ラズベリーパイと音声で最後のLチカができない。ご教示をお願いいたします。
Q&A
Closed
https://qiita.com/mooriii/items/6a16663ce9a80b2e2b92
の記事を見ながら、実行しています。

途中までは、imagou様やhon_no_mushi様のお力を頂き、実行できましたが、最後のLチカが実現でいません。ご知見のある方、対応方法をご教示頂けませんでしょうか。
■実行内容
記事の

の3行を自身の環境に合わせて、
$ sudo modprobe snd-pcm-oss
$ julius -C ~/julius/julius-kit/dictation-kit-v4.4/am-gmm.jconf -nostrip -gram ~/julius/dict/denki -module
$ python /home/pi/prog/juliustest.py
と実行すると、
や
となります。

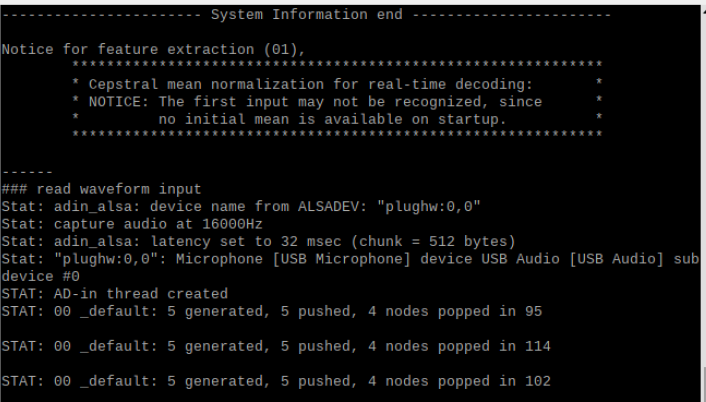
記事では、
となっていて、わたしの実行した表示と違います。(末尾に[/s]が入っている)

■プログラム(juliustest.py)の情報
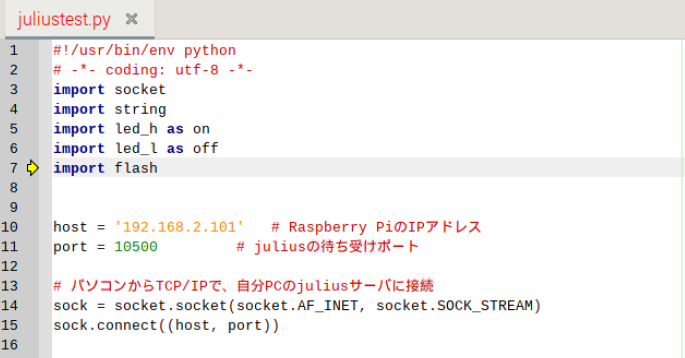
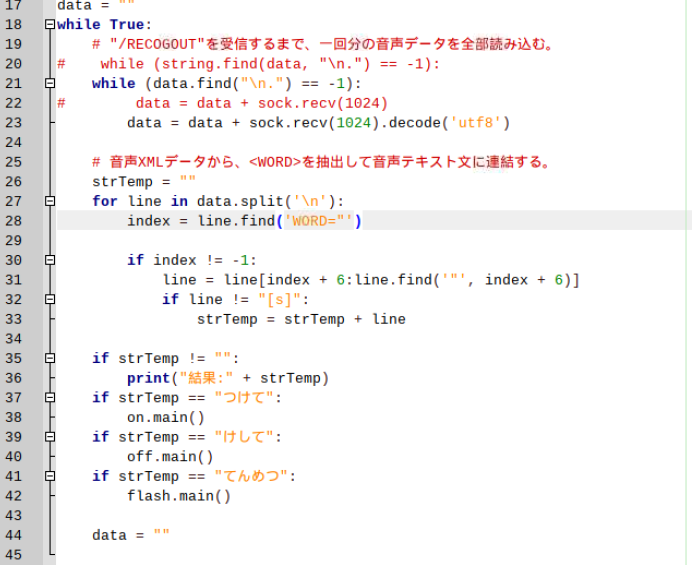
*21行目は、hon_no_mushi様のご教示で変更
*23行目は、https://detail.chiebukuro.yahoo.co.jp/qa/question_detail/q11199585811
のuso8mega様のご教示で変更
■juliustest.pyのテキスト
import socket
import string
import led_h as on
import led_l as off
import flash
host = '192.168.2.101' # Raspberry PiのIPアドレス
port = 10500 # juliusの待ち受けポート
######### パソコンからTCP/IPで、自分PCのjuliusサーバに接続
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.connect((host, port))
data = ""
while True:
########## "/RECOGOUT"を受信するまで、一回分の音声データを全部読み込む。
########## while (string.find(data, "\n.") == -1):
while (data.find("\n.") == -1):
########## data = data + sock.recv(1024)
data = data + sock.recv(1024).decode('utf8')
########## 音声XMLデータから、を抽出して音声テキスト文に連結する。
strTemp = ""
for line in data.split('\n'):
index = line.find('WORD="')
if index != -1:
line = line[index + 6:line.find('"', index + 6)]
if line != "[s]":
strTemp = strTemp + line
if strTemp != "":
print("結果:" + strTemp)
if strTemp == "つけて":
on.main()
if strTemp == "けして":
off.main()
if strTemp == "てんめつ":
flash.main()
data = ""
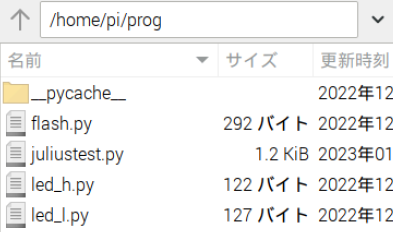
■その他プログラム
以下のように同一フォルダにあります。
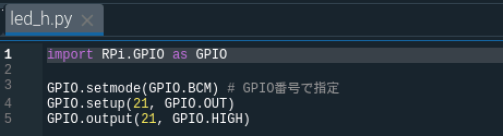
また、例えば、led_h.pyは
であり、led_h.py単独で実行させた場合、GPIO21に接続したLEDは点灯します。
以上です。