今回の目標
盤面の画像データから最終結果を予測する
という予定でしたが、結局33で作成したニューラルネットワークの改良をすることにします。
ここから本編
なぜ、盤面の画像データから最終結果を予測しようとしていたか説明します。
コンピュータはオセロの盤面を見るとき、場所一つずつを見ることしかできません。
しかし人間は盤面全体を俯瞰的に、大局的に見ている(はず)です。この思考をプログラム上で再現しようと思ったときに、画像を見るという手法は有効なのではないかと考えました。
自分が調べた限りでは同じことをしている人はいないので、面白いアプローチになると思います。
次に、画像認識を用いた時の今までの方法との違いを説明します。
「画像といっても結局は配列だから同じなのでは?」と思うかもしれませんが、今までは黒の石が置かれているところだけ立っている長さ64の配列と白の石が置かれているところだけ立っている長さ64の配列を説明変数として用いていました。長さは合わせて128、各値は0または1でした。
しかしこの手法では黒と白を分けることをせず、RGBなので8x8x3の配列を用います。ここで着目したのは、「石が置かれていないところには、石が置かれていないことが強調される」という点です。これまでは石が置かれていないところをきちんと見ることはありませんでした。
また説明変数が画像であることで、人間が見てわかりやすいという利点もあります。
と、ここまで考えて、「それなら何も置かれていないところだけ立っている配列を作成し、説明変数として加えればいいのでは?」と思い立ちましたのでそれを実行してみます。
また、収束まで時間はかかるようになるものの、多層のほうが一般的には精度が向上するため、今回は試験的に一気に10層まで増やしてみたいと思います。
ミス修正
話題がずれて申し訳ないのですが、今までのデータ集めプログラムにミスを見つけてしまいました。
最終結果を記録する際、それが黒のターンであろうが白のターンであろうが、黒の最終的な石数-白の最終的な石数を目的変数としてしまっていました。
説明変数である盤面のほうが白黒で分けられていれば問題ないのですが、そのターンでの自分の石と相手の石で分けられていました。
なので自分の石配置と相手の石配置しか教えずに(つまり、どちらが黒なのかを教えないで)、黒の最終的な石数-白の最終的な石数を求めろという、かなりの無茶ぶりをしていたことになります。
そのターンがたまたま黒のターンなら黒の石配置と白の石配置を教えて自分のスコアを求めるので問題ないのですが、白のターンなら白の石配置と黒の石配置から相手のスコアを求めるという、おかしなことになってしまいます。
そのため、どのターンでもこれから置く側目線でのスコアを目的変数となるよう修正しました。
playメソッドとdata_setメソッドを変更しました。
def play(self) -> list:
