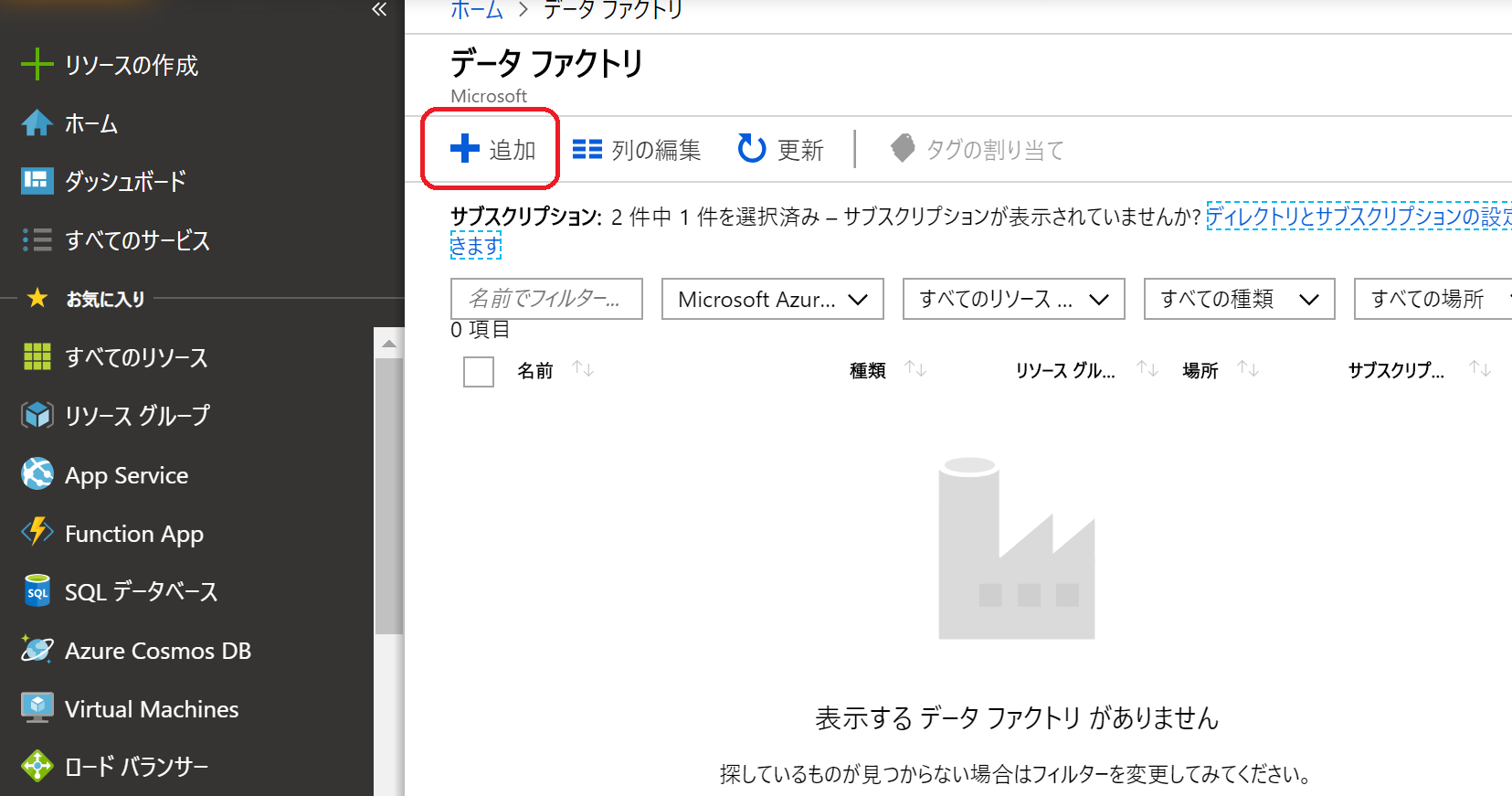
(12)新しいData Factoryを作成するため、必要項目を入力し「作成」をクリックする
ちなみに、名前はグローバルで一意である必要がある
リソースグループは(1)で作成したものを選択
場所はまだ日本はないらしい・・・(早く実装されてほしい)
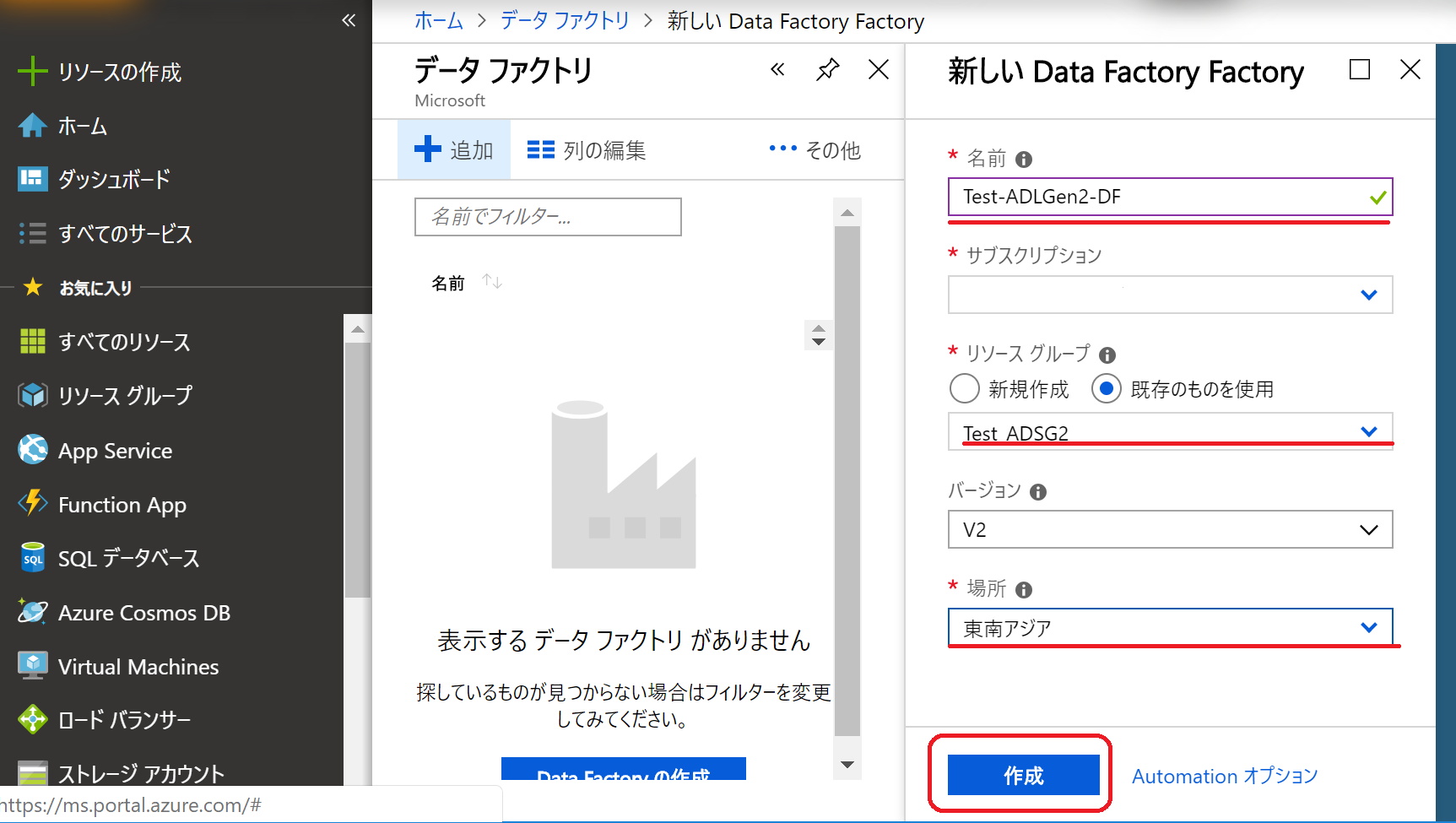
(13)作成したデータファクトリーを開き「作成と監視」をクリック
