はじめに
『オープンソースデータベース標準教科書 -PostgreSQL-(Ver.2.0.0)Kindle版』を進めています。
同じくこの教科書で学習する人に向けて、また、自分の忘備録として学習記録を残します。
今回は下記を進めました。
・2.データ型 →6/3済
--2.1 数値データ型(integer型,numeric型,その他)
--2.2 文字列データ型(character vaying型(varchar型),character型(char型),text型)
--2.3 日付・時刻データ型
・3.表 →6/4済
--3.1表の作成(CREATE TABLE)
--3.2表定義の修正(ALTER TABLE)
--3.3表の削除(DROP TABLE,DELETE,TRUNCATE)
--3.4行データのセーブ・ロード
・4.演習
--4.1演習1:データ操作 →6/5済
--4.2演習2:郵便番号データベース →作業中
つまずいたこと
・csvファイルをデータベースに取り込む方法がわからない!(4.2演習2:郵便番号データベース)
→ 解決方法 = 今回は解決できず。
環境
ホストPC:Windows10
GUI DBツール:DBeaver
仮想化ソフト:VirtualBox
ゲストPC:Vagrant(=CentOS7=仮想マシン)
コンテナ型仮想環境:Docker
CUI DBクライアント:PostgreSQL
3章-4 行データのセーブ・ロード がわからない
この項、何度か読んでみても頭の中がこんがらがるばかりで、
何を言っているのかすぐに理解することができませんでした。
とりあえず把握できたのは次のことがら。
・セーブとは?
→保存すること。
・ロードとは?
→読み込むこと。
・COPY文を使用すると、行データをファイルにセーブしたり、ファイルからロードすることができる。
・FORMAT句でcsvを指定することで、CSV形式のファイルをセーブ、ロードができる。
←COPY文は「行データをファイルからロードできる」とあった。こちらのFORMAT句は「csv形式のファイルをロードできる」とある。
←4.2の演習では日本郵政のサイトから郵便番号CSVデータをPCのHDDにダウンロードして、そのCSVデータをPostgreSQL(DBeaverで操作中)に「ロード」するという流れだよね。つまり、このFORMAT句を使ってロードするのかな?と予想。
←いやいや、「3.4.2 CSVファイルのロード」の項で「COPY FROM文でファイルから行データをロードできます」「以下の例は、customer表のデータをCSV形式のファイルからロードしています(COPY FROM文の提示)」とある。COPY文でもCSVファイルをロード可能みたい。
COPY文とFORMAT句の違いって何??
そもそも行データって何???
・COPY文とFORMAT句の違いは?
→COPY文の中でFORMAT句を使うってことかな?COPY文の中でFORMAT句を使ってcsvを指定することで、CSV形式のファイルをロードできるよってことかな。
・行データとは?
→回答を見つけられず。普通に行のデータ?標準教科書の上記のような説明ではどういう意味で使われているんだろう?CSVデータと同義で使われているのだ、と予想。
・CSVとは?
--Comma Separated Valueの略で、Comma(カンマ)で Separated (区切った)Value(値)。「カンマで値を区切ったもの」が入っているファイルで、カンマ区切りファイルともいう。
--ファイルの拡張子は .csv。
--文字や記号で構成されているテキストファイルであり、そのままクリックしてメモ帳で開くことができる。
--互換性が高い。
・COPYはDBサーバー上のファイルに直接データを書き出す操作で、PostgreSQLのスーパーユーザーでのみ実行することができる。
←DBeaverで操作している今の状態は、「スーパーユーザーで実行してる状態」なのだろうか?
※OSS-DB公式ページにも解説があったのでここにメモしておく。
[ 第7回 テキストファイル(CSVなど)の入出力 ]
4章-2 の演習で同じ内容の演習があったので、そちらの演習を通して内容を理解していくことにしました。
郵便番号CSVデータを使って演習
標準教科書 [ 4.2演習2:郵便番号データベース ]に従って進めます。
①郵便番号CSVデータをDL
日本郵政のHPから郵便番号CSVデータをPCのHDDにダウンロード。
(以下はDBeaverの操作)
②CREATE TABLE zipで表作成
「CREATE TABLE zip(表定義を教科書どおりにズラっと)」を実行してzip表を作成した。
③文字コードを確認
標準教科書には
「ダウンロードできるCSVデータは、日本語部分がシフトJISで作成さ れています。一方、 現在使用しているデータベースは日本語をUTF-8 で格納するようにしているため、文字コードをUTF-8に揃える必要があります。」
とありました。
標準教科書ではコマンドでデータベースを作成していますが、
私はDBeaverを使って作成しています。
私のデータベースの文字コードは何なのか?を、まず確認してみます。
→こちらのページのSQL
--PostgreSQLのDBの文字コードを確認
SELECT character_set_name FROM information_schema.character_sets;
をDBeaverで実行したら、「UTF8」と返ってきました!
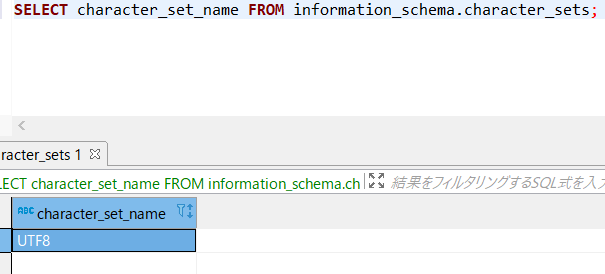
標準教科書と同じ状況ということですね。
では、CSVデータの文字コードをシフトJISからUTF-8に変更します。
④CSVデータの文字コードをシフトJISからUTF-8に変更
シフトJISのデータをUTF-8に変換するには、psqlで\encodingメタコマンドを使用する方法と、Linuxのコマンドで文字コード変換をする方法があります。
【psqlメタコマンドを使用する方法】
\encodingメタコマンドを使用すると、psqlが扱うデータの文字コードを変更できます。以下の例は、\ encodingメタコマンドでpsqlが扱うデータの文字コードをシフトJISに変更しています。データベースはUTF-8 で格納するので、シフトJISからUTF-8への文字コード変換が行われます。
ossdb =# \encoding SJIS
ossdb =# \copy zip from KEN_ ALL. CSV with csv
ossdb =# \encoding UTF-8
(引用元:宮原徹; 喜田紘一. オープンソースデータベース標準教科書 -PostgreSQL-(Ver.2.0.0) (Kindle の位置No.1359-1367). LPI-Japan. Kindle 版.)
上記3行のコマンドはSQLではないですよね・・・、DBeaverにそのまま入力して実行可能なのでしょうか?
とりあえずやってみます。
→3行について、1行ずつ実行してみました。が、全てエラー。syntax error。
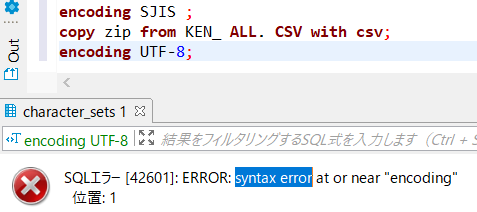
DBeaverではなく、PowerShellでコマンド実行してみます。

「KEN_ALL.CSV: No such file or directory」と出てしまいました。
あれかな、郵便番号のzipファイルがどこにあるかがわかっていないみたい。
今PCにあるCSVファイルのファイル名は小文字だから、コマンド内のファイル名も小文字にしてみる。
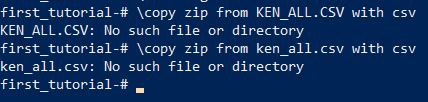
同じエラーが出ました。大文字/小文字の問題じゃないみたい。
次は・・・CSVファイルをfirst_tutorialと同じディレクトリに移動させてみよう!
と思ったのですが、DBeaverが入っているディレクトリは
「C:\ProgramData\Microsoft\Windows\Start Menu\Programs\DBeaver Community」
で、その中のディレクトリに進むことは、PCのコントロールパネル(?)ではできませんでした。
ならば、GUIであるDBeaver上で「データインポート」みたいなボタンがあるのではないか?と予想し、
探してみました。
すると、それらしきものが見つかりました!
