今回の目標
前回作成したモデルの正解率を上げるハイパーパラメータを探します。
ここから本編
model_test.ipynb
31の実験の際と同様、まずは精度が悪くてもいいのである程度学習してくれるパラメータを探します。
プログラムは35のmodel.ipynbと全く同じものを用いて、そのパラメータを変更しながら実験を行いました。
まず、勾配消失を疑ったので活性化関数を変えようと思いましたが、relu以外の絶対値1以上をとる活性化関数ではうまく学習できませんでした。そのため、tanhを2倍してみました。強引な方法ではありますが一応学習はしてくれました。reluとtanh以外でうまく学習できなかった理由は勾配爆発の可能性もあると考えました。誤差が非常に大きくなった時にエラーが起きるためです。
また、GradientHardClippingの引数を-2と2にすると何とか学習してくれました。
その時のグラフを以下に示します。
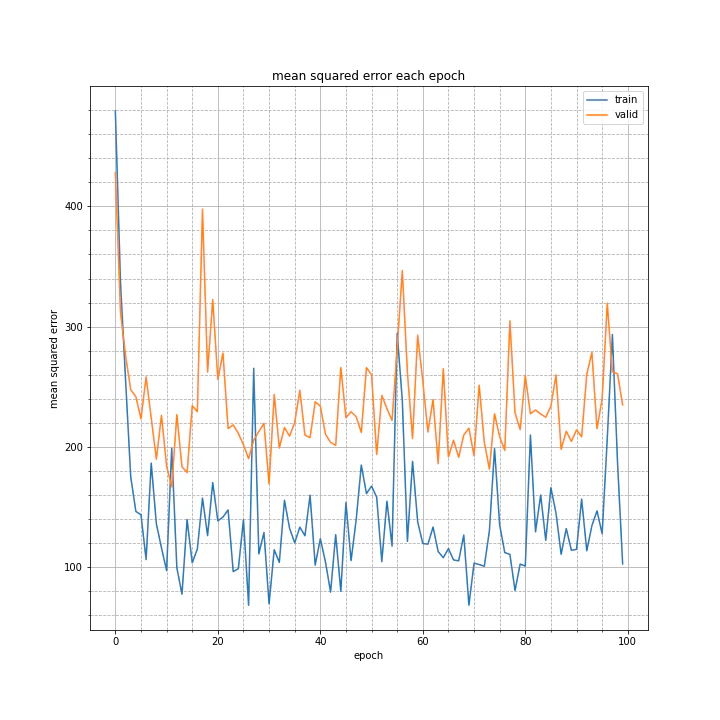

また、最終的に何とか学習が進んだパラメータを載せておきます。
- 層の数は10層
- データ集めの量は1(詳しくは後述)
- 活性化関数は2xtanh
- バッチサイズは200
- boundは2
- エポック数は100(上のグラフを見る限り40程度でも十分)
- 最適化手法はAdaBound
- 誤差関数は平均二条誤差
run.ipynb
基本的には31の実験とほぼ同じ実験手法ですが、もう一度説明します。
今回使用するクラスやファイルは以下のようになっています。
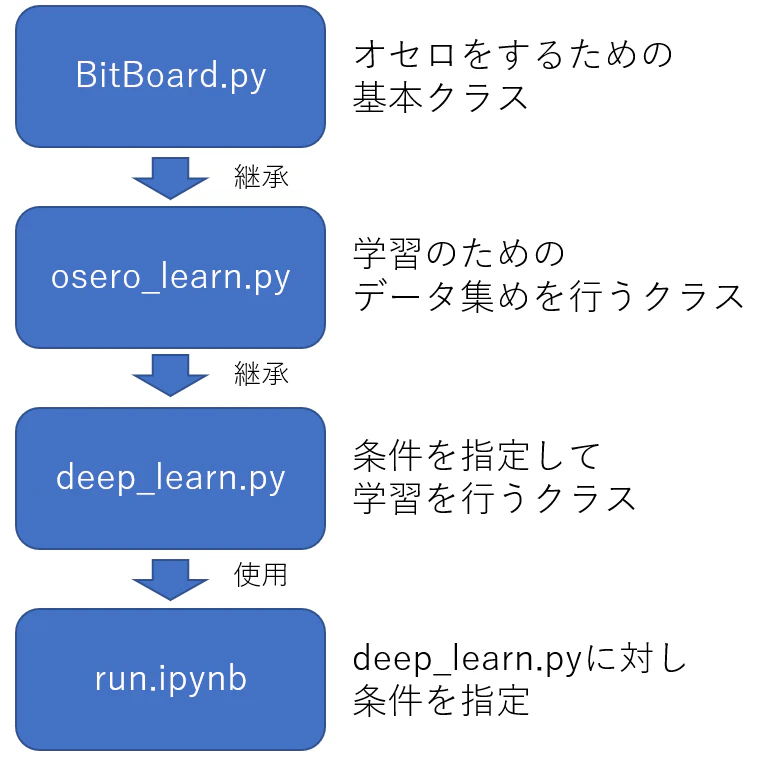
ファイル構造は以下のようになっています。
36
├── fig
│ └── ※実験データをグラフ化した画像が入る※
├── BitBoard.py ・・・オセロのための基本クラスを定義
├── deep_learn.py ・・・深層学習のためのクラスを定義
├── Net.py ・・・ニューラルネットワークを定義
├── osero_learn.py ・・・データ集めのためのクラスを定義
└── run.ipynb ・・・実験実行のためのファイル
また、学習時間短縮のためエポック数は40にしたいと思います。本番のモデルのみ100回で学習させようと思います。
準備
学習を行うためのクラスをインポートします。
from deep_learn import *
実験
データ量
学習に用いるデータの量を変えながら実験を行いました。
ここでデータ量とは、random、1hand、1hand_custom、1least、1mostのそれぞれが総当たり戦を一通り行い、そこで集まるデータの量を1とします。
run = deep_learn()
num_arr = [1, 5, 10]
run.save_dir = "fig/data_quantity"
i = 1
MSE_test = []
MAE_test = []
for num in num_arr:
print("\r%d/%d" % (i, len(num_arr)), end="")
run.num = num
run.fig_name1 = "MSE of each epoch (data quantity is %d)" % num
run.fig_name2 = "MAE of each epoch (data quantity is %d)" % num
run.set_data()
run.fit()
run.plot()
test_error = run.cal_test_error()
MSE_test.append(test_error[0])
MAE_test.append(test_error[1])
i += 1
実行結果はこちら。
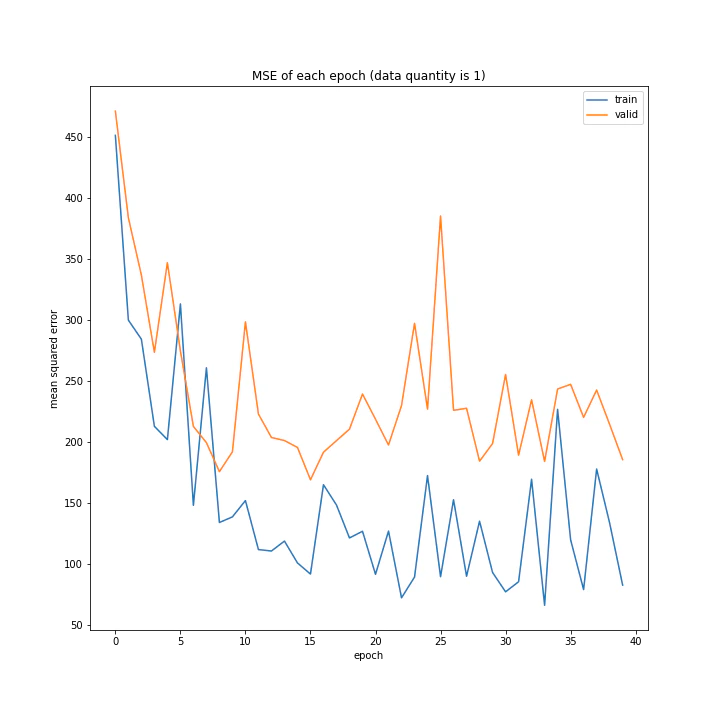
