今回の目標
前回行った深層学習の改善を行う予定でしたが、ミスを見つけたのでまずはその修正を行います。
そののち改善のための実験を行います。
ここから本編
ミス修正
データ集めの際、オセロの試合が終わった時に盤面を元に戻していませんでした。これにより、第二試合以降は始まった瞬間に終了しており十分なデータが集められていませんでした。
修正は以下の通り。
data = []
result = []
turn_vari = [i for i in range(5, 61, 5)]
run = learn(0, 0, turn_vari, eva=eva)
for i in range(10):
print("\r[" + "#" * (i+1) + " " * (10-i+1) + "]", end="")
for black in PLAY_WAY:
for white in PLAY_WAY:
run.setup() # この部分が足りなかった
run.black_method = black
run.white_method = white
run.eva = eva
data_ele, result_ele = run.play()
for data_each_turn in data_ele:
data.append(data_each_turn)
for result_each_turn in result_ele:
result.append([result_each_turn])
data = np.array(data).astype(np.float32)
result = np.array(result).astype(np.float32)
print("\r[" + "#" * 10 + "]")
さらに、盤面の記録にもミスがありました。
これまでの方法だとビットシフトしすぎて後半がすべて0になってしまっていました。
# これまで
def data_set(self, data: list, turn_num: int) -> None:
data.append([])
if self.turn:
my = ["b_u", "b_d"]
opp = ["w_u", "w_d"]
else:
my = ["w_u", "w_d"]
opp = ["b_u", "b_d"]
for i in range(64):
data[-1].append(int((self.bw[my[i >= 32]] & (1 << i)) != 0))
data[-1].append(int((self.bw[opp[i >= 32]] & (1 << i)) != 0))
# 修正
def data_set(self, data: list, turn_num: int) -> None:
data.append([])
if self.turn:
my = ["b_u", "b_d"]
opp = ["w_u", "w_d"]
else:
my = ["w_u", "w_d"]
opp = ["b_u", "b_d"]
for i in range(32):
if self.bw[my[0]] & 1 << i:
data[-1].append(1)
else:
data[-1].append(0)
if self.bw[opp[0]] & 1 << i:
data[-1].append(1)
else:
data[-1].append(0)
for i in range(32):
if self.bw[my[1]] & 1 << i:
data[-1].append(1)
else:
data[-1].append(0)
if self.bw[opp[1]] & 1 << i:
data[-1].append(1)
else:
data[-1].append(0)
データ集めのミスを修正すると今度は学習しなくなったので、まずturn_variを変更しました。データ量が少ないから学習しなかったのでは? と考えたためです。
# turn_vari = [i for i in range(5, 61, 5)]
turn_vari = [i for i in range(1, 61)]
また、よく考えると目的変数はマイナスになることもあるので、マイナス値の存在しないreluを活性化関数にするのは問題がありました。
ということでとりあえずtanhに変更。
class Net(chainer.Chain):
def __init__(self, n_in, n_hidden, n_out):
super().__init__()
with self.init_scope():
self.l1 = L.Linear(n_in, n_hidden)
self.l2 = L.Linear(n_hidden, n_hidden)
self.l3 = L.Linear(n_hidden, n_out)
def forward(self, x):
h = F.tanh(self.l1(x))
h = F.tanh(self.l2(h))
h = self.l3(h)
return h
batch_sizeが10ではほぼ学習しなかったので50にすると改善しました。これに関しては追って検証します。
batch_size = 50
dataset = TupleDataset(data, result)
train_val, test = split_dataset_random(dataset, int(len(dataset) * 0.7), seed=0)
train, valid = split_dataset_random(train_val, int(len(train_val) * 0.7), seed=0)
train_iter = SerialIterator(train, batch_size=batch_size, repeat=True, shuffle=True)
また前回のn_batch変数が何もしていないことに気づいたので消しました。チュートリアル内にあったので書いてみたのですが、なぜ書いてあったのかは分かりません。
他の条件は前回と同じで再学習。
結果は以下。
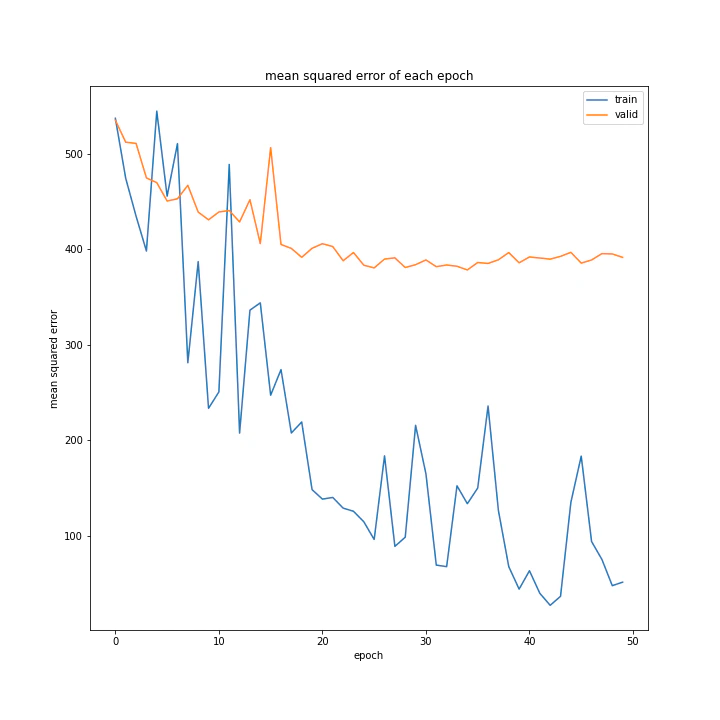
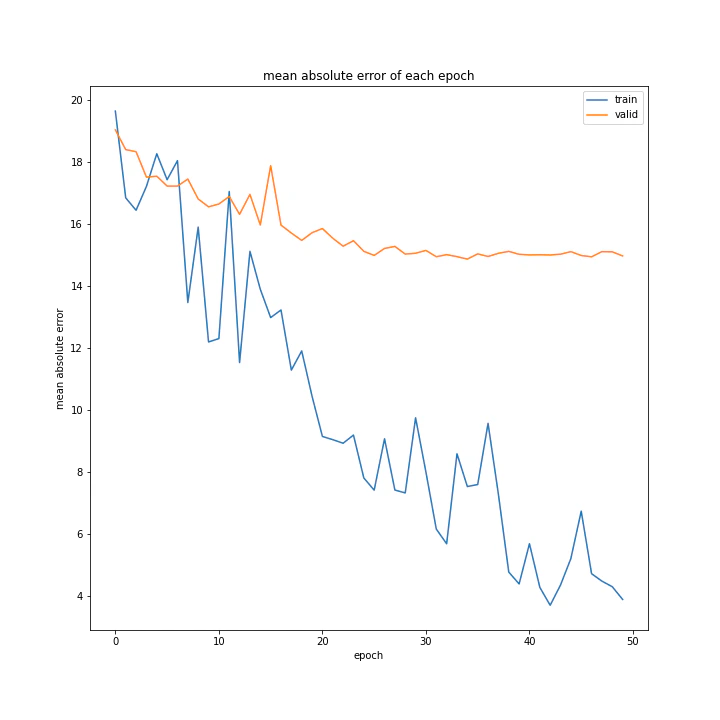
test MSE: 371.1285
test MAE: 14.7923
前回と比べると見劣りする結果ですが、何とか学習はしてくれました。
実験
ファイル構造
実験のためのファイル構造は以下の通り。
experiment
├── fig
│ └── ※実験データをグラフ化した画像が入る※
├── Net_box
│ └── ※ニューラルネットワークを定義したPythonファイルが入る※
├── BitBoard.py ・・・オセロのための基本クラスを定義
├── deep_learn.py ・・・深層学習のためのクラスを定義
├── osero_learn.py ・・・データ集めのためのクラスを定義
└── run.ipynb ・・・実験実行のためのファイル
BitBoard.py
変更はありません。
osero_learn.py
記事冒頭で示した以外の変更はありません。
deep_learn.py
インポート部分
下2行が上述したクラスです。
from copy import deepcopy
import numpy as np
from chainer.datasets import TupleDataset, split_dataset_random
