今回の目標
前回も書いた通り17の評価値と、ついでに15で求めた評価値についてその有用性を検証します。
ここから本編
具体的な検証方法は、求めた評価値に従って1handなど様々な手法の相手と戦い、その勝率を見ます。
srand関数の引数については、18で求めた最も勝敗に影響しない81~100を使います。
詳しくは後述。
評価値、整形
15および17で出力した評価値は人間が見やすいような配置にしてありましたが、プログラムで読み込むのは大変そうなのでいったん整形します。
成形には以下のプログラムを使いました。
全てのcsvファイルを読み、空白行を無視し、「,」を省き、数字を一つずつ並べています。
csvファイルの空白行を読み込むと、他の行と同じだけ「,」が打たれた文字列と改行マークが返されるようです。それを知らなかったので大変苦戦しました。
from glob import glob
all_eva = open("all_eva.txt", "w")
name = open("filename.txt", "w")
for filename in glob("csv/eva*.csv"):
name.write(filename.lstrip("csv\\") + "\n")
with open(filename, "r") as data:
for num in data:
num = num.rstrip("\n")
if num != ",,,,,,,":
while num != "":
if num[0] != ",":
all_eva.write(num[0])
else:
all_eva.write("\n")
num = num[1:]
else:
all_eva.write("\n")
all_eva.close()
