TL;DR
- パーティションをノード間でレプリケーションするDRBD9をKubernetesから試す。
- DRBD9の管理ツールであるLINSTOR経由で、PVのプロビジョニング・アタッチ等が可能。
- CSIにも対応しており、今回はlinstor-csiを試してみる。
概要
以下の構成図のように、LINSTORのCONTROLLERを1台(実際はSATELLITEとのCOMBINED)とSATELLITEを2台(兼DBデプロイノード)、計3台からなるKubernetesクラスタを構築します。
[linstor-csi+DRBD9でPostgreSQL on k8s の構成図(完成図)]
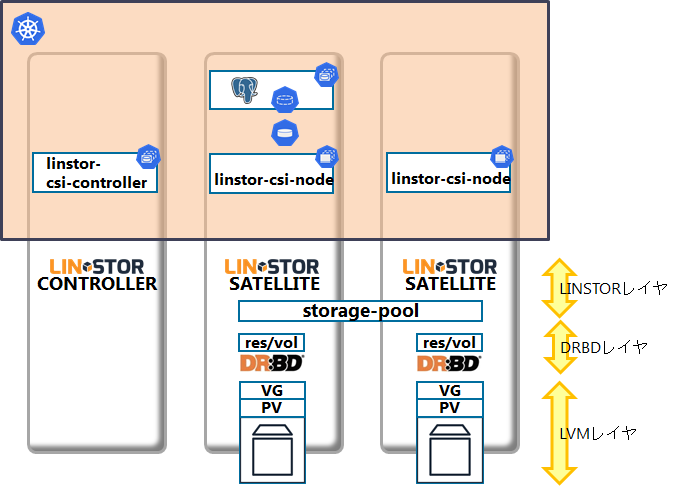
SATELLITEのディスク1本をレプリケーション対象とし、そこにLVMのPV・VGを構築していきます。
PostgreSQLはCSI経由でDRBDのボリュームをマウントします。このボリュームは常に1ノードからのみマウントされるようにLINSTORが制御するため、ポッドの移動時には移動元ノードでのアンマウントと移動先での再マウントが行われます。レプリケーションされているため、ノードを跨いで移動してもデータは同じものを参照可能です。
DRBD9とLINSTORのインストール
サードウェア(現在はサイオステクノロジーと合併しています)が編集したこちらの手順を参考に、CONTROLLERノードとSATELLITEノードを構築します。
しかし、現時点ではこの手順が非常に煩雑です。
- DRBD、LINSTOR関連パッケージのビルド
- DRBDのレプリケーションに必要なLVMの設定
- LINSTORコマンドを用いてノード、ストレージプールの登録
LINBITのリポジトリを参照できるサポート契約を持っている方であれば、yumでの管理が可能ですが、そうでない場合は一つ一つのパッケージをビルドしてインストールする必要があります。
先ほどのイメージ図で表すと、ここまでで以下のような構成になります。
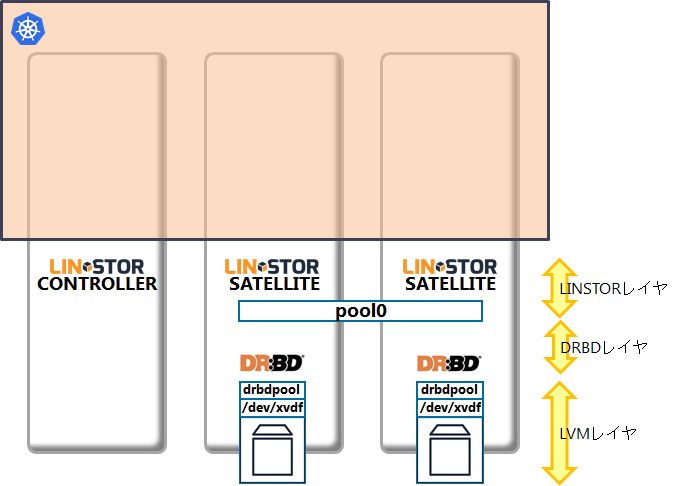
この時点ではDRBDでレプリケーションされるリソース/ボリュームは作成されていません。それらはlinstor-csiでPersistentVolumeが作成される際にプロビジョニングされます。
ここまでの手順は、RookのようにDRBD9+LINSTORのデプロイを行うoperatorが開発されれば簡単となるはずです。LINSTOR関連のコンテナは公式のものが存在するようですので(但しサポート契約が必要)、そちらも追って試してみたいと思います。
linstor-csiをKubernetesにインストール
DRBD9+LINSTORの環境構築が完了しましたので、次はlinstor-csiをKubernetesに構築していきます。こちらもサードウェアのこちらのブログに手順がありますので、手順書内の「3. linstor-csi-controller, linstor-csi-node の配備」から作業を実施していきます。
といっても実行するのはlinstor-csi.yamlのLINSTOR CONTROLLERのIPアドレスを書き換えて、kubectl applyするだけです。
- linstor-csi.yamlの適用
$ kubectl apply -f linstor-csi.yaml
linstor-csi.yamlは以下の内容をデプロイします。
- Daemonsetとして、linstor-csi-nodeをデプロイ
- StatefulSetとして、linstor-csi-controllerをデプロイ
- linstor-csi-controllerは複数のコンテナ(linstor-csi-plugin、csi-provisioner、csi-attacherなど)を持つ。
- linstor-csi-nodeもcsi-node-driver-registrarとlinstor-csi-pluginの2コンテナからなる。
システム構成はここまでで下図のような状態となっています。
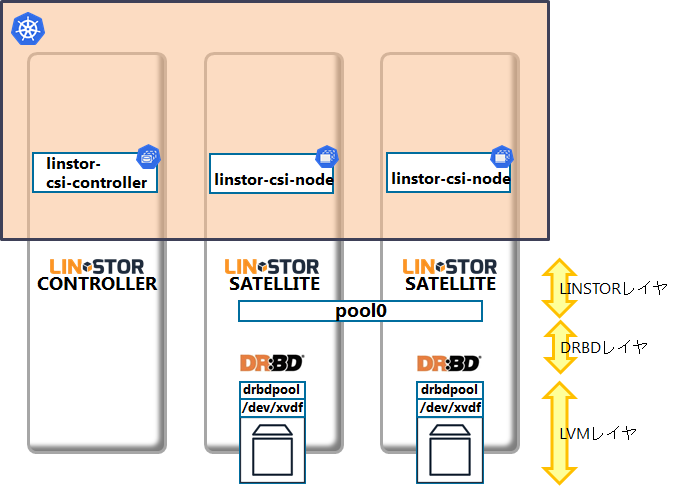
なお、私が構築する際にはlinstor-csi-controllerとlinstor-csi-nodeを稼動させるノードを適切に割り当てるために、YAMLにnodeSelectorを追加しています。
CSIを利用したストレージのマウント
ここまででDRBD9+LINSTOR環境の構築と、それらをKubernetesからCSI経由で利用するためのプラグインの準備ができました。
次にStorageClassとPersistentVolumeClaimを作成して、PostgreSQLのPodからマウントを試します。
5) StorageClassの作成
StorageClassを定義するYAMLファイルは以下のようになります。まずはapplyしてみましょう。
