TL;DR
- NewSQL解説の続編。前回以降のリリース内容を深読みする。
- 共通する改善点は3つ、OLAP対応・悲観的ロック・バックアップ強化
- かつてRDBに近づこうとしたデータベースと同じ道を辿っている(かもしれない)
前回に引き続きのNewSQL解説(さらに深みへ)
今年2-3月にNewSQLに関する2本の記事を書いたところ、想像以上の反響があった。それ以降もいくつかの製品のリリースを継続調査しているが、まとまりのある文章としては残せていない。
そこで当記事では「2020年現在のNewSQLについて」を補足する意味で、各製品の機能改善について振り返っていく。とはいえ、NewSQLに得意なこと/苦手なことは共通しており、改善ポイントには類似性が見られる。まずはそれらをグルーピングしていこう。
対象とするNewSQL
過去記事では、Spannerクローンとして3つのNewSQLデータベースを紹介している。すなわち、CockroachDB・TiDB・YugabyteDBである。
今回もこれら3製品を対象とするが、まずは直近のメジャーバージョンアップで改善された機能を確認しておこう。
| 名称 | 最新 メジャーバージョン |
リリース時期 | 特徴的な追加/改善内容 |
|---|---|---|---|
| CockroachDB | 20.1 | 2020/5/12 | - SELECT FOR UPDATEのサポート - ベクター化された実行の改善 - クラスタの完全バックアップとリカバリ - オンライン主キー変更 |
| TiDB | 4.0 | 2020/6/17 | - 悲観的ロックの採用 - TiFlash(カラムナストア) - Backup&Restore(BR) - SQL Plan Managementの導入 |
| YugabyteDB | 2.2 | 2020/7/15 | - Colocated Table - トランザクション対応バックアップ - オンライン・インデックスビルド |
上表の「特徴的な追加/改善内容」の列を見てもらうと分かる通り、下記3つのポイントが機能改善の傾向として共通している(なお、YugabyteDBは2020年2月に2.1をリリース済で2.2の差分が小さい)。
- OLAP向け機能の強化(カラムナストア、ベクター化実行)
- 悲観的ロックのサポート
- バックアップとリカバリの機能強化
それぞれがどんな意図を持って追加されたのか、次節以降で私なりに解説をしていく。
1. OLAP向け機能強化
このテーマについて議論する前に一つ触れるべきなのは、
「NewSQLは分析系クエリ、つまりOLAP処理に適しているのか?」
という疑問である。
個人的にこれに回答するならば、現時点では"No"となる。
シンプルな言い方をすればRedshiftやBigQuery、最近であればSnowflakeなど分析クエリを専門とするデータベースとは方向性が異なり、まともには競えない。
それでも、NewSQLが「SQLが利用できる、分散データベース」である以上、複雑なクエリを並列処理させたいという考えに至ることは理解できる。