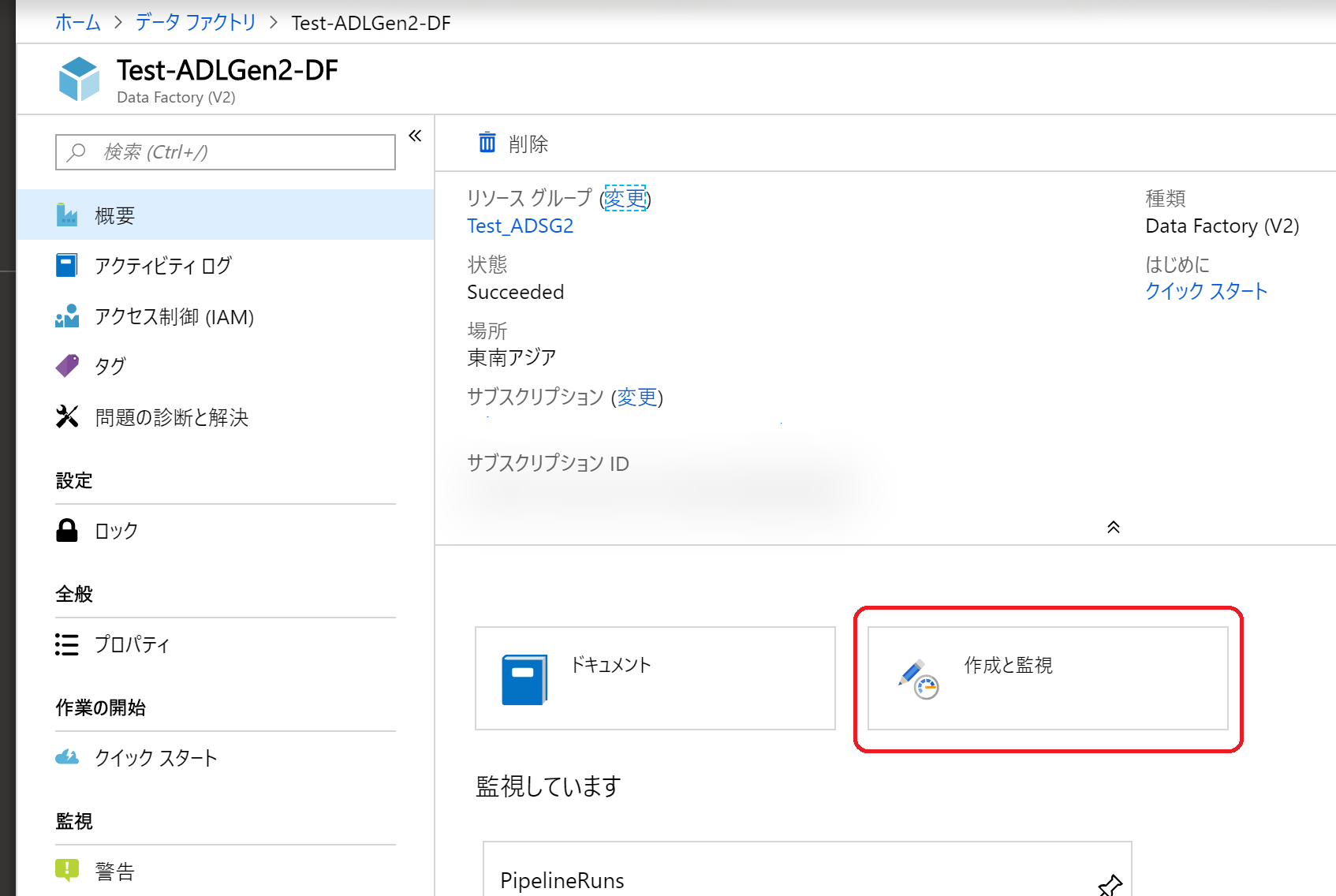
(14)別タブでデータ統合アプリケーションが開くので(結構時間がかかる)、「Copy Data」をクリック
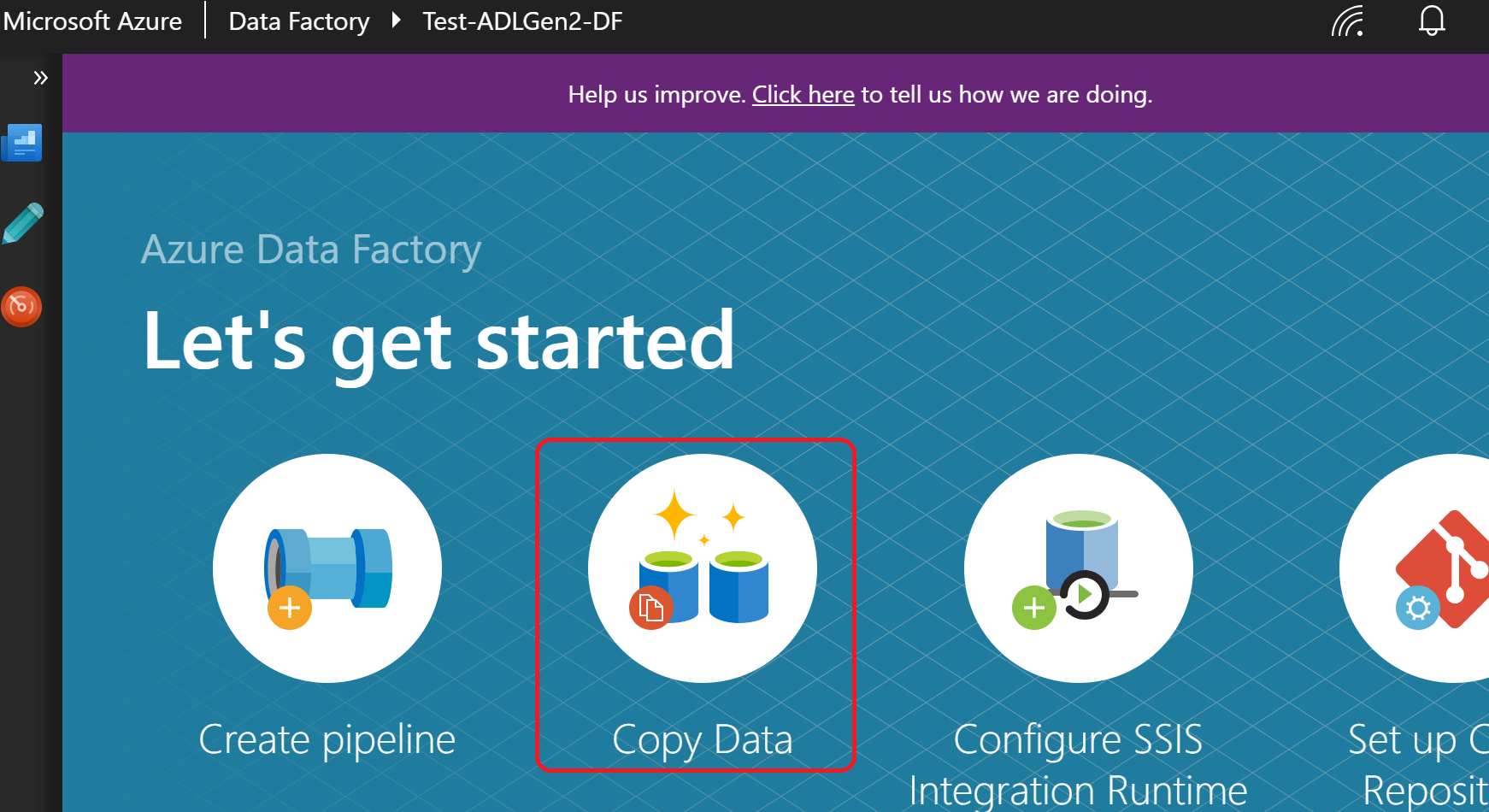
(15)Task name を適当に設定し「Next」をクリック
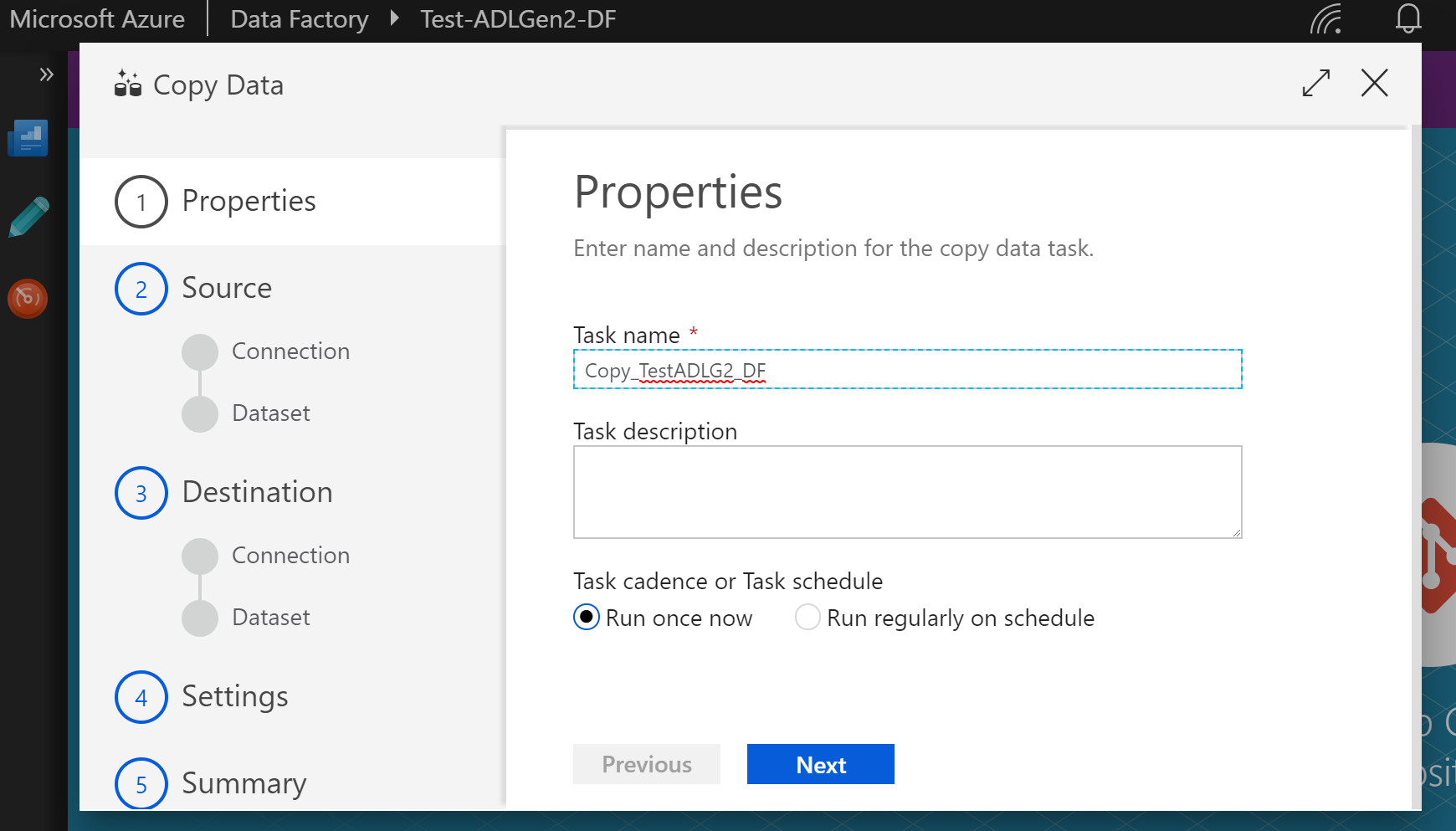
(16)データソースを選択するため、「Create new connection」をクリック