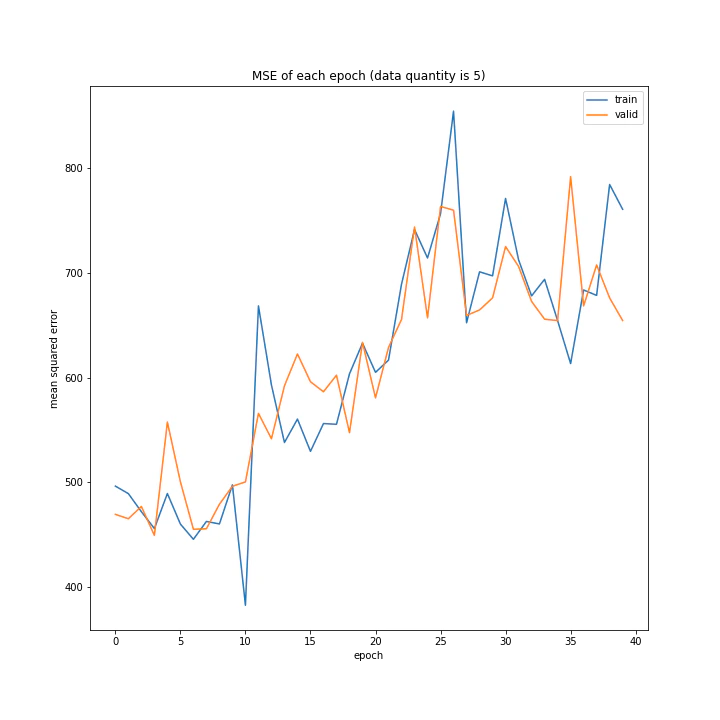
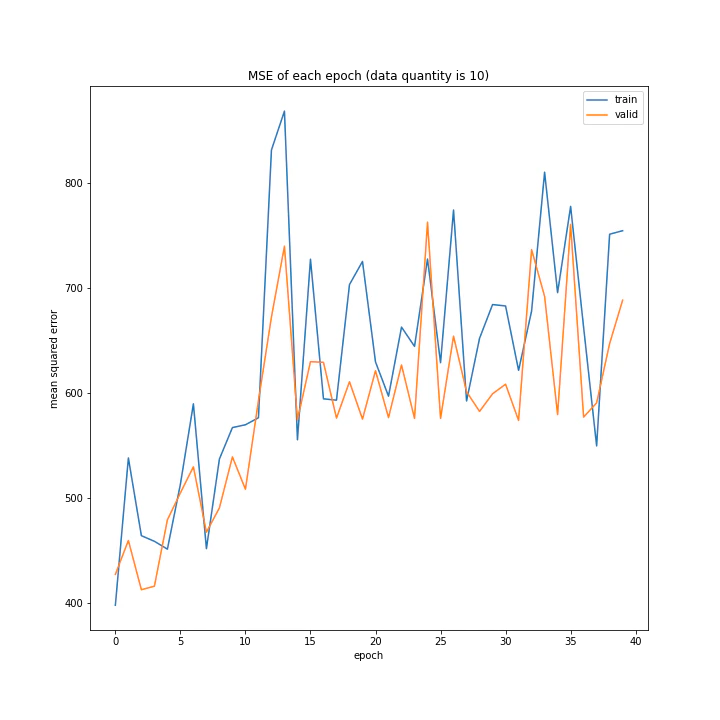

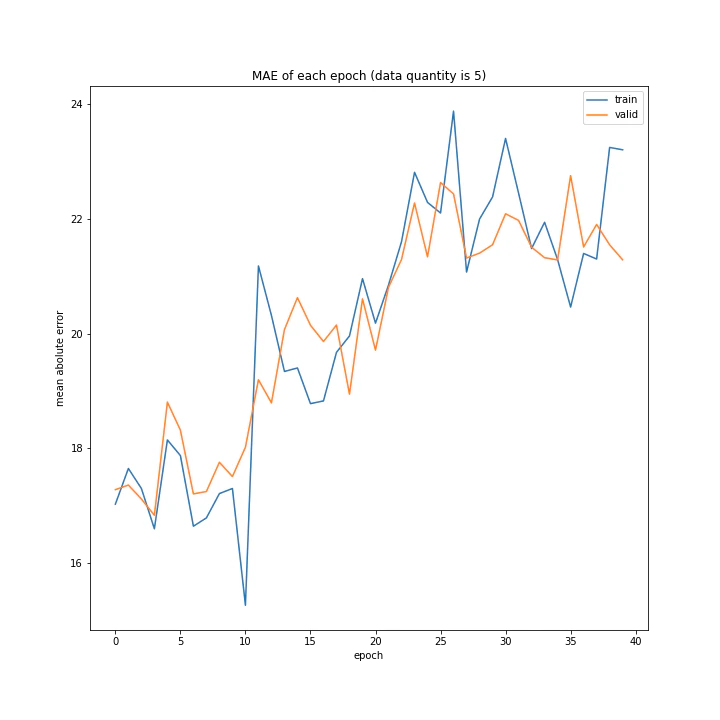
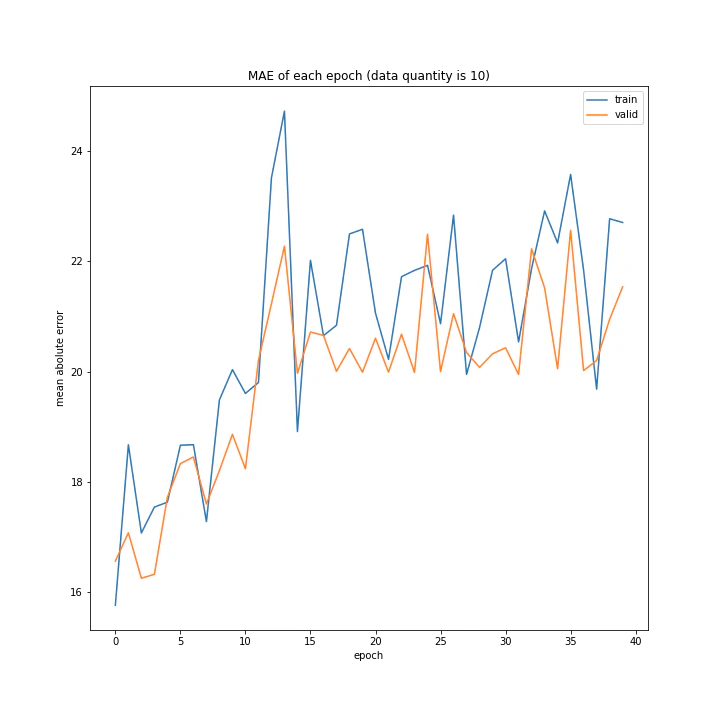
number: [1, 5, 10]
MSE: [variable(318.2084), variable(184.82645), variable(302.7841)]
MAE: [variable(11.776607), variable(9.148406), variable(12.213117)]
四層の時と同様、1の時しか学習しませんでした。
バッチサイズ
バッチサイズを変えながら調べました。
またこれ以降のプログラムはほとんどデータ量の時と変わらないので省略し実行結果のみ載せます。
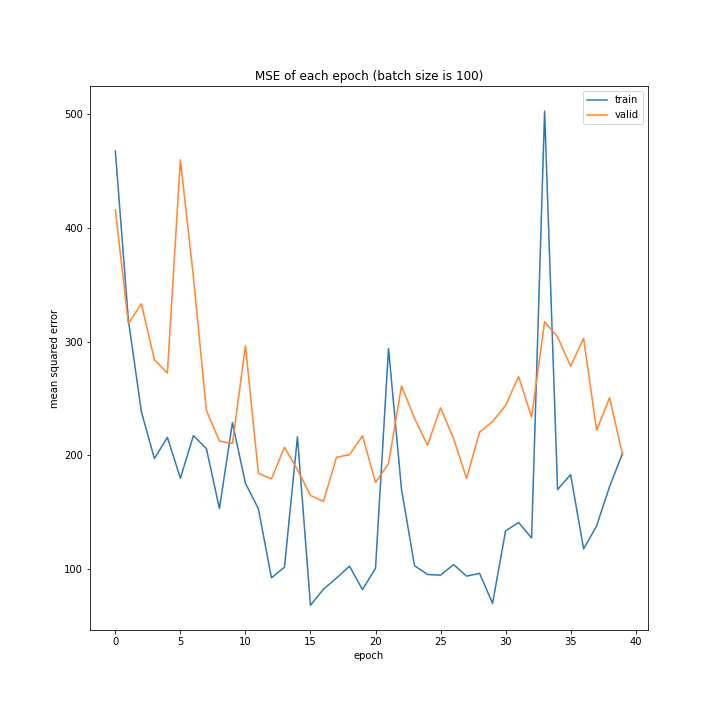
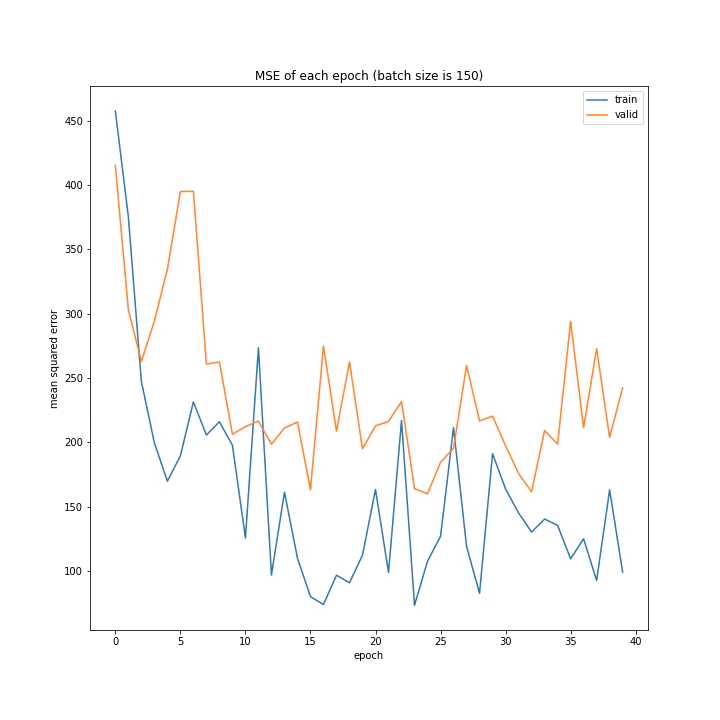
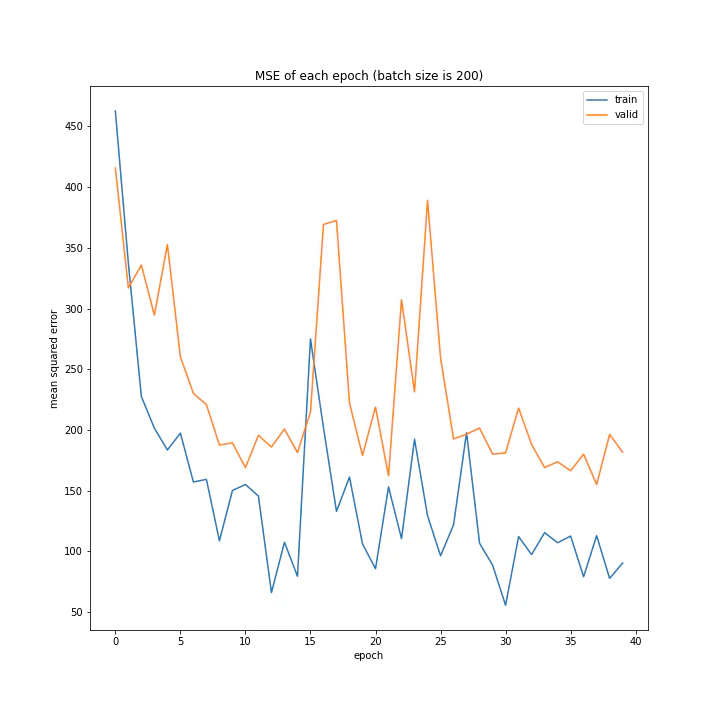
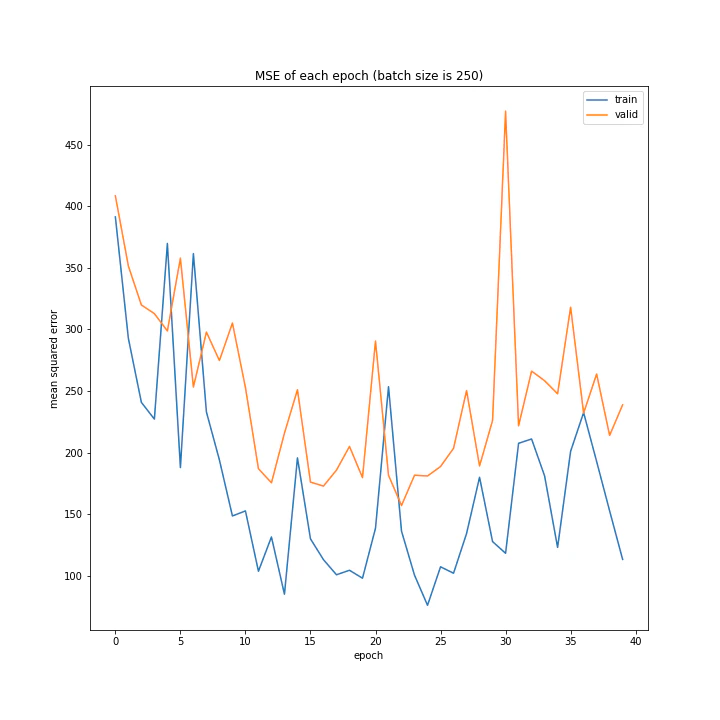
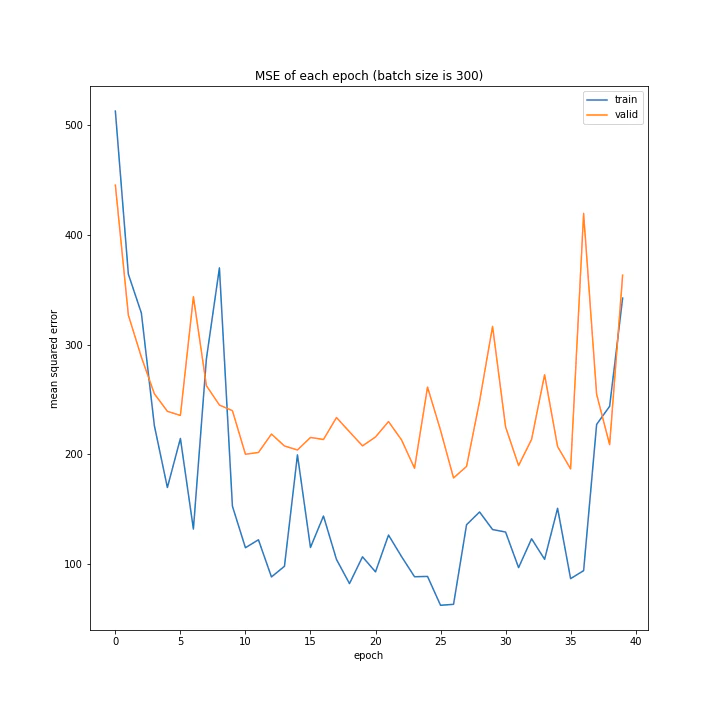

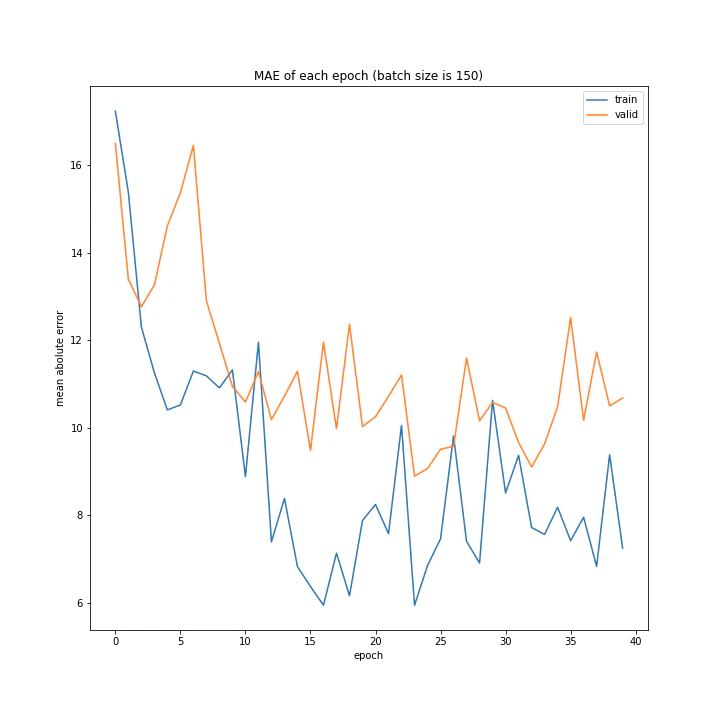
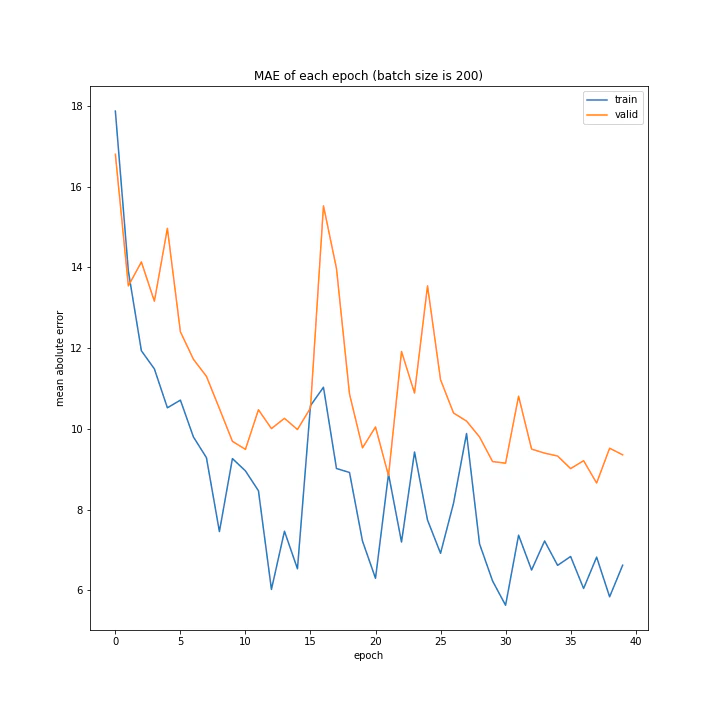
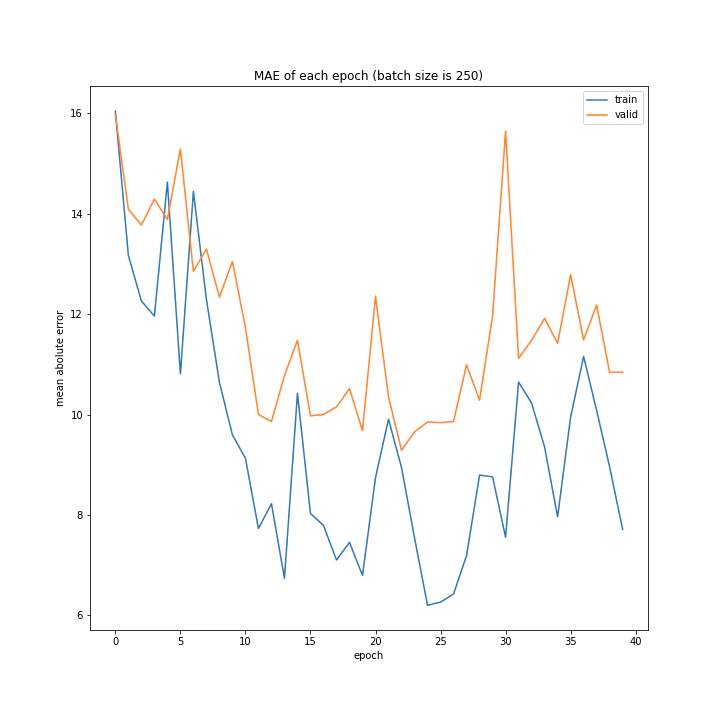
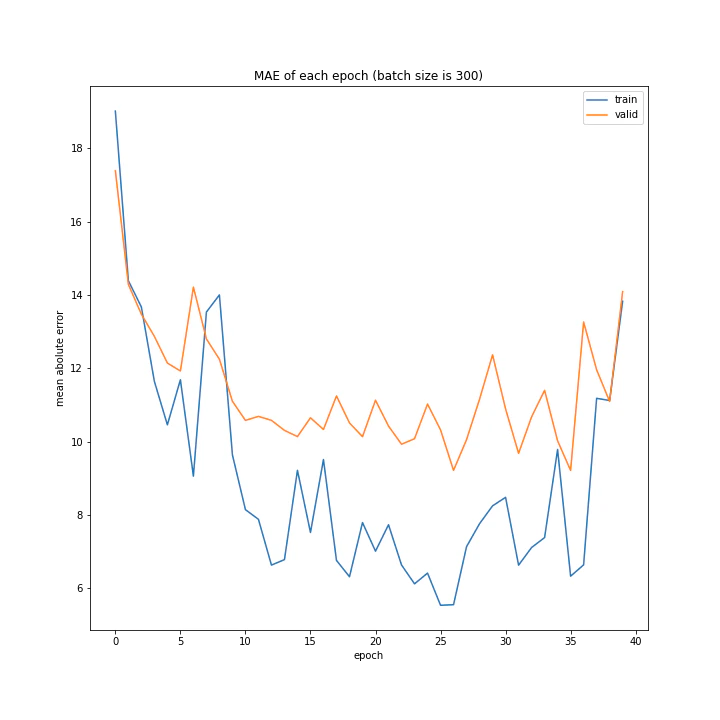
batch size: [100, 150, 200, 250, 300]
MSE: [variable(208.28833), variable(237.04642), variable(208.90796), variable(231.01593), variable(377.63495)]
MAE: [variable(10.089901), variable(10.971919), variable(9.383556), variable(10.808541), variable(14.816)]
グラフを見ると、きれいに学習できているのは150から250の間くらいですね。
最終結果もその付近が最小ごさとなっています。
活性化関数の乗数
活性化関数の種類については、上述のとおりtanh一択という状態なので実験しません。
tanhにかける乗数を変更しながら学習させてみました。
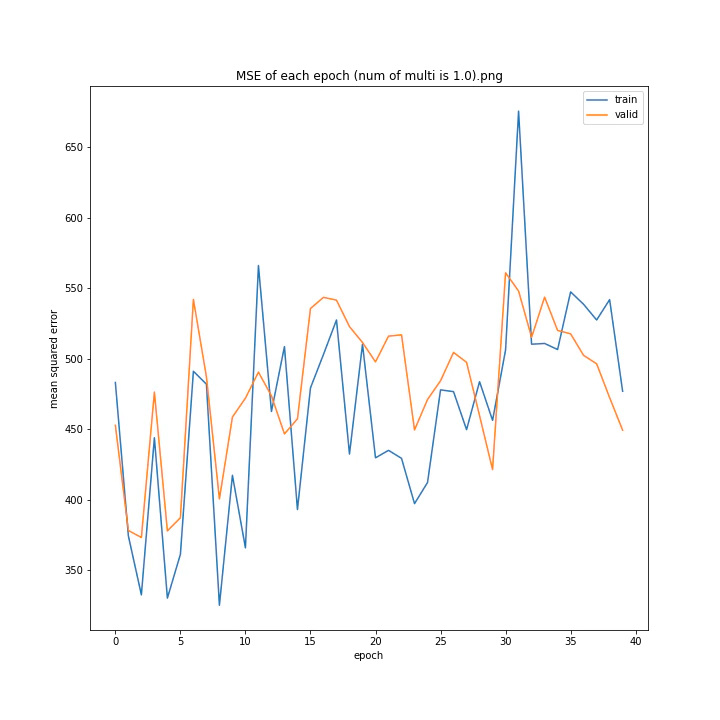
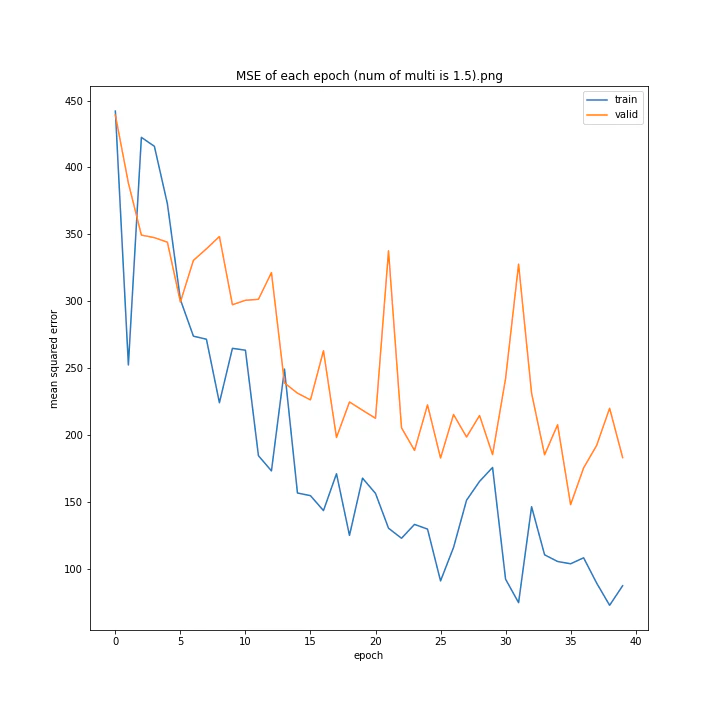
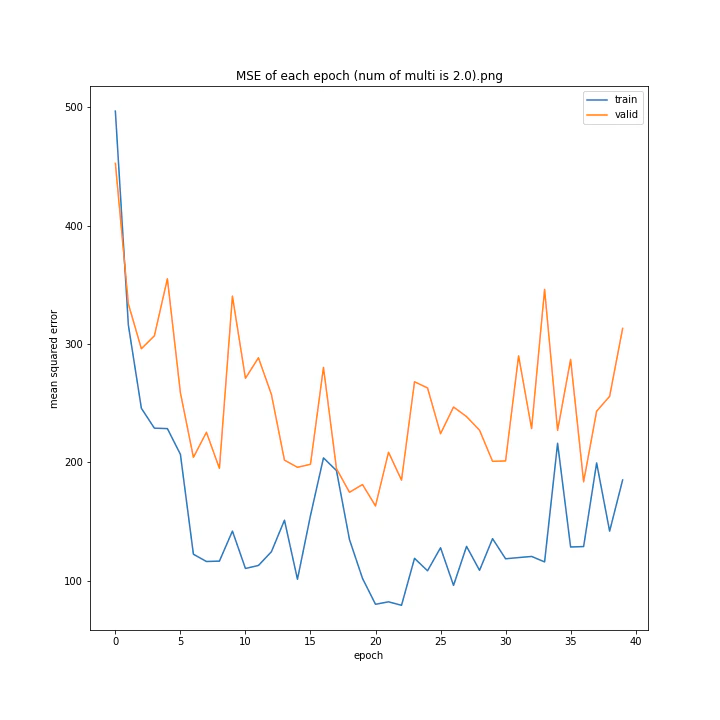
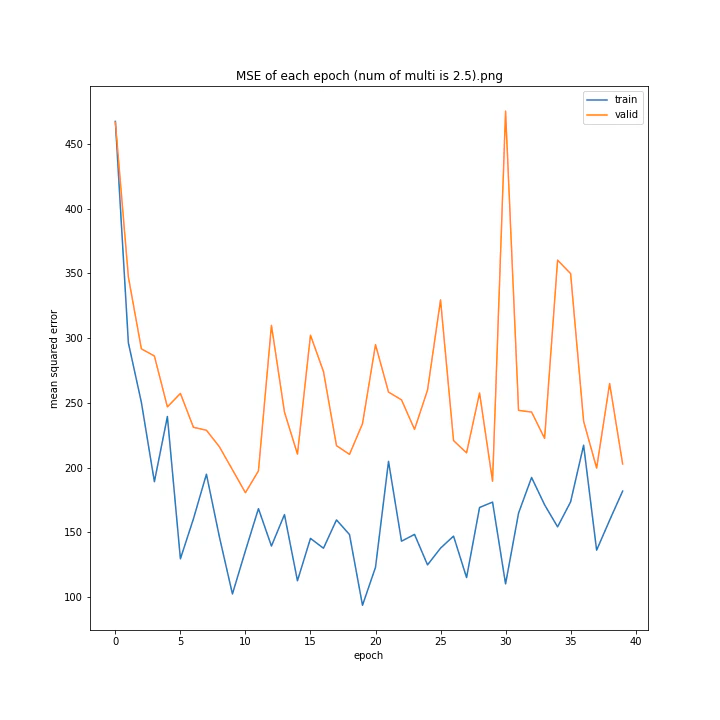
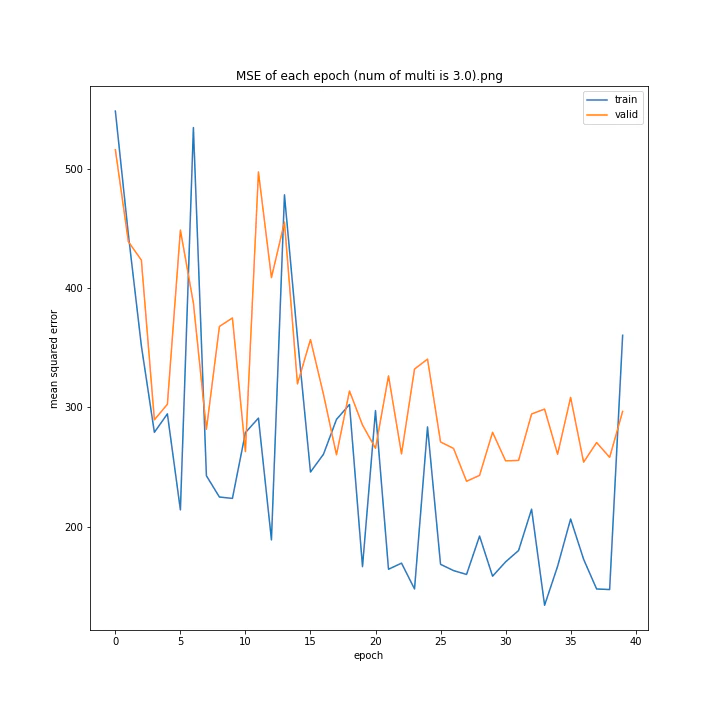
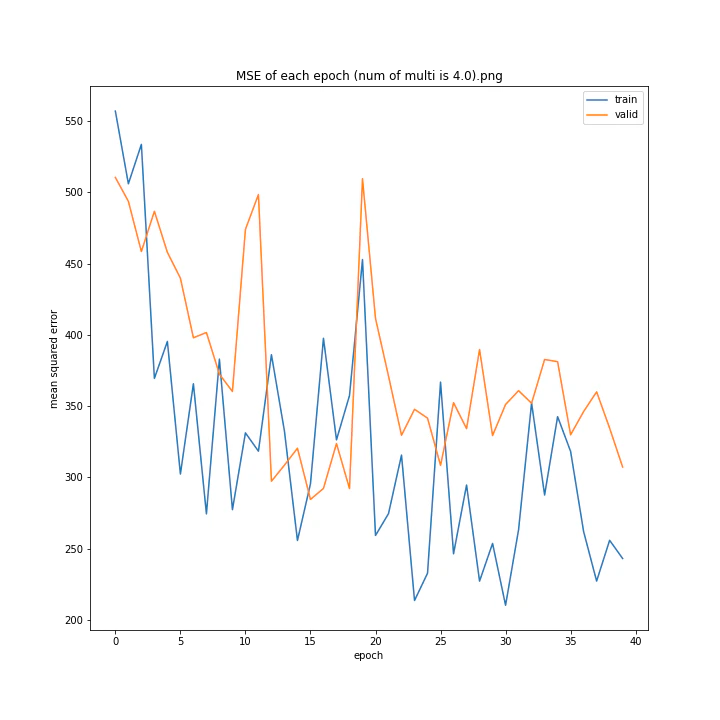
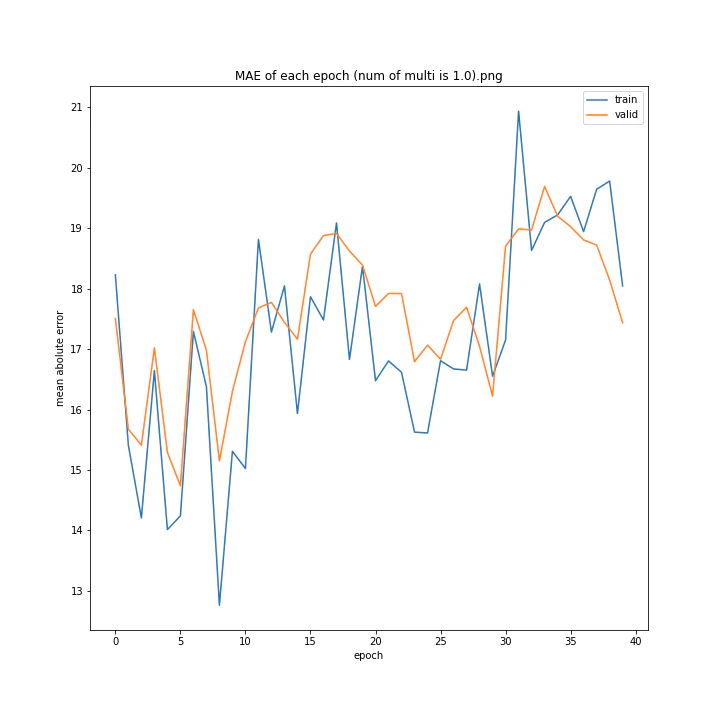
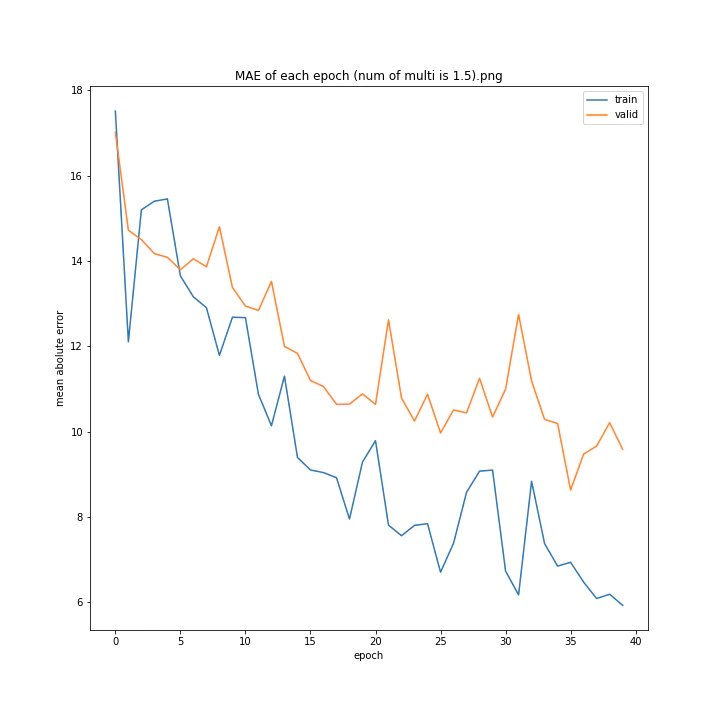
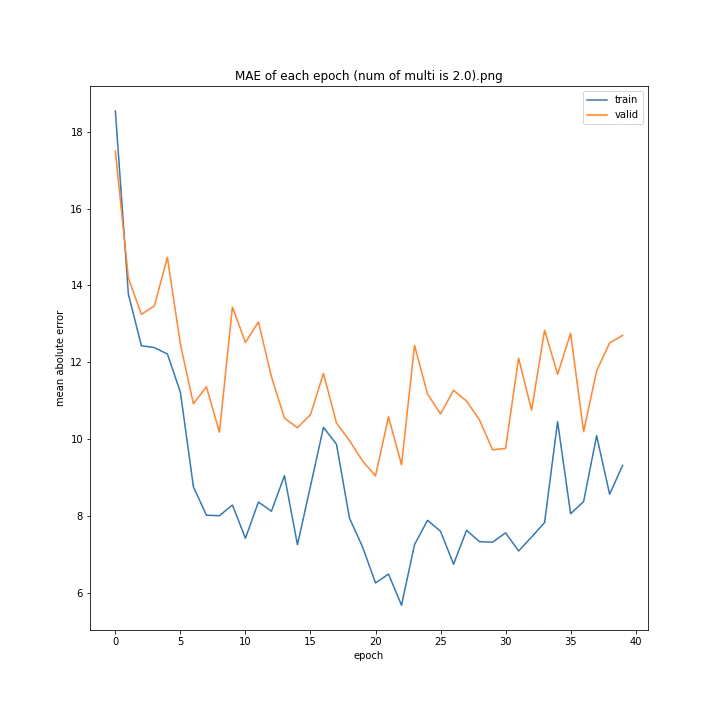
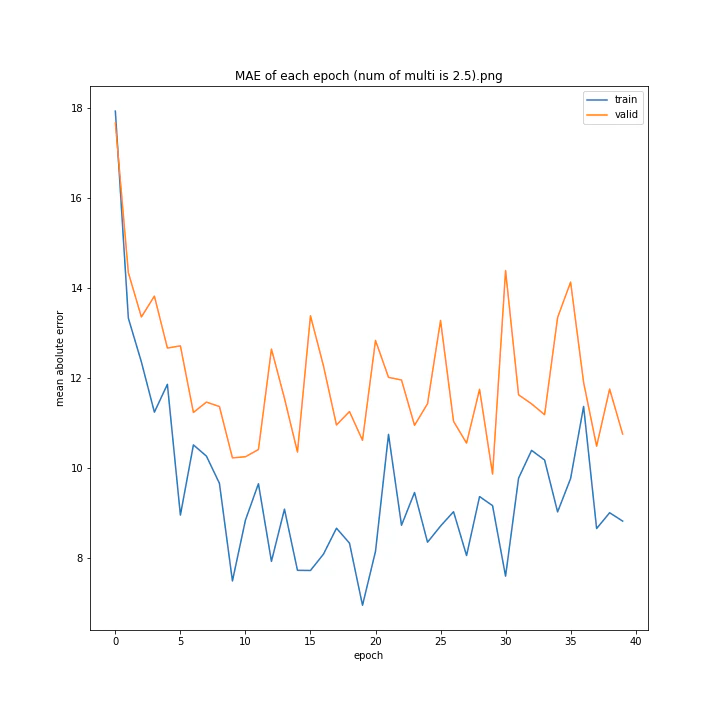
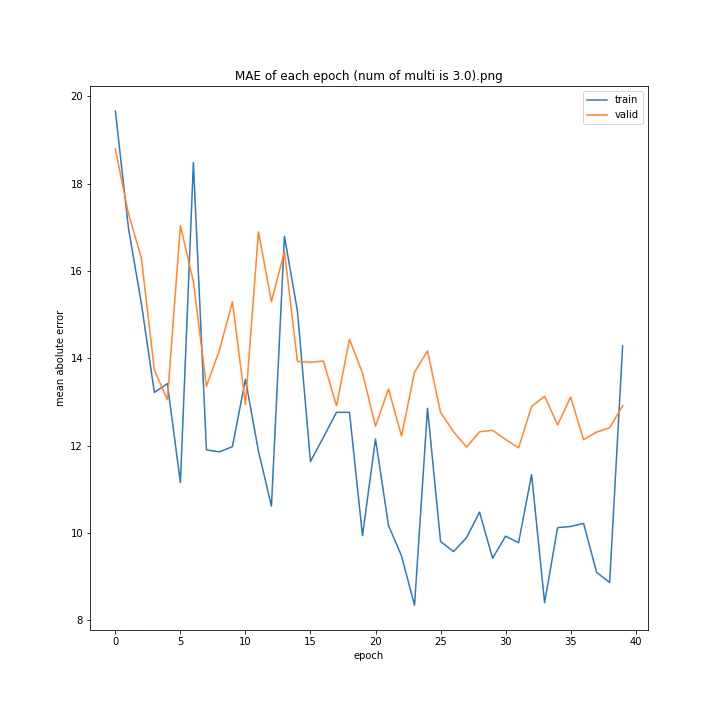
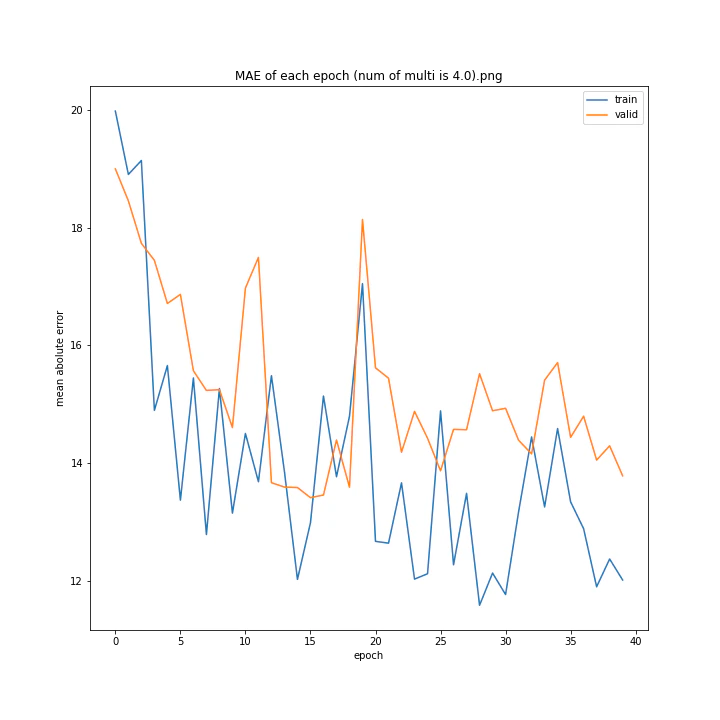
num of multi: [1, 1.5, 2, 2.5, 3, 4]