name.close()
このプログラムによる出力ファイルがこちら。
0.1744
-0.1659
0.2753
-0.9104
-0.23
0.4792
0.4843
-0.5478
0.8684
0.9085
-0.3466
0.3122
0.7645
-0.4478
0.3706
-0.613
0.8686
-0.9667
-0.9337
-0.2648
0.7867
0.0804
-0.8602
0.7856
(以下略)
eva1hand_1hand_genetic.csv
eva_1hand_1hand_rand.csv
eva_1hand_rand_genetic.csv
eva_1hand_rand_rand.csv
eva_2hand_2hand_rand.csv
eva_2hand_rand_genetic.csv
人間が見てもさっぱりですが、機械にとっては分かりやすい表記になりました。
今更ですがアンダーバーを付け忘れているファイル名がありました。
なお、末尾が「genetic」のものが15で求めた評価値、つまりsrand関数の引数がすべて0の時の評価値です。「rand」のものが17で求めた評価値、つまりsrand関数の引数が主に0~1030程度の値をとった時の評価値です。
対戦プログラム
今回の対戦パターンは複雑で、
- 評価値が6ファイル
- 評価値が1ファイルあたり30通り
- コンピュータが評価値に従う1hand、2handの2通り
- プレイヤーがrandom、普通の1hand、2handの3通り
- srand関数の引数が81~100の20通り
全部で6302320=21600通りの試合を行います。
そのせいでfor文が五重になっています。
実行プログラムは以下の通りです。