from chainer.iterators import SerialIterator
import chainer
import chainer.functions as F
from chainer import optimizers
from chainer.optimizer_hooks import WeightDecay
from chainer.dataset import concat_examples
import matplotlib.pyplot as plt
from BitBoard import osero
from osero_learn import learn
定義部分
PLAY_WAY = deepcopy(osero.PLAY_WAY)
del PLAY_WAY["human"]
PLAY_WAY = PLAY_WAY.values()
eva = [[
1.0, -0.6, 0.6, 0.4, 0.4, 0.6, -0.6, 1.0,
-0.6, -0.8, 0.0, 0.0, 0.0, 0.0, -0.8, -0.6,
0.6, 0.0, 0.8, 0.6, 0.6, 0.8, 0.0, 0.6,
0.4, 0.0, 0.6, 0.0, 0.0, 0.6, 0.0, 0.4,
0.4, 0.0, 0.6, 0.0, 0.0, 0.6, 0.0, 0.4,
0.6, 0.0, 0.8, 0.6, 0.6, 0.8, 0.0, 0.6,
-0.6, -0.8, 0.0, 0.0, 0.0, 0.0, -0.8, -0.6,
1.0, -0.6, 0.6, 0.4, 0.4, 0.6, -0.6, 1.0
] for i in range(2)]
check_point = [i for i in range(1, 61)]
コンストラクタ
とにかくインスタンス変数をたくさん作りました。
class deep_learn:
def __init__(self):
self.PLAY_WAY = PLAY_WAY
self.eva = eva
self.data = []
self.result = []
self.osero = learn(0, 0, check_point)
self.num = 1
self.n_epoch = 50
self.batch_size = 50
class Inner_Net(chainer.Chain):
pass
self.Net = Inner_Net
self.lr = 0.01
self.optimizer = optimizers.SGD(lr=self.lr)
self.WeightDecay = 0.00001
self.hook_f = WeightDecay(self.WeightDecay)
self.xlabel1, self.xlabel2 = "epoch", "epoch"
self.ylabel1, self.ylabel2 = "mean squared error", "mean abolute error"
self.fig_name1, self.fig_name2 = "MSE of each epoch", "MAE of each epoch"
self.save_dir = "fig"
set_data
学習のためのデータ集めをするメソッド。
def set_data(self):
self.data = []
self.result = []
for i in range(self.num):
for black in self.PLAY_WAY:
for white in self.PLAY_WAY:
self.osero.setup()
self.osero.black_method = black
self.osero.white_method = white
self.osero.eva = self.eva
data_ele, result_ele = self.osero.play()
for data_each_turn in data_ele:
self.data.append(data_each_turn)
for result_each_turn in result_ele:
self.result.append([result_each_turn])
self.data = np.array(self.data).astype(np.float32)
self.result = np.array(self.result).astype(np.float32)
self.dataset = TupleDataset(self.data, self.result)
train_val, self.test = split_dataset_random(\
self.dataset,
int(len(self.dataset) * 0.7),
seed = 0
)
self.train, self.valid = split_dataset_random(\
train_val,
int(len(train_val) * 0.7),
seed = 0
)
self.train_iter = SerialIterator(
self.train,
batch_size = self.batch_size,
repeat = True,
shuffle = True
)
fit
学習を行うメソッド。
def fit(self):
net = self.Net()
optimizer = self.optimizer
optimizer.setup(net)
for param in net.params():
if param.name != "b":
param.update_rule.add_hook(self.hook_f)
results_train = {
"MSE": [],
"MAE": []
}
results_valid = {
"MSE": [],
"MAE": []
}
self.train_iter.reset()
for epoch in range(self.n_epoch):
while True:
train_batch = self.train_iter.next()
x_train, t_train = concat_examples(train_batch)
y_train = net(x_train)
MSE_train = F.mean_squared_error(y_train, t_train)
MAE_train = F.mean_absolute_error(y_train, t_train)
net.cleargrads()
MSE_train.backward()
self.optimizer.update()
if self.train_iter.is_new_epoch:
with chainer.using_config("train", False), chainer.using_config("enable_backprop", False):
x_valid, t_valid = concat_examples(self.valid)
y_valid = net(x_valid)
MSE_valid = F.mean_squared_error(y_valid, t_valid)
MAE_valid = F.mean_absolute_error(y_valid, t_valid)
results_train["MSE"].append(MSE_train.array)