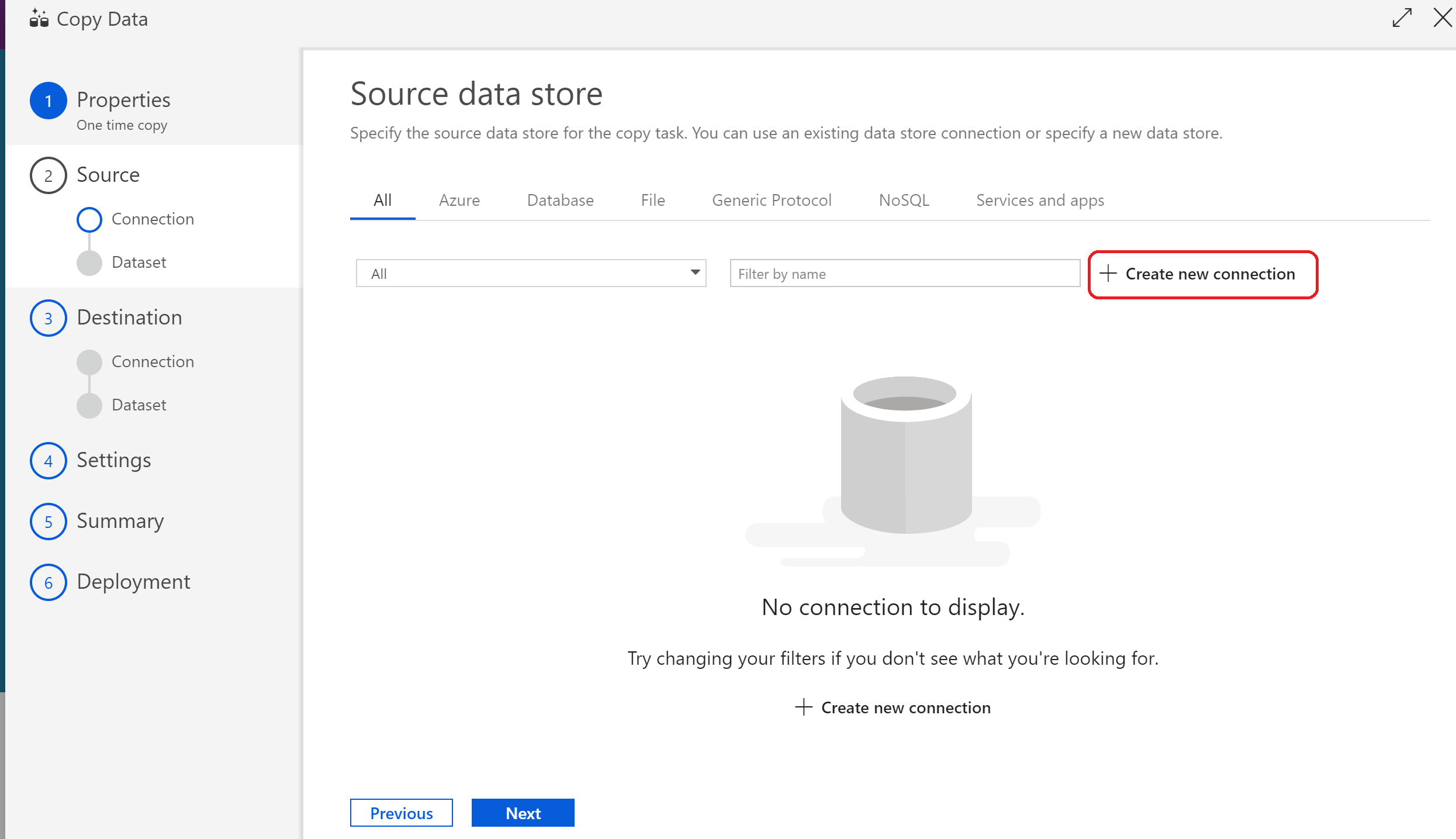
(17)接続させたい接続元サービスを選択する
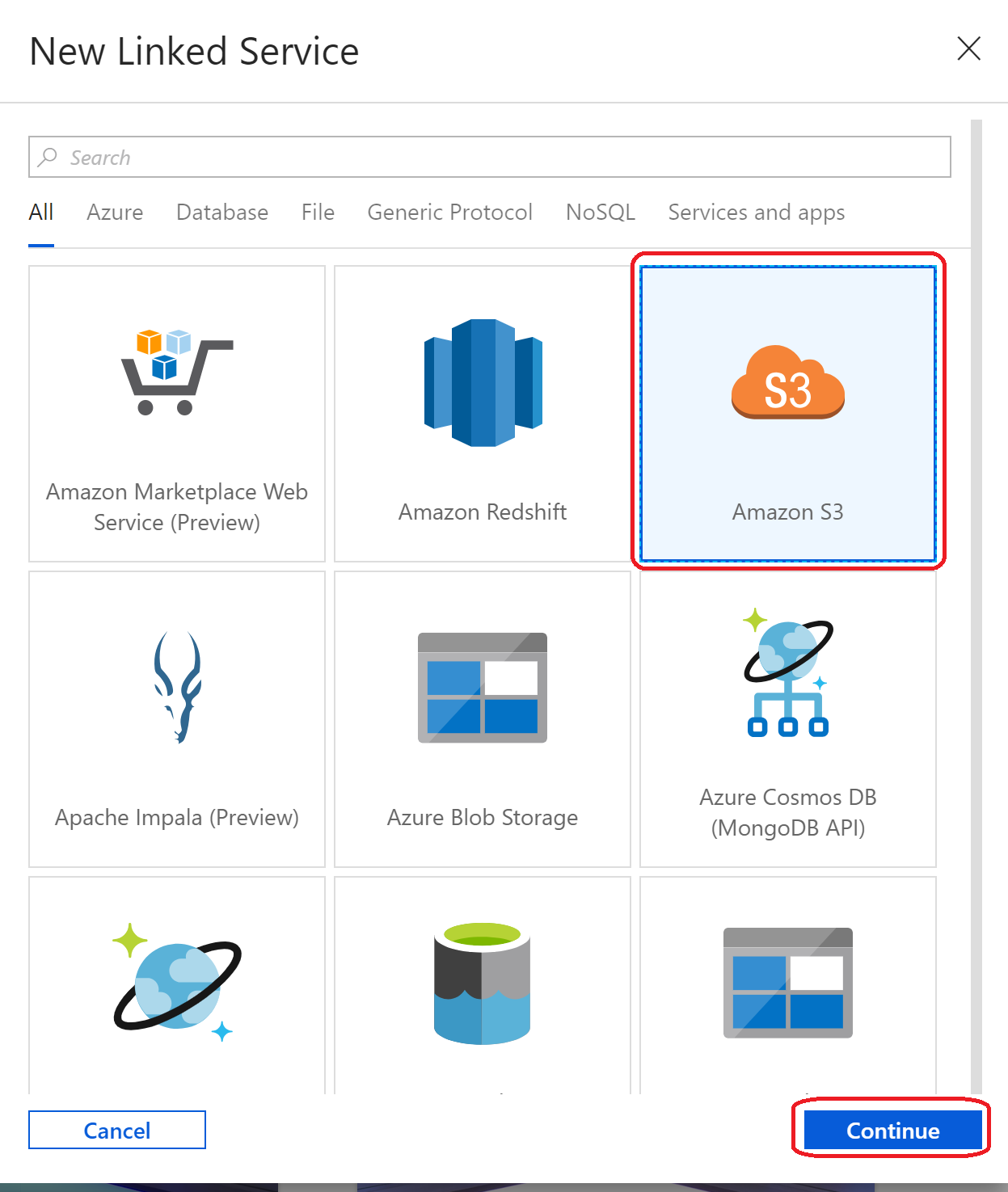
Amazon Redshift や Google BigQuery とも連携できるようなのですが、テストとしてAmazonS3にあるファイルを取りこんでみる
というわけで、「Amazon S3」を選択し「Continue」を選択