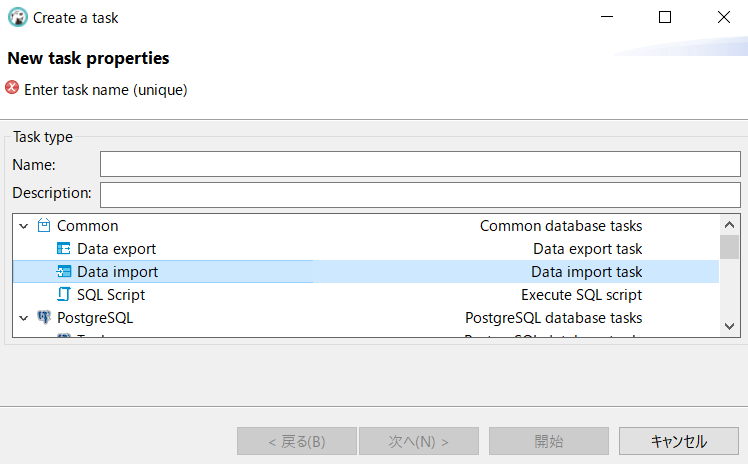
赤枠を適当に入力して「次へ」
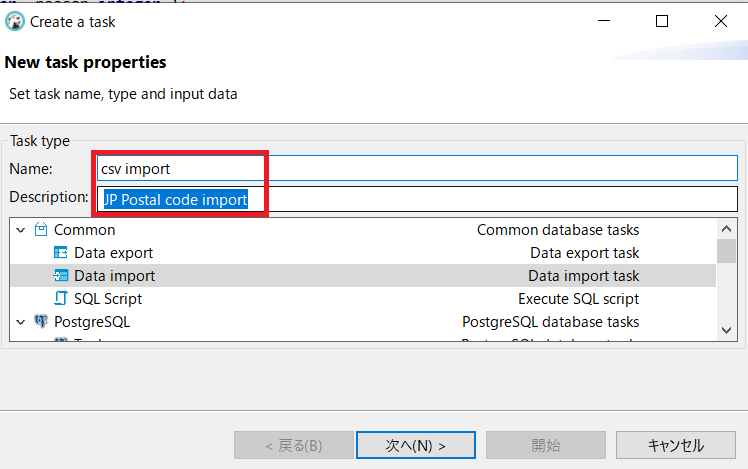
「Add Table」→「zip」を選択→「OK」→「次へ」
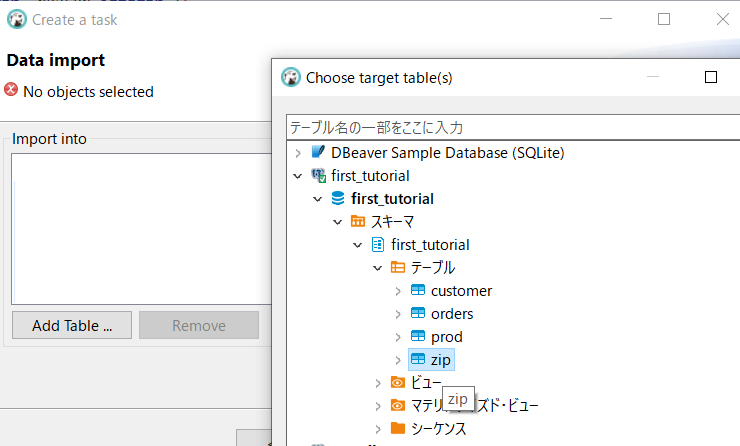
↓あれ?なんだか思っていたのと違う結果になってしまいました。予想では、ここで「インポートするファイルの選択」みたいな画面になって、PCのHDDから「ken_all.csv」ファイルを選択することができる、と思っていたのだけれど、そうはなりませんでした。「キャンセル」をクリックして取りやめました。
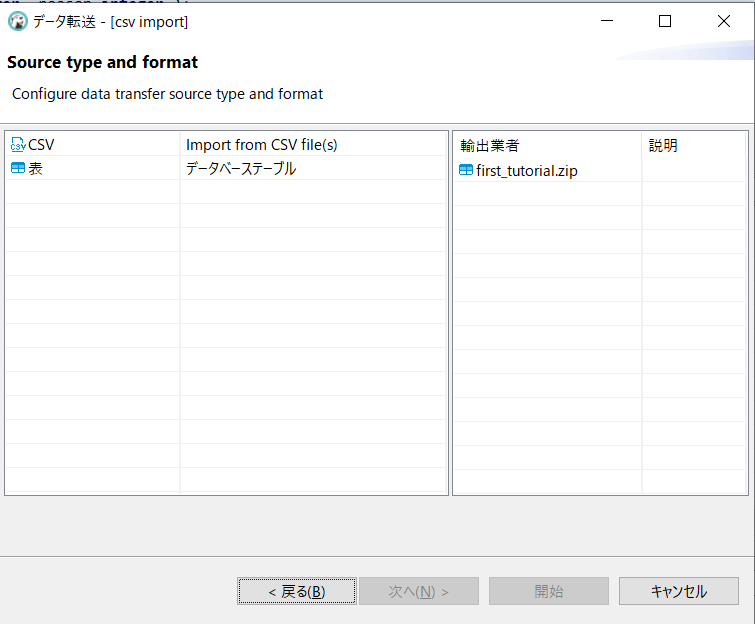
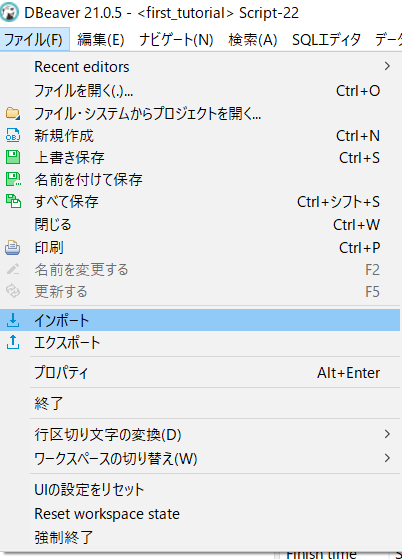
他に何かそれらしいボタンは無いかと探すと・・・
ありました!「ファイル」の中に「インポート」とあります。
「一般」→「ファイル・システム」→「次へ」
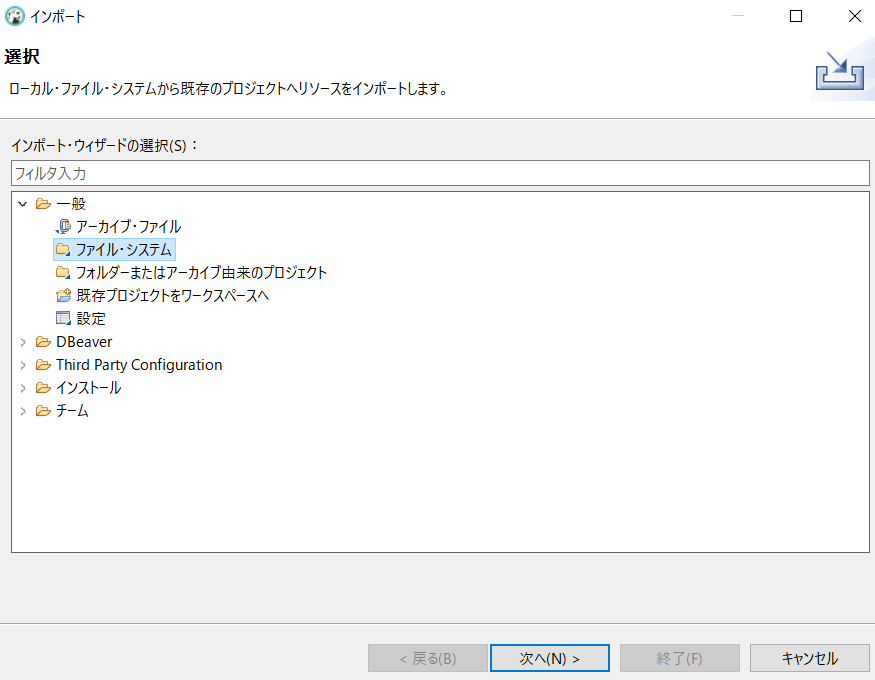
「参照」→csvファイルがあるディレクトリへ行く
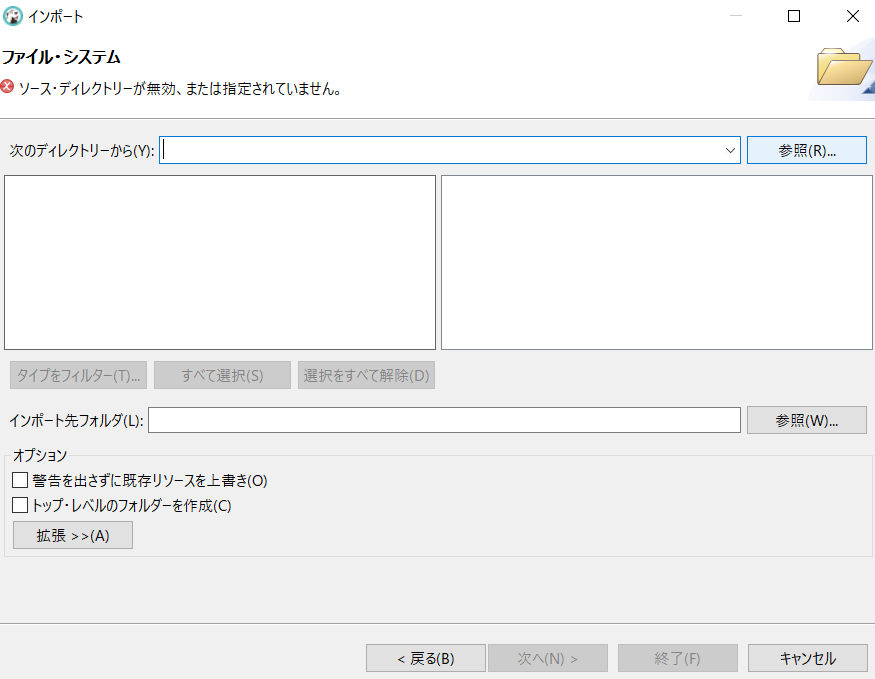
ここでcsvファイルがあるディレクトリへ行ったのですが、空の状態でした。
zip形式なのがダメなのかな?とファイルを展開すると、無事参照の中に表示されました。
選択して、次にインポート先のフォルダの欄で「参照」をクリックします。
選択できるフォルダは「Scripts」一択だったので、よくわかりませんがとにかくこれを選択し、「OK」。
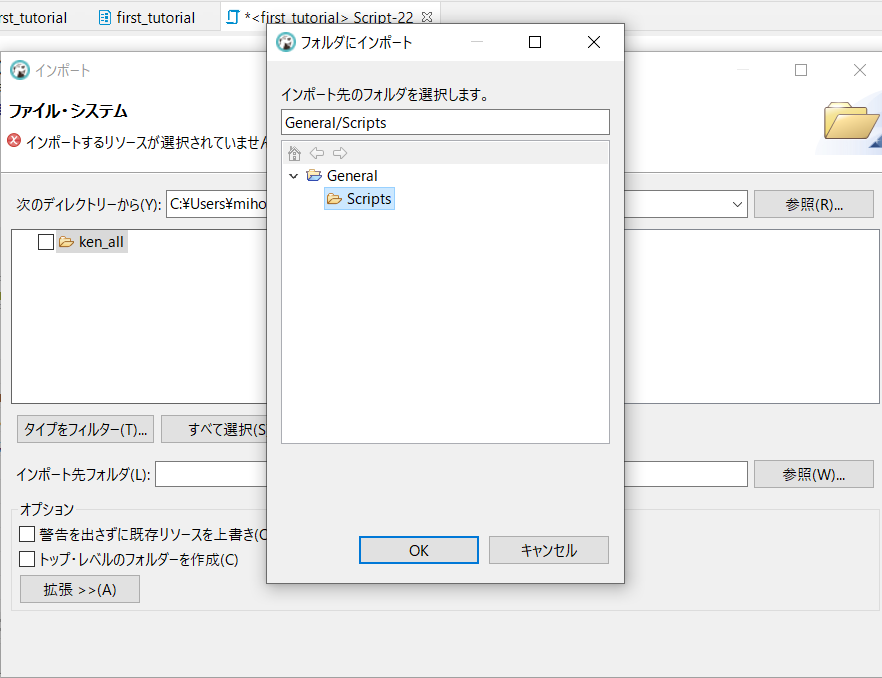
インポートするファイルのチェックボックスをクリックし、「終了」。
さあ、これでインポートできたのでしょうか?