MSE: [variable(493.82068), variable(229.75685), variable(335.4347), variable(222.12787), variable(299.72604), variable(299.94046)]
MAE: [variable(18.411568), variable(10.173277), variable(13.183862), variable(10.945747), variable(12.994248), variable(13.425252)]
1は当然のように学習しませんでした。しかし値が大きすぎても発散するようです。
ここでは1.5が最小誤差でした。
最適化関数
最適化関数について、四層の時も用いた関数たちをもう一度集め検証しました。
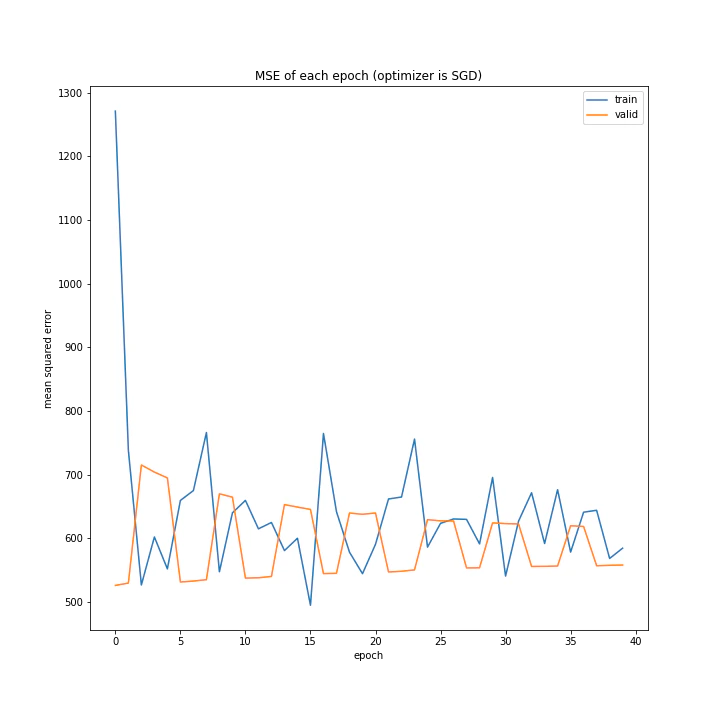
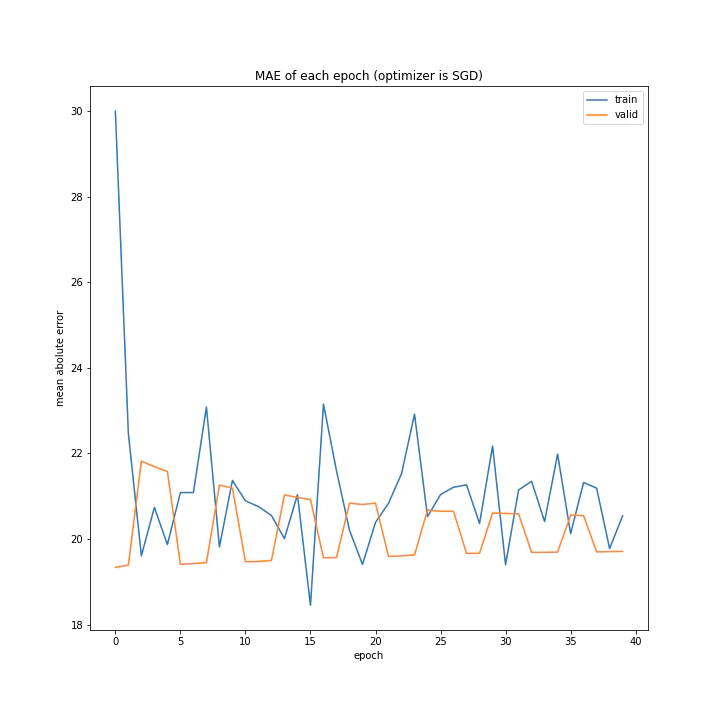
グラフ数が非常に多いので、一つずつ見ていきます。
まずSGDですが全く学習していませんでした。
確認データでの誤差が周期的に変動しているのが気になります。
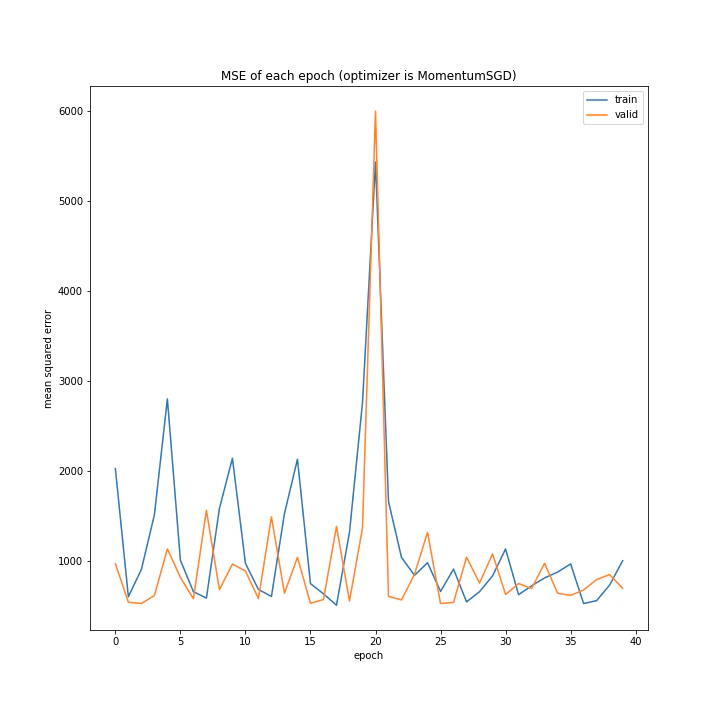

次にMomentumSGDですが、こちらも同様に学習していません。
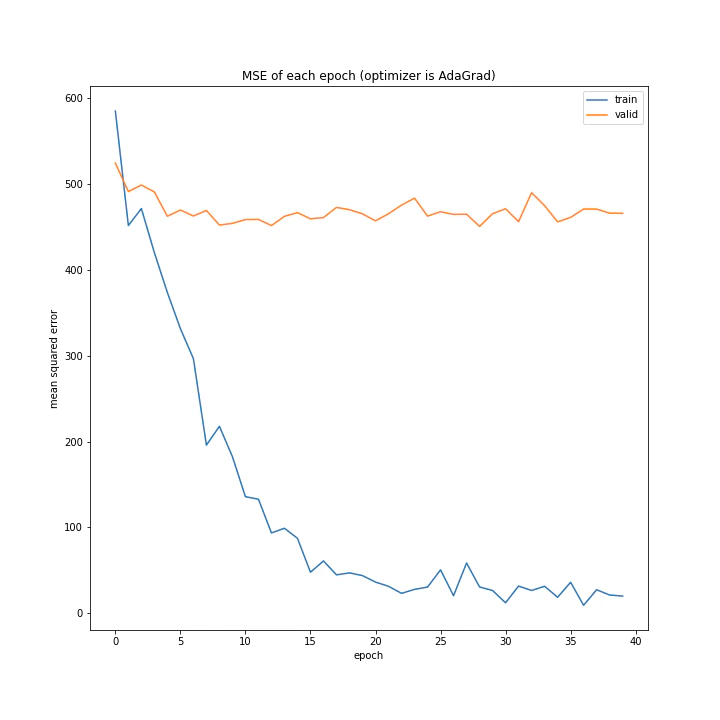
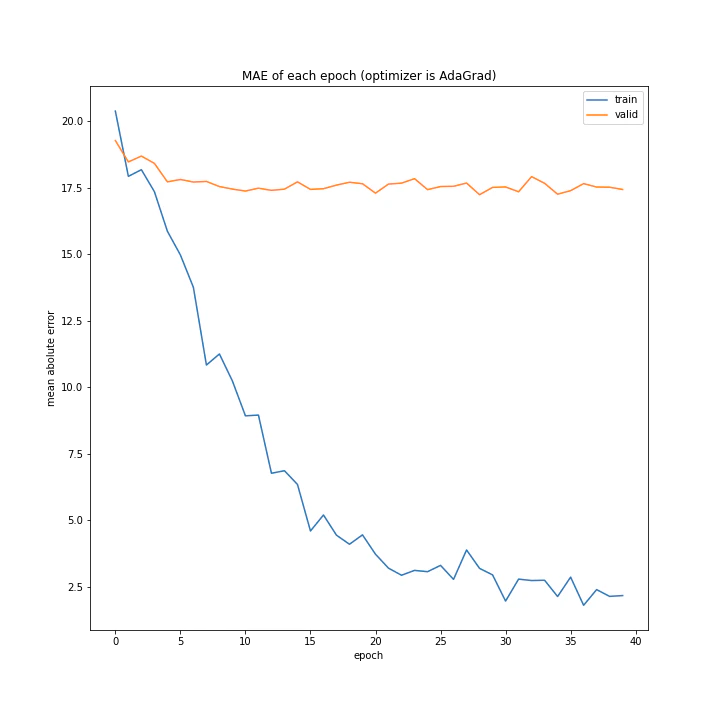
AdaGradは過学習を起こしました。
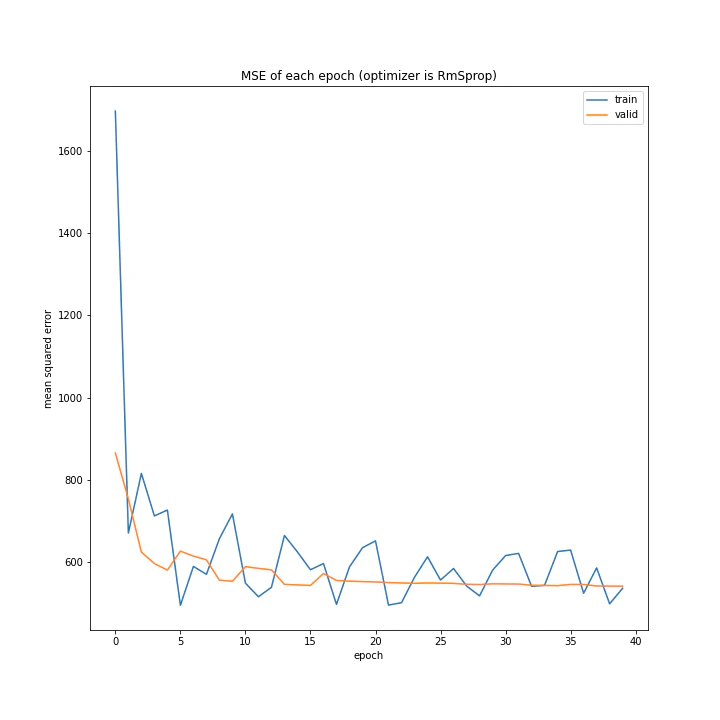
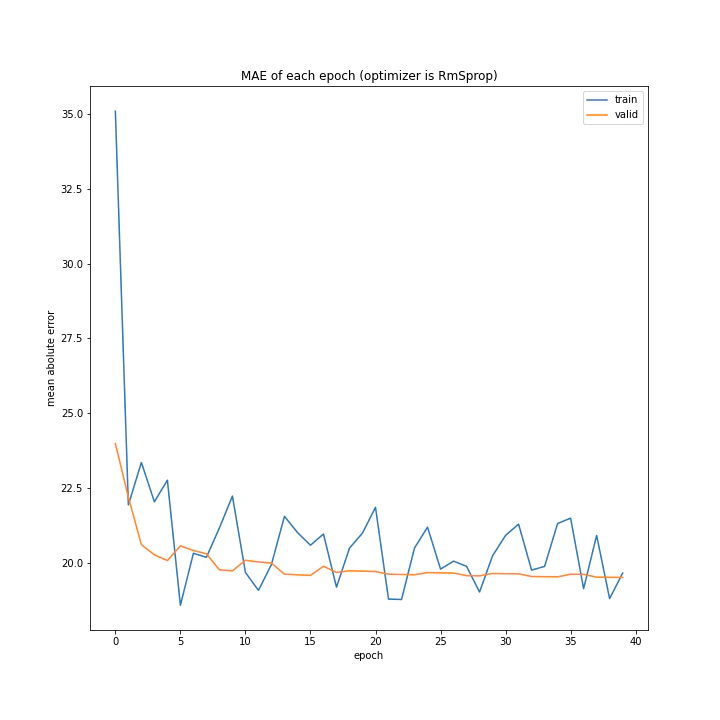
RMSpropはSGDと似たようなグラフを作りましたが、SGDと異なり確認データでの誤差はほとんど変動していません。
このことからパラメータ更新すらほぼ行われていないのではないかと考えました。
しかし理論上では、RMSpropはAdaGradに比べパラメータが更新されやすくなっているはずです。そのAdaGradが過学習を引き起こすほどにパラメータ更新され、RMSpropは変動なしというのは考えにくいと思うのですが・・・。
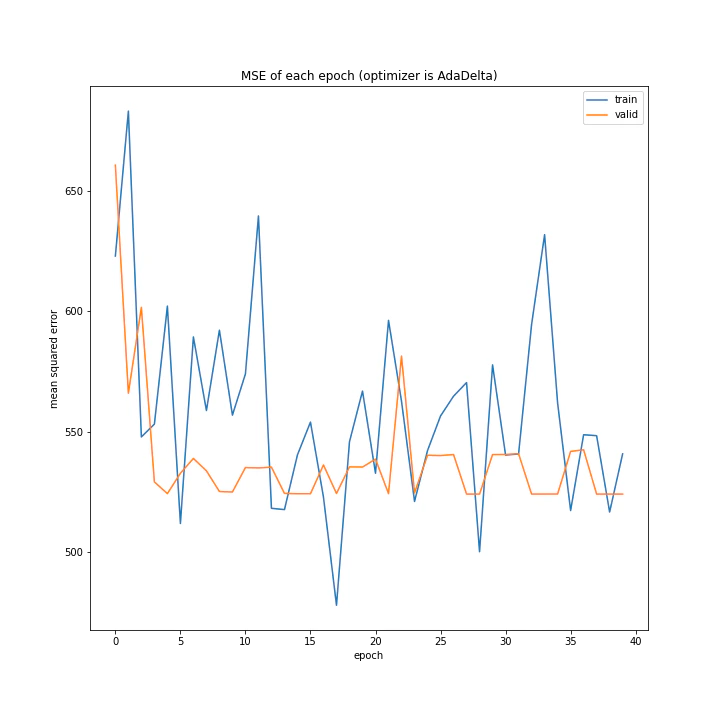
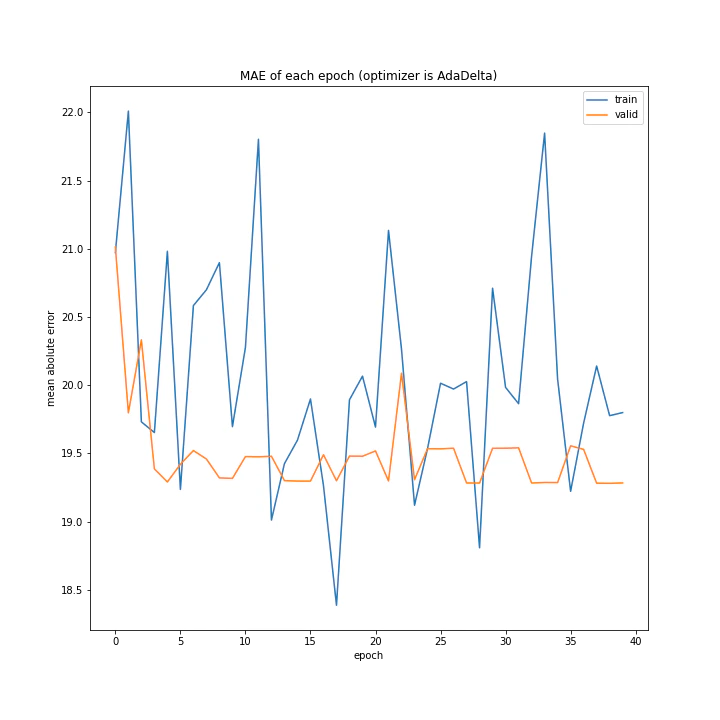
AdaDeltaもあまり学習していませんでした。しかし、確認データでの誤差推移がトレーニングデータでのそれよりはるかに穏やかである特徴がRmSprop以上に顕著であるように見えます。
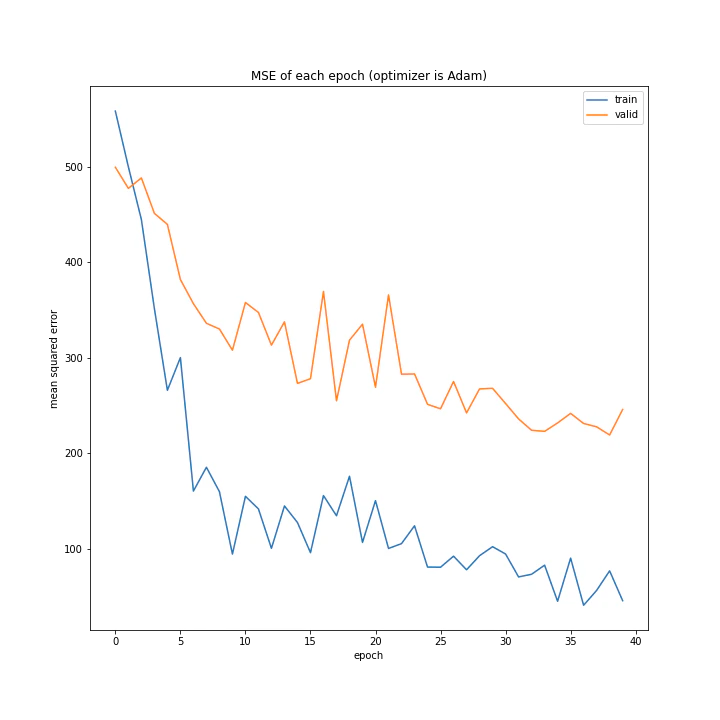
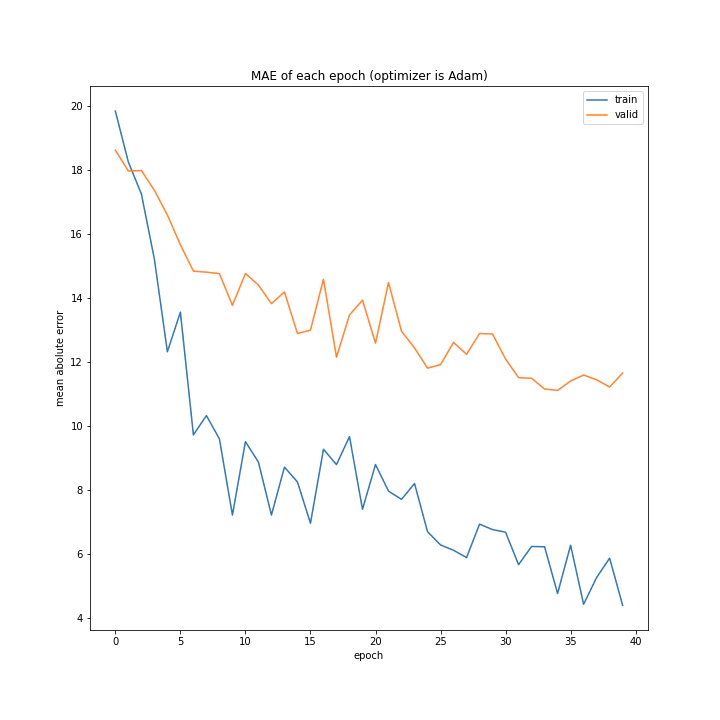
Adamこれまでの関数に比べるとまっとうに学習しているように見えます。
しかし最終的な精度はあまり高くないですね。
RMSpropは全く学習していなかったのに対し、Adamがある程度学習できているのは不思議です。
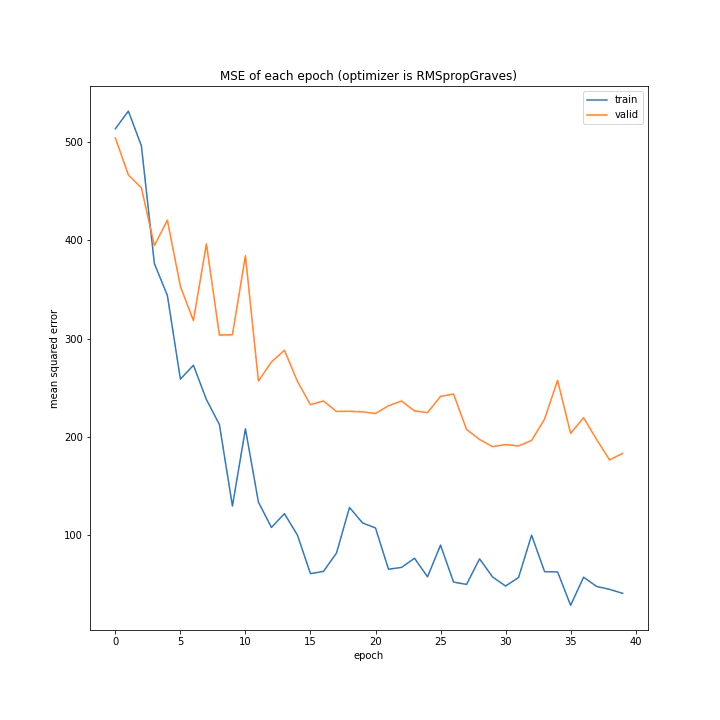
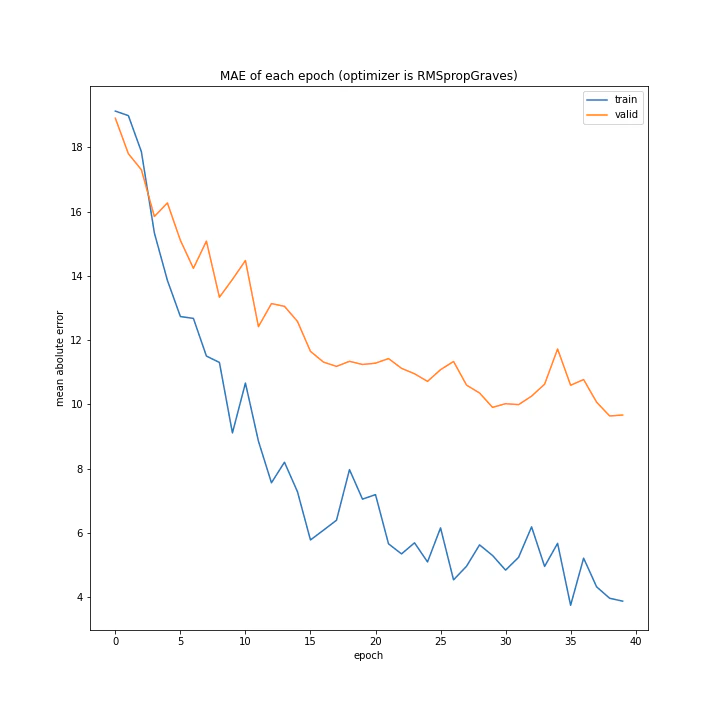
RMSpropGravesもAdamと同様、学習できています。
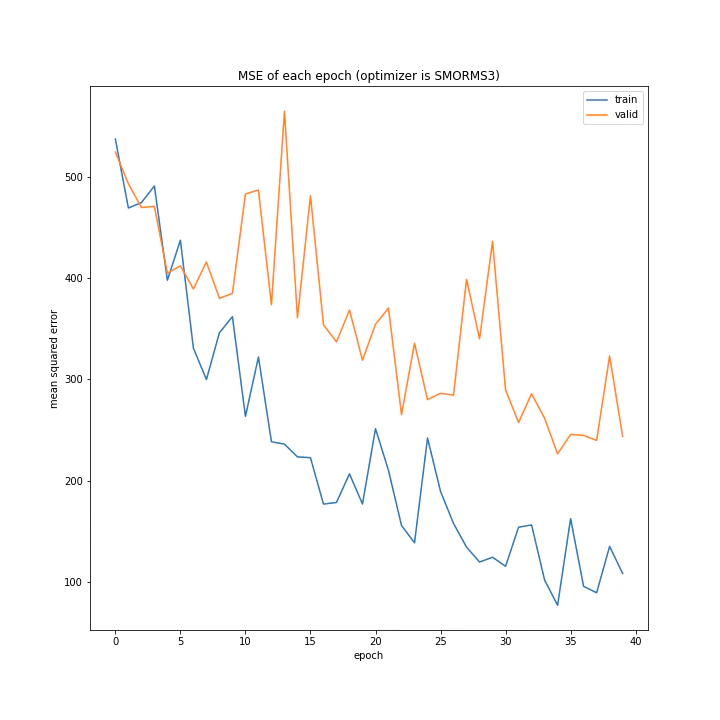
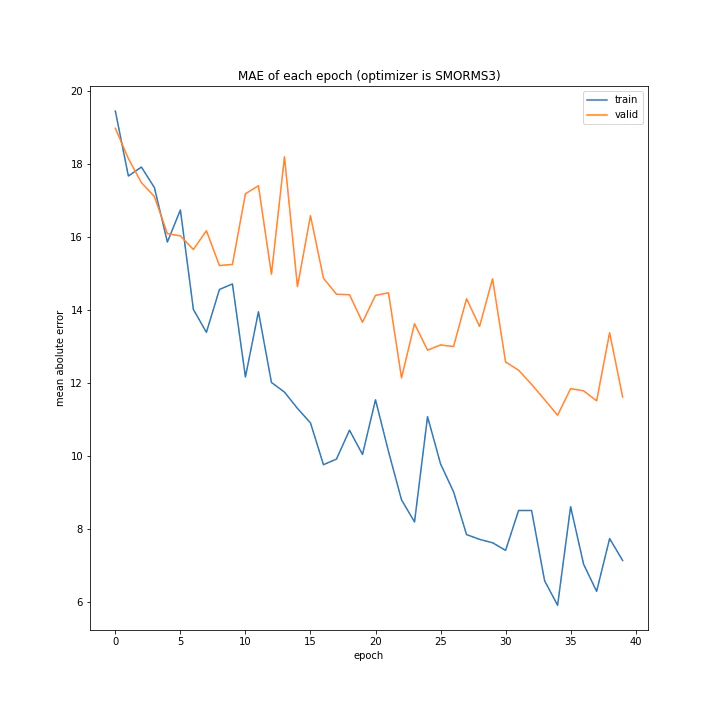
SMORMS3も学習できていますが、収束まで時間がかかっています。
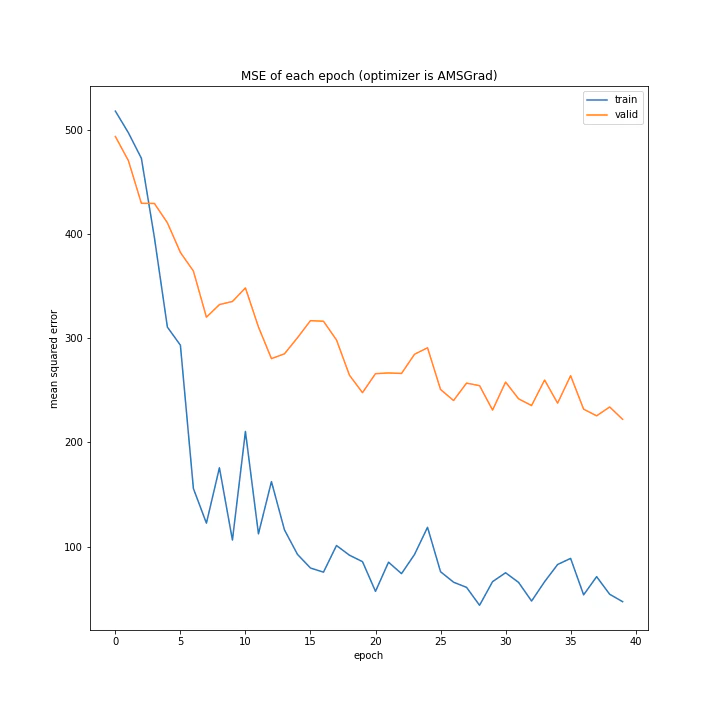
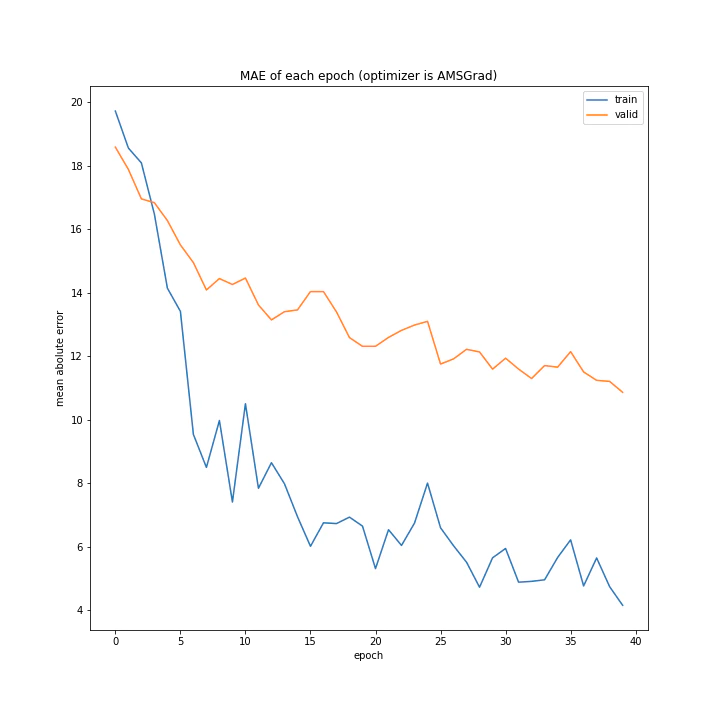
AMSGradはきれいに学習できていますが、Adam同様最終的な精度はいまいちです。