おそらく顧客からの要望もあるのだろう、最近の各製品のリリースではそうしたOLAP向けの機能強化が図られているため、以降ではそれを解説していく。
CockroachDBの対応
CockroachDBでは、後述するTiDBのように列形式でのデータ保持を行っていない。
しかし、OLAPに代表されるような大規模なクエリ処理のために**"vectorized execution"**の機能を順次強化している。例えば、過去のblogではCockroachDBが苦手としてきたハッシュ結合のパフォーマンスを40倍改善する試みが語られている。
バージョン20.1のリリースにおいても、同様の機能の強化は続いており、メモリとディスクを効率的に利用しながら"vectorized execution"を行う改善内容がこちらのblogで説明されている。
これは多くのRDBがソートやハッシュ結合にディスク上の一時領域を使う処理に似ており、そうした方向の機能強化として評価できる。
TiDBの対応
現時点でOLAP向けの対応を、ビジョンとして強く打ち出しているのがTiDBである。
バージョン4.0がGAになった際の彼らのキーフレーズは「Real-Time HTAP Database」であり、トランザクション指向と分析指向の双方のワークロードに応えられるDBを目指していることを示している。
【TiDBにおける行ストア(TiKV)+列ストア(TiFlash)の構成例】
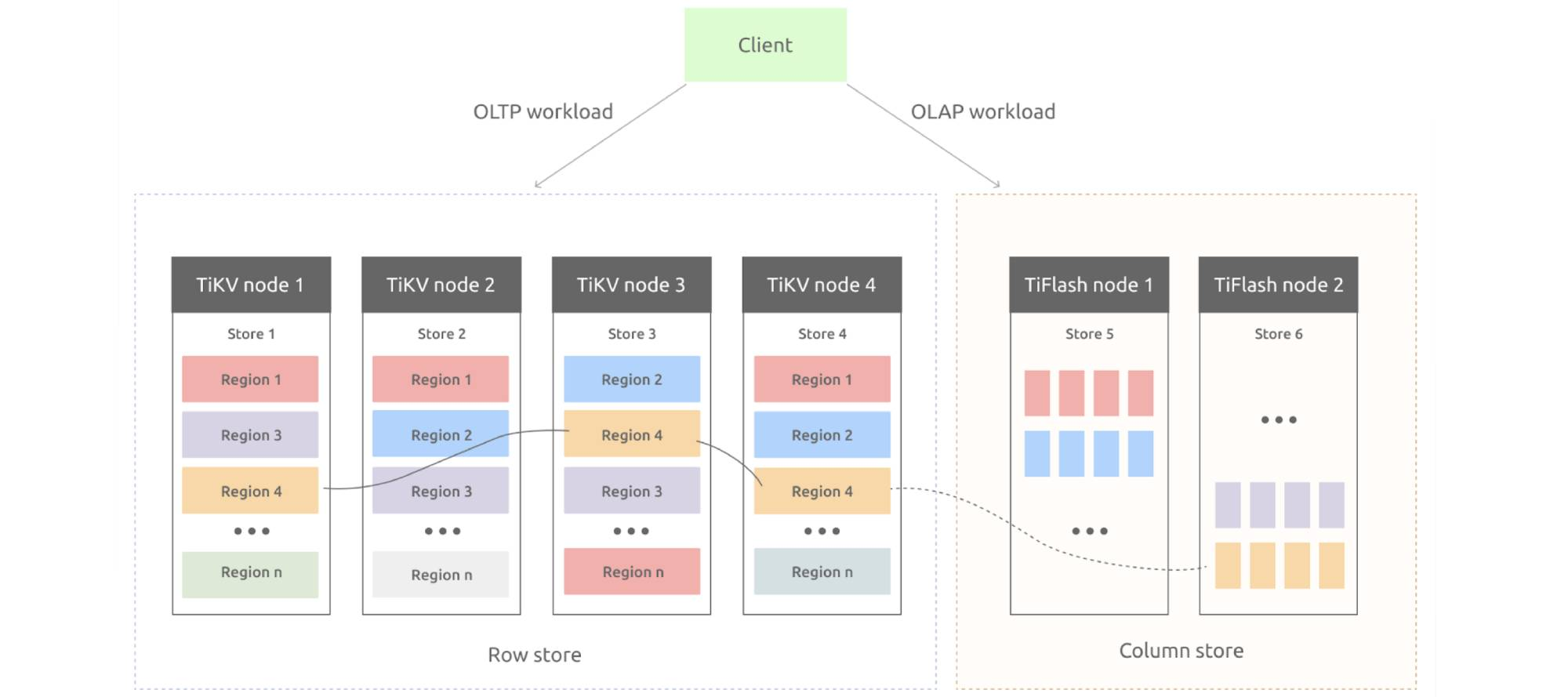
出典:<VLDB 2020: TiDB, A Raft-based HTAP Database>
こちらのblogでは、TiDBの4.0で具体的にOLAP向けとして強化された下記の機能が解説されている。
- リアルタイム更新可能なカラムナストア(TiFlash)
- Raftを利用した非同期のレプリカ更新(Learnerの利用)
- コストベースのアクセスパス選択(Smart Selection)
行ベースのストレージエンジンであるTiKVではRaftを用いて一貫性のあるWrite/Readを担保し、列ベースのストレージエンジン TiFlashへのデータ更新は非同期で行われる。これによって、リアルタイム更新可能なカラムナストアを実現している。
そして、行ベースと列ベースの2つのストレージエンジンを使い分けるのがSmart Selectionと呼ばれる、コストベースのアクセスパス選択機能である。
これは多くのRDBMSでも実装されているコストベース・オプティマイザに相当し、TiDBはTiFlashのカラムナストアをインデックスのように扱うことで、クエリに応じて最適なアクセスパスを選ぶことができる。つまり、OLTPの少数レコードを扱うクエリではTiKVストレージを、OLAPの大量レコードを読み出し集計するクエリではTiFlashストレージを使う、といった具合である。
もちろん、TiDBのHTAP構想にはデメリットもある。例えば、ストレージ消費量の増加である。