(18)設定したいS3の情報を記載し、「Test Connecting」をクリックして問題なければ「Finish」をクリック
(S3側であらかじめアクセスキーを設定しておく必要あり)
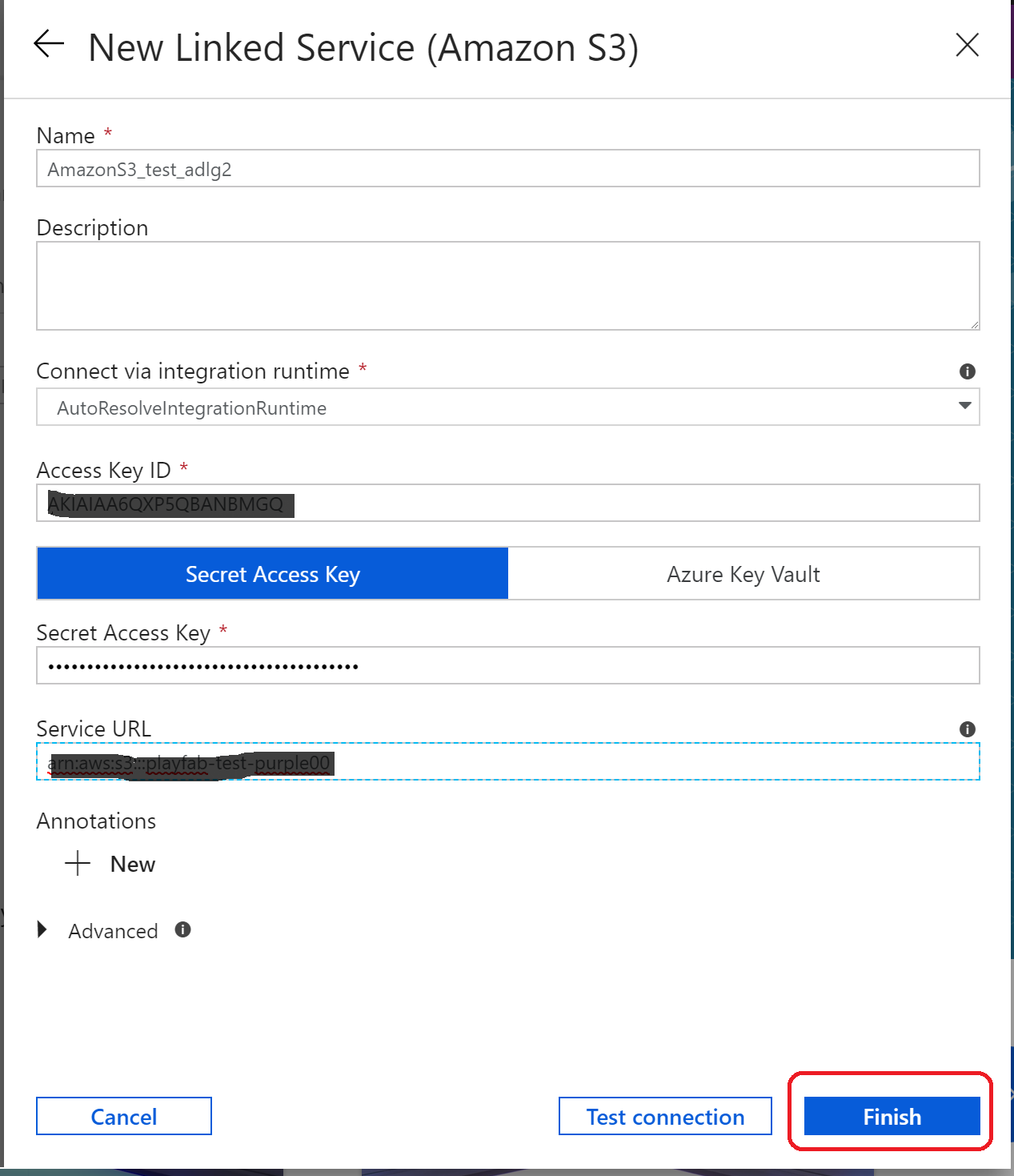
(19)「Next」をクリック
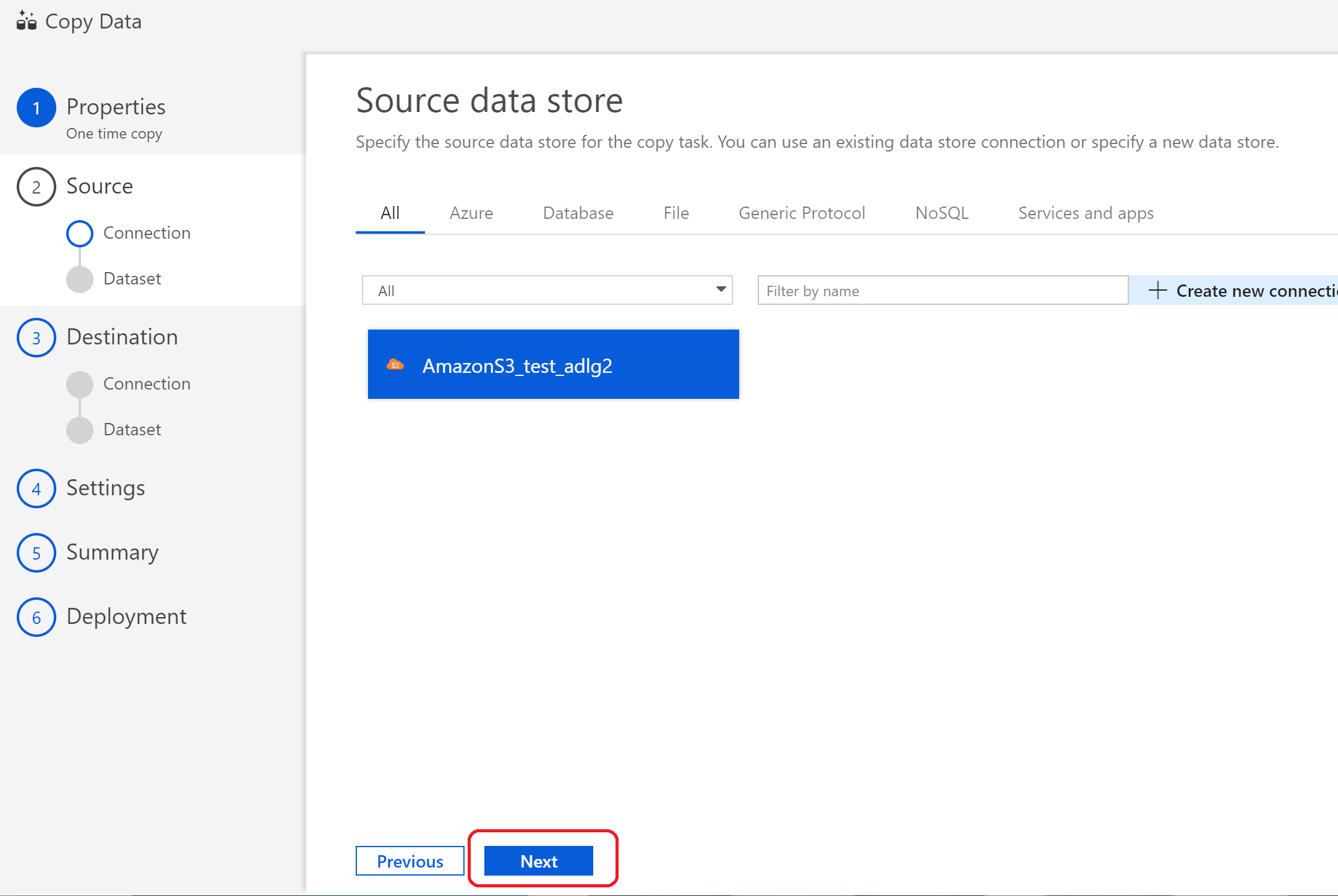
(20)ソースとなるフォルダまたはファイルを「Browse」ボタンから選択し、「Copy file recursively」(ファイルの再起コピー)と「Binary