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: sc-linstor-csi-2r
provisioner: io.drbd.linstor-csi
parameters:
autoPlace: "2"
storagePool: "pool0"
filesystem: "xfs"
ここではprovisionerとしてio.drbd.linstor-csiを利用し、そのパラメータとしてレプリカ数(autoPlace)や先ほど作成したstoragePoolのpool0、そしてフォーマットする際のファイルシステムを指定しています。
6) PersistentVolumeClaimの作成
次に5)で作成したStorageClassを使用したPersistentVolumeClaimを作成します。ここでPVが動的にプロビジョニングされ、実際にDRBDのリソース・ボリュームが作成されることになります。
PVCのYAMLファイルは以下になります。こちらもapplyしていきます。
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: pvc-linstor-csi-2r
spec:
storageClassName: sc-linstor-csi-2r
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 8Gi
上記のYAMLはPostgreSQLのDATAを格納する領域となるので、アーカイブログ(xlog)を格納する領域のPVCも作成して状況を確認すると以下のようになっています。
$ kubectl get sc,pvc,pv
NAME PROVISIONER AGE
storageclass.storage.k8s.io/sc-linstor-csi-2r io.drbd.linstor-csi 18h
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/pvc-linstor-csi-2r Bound pvc-1ee64e33-7007-11e9-b593-062a213f9ba0 8Gi RWO sc-linstor-csi-2r 18h
persistentvolumeclaim/pvc-linstor-csi-2r-xlog Bound pvc-5f39241b-7007-11e9-b593-062a213f9ba0 2Gi RWO sc-linstor-csi-2r 18h
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/pvc-1ee64e33-7007-11e9-b593-062a213f9ba0 8Gi RWO Delete Bound default/pvc-linstor-csi-2r sc-linstor-csi-2r 18h
persistentvolume/pvc-5f39241b-7007-11e9-b593-062a213f9ba0 2Gi RWO Delete Bound default/pvc-linstor-csi-2r-xlog sc-linstor-csi-2r 18h
ここまででLINSTOR+DRBD9のプロビジョニングも完了し、LINSTORコマンドで確認すると以下のようにリソースが確認できます。
$ linstor resource list
-----------------------------------------------------------------------------------
| ResourceName | Node | Port | Usage | State |
-----------------------------------------------------------------------------------
| pvc-1ee64e33-7007-11e9-b593-062a213f9ba0 | linstor01 | 7001 | Unused | UpToDate |
| pvc-1ee64e33-7007-11e9-b593-062a213f9ba0 | linstor02 | 7001 | Unused | UpToDate |
| pvc-5f39241b-7007-11e9-b593-062a213f9ba0 | linstor01 | 7002 | Unused | UpToDate |
| pvc-5f39241b-7007-11e9-b593-062a213f9ba0 | linstor02 | 7002 | Unused | UpToDate |
-----------------------------------------------------------------------------------
この時点ではまだアタッチがされていないため、いずれのリソースもUnusedとなっていることが分かります。