上図のように1レコードに対して、TiKV側で3レプリカ、TiFlash側で2レプリカのような構成を取った場合、ストレージスペースは3-4倍消費されることが予想される(カラムナストアは圧縮が効きやすいという特徴があるにしても)。
補足:デュアルフォーマットのデータベース
TiDBのように行・列双方のフォーマットでデータを持つ形式のDBをデュアルフォーマットと呼ぶことがある。
ここでも基本的な考え方として、OLTPを行ベースで処理し、OLAPを列ベースで処理する。
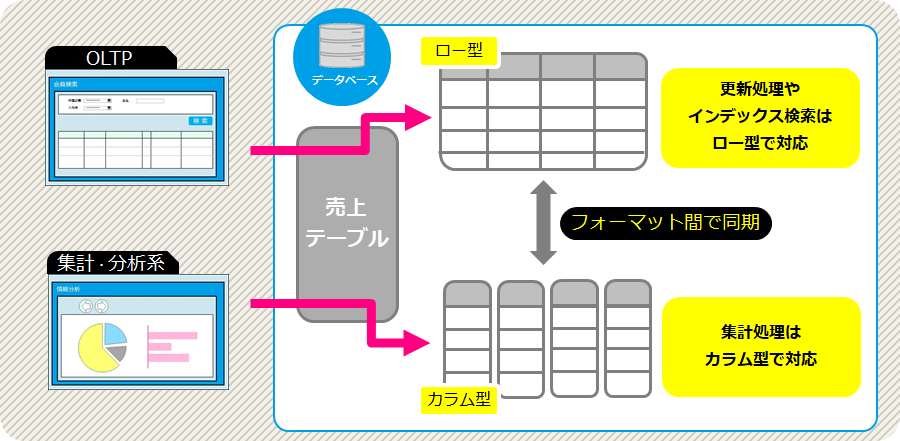
行・列それぞれのデータをどこに持つかが製品によって異なり、例えばOracle Database In-Memoryは行ベースの永続化を基本として、列ベースのデータはメモリにだけ展開する構成となっている。
YugabyteDBの対応
YugabyteDBは、こちらのFAQにOLAP向けではないことが明記されている。
実際にOLAPの機能を提供するには、PrestoやDruidなどと組み合わせて利用する必要があるだろう。
しかし、YugabyteDBでもOLAP利用時の性能を向上させる改善は行われている。
例えば、以前書いたようにYugabyteDBはRocksDBをエンハンスした独自のストレージエンジン:DocDBを利用しているが、そこへの積極的なプッシュダウン処理は分析系クエリでも大きく性能を改善する可能性がある。
具体的にはこちらのblogに記載があるが、クエリレイヤからストレージエンジンへフィルタや集計処理の一部を委譲することで、全体的な性能を向上している。
また、他のNewSQLでも見られるColocated Tableの構成は結合時のデータアクセスを効率化することが可能であり、こちらのblogで詳しく解説されている。
2. 悲観的ロックのサポート
「NewSQLのコンポーネント詳解」の 4.4.1.2 Serializable Snapshot Isolation で解説したように、NewSQLでは同時実行性向上のために、楽観的トランザクション制御(OCC)を採用していた。
この制御方式は、上記blogから引用すると、「分離したスナップショットを用いて、楽観的にトランザクションを並行して進め、書き込み時の衝突を検知したらトランザクションを中断してリトライしよう」という特徴を持つ。
しかし、この楽観的トランザクション制御には欠点が存在する。
まず、性能観点から見て、同時に実行されるトランザクションが競合/衝突するケースではリトライが多発し、パフォーマンスが劣化するという欠点がある。
そして、このリトライをどのようにアプリケーションで実装するかという点で互換性の問題が生じる。
SpannerなどのようにSerializable以上の分離レベルを前提とした分散データベースの経験がある開発者であれば問題ないだろうが、例えばCockroachDBのドキュメントにあるように、Read Committedなどの分離レベルでRDBを使ってきた開発者には従来と異なる実装を要求することになる。
これは従来のPostgreSQLやMySQLなどを前提に開発されたアプリケーションがそのまま動かないことを意味している。