results_train["MAE"].append(MAE_train.array)
results_valid["MSE"].append(MSE_valid.array)
results_valid["MAE"].append(MAE_valid.array)
break
self.results_train = results_train
self.results_valid = results_valid
self.net = net
plot
学習過程での平均二乗誤差と平均絶対誤差をグラフ化するメソッド。
def plot(self):
fig = plt.figure(figsize=(10, 10))
plt.plot(self.results_train["MSE"], label="train")
plt.plot(self.results_valid["MSE"], label="valid")
plt.legend()
plt.xlabel(self.xlabel1)
plt.ylabel(self.ylabel1)
plt.title(self.fig_name1)
plt.savefig(self.save_dir + "/" + self.fig_name1)
plt.clf()
plt.close()
fig = plt.figure(figsize=(10, 10))
plt.plot(self.results_train["MAE"], label="train")
plt.plot(self.results_valid["MAE"], label="valid")
plt.legend()
plt.xlabel(self.xlabel2)
plt.ylabel(self.ylabel2)
plt.title(self.fig_name2)
plt.savefig(self.save_dir + "/" + self.fig_name2)
plt.clf()
plt.close()
cal_test_error
テストデータでの平均二乗誤差と平均絶対誤差を計算するメソッド。
def cal_test_error(self):
x_test, t_test = concat_examples(self.test)
with chainer.using_config("train", False),\
chainer.using_config("enable_backprop", False):
y_test = self.net(x_test)
MSE_test = F.mean_squared_error(y_test, t_test)
MAE_test = F.mean_absolute_error(y_test, t_test)
return MSE_test, MAE_test
Net_box
ニューラルネットワークを定義したファイルを置いたフォルダ。
plane.py
ミス修正の時に用いたクラス。
from chainer import Chain
import chainer.links as L
import chainer.functions as F
class Net(Chain):
def __init__(self):
super().__init__()
n_in = 128
n_hidden = 128
n_out = 1
with self.init_scope():
self.l1 = L.Linear(n_in, n_hidden)
self.l2 = L.Linear(n_hidden, n_hidden)
self.l3 = L.Linear(n_hidden, n_out)
def __call__(self, x):
h = F.tanh(self.l1(x))
h = F.tanh(self.l2(h))
h = self.l3(h)
return h
n_layer.py
層の数のみ変更したクラス。
from chainer import Chain
import chainer.links as L
import chainer.functions as F
n_in = 128
n_hidden = 128
n_out = 1
class Net2(Chain):
def __init__(self):
super().__init__()
with self.init_scope():
self.l1 = L.Linear(n_in, n_hidden)
self.l2 = L.Linear(n_hidden, n_out)
def __call__(self, x):
h = F.tanh(self.l1(x))
h = self.l2(h)
return h
class Net3(Chain):
def __init__(self):
super().__init__()
with self.init_scope():
self.l1 = L.Linear(n_in, n_hidden)
self.l2 = L.Linear(n_hidden, n_hidden)
self.l3 = L.Linear(n_hidden, n_out)
def __call__(self, x):
h = F.tanh(self.l1(x))
h = F.tanh(self.l2(h))
h = self.l3(h)
return h
class Net4(Chain):
def __init__(self):
super().__init__()
with self.init_scope():
self.l1 = L.Linear(n_in, n_hidden)
self.l2 = L.Linear(n_hidden, n_hidden)
self.l3 = L.Linear(n_hidden, n_hidden)
self.l4 = L.Linear(n_hidden, n_out)
def __call__(self, x):
h = F.tanh(self.l1(x))
h = F.tanh(self.l2(h))
h = F.tanh(self.l3(h))
h = self.l4(h)
return h
class Net5(Chain):
def __init__(self):
super().__init__()
with self.init_scope():
self.l1 = L.Linear(n_in, n_hidden)
self.l2 = L.Linear(n_hidden, n_hidden)
self.l3 = L.Linear(n_hidden, n_hidden)
self.l4 = L.Linear(n_hidden, n_hidden)
self.l5 = L.Linear(n_hidden, n_out)
def __call__(self, x):
h = F.tanh(self.l1(x))
h = F.tanh(self.l2(h))
h = F.tanh(self.l3(h))
h = F.tanh(self.l4(h))
h = self.l5(h)
return h
kind_function.py
活性化関数の種類のみ変更したクラス。
from chainer import Chain
import chainer.links as L
import chainer.functions as F
functions_arr = [
F.relu,
F.tanh,
F.elu,
F.leaky_relu,