ヘッダファイルおよびソースファイルには大きな変更はありません。しいて言えばrandom関数がdo-while文になったこと、mode変数のデフォルト値が1になったことぐらいです。
# include "osero_genetic.h"
int main(void){
FILE * eva_file, * name_file, * fp;
osero_genetic * run;
double eva[64], eva_p[64];
char filename[50];
char eva_ele[10], * not_eva;
bool win_lose;
for (int i = 0; i < 64; i++) eva_p[i] = 1.0;
eva_file = fopen("all_eva.txt", "r");
name_file = fopen("filename.txt", "r");
fp = fopen("all_data.csv", "w");
fprintf(fp, "filename,eva_num,computer,player,srand_num,win_lose\n");
for (int file = 0; file < 6; file++){
// 進行状況表示
printf("[");
for (int i = 0; i < file + 1; i++) printf("#");
for (int i = 0; i < 6 - file - 1; i++) printf(" ");
printf("]\n");
fgets(filename, sizeof(filename), name_file);
for (int i = 0; i < sizeof(filename); i++){
if (filename[i] == '.'){
filename[i] = '\0';
break;
}
}
for (int eva_num = 0; eva_num < 30; eva_num++){
for (int i = 0; i < 64; i++){
fgets(eva_ele, 10, eva_file);
eva[i] = strtod(eva_ele, ¬_eva);
}
for (int computer = 1; computer <= 2; computer++){
for (int player = 0; player < 3; player++){
for (int srand_num = 81; srand_num <= 100; srand_num++){
if (player == 0){
run = new osero_genetic(0, eva, 1);
}else{
run = new osero_genetic(0, eva, 0, eva_p);
}
run -> srand_num = srand_num;
run -> read_goal[0] = computer;
run -> read_goal[1] = player;
run -> computer = 0;
run -> player = 1;
win_lose = run -> play();
fprintf(
fp,
"%s,%d,%d,%d,%d,%d\n",
filename,
eva_num,
computer,
player,
srand_num,
INT(win_lose)
);
delete run;
}
}
}
}
}
fclose(eva_file);
fclose(name_file);
fclose(fp);
return 0;
}