can, old_can = True, True
turn_num = 0
data = []
turn_arr = []
can = self.check_all()
while can or old_can:
if can:
turn_num += 1
if self.turn:
self.think[self.black_method]()
else:
self.think[self.white_method]()
if turn_num in self.check_point:
self.data_set(data, turn_num)
turn_arr.append([self.turn])
self.turn = not self.turn
old_can = can
can = self.check_all()
self.count_last()
# 変更前
# last_score = [self.score] * len(data)
turn_arr = np.array(turn_arr)
last_score = self.score * (-1) ** turn_arr
# return data, last_score
return data, last_score.tolist()
def count_last(self) -> None:
black = self.popcount(self.bw["b_u"])\
+ self.popcount(self.bw["b_d"])
white = self.popcount(self.bw["w_u"])\
+ self.popcount(self.bw["w_d"])
# self.score = black - white
self.score = white - black
self.turnは黒のターンの時True、白のターンの時Falseとなりますので、これで白黒それぞれの目線での最終スコアを目的変数にできます。
また、oseroクラスのコンストラクタにて、seed設定をコメントアウトしたまま外すのを忘れていました。
同じ条件で学習させても違う結果になったりするので不思議に思っていましたが、これが原因だと思います。
修正後の学習結果はこちら。
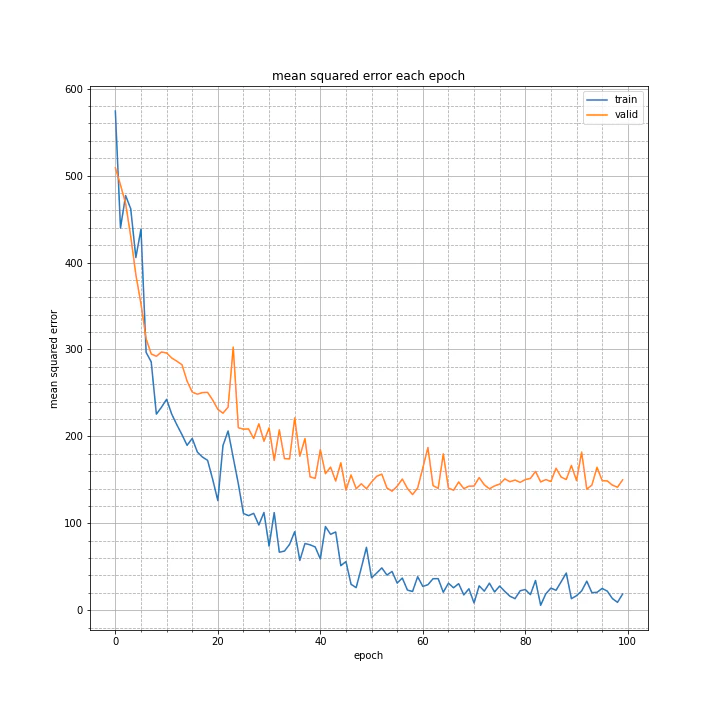
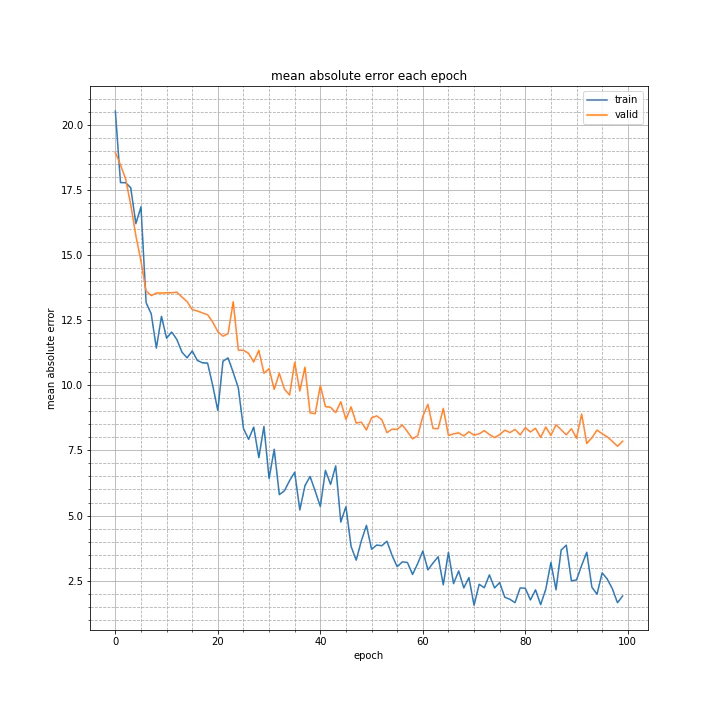
test MSE: 167.5413
test MAE: 8.2660
説明変数と目的変数に関連が生まれたと思ったのですが、精度は下がってしまいました(以前の学習結果)。
理由として考えられるのは、今まで学習がうまくいっていたのは偶然で、正しいデータでの学習の際の最適なパラメータはこれではないということです。