F.rrelu,
F.selu
]
functions_name = [
"relu",
"tanh",
"elu",
"leaky_relu",
"rrelu",
"selu"
]
func = None
class Net(Chain):
def __init__(self):
super().__init__()
n_in = 128
n_hidden = 128
n_out = 1
with self.init_scope():
self.l1 = L.Linear(n_in, n_hidden)
self.l2 = L.Linear(n_hidden, n_hidden)
self.l3 = L.Linear(n_hidden, n_out)
def __call__(self, x):
h = func(self.l1(x))
h = func(self.l2(h))
h = self.l3(h)
return h
run.ipynb
まず、以下のインポートを行います。
from deep_learn import *
import Net_box.plane as plane
データ量変更
全ての手法の総当たり戦を、全部で何通りするかをnum変数で表します。
run = deep_learn()
run.Net = plane.Net
num_arr = [1, 10, 50]
run.save_dir = "fig/data_quantity"
i = 1
MSE_test = []
MAE_test = []
for num in num_arr:
print("\r%d/%d" % (i, len(num_arr)), end="")
run.num = num
run.fig_name1 = "MSE of each epoch (data quantity is %d)" % num
run.fig_name2 = "MAE of each epoch (data quantity is %d)" % num
run.set_data()
run.fit()
run.plot()
test_error = run.cal_test_error()
MSE_test.append(test_error[0])
MAE_test.append(test_error[1])
i += 1
結果はこちら。
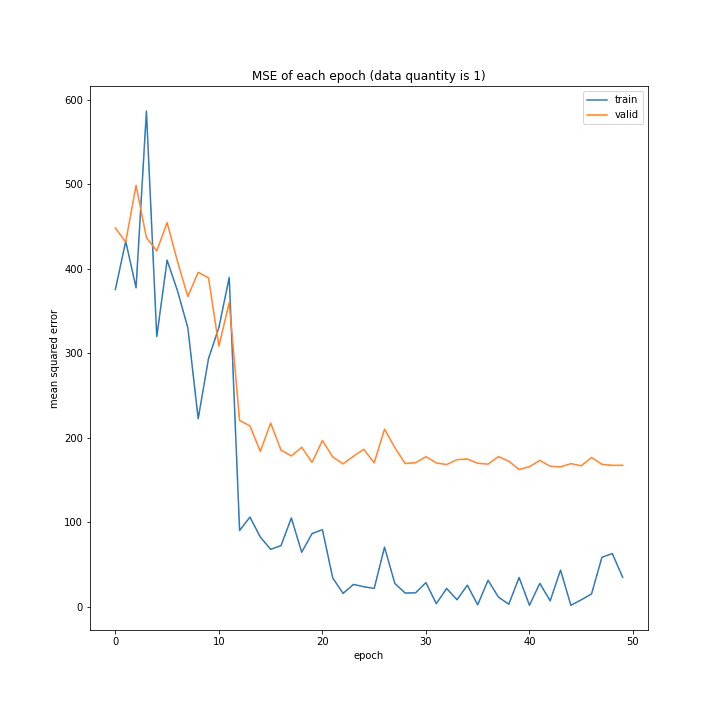
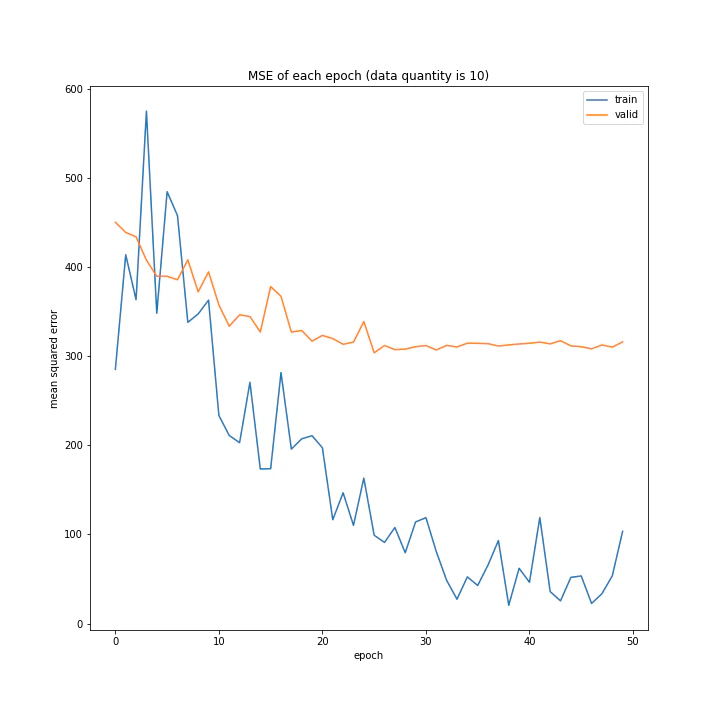
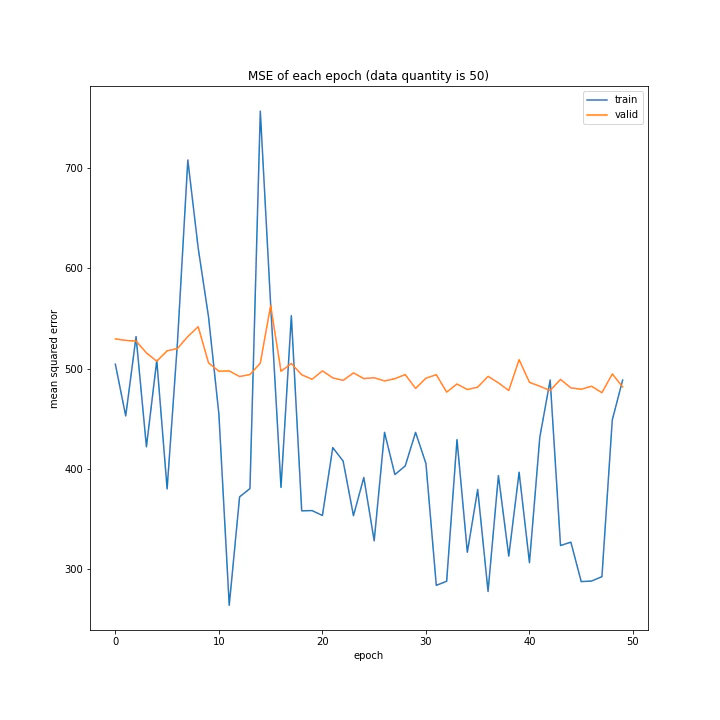
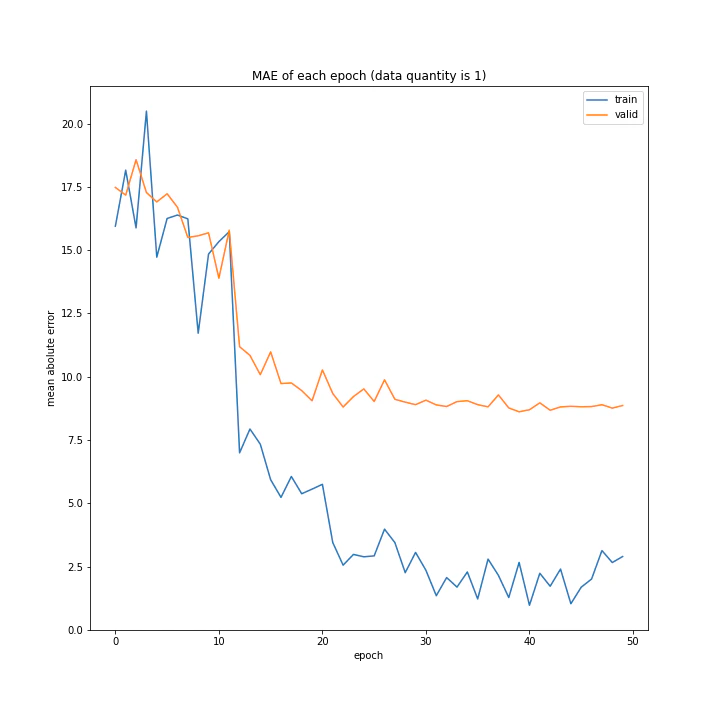
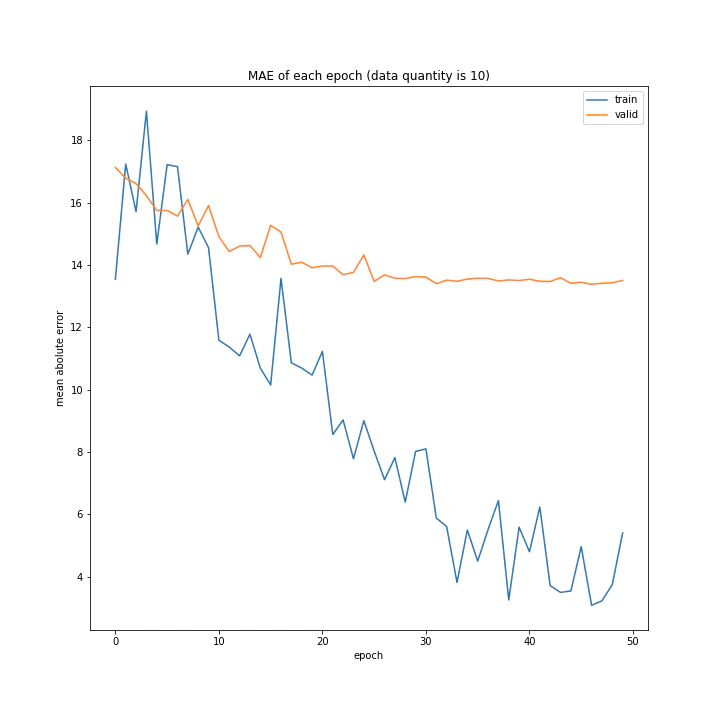
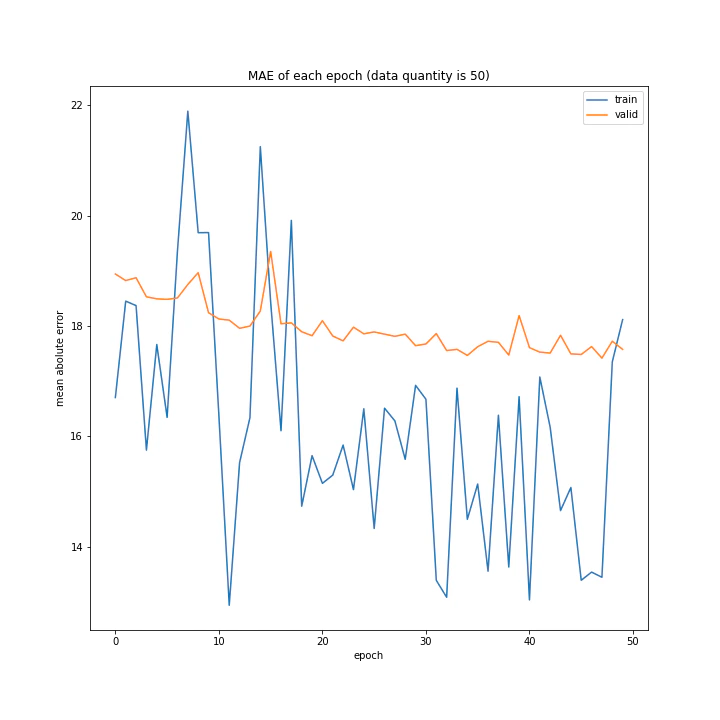
MSE: [variable(187.12271), variable(328.72275), variable(488.58707)]
MAE: [variable(9.387474), variable(13.689546), variable(17.651814)]
意外にもデータ量を増やすほど上手く学習できないと分かりました。1が最優秀という結果に。
またデータ量1および10のとき、どちらもエポック数10回まではトレーニングデータと確認データの精度はほぼ同じですが、それ以降は異なっています。理由は分かりません。
また、平均絶対誤差において、最初は1より10の方が誤差が小さいですが、10回以降では逆転しています。平均二乗誤差ではそうはなっておらず、10回目以降の誤差の値が異なるのみでした。平均二乗誤差に大きな差がないにもかかわらず平均絶対誤差が異なる理由として、データ量10では全体的に小さい誤差が多いが、たまに大きな誤差が混じっていると考えられます。
十分学習した時の誤差は、平均も二乗も1が勝っていました。
バッチサイズ変更
run = deep_learn()
run.Net = plane.Net
batch_arr = [5, 10, 25, 50, 75, 100, 150, 200, 300]
run.save_dir = "fig/batch_size"
i = 1
MSE_test = []
MAE_test = []
run.set_data()
for batch_size in batch_arr:
print("\r%d/%d" % (i, len(batch_arr)), end="")
run.batch_size = batch_size
run.fig_name1 = "MSE of each epoch (batch size is %d)" % batch_size
run.fig_name2 = "MAE of each epoch (batch size is %d)" % batch_size
run.fit()
run.plot()
test_error = run.cal_test_error()
MSE_test.append(test_error[0])
MAE_test.append(test_error[1])
i += 1
結果はこちら。
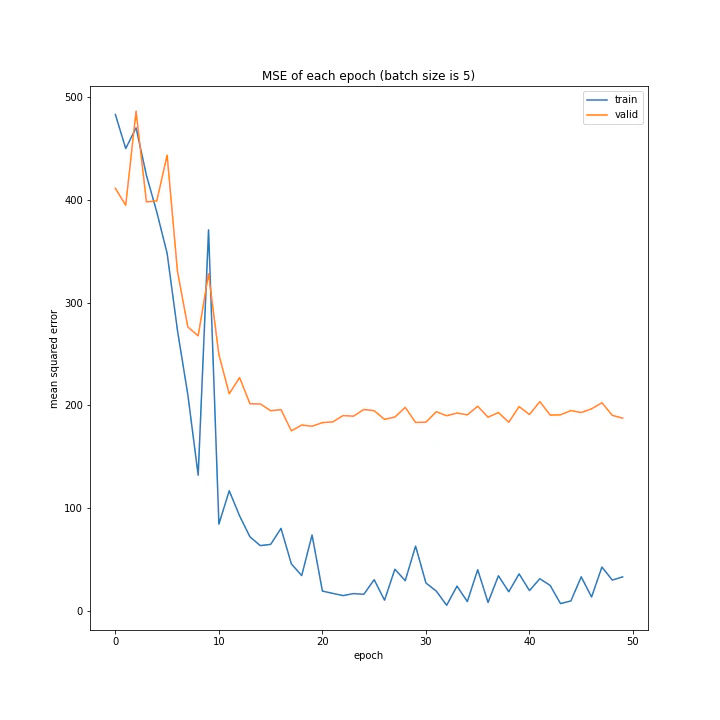
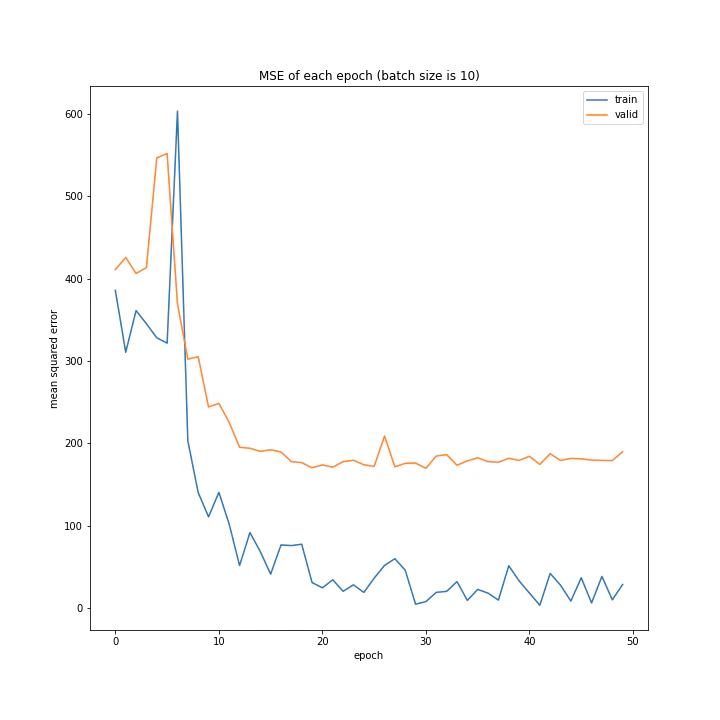
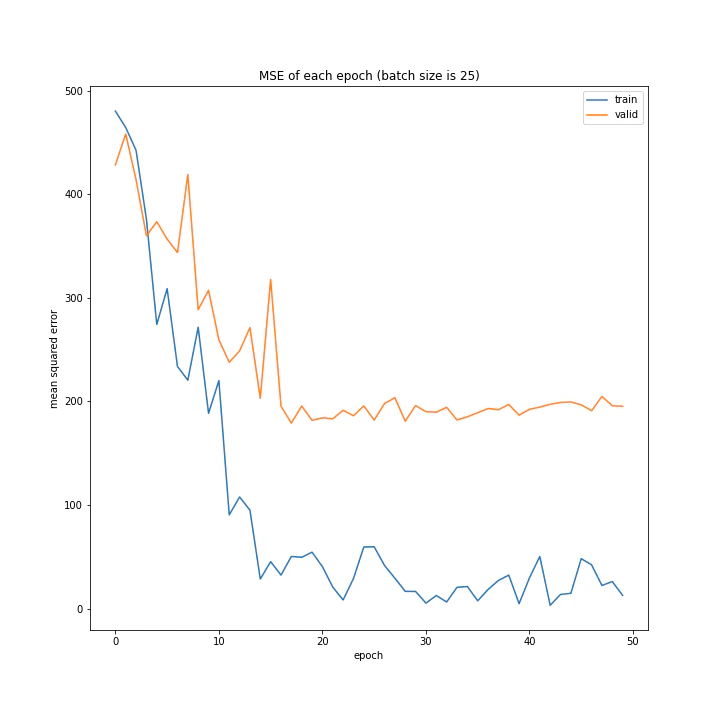
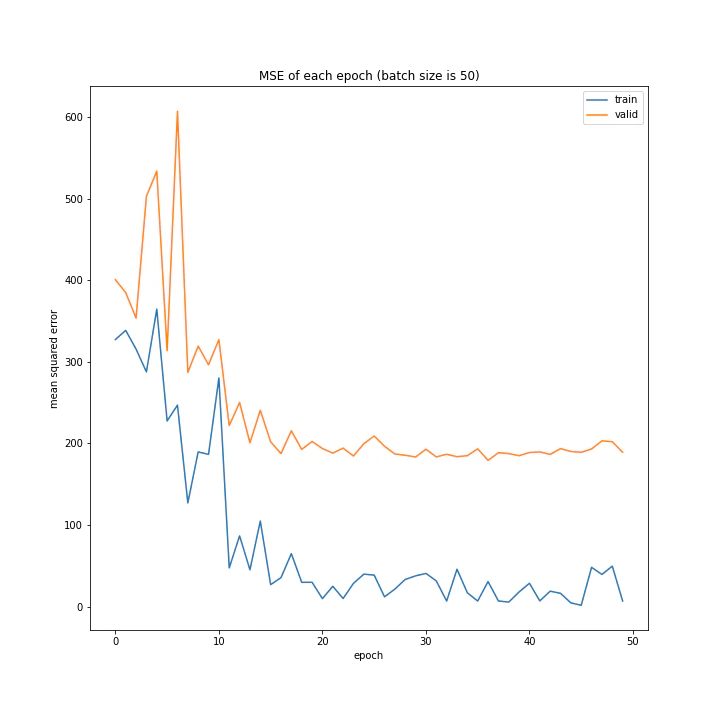
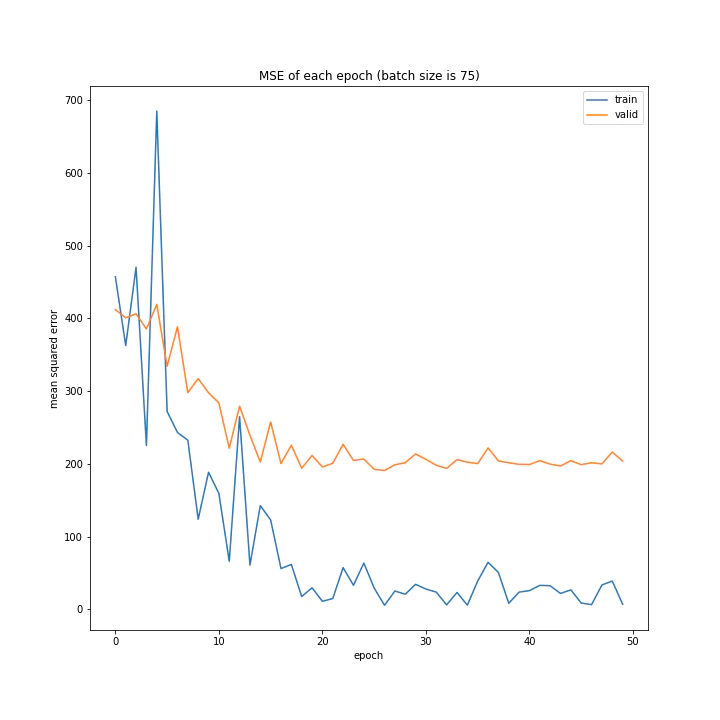
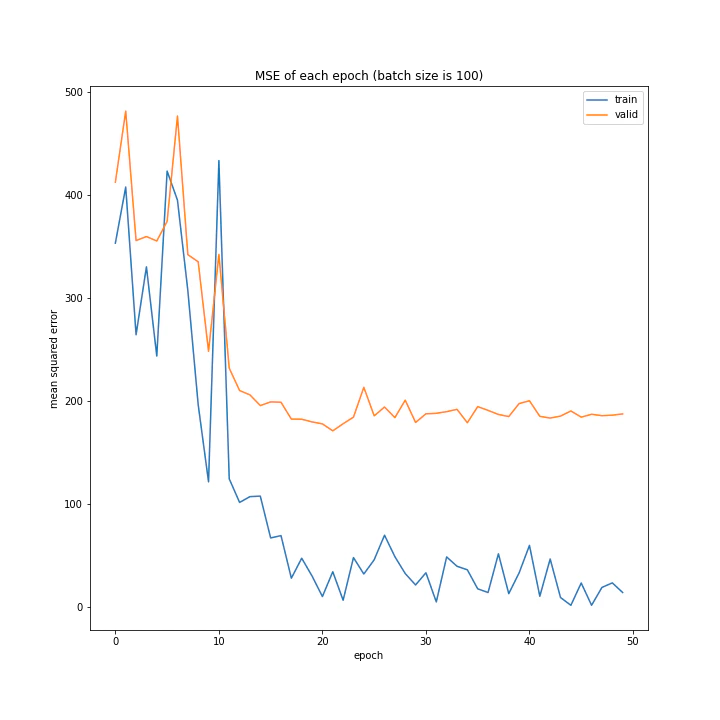
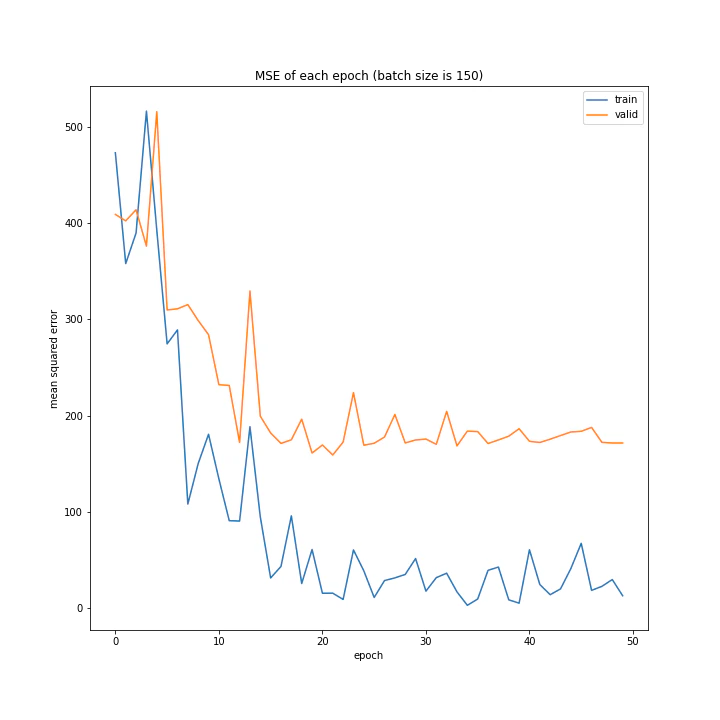
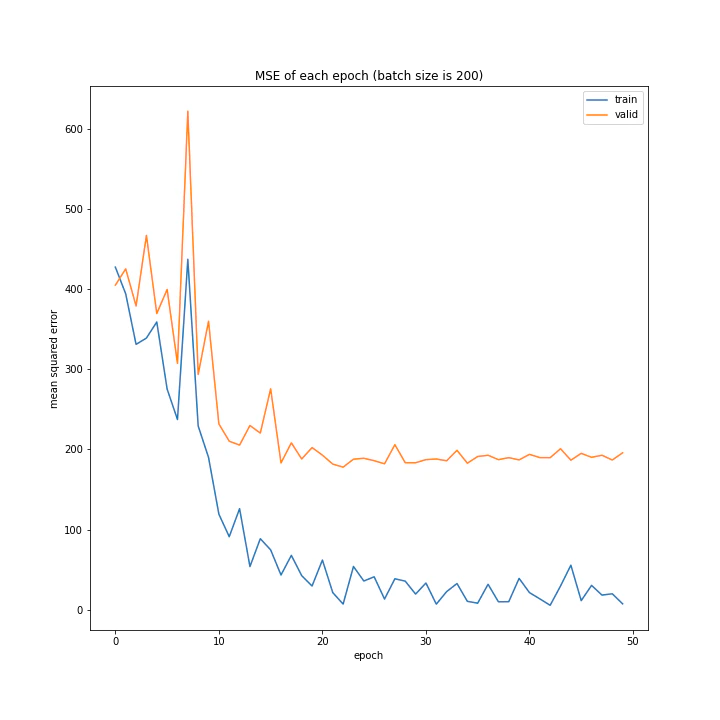
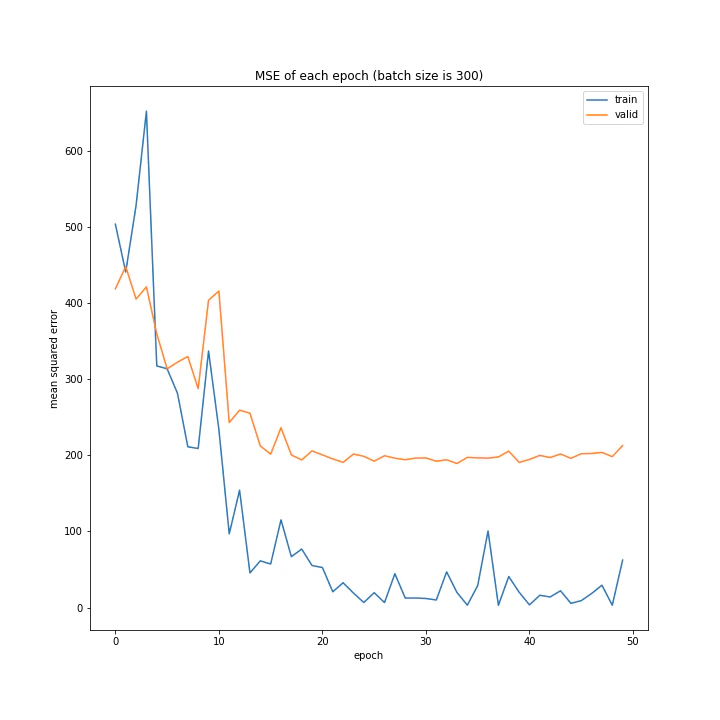
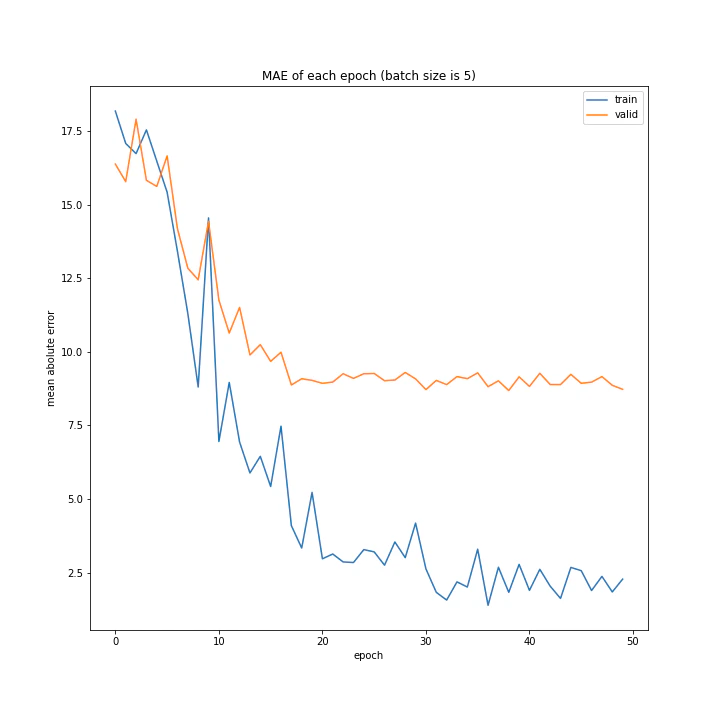
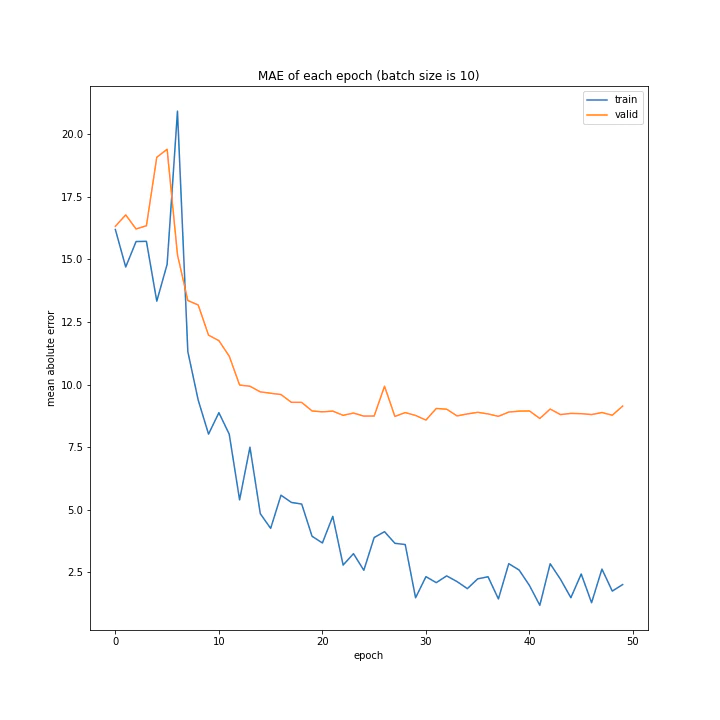
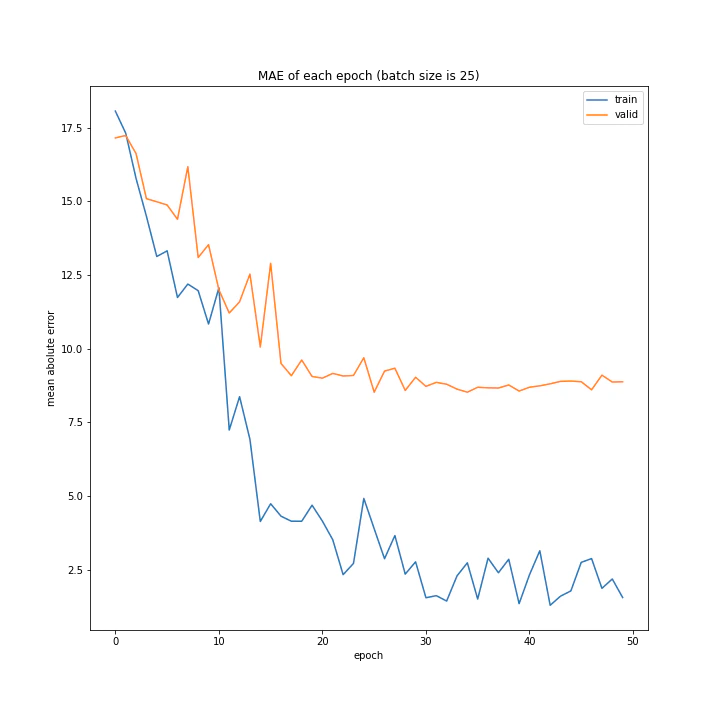
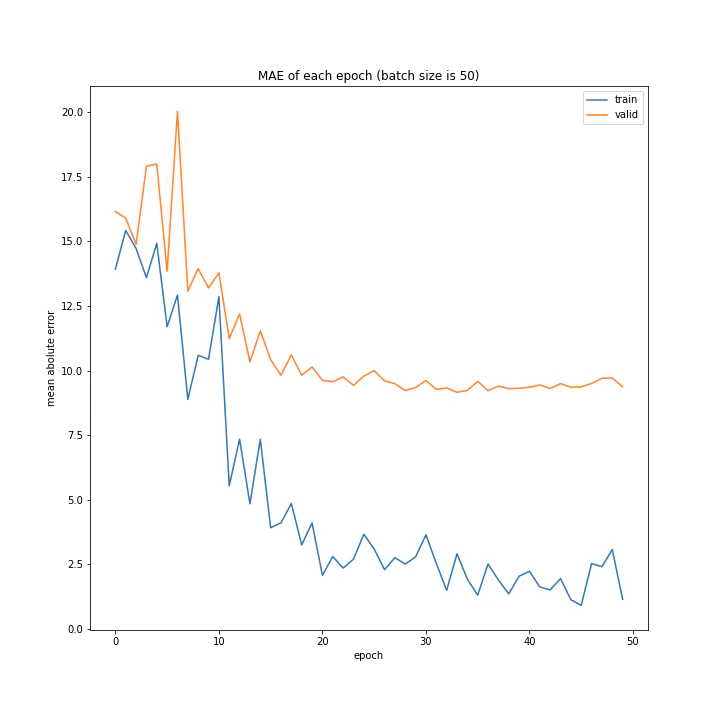
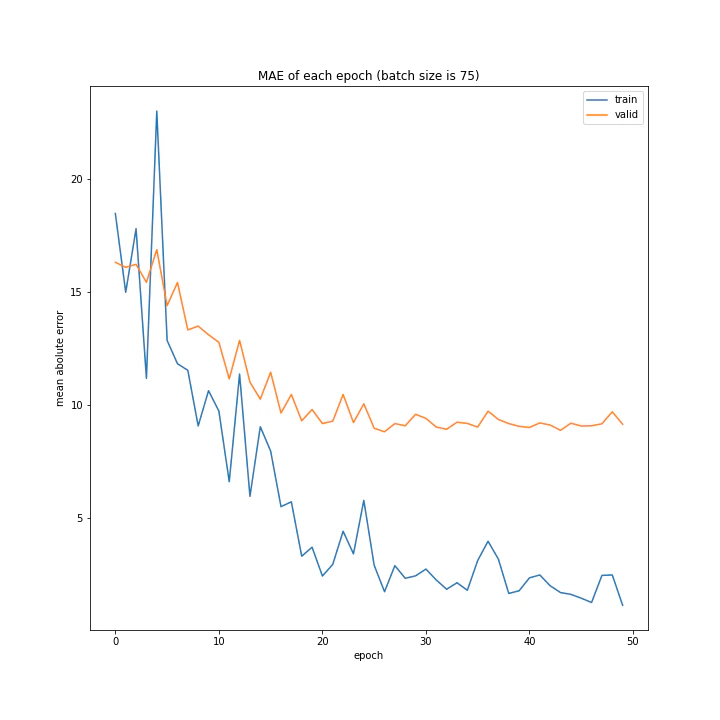
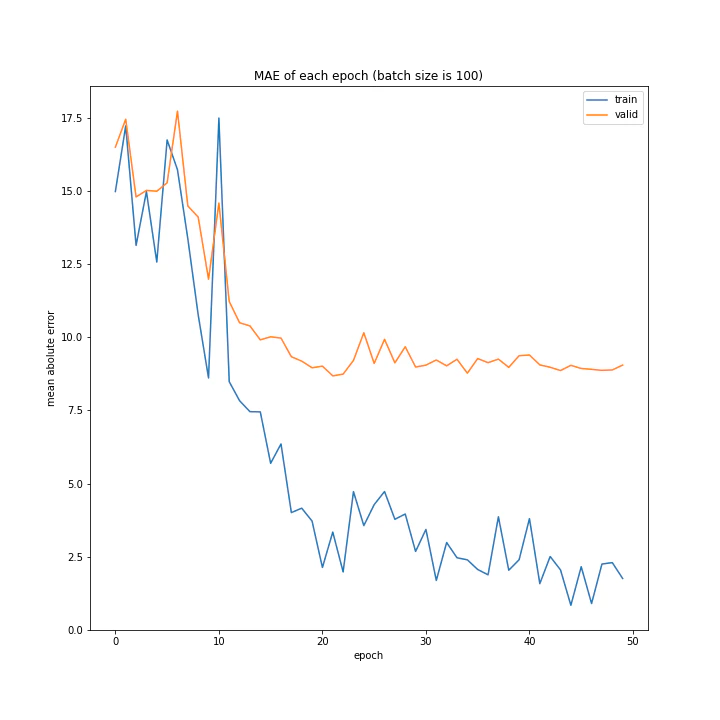
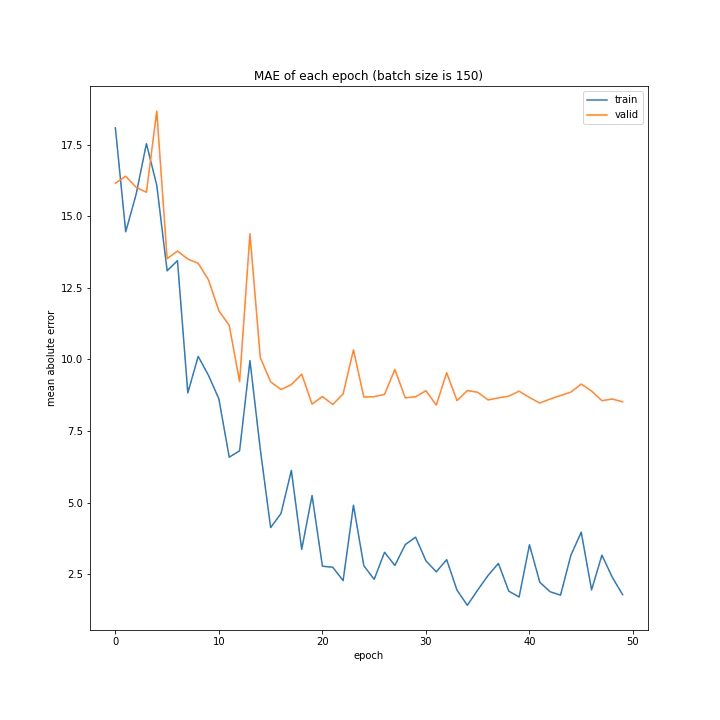
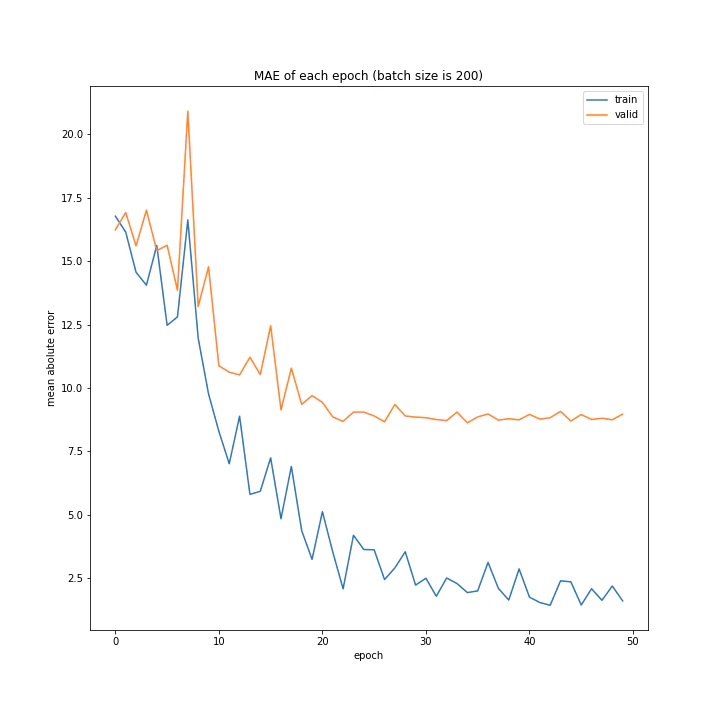
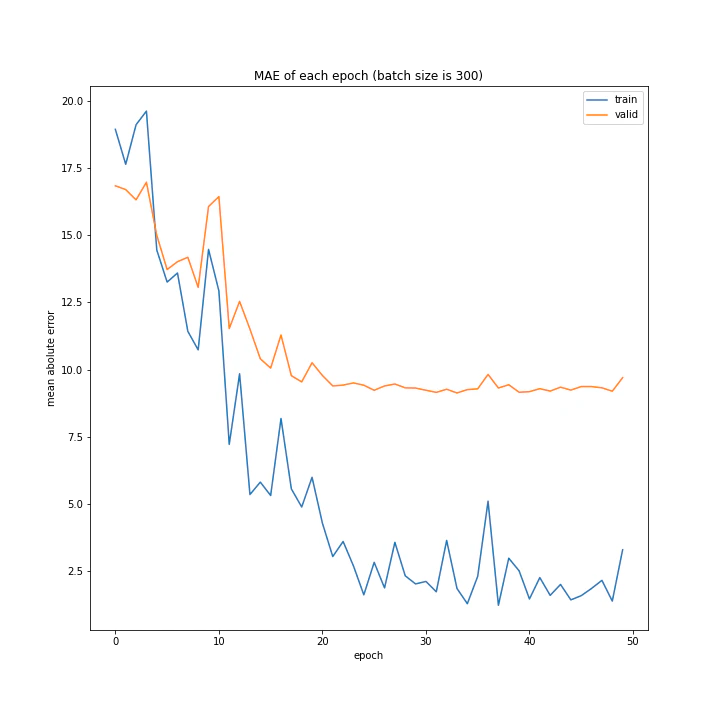
MSE: [variable(208.4556), variable(205.58469), variable(212.24141), variable(205.57669), variable(223.43636), variable(193.73814), variable(199.80457), variable(215.08165), variable(213.957)]