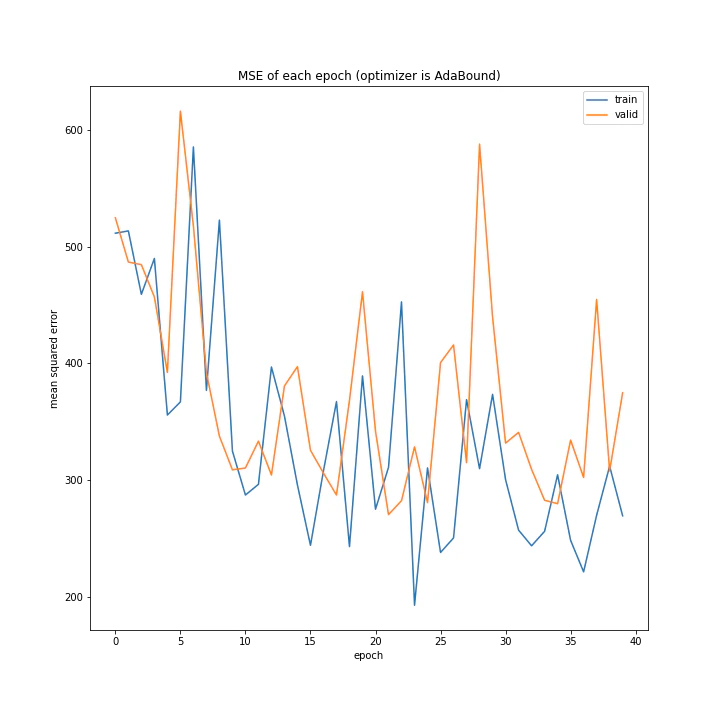
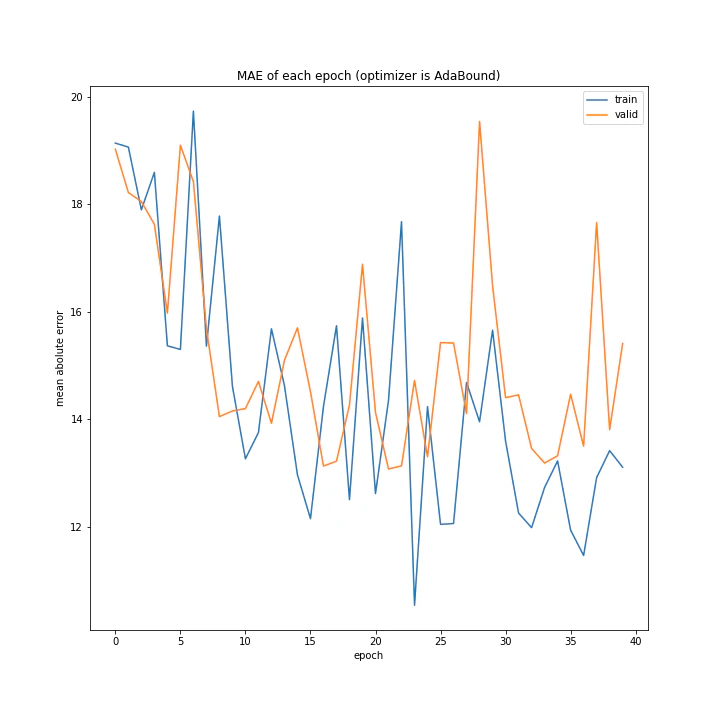
AdaBoundは最初の段階よりやや誤差が小さくなっているので一応学習はしているようです。しかしその精度、学習の進み具合は上のいくつかの手法に比べ明らかに劣っています。
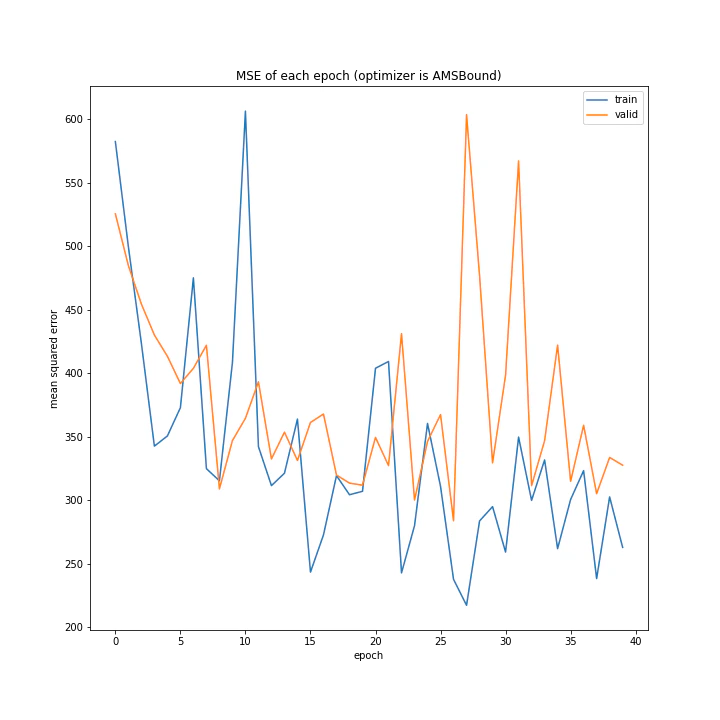
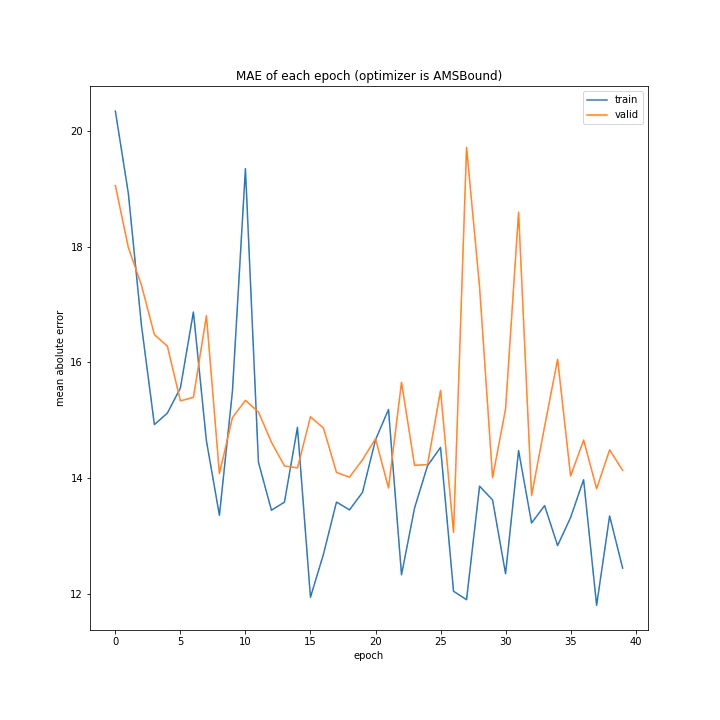
最後にAMSBoundです。こちらもAdaBoundと同様、一応学習はしているもののあまりいい方法ではなさそうです。
opt name: ['SGD', 'MomentumSGD', 'AdaGrad', 'RmSprop', 'AdaDelta', 'Adam', 'RMSpropGraves', 'SMORMS3', 'AMSGrad', 'AdaBound', 'AMSBound']
MSE: [variable(596.67865), variable(748.88885), variable(481.1794), variable(581.58185), variable(567.9831), variable(257.87805), variable(183.6314), variable(225.72916), variable(242.25677), variable(317.26895), variable(299.14655)]
MAE: [variable(20.720228), variable(22.436901), variable(17.671604), variable(20.507269), variable(20.240658), variable(11.837251), variable(9.939592), variable(10.39656), variable(11.440739), variable(13.673), variable(13.514401)]
各最適化関数でのテストデータでの誤差です。
最小はRMSpropGravesでした。
bound
boundとは、GradientHardClippingに与える引数のことで、その絶対値を指定します。
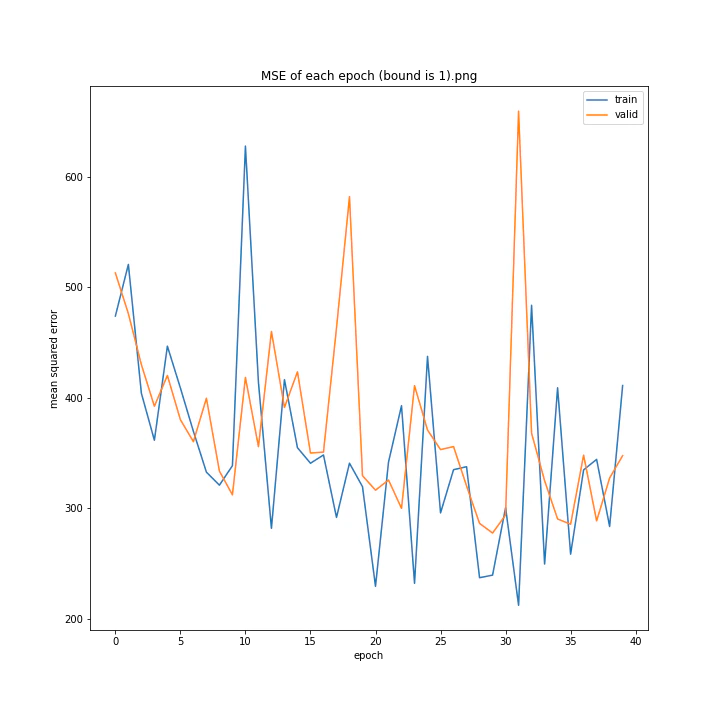
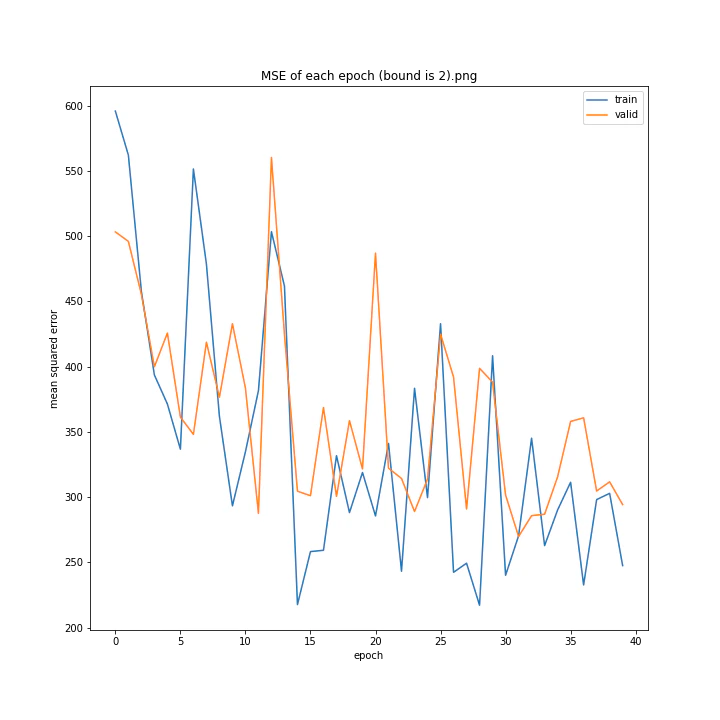
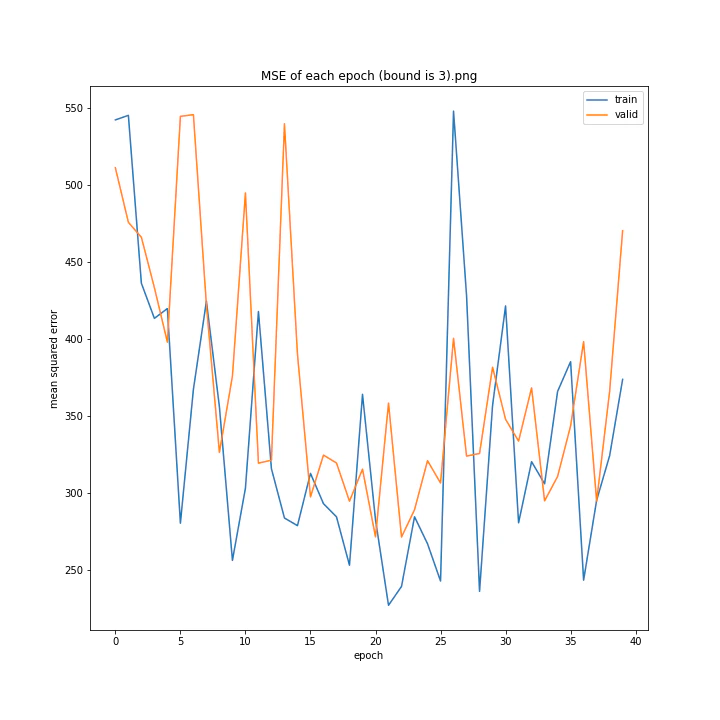
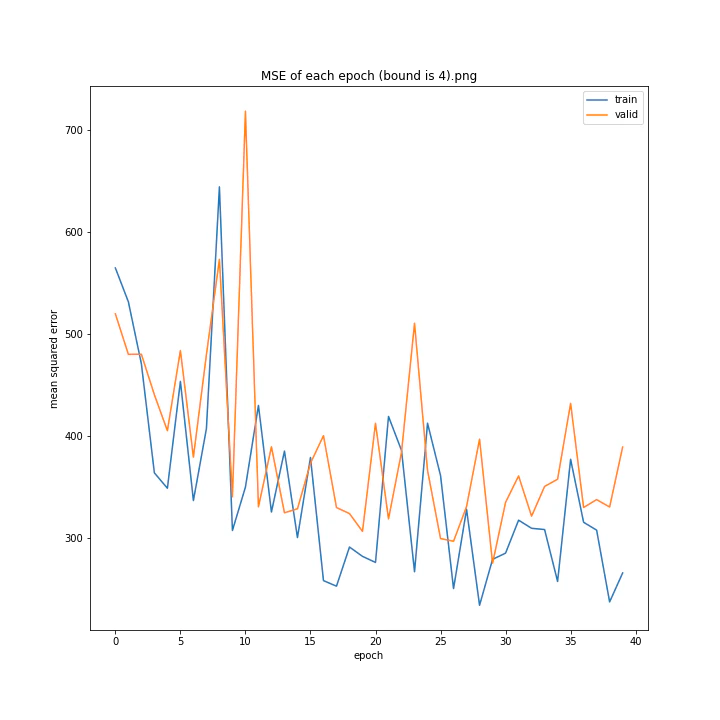
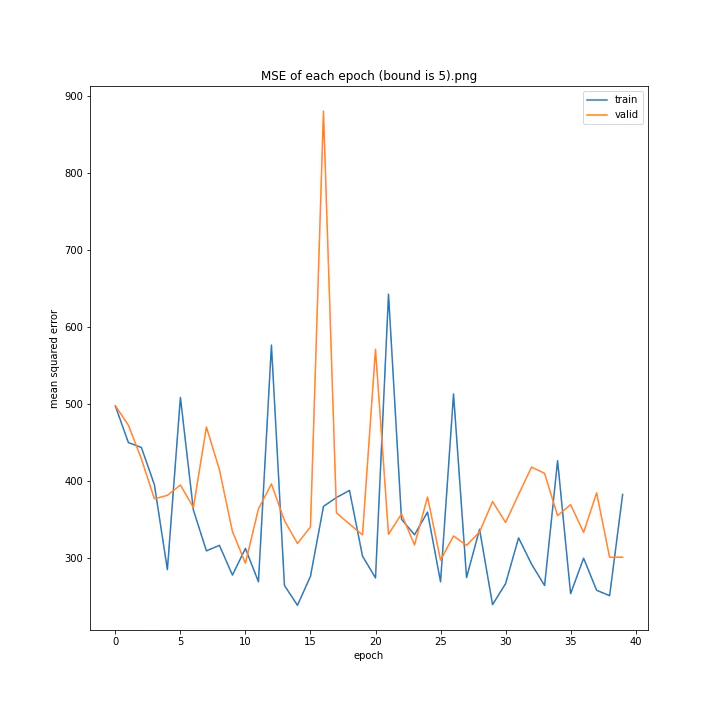
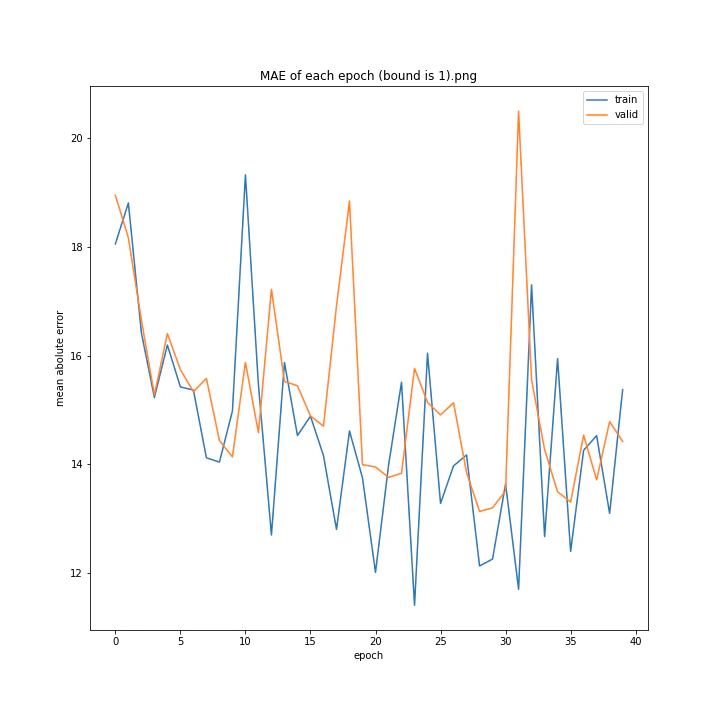
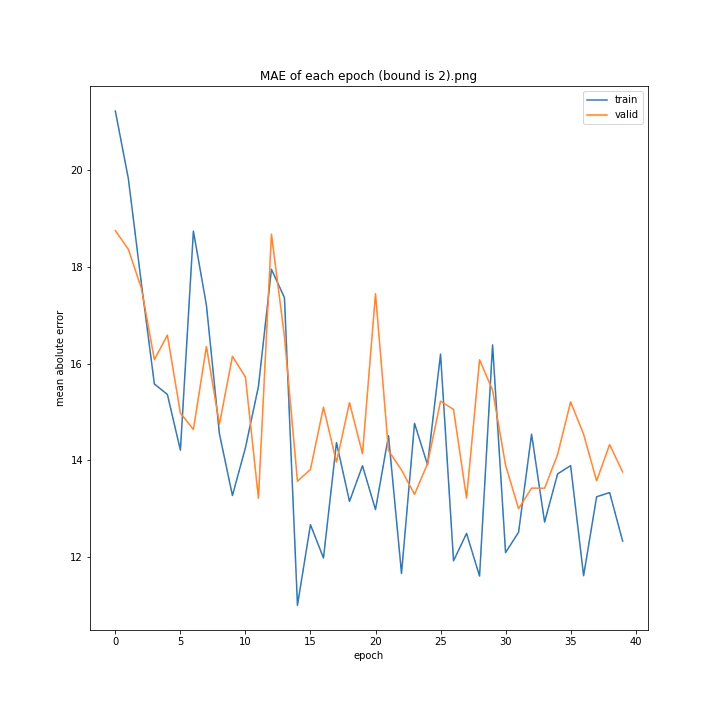

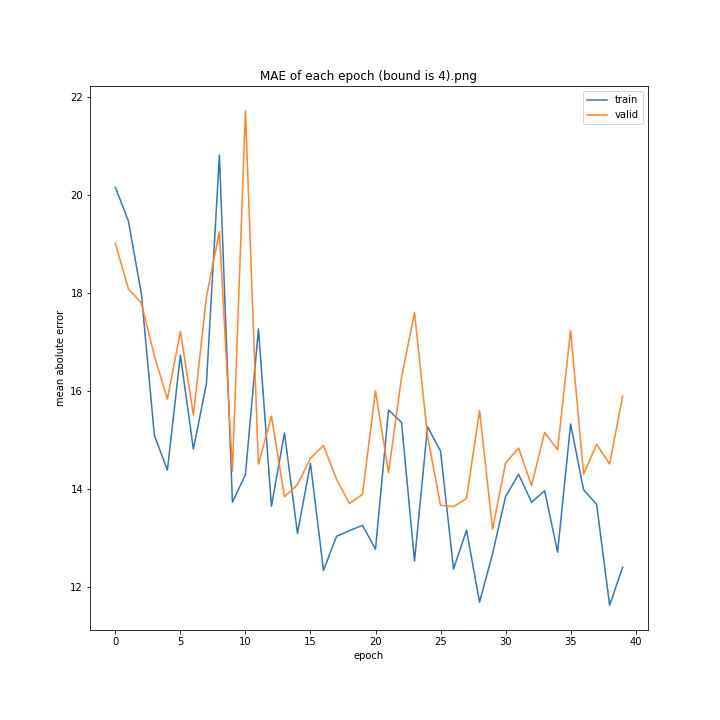
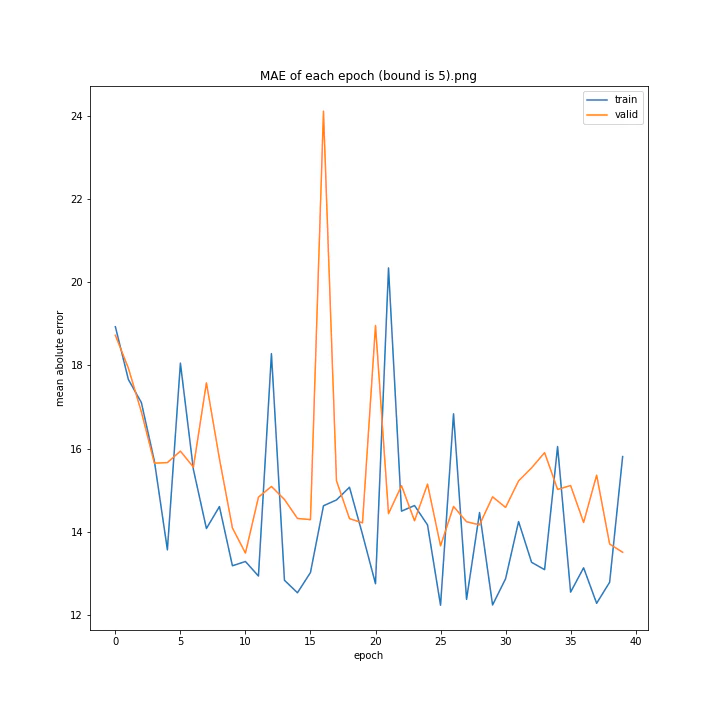
あまり学習していないように見えますが、4は比較的きれいなグラフになっています。
bound : [1, 2, 3, 4, 5]
MSE: [variable(373.4251), variable(277.93234), variable(436.827), variable(403.12445), variable(308.02844)]
MAE: [variable(14.932132), variable(13.277081), variable(16.416647), variable(16.157673), variable(13.493976)]
誤差はどれも非常に大きくなる結果となりました。
更新回数
