概要
Azure Databricks 上にて、1レコードに複数(MAX:10)存在する類似データを、その類似データ毎のレコードとして新たに生成し、ファイルに保存する Python プログラムです。(イメージは以下、、、、)
## 元データ
3001,WS1,中野 一郎,79,1630000,WS2,上野 二郎,104,1000000,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,2021/7/27,
3002,PS1,下野 三郎,32,800000,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,2021/6/29,
3003,ST1,中川 四郎,100,1656000,ST2,前川 五郎,64,1104000,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,2021/8/30,
↓↓↓
## 抽出変換データ
3001,WS1,中野 一郎,79,1630000,2021/7/27
3001,WS2,上野 二郎,104,1000000,2021/7/27
3002,PS1,下野 三郎,32,800000,2021/6/29
3003,ST1,中川 四郎,100,1656000,2021/8/30
3003,ST2,前川 五郎,64,1104000,2021/8/30
ローカル環境
- macOS Monterey 12.0.1
- python 3.8.3
- Azure CLI 2.28.0
前提条件
- Azure環境がすでに用意されていること(テナント/サブスクリプション)。
- ローカル環境に「azure cli」がインストールされていること。
事前準備
Azure 環境の準備
### ローカル環境変数の定義
export RG_NAME=rg-ituru_bricks02
export SUBS_NAME=PSP-01
export DB_WORKSPACE_NAME=db-ituru_workspace02
## 使用するテナントへのログイン
$ az login --tenant <tenant_id>
## 使用サブスクリプションの定義
$ az account set --subscription $SUBS_NAME
## 使用サブスクリプションの確認(IsDefault=True)
$ az account list --output table
## Azure Data Bricks 用のリソースグループ作成
$ az group create --name $RG_NAME --location japaneast
Azure Data Bricks の作成
14日間無料のトライアル版で構成します
## Azure Databricks Workspace の作成・・・完了まで数分かかります
az databricks workspace create --resource-group $RG_NAME --name $DB_WORKSPACE_NAME --location japaneast --sku trial
Spark クラスタの作成
-
Azure portal で、作成した Databricks サービスに移動し、「ワークスペースの起動」 を選択します
-