MAE: [variable(9.421841), variable(9.583598), variable(9.503884), variable(9.683197), variable(9.855479), variable(9.166233), variable(8.903477), variable(9.325055), variable(9.886406)]
増やすほど結果がよくなるような、単純な結果にはなりませんでした。
最終結果はどれもほぼ同じでしたが、収束までの時間に差がありました。バッチ数を減らすほど少ないエポック数で最適解に近づいているようです。しかしバッチ数が少ないほど1つのエポックにかかる時間は増加します。
最優秀を決めるとすれば、テストデータでの誤差が小さく、収束までの実時間もそう長くない150でしょうか。
層の数を変更
import Net_box.n_layer as n_layer
run = deep_learn()
Net_arr = [n_layer.Net2, n_layer.Net3, n_layer.Net4, n_layer.Net5]
run.save_dir = "fig/n_layer"
i = 1
MSE_test = []
MAE_test = []
run.set_data()
for Net in Net_arr:
print("\r%d/%d" % (i, len(Net_arr)), end="")
run.Net = Net
run.fig_name1 = "MSE of each epoch (number of layer is %d)" % (i + 1)
run.fig_name2 = "MAE of each epoch (number of layer is %d)" % (i + 1)
run.fit()
run.plot()
test_error = run.cal_test_error()
MSE_test.append(test_error[0])
MAE_test.append(test_error[1])
i += 1
結果はこちら。
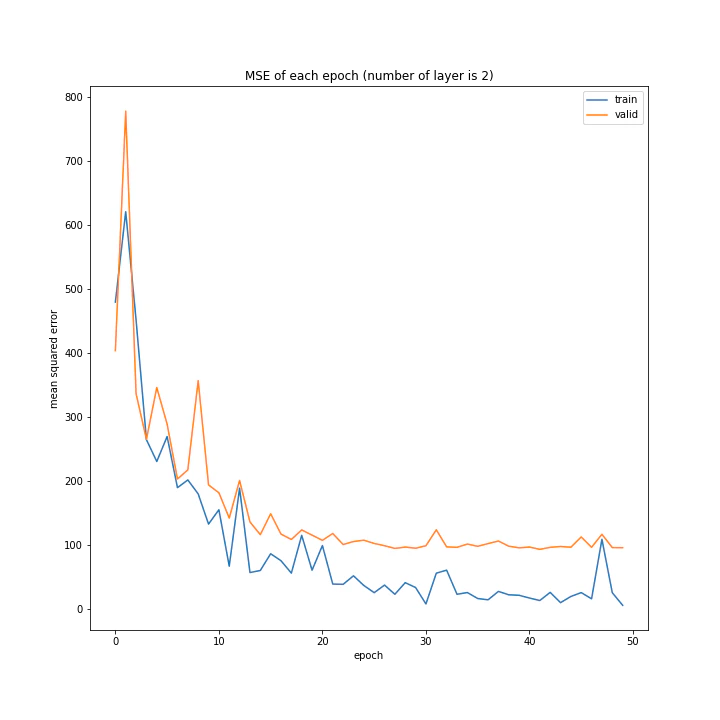
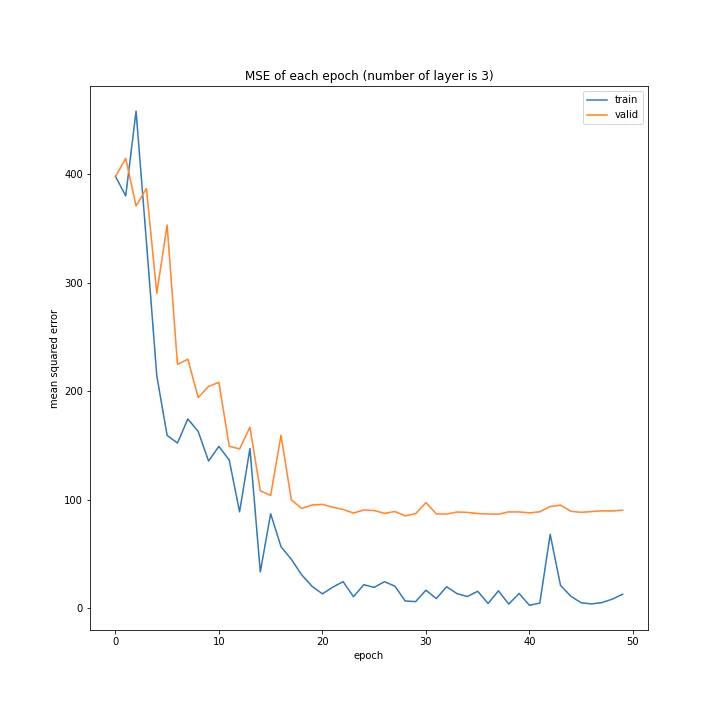
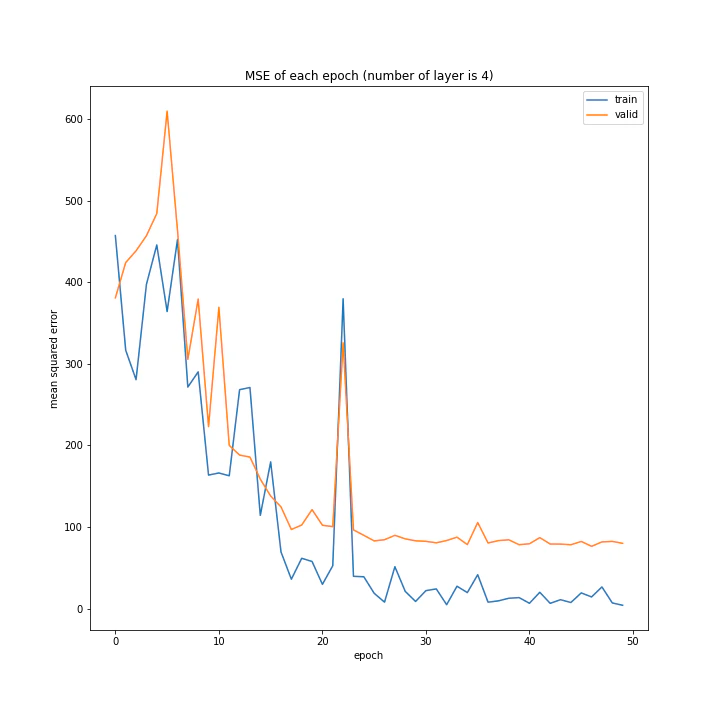
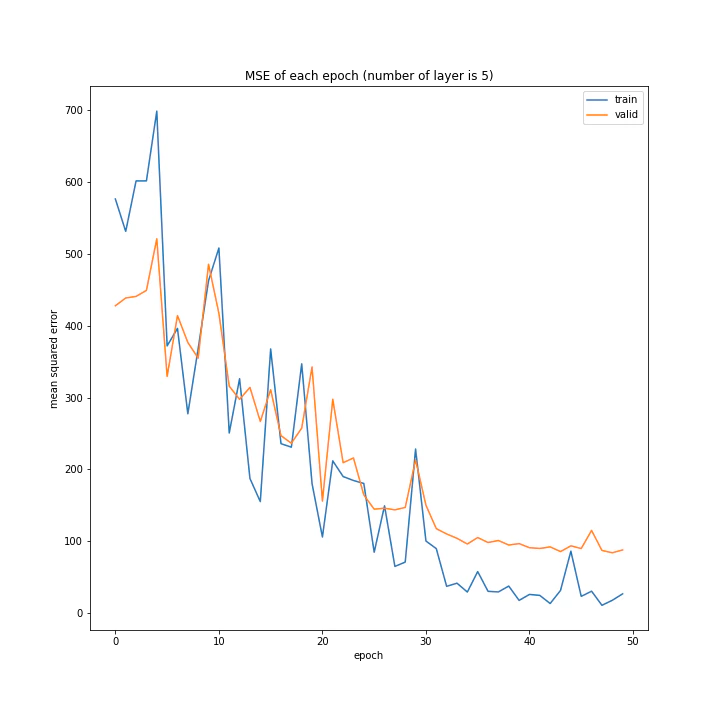
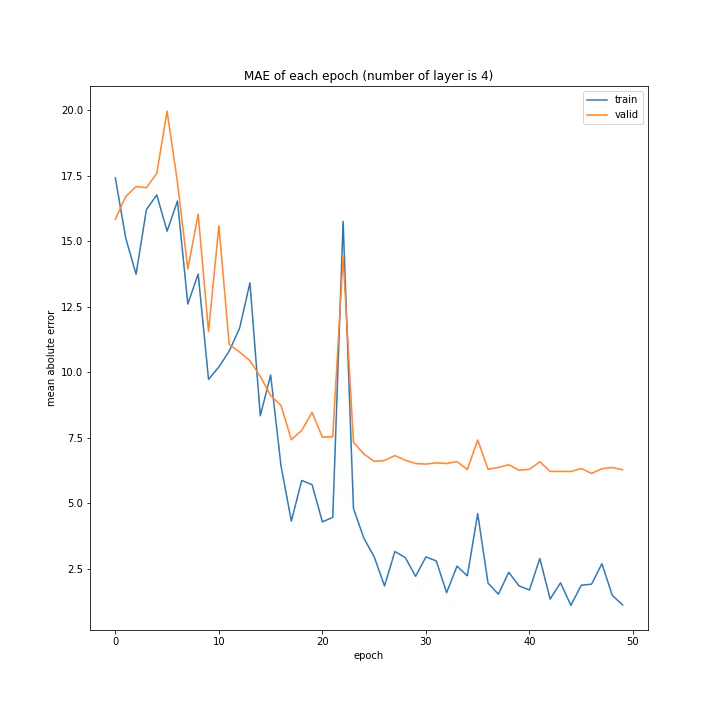
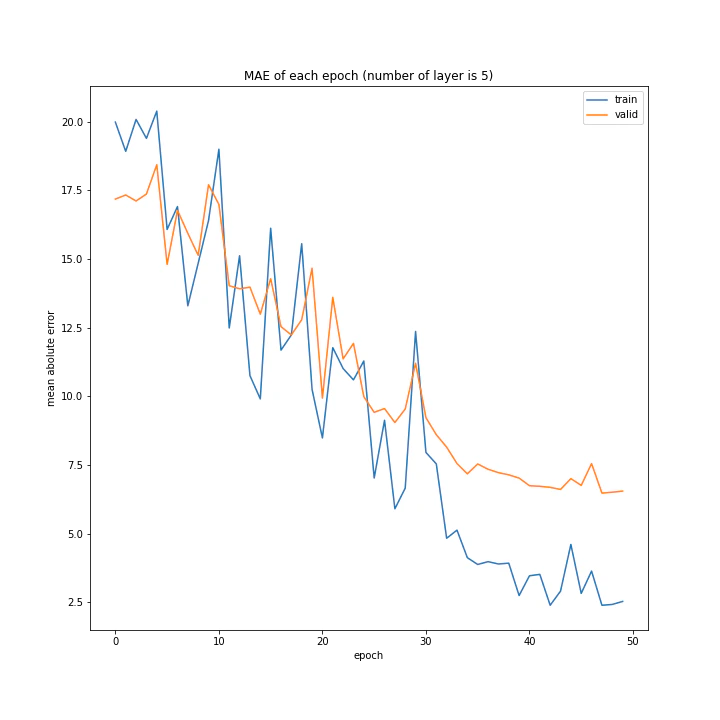
MSE: [variable(108.787415), variable(100.24213), variable(100.931335), variable(117.44594)]
MAE: [variable(7.6647296), variable(7.145885), variable(7.118979), variable(7.5313835)]
層の数を増やすほど精度は上がると予想していましたがそうではないようです。こちらも、バッチサイズと同じく最終的な誤差はほぼ同じ結果となりました。
また、層の数が増えるほど収束に時間がかかるようです。これは、層の数が増えるほど調整しなければならないパラメータが増えるためだと思われます。
テストデータでの最優秀は4層ですが、20付近で一度誤差が大きくなっていること、また3層の方が収束が早く精度もそう変わらないことから3層が最優秀と考えました。
活性化関数の種類を変更
前回用いたrelu、今回用いたtanh、マイナス値の存在するelu、leaky_relu、rrelu、seluについて調べました。
import Net_box.kind_function as kind_f
run = deep_learn()
f_arr = kind_f.functions_arr
f_name = kind_f.functions_name
run.save_dir = "fig/kind_function"
i = 1
MSE_test = []
MAE_test = []
run.set_data()
for function in f_arr:
print("\r%d/%d" % (i, len(f_arr)), end="")
kind_f.func = function
run.Net = kind_f.Net
run.fig_name1 = "MSE of each epoch (function is %s)" % f_name[i - 1]
run.fig_name2 = "MAE of each epoch (function is %s)" % f_name[i - 1]
run.fit()
run.plot()
test_error = run.cal_test_error()
MSE_test.append(test_error[0])
MAE_test.append(test_error[1])
i += 1
結果は、reluとtanh以外nanになりました。
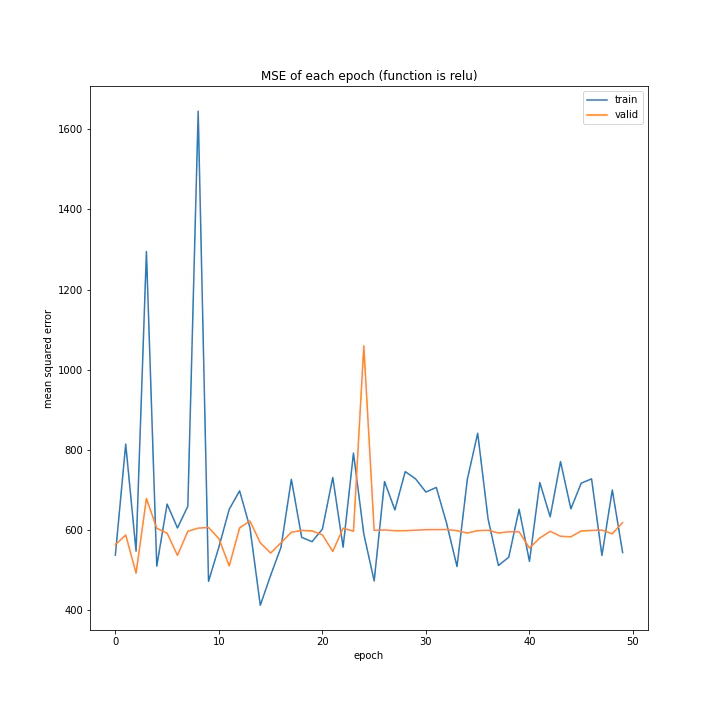
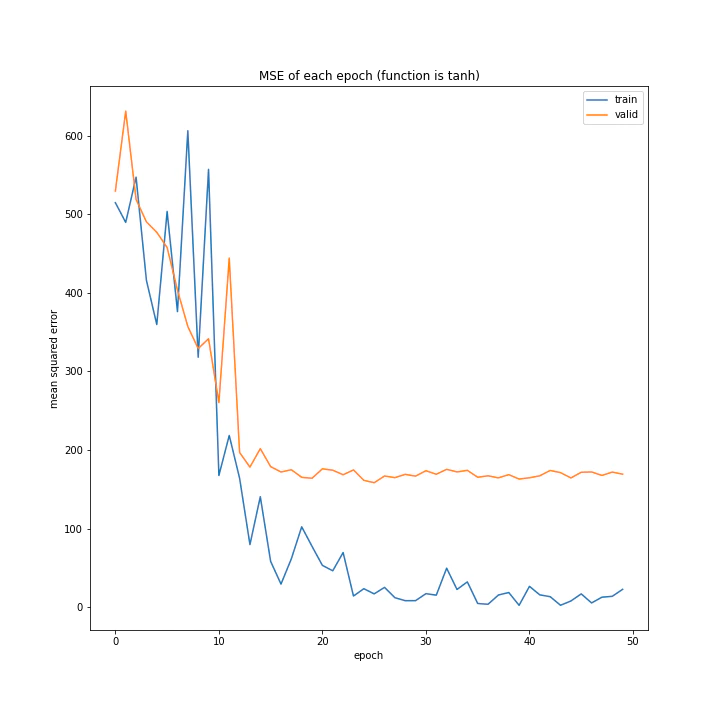
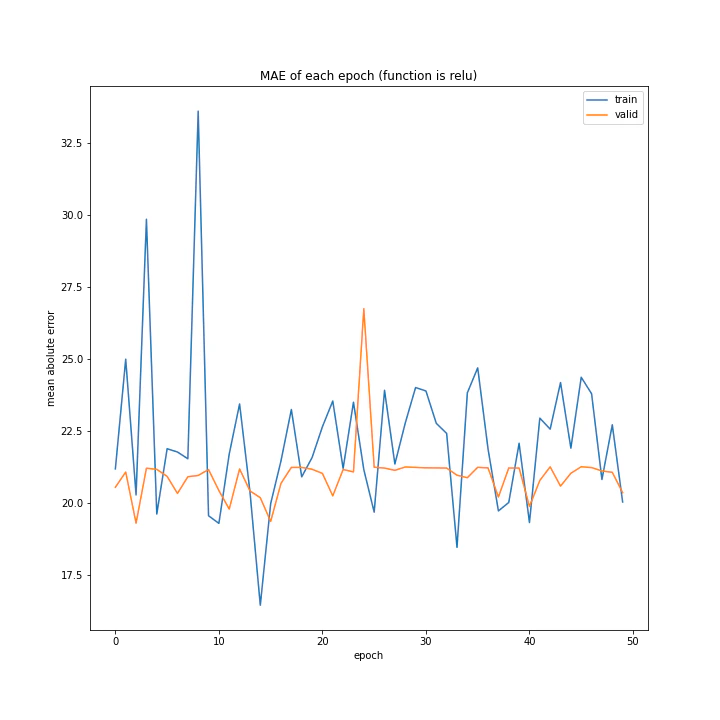
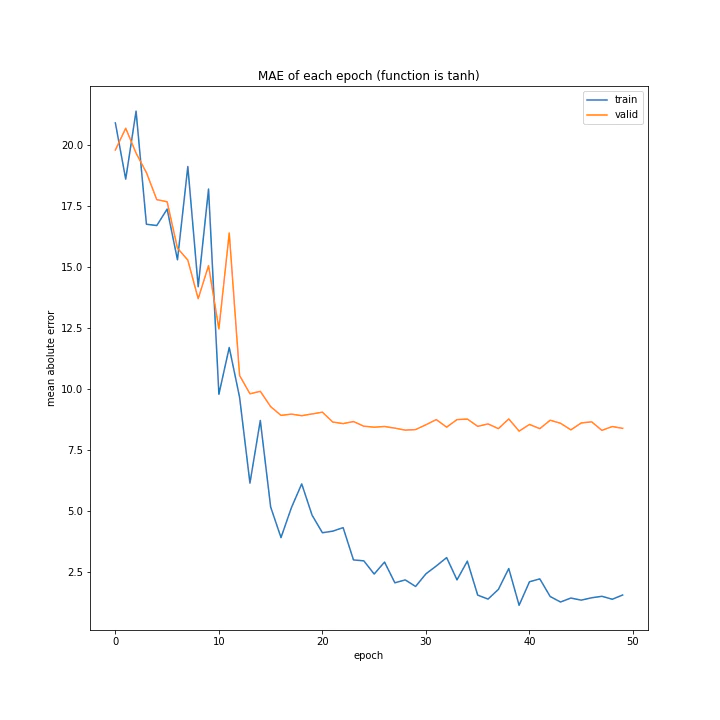
['relu', 'tanh', 'elu', 'leaky_relu', 'rrelu', 'selu']
MSE: [variable(555.87366), variable(204.87903), variable(nan), variable(nan), variable(nan), variable(nan)]
MAE: [variable(19.49682), variable(9.199303), variable(nan), variable(nan), variable(nan), variable(nan)]
reluとtanh以外はデータが取れず、reluは全く学習していないことがグラフからも分かります。
消去法でtanhを選ぶべきでしょう。
学習率を変更
run = deep_learn()
run.Net = plane.Net
lr_arr = [0.0001, 0.0005, 0.001, 0.005, 0.01, 0.025, 0.05, 0.1, 0.2, 0.3]
run.save_dir = "fig/lr"
i = 1
MSE_test = []
MAE_test = []
run.set_data()
for lr in lr_arr:
print("\r%d/%d" % (i, len(lr_arr)), end="")
run.lr = lr
run.fig_name1 = "MSE of each epoch (lr is %f).png" % lr
run.fig_name2 = "MAE of each epoch (lr is %f).png" % lr
run.fit()
run.plot()
test_error = run.cal_test_error()
MSE_test.append(test_error[0])
MAE_test.append(test_error[1])
i += 1
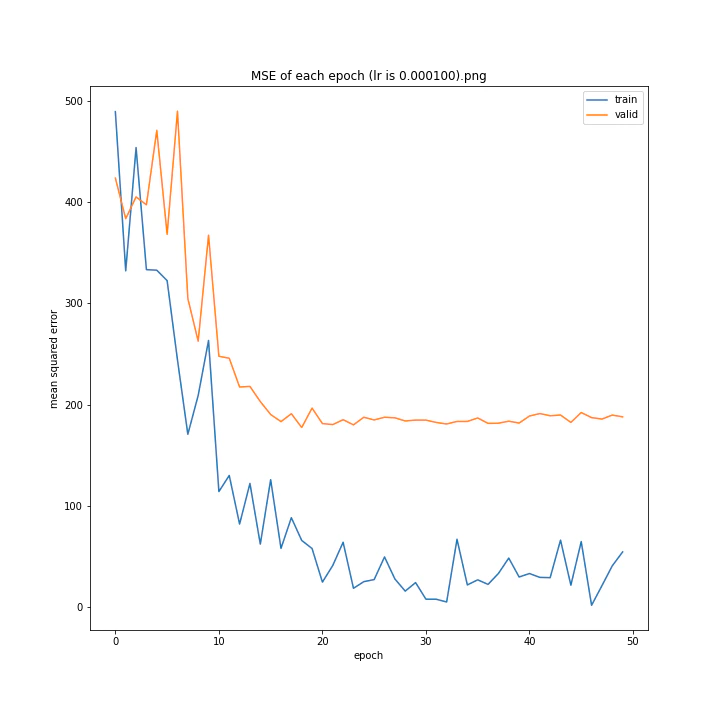
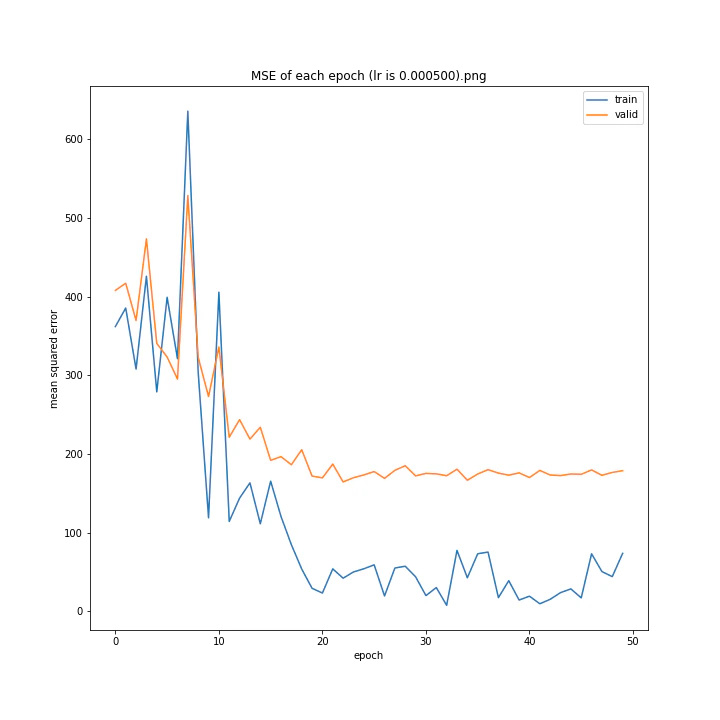
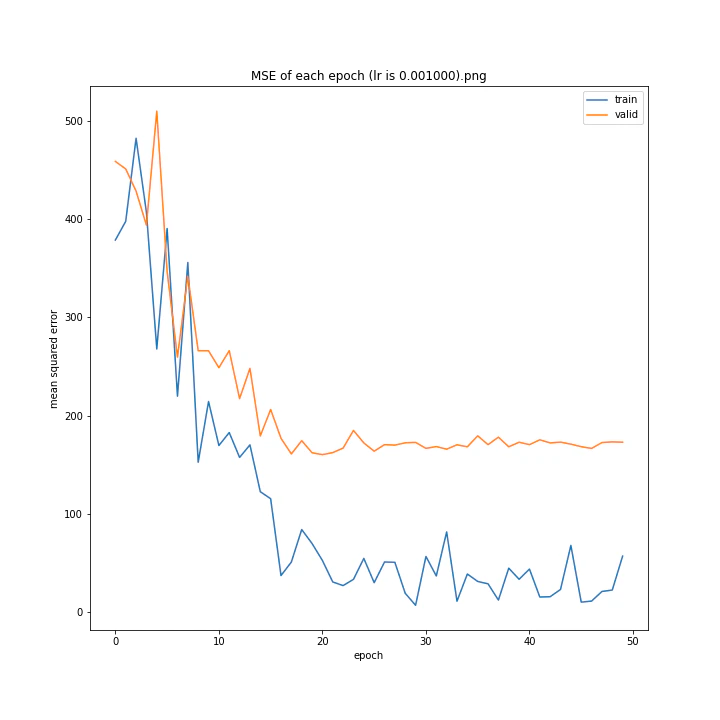