改めて、PowerShellで
# \encoding SJIS
# \copy zip from KEN_ ALL. CSV with csv
# \encoding UTF-8
を実行してみます。

以前と同じく2行目の時点でエラーになってしまいました。
「インポート先のフォルダ」の指定がまずかったのではないか、と思うのですが、
参照先の候補には、今回選択した「General/Scripts」フォルダのみが表示されていました。
本来はここに「first_tutorial」が候補として表示されるかと思っていたのですが、表示されませんでした。
どうすればcsvファイルを取り込めるのでしょうか?
何につまずいているのか整理
一度、自分が何につまずいているのか整理してみます。
今取り組んでいるのは、『OSS-DB標準教科書』の「4.2演習2:郵便番号データベース」。
この演習の中で、
1)日本郵便のHPから郵便番号のcsvファイルをDLして、
2)その文字コードをシフトJISからUTF-8に変換して
3)データベースに取り込む
という作業がある。
文字コードの変換と、データベースへのCSVデータ取り込みができずに苦戦しています。
教科書には
# \encoding SJIS
# \copy zip from KEN_ ALL. CSV with csv
# \encoding UTF-8
を実行せよ、書いてありました。
が、「# \copy zip from KEN_ ALL. CSV with csv」がうまくいきません。
DBeaver上で「ファイルインポート」のような機能が無いか探し、
この記事に書いてきたような試行錯誤をしましたが、解決方法がわからなく、つまずいています。
①Qiitaの最後に試した「ファイル>インポート」の機能を使って、PCのHDDにあるcsvファイルをDBeaverに読み込ませることは、可能なのでしょうか?
②「インポート先のフォルダを選択します」で「General>Scripts」を指定したのですが(これしか選択肢として表示されなかった)、この指定を「first_turorial>zip」にすれば読込みができると思うのですが、この考えは合っているのでしょうか?
③「first_turorial>zip」を選択肢として表示させる方法があるのでしょうか?
④そもそも、ここで立ち止まらずに、読込みは現時点ではできない状態で置いておいて、次の項に進むべきでしょうか?それとも、やはりここでしっかりできるようになるべきでしょうか?
アドバイスを受ける
黒澤さんからのアドバイスをいただきました。
◆まずこのプロセスは、「郵便番号データをDBに取り込んで、
以降そのデータ(テーブル、レコード)を使ってSQLをより深く学習する」ことなので、
無理にインポート機能を使う必要は無いと考える
(インポート機能についての公式ドキュメント=「Importing data from CSV format」)
◆カラム名と属性を確認しテーブルを作成し、insert文で追加してあげれば良いのでは?
なお文字コードがずれてても文字化けがするだけでinsertはできる
◆なので、悩む場合以下の順番で
①テーブル作成
②レコード挿入
③文字化け
④文字コード設定
◆テーブル作成できたら、直接CSVファイルからinsert文を生成しちゃった方が早い。それを一気にデビバからコピペすれば一発なので。
↓
これらをふまえて再チャレンジします。
試行錯誤:「テーブル作成 → csvファイルからinsert文生成 → DBeaverに貼付け」
1)以下のCREATE文でテーブル作成
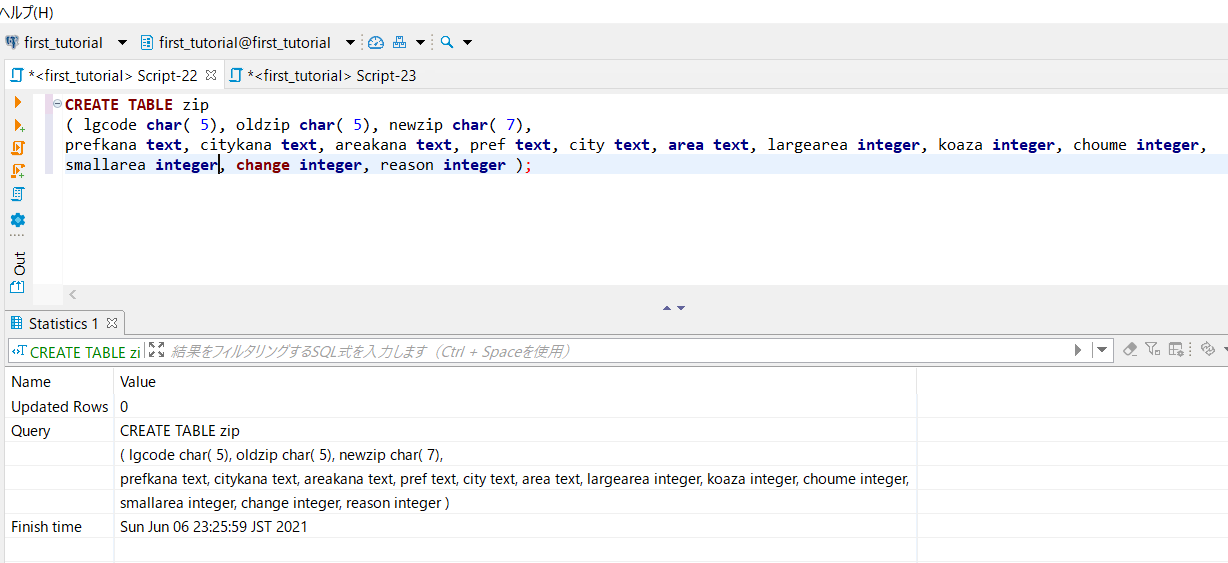
CREATE TABLE zip
(lgcode char(5), oldzip char(5), newzip char(7),
prefkana text, citykana text, areakana text, pref text,
city text, area text, largearea integer, koaza integer,
choume integer, smallarea integer, change integer, reason integer);
↑の意味:
zipという名前のテーブルを作るよ。
テーブルの列は以下の通り。
文字列データをchar型およびtext型で定義するよ。
| 内容 | 備考 |
|---|---|
| 全国 地方公共団体 コード( JIS X0401、X0402) | 半角数字 |