エポック数を1000まで増やしてみました。
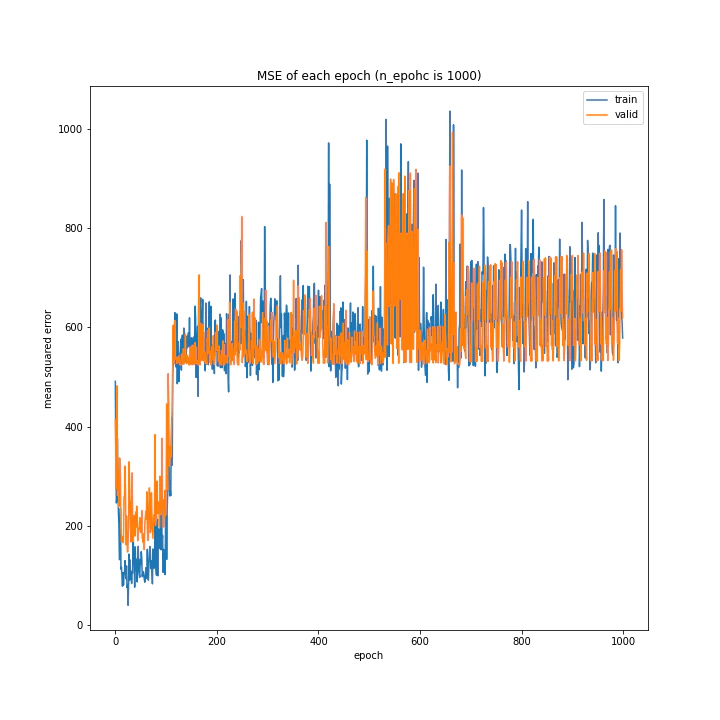
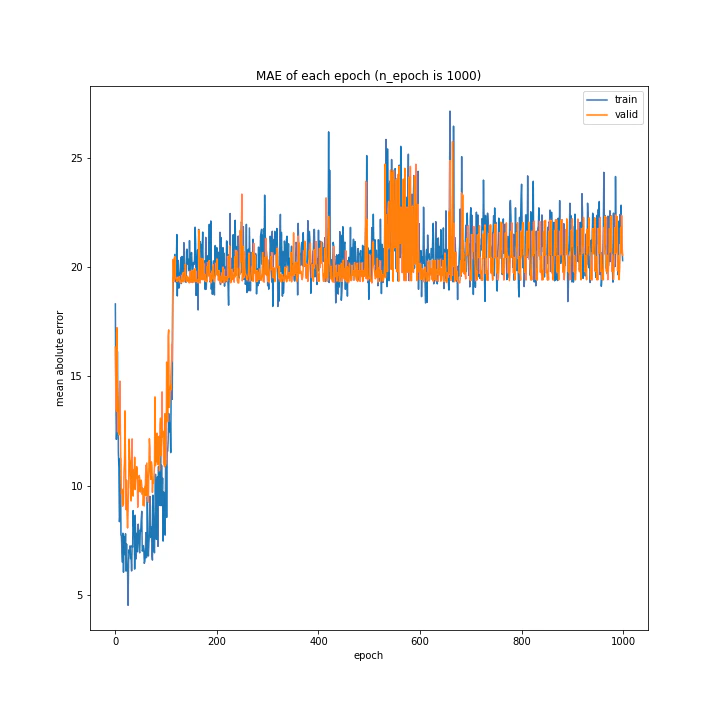
n_epoch: 1000
MSE: variable(671.48865)
MAE: variable(21.532646)
序盤は学習するものの、エポック数が100付近になったところから誤差が急増しそのまま減らなくなりました。これは四層の時とは全く異なる挙動です。
理由はわかりませんが、本番用のモデルはいいところで学習を止める必要性があるかもしれません。
調査ターン
データ集めの際、何ターンごとにデータを集めるかを変えながら調べてみました。
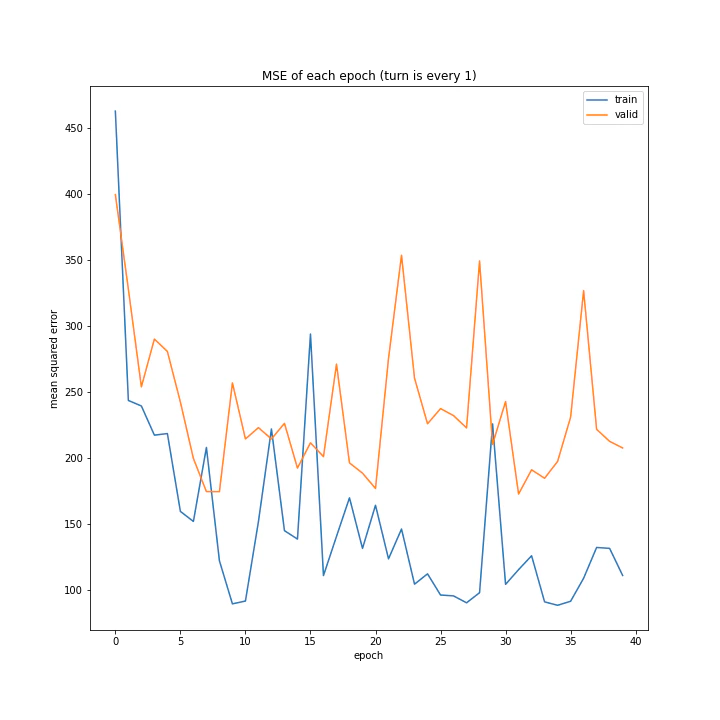
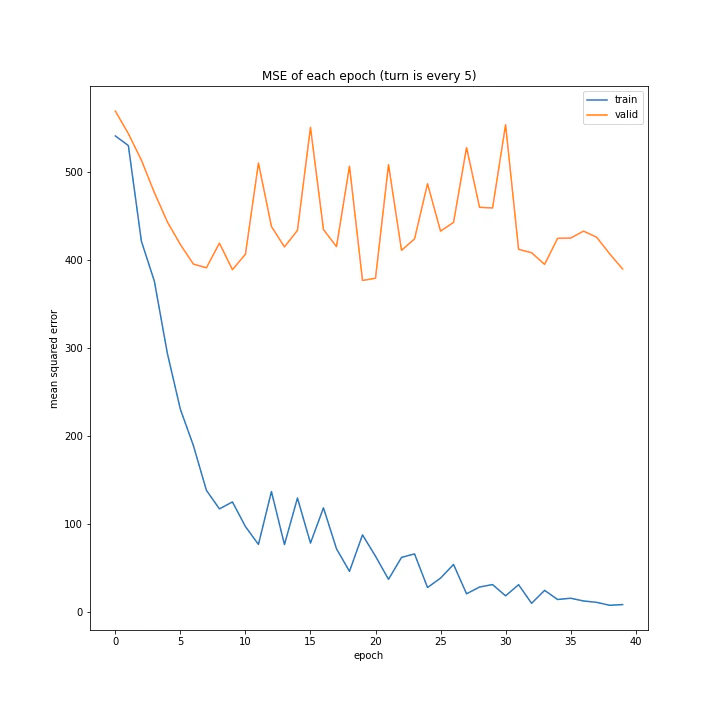



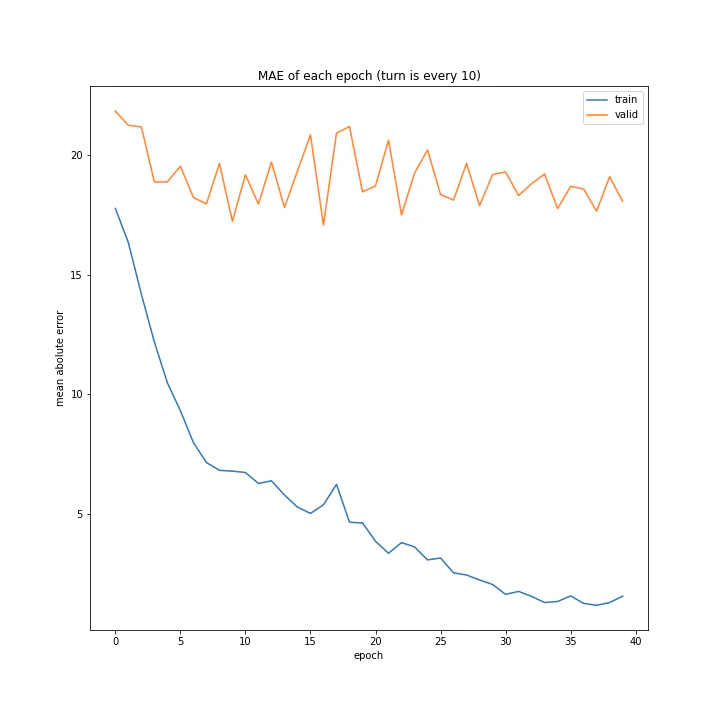
['every 1', 'every 5', 'every 10']
MSE: [variable(199.15181), variable(414.1164), variable(571.50305)]
MAE: [variable(9.791213), variable(15.582603), variable(17.601833)]
こちらは予想通り、より多くデータを集めたほうが過学習しにくい結果となりました。
重み減衰
重み減衰の手法を変えながら実験を行いました。
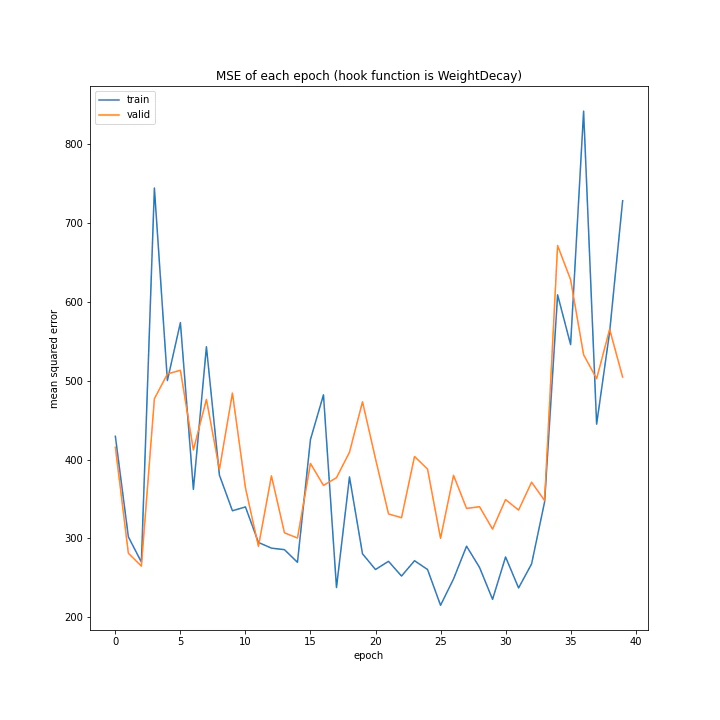
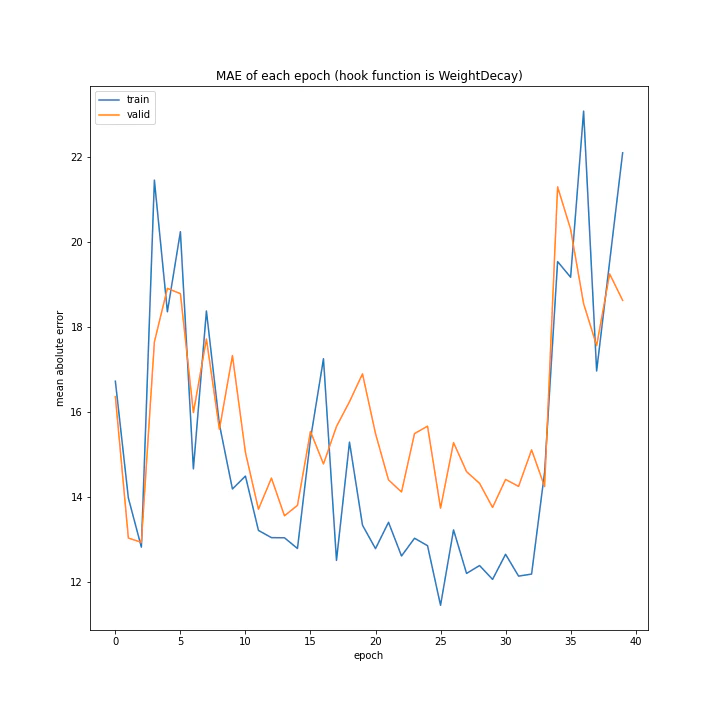
途中まで誤差が小さくなっているように見えるものの、35付近で大きくなっています。
また、誤差が小さくなっているというのもはっきりとそうであるとは言えないと思います。
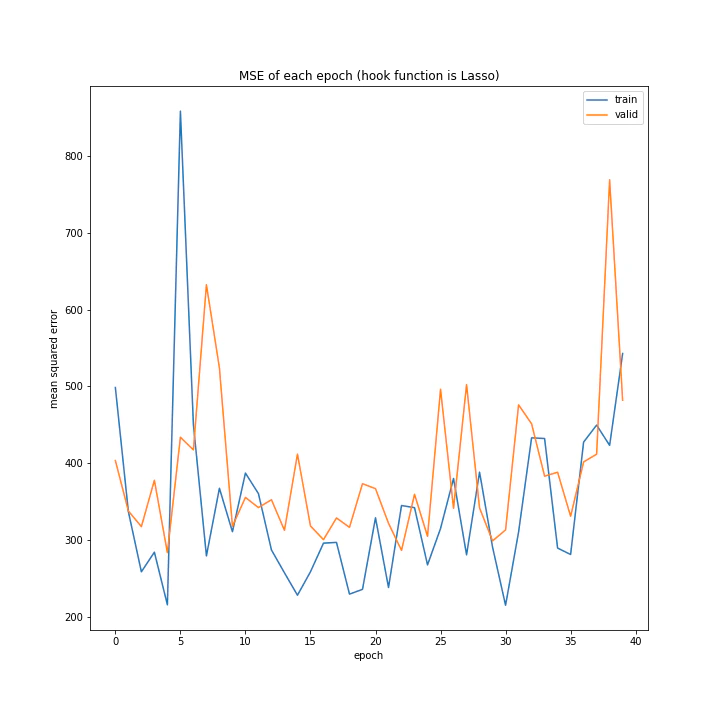
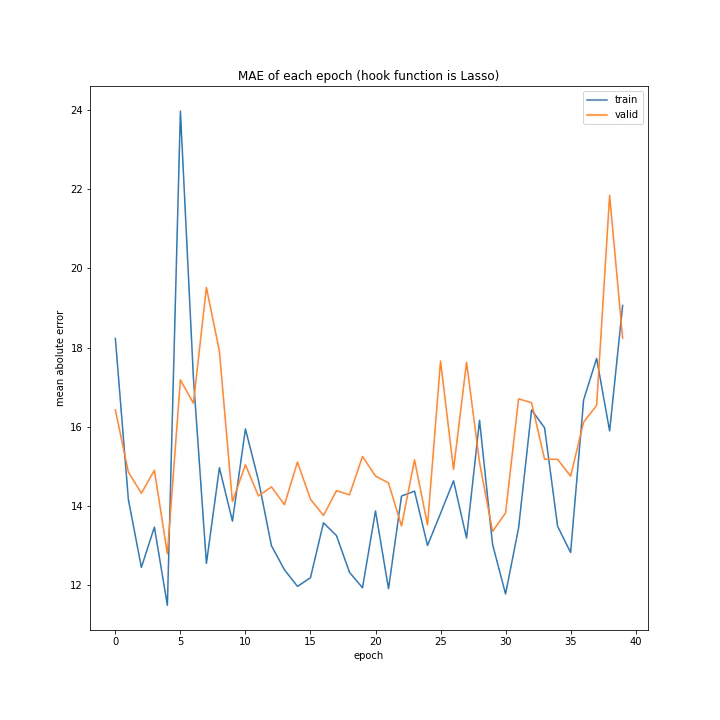
こちらはほぼ学習していないように見えます。
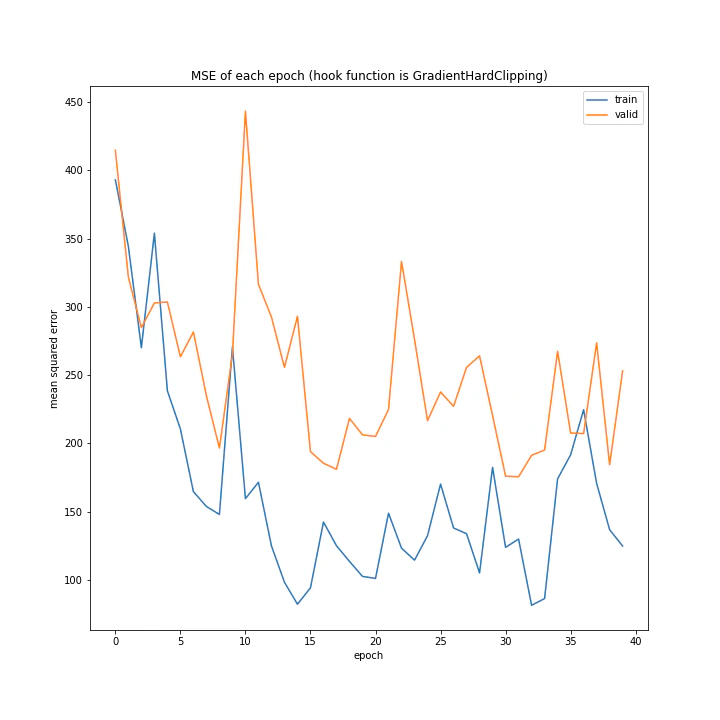
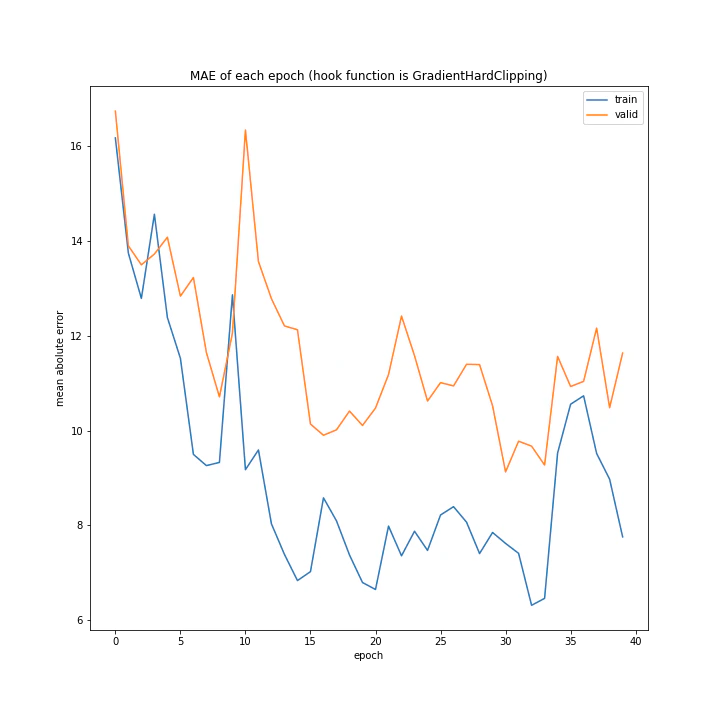
上二つと違い、きれいな形ではないものの学習はしているようです。
GradientHardClippingの基本概念は上二つと同じく重みを大きくしすぎないことですが、WeightDecayとLassoにはあまり効果が見られずこれだけがうまくいきました。
そのため、説明変数が多い状態で重み0を目指すのはあまりよくないのではと考えました。GradientHardClippingは重みの最大を制限はするものの、最小を目指すわけではありません。
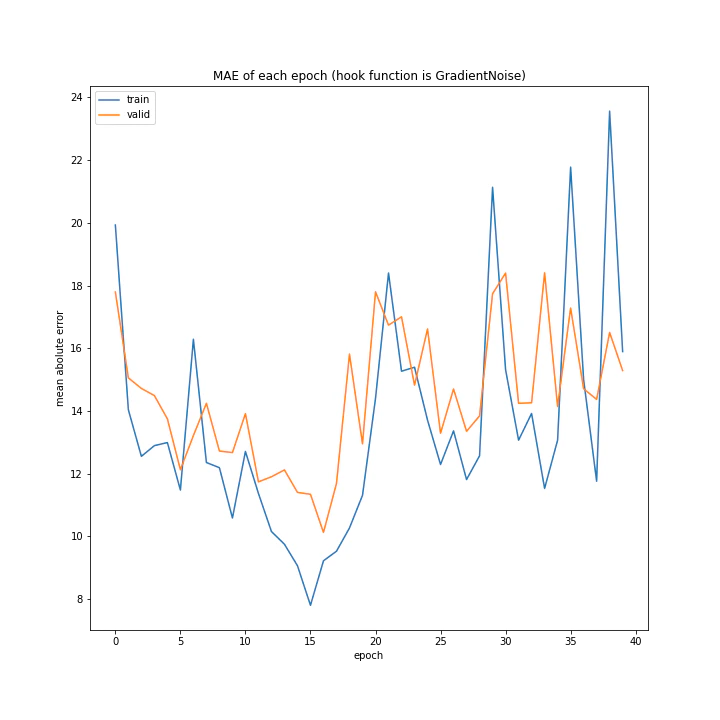
エポック数15までの部分のみを見ると順調に下がっているようにも見えなくない結果となりました。
誤差の最小記録だけを見れば悪くないですが、安定してこの精度が出るかどうかはわかりません。
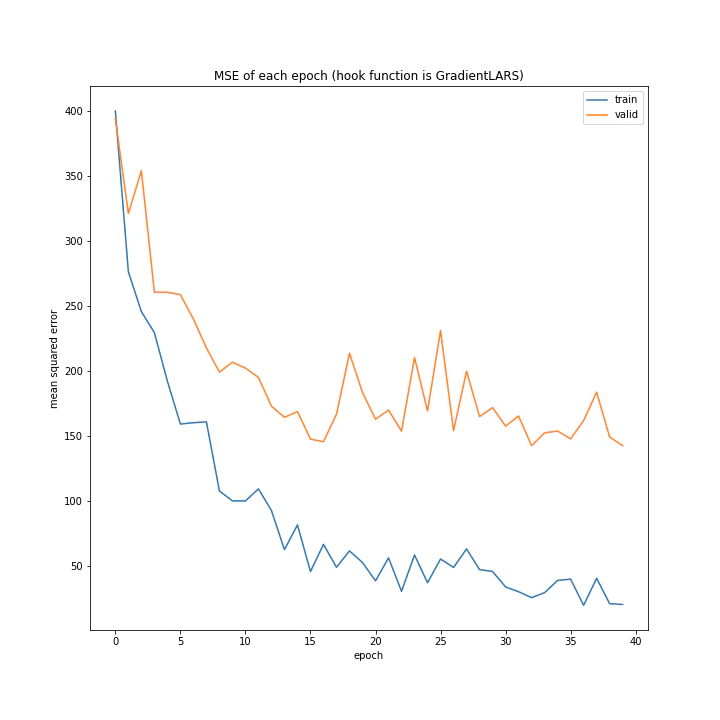
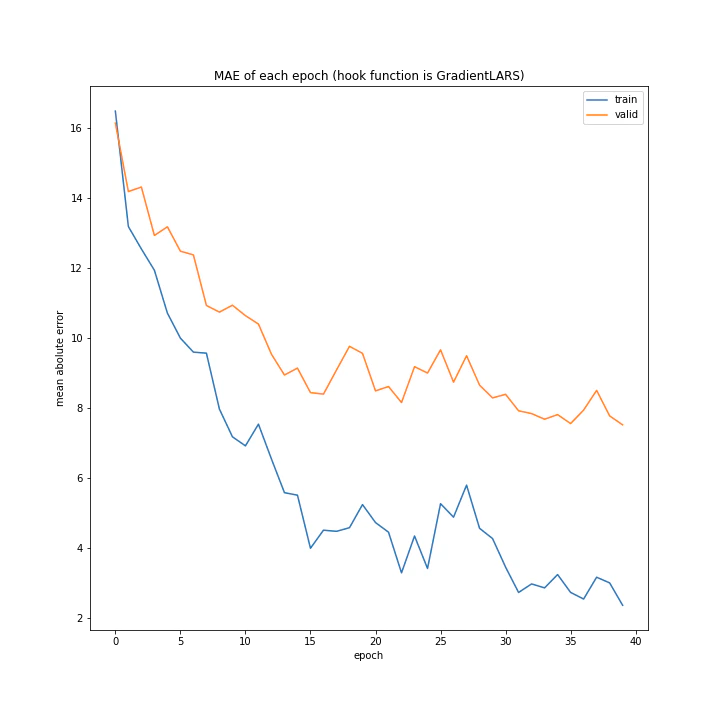
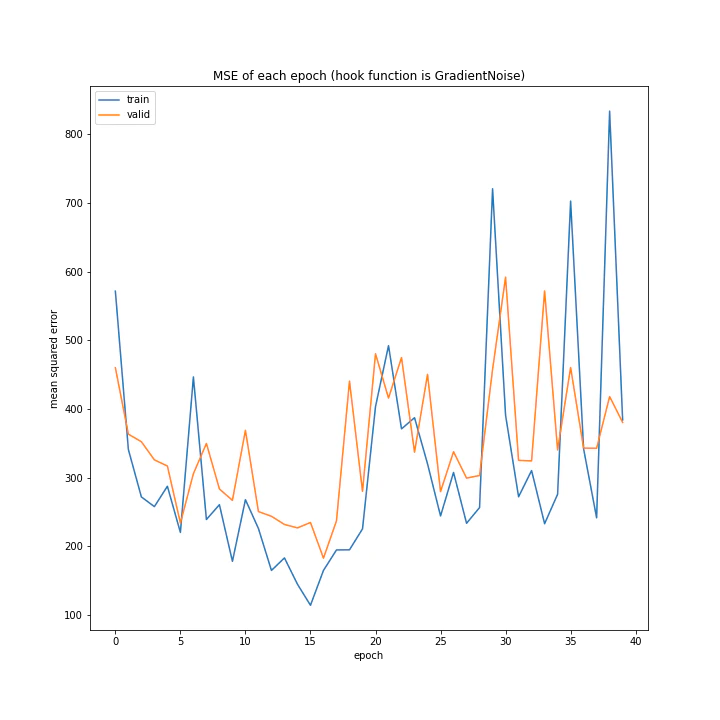
かなり順調に学習しており、最終的なトレーニング平均絶対誤差は2付近まで下がっています。
['WeightDecay', 'Lasso', 'GradientHardClipping', 'GradientNoise', 'GradientLARS']