つまりこの目的変数に合わせた最適なパラメータ探しをやり直さなければいけないということになります。
NN改良
「最適なパラメータ探しをやり直さなければいけない」と書きましたが、結局説明変数を追加するので今パラメータ探しをする意味はありません。
まずは上のモデルに説明変数を追加したものを作りたいと思います。
osero_learn.py
まずは説明変数として、何も置かれていないところだけ1で、それ以外が0である配列を追加作成します。といっても、説明変数配列に付け加えるだけです。
これはdata_setメソッド内に追記する形で実現しました。
def data_set(self, data: list, turn_num: int) -> None:
data.append([])
if self.turn:
my = ["b_u", "b_d"]
opp = ["w_u", "w_d"]
else:
my = ["w_u", "w_d"]
opp = ["b_u", "b_d"]
for i in range(32):
if self.bw[my[0]] & 1 << i:
data[-1].append(1)
data[-1].append(0)
data[-1].append(0)
elif self.bw[opp[0]] & 1 << i:
data[-1].append(0)
data[-1].append(1)
data[-1].append(0)
else:
data[-1].append(0)
data[-1].append(0)
data[-1].append(1)
for i in range(32):
if self.bw[my[1]] & 1 << i:
data[-1].append(1)
data[-1].append(0)
data[-1].append(0)
elif self.bw[opp[1]] & 1 << i:
data[-1].append(0)
data[-1].append(1)
data[-1].append(0)
else:
data[-1].append(0)
data[-1].append(0)
data[-1].append(1)
model.ipynb
ほとんどの部分は32と同じですので、変更となったニューラルネットワークのクラス部分のみ載せます。
class Net(chainer.Chain):
def __init__(self):
n_in = 192
n_hidden = 192
n_out = 1
super().__init__()
with self.init_scope():
self.l1 = L.Linear(n_in, n_hidden)
self.l2 = L.Linear(n_hidden, n_hidden)