Azure Databricks ポータルにリダイレクトされます。 ポータルで [New Cluster] を選択します
-
以下のパラメータ入力後、「Create Cluster」ボタンを押します。クラスターが作成され、起動されます
項目 値 Cluster Name db_ituru_cluster02 Cluster Mode Single Node Databrickes Runtime Version 9.1 LTS (Scala 2.12, Apache Spark 3.1.2) AutoPilotOprions Terminate after 45 minutes of inactivity Node Type Standard_DS3_v2 (14GB Memory 4Cores)
データファイルのアップロード
- Azure Databricks ポータルで [Import & Explorer Data] を選択します
- 「Drop files to upload, or click to browse」に対象のファイルをドラッグ&ドロップします
- 「DBFS」タブを選択し、「FileStore - tables」フォルダ配下にドロップしたファイル(Operation_SE_Cost_short.csv)を確認することができます
Notebook の作成
-
Azure Databricks ポータルで [New Notebook] を選択します
-
以下のパラメータ入力後、「Create」ボタンを押します。新規の Notebook 画面が表示されます
項目 値 Name Pandas_02 Default Language Python Cluster db_ituru_cluster02
Notebook の実装
変換元ファイルの確認
cmd_1
display(dbutils.fs.ls("/FileStore/tables/"))

データの抽出変換
cmd_2
import pandas as pd
# 1レコードに存在する複数分の類似データをその類似毎のレコードとして新たに生成
def DataSpilit():
# csv型式のデータファイルをDataFrameとして読取る
df = spark.read.csv('/FileStore/tables/Operation_SE_Cost_short.csv', header='true', inferSchema='true', encoding='ms932')
# columns は全ての列名を list で返す
colist = df.columns
# print(colist)
# 類似データあたりの登録項目数
n = 4
# ダミーデータを使用した、最終形のDataframeの作成
dfl = spark.createDataFrame([(0,'PPP','USER_J',0,0,'2020/1/1')],['Num', 'Dept', 'J_Name', 'W_Time', 'UP_Cost', 'Fix_Date'])
display(dfl)
# MAX10の類似データ
for j in range(1,11) :
# select(*cols) は列名または式の抽出を行い, 結果を DataFrame で返す
dfs = df.select(colist[0], colist[(j*n)-3], colist[(j*n)-2], colist[(j*n)-1], colist[j*n], colist[41])
