はじめに
『オープンソースデータベース標準教科書 -PostgreSQL-(Ver.2.0.0)Kindle版』で
「郵便番号のCSVファイルを格納するデータベースを設計し、そこにデータを格納する」という演習があったので、実行したい。
(教科書の章=4.演習 --4.2演習2:郵便番号データベース)
の続き。
今回やること
[WSL2(Ubuntu)にインポートした郵便番号CSVファイル]をDBにインサートしたい。
そのために・・・
① 郵便番号データを格納するための表をDBに作成
② psqlから\copyメタコマンドで①の表にCSVファイルをインサート
以上2点を実行する。
環境
| バージョン | ||
|---|---|---|
| Host OS | Windows 10 Home | 21H1(OSビルド:19043.1165) |
| Virtual Machine(仮想環境技術) | WSL2 | - |
| Remote OS(仮想環境OS) | Ubuntu | 20.04.2 LTS (GNU/Linux 5.4.72-microsoft-standard-WSL2 x86_64) |
| Database | PostgreSQL | 12.7 (Ubuntu 12.7-0ubuntu0.20.04.1) |
| Database GUI | 無し | - |
| Docker | 無し | - |
| エディタ | Visual Studio Code | 1.60.0 |
① 郵便番号データ(CSV)を格納するための表をDBに作成
◆前提条件◆
VSCでpostgresサービスに接続し、psqlシェルに入っている状態。
(今回の場合はユーザー名「postgres」でpsqlに入ったので、コマンドラインが「postgres=#」で始まっている状態。)
◆表作成◆
CREATE TABLEで「zip」という名前のテーブル(表)を作る。
# CREATE TABLE zip
(lgcode char(5), oldzip char(5), newzip char(7),
prefkana text, citykana text, areakana text, pref text,
city text, area text, largearea integer, koaza integer,
choume integer, smallarea integer, change integer, reason integer);
実行画面。↓ 入力したコマンドの次行に「CREATE TABLE」と表示された。

表、できた!!
◆気になったのでメモ(データ型)◆
(自分メモ:以前の記事 をコピペ&修正 ↓)
上記CREATE文中で定義しているデータ型は「char(n), text, integer」の3種類。
| データ型 | 意味 |
|---|---|
| char(n) | 空白で埋められた固定長のデータ型。またの表記をcharacter(n)。 |
| text | 制限無し可変長のデータ型。 |
| integer | 4バイト符号付き整数のデータ型。 |
↓ text型についてメモ ↓
PostgreSQLは、いかなる長さの文字列でも格納できるtextをサポートします。 text型は標準SQLにはありませんが、多くの他のSQLデータベース管理システムも同様にサポートしています。
(引用元:PostgreSQL 9.3.2文書 第8章データ型 8.3.文字型)
◆気になったのでメモ(表の確認)◆
本当に表作成できたのか、確認したくなったので
# \d zip;
(\d テーブル名 = テーブル構造の表示)
(; を忘れずに!)