Copy」にチェックを入れて「Next」をクリック
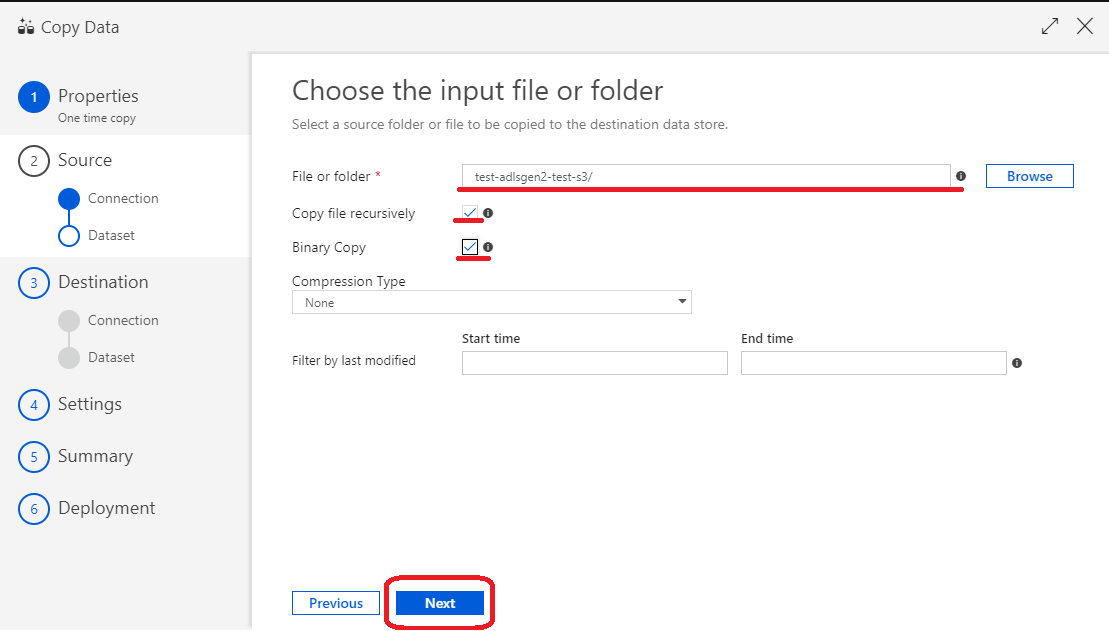
(21)データのストア先を設定するため、「Create new connection」をクリック
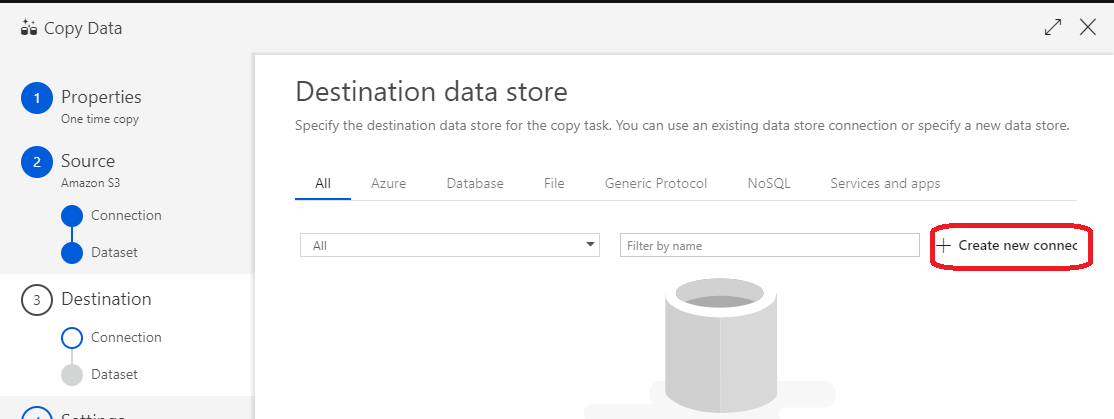
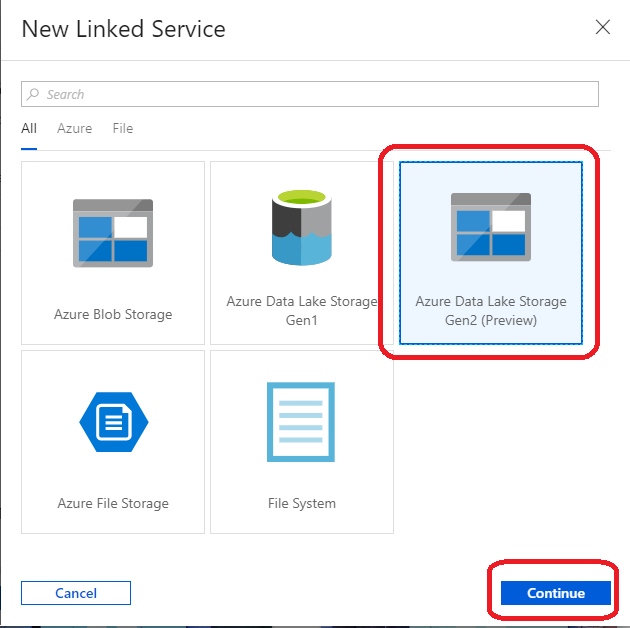
(22)「Azure Data Lake Storage Gen2」 を選択して「Continue」Continue をクリック