MSE: [variable(547.9877), variable(516.57294), variable(265.04657), variable(368.97327), variable(132.2816)]
MAE: [variable(19.518631), variable(19.172485), variable(11.6672735), variable(15.090247), variable(7.1252656)]
テストデータでの誤差もGradientLARSがずば抜けて優秀でした。
平均二乗誤差が100代前半なのは非常にいいですね。
GradientLARSの引数
次に、先ほどの実験で好成績を残したGradientLARSの引数を変更しながら最適なパラメータを探しました。
threashold
重みの上限のようなものです。デフォルトは0.01。

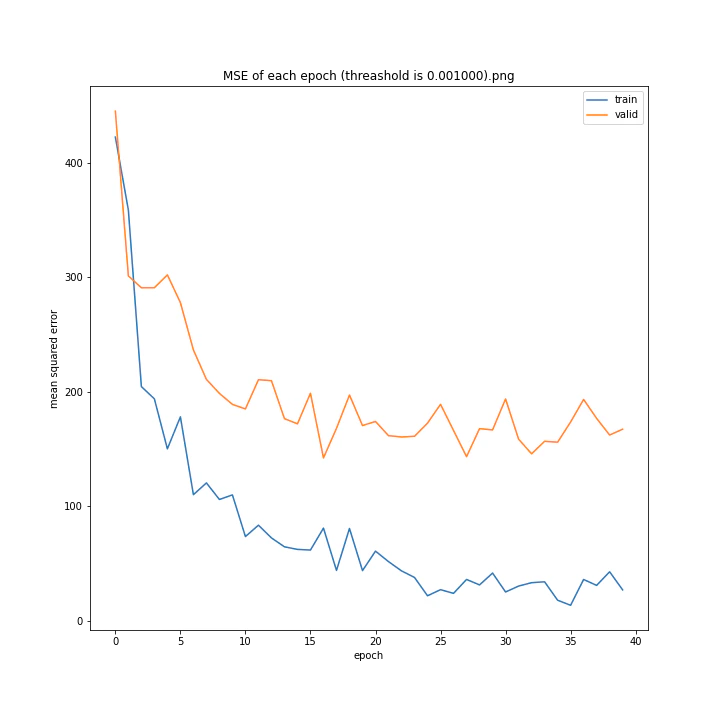
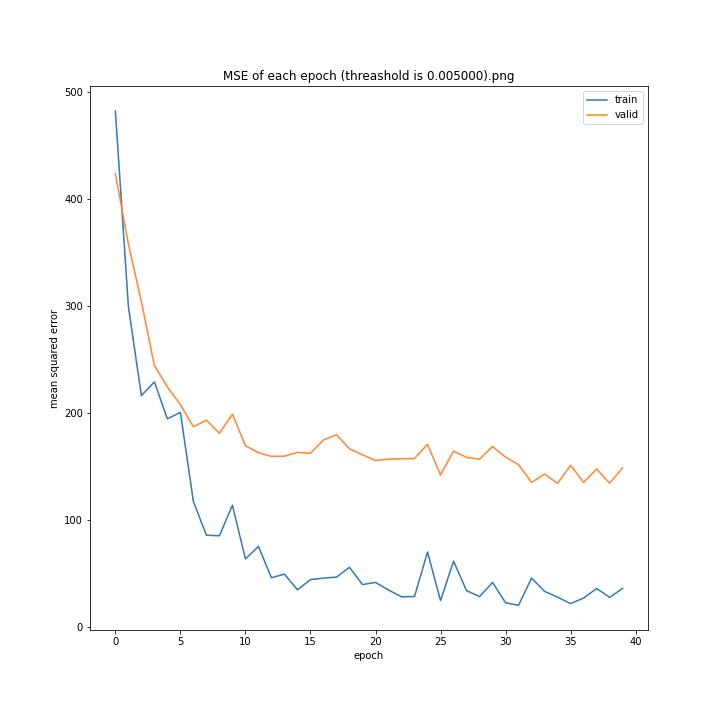
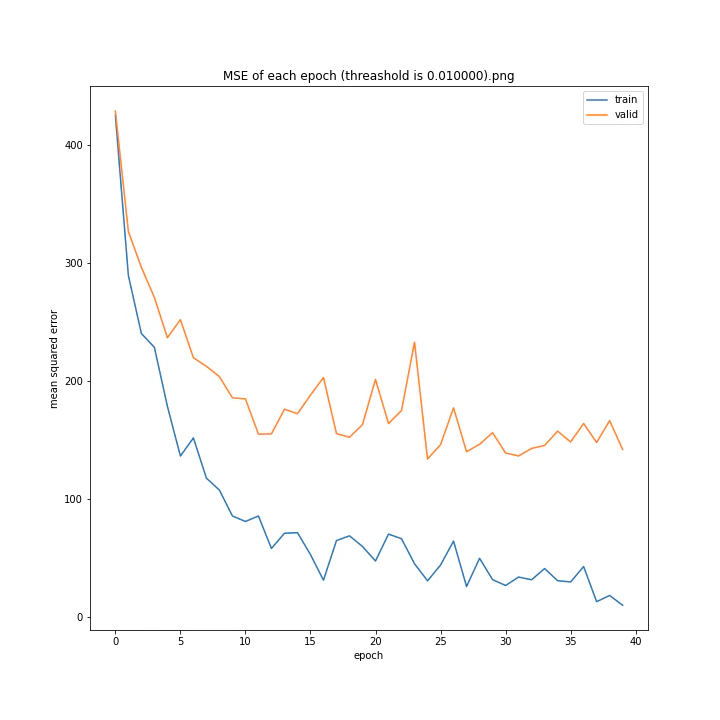
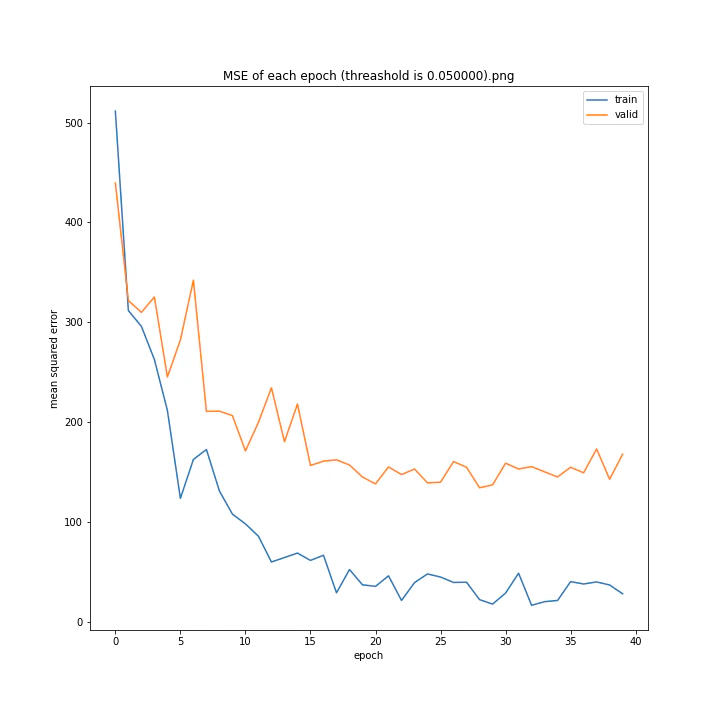
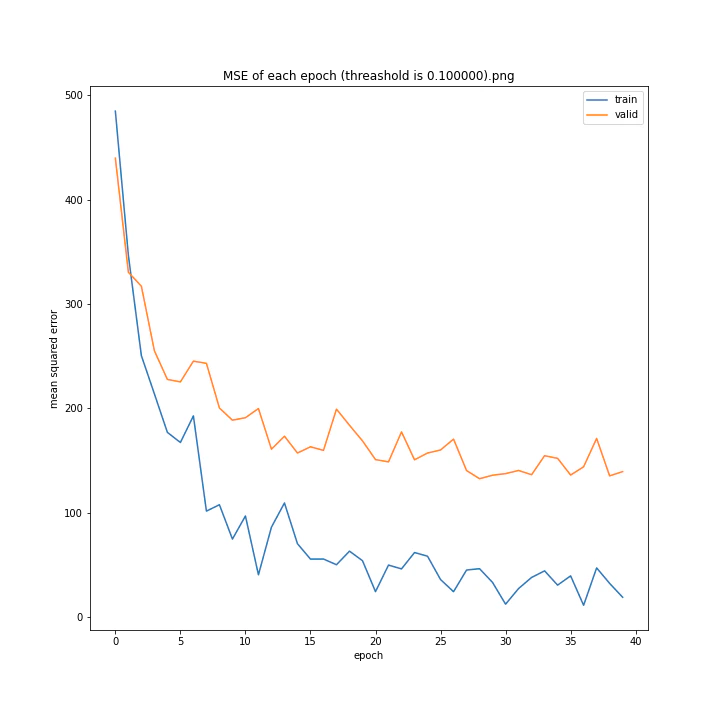
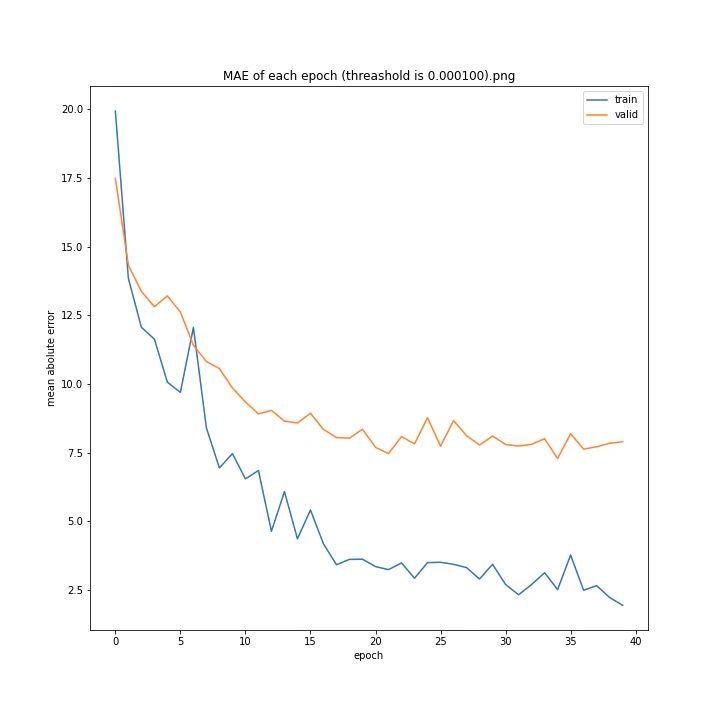
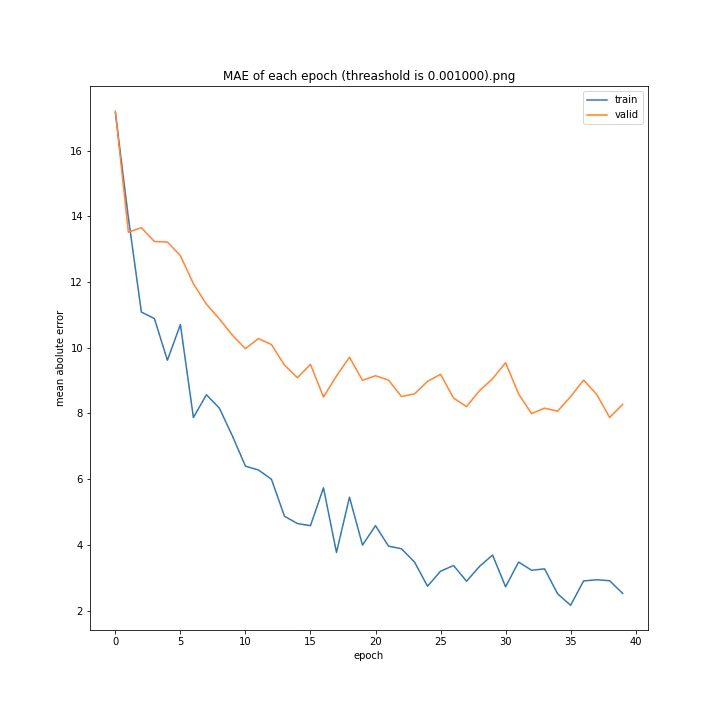
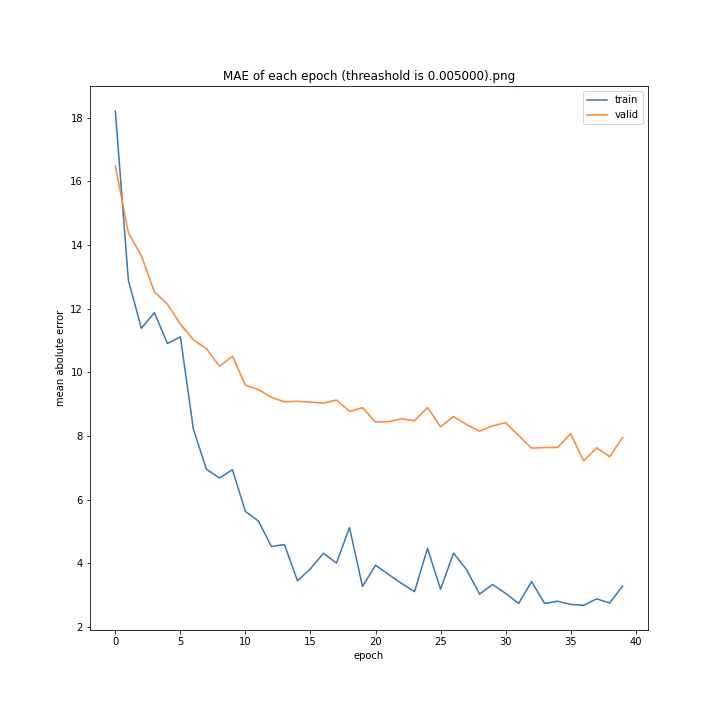
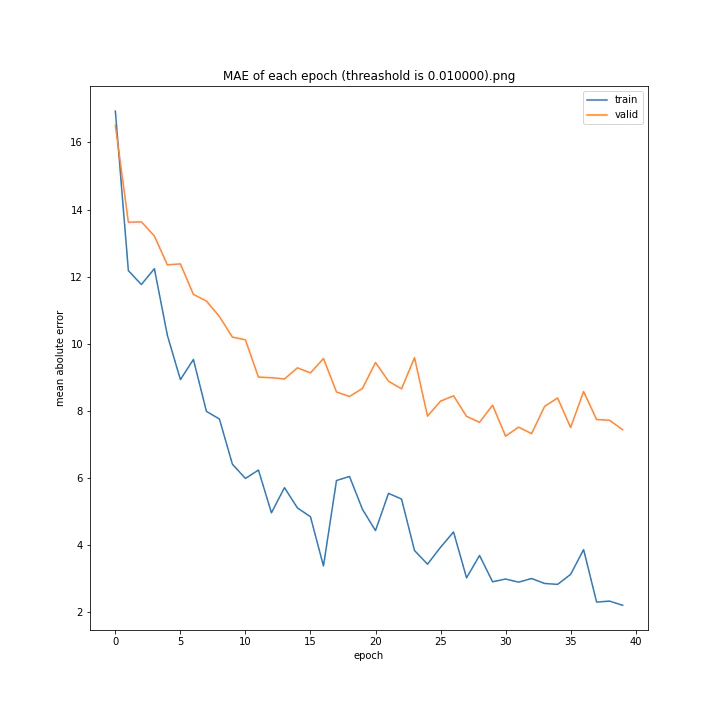
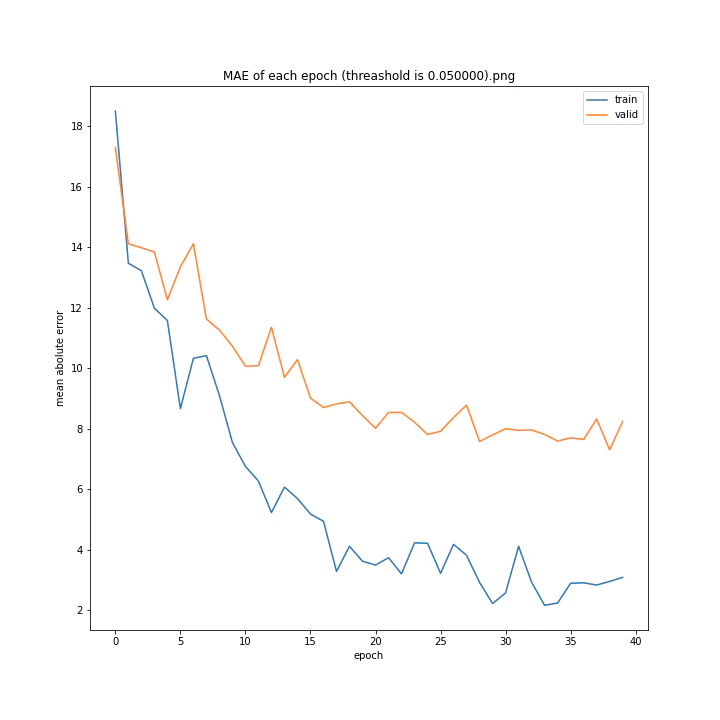
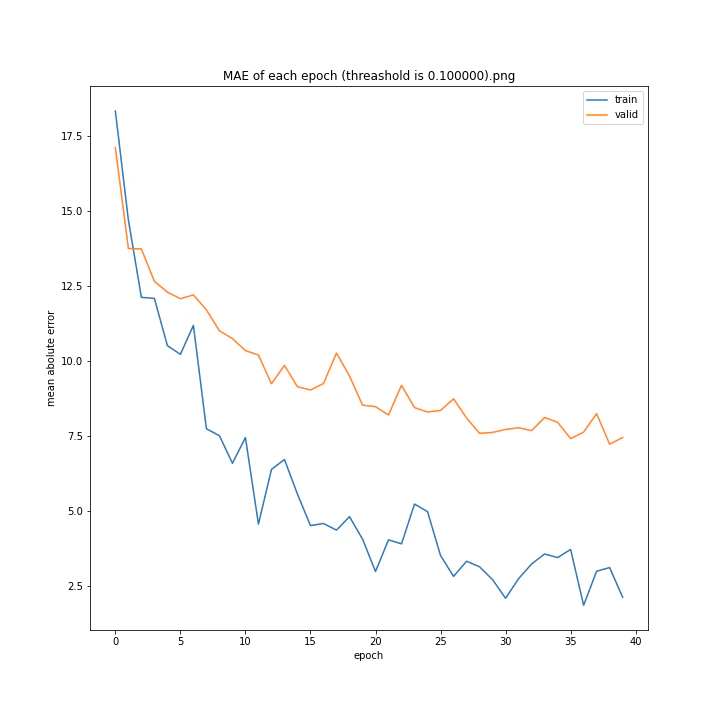
threshold arr: [0.0001, 0.001, 0.005, 0.01, 0.05, 0.1]
test MSE: [variable(166.19632), variable(170.0784), variable(171.25908), variable(163.18517), variable(170.33223), variable(146.83133)]
test MAE: [variable(8.09928), variable(8.408168), variable(8.693802), variable(8.035527), variable(8.495775), variable(7.6456904)]
以外にもどの値でもほとんど変わらない結果になりました。
10層でしかも説明変数が64x3=192個もあるため、そもそもあまり制限しなくても重みはあまり大きくならないのではないかと考えました。
デフォルト値を採用しようと思います。
weight_decay
重み減衰係数です。デフォルトは0.0。
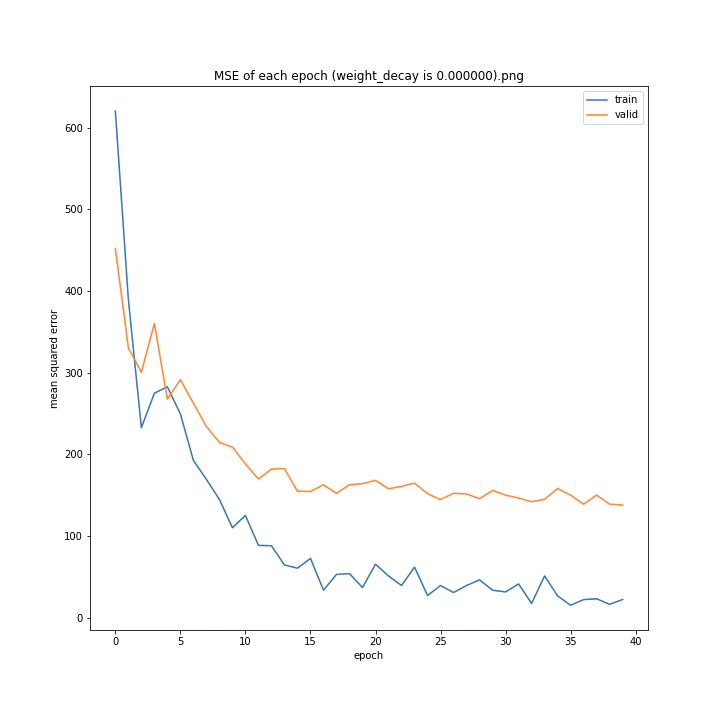
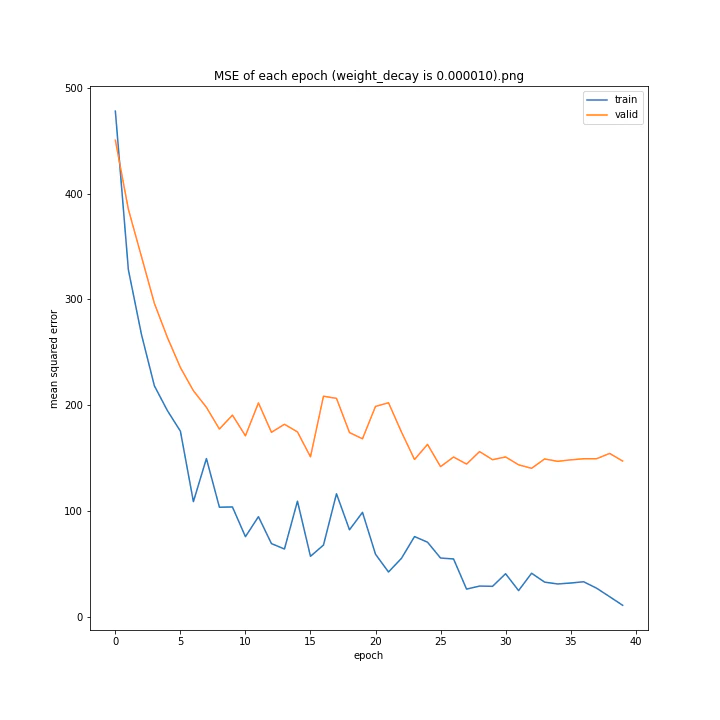

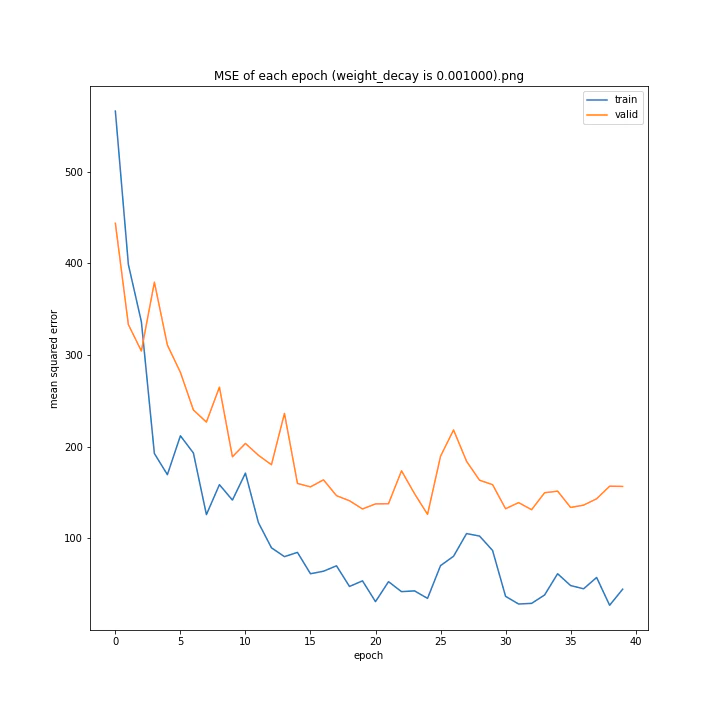

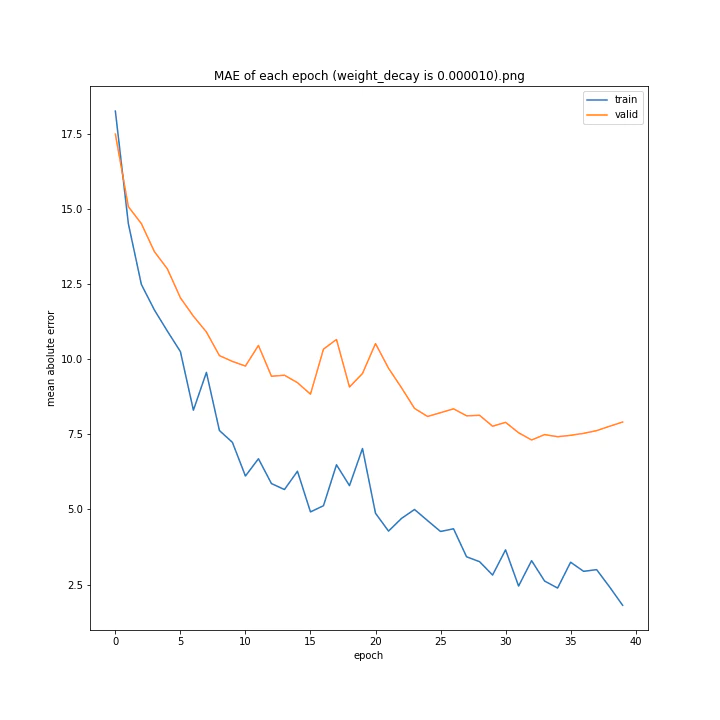
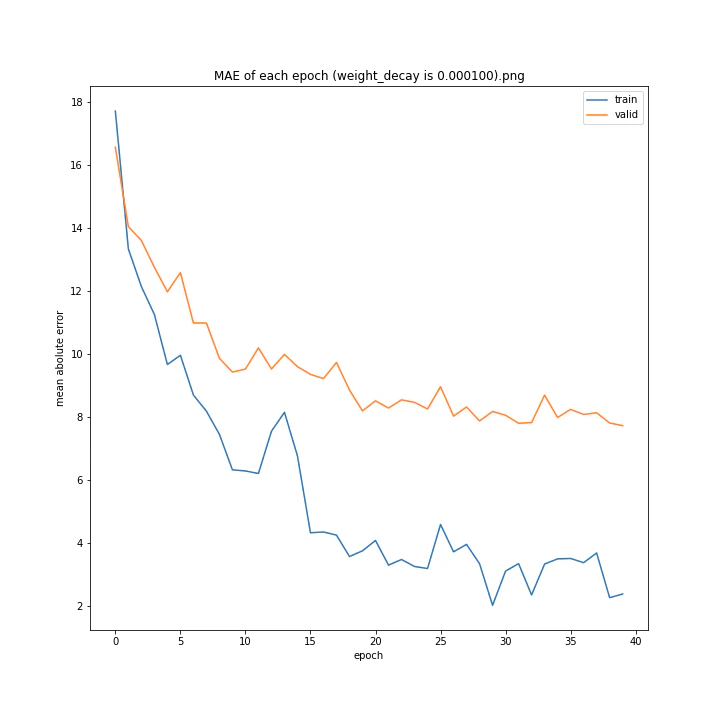
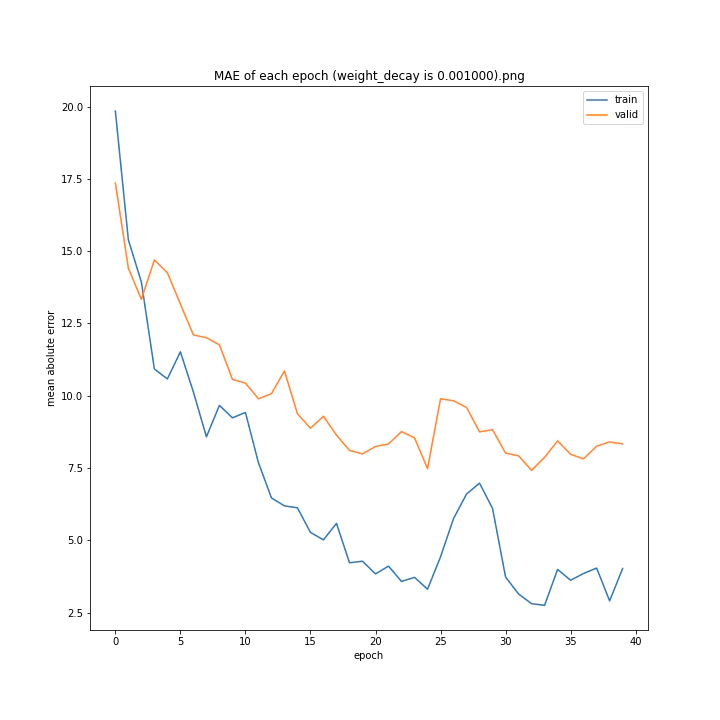
weight_decay arr: [0.0, 1e-05, 0.0001, 0.001]
test MSE: [variable(150.91196), variable(148.27405), variable(147.56767), variable(157.84373)]
test MAE: [variable(7.587319), variable(8.179049), variable(7.731195), variable(8.590252)]