一重目のfor文内でfilenameの中身をいじっているのは、改行マークを外したはずなのにcsvファイル内でなぜか改行されたためです。もともと「\n」を「\0」に変更していましたが、拡張子からカットしたら上手く行きました。理由は分かりません。
あとは五重目のループ内で、様々な条件で対戦を行っています。
結果
以下に示すプログラムでグラフを作成しました。
ファイル以外についても条件ごとに勝率グラフを作っています。
import pandas as pd
import matplotlib.pyplot as plt
######## read data ########
filename = []
with open("filename.txt", "r") as data:
for line in data:
filename.append(line[:-5])
df = pd.read_csv("all_data.csv")
######## per file ########
win_lose = []
for i in filename:
df_ele = df[df.filename == i]
win_lose.append(df_ele["win_lose"].mean())
fig = plt.figure(figsize=(10, 10))
plt.bar(filename, win_lose)
plt.xticks(rotation=10)
plt.title("per file")
# plt.show()
plt.savefig("fig/per_file")
plt.cla()
(以下略)
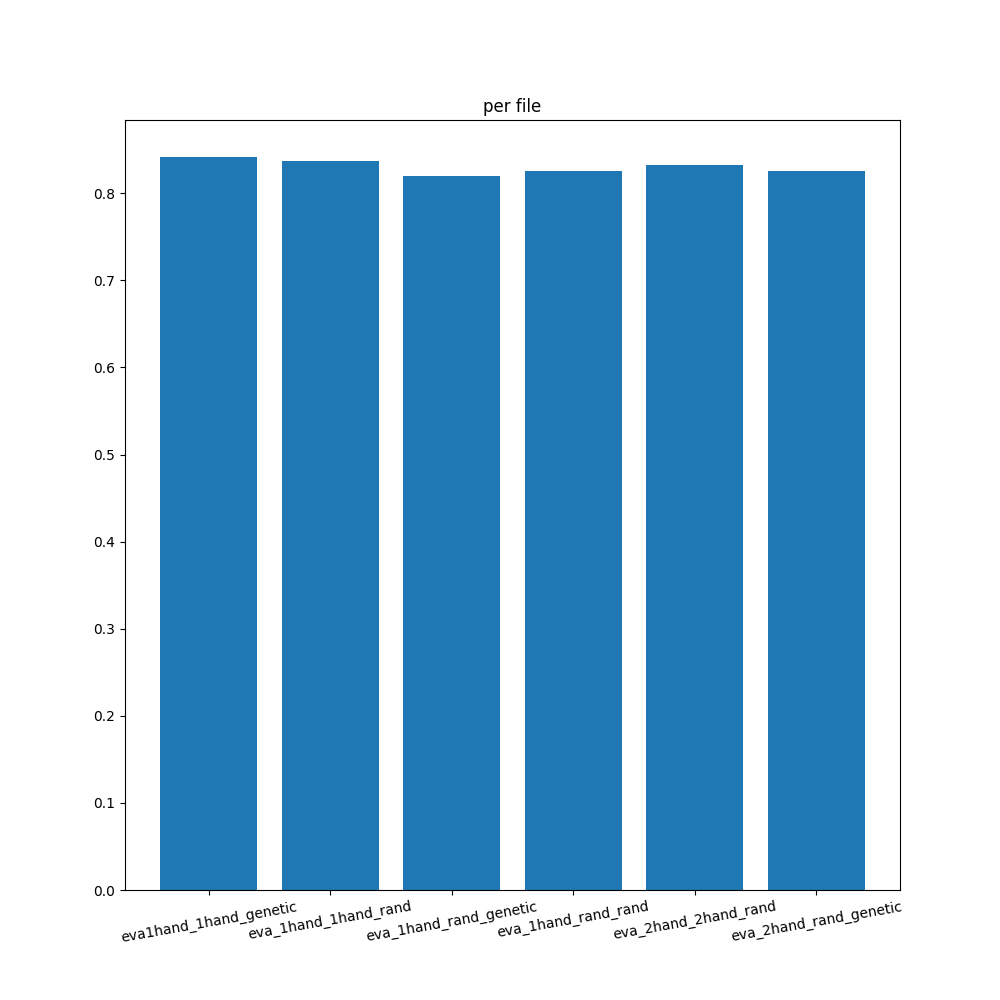
上のプログラムの実行結果がこちら。
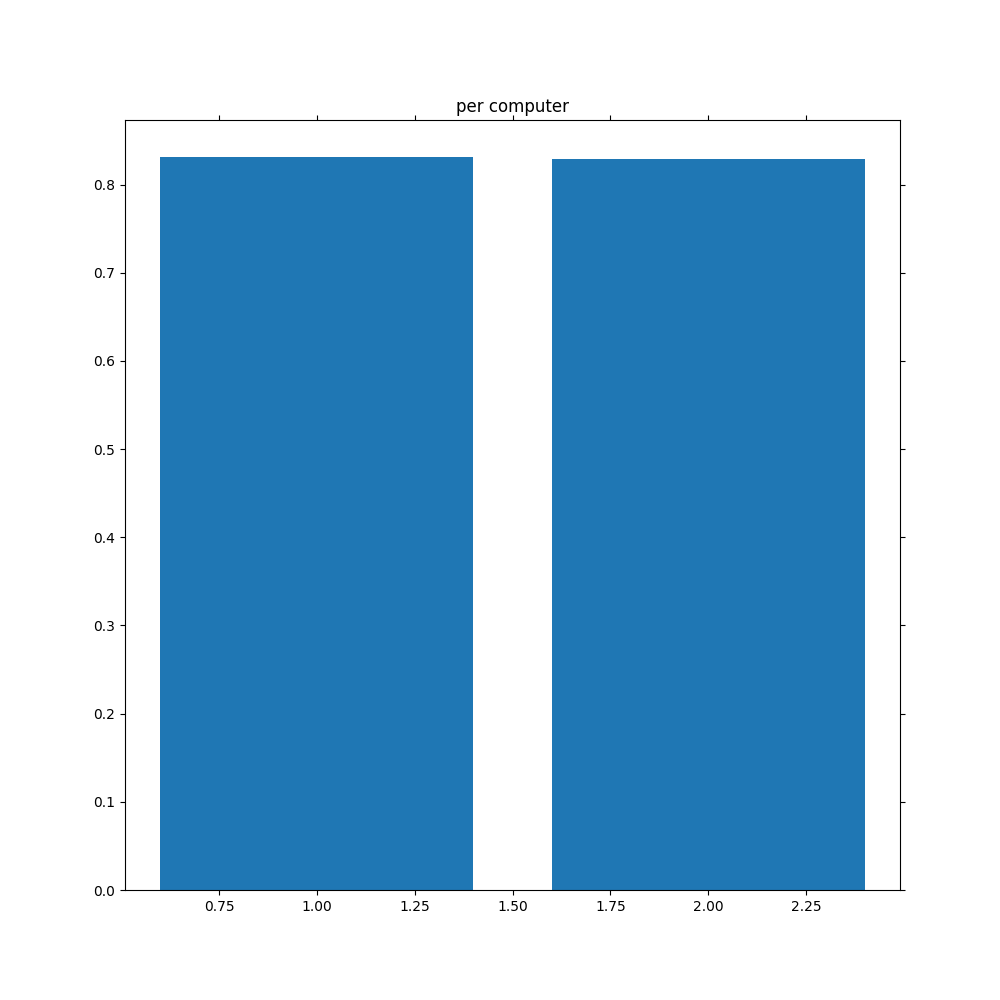