で確認。
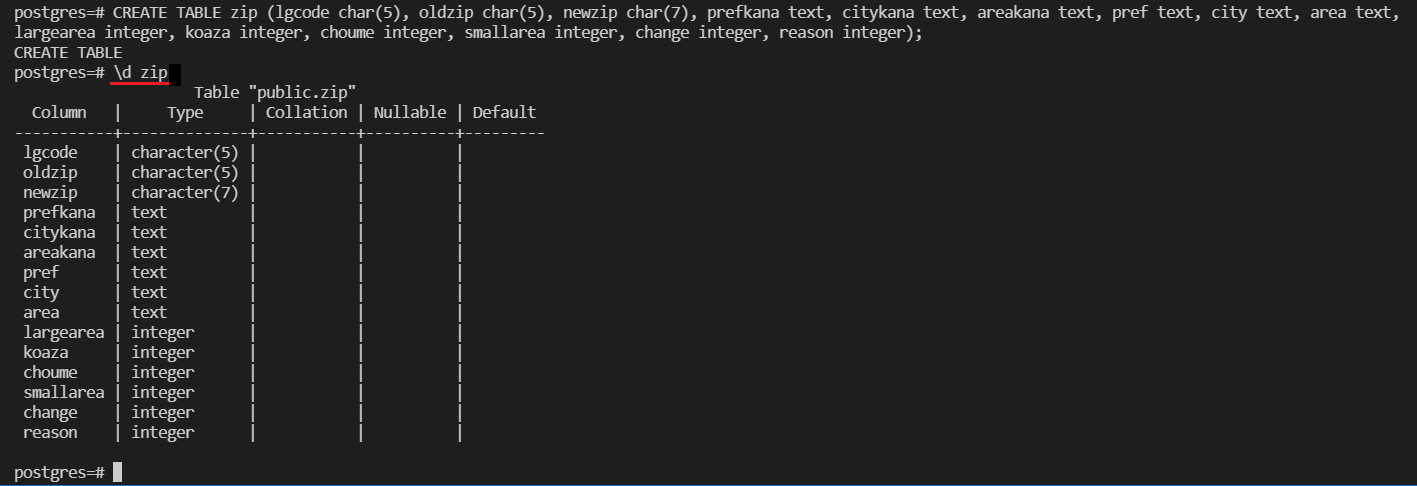
OK!できてた!
② psqlから\copyメタコマンドで①の表にCSVファイルをインサート
標準教科書に
psql から\copy メタコマンドでロードします。
ossdb=# \copy zip from KEN_ALL_UTF8.CSV with csv
(引用元:『オープンソースデータベース標準教科書 -PostgreSQL-(Ver.2.0.0)』4.2.3 データのロードと文字コードについて)
とあったので、自分の状況に合わせてコマンドを替えて、実行する。
# \copy zip from database/KEN_ALL.CSV with csv
(copy ロード先のテーブル名 from 絶対パス/ロードするファイル名 with csv)
(copy from = ファイルをテーブルに読み込むコマンド)
(FROM句には、DBサーバ内の絶対パスで対象ファイルを指定する)

「COPY <CSVファイルの桁数>」が表示された。
インサート完了!
↓
# select * from zip;
(SELECT文。「zip」テーブルから全データを取得。)
でインサートできているか確認。
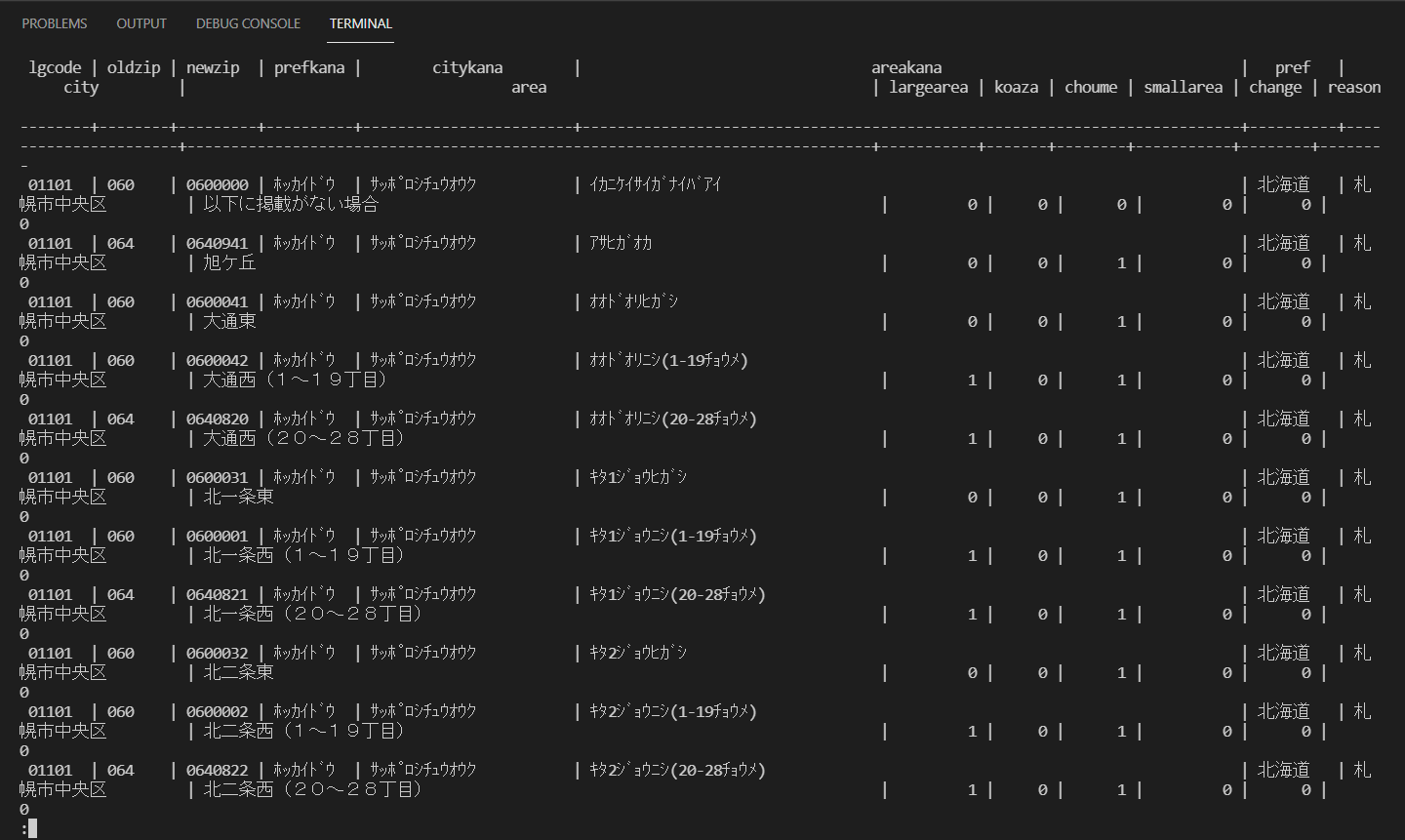
OK!できてた!
メモ
◆catコマンドとdコマンドの違いは?どちらも情報を閲覧しているように思える。
cat=ファイルの閲覧。
d=テーブル(表)に含まれるカラムに関する情報を取得。