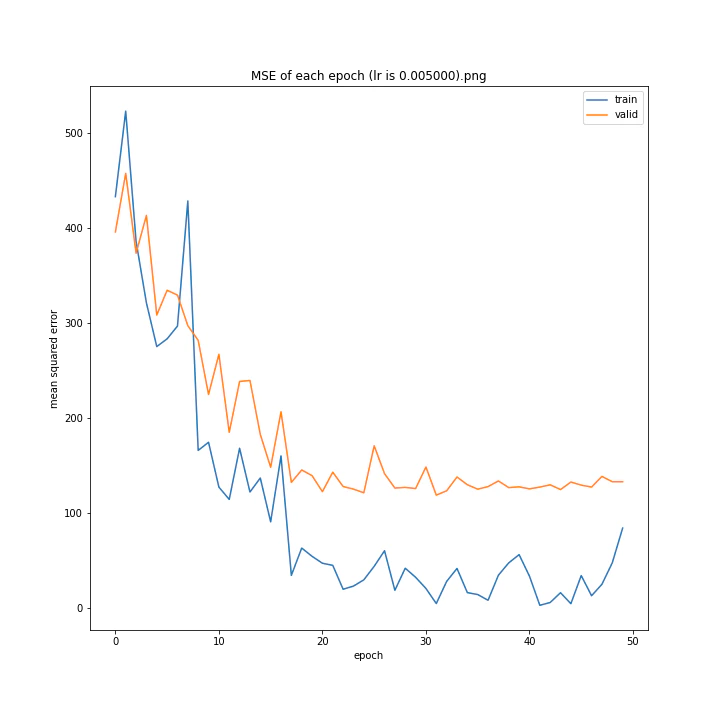
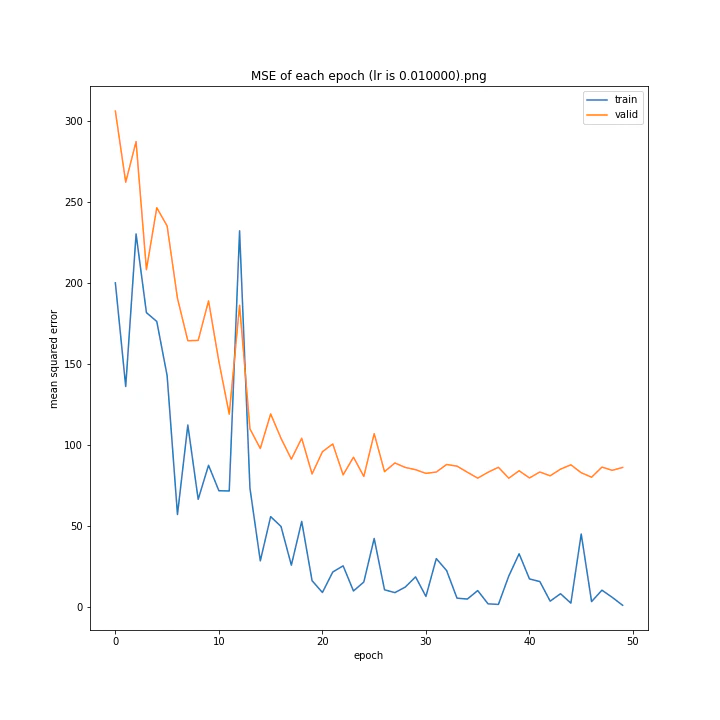
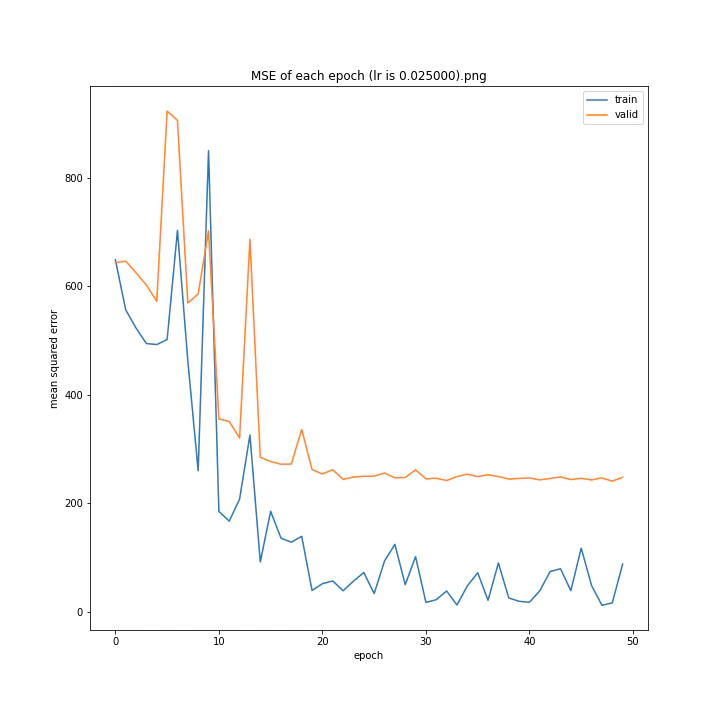
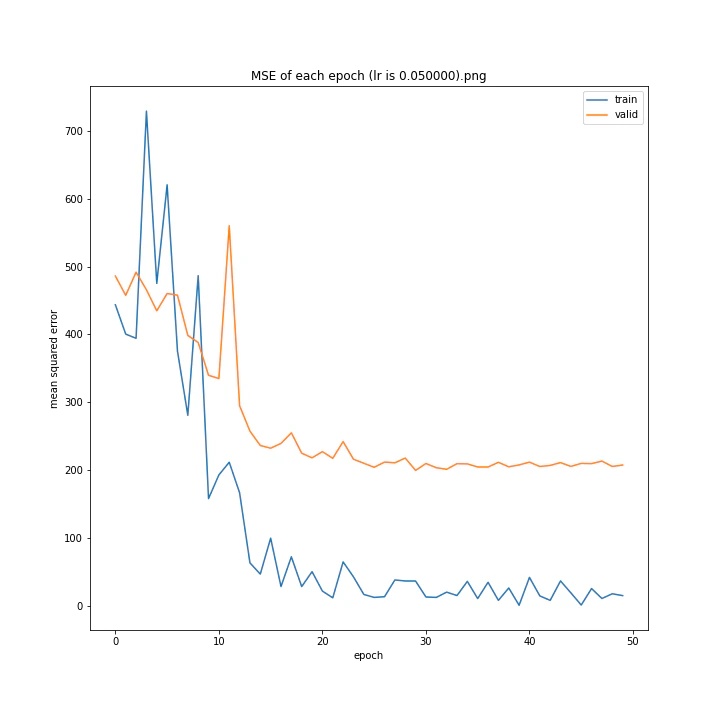
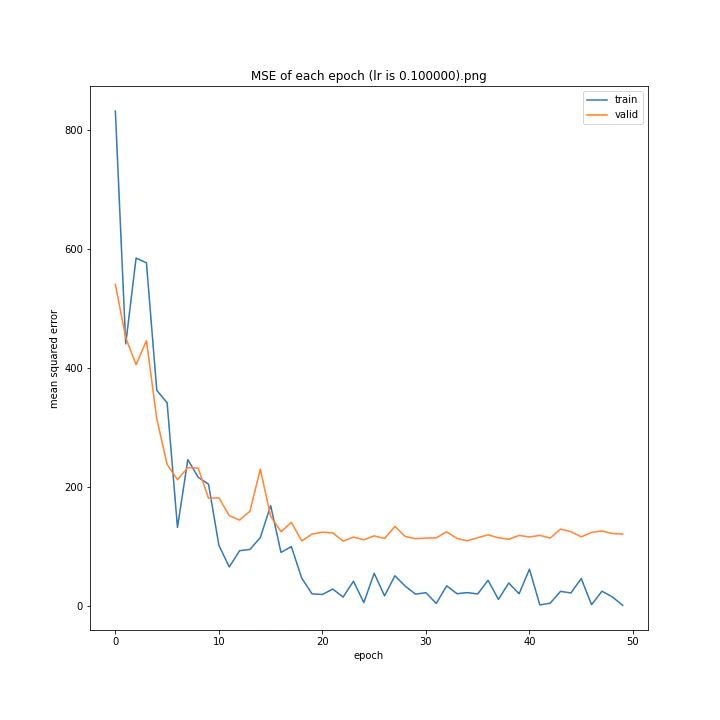
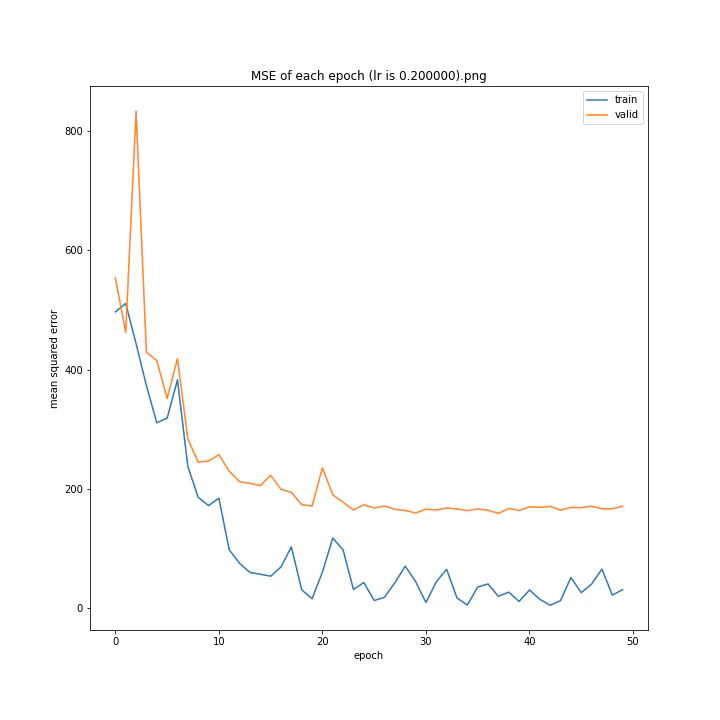
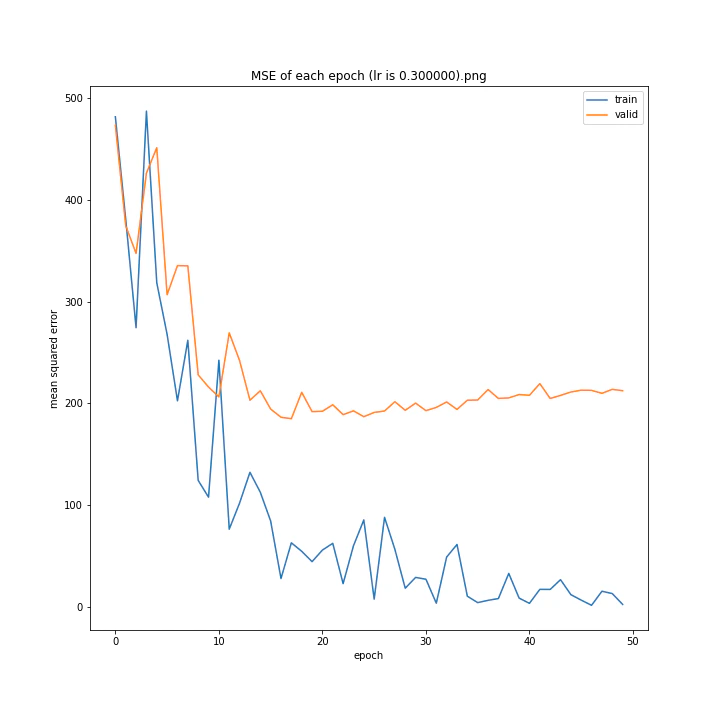
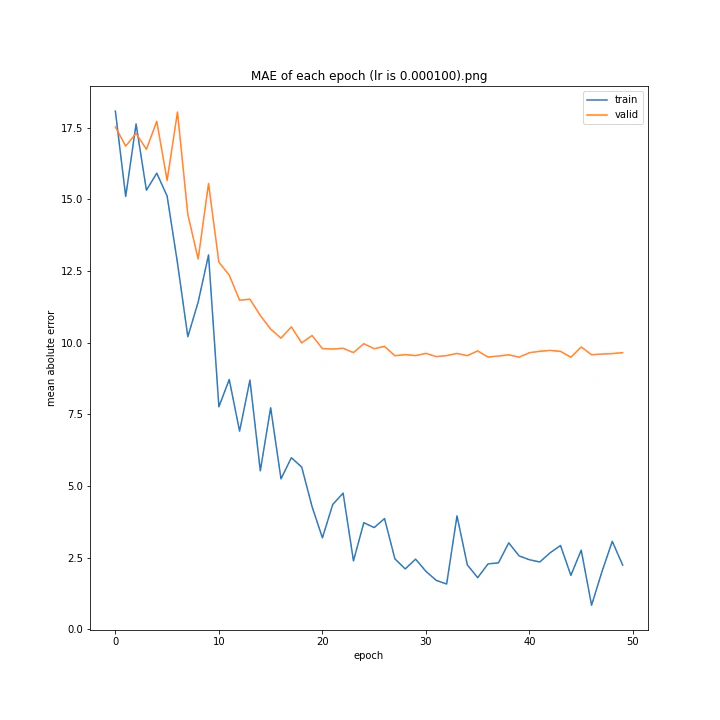
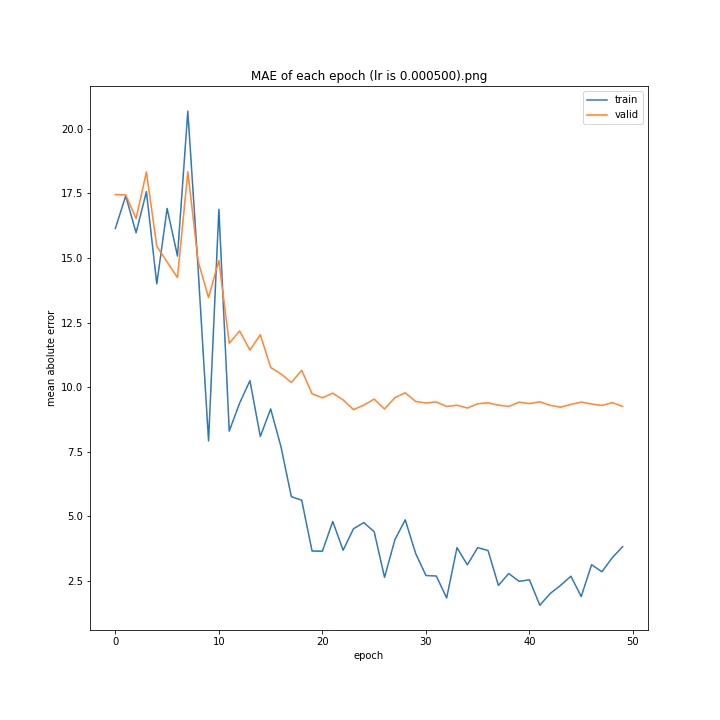
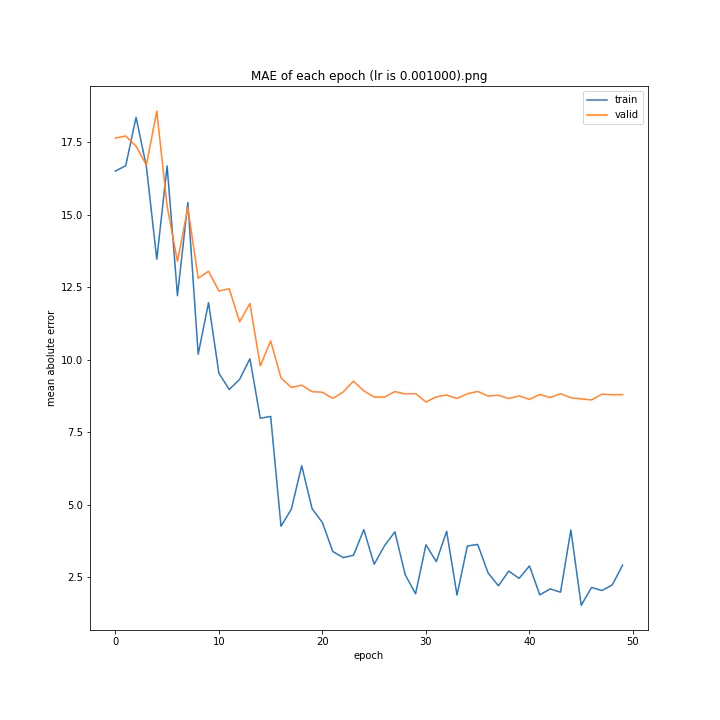
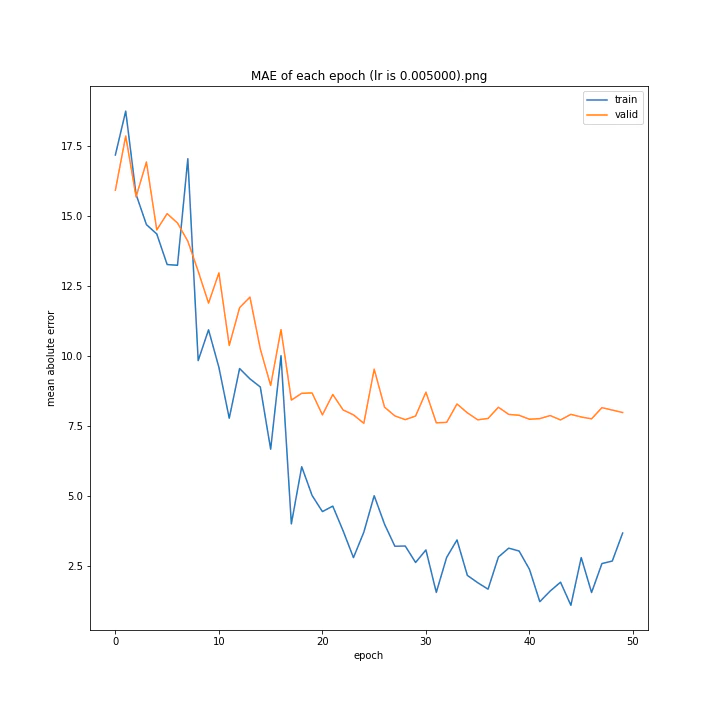
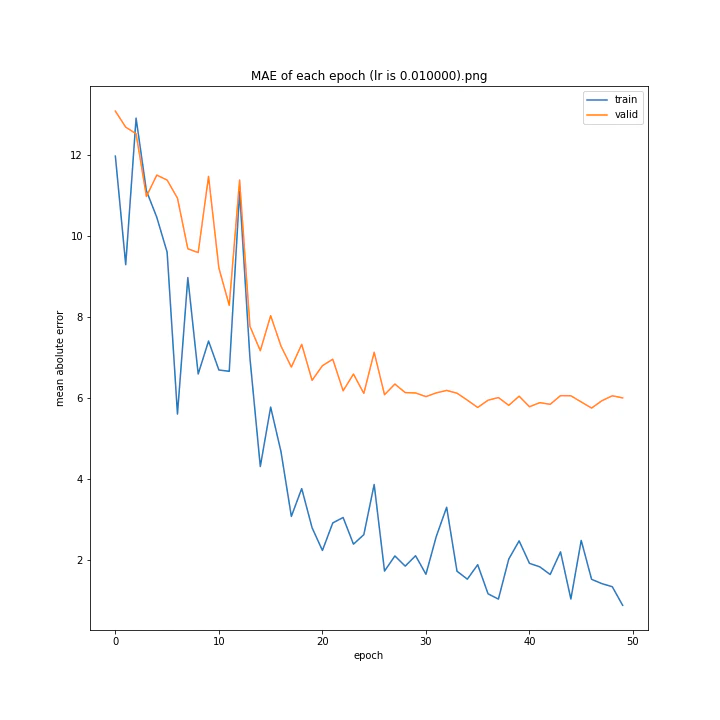
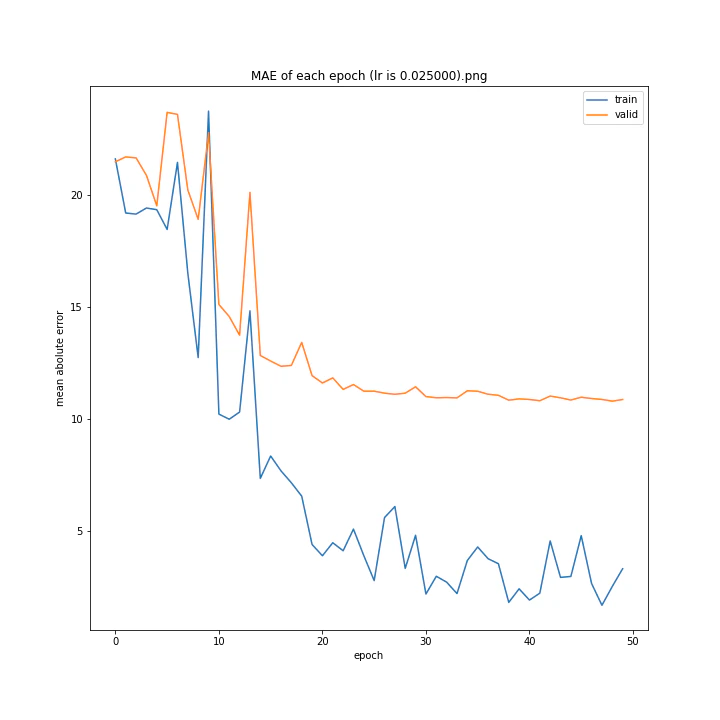
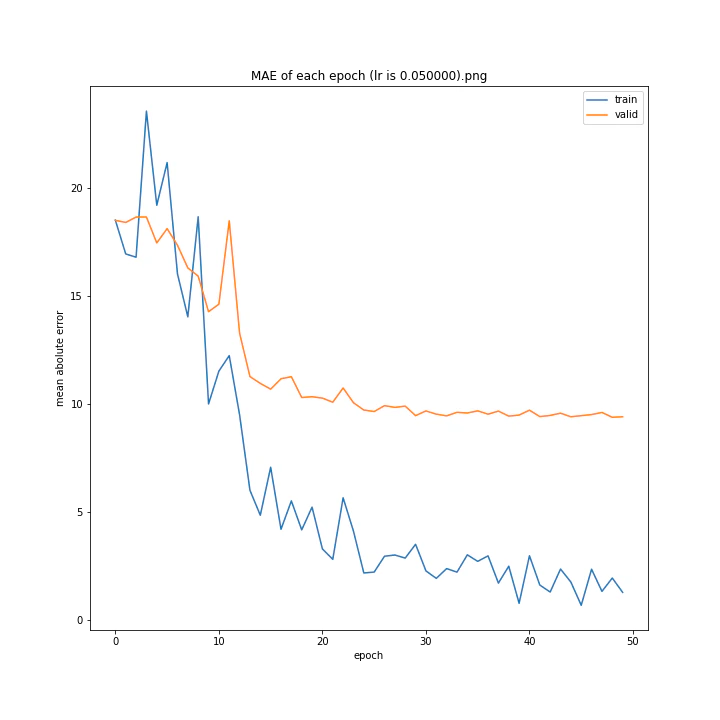
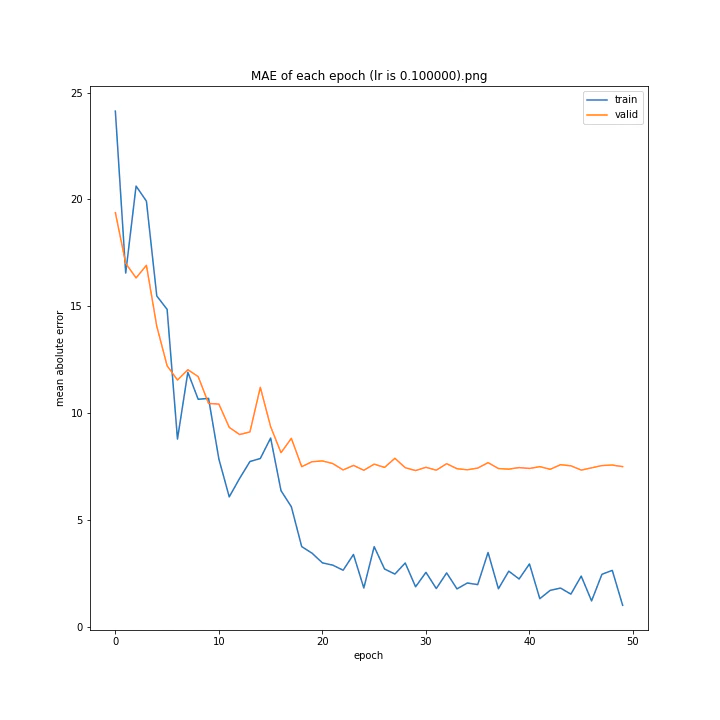
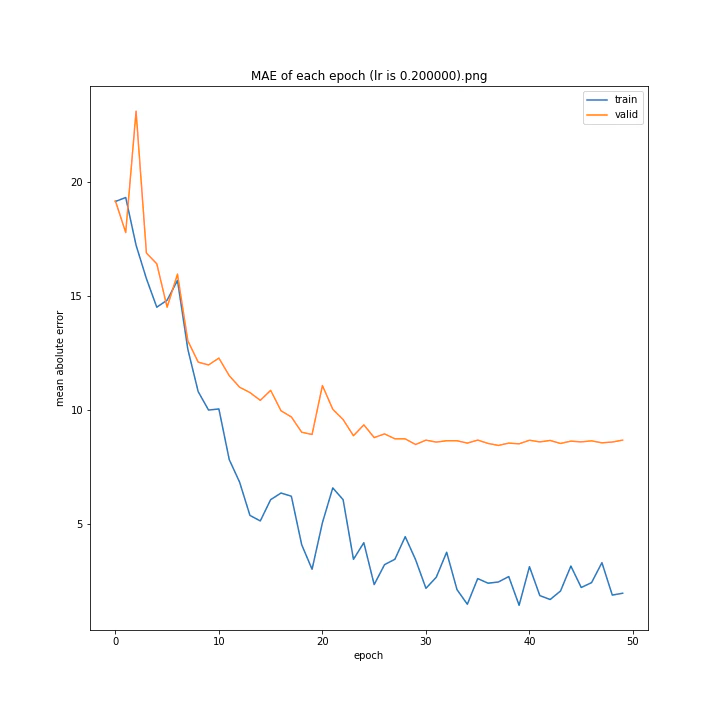
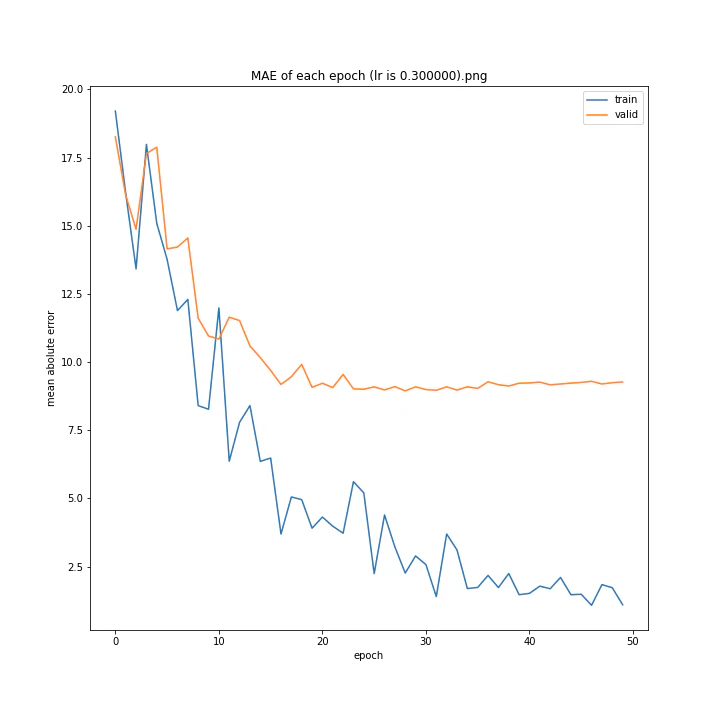
MSE: [variable(170.00241), variable(171.05908), variable(181.1228), variable(192.46042), variable(161.02898), variable(163.08765), variable(170.65488), variable(177.69069), variable(170.5684), variable(163.26263)]
MAE: [variable(8.892699), variable(8.849699), variable(9.052602), variable(9.407764), variable(8.696438), variable(8.609232), variable(8.800114), variable(8.914179), variable(8.9228115), variable(8.645447)]
最終結果に大きな差異はなかったですが、0.3については30以降、確認データの誤差が大きくなっているのが気になりました。
0.01が最優秀でした。
最適化関数を変更
URLに載っていた最適化関数の中で、chainerで実装されていたものをすべて試してみました。
# https://qiita.com/ZoneTsuyoshi/items/8ef6fa1e154d176e25b8
from chainer import optimizers
opt_arr = [
optimizers.SGD(),
optimizers.MomentumSGD(),
optimizers.AdaGrad(),
optimizers.RMSprop(),
optimizers.AdaDelta(),
optimizers.Adam(),
optimizers.RMSpropGraves(),
optimizers.SMORMS3(),
optimizers.AMSGrad(),
optimizers.AdaBound(),
optimizers.AMSBound()
]
opt_name = [
"SGD",
"MomentumSGD",
"AdaGrad",
"RmSprop",
"AdaDelta",
"Adam",
"RMSpropGraves",
"SMORMS3",
"AMSGrad",
"AdaBound",
"AMSBound"
]
run = deep_learn()
run.Net = plane.Net
run.save_dir = "fig/optimizer"
i = 1
MSE_test = []
MAE_test = []
run.set_data()
for opt in opt_arr:
print("\r%d/%d" % (i, len(opt_arr)), end="")
run.optimizer = opt
run.fig_name1 = "MSE of each epoch (optimizer is %s)" % opt_name[i - 1]
run.fig_name2 = "MAE of each epoch (optimizer is %s)" % opt_name[i - 1]
run.fit()
run.plot()
test_error = run.cal_test_error()
MSE_test.append(test_error[0])
MAE_test.append(test_error[1])
i += 1
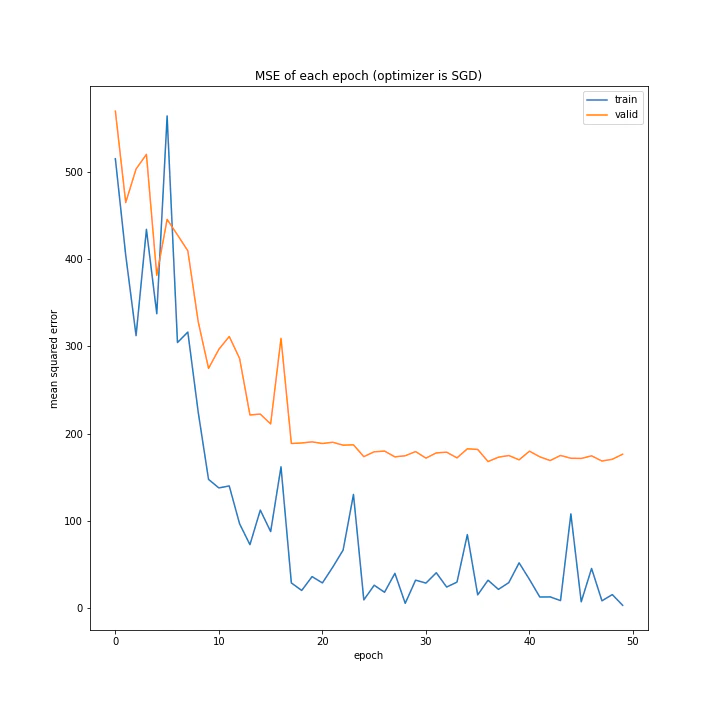
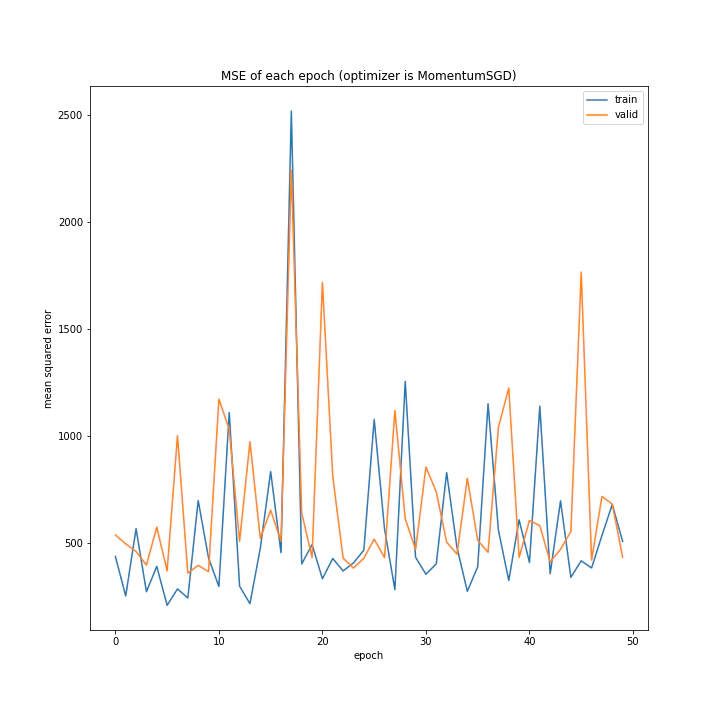
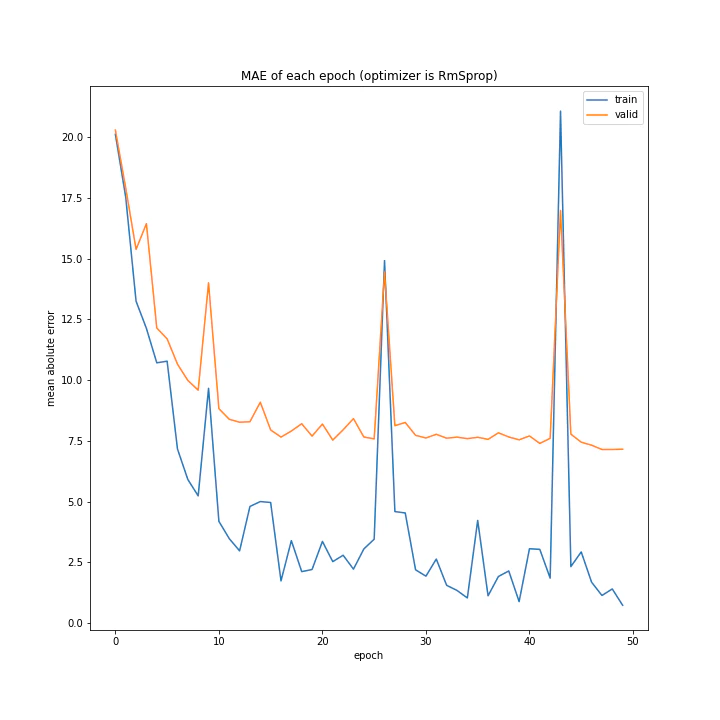
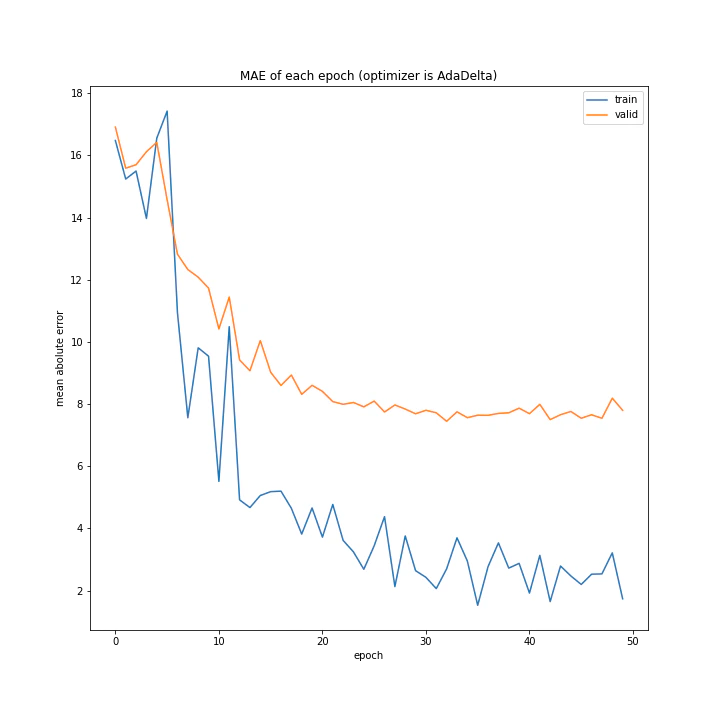
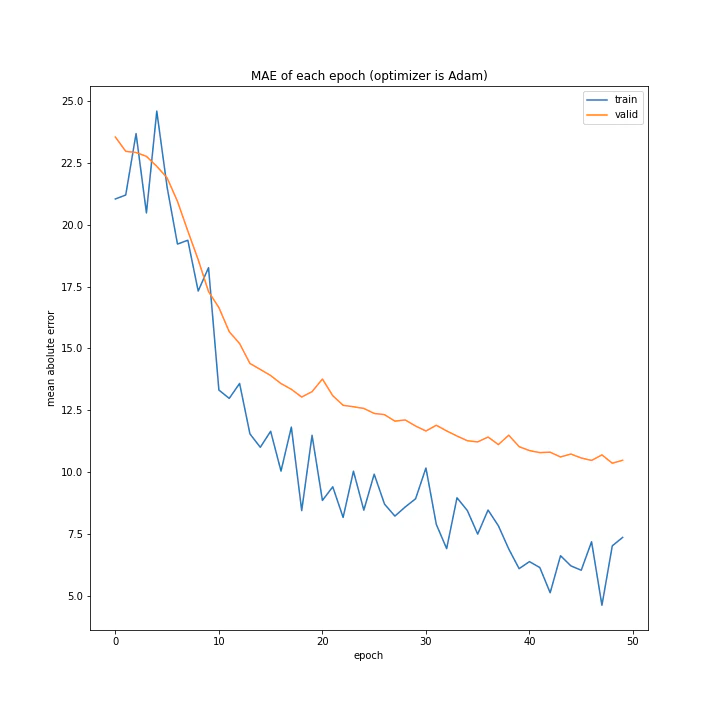
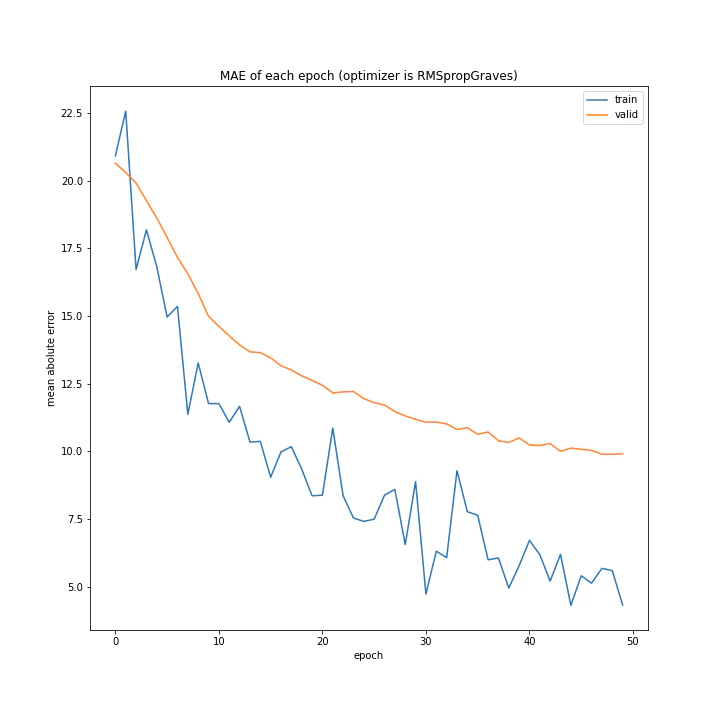
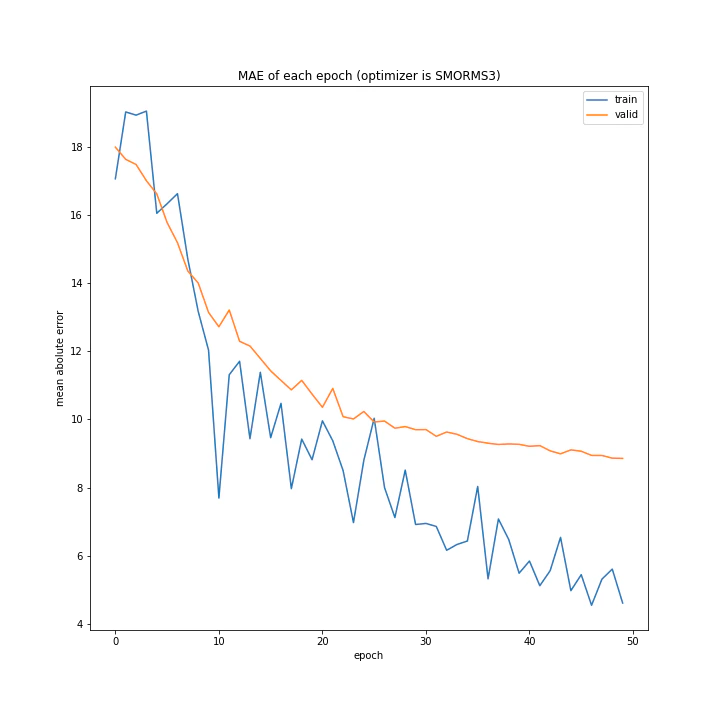
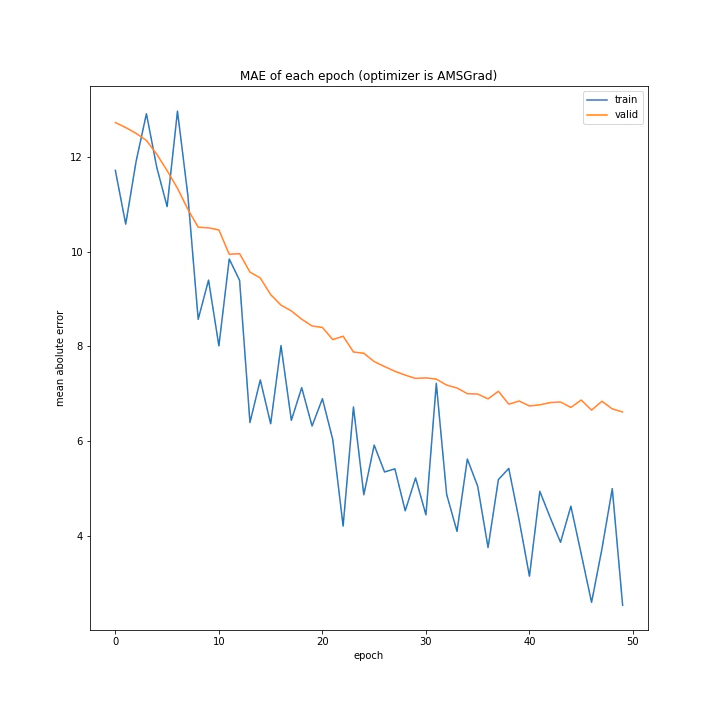
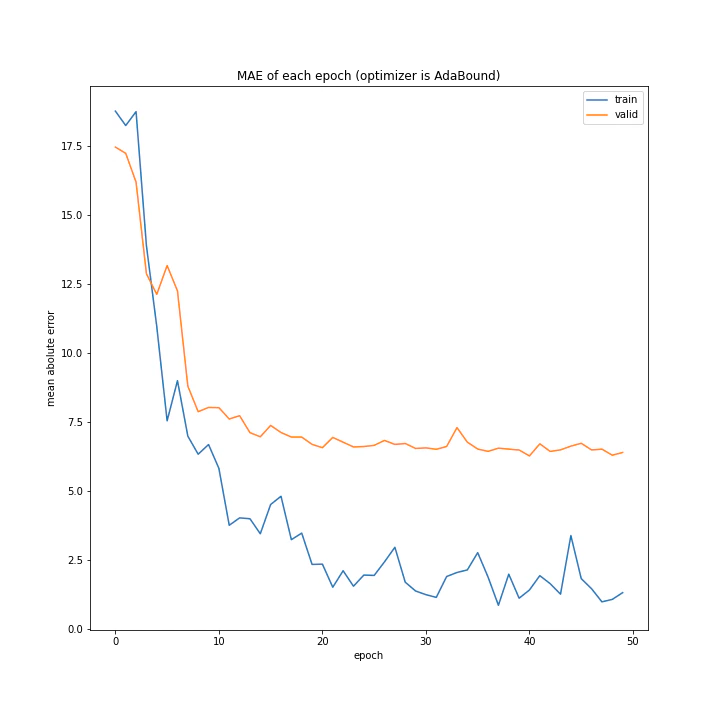
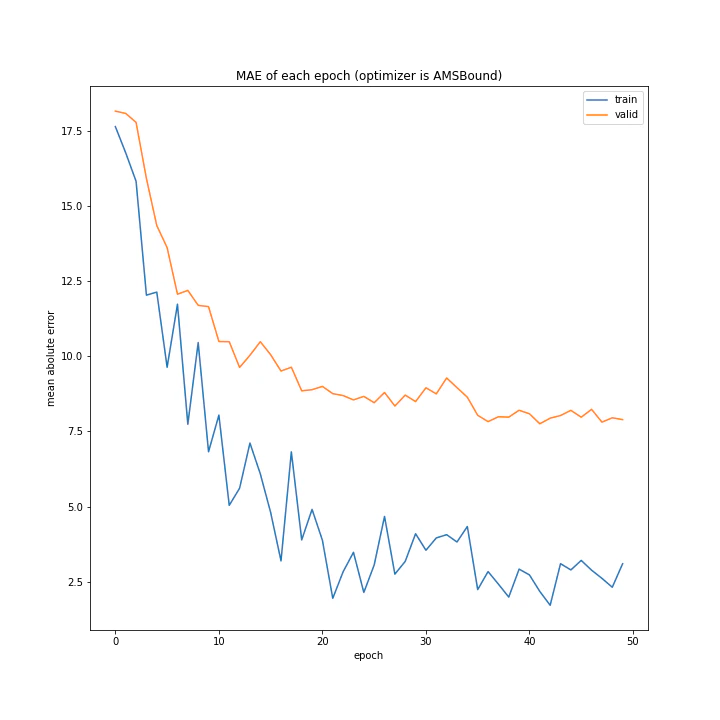
['SGD', 'MomentumSGD', 'AdaGrad', 'RmSprop', 'AdaDelta', 'Adam', 'RMSpropGraves', 'SMORMS3', 'AMSGrad', 'AdaBound', 'AMSBound']
MSE: [variable(140.35452), variable(351.79584), variable(362.52658), variable(130.66309), variable(105.02744), variable(230.22269), variable(200.24446), variable(137.35747), variable(74.48441), variable(104.179436), variable(163.56358)]
MAE: [variable(7.8985395), variable(15.806046), variable(14.46501), variable(7.234192), variable(6.230004), variable(10.566997), variable(10.3872595), variable(8.752416), variable(6.492539), variable(5.505145), variable(8.154634)]
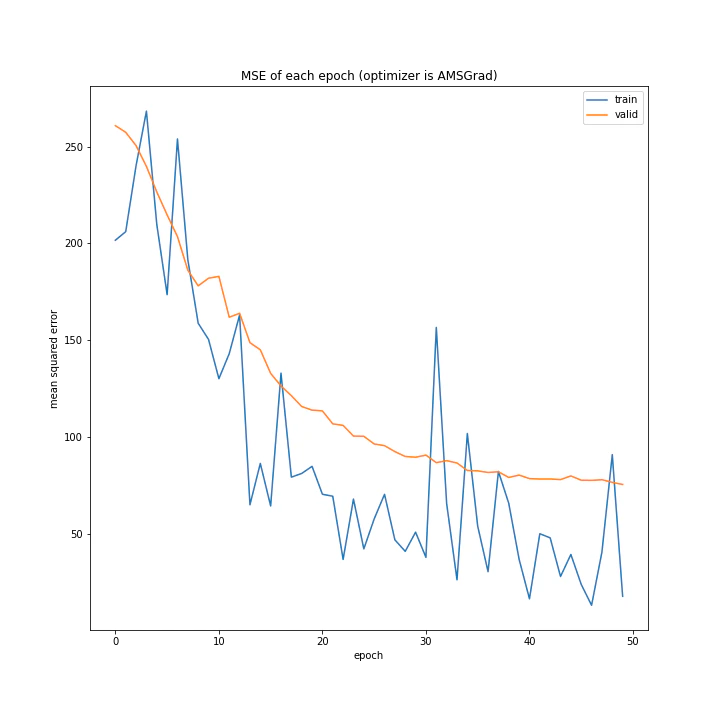