上記の性能、そして互換性のサポートという意味で各製品では悲観的ロックのサポートを打ち出している。
CockroachDBでの対応
CockroachDBの悲観的ロック(SELECT FOR UPDATE)のサポートについては、こちらのblogに詳細が説明されている。
上記blogでは分離レベルが低いリレーショナル・データベースに慣れている開発者向けにSELECT FOR UPDATEを有効にすることで、リトライ処理を簡素化できるとしている。
また、CockroachDBの特徴として、20.1ではsql.defaults.implicit_select_for_update.enabledという設定が追加されており、デフォルトでONになっている。
これはUPDATE文の実行時に前半では対象行のReadが行われるが、そこでSELECT FOR UPDATEが使われることを意味する。もし、UPDATE処理で楽観的同時実行制御を行う場合には、上記設定をOFFにする必要がある。
もちろん、明示的にSELECT文にFOR UPDATE句を付けることで、対象行に悲観的ロックを掛けることも可能である。
TiDBでの対応
TiDBの悲観的ロックについては、こちらのblogに解説がある。
上記blogでは、悲観的ロックを有効にした際の動作などを解説しているが、TiDBでの注意点はtidb_txn_modeが、デフォルトでpessimisiticになっていることだろう。
つまり、TiDB 4.0以上では悲観的トランザクション制御がデフォルトである。
また、blogやこちらのドキュメントにはMySQL InnoDBとの動作の違いが整理されている。例えば、TiDBにはギャップロックがない等、悲観的ロックがデフォルトであっても注意すべき差異が存在する。
YugabyteDBでの対応
YugabyteDBでは最新リリース以前から楽観的ロックと悲観的ロック双方をサポートしており、こちらのドキュメントにも明記されている。
上記ドキュメントには、YugabyteDBがPostgreSQLと同様の多様なタイプの行ロックをサポートしていること、そして一部でPostgreSQLと動作の違いがあることが説明されている。
また、このドキュメントには楽観的・悲観的なトランザクションがそれぞれ向いているワークロードについても解説されている。
まず、楽観的トランザクション制御は、トランザクションの多くが競合しないケース(例えばデータセットが大きく、ユーザアクセスが局所的にしか発生しないケースなど)に向いており、そうした場合はアボートが発生せず、ロックも取らないため、性能が向上する。
一方で、悲観的トランザクション制御は、長時間にわたってトランザクションの競合を発生させるようなワークロードに向いている。つまり、バッチ処理のように大きな読取りセットを長時間にわたって順次処理していくようなケースが想定される。こうしたケースで楽観的トランザクション制御を使うと、何度もバッチ処理側がアボートしてしまうことが考えられる。
そもそも、こうした長時間一貫した読取りセットを必要とするような処理は、NewSQL上で組むこと自体に問題があるが、RDBとの互換性という意味ではこうした視点が必要になるだろう。