self.l3 = L.Linear(n_hidden, n_hidden)
self.l4 = L.Linear(n_hidden, n_hidden)
self.l5 = L.Linear(n_hidden, n_hidden)
self.l6 = L.Linear(n_hidden, n_hidden)
self.l7 = L.Linear(n_hidden, n_hidden)
self.l8 = L.Linear(n_hidden, n_hidden)
self.l9 = L.Linear(n_hidden, n_hidden)
self.l10 = L.Linear(n_hidden, n_out)
def __call__(self, x):
h = F.tanh(self.l1(x))
h = F.tanh(self.l2(h))
h = F.tanh(self.l3(h))
h = F.tanh(self.l4(h))
h = F.tanh(self.l5(h))
h = F.tanh(self.l6(h))
h = F.tanh(self.l7(h))
h = F.tanh(self.l8(h))
h = F.tanh(self.l9(h))
h = self.l10(h)
return h
結果はこちら。
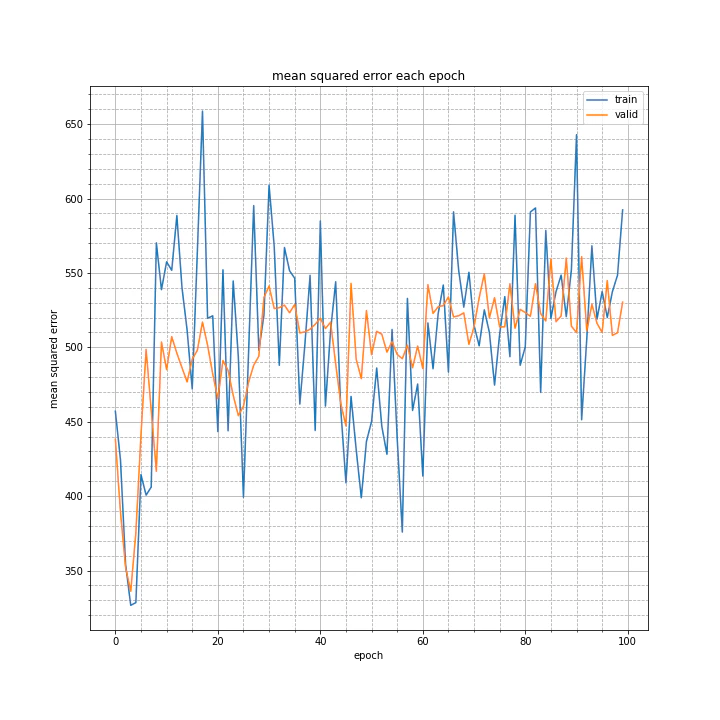
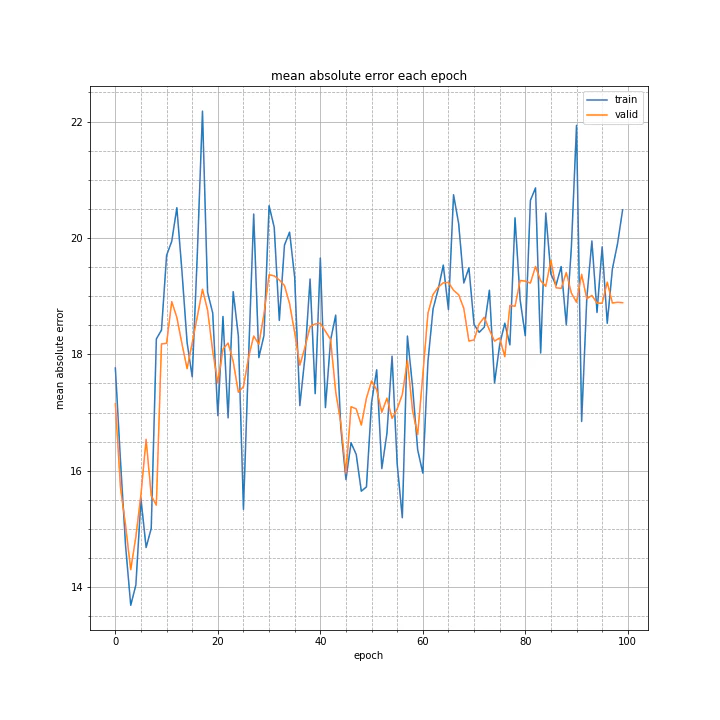
test MSE: 574.5880
test MAE: 19.7724
全く学習していないですね。
理由として考えられるのは、上述の通りハイパーパラメータが適切でないこと。
また、層の数も説明変数も増え、調整すべきパラメータは増えたのにエポック数が変わっていないため学習が進まなかった可能性も考えられます。
さらに、今までは3層や4層だったのであまり問題ありませんでしたが、活性化関数がtanhですので勾配消失が起きた可能性も否定できません。
上のクラスの一部をコメントアウトし、4層での学習を試みてみました。
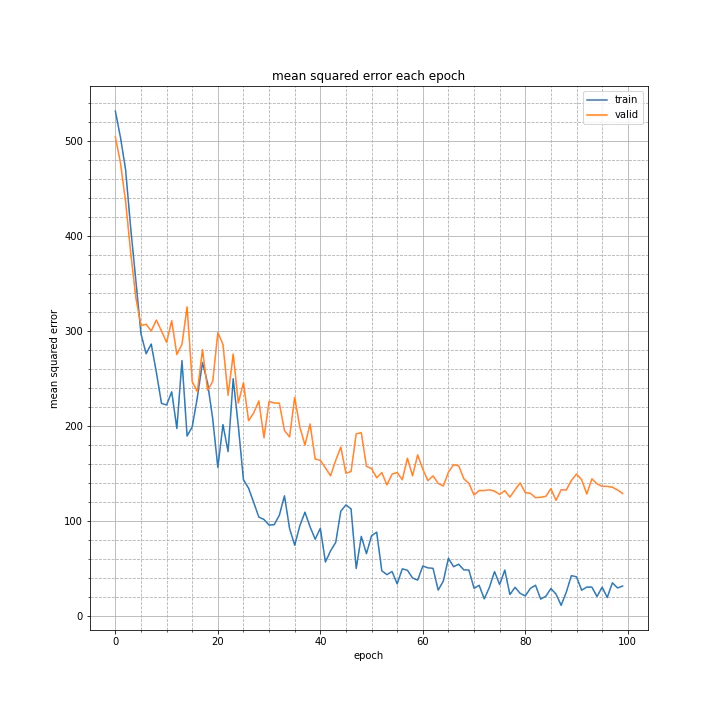
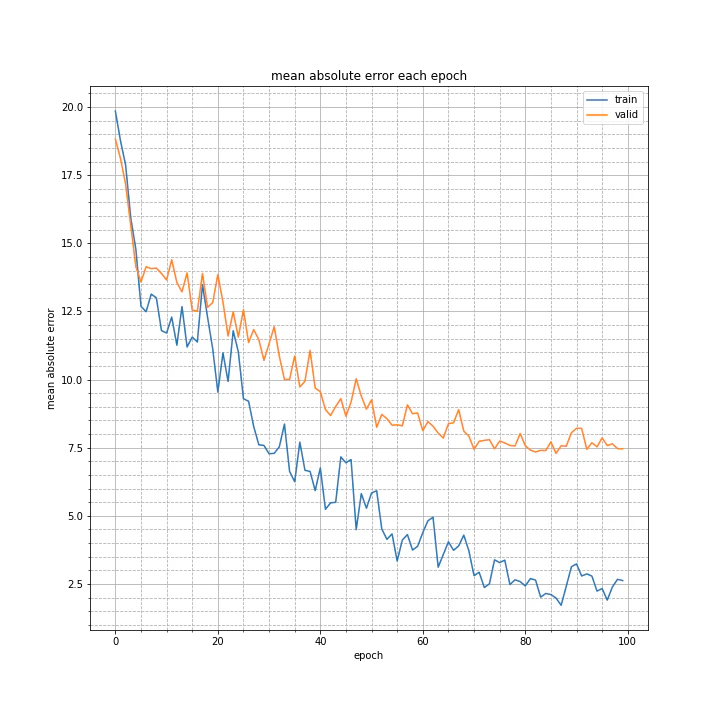
test MSE: 137.5746
test MAE: 7.5991
4層だときれいに学習が進みますね。
10層でやるなら10層に合わせたハイパーパラメータを指定する必要がありそうです。
まとめ
今のパラメータでは、4層でも学習は進むものの精度としてはあまり高くない。
10層なら4層以上の精度を得られるかも知れないが、4層の時とは異なるハイパーパラメータが必要になる。
フルバージョン
次回は
10層に適したハイパーパラメータを探します。
もし(以前の学習結果)以上の精度が出せれば10層を採用したいと思います。