今回のケースだと、
catはテーブル作成の前に、「CSVファイルを閲覧」するために使用した。
dはテーブル作成の後に、「テーブルの構造を表示」するために使用した。
◆コマンドは「\」で始める。SQLは「;」で終わる。
「;」について ↓
1行の最後にセミコロン(;)があれば,そこまでをSQL文とみなして処理します(セミコロンの後ろの空白及び制御文字は無視されます)。セミコロンがない場合は,その行は次の行に継続しているものとして扱われます。
(引用元:継続行の扱い)
◆言葉
| 意味 | |
|---|---|
| アップロード | ファイルをサーバー等に置いてくること。PCとサーバーのファイルのやり取り。 |
| インポート | アプリケーション内にデータを取り込むこと。アプリケーション間のデータの移行に使う。 |
| インサート | 「データをデータベースにインサート」のように使う。SQLのinsert文使うときとか。 |
| ロード | 読み込むこと。何をどこに読み込むかはケース・バイ・ケース。 |
| (参考:アップロード・インポート、ロード) |
参考
・「PostgreSQLの基本的なコマンド」@H-A-L さんQiita記事
次やる事
・DBeaverからUbuntu(WSL2)への接続
(pg_hbaの設定が効いていない可能性を疑ってみる。設定前に戻して、エラー文言が変わらなければ設定が間違ってたり、効いていない可能性を疑う。)
・「KEN_ALL.CSV」のデータをDBeaverで参照