| (旧) 郵便番号( 5 桁) | 半角数字 |
| 郵便番号( 7 桁) | 半角数字 |
| 都道府県名 | 半角カタカナ(コード順に掲載) |
| 市区町村名 | 半角カタカナ(コード順に掲載) |
| 町域名 | 半角カタカナ( 五十音順に掲載) |
| 都道府県名 | 漢字( コード順に掲載) |
| 市区町村名 | 漢字( コード順に掲載) |
| 町域名 | 漢字(五十音順に掲載) |
| 一町域が二以上の郵便番号で表される場の表示 | - |
| 小字毎番地が起番 れている町域の表示 | - |
char型とtext型についての説明
char(n)=空白で埋められた固定長の文字型
text=制限なし可変長の文字型
PostgreSQLは、いかなる長さの文字列でも格納できるtextをサポートします。 text型は標準SQLにはありませんが、多くの他のSQLデータベース管理システムも同様にサポートしています。
(引用元:PostgreSQL 9.3.2文書 第8章データ型 8.3.文字型)
2)CSVファイルからinsert文を生成
※郵便番号のcsvデータをDLした際の注意事項欄に書かれていた
4.全国一括のデータは12万件あるため、一般的な表計算ソフト等では全データを読み込むことができない場合があります。
5.一般的な表計算ソフト等では、郵便番号を示す列や町域を示す列において、上1けたあるいは2けたの「0」「00」が表示されない場合や、年月日で表示される場合がありますので、ご注意ください。
(引用元:郵便番号データの説明―郵便局HP)
という記載が気になっていたのですが、私のPCでデータ解凍して確認したところ
4. → 問題無し。ラスト124,523件目読み込めていたので。
5. → 問題あり。青森県の郵便番号を確認したら、最初の「0」が表示されていませんでした。なので他の項目についてもこの注意事項の通りだと思われます。 → しかし、今回は「値をINSERTする」ことを目的にしており、正しい郵便番号でなくてもその目的は達成されるので、今回はこのままこの問題点は無視して進めることにします。
↓
まずは1行だけinsert文を作ってみます。
青線部分を""で囲い文字列扱いにして、&でセル参照部分を結合して作成しました。
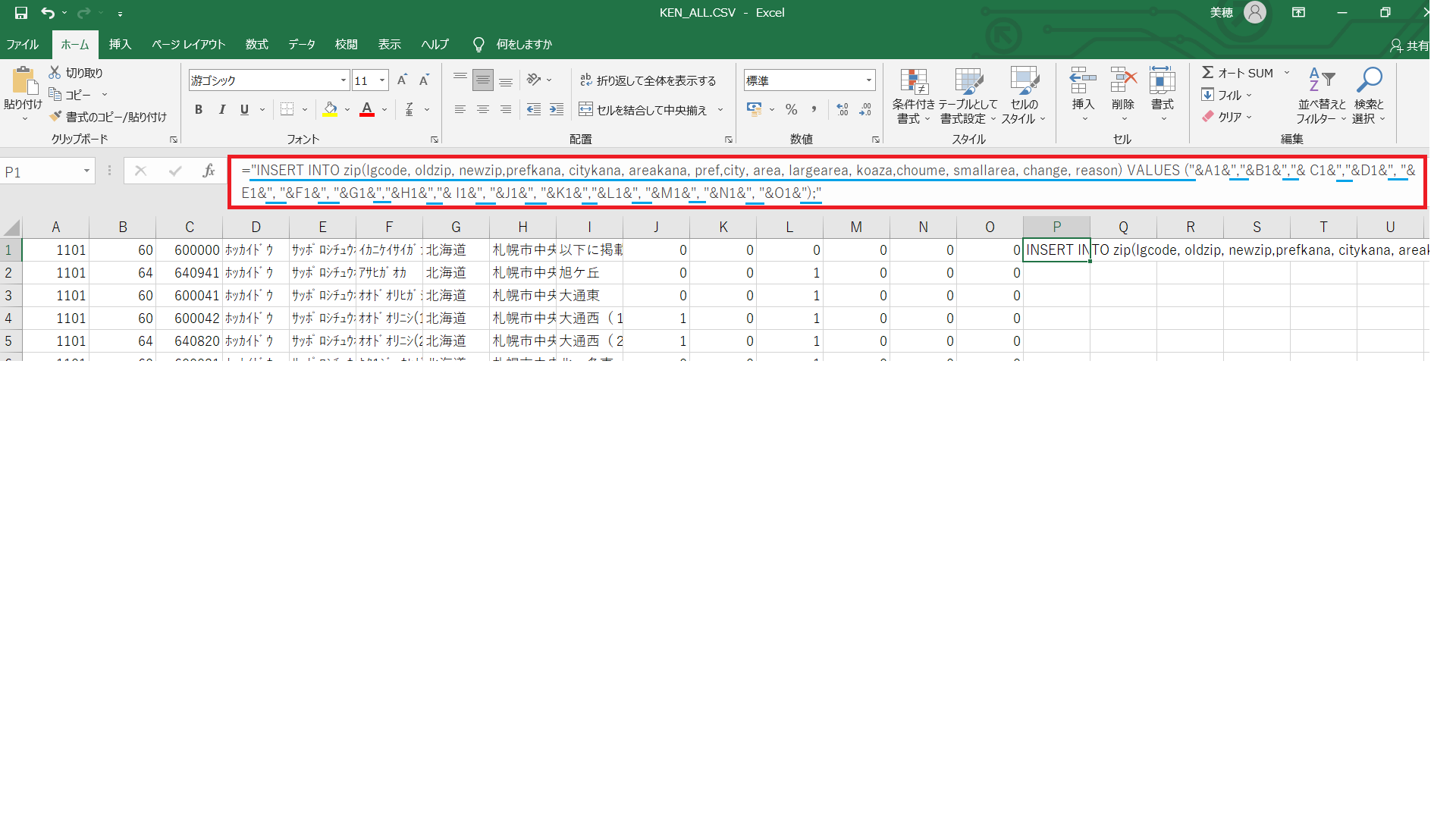
="INSERT INTO zip(lgcode, oldzip, newzip,prefkana, citykana, areakana, pref,city, area, largearea, koaza,choume, smallarea, change, reason) VALUES ("&A1&","&B1&","& C1&","&D1&", "&E1&", "&F1&", "&G1&","&H1&","& I1&", "&J1&", "&K1&","&L1&", "&M1&", "&N1&", "&O1&");"
↓
このようにきちんと反映されました。

↓
P1の右下をダブルクリックして、最終行まで同じ文をコピー。
↓
そのまま同じ位置で値貼付け。
3)この値をそのままDBeaverにコピー&ペースト!
・・・をしたら、水色くるくるマークが出て、フリーズしてしまいました。
20分待っても状況は変わらず。(応答なし)と表示されています。
行数も多いし、こうなる可能性もあるとは思っていましたが、えいやとコピペしてしまいました・・・。
↓
DBeaverの右上「×」をクリックし、DBeaverを終了。
4)DBeaverを再起動
5)INSERT文を1行だけ実行
まずは1行だけ試しに実行してみます。
エクセルから1行目の値をDBeaverのSQLエディタにコピペ。
↓
今回はすぐにペーストされました!
全行一度にペーストするのは、やはり情報量が多すぎたようです。
↓
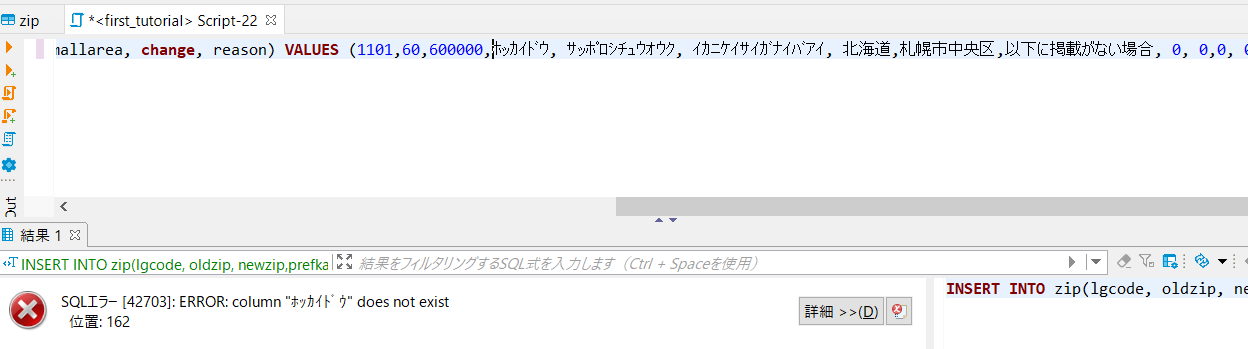
「Ctrl + Enter」で実行!
↓
エラー!
「SQLエラー [42703]: ERROR: column "ホッカイドウ" does not exist 位置: 162」とあります。
↓
エラー原因予想:
文字列だから「'」で囲う必要があるのではないか?
↓
「ホッカイドウ」→「'ホッカイドウ'」に変更して、実行!

↓
「ホッカイドウ」の部分のエラーが消えました!やはり「'」で囲えば良いみたいです。
他の文字列も「'」で囲って、実行!