最適な数字の時に誤差が最小になると予想していましたが、実際にはどれも大して変わらない結果となりました。
何が最適であるかわからない以上デフォルト値を使いたいと思います。
eps
デフォルトはe^(-9)、およそ0.0001234です。
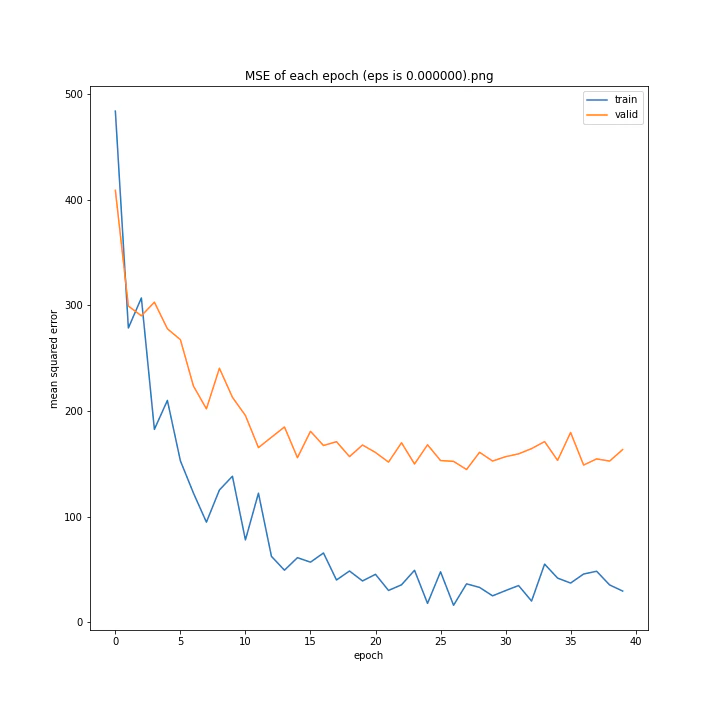
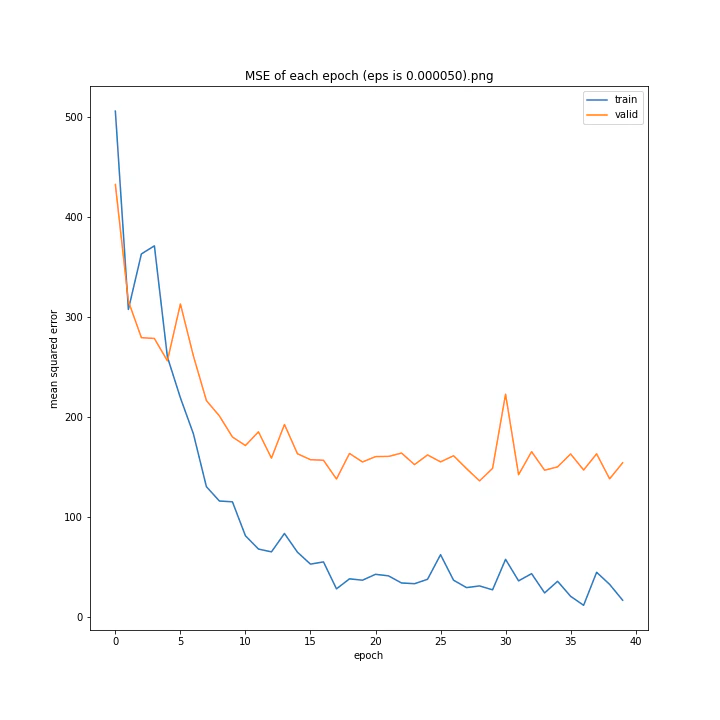
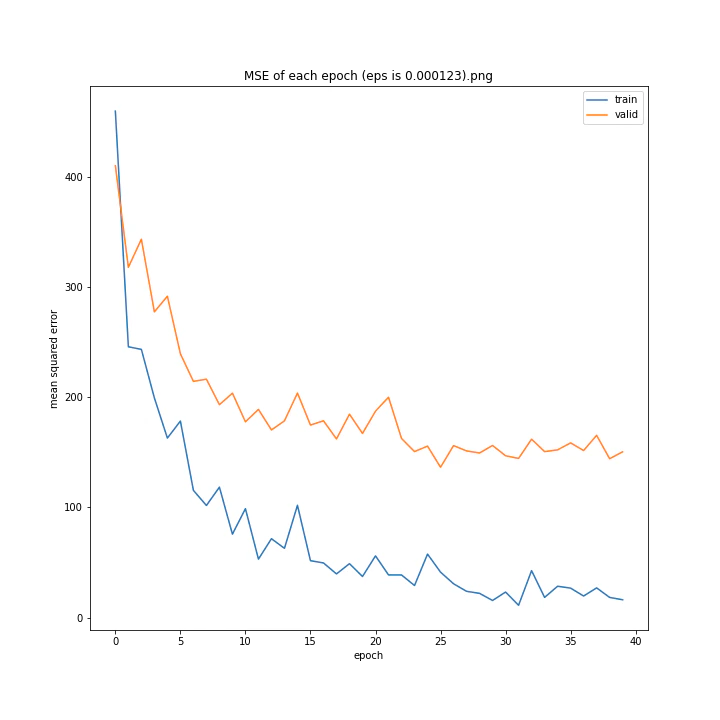
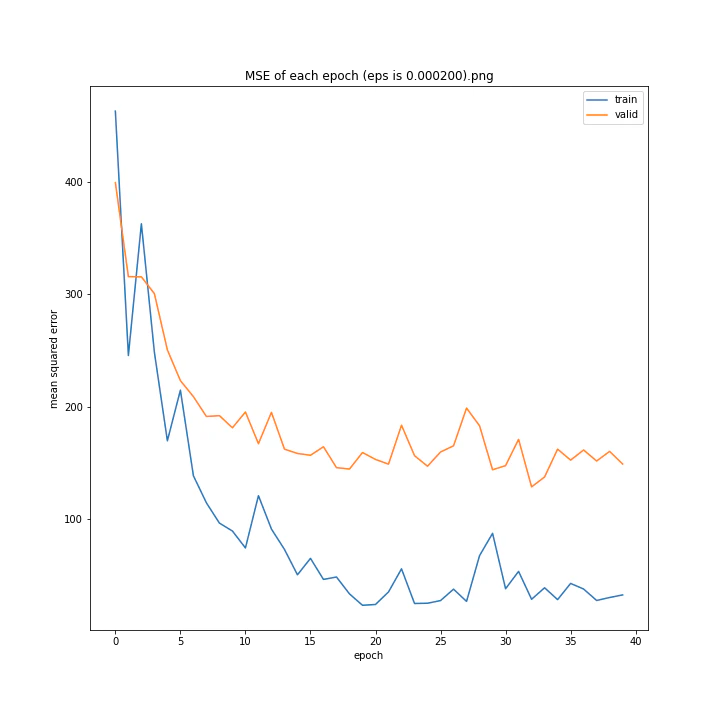
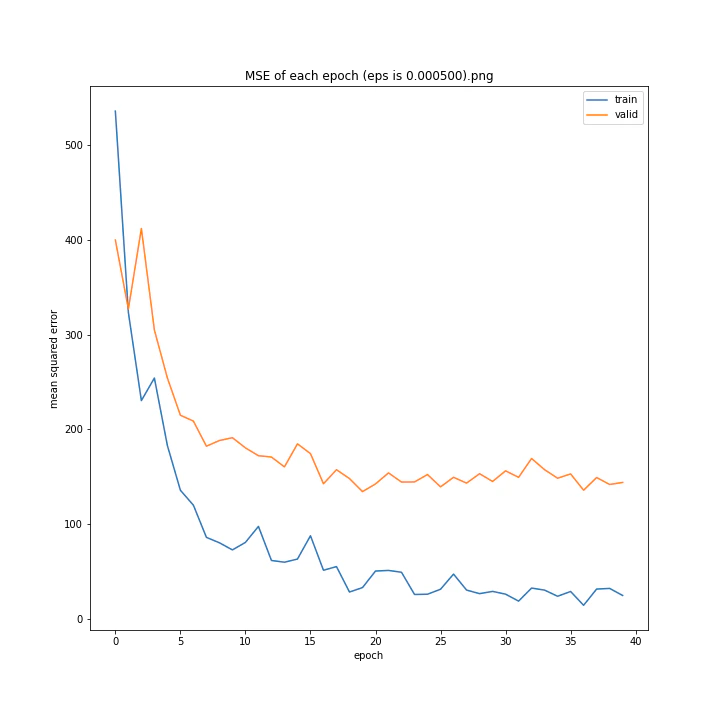
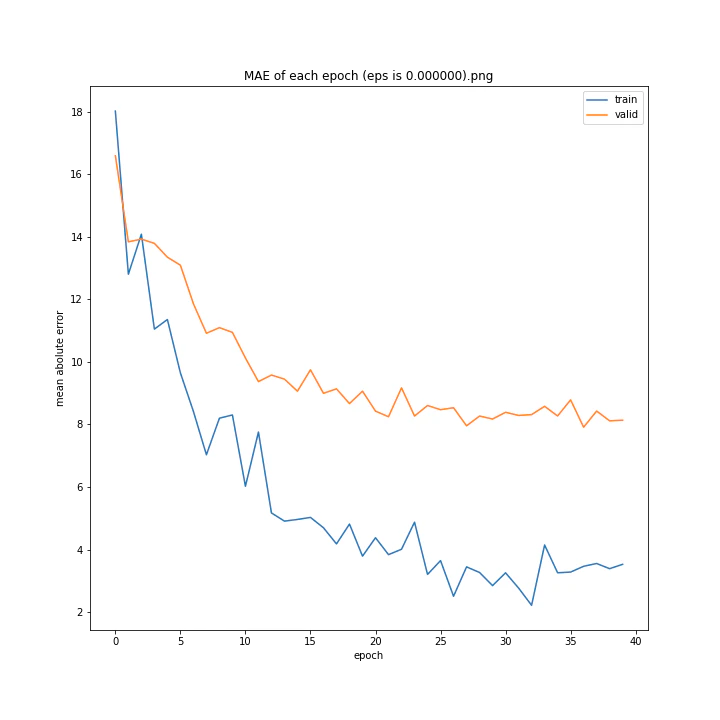
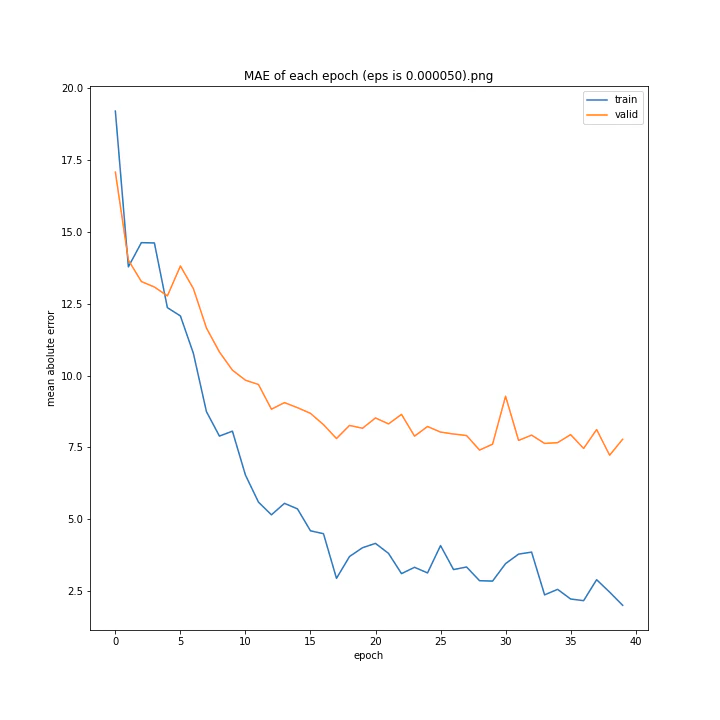

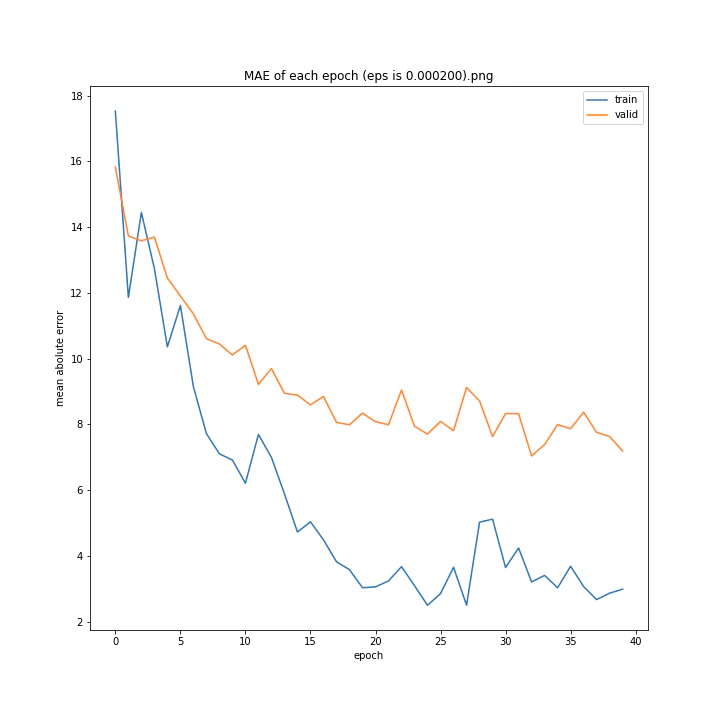
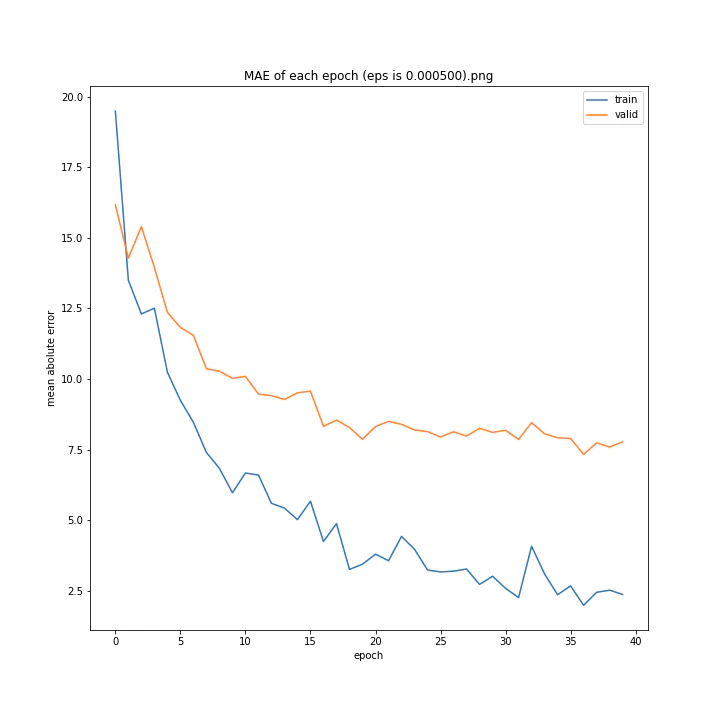
eps arr: [0.0, 5e-05, 0.0001234, 0.0002, 0.0005]
test MSE: [variable(170.8527), variable(145.1517), variable(144.97327), variable(148.69962), variable(156.80756)]
test MAE: [variable(8.57553), variable(7.707429), variable(7.4129925), variable(7.4839306), variable(7.969676)]
どれも似たような結果になりました。
最小記録となったデフォルト値を採用したいと思います。
また全体を通して、平均絶対誤差では差が開いても平均二乗誤差ではあまり差が開かないことが数回あったことが気になりました。
安定して誤差が小さいのは平均二乗誤差が小さいほうなので、同じ平均絶対誤差ならそちらを見ていく必要がありそうです。
更新回数
GradientHardClippingからGradientLARSに変更したので、エポック数を極端に増やした場合の挙動も変化するかもしれないと考え実験してみました。
その結果はこちら。
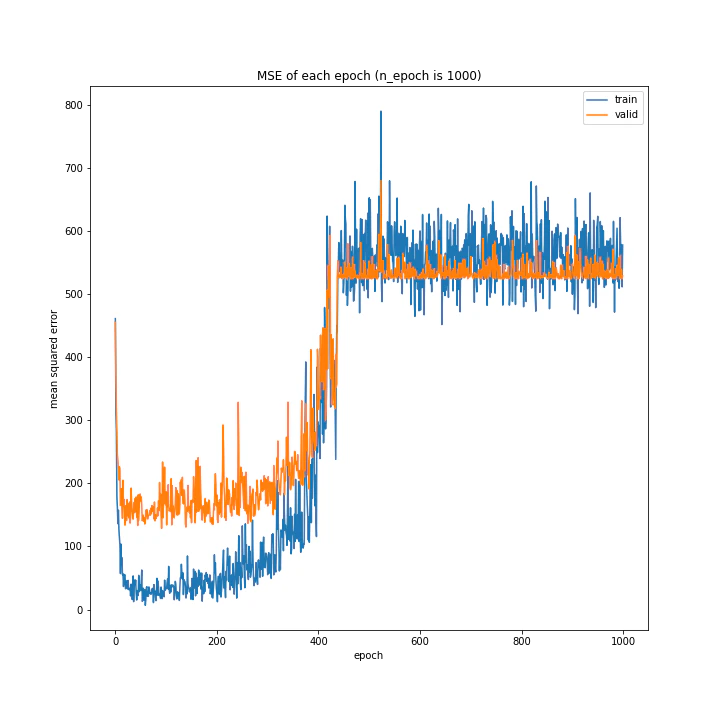
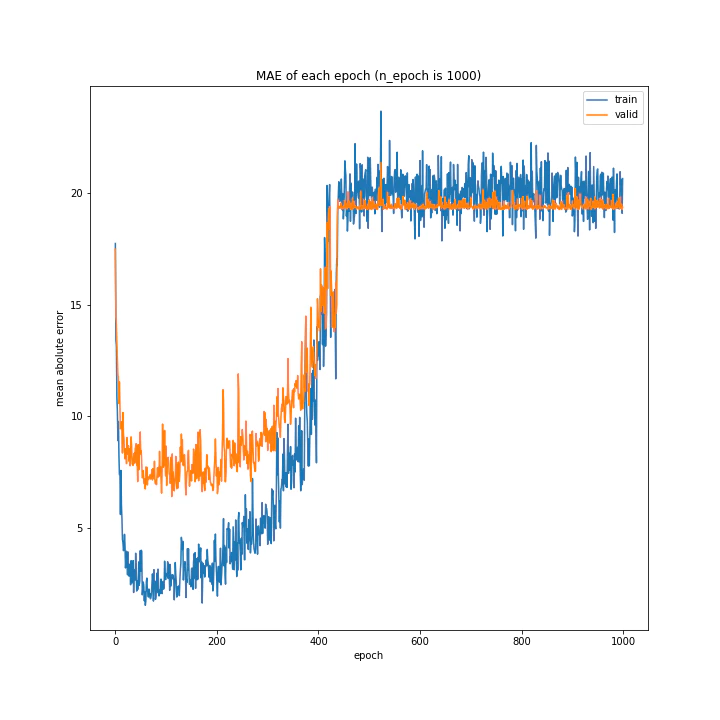
n_epoch: 1000
test MSE: variable(574.58624)
test MAE: variable(20.3639)
GradientHardCLippingの時と同様、途中から誤差が大きくなり更新されなくなりました。
しかし誤差が急増するまでのエポック数は増えていました。
誤差がNanになっていないので勾配爆発ではないと思いますが、エポック数約500以降で特に改善も悪化もしていない理由は今の時点ではわかりません。
総合実験
今まで求めてきたパラメータを組み合わせたうえで、どの組み合わせが最も学習が進むかどうか調べたいと思います。
import chainer.optimizers as opt
from chainer.optimizer_hooks.gradient_lars import GradientLARS
import pandas as pd
import Net
################################
bs_arr = [150, 200, 250]
multi_arr = [1.5, 2.0, 2.5]
opt_arr = [
opt.Adam,
opt.RMSpropGraves,
opt.SMORMS3,
opt.AMSGrad