7) StatefulSetから6)のPVCを使用してレプリケーション設定済ボリュームをマウント
6)で作成したPVC2つを使用するStatefulSetをデプロイしていきます。
実際に使うStatefulSetのYAMLは以下です。これをapplyしていきます。
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: pg-drbd-sf
spec:
serviceName: pg-drbd-sf
replicas: 1
selector:
matchLabels:
app: pg-drbd-sf
template:
metadata:
labels:
app: pg-drbd-sf
spec:
containers:
- name: pg-drbd-sf
image: postgres:10.4
ports:
- containerPort: 5432
args:
- -c
- config_file=/etc/postgresql/postgresql.conf
lifecycle:
postStart:
exec:
command:
- sh
- -c
- chmod a+w /mnt/postgresql/xlog/
envFrom:
- configMapRef:
name: postgres-config
env:
- name: PGDATA
value: /var/lib/postgresql/data/pgdata
volumeMounts:
- mountPath: /var/lib/postgresql/data
name: pg-drbd-vol
- mountPath: /mnt/postgresql/xlog
name: pg-drbd-vol-xlog
- mountPath: /etc/postgresql
readOnly: true
name: postgres-conf
volumes:
- name: pg-drbd-vol
persistentVolumeClaim:
claimName: pvc-linstor-csi-2r
- name: pg-drbd-vol-xlog
persistentVolumeClaim:
claimName: pvc-linstor-csi-2r-xlog
- name: postgres-conf
configMap:
name: postgres-conf
items:
- key: postgresql.conf
path: postgresql.conf
内部でConfigMapなども利用していますが、全てのYAMLはこちらを参考にして下さい。
ここまでで冒頭の構成図(完成図)と同じ構成になりました。
PostgreSQLのノード間移動
では、DRBDでローカルディスクが冗長化されたPostgreSQLコンテナ(StatefulSet)で、ノード障害が起きたケースのシュミレーションをしてみましょう。
下図のようにLINSTOR SATELLITE兼DBノードが停止し、別のSATELLITEノードでPostgreSQLで起動してくるケースを考えます。
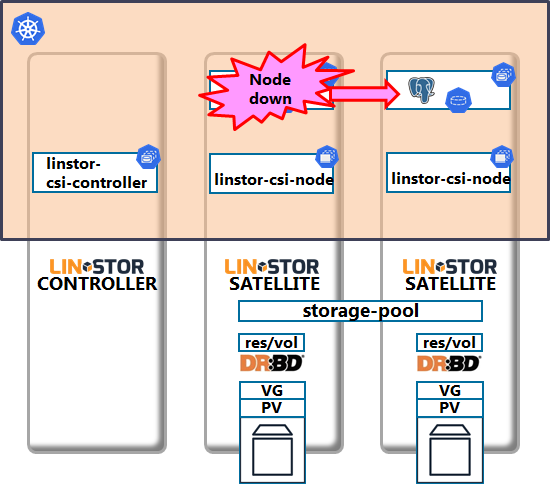
以下の手順で障害テストを行います。
a. LINSTOR SATELLITE兼DBノードを停止
KubernetesからはNodeがNot Ready、そこで稼動していたPodがTerminatingとなります。
以前の投稿でも検証したようにStatefulSetのデフォルトでは、このPodが他ノードに移動することはありません。
$ kubectl get node
NAME STATUS ROLES AGE VERSION
linstor01 Ready worker 20d v1.13.4
controller Ready worker 20d v1.13.4
linstor02 NotReady worker 20d v1.13.4
$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pg-drbd-sf-0 1/1 Terminating 0 9m28s 10.42.4.46 linstor02 <none> <none>
b. kubectl delete [ pod ] --force --grace-period=0 でPodを強制削除
$ kubectl delete pod pg-drbd-sf-0 --force --grace-period=0
warning: Immediate deletion does not wait for confirmation that the running resource has been terminated. The resource may continue to run on the cluster indefinitely.