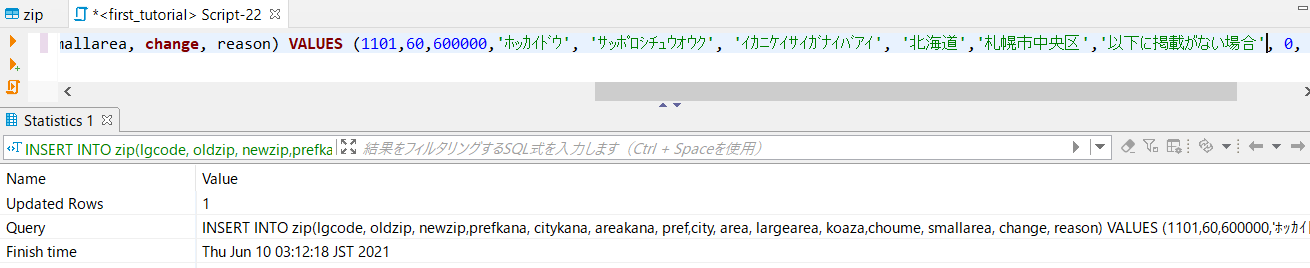
成功です!
6)エクセルのINSERT文を全て「'」付きに書き換える
該当部分の「,」の前後に「'」を加えました。(赤線部分)

7)6)で生成したINSERT文1行をDBeaverにコピペして実行
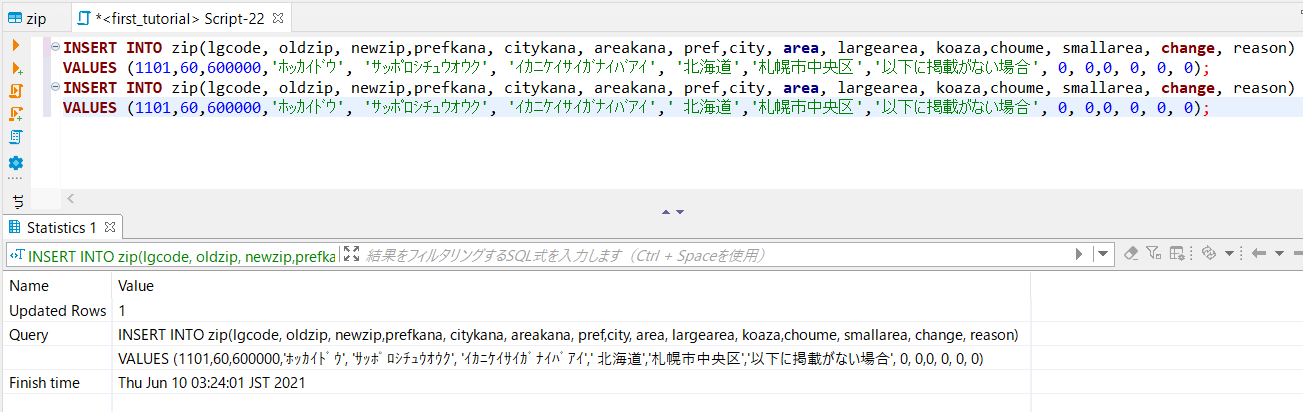
成功です!
8)エクセルのINSERT文を最終行までコピーし、表示形式を計算式から値に変更。
9)生成したINSERT文全行をDBeaverのSQLエディタにコピペしたい。
単純に全行選択→コピペ をすると、3)のときのようにDBeaverがフリーズしてしまいます。
どうやってペーストすれば良いのでしょう?
黒澤さんからのアドバイスには、「一気にデビバからコピペすれば一発」とありました。
「デビバからコピペ」ということは、
「DBeaverに、大量のINSERT文を外部から読み込む機能がある」ということでしょうか。
調べてみます。
10)試行錯誤①:COPYコマンドを試す
「1000万件のINSERTを映画1本分ぐらい時間節約できた話」-DATUM STUDIO-2017.10.26記事
こちらの「5 COPY コマンド (PostgreSQL特有)」という方法が気になったので、試してみます。
※コマンドなので、DBeaverのSQLエディタで使えるものなのか不明なので、
「SQL COPY table from with csv」等でググったのですが、
これだ!という記事が見当たらなかったので、とにかく実行してみます。
記事に出ていたコマンドはこちら。
COPY table FROM 'sample.csv' WITH CSV
↓
INSERT文(値ver)のみを羅列したエクセルCSVファイルを作る。
(ファイル名=insert文値.CSV)
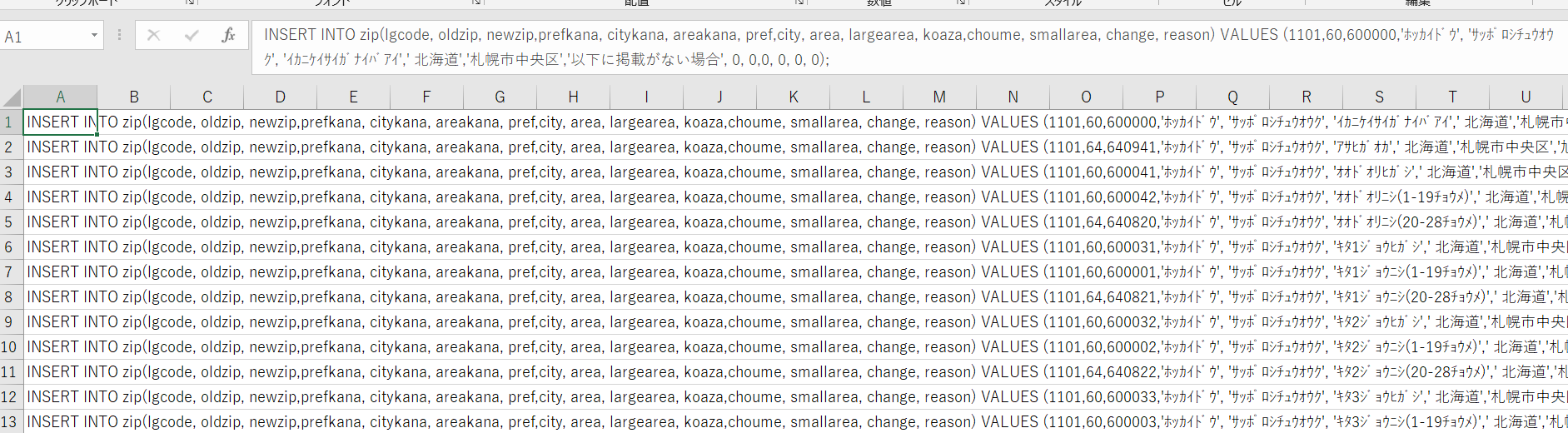
↓
DBeaverで下記コマンドを実行しようとして、やはり実行するのをやめました。
COPY table FROM 'insert文値.CSV' WITH CSV
これをやっては、
「④CSVデータの文字コードをシフトJISからUTF-8に変更」でやったことの繰り返しになってしまいます。
その1)生成した12万個のINSERT文をコピペする他の方法を探す
その2)(INSERT文のコピペは諦めて)WinSCPでcsvファイルをアップロードする
の2つの方法を、引き続き試していこうと思います。
INSERT文の値を羅列したCSVファイルをDBeaverへインポート
1)まず、INSERT文124,523件を下のようなCSVファイルにしました。
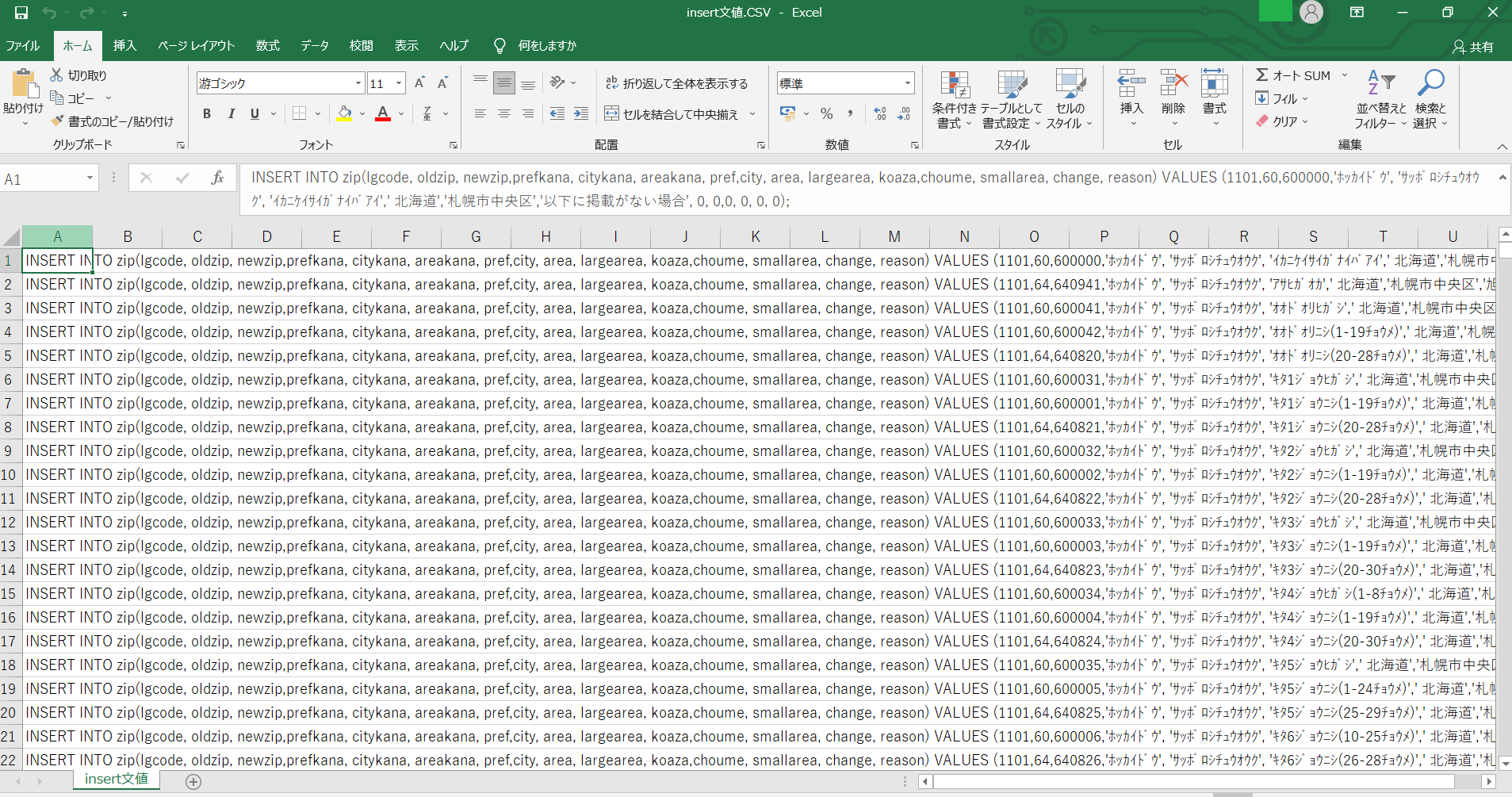
2)DBeaverで「zip>データのインポート」
3)「CSV」を選択
↓
「次へ」をクリック
↓
該当csvファイルを選択
↓
「次へ」
↓
(デフォルトのまま)「次へ」
↓
設定の画面になりました。↓はデフォルトの状態。それぞれの項目の意味を確認します。
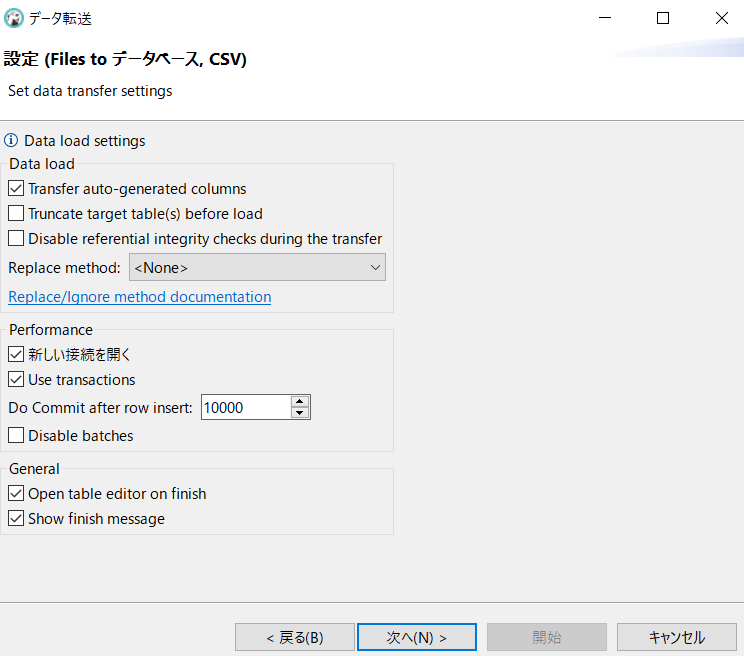
【Data load】
・Transfer auto-generated columns(自動生成カラムの転送)
・Truncate target table(s) before load(ロードする前にターゲットテーブルを切り捨てる)
・Disable referential integrity checks during the transfer(転送中の参照整合性チェックを無効にする)