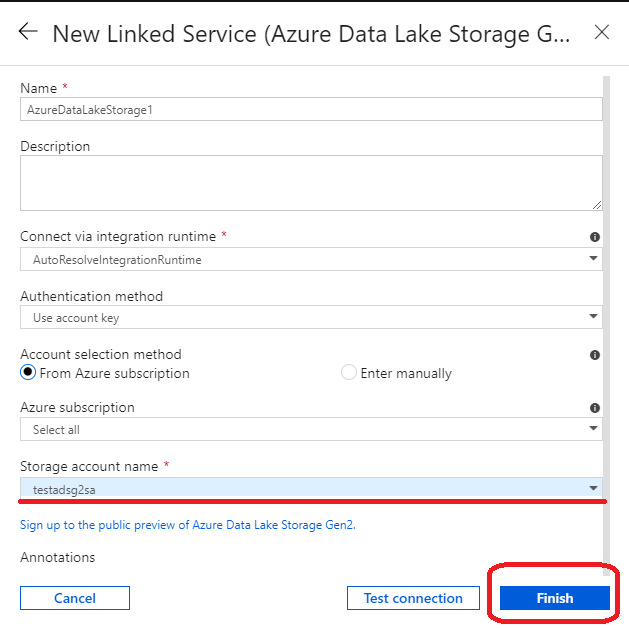
(23)(7)で指定した Strage account name を指定し「Finish」をクリック
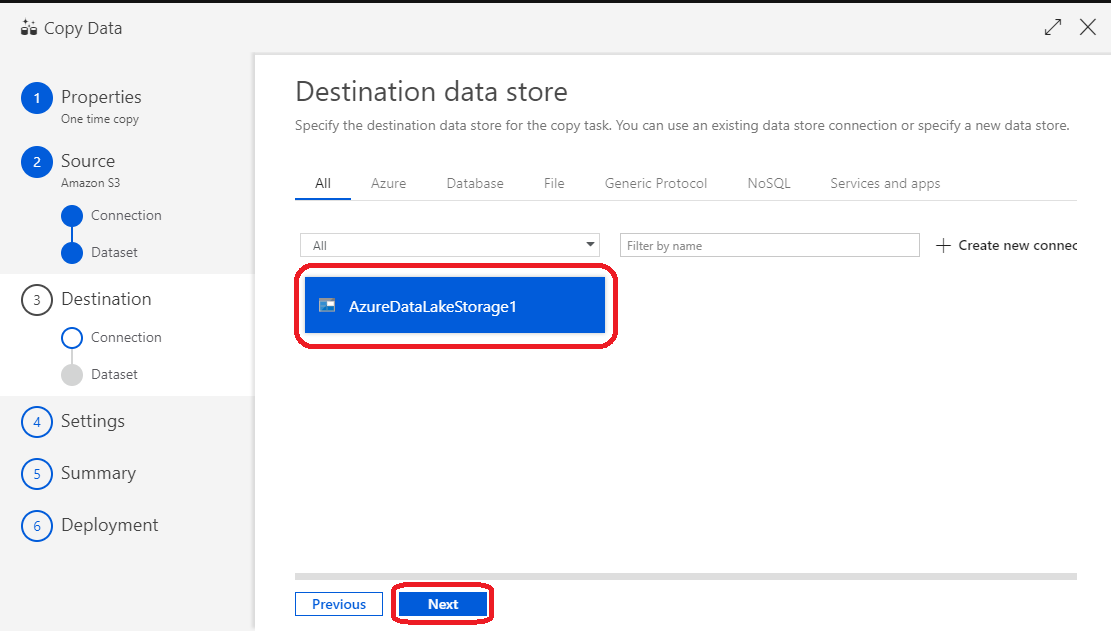
(24)正常に登録されていることを確認し「Next」をクリック
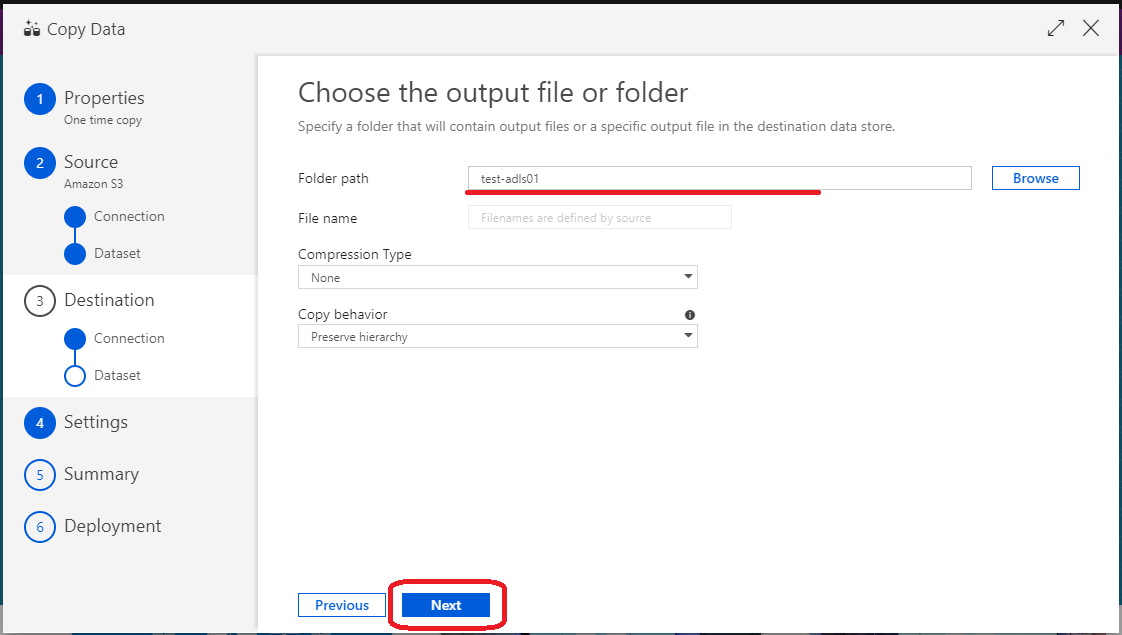