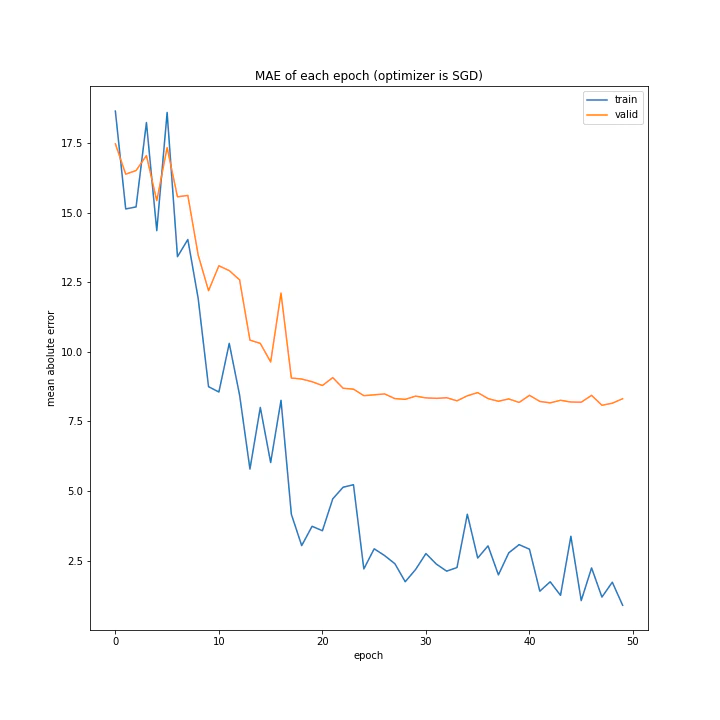
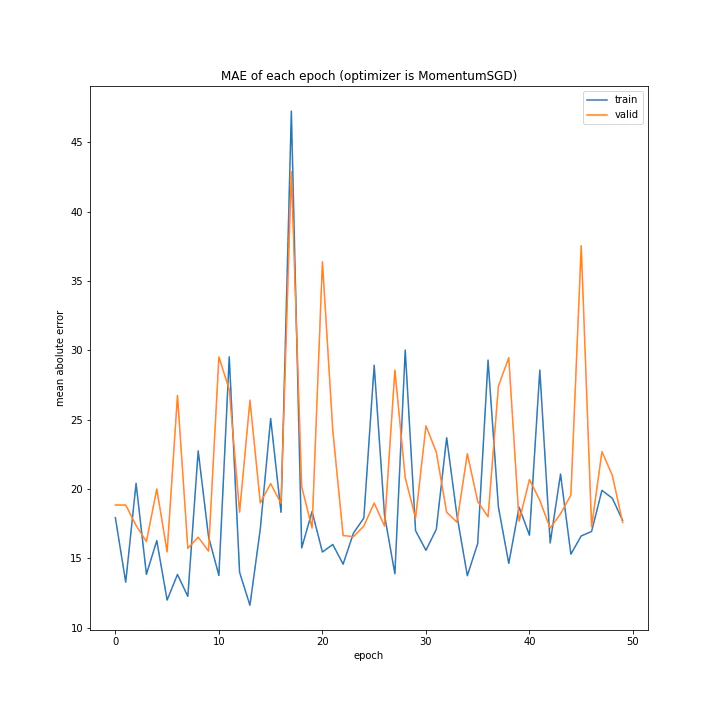
MomentumSGDは誤差もあり得ないほど大きいし学習も全くしていない尖った結果になりました。SGDは問題なく学習できているので、この場合一昔前の勾配情報は必要ない、むしろ悪手であると考えられます。またMomentumSGDのグラフを見ると波打っていること、また盤面から最終結果を予測するという今回の課題から、評価関数の谷は非常にたくさんあると考えられます。
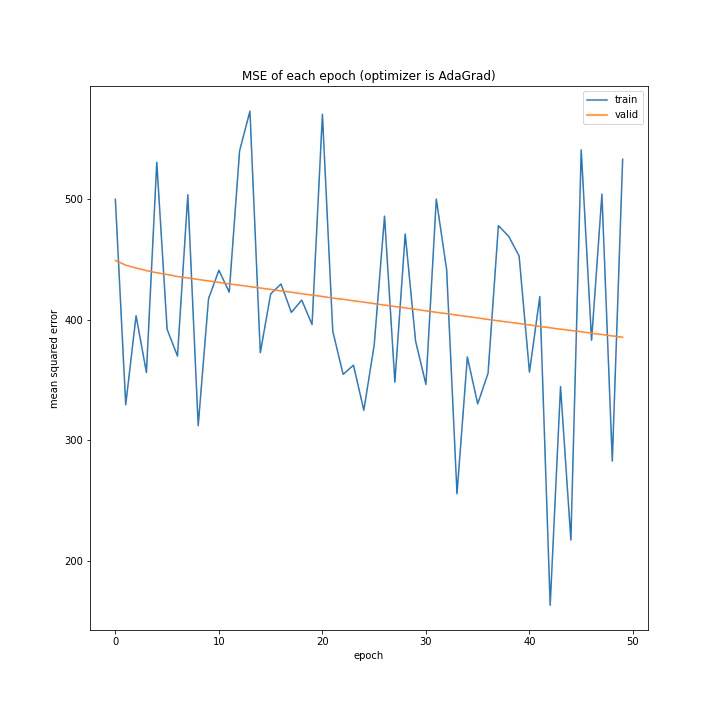
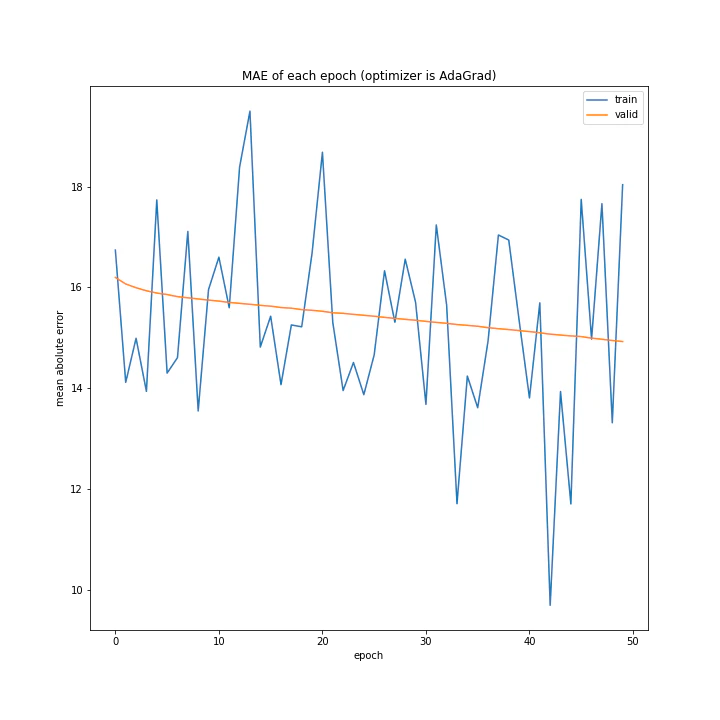
AdaGradも個性的な結果になりました。各変数ごとに勾配に応じて重みを更新するアルゴリズムですが、非常にゆっくり学習していることから、評価関数には非常に深い谷が存在する可能性もあると考えました。
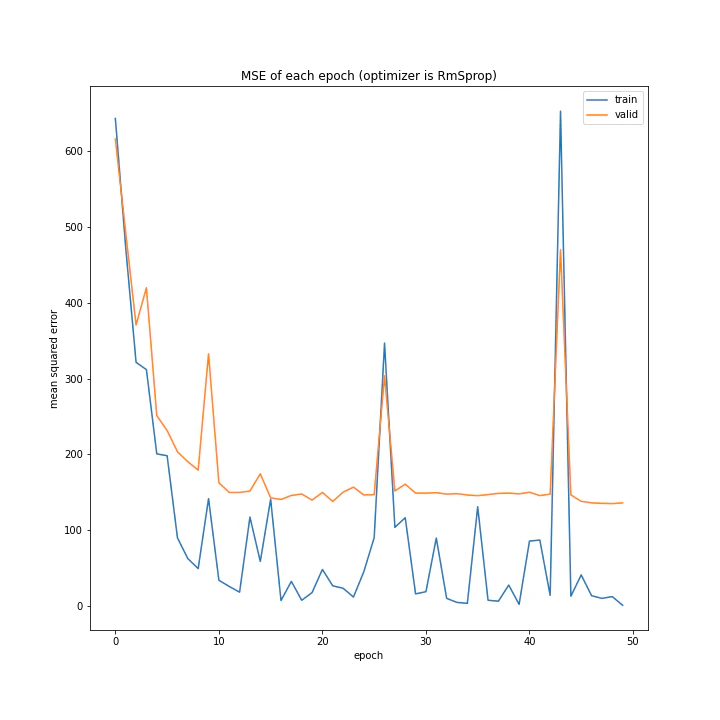
RmSpropのグラフは大きな山が複数できる結果になりました。これはある程度過去の勾配情報は無視するアルゴリズムなのですが、それが(山を除き)SGDに近い形のグラフを作っているということは、やはり評価関数には大きな谷があるということでしょうか。よく分かりません。
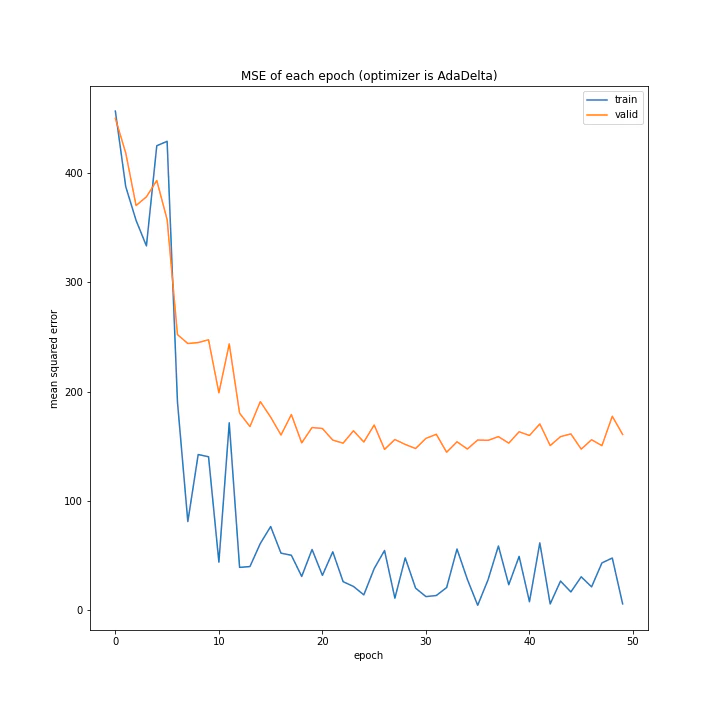
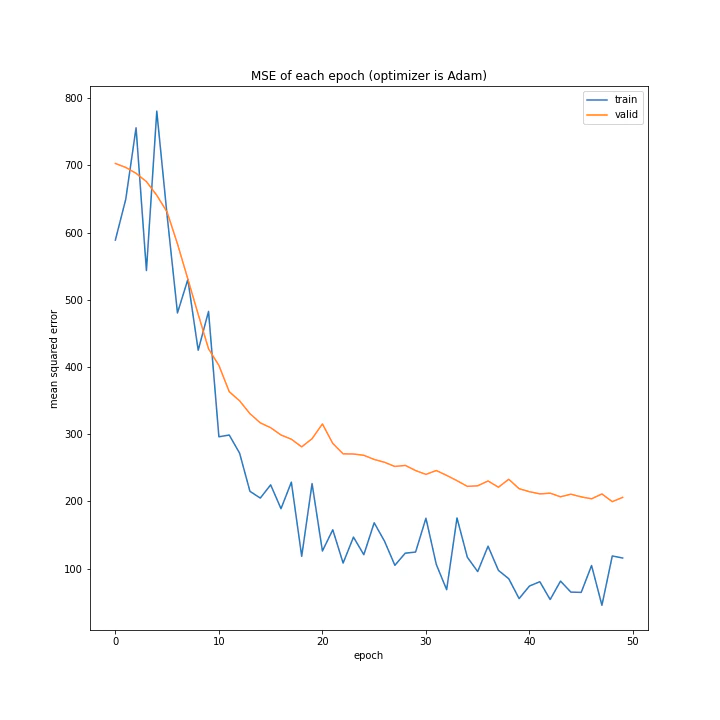
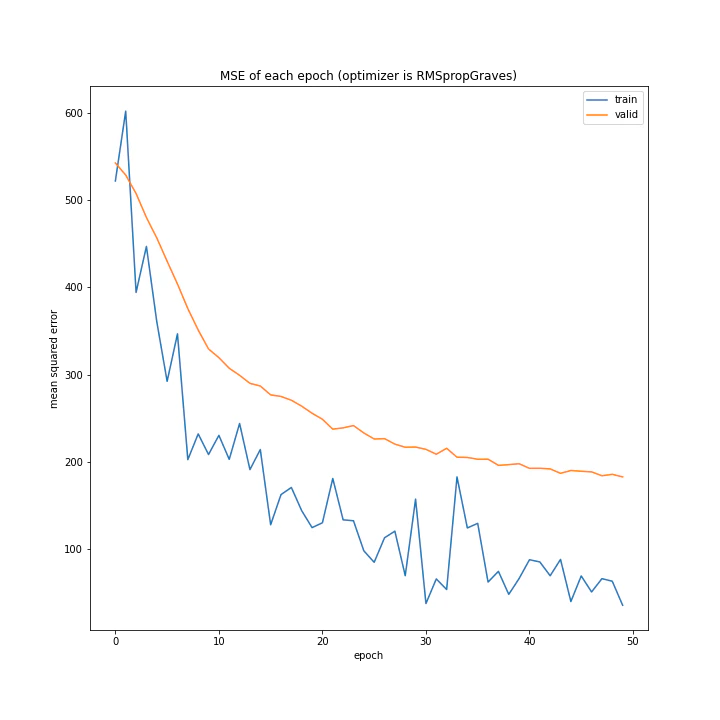
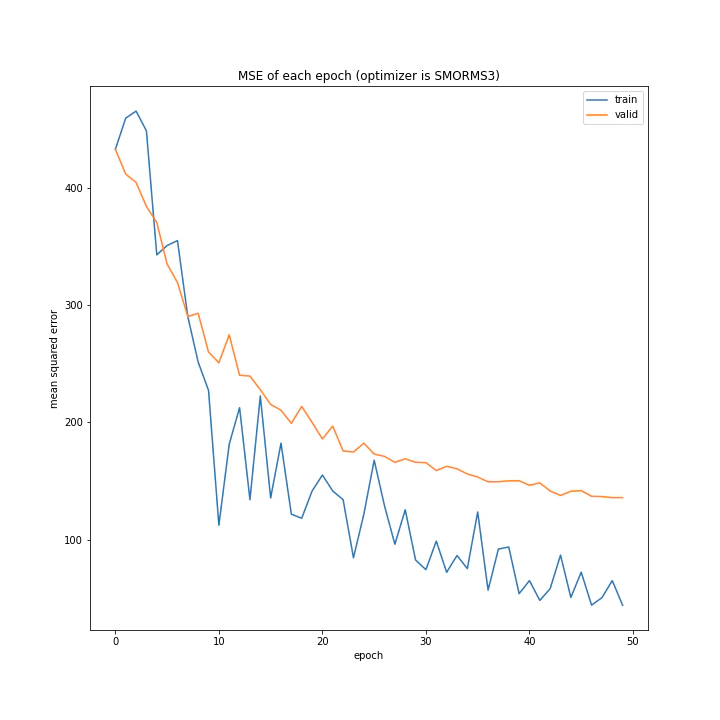
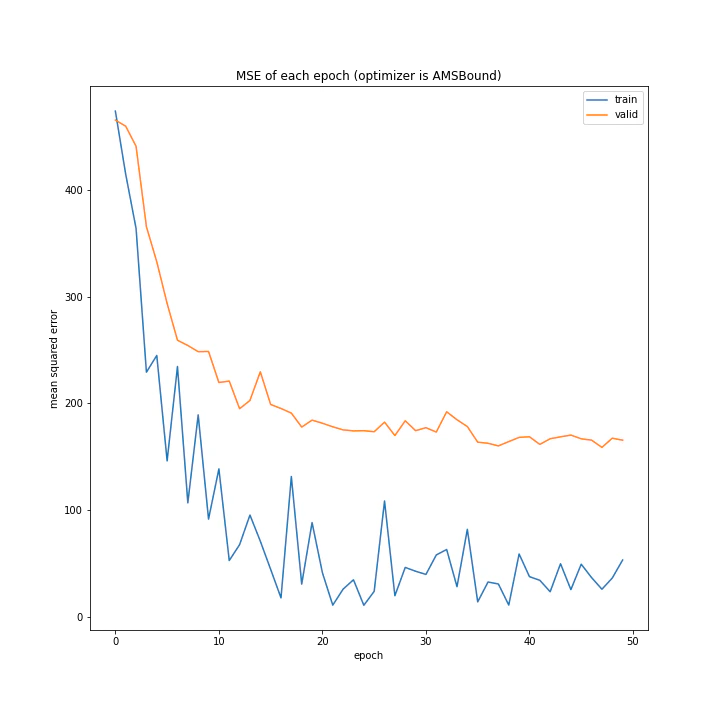
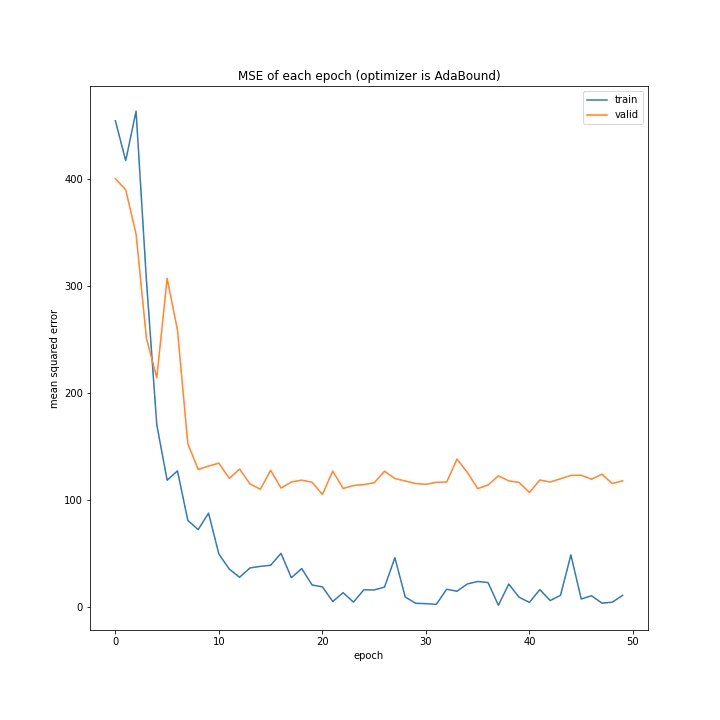
AdaDelta、Adam、RMSpropGraves、SMORMS3、AMSGrad、AdaBound、AMSBoudnは順調に学習できていることが分かります。
AdaDeltaはRMSpropの次元数を合わせたものですが、その考え方は有効であることがここから分かります。
Adamは綺麗に収束していますが、最終的な誤差はいまいちでした。
テストデータで最優秀、かつ収束も綺麗で早かったAdaBoundを採用しようと思います。
重み減衰係数を変更
run = deep_learn()
run.Net = plane.Net
WD_arr = [0.000001, 0.000005, 0.00001, 0.00002, 0.00005, 0.0001, 0.0005, 0.001]
run.save_dir = "fig/WeightDecay"
i = 1
MSE_test = []
MAE_test = []
run.set_data()
for WD in WD_arr:
print("\r%d/%d" % (i, len(WD_arr)), end="")
run.WeightDecay = WD
run.fig_name1 = "MSE of each epoch (coefficient of WeiteDecay is %f).png" % WD
run.fig_name2 = "MAE of each epoch (coefficient of WeiteDecay is %f).png" % WD
run.fit()
run.plot()
test_error = run.cal_test_error()
MSE_test.append(test_error[0])
MAE_test.append(test_error[1])
i += 1
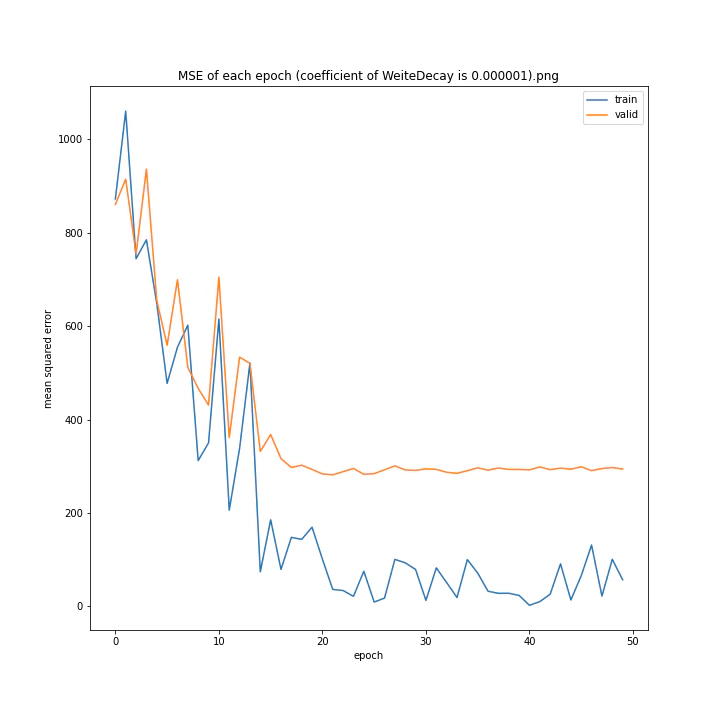
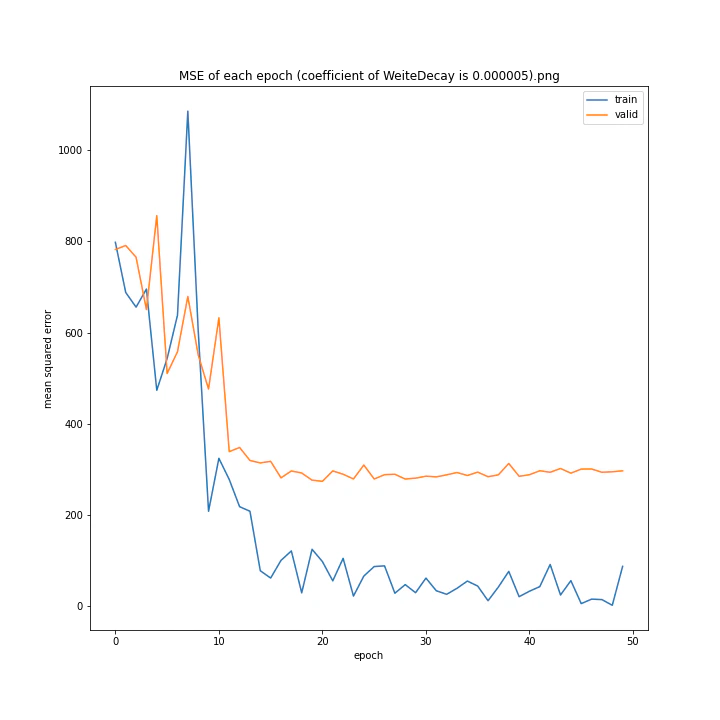
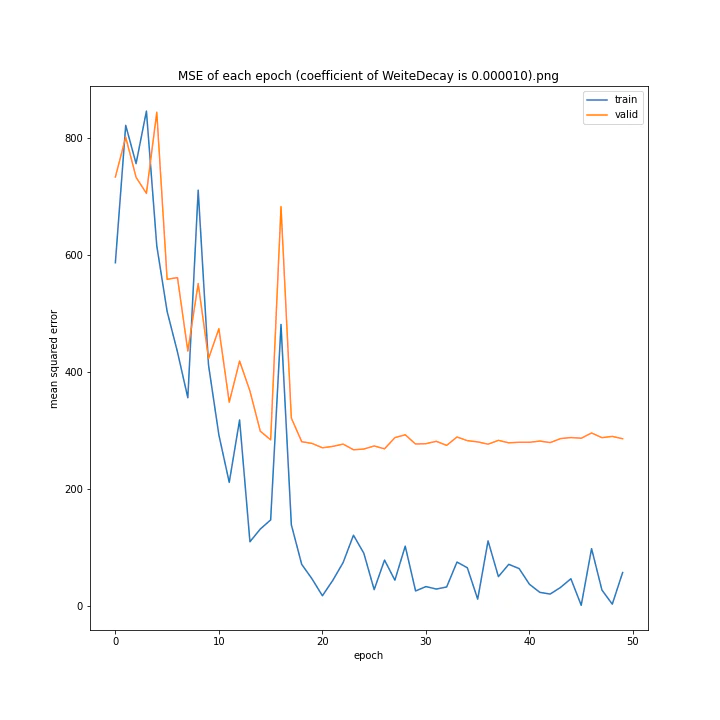
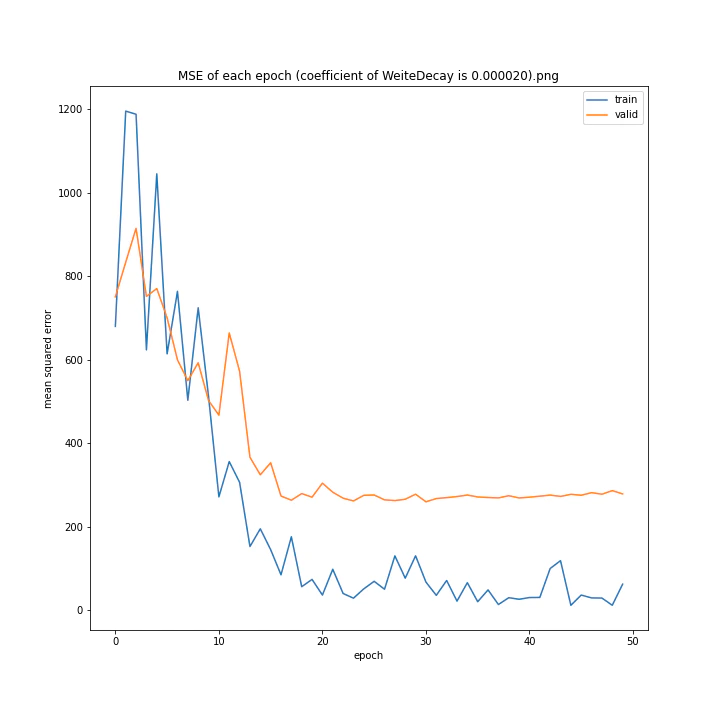
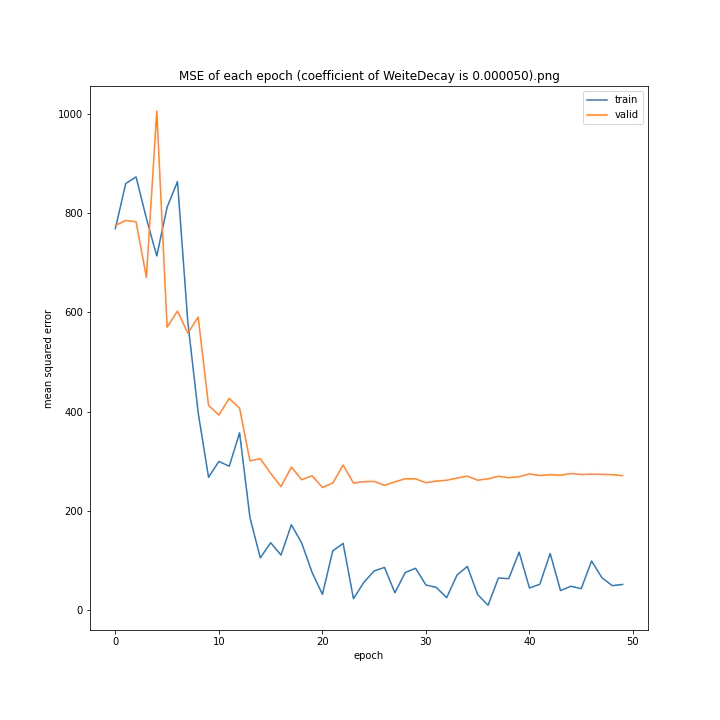
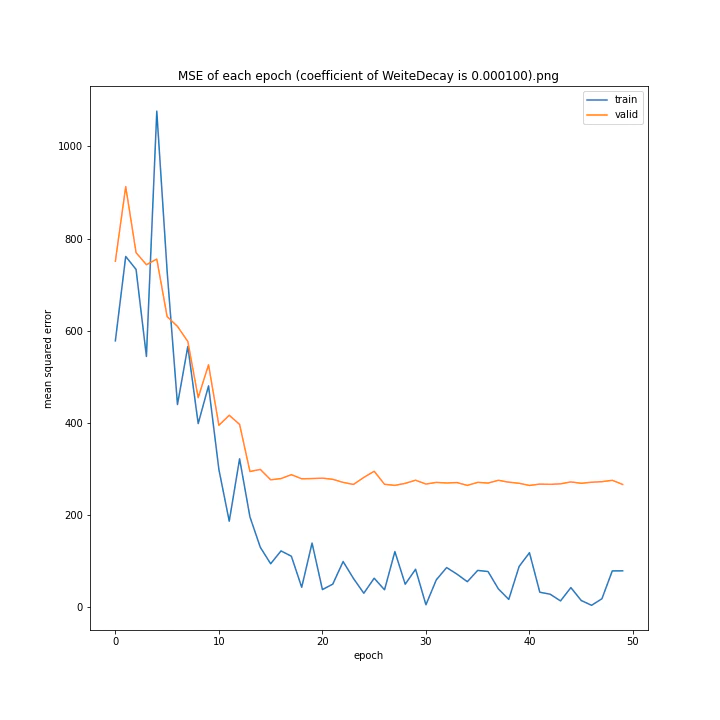
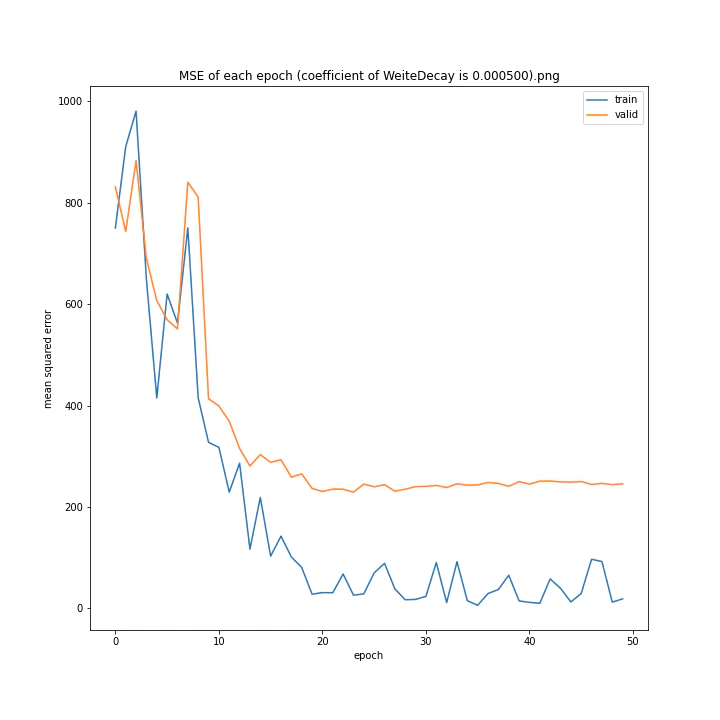
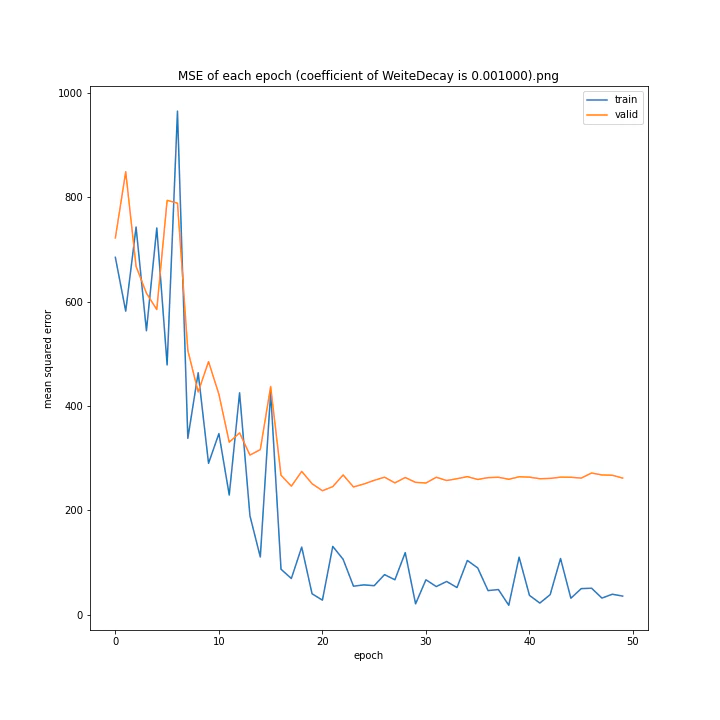
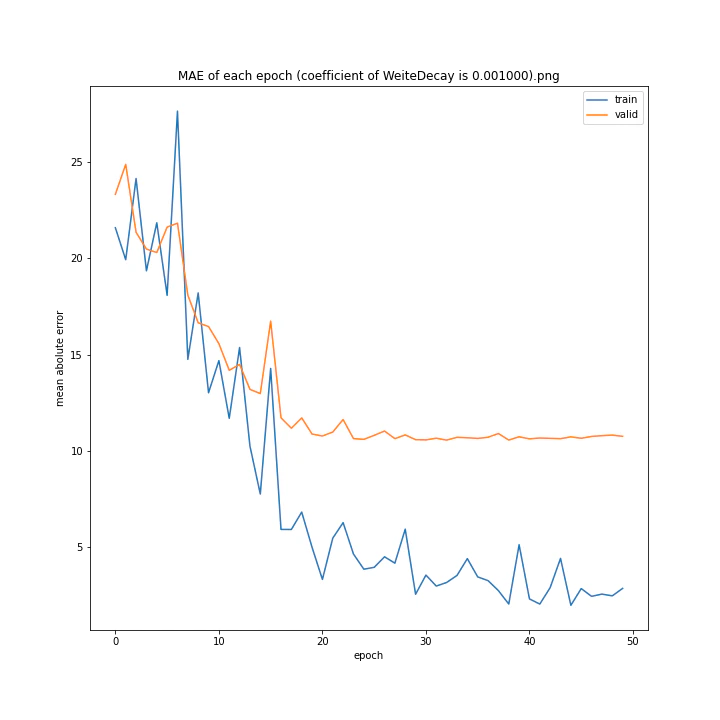
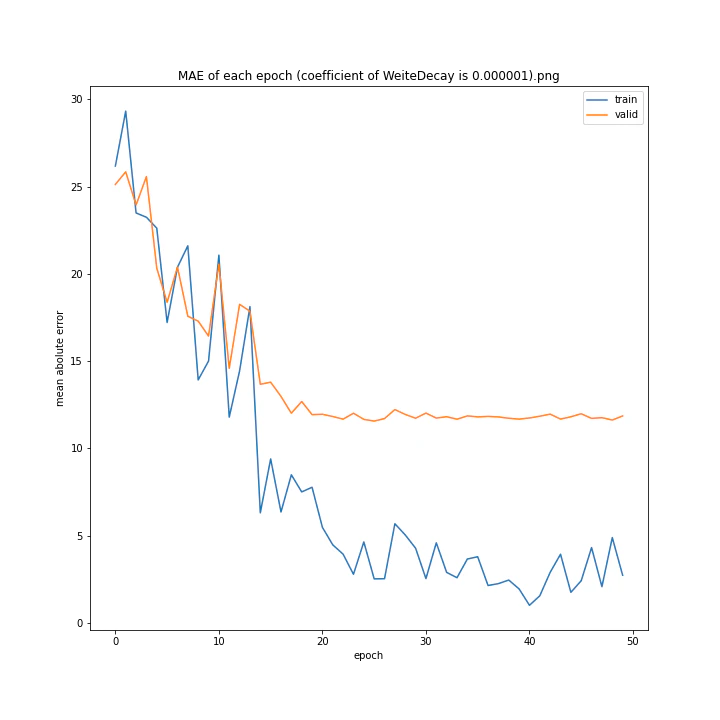
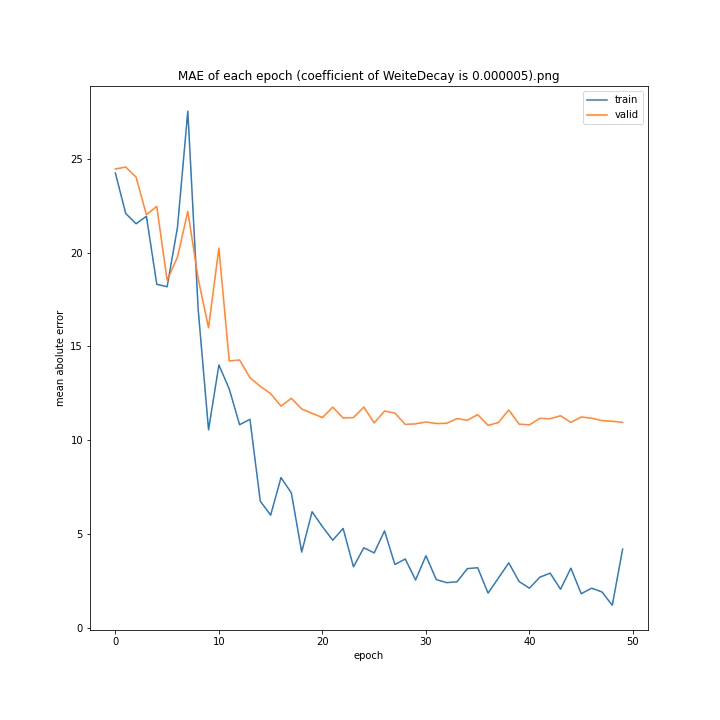
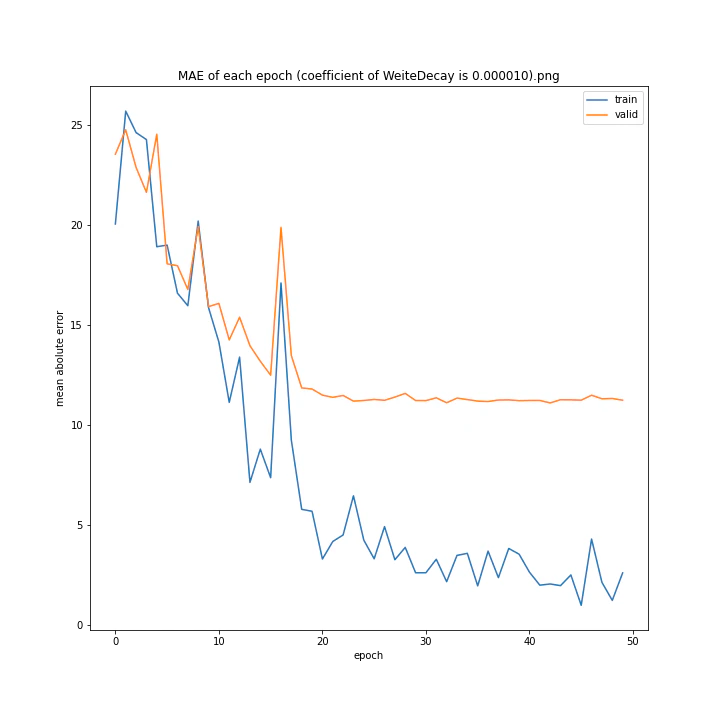
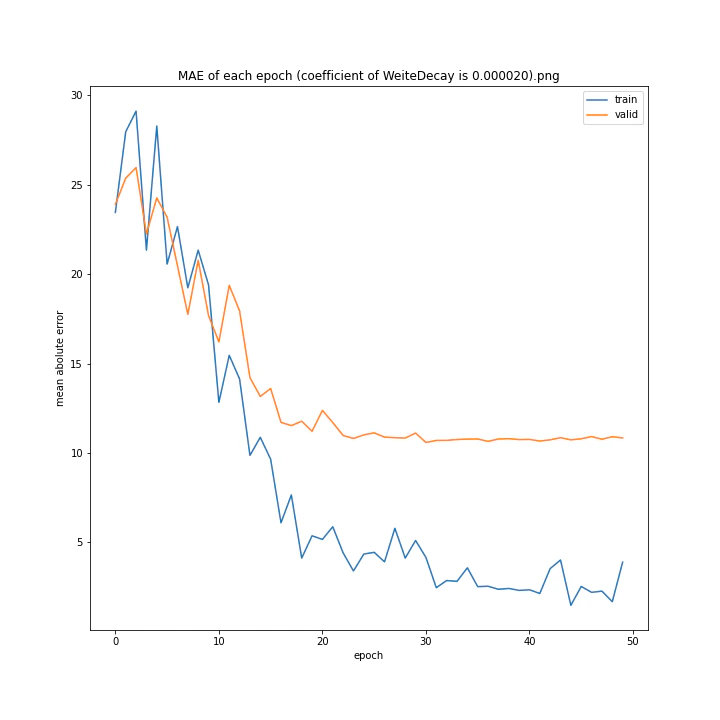
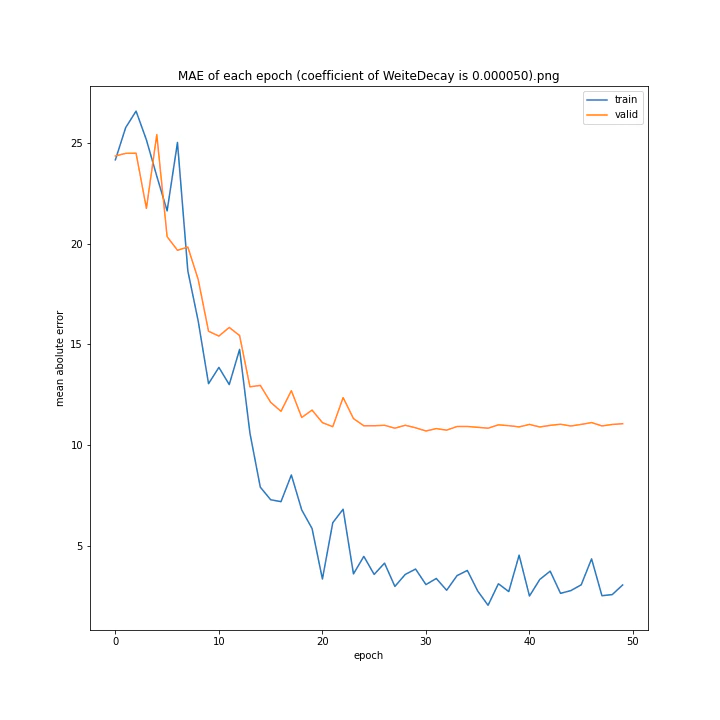
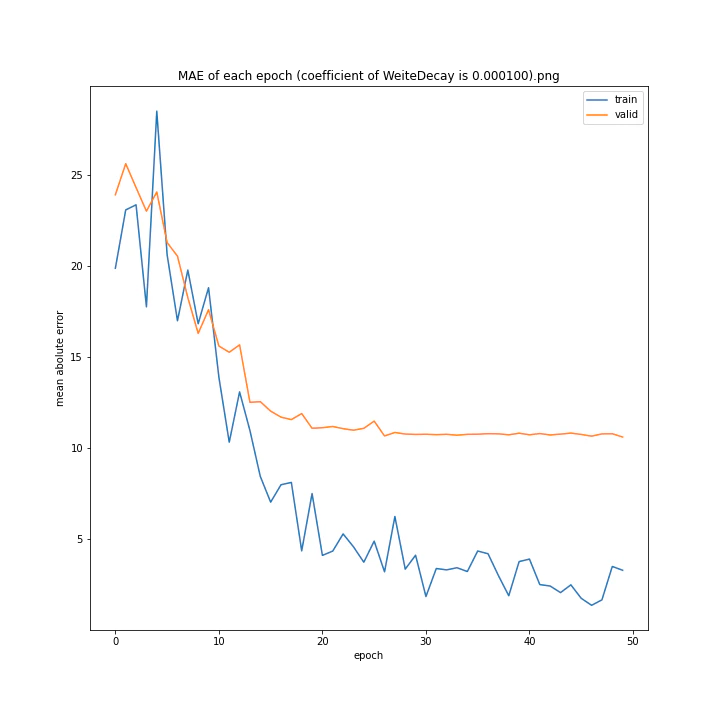
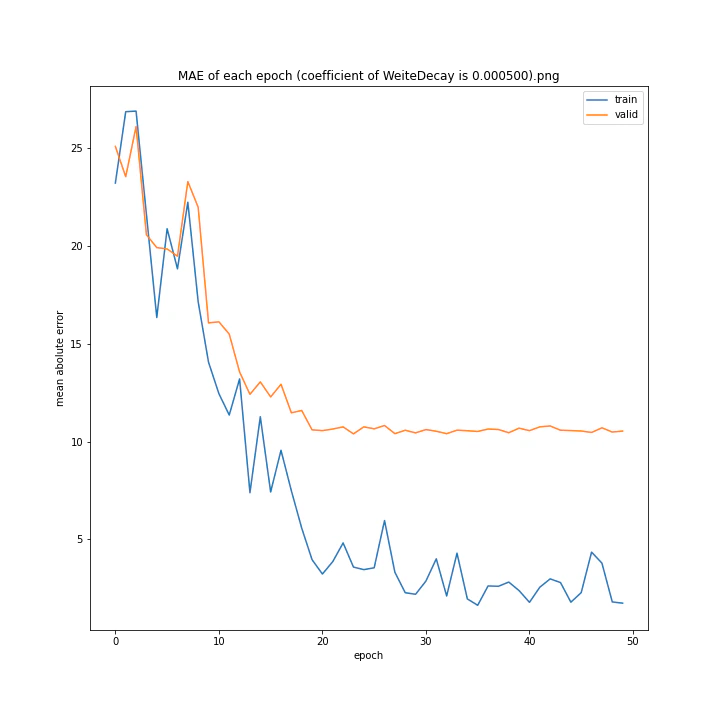
MSE: [variable(323.6231), variable(337.4172), variable(317.3086), variable(345.4895), variable(360.81476), variable(347.40695), variable(317.54373), variable(336.22287)]
MAE: [variable(11.564267), variable(11.702841), variable(11.491479), variable(12.228395), variable(12.072598), variable(11.99491), variable(11.335259), variable(11.767622)]
どれもあまり大きな違いはない結果になりました。
テストデータでの最優秀は0.00001でした。
更新回数を変更
変更と書きましたが、実際は行けるところまで学習させてみただけです。
run = deep_learn()
run.Net = plane.Net
run.save_dir = "fig/n_epoch"
run.set_data()
run.n_epoch = 1000
run.fig_name1 = "MSE of each epoch (n_epohc is %d)" % run.n_epoch
run.fig_name2 = "MAE of each epoch (n_epoch is %d)" % run.n_epoch
run.fit()
run.plot()
MSE_test, MAE_test = run.cal_test_error()
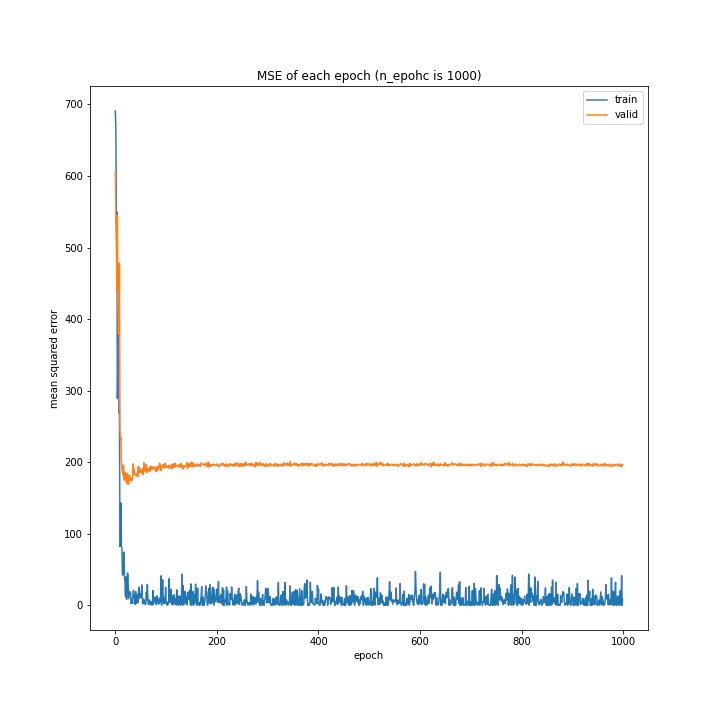
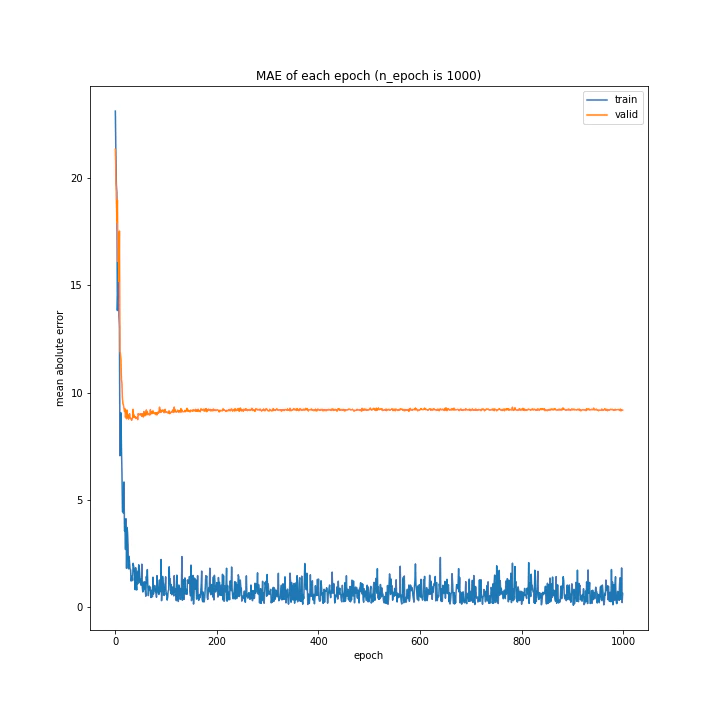
MSE: variable(173.23218)
MAE: variable(8.805884)
1000回もする必要はさすがになかったようです。
今まで通り50回でも十分な精度は出ます。
精度検証は50回で行い、本番の学習は念のため100回で行こうと思います。
データ集めの際のターン数を変更
完全に失念していました。
check_pointについて、変更しながらデータ集めをし学習させてみます。