3. 一貫性バックアップの機能・性能強化
Spannerクローンのアーキテクチャで軽く触れたように、CockroachDBとYugabyteDBはPostgreSQL互換、TiDBはMySQL互換をそれぞれ謳っている。
つまり、バックアップの方法としてPostgreSQLやMySQLの論理バックアップと同レベルの手段が実装されている。
- CockroachDB:cockroach dumpが利用可能。
- TiDB:mysqldumpやmydumperによるバックアップも可能だが、専用ツールとしてDumplingも用意されている。
- YugabyteDB:pg_dump派生のysql_dumpによるバックアップが可能。
しかし、こうした論理バックアップにより数100TB、またはPB級の分散データベースをバックアップするのは現実的でない。
そのため、NewSQLの運用では「巨大なデータベースで高速に、一貫性のあるバックアップを取得できる」ツールが必須であると言える。
こうしたバックアップ・リカバリ運用の改善が最近の各製品のリリースでは行われているので、それらを確認していこう。
CockroachDBの対応
20.1.0のリリースノートでも触れられている通り、以下のBACKUPコマンドの機能強化が行われている。
- Full-cluster backup and restore:DBクラスタの完全バックアップ/リストアが可能に。
- Encrypted backups:バックアップデータを暗号化が可能に。
CockroachDBのBACKUPコマンドでは、ユーザ権限やゾーン・クラスタ設定など全てを対象とするため、同データから新規クラスタへ完全復旧が可能となり、以降のマイナーリリースでも継続的な性能改善が行われている。
また、同BACKUPコマンドでは完全バックアップ以外にも差分バックアップが可能で、週末のみ完全バックアップ、平日は差分バックアップといった運用が可能となっている。もちろん、暗号化オプションは完全・差分双方で利用可能である。
但し、このBACKUPコマンドの利用にはCockroachDBのエンタープライズライセンスが必要となる点には注意が必要である。
TiDBの対応
TiDBでも4.0の目玉機能として、Backup&Restore(BR)のリリースをこちらのblogなどで具体的なベンチマークと共に大きくアピールしている。
上記blogにも「When it takes a lot of time to backup or restore a database, Garbage Collection might break the snapshot used in the backup or restore process.」と書かれているように、大規模分散データベースでのバックアップには、下記2点の課題がある。
- データセットが大きくなりがちだが、バックアップに長時間かかると過去バージョンのレコードを削除する処理が走り、一貫性が保持できない。
- 一貫性を重視した場合は長時間バックアップが履歴の長期保持に繋がり、データベースが肥大化する。