(25)「Folder path」に出力先のフォルダ名を入力し「Next」をクリック
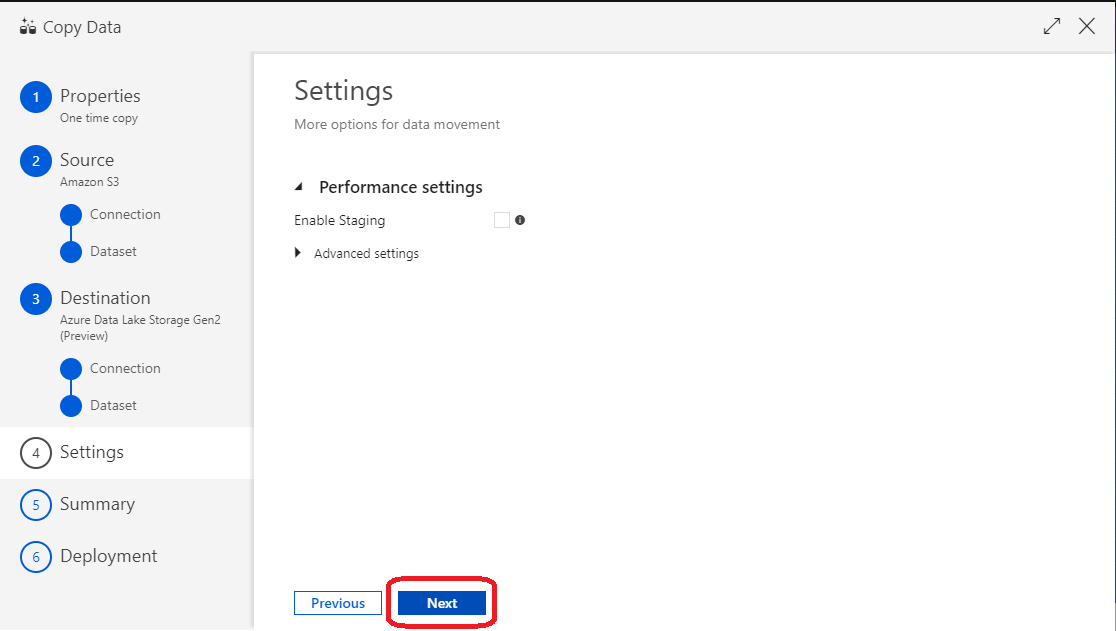
(26)オプション設定なので特に設定せず「Next」をクリック
(27)ここまで設定してきた内容を確認し、問題なければ「Next」をクリック
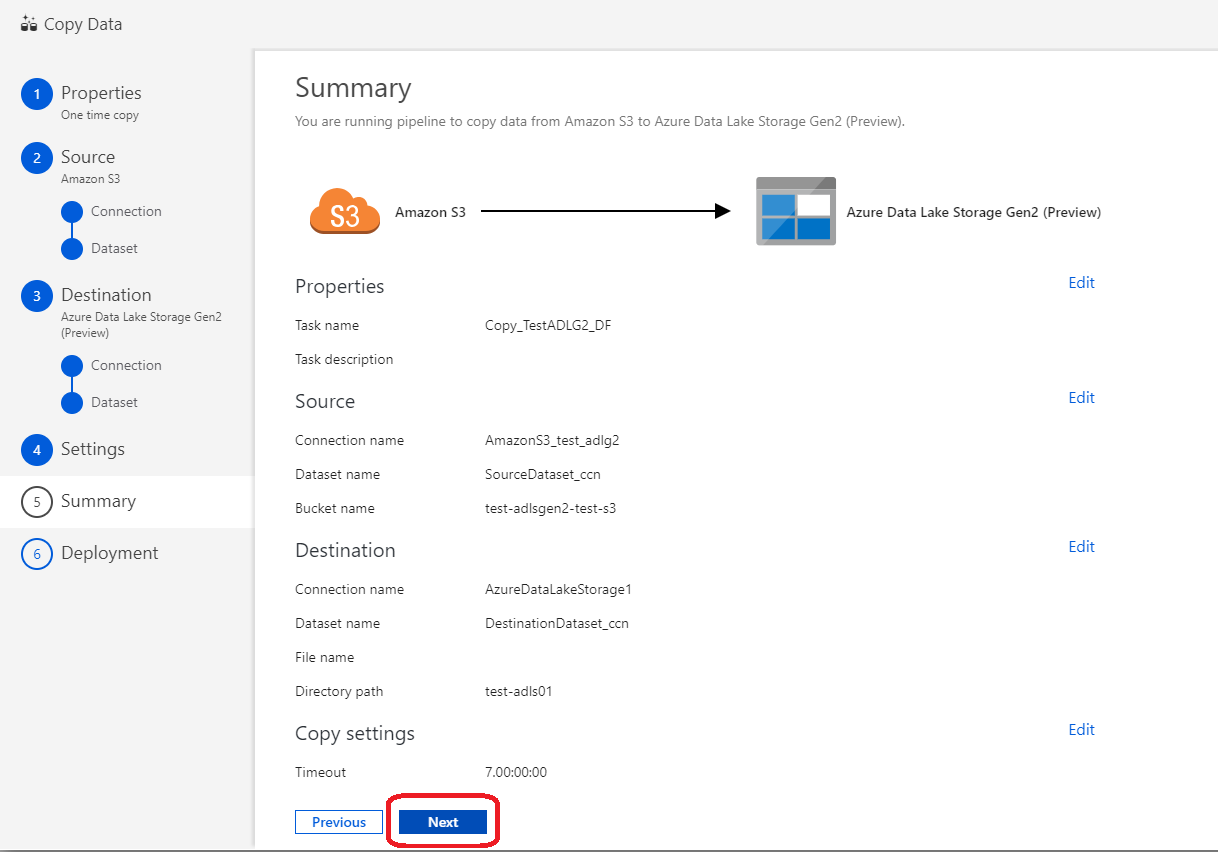
(28)正常にDeployが完了したら「Monitor」をクリックする
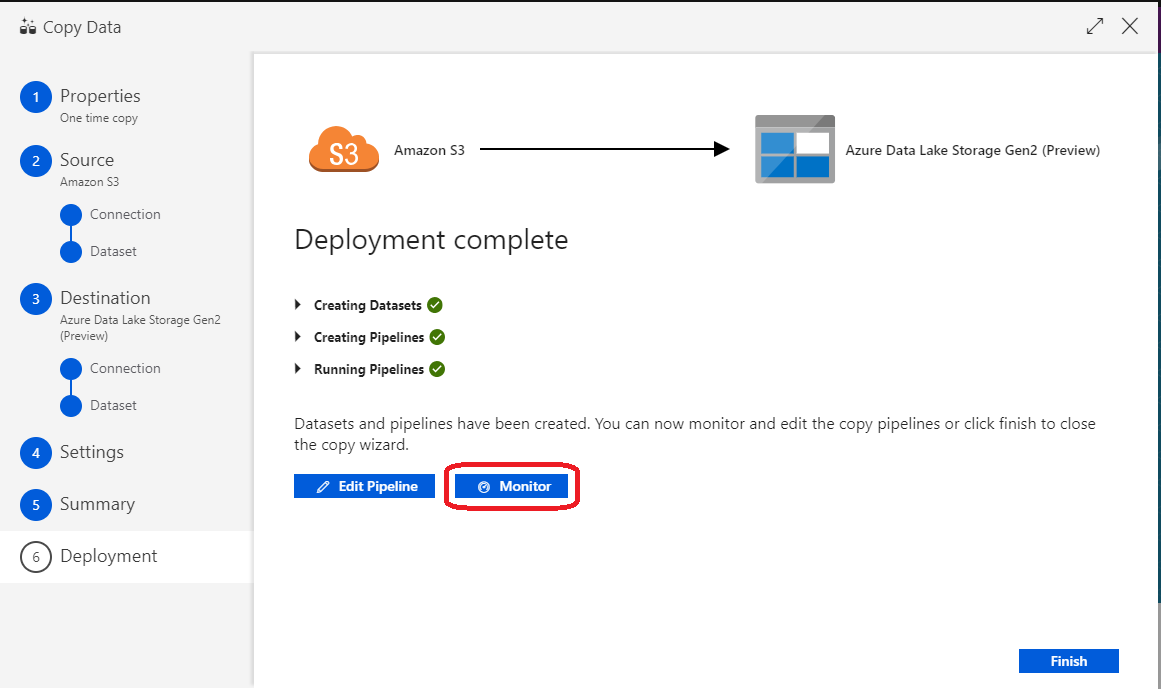