*Replace method:(置換方法:<なし/競合あり 何もしない/競合あり 更新セット>)
*Replace/Ignore method documentation(置き換える/メソッドのドキュメントを無視する)
【Performance】
・Use transcations(トランザクションを使用する)
*Do commit after row insert(行挿入後にコミットする)←数字を選ぶようになってる・・・INSERT文の件数を入力すれば良いのかな?
・Disable batches(バッチを無効にする)
【General】
・Open table editor on finish(終了時にテーブルエディタを開く)
・Show finish message(終了メッセージを表示)
↓
「*Do commit after row insert」のみ「10000→125000(124,523から少し余裕を見た数)」に変更して、
「次へ」
↓
「開始」
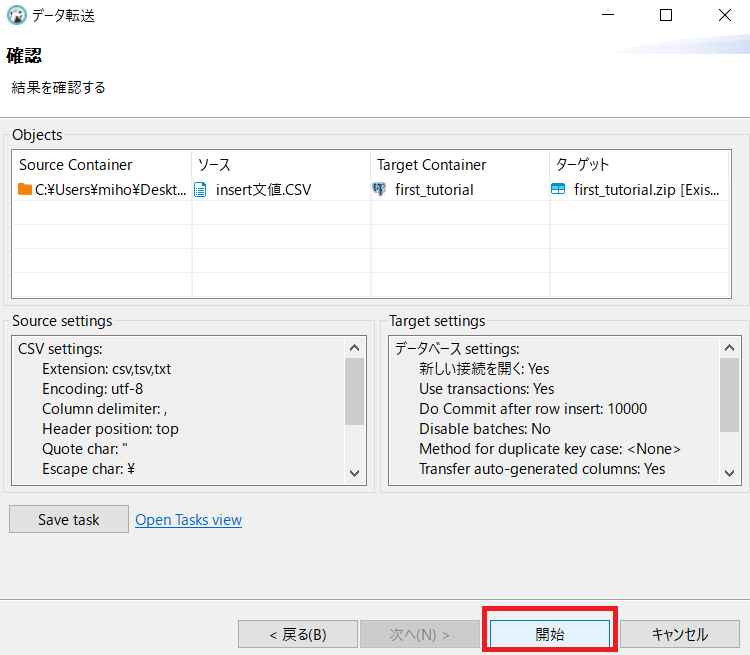
↓
エラー!
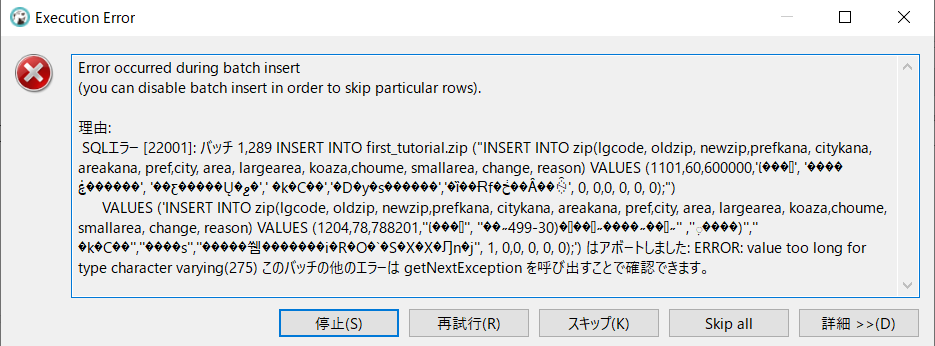
エラー文は下記の通り。
Error occurred during batch insert
(you can disable batch insert in order to skip particular rows).
理由:
SQLエラー [22001]: バッチ 1,289 INSERT INTO first_tutorial.zip ("INSERT INTO zip(lgcode, oldzip, newzip,prefkana, citykana, areakana, pref,city, area, largearea, koaza,choume, smallarea, change, reason) VALUES (1101,60,600000,'ί���', '����ۼ������', '��ƹ�����Ų�ޱ�',' �k�C��','�D�y�s������','�ȉ��Ɍf�ڂ��Ȃ��ꍇ', 0, 0,0, 0, 0, 0);")
VALUES ('INSERT INTO zip(lgcode, oldzip, newzip,prefkana, citykana, areakana, pref,city, area, largearea, koaza,choume, smallarea, change, reason) VALUES (1204,78,788201,''ί���'', ''��˶ܼ'', ''˶��˶����˶���(30-499����)'','' �k�C��'',''����s'',''�����쒬�������i�R�O�`�S�X�X�Ԓn�j'', 1, 0,0, 0, 0, 0);') はアボートしました: ERROR: value too long for type character varying(275) このバッチの他のエラーは getNextException を呼び出すことで確認できます。
↓
とりあえず「スキップ」をクリック。エラー内容を確認します。
・SQLエラー [22001]とは?
→文字列データの右側の切り詰め(引用元:PostgreSQLエラーコード(PostgreSQL 8.0.4 文書))
・アボートとは?
→「中止」「強制終了」
・value too long for type character varying(275)の意味
→VALUEで指定してる値の文字数が多すぎ!275文字の制限超えちゃってる!
・getNextExceptionを呼び出す とは?