import osero_learn as ol
import deep_learn as dl
run = dl.deep_learn()
run.Net = plane.Net
run.save_dir = "fig/check_point"
cp_arr = [
[i for i in range(1, 61)],
[i for i in range(5, 61, 5)],
[i for i in range(10, 61, 10)]
]
cp_name = [
"every 1",
"every 5",
"every 10"
]
i = 1
MSE_test = []
MAE_test = []
for cp in cp_arr:
print("\r%d/%d" % (i, len(cp_arr)), end="")
run.osero = ol.learn(0, 0, cp)
run.set_data()
run.fig_name1 = "MSE of each epoch (turn is %s)" % cp_name[i - 1]
run.fig_name2 = "MAE of each epoch (turn is %s)" % cp_name[i - 1]
run.fit()
run.plot()
test_error = run.cal_test_error()
MSE_test.append(test_error[0])
MAE_test.append(test_error[1])
i += 1
実行結果はこちら。
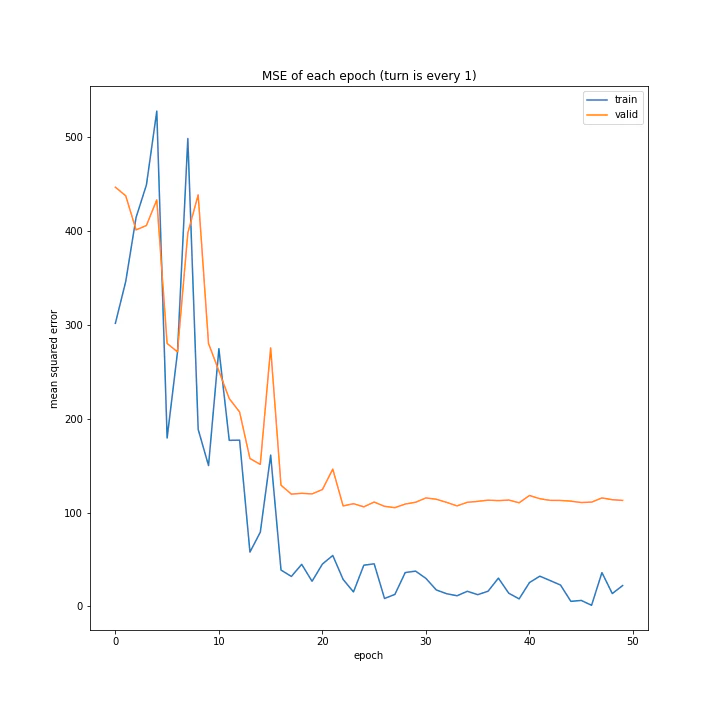
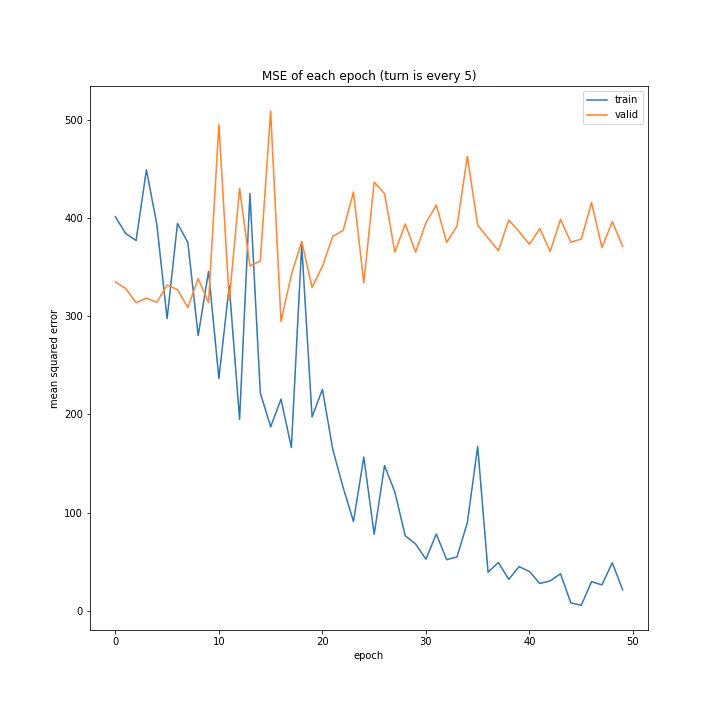
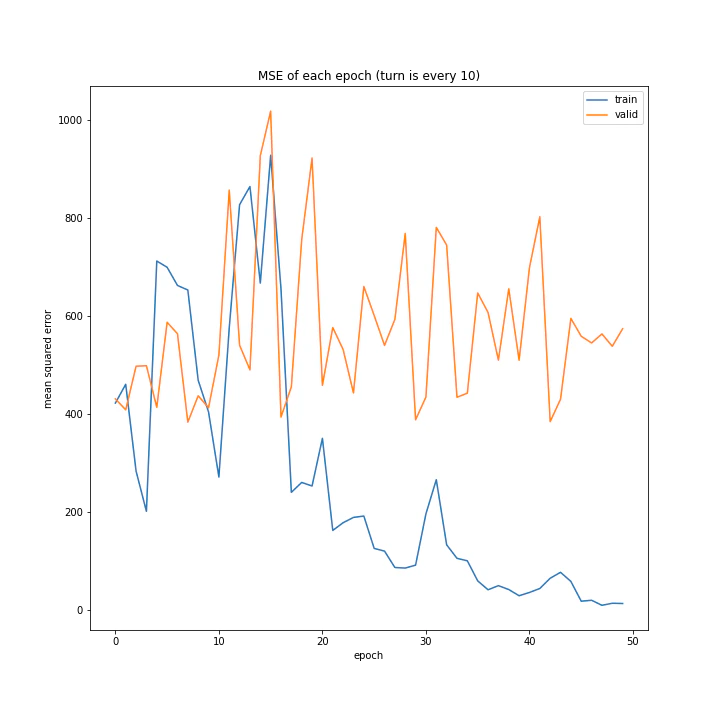
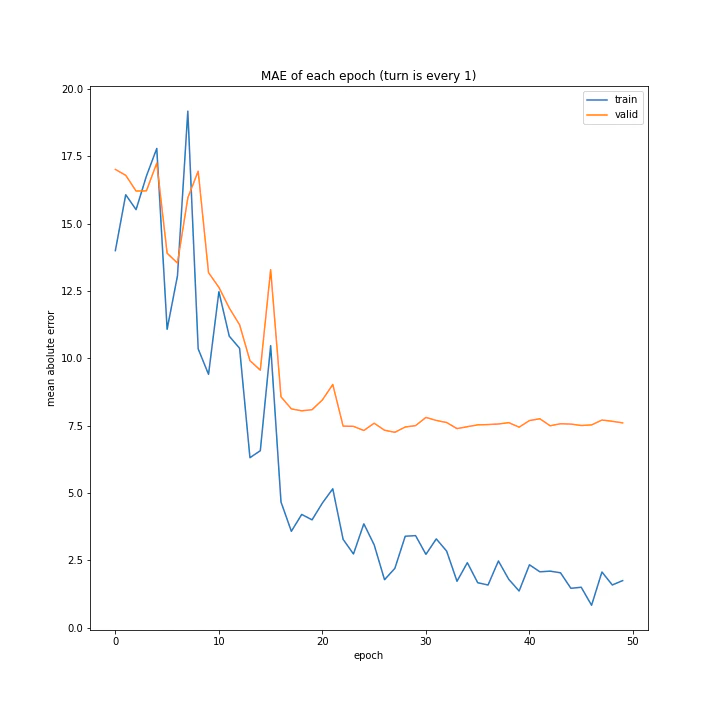
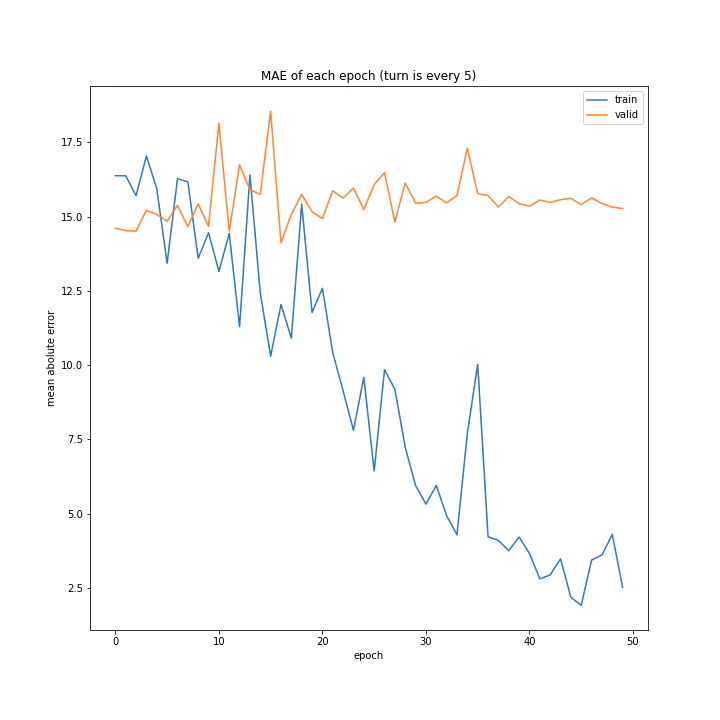
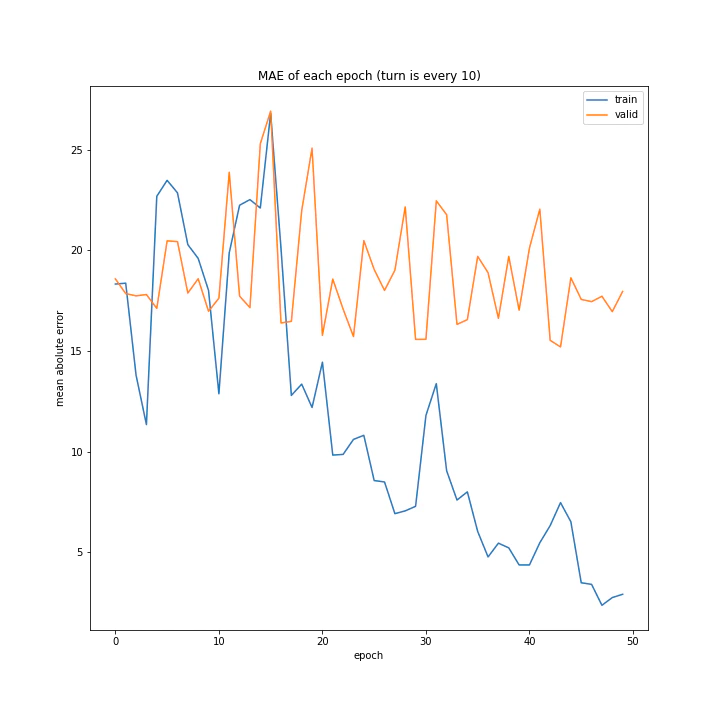
['every 1', 'every 5', 'every 10']
MSE: [variable(134.67699), variable(360.08517), variable(555.0388)]
MAE: [variable(7.625587), variable(15.11074), variable(18.970434)]
言うまでもなくevery 1が最適ですね。
重み減衰を変更
こちらも失念しておりました。
chainerに実装されているものをすべて試すつもりでしたが、GradientClippingのみなぜかエラーが出て実行できなかったため試せていません。
引数については大体で設定しました。
import chainer.optimizer_hooks as hf
run = deep_learn()
run.Net = plane.Net
run.save_dir = "fig/hook_function"
hf_arr = [
hf.WeightDecay(0.00001),
hf.Lasso(0.00001),
# hf.GradientClipping(1.0),
hf.GradientHardClipping(-1.0, 1.0),
hf.GradientNoise(0.3),
hf.GradientLARS()
]
hf_name = [
"WeightDecay",
"Lasso",
# "GradientClippint",
"GradientHardClipping",
"GradientNoise",
"GradientLARS"
]
i = 1
MSE_test = []
MAE_test = []
run.set_data()
for hook_f in hf_arr:
print("\r%d/%d" % (i, len(hf_arr)), end="")
run.hook_f = hook_f
run.fig_name1 = "MSE of each epoch (hook function is %s)" % hf_name[i - 1]
run.fig_name2 = "MAE of each epoch (hook function is %s)" % hf_name[i - 1]
run.fit()
run.plot()
test_error = run.cal_test_error()
MSE_test.append(test_error[0])
MAE_test.append(test_error[1])
i += 1
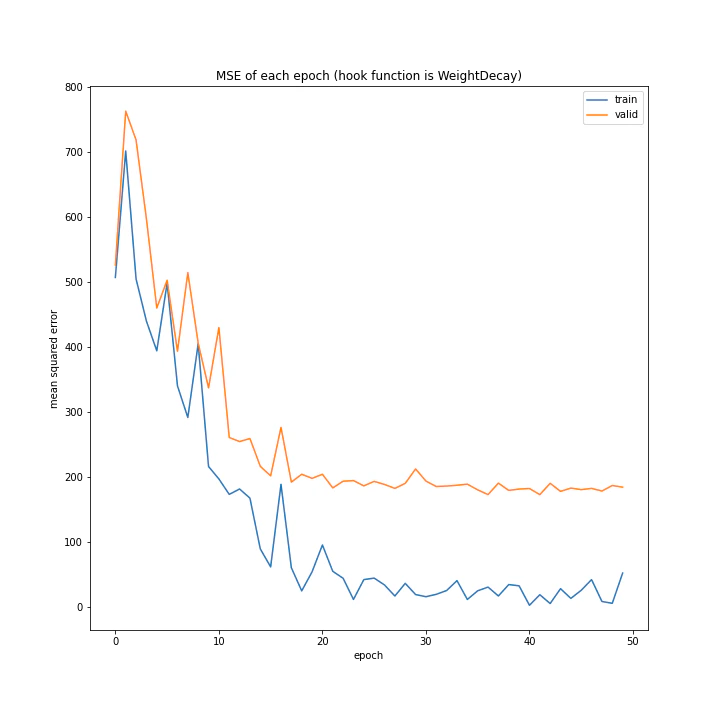
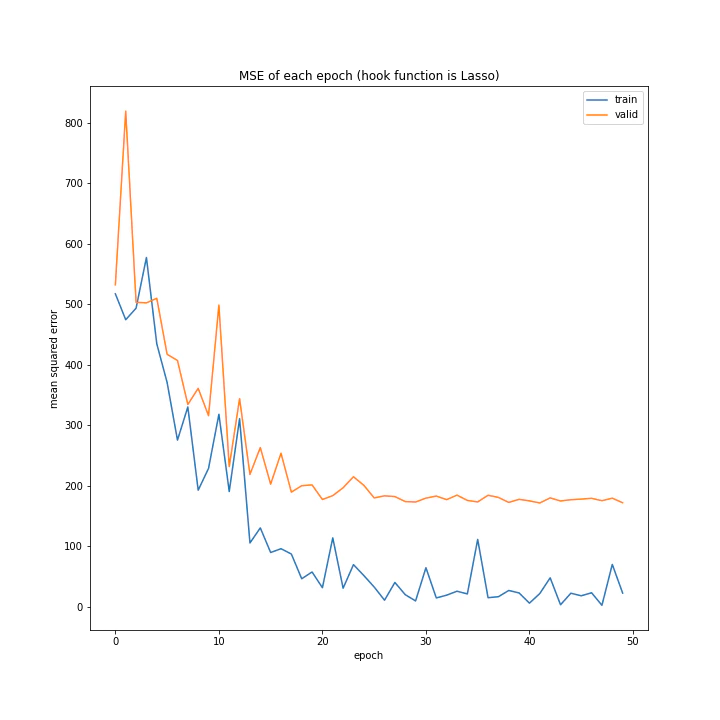
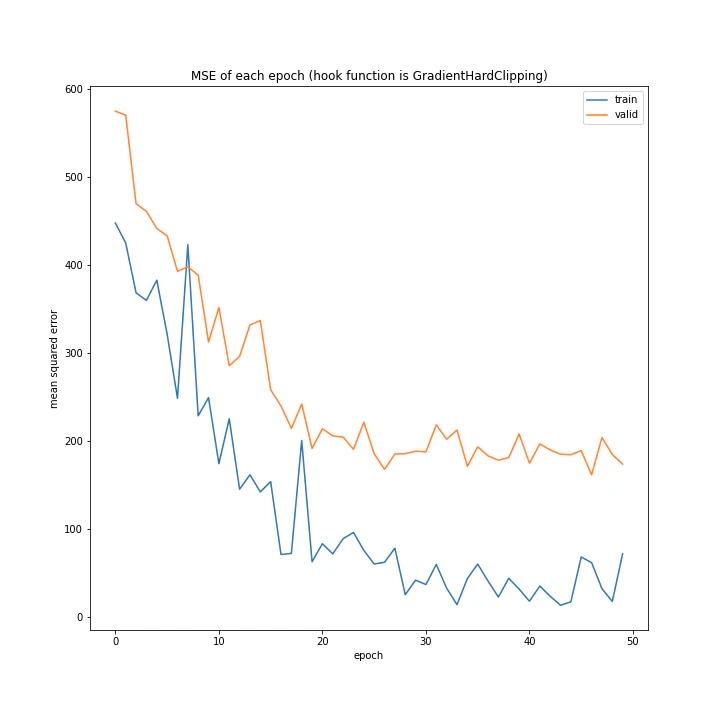
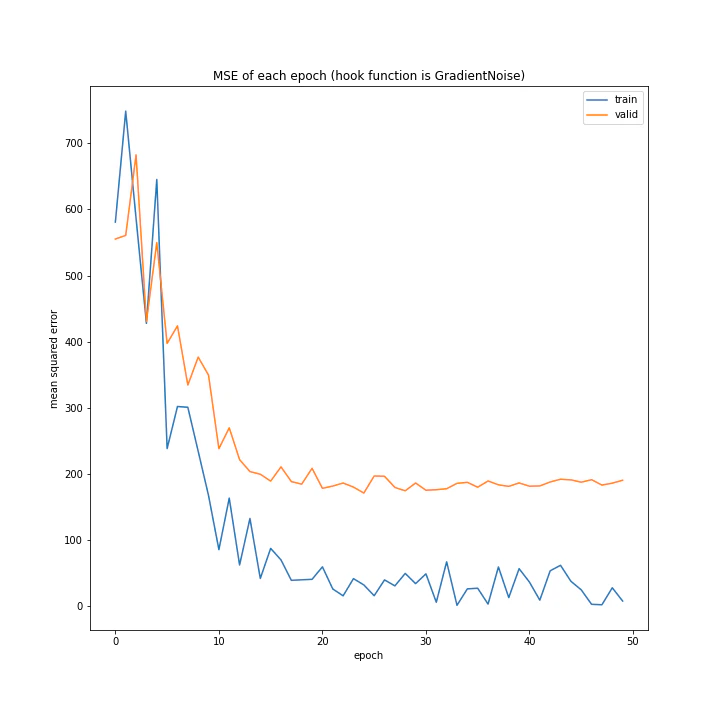
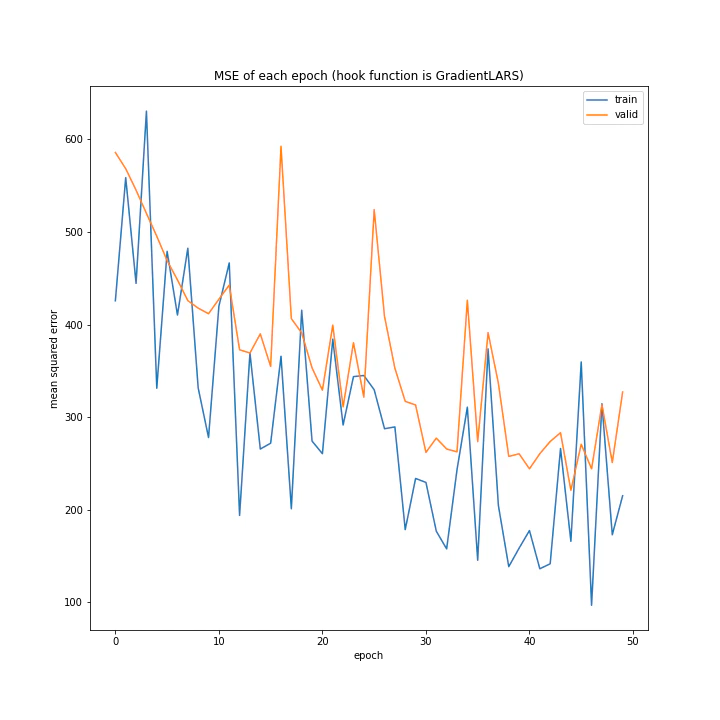
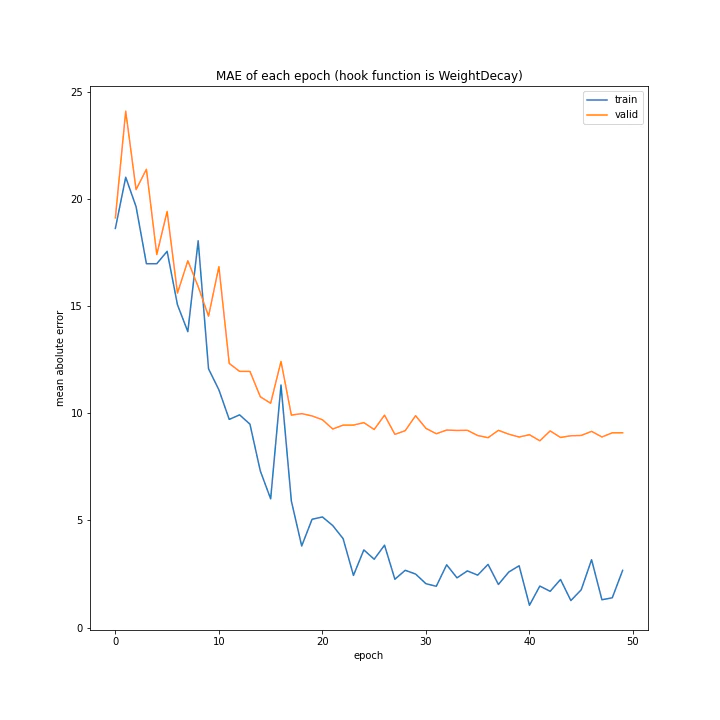
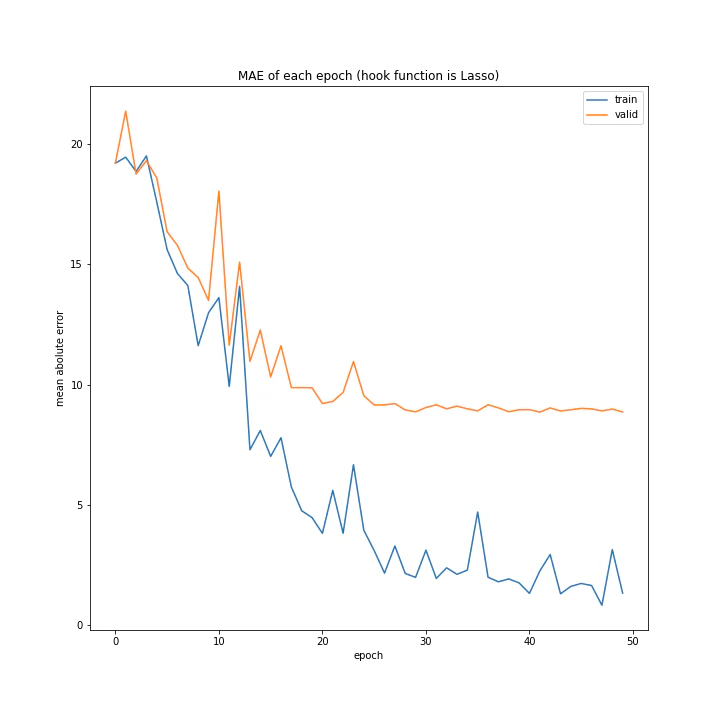
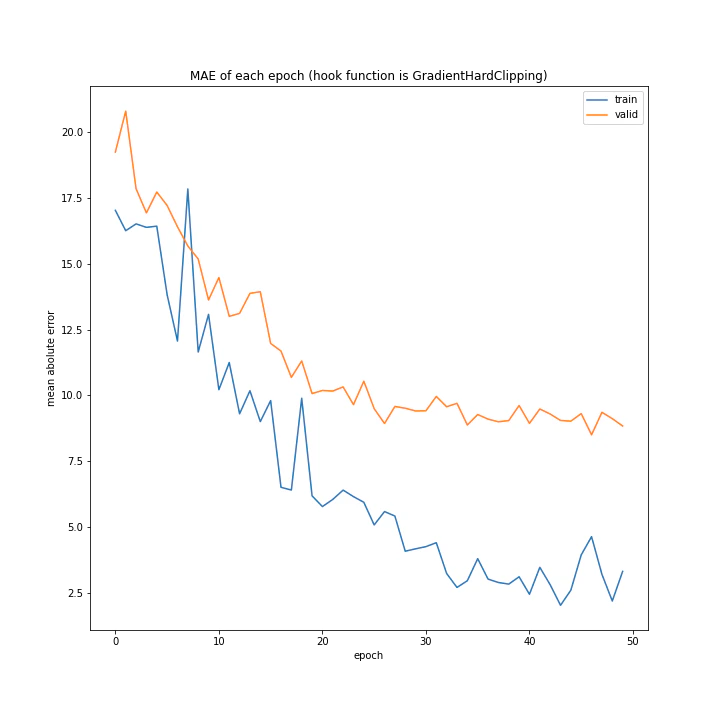
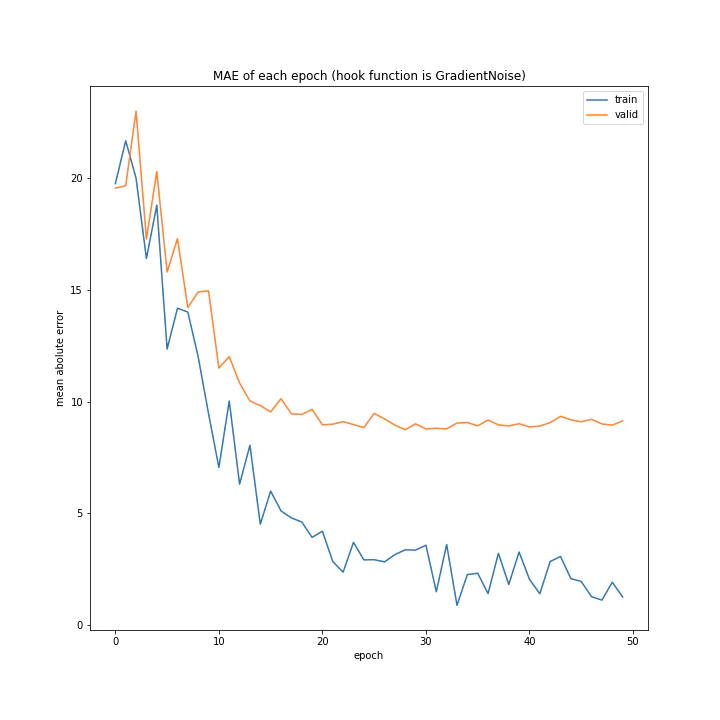
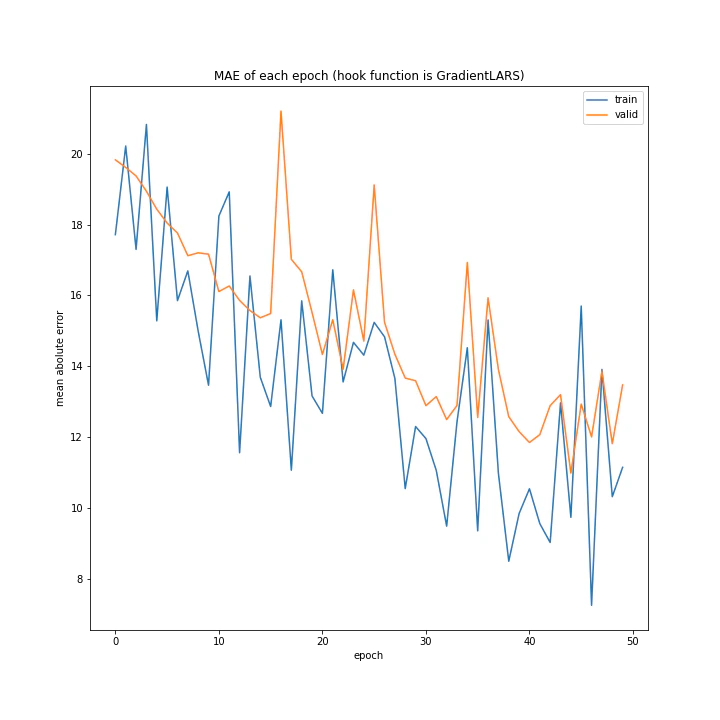
['WeightDecay', 'Lasso', 'GradientHardClipping', 'GradientNoise', 'GradientLARS']
MSE: [variable(173.38802), variable(165.7673), variable(149.28122), variable(170.66235), variable(334.34393)]
MAE: [variable(8.827514), variable(8.926463), variable(8.31733), variable(8.63603), variable(13.599926)]
WeightDecayとLasso以外はネット上に全く情報がなく、考察のしようがないです。
とりあえずGradientLARSはうまく学習できていないことしか分かりません。
テストデータでの誤差が小さく、収束もまだ余裕がありそうに見えるGradientHardClippingを採用したいと思います。
まとめ
今回の実験で分かった、オセロ学習において有効であろうパラメータを以下に示します。
- データ量 5x5の25試合、全ターンを記録
- バッチサイズ 150
- 層の数 3
- 活性化関数 tanh
- 学習率 0.01
- 最適化関数 AdaBound
- 重み減衰 GradientHardClipping
- 更新回数 50回で十分、本番に使用するモデルは100回
重み減衰係数については、WeightDecayの時のみ有効なデータなのでここには書きません。
また、記事が長くなってきたので、GradientHardClippingのパラメータやこれらを組み合わせての実験は次回行いたいと思います。
フルバージョン
次回は
前述した通り、GradientHardClippingのパラメータを変更しての実験およびまとめに記した条件を組み合わせての実験を行います。