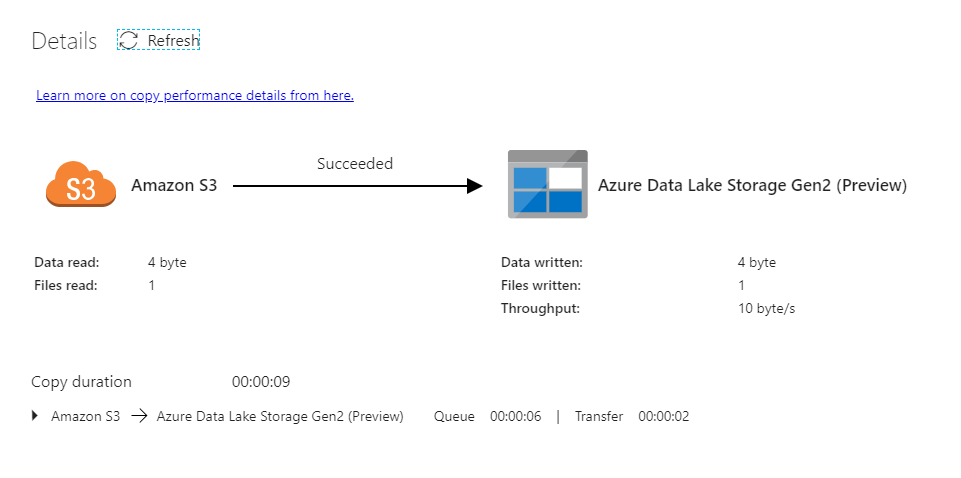
(29)実際に実行してファイルコピーの結果は下図のように確認することができる
テストでファイルが小さいので早いですね
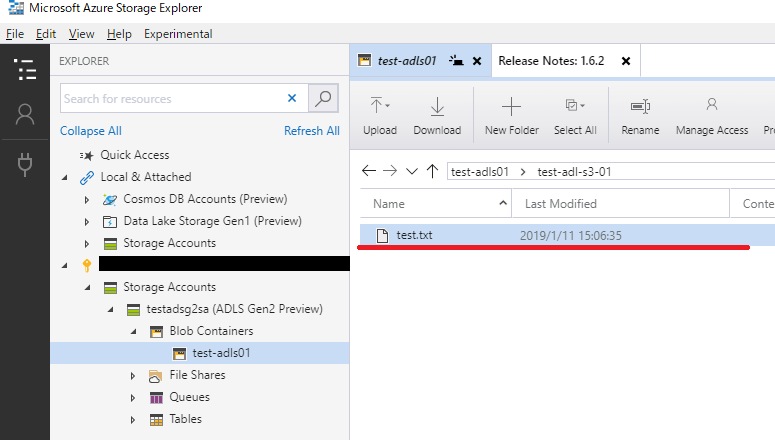
(30)実際にコピーした情報は、Azure Storage Explorer からも確認することができた
次回はこれを使って分析する方法をテストしてみたいと思います。