↑ 1が評価値に従った1hand、2が評価値に従った2hand
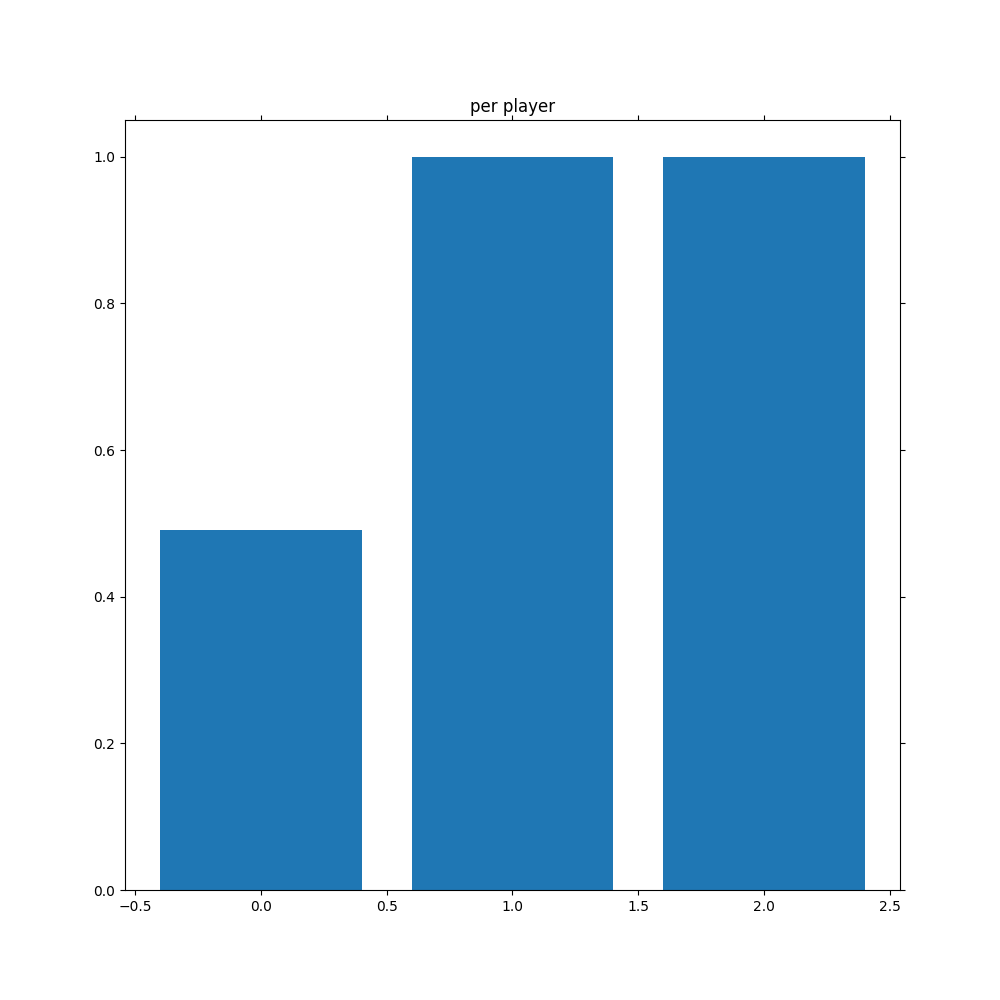
↑ 0がrandom、1が普通の1hand、2が普通の2hand
考察
まず、どの方法で求めた評価値も約8割の勝率でした。
つまり学習していないように見えた結果も含め、以外にも全ての学習結果は「局所解である」または「実はこれが最適解である」のどちらかである、といえます。
しかし、「per player」のグラフを見ると1handや2hand相手ならほぼ完封しているものの対random戦において5割程度の勝率しかありません。つまり、「局所解である」というのが正しい認識だろうと思います。
なお、学習方法ごとのrandom相手の勝率を調べたところ以下のようになっていました。
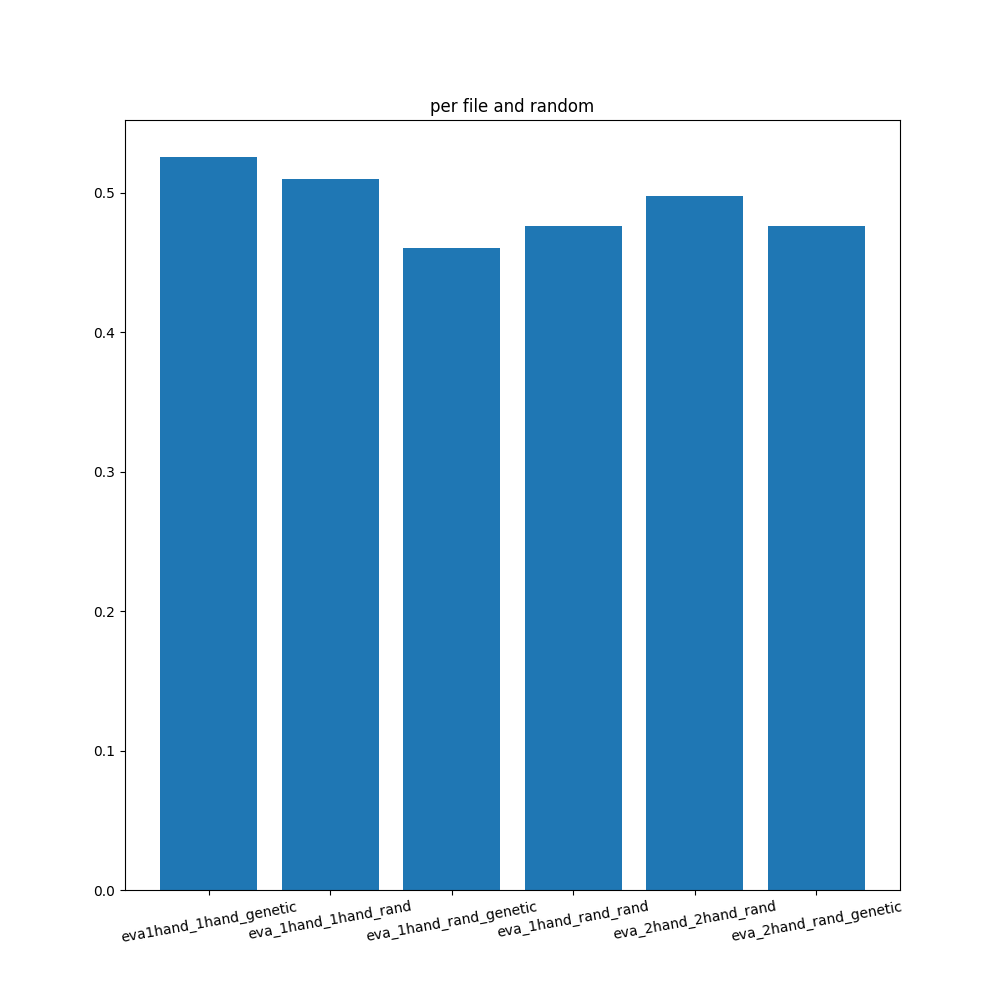
geneticであるかrandであるかに関わらず、「1hand_1hand」及び「2hand_2hand」は高い勝率を誇り、プレイヤー役がrandの際は低い勝率となりました。
やはり16で考察した通り、random相手では相手の戦法が読めず、学習ができない・進まないのではないかと考えられます。だからといって1handや2handとばかり戦っていると局所解に陥るようだと分かりました。
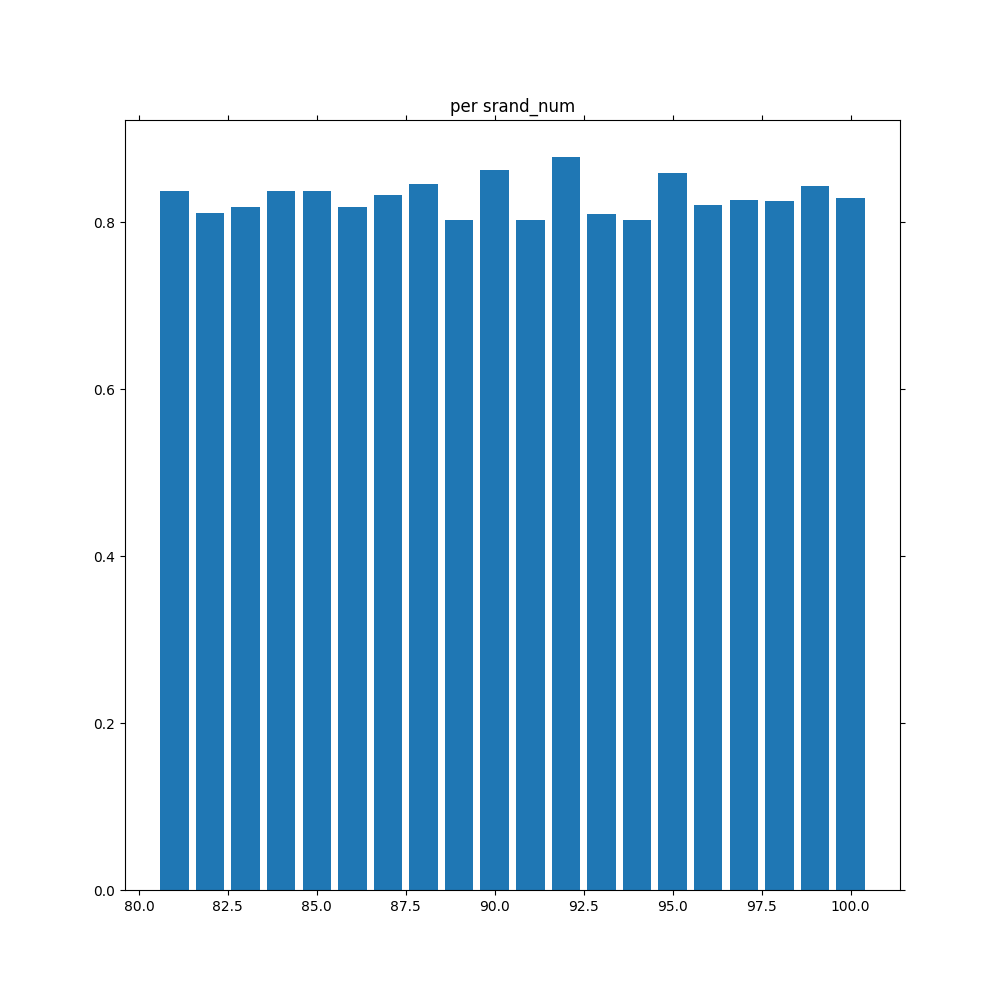
また、「per srand_num」のグラフこそ高さが一定になることを期待していましたがそうはなりませんでした。やはりsrand関数の引数による有利・不利は少なからず生まれるようです。
なおsrand_numごとのrandom相手の勝率を調べると以下の通りでした。
