概要
Kaggleの血液検査データセットを使ってデータ分析をしてみた。
いろいろ試してみた結果、量が多くなったので分割します。
今回はその③ (全5回)
他の回はこちらから
①~モデルの性能比較をしてみた~
②~特徴選択をして、重要度を可視化してみた~
④~外れ値の取り扱い~
⑤~不均衡データの取り扱い~
使用したデータセット:Patient Treatment Classification (Electronic Health Record Dataset)
インドネシアの病院で集められた血液検査の結果から、患者に治療が必要かどうかを判定する
モデル
今回使用したモデルは以下の6種類
- XGBoost
- ニューラルネットワーク
- ランダムフォレスト
- ロジスティック回帰
- 決定木
- k-近傍法
データ確認
データは血液検査の結果。
データの検査方法が分からなかったため、正常値は2016年度国立がん研究センターのデータをお借りしました。(※ 正常値は測定方法などにより若干のばらつきあり)
| 列No | 検査値 | 和訳 | 正常値 | 高いと | 低いと |
|---|---|---|---|---|---|
| 1 | HAEMATOCRIT | ヘマトクリット | 男性:40.7~50.1 %, 女性:35.1~44.4 % |
多血症など | 貧血など |
| 2 | HAEMOGLOBINS | ヘモグロビン | 男性:13.7~16.8 g/dl, 女性:11.6~14.8 g/dl |
多血症など | 貧血など |
| 3 | ERYTHROCYTE | 赤血球 | 男性:4.35~5.55 x 106 /μL, 女性:3.86~4.92 x 106 /μL |
多血症など | 貧血など |
| 4 | LEUCOCYTE | 白血球 | 3.3~8.6 x 103/μL | 感染症・白血病など | 一部感染症・膠原病・貧血など |
| 5 | THROMBOCYTE | 血小板 | 158~348 x 103/μL | 血小板血症・白血病・多血症など | 貧血・紫斑病など |
| 6 | MCH | 平均赤血球ヘモグロビン量 | 27.5~33.2 pg | 巨赤芽球性貧血など | 鉄欠乏性貧血など |
| 7 | MCHC | 平均赤血球ヘモグロビン濃度 | 31.7~35.3 g/dL | 脱水・多血症など | 貧血など |
| 8 | MCV | 平均赤血球容積 | 83.6~98.2 fL | 巨赤芽球性貧血など | 鉄欠乏性貧血など |
| 9 | AGE | 年齢 | ― | ― | ― |
| 10 | SEX | 性別 | ― | ― | ― |
| 11 | SOURCE | 治療が必要か | out: 治療不要, in: 治療が必要 | ― | ― |
前処理は①と同じなので割愛
アンサンブル学習
複数のモデルの結果を融合させて精度を向上させる手法。
今回はランダムフォレスト、ロジスティック回帰、決定木を使ってアンサンブル学習
前回までの結果
| ROC_AUC | 特異度 | 感度 | f1値 |
|---|---|---|---|
| ['AUC_RF', 0.755] | ['specificity_RF', 0.859] | ['recall_RF_S', 0.658] | ['f1_RF', 0.707] |
| ['AUC_RF_S', 0.75] | ['specificity_KN_S', 0.853] | ['recall_RF', 0.652] | ['f1_RF_S', 0.703] |
| ['AUC_LR', 0.723] | ['specificity_RF_S', 0.843] | ['recall_DT', 0.618] | ['f1_LR', 0.666] |
| ['AUC_DT_S', 0.721] | ['specificity_LR', 0.837] | ['recall_LR', 0.61] | ['f1_DT_S', 0.664] |
| ['AUC_LR_S', 0.719] | ['specificity_DT_S', 0.833] | ['recall_DT_S', 0.61] | ['f1_LR_S', 0.661] |
| ['AUC_KN', 0.702] | ['specificity_LR_S', 0.831] | ['recall_LR_S', 0.607] | ['f1_KN', 0.641] |
| ['AUC_KN_S', 0.69] | ['specificity_KN', 0.813] | ['recall_KN', 0.591] | ['f1_DT', 0.625] |
| ['AUC_DT', 0.677] | ['specificity_DT', 0.737] | ['recall_KN_S', 0.527] | ['f1_KN_S', 0.61] |