# display(dfs)
# null の行の削除
# dropna は欠測値を含む行を削除した新しい DataFrame を返す
dfd = dfs.dropna()
display(dfd)
# union は2つの DataFrame を統合し新しい DataFrame を返す
dfl = dfl.union(dfd)
# ダミーデータの削除 → 最終データ
display(dfl)
dff = dfl.filter(dfl.Num > 0)
display(dff)
# ファイルへ保存
cnt = DataToFile(dff)
return cnt
# 変換データをファイルへ保存
def DataToFile(dff):
# PySpark Dataframes から Pandas への変換
pdf = dff.toPandas()
# カラム:Data の型を str型 から datetime型 にデータ変換する
# (クエリ処理で、Dateを範囲指定(Betweem)で行いたいため)
pdf['Fix_Date'] = pd.to_datetime(pdf['Fix_Date'].astype(str), format='%Y-%m-%d')
# print(type(pdf['Date'][0]))
# display(pdf)
# Pandas から PySpark Dataframes への変換
df_fix = spark.createDataFrame(pdf)
display(df_fix)
# DBFSへのデータの保存
df_fix.write.mode('overwrite').json("/FileStore/tables/tech_perup_short.json")
return df_fix.count()
# 実行関数のコール
result = DataSpilit()
print(result)
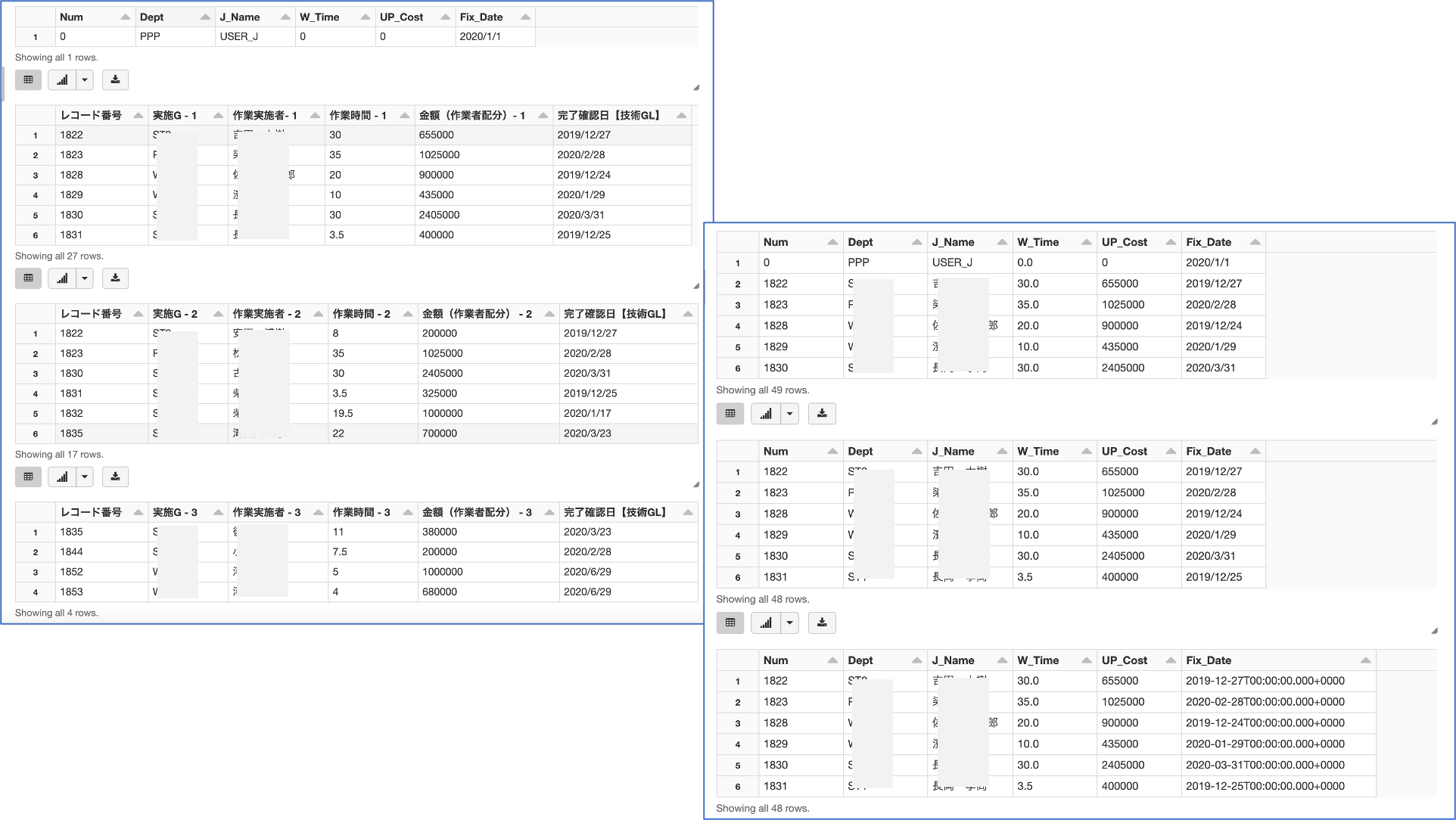
変換済みデータファイルの確認_1
cmd_3
display(dbutils.fs.ls("/FileStore/tables/"))

変換済みデータファイルの確認_2
cmd_4
display(dbutils.fs.ls("/FileStore/tables/tech_perup_short.json/"))

変換済みデータファイルの読込再確認
cmd_5
rdf = spark.read.json('/FileStore/tables/tech_perup_short.json')
display(rdf)
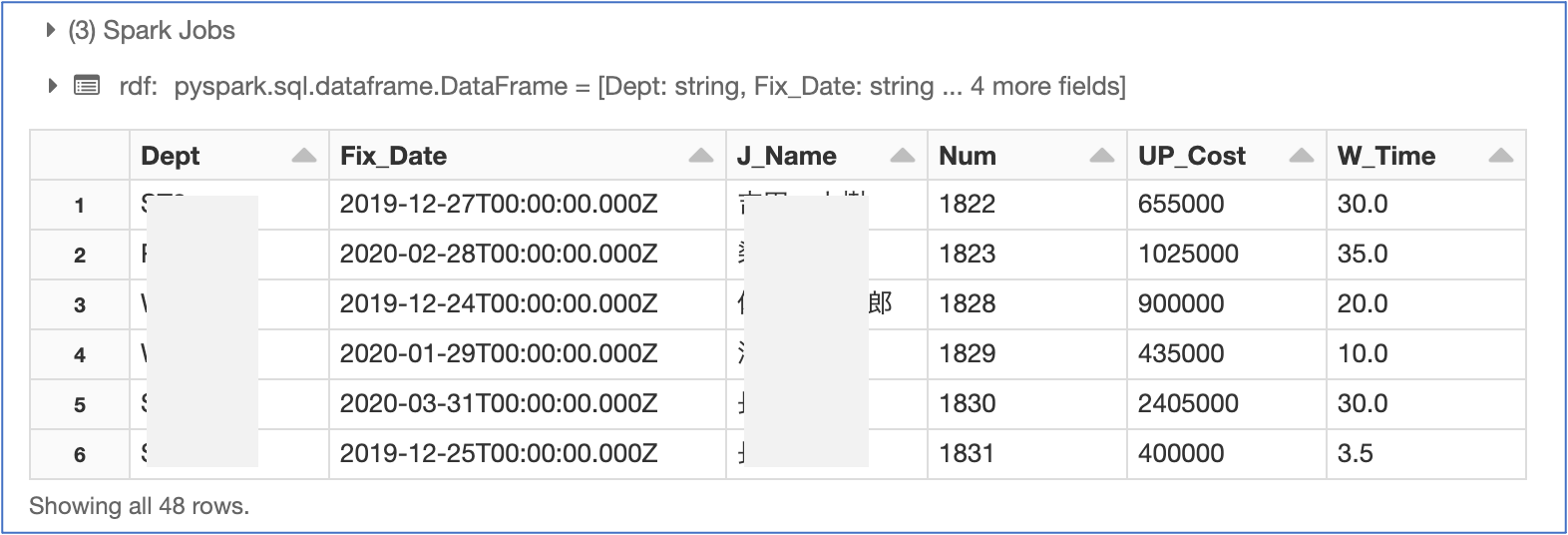
Azure Data Bricks リソースのクリーンアップ
## リソースをクリーンアップするには、ワークスペースを削除します
az databricks workspace delete --resource-group $RG_NAME --name $DB_WORKSPACE_NAME
まとめ
Pyhton の Dataframe と Pyspark の Dataframe って扱い方がちょっと異なるんですね、、、、、
参考記事
以下の記事を参考にさせていただきました。感謝申し上げます。
【Spark】pyspark.sql.DataFrame クラスのメソッド