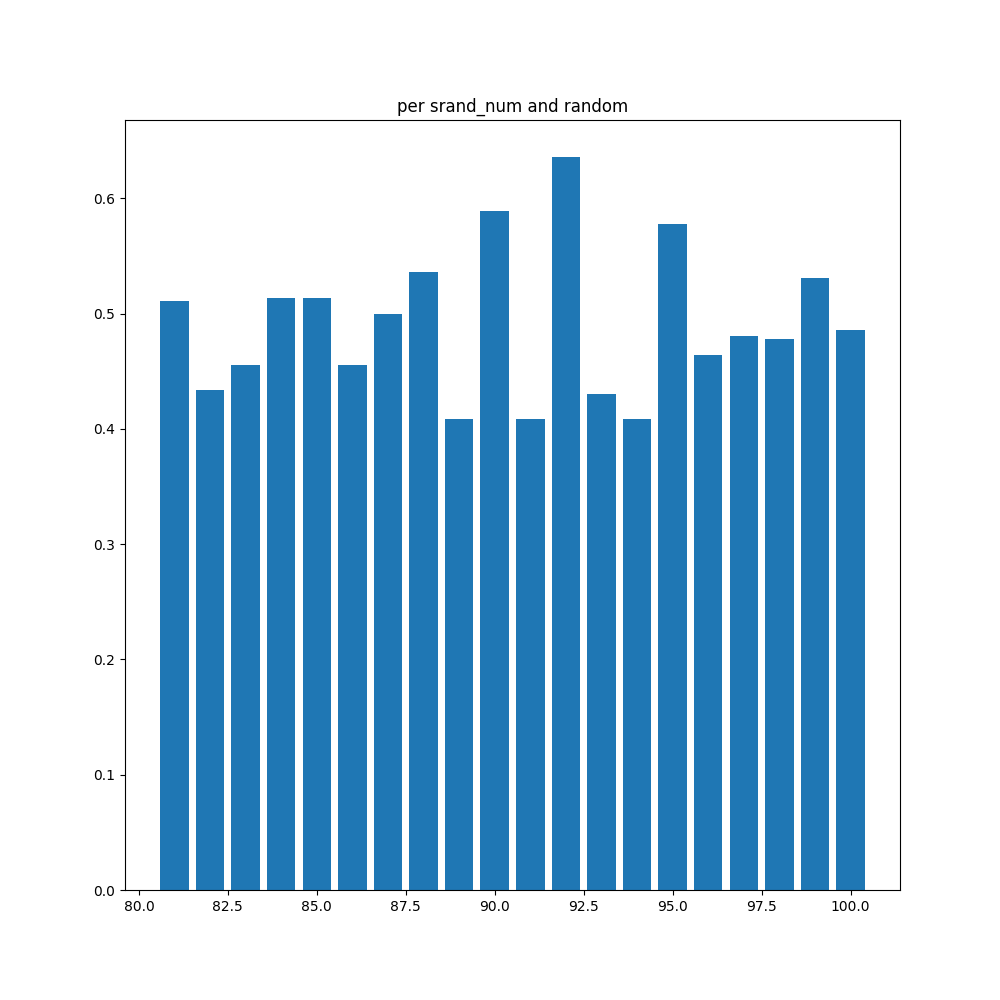
やはりバラツキが大きいですね。
考察内のグラフを描画したプログラムはこちら。
import pandas as pd
import matplotlib.pyplot as plt
######## read data ########
filename = []
with open("filename.txt", "r") as data:
for line in data:
filename.append(line[:-5])
df = pd.read_csv("all_data.csv")
######## per file and random ########
win_lose = []
for i in filename:
df_ele = df[df.filename == i]
df_ele = df_ele[df_ele.player == 0]
win_lose.append(df_ele["win_lose"].mean())
fig = plt.figure(figsize=(10, 10))
plt.bar(filename, win_lose, width=0.8)
plt.xticks(rotation=10)
plt.title("per file and random")
# plt.show()
plt.savefig("fig_custom/per_file_and_random")
plt.cla()
(以下略)
フルバージョン
checkフォルダ内にあります。
次回は
今後はこのプログラムを使いながら、作成した評価値の評価を行います。
次回は遺伝的アルゴリズムの学習方法を改善し、random相手にも勝ち越せるような評価値を探します。