→「getNextException」っていうソフトかプログラムか何かがあるのか?と思ってググったけど、それらしきものは見当たらず。excepthionは「例外」の意。「このバッチの他のエラーは"次の例外をgetする"を呼び出すことで確認できます」・・・。とにかく表示されてる「文字数多すぎ!」のエラーを解決して、そしてまたcsv読み込んでみたらまたエラー出るよ、ということかな。
とにかくまずは、「文字数長すぎ」問題を解決します。
文字数長すぎ問題を解決
「character varying(275)」は「上限付き可変長」の文字型。275文字が上限。(SQL_ASCIIの時はバイト単位(全角文字は2バイト、半角文字は1バイト))
(参考:PostgreSQL 文字列メモ)
PostgreSQLの文字コードは「③文字コードを確認」で調べた通り、「UTF-8」。
読み込んでいるエクセルcsvファイルの文字コードは「ANSI」
(文字コード確認方法:csvファイルを右クリック→プログラムから開く→メモ帳→名前をつけて保存→文字コードの欄を確認した)。
見た目の文字数の2倍の文字数になってるってことかな?だから文字数オーバーの扱いになってしまった?
↓
csvの文字コードを ANSI → UTF-8 に変えます。
方法:【csvファイルの文字コードを変更する方法】-NJSS
↓
解決!
↓
あらためてcsvファイルをDBeaverに読み込みます。
「INSERT文の値を羅列したCSVファイルをDBeaverへインポート」の方法をもう一度やる)
↓
エラー!内容は下記。
Error occurred during batch insert
(you can disable batch insert in order to skip particular rows).
理由:
SQLエラー [22001]: バッチ 2,058 INSERT INTO first_tutorial.zip ("INSERT INTO zip(lgcode, oldzip, newzip,prefkana, citykana, areakana, pref,city, area, largearea, koaza,choume, smallarea, change, reason) VALUES (1101,60,600000,'ホッカイドウ', 'サッポロシチュウオウク', 'イカニケイサイガナイバアイ',' 北海道','札幌市中央区','以下に掲載がない場合', 0, 0,0, 0, 0, 0);")
VALUES ('INSERT INTO zip(lgcode, oldzip, newzip,prefkana, citykana, areakana, pref,city, area, largearea, koaza,choume, smallarea, change, reason) VALUES (1210,6831,683161,''ホッカイドウ'', ''イワミザワシ'', ''クリサワチョウミヤムラ(248、339、726、780、800、806バンチ)'','' 北海道'',''岩見沢市'',''栗沢町宮村(248、339、726、780、800、806番地)'', 1, 0,0, 0, 0, 0);') はアボートしました: ERROR: value too long for type character varying(275) このバッチの他のエラーは getNextException を呼び出すことで確認できます。
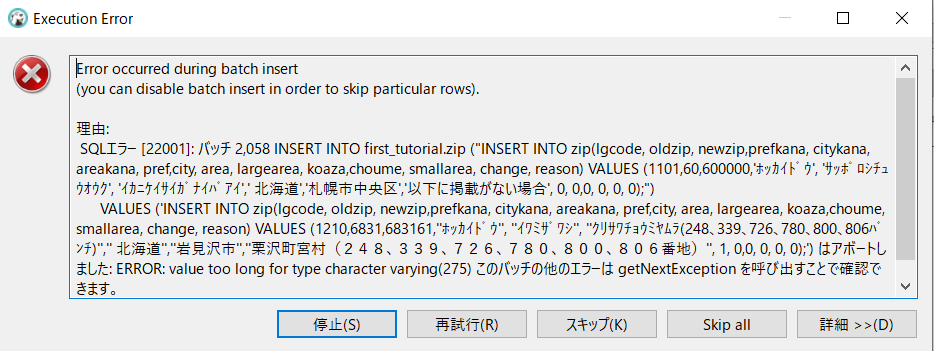
エラーは出ましたが、文字化けは解消されました。文字については解決です!
では、エラー文を見ていきましょう。
・また「 value too long for type character varying(275)」と言っています。
・「 SQLエラー [22001]: バッチ 2,058 」
→前回のエラーと全く同じ内容のエラーです。エラー先(?)が「2,058行目のデータ」という部分だけは異なります。
この「275」という数字はどこから来たのでしょうか?
CREATE文は前述したように
CREATE TABLE zip
(lgcode char(5), oldzip char(5), newzip char(7),
prefkana text, citykana text, areakana text, pref text,
city text, area text, largearea integer, koaza integer,
choume integer, smallarea integer, change integer, reason integer);
です。275文字を上限とした部分はありません。
また、エラー文中の「character varying(n)」は またの表記をvarchar(n)、
意味は「(n)字の上限付き可変長のデータ型」です。
このcharacter vayingのデータ型は、CREATE文の中には登場していません。
上記CREATE文中で指定しているデータ型は「char(n), text, integer」の3種類です。
それぞれの意味は
char(n) :空白でパッドされた固定長のデータ型。またの表記をcharacter(n)。
text :制限無し可変長のデータ型。
integer :4バイト符号付き整数のデータ型。
なぜ、CREATE文に登場しない「character varying(275)」が、
エラー文で指摘されているのでしょうか??
INSERT文で私は「character varying(275)」という指定をしていないつもりだけれど、
何らかのタイミングで気づかない内に「character varying(275)」を指定してしまったってこと??
DBeaverでzipテーブルのプロパティを確認してみると・・・
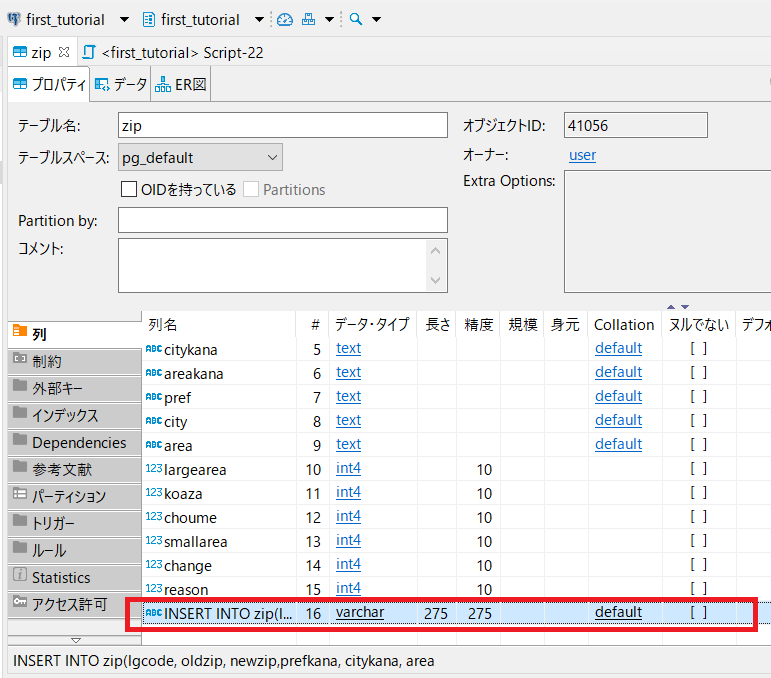
「データタイプ:varchar 長さ:275」ってガッツリ書いてあるーーーー!!!!
これ、消したい・・・。ここを選択したまま右クリック→「削除」って選択肢が出てきたけど
「削除」してOKなのか??
試してみる。「削除」!
「はい」
↓
消えた。
あらためてcsvファイルをDBeaverに読み込みます。
「INSERT文の値を羅列したCSVファイルをDBeaverへインポート」の方法をもう一度やる)
↓
エラー!またもや同じエラーが出ました。
エラー文:
SQLエラー [22001]: バッチ 2,058 INSERT INTO first_tutorial.zip(以下略
そしてまたzipテーブルのプロパティを確認したところ、
「列名:INSERT INTO ~、データタイプ:varchar 長さ:275」が復活していました。
もしかして、INSERT文がINSERT文としてではなく、ただの文字列として認識されているのかな??
だとしたら、CSVファイルとしてINSERT文の情報をDBeaver上からPostgreSQLにインポートする方法は、
この方法ではないということ??
うーん・・・。
解決方法がわからないので、INSERT文12万件以上の情報をインポートすることは、一度諦めます。
郵便番号データの文字コードをANSIからUTF-8へ変更し、変更後のcsvファイルをDBeaverを使ってPostgreSQLにインポートする
郵便番号csvデータのファイルを右クリック→プログラムから開く→「メモ帳」を選択→ファイル→名前を付けて保存→文字コードをANSIからUTF-8に変更して保存→DBeaverのDBナビゲーターの中のzipフイルの上で右クリック→「データのインポート」→あとはこれまでと同じく操作して、インポート完了するはず。
→インポート完了した!