]
opt_name = [
"Adam",
"RMSpropGraves",
"SMORMS3",
"AMSGrad"
]
bound_arr = [1, 2, 3, 4]
################################
data = {}
data["batch_size"] = []
data["multi"] = []
data["optimizer"] = []
data["bound"] = []
data["test_MSE"] = []
data["test_MAE"] = []
################################
run = deep_learn()
run.num = 2
run.set_data()
i, j = 1, 1
for bs in bs_arr:
# print("\r%d/%d" % (i, len(bs_arr)), end="")
run.batch_size = bs
for multi in multi_arr:
print("\r%d/%d" % (i, len(bs_arr)) + "." * j, end="")
# print(".", end="")
Net.n_multi = multi
run.Net = Net.Net
for opt_num in range(len(opt_arr)):
run.optimizer = opt_arr[opt_num]()
for bound in bound_arr:
run.bound = bound
run.hook_f = GradientLARS()
run.fit()
test_error = run.cal_test_error()
data["batch_size"].append(bs)
data["multi"].append(multi)
data["optimizer"].append(opt_name[opt_num])
data["bound"].append(bound)
data["test_MSE"].append(test_error[0])
data["test_MAE"].append(test_error[1])
j += 1
i += 1
################################
data_df = pd.DataFrame(data)
data_df.to_csv("data.csv")
本当はGradientLARSの引数についても変更しながら調査したかったですが、引数三つのパラメータをそれぞれ三つずつ(デフォルト値及びその前後の値)で検証すると実行時間が十倍近くになってしまうので取りやめました。
実行結果はanalysis.ipynbのほうで示します。
analysis.ipynb
import pandas as pd
data = pd.read_csv("data.csv")
################################
data_top = data["test_MAE"].min()
data_top
実行結果はこちら。
'variable(10.051524)'
最小で10程度という意外な結果になりました。
平均二乗誤差についても調べたところ、
data_top = data["test_MSE"].min()
data_top
'variable(167.63565)'
あまりよくないですね。
フルバージョン
参考資料
深層学習の最適化アルゴリズム
chainer.optimizer_hooks.GradientHardClipping
chainer.optimizer_hooks.GradientNoise
chainer.optimizer_hooks.GradientLARS
次回は
10層については潔くいったん諦め、34の結果から考えていることがありますのでそちらを試したいと思います。