どちらも解決するには高速に、おそらくそれは並列にバックアップを取得する必要があり、それに真正面から取り組んでいるのが、TiDBのBRであろう。
BRを利用する際の構成は下図の通りだが、大きな特徴として、TiDB(つまりMySQL互換のクエリレイヤ)は経由せずに、TiKV(つまりストレージレイヤ)と直接の通信を行い、バックアップを並列に取得することができる。また、この経路で一貫性のあるバックアップが可能なのは、下図のPDからタイムスタンプを取得し、それに基くスナップショットをTiKVから取得できるという構造に拠っている。
【TiDBのBRを利用する際の構成】
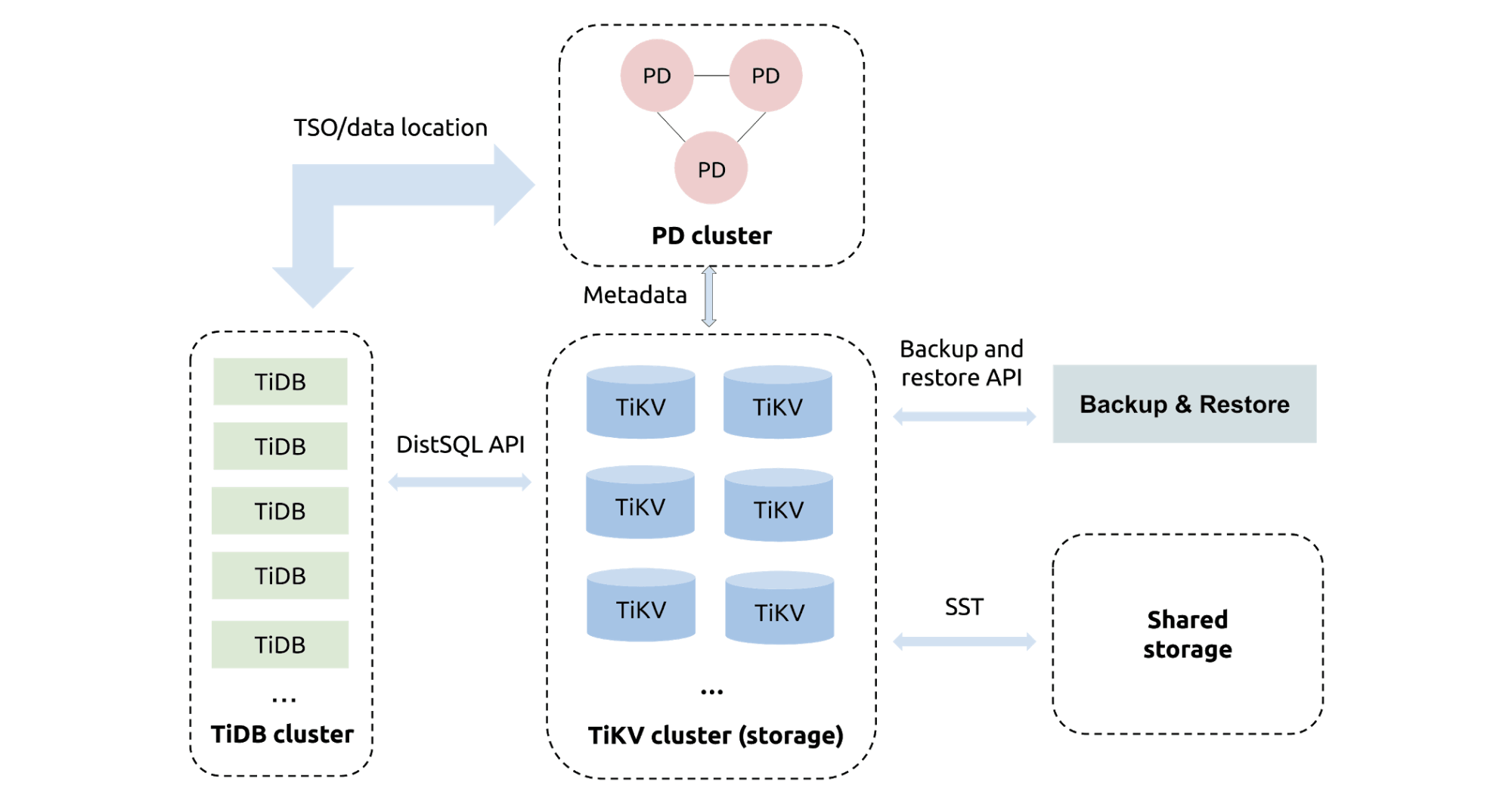
出典:<How to Back Up and Restore a 10-TB Cluster at 1+ GB/s>
上図の出典元記事では、BRにより10TBのデータベースを平均2.7GB/sの速度でバックアップ、平均1.1GB/sでリストアが出来たというベンチマークを提示している。
YugabyteDBの対応
YugabyteDBでは、2.2でTransactional distributed backupsをサポートした。
2.2リリース時のblogにあるように、以前のバージョンで提供されていたSnapshotでは単一行のトランザクションしかサポートされておらず(つまりほぼ使い物にならない)、2.2でようやく複数行のトランザクションをSnapshotで処理できるようになっている。
個人的な意見だが、YugabyteDBのバックアップ・リストア関連機能は2.2時点でも途上と思われる。CockroachDBのような増分バックアップや、TiDBのようなストレージレイヤから直接かつ並列にバックアップをするような手法を準備できていないように見える。
この辺りは次回以降のリリースに期待をしたい。
まとめ
今回記事のアジェンダを検討している際に、以下のような貴重なご意見を頂いた。
10年前ぐらいかな、HbaseがRDBMSと比較してここら辺RDBMSと同様に実現出来てスケールの優位性を豪語してたのを思い出した。ここら辺は技術者としたらときめくよねって思ったり。 https://t.co/si5I6gqYfO
— hironomiu (@hironomiu) August 5, 2020
たしかにNoSQLをベースとしてSQLをサポートする際に、RDBに近づいたり、互換性を保つために行われた機能強化があったはずで、それらと今回紹介したNewSQLの機能改善の方向は似ているのかもしれない。
Google Cloud Spannerのように他のデータストア(BigTableやCloud SQLなど)と一体となって、包括的なデータストアを提供するクラウドベンダとは異なり、今回あげたNewSQLベンダは様々なワークロードにベンダ内のエコシステムで対抗する必要がある。
そう考えると今後のNewSQLの方向性も少しずつ見えてくるかもしれない。
今回も長文となり大変申し訳ないが、付き合って頂いた読者の皆様に感謝する。