「列」の項にずらーっと下画面のように並んだ。
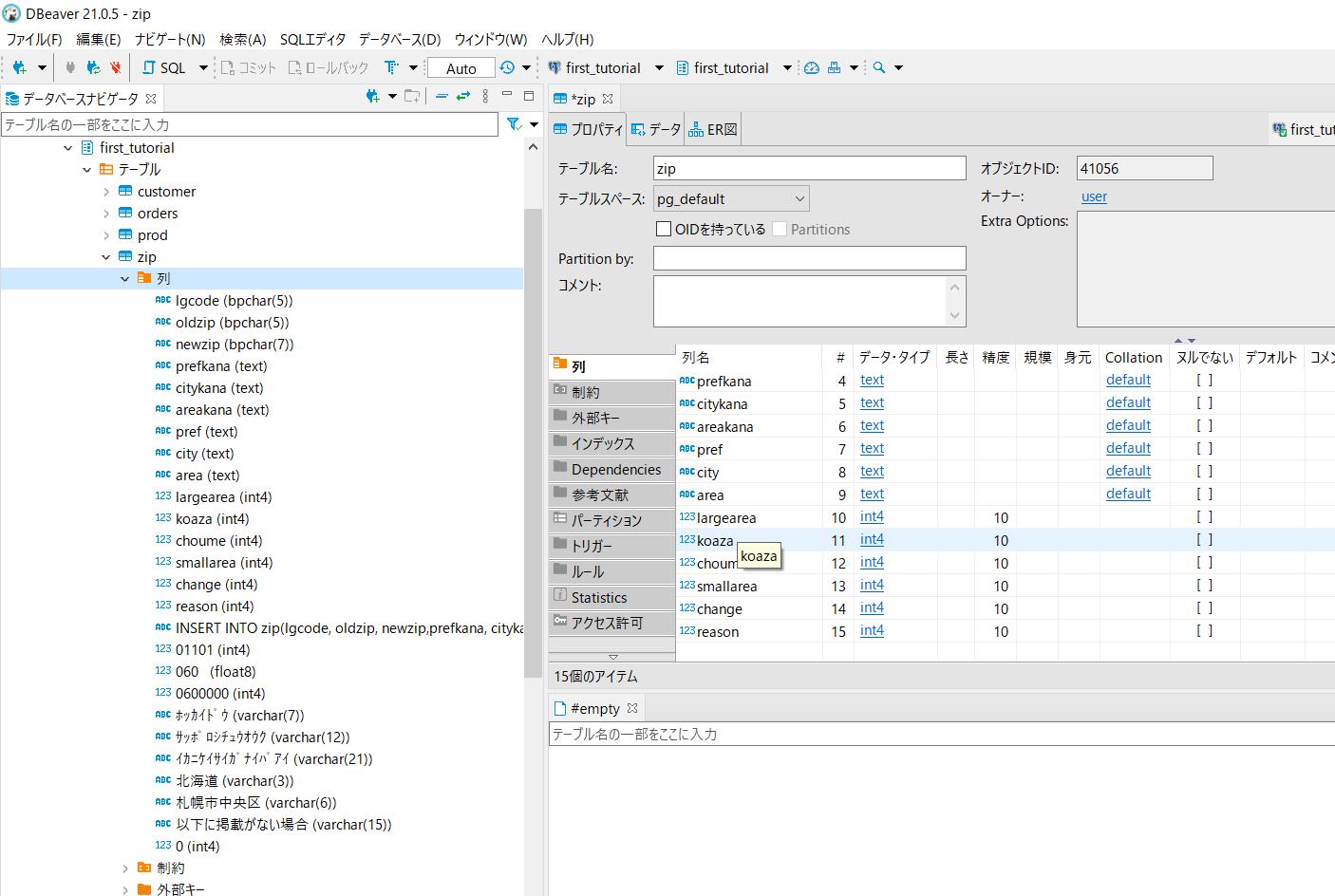
んんーーー??
これで良いのか?
いまいちよくわからない。
とりあえず教科書に記載されていたとおり
「select * from zip where newzip = '1500002';」を実行してみたけれど、
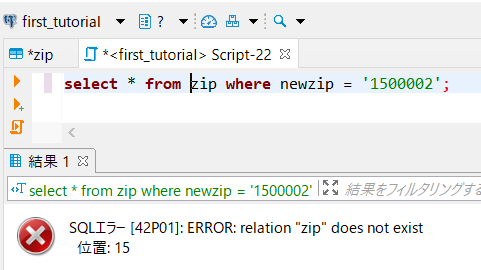
やはり、エラー。そうだよね・・・。
「列」に並んだ項を見てみると、
・CREATE TABLE文で作った列(全15列)と、
・「INSERT INTO zip(lgcode, oldzip, newzip,prefkana, citykana, area(varchar(275))」、
・CSVファイルの情報の1行目の情報の内、15列中1~10列目のみの情報
が、表示されています。
教科書の説明は、
4.2.3.データのロードと文字コードについて
「csvファイルの文字コードをシフトJISからUTF-8に変更」してからすぐ
「psqlから\copyメタコマンドでロード(ossdb =# \copy zip from KEN_ ALL_ UTF 8. CSV with csv)」し、その後すぐに
「4.2.4.郵便番号データの確認。(ossdb =# SELECT * FROM zip WHERE newzip = '1500002';)」
となっていました。
これを読んだ際にもやっと感じたのですが、実際に試行錯誤した今持つのは、
「いつ、csvファイルの列をzipテーブルの列に紐づけたの?」
という疑問です。
csvファイルの先頭行は

というように、レコードとなっています。
zipテーブルと紐づくような列名は記されていません。
この状況で、PostgreSQLはどうやってcsvファイルの情報とzipテーブルの情報を紐づけるのでしょうか?
列数が「15」に揃っているから、その順番通りに自動的に紐づいていくのでしょうか??
現に、今の私のDBeaverの画面では、紐づけができずにcsvファイルの列は新たな列として登録されてしまっています。
そして謎の「INSERT INTO zip(lgcode, oldzip, newzip,prefkana, citykana, area(varchar(275))」という列まで発生している・・・。いつ発生したんだ?
仮定:
「INSERT INTO zip(lgcode, oldzip, newzip,prefkana, citykana, area(varchar(275))」は
csvファイルをインポートしたときに自動生成された。
csvのA列から順番に、lgcode以下の列に振り分けられるようなINSERT INTO文になっている。」
この過程が正だとすると、
なぜこのINSERT文に記されているのは15列全てではなくて1~6列目だけなのだろうか?
という疑問が生まれる。
・・・このINSERT文を15列分に書き換えれば、うまくいくのではないか?同時に「area(varchar(275)」のデータ型の指定を消してしまえば、問題解決なのではないか??
やってみよう。
csvファイルとzipテーブル紐づけのために自動生成された(?)INSERT文が間違っていたので正しく書き換える
1)まず、今あるINSERT文を削除します。
該当のINSERT文を右クリック→「削除」→(オブジェクトの削除:カラム"INSERT INTO zip(lgcode, oldzip, newzip,prefkana, citykana, area"を削除しもよろしいですか?)「はい」
2)新たなINSERT文を記述します。
「SQLエディタ」→「新たなSQLエディタ」→以下を実行
INSERT INTO zip(lgcode, oldzip, newzip, prefkana, citykana, areakana, pref, city, area, largearea, koaza, choume, smallarea, change, reason);
↓
エラー。「SQLエラー[42601]:ERROR:syntax error at end of input」

「syntax error at end of input」と出てはいるけれど、end of inputの部分は問題なさそう。
気になるのは「area」と「change」が色付き文字になっていること。
もしかして、予約語なのでは?
しかし、PostgreSQLの予約語を調べてもこの2つは予約語ではありませんでした。
そもそもドキュメントにも、
PostgreSQL では予約語は完全に予約されたものではなく、列名として使用することが可能です
(引用元:PostgreSQL 7.3.4 ユーザガイド (Appendix B. SQL キーワード))
と記載があったので、たとえ予約語であっても問題は無いということですね。
ではなぜ色付き文字になっているのだ?とまた疑問。
「INSERT INTO syntax error at end of input」等でググってみても、解決方法は見つからず。
どうすれば良いのか!!
この疑問に加えて、
なぜ「CSVファイルの情報の1行目の情報の内、15列中1~10列目のみの情報」のみがDBeaverの列一覧に表示されているのか?11~15列目もここに反映させるためにはどうすれば良いのか?
という疑問も残っています。
アドバイスを受ける
ここで黒澤さんに、私の仮定(自動生成された(?)INSERT文の内容が誤っているから、csvファイルとzipテーブルとの紐づけがうまくいかない)は合っているのか、質問しました。
いただいたアドバイスと私の状況は下記の通り。
・インサートやり直す際は前のデータを消して(truncate)してからやり直してる?
→私:やり直していません。
・紐づきについては、実際は作成したテーブルのカラムの順番にcsvからデータがインポートされるのでcsvにはカラム名や属性情報は無いです。7列目以降のカラムがインポートされてないならテーブル作成が失敗してると仮説を立てるべき
→私:カラム名や属性情報は無く、カラムの順番にインポートされるのね!
・一度テーブル削除した方が良い
→私:たしかに!
・テーブル作成からインポートまでのソースを一度まとめてください
→私:一度テーブル削除し、テーブル作成からやり直す。そのソースをまとめよう。
今あるzipテーブルを削除
DBeaverのDBナビゲータ内のzipテーブル上で右クリック→「削除」
で削除できました。
さあ、あらためてテーブル作成からやり直しです。
記事がごちゃついてきたので、新たな記事を立ち上げて記録します。