pod "pg-drbd-sf-0" force deleted
この際、LINSTOR側でもSATELLITEノードが停止することで該当リソースがUnknownとなります。
$ linstor resource list
-----------------------------------------------------------------------------------
| ResourceName | Node | Port | Usage | State |
-----------------------------------------------------------------------------------
| pvc-1ee64e33-7007-11e9-b593-062a213f9ba0 | linstor01 | 7001 | Unused | UpToDate |
| pvc-1ee64e33-7007-11e9-b593-062a213f9ba0 | linstor02 | 7001 | | Unknown |
| pvc-5f39241b-7007-11e9-b593-062a213f9ba0 | linstor01 | 7002 | Unused | UpToDate |
| pvc-5f39241b-7007-11e9-b593-062a213f9ba0 | linstor02 | 7002 | | Unknown |
-----------------------------------------------------------------------------------
c. 別のSATELLITEノードでPodが起動してくることを確認
$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pg-drbd-sf-0 1/1 Terminating 0 45s 10.42.2.26 linstor01
もちろん、LINSTOR側でも別ノードでリソースが利用されていることが確認でき、データも保持されています。
$ linstor resource list
-----------------------------------------------------------------------------------
| ResourceName | Node | Port | Usage | State |
-----------------------------------------------------------------------------------
| pvc-1ee64e33-7007-11e9-b593-062a213f9ba0 | linstor01 | 7001 | InUse | UpToDate |
| pvc-1ee64e33-7007-11e9-b593-062a213f9ba0 | linstor02 | 7001 | | Unknown |
| pvc-5f39241b-7007-11e9-b593-062a213f9ba0 | linstor01 | 7002 | InUse | UpToDate |
| pvc-5f39241b-7007-11e9-b593-062a213f9ba0 | linstor02 | 7002 | | Unknown |
-----------------------------------------------------------------------------------
但し、Podの強制削除から別ノードへの移動まで想定よりも時間がかかりました。この辺りは改めて検証をしたいと思います。
d. kubectl drainで手動フェイルオーバ
こちらの手動フェイルオーバのシナリオと同様にPostgreSQLのポッドが稼働中のノードにkubectl drainをして、フェイルオーバをしてみます。
$ kubectl drain linstor01 --ignore-daemonsets
node/linstor01 cordoned
WARNING: Ignoring DaemonSet-managed pods: cattle-node-agent-x426x, kube-api-auth-8mt4x, nginx-ingress-controller-f8kfg, canal-xhgbp, linstor-csi-node-7t9qz, csi-rbdplugin-fcszp, rook-ceph-agent-lhxll, rook-discover-pvvc4
pod/pg-drbd-sf-0 evicted
pod/cattle-cluster-agent-f4b7f64f5-5kbcg evicted
node/linstor01 evicted
上記で問題なくフェイルオーバしましたが、以前の検証ではkubectl drainコマンドに--forceも付けていましたが、これを付けると上手く動きませんでした。必要なアンマウント処理などもSkipされてしまうからかも知れません。
まとめ
ここまでまとめてきたように、LINSTOR+DRBD9をKubernetesから利用した際にも、Rookと同じように、ノード停止時にStatefulSetのPodを移動させることが出来ました。
ノード停止時の移動時間の短縮については、もう少し検証を進めたいと思います。
あとはLINSTOR+DRBD9の環境で性能測定をしてみる予定です。前回のAmazon EBSやRook/Cephの検証と比べどうなるのか、見ものです。