X_ENS, y_ENS, df_ENS = dframe_copy(df_samp, "SOURCE")
train_X, test_X, train_y, test_y = train_test_split(X_ENS, y_ENS, test_size=0.2, random_state=42)
train_X, val_X, train_y, val_y = train_test_split(train_X, train_y, test_size=0.1, random_state=42)
train_X = np.asarray(train_X).astype(np.float32)
train_y = np.asarray(train_y).astype(np.float32)
val_X = np.asarray(val_X).astype(np.float32)
val_y = np.asarray(val_y).astype(np.float32)
test_X = np.asarray(test_X).astype(np.float32)
test_y = np.asarray(test_y).astype(np.float32)
重み付きVoting
dtc = DecisionTreeClassifier()
estimators = [('DT', DT_model), ('RF', RF_model), ('LR', LR_model)]
vote_clf = VotingClassifier(estimators=estimators, voting='soft', weights=[1, 3, 2])
vote_clf.fit(train_X, train_y)
vote_clf.score(test_X, test_y)
pred_y = vote_clf.predict(test_X)
# モデル評価
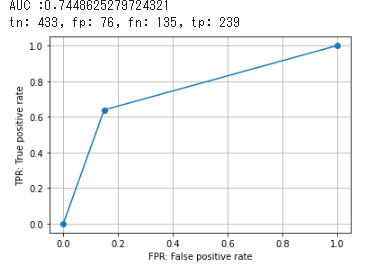
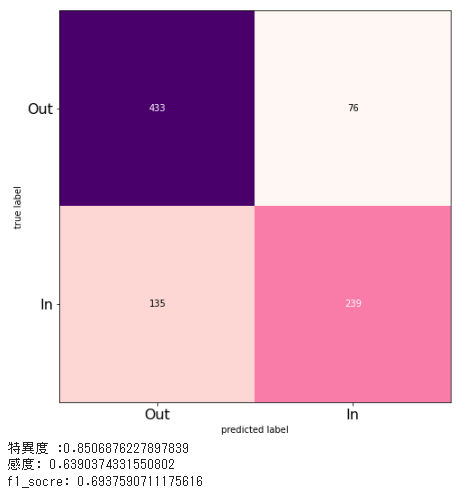
AUC_WAV = create_ROCcurve(test_y, pred_y)
tn_WAV, fp_WAV, fn_WAV, tp_WAV, specificity_WAV, recall_WAV, f1_WAV = create_cm(test_y, pred_y, True)
AUC_list.append(["AUC_WeightAvarageVoting", np.round(AUC_WAV, 3)])
specificity_list.append(["specificity_WeightAvarageVoting", np.round(specificity_WAV, 3)])
recall_list.append(["recall_WeightAvarageVoting", np.round(recall_WAV, 3)])
f1_score_list.append(["f1_WeightAvarageVoting", np.round(f1_WAV, 3)])
結果
Bagging
bag_model = BaggingClassifier(base_estimator=DT_model, n_estimators=100)
bag_model.fit(train_X, train_y)
bag_model.score(test_X, test_y)
pred_y = bag_model.predict(test_X)
# モデル評価
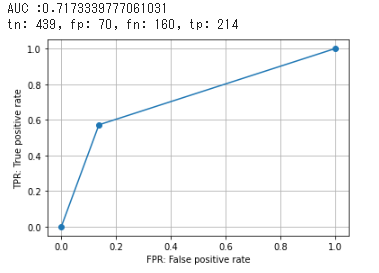
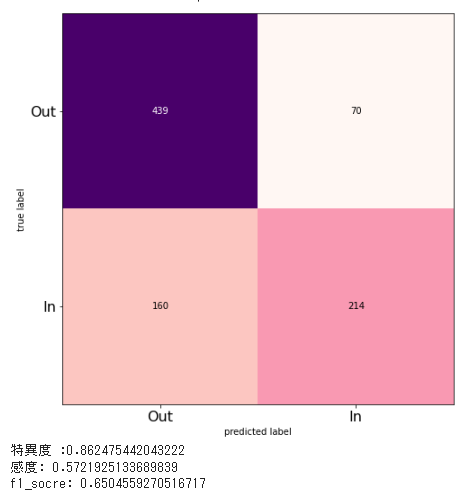
AUC_BAG = create_ROCcurve(test_y, pred_y)
tn_BAG, fp_BAG, fn_BAG, tp_BAG, specificity_BAG, recall_BAG, f1_BAG = create_cm(test_y, pred_y, True)
AUC_list.append(["AUC_Bagging", np.round(AUC_BAG, 3)])
specificity_list.append(["specificity_Bagging", np.round(specificity_BAG, 3)])
recall_list.append(["recall_Bagging", np.round(recall_BAG, 3)])
f1_score_list.append(["f1_Bagging", np.round(f1_BAG, 3)])
結果
Stacking
estimators = [('DT', DT_model), ('RF', RF_model), ('LR', LR_model)]
stk_clf = StackingClassifier(estimators=estimators, final_estimator=LogisticRegression(solver='liblinear'))
stk_clf.fit(train_X, train_y)
stk_clf.score(test_X, test_y)
pred_y = stk_clf.predict(test_X)
# モデル評価
AUC_STK = create_ROCcurve(test_y, pred_y)
tn_STK, fp_STK, fn_STK, tp_STK, specificity_STK, recall_STK, f1_STK = create_cm(test_y, pred_y, True)
AUC_list.append(["AUC_Stacking", np.round(AUC_STK, 3)])
specificity_list.append(["specificity_Stacking", np.round(specificity_STK, 3)])
recall_list.append(["recall_Stacking", np.round(recall_STK, 3)])
f1_score_list.append(["f1_Stacking", np.round(f1_STK, 3)])
結果
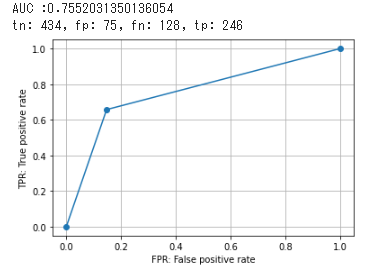
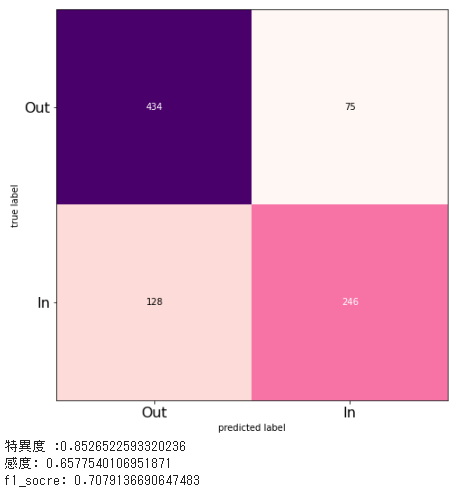
考察
| ROC_AUC | 特異度 | 感度 | f1値 |
|---|---|---|---|
| ['AUC_RF', 0.755] | ['specificity_Bagging', 0.862] | ['recall_RF_S', 0.658] | ['f1_Stacking', 0.708] |
| ['AUC_Stacking', 0.755] | ['specificity_RF', 0.859] | ['recall_Stacking', 0.658] | ['f1_RF', 0.707] |
| ['AUC_RF_S', 0.75] | ['specificity_KN_S', 0.853] | ['recall_RF', 0.652] | ['f1_RF_S', 0.703] |
| ['AUC_WeightAvarageVoting', 0.745] | ['specificity_Stacking', 0.853] | ['recall_WeightAvarageVoting', 0.639] | ['f1_WeightAvarageVoting', 0.694] |
| ['AUC_LR', 0.723] | ['specificity_WeightAvarageVoting', 0.851] | ['recall_DT', 0.618] | ['f1_LR', 0.666] |
| ['AUC_DT_S', 0.721] | ['specificity_RF_S', 0.843] | ['recall_LR', 0.61] | ['f1_DT_S', 0.664] |
| ['AUC_LR_S', 0.719] | ['specificity_LR', 0.837] | ['recall_DT_S', 0.61] | ['f1_LR_S', 0.661] |
| ['AUC_Bagging', 0.717] | ['specificity_DT_S', 0.833] | ['recall_LR_S', 0.607] | ['f1_Bagging', 0.65] |
| ['AUC_KN', 0.702] | ['specificity_LR_S', 0.831] | ['recall_KN', 0.591] | ['f1_KN', 0.641] |
| ['AUC_KN_S', 0.69] | ['specificity_KN', 0.813] | ['recall_Bagging', 0.572] | ['f1_DT', 0.625] |
| ['AUC_DT', 0.677] | ['specificity_DT', 0.737] | ['recall_KN_S', 0.527] | ['f1_KN_S', 0.61] |
ランダムフォレスト、ロジスティック回帰、決定木でアンサンブル学習を実施したが、元のランダムフォレストによる学習と大きな差はなかった。
一方で、ロジスティック回帰や決定木と比べると重み付きVoteingやStackingで改善がみられることから、精度の高いモデルを使用すれば全体的な改善につながると考えられる。
参考資料
機械学習上級者は皆使ってる?!アンサンブル学習の仕組みと3つの種類について解説します
アンサンブル学習
アンサンブル学習 ~三人寄れば文殊の知恵~ たくさんモデルを作って推定性能を上げよう!
アンサンブル学習(Ensemble learning)解説と実験
アンサンブル学習