この記事について
研究でWebページ上にある表をスクレイピングする必要があったので,そのときに使用したpythonのプログラムを紹介します.ちなみに,自分はスクレイピング歴0だったので色々調べながら作っていったのですが,Webページ上の表をHTML化した後にHTMLの表部分をcsv化する方法まで説明しているものがほとんどなかったのでこの記事を書きました.
はじめに
スクレイピングについての注意点は,下記URLから御覧ください
https://qiita.com/Azunyan1111/items/b161b998790b1db2ff7a
Pythonでスクレイピング
プログラム全体はこちらに置いてあります.
import
import csv
import urllib
from bs4 import BeautifulSoup
importしたライブラリの説明
・csvは,Pythonの標準ライブラリで今回はCSVファイルの書き込みで使用
・urllibは,web上のデータ(HTML)にアクセス&取得するために使用
・BeautifulSoupは,HTMLから狙ったデータを抽出するために使用
HTMLを取得
url = "https://en.wikipedia.org/wiki/List_of_cities_in_Japan"
html = urllib.request.urlopen(url)
soup = BeautifulSoup(html, 'html.parser')
# HTMLから表(tableタグ)の部分を全て取得する
table = soup.find_all("table")
今回は,日本の都市についてまとめてあるwikipediaの表をスクレイピングしてみます.
プログラムのurllib.request.urlopenは,指定したurlのHTMLを取得します.その後,Beautiful Soupを使って扱いやすいように整形し,更に,HTMLから表がある部分(table タグで囲われてある部分)を全てsoup.find_all("table")で取得すれば準備完了です.
取得したいTABLEタグの名前を調べる
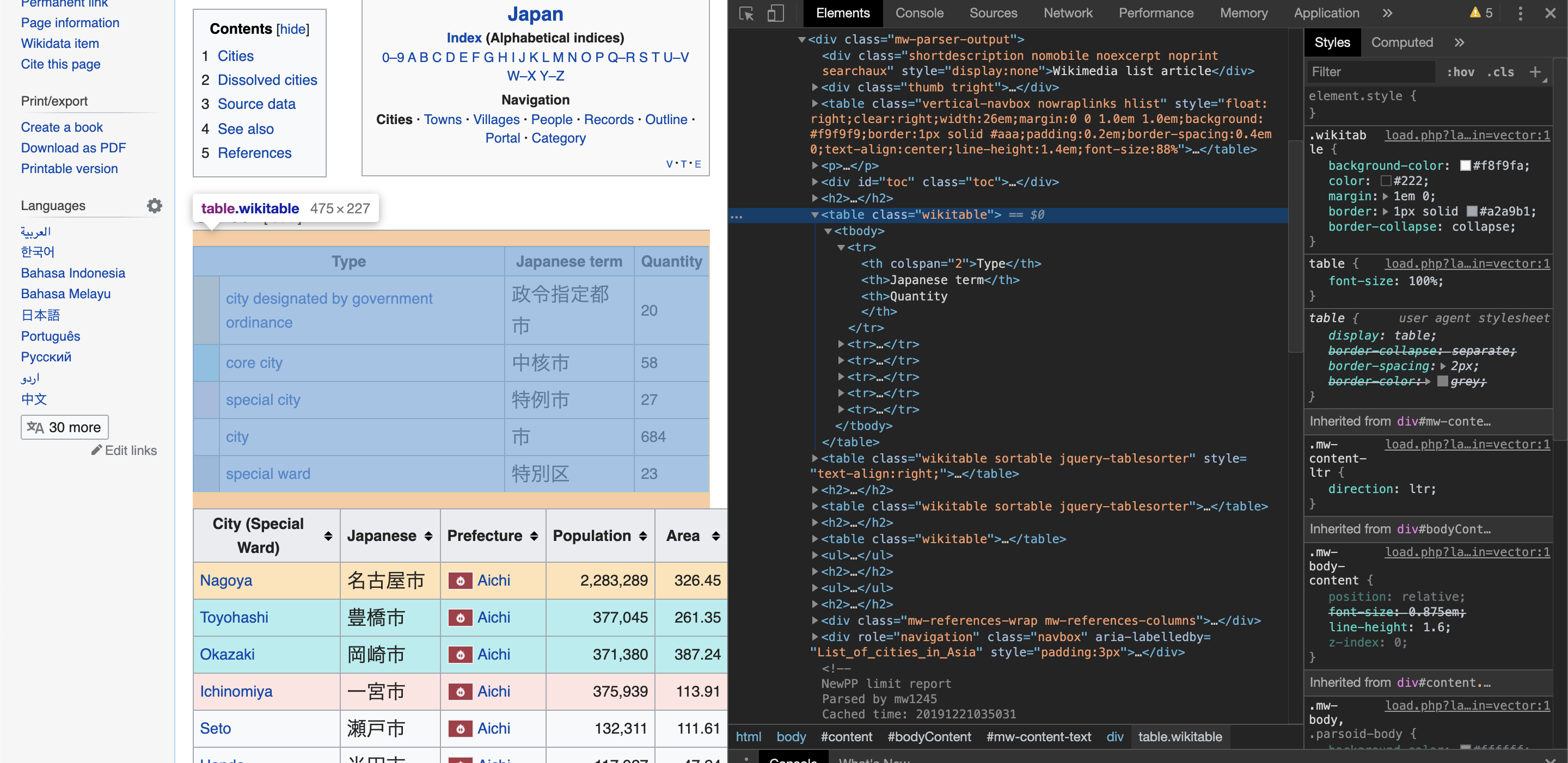
chromeブラウザを使用している方は,F12(macだとcommand+option+I)を押すことで開発者ツール(スクリーンショットの黒い画面)に入ることができます.その後,ElementsからHTMLのソースコードを見ることができるので,その中からスクレイピングしたいtableタグを探します.今回は,青く選択されている表を取得してみたいと思います.実はこれは単純に,全てのtableタグからclassNameが"wikitable"のものを選択することで取得できます.
for tab in table:
table_className = tab.get("class")
print(table_className)
if table_className[0] == "wikitable":
break
# break文がないときの出力結果
# ['vertical-navbox', 'nowraplinks', 'hlist']
# ['wikitable'] <- ここで,break文を使って抜ける
# ['wikitable', 'sortable']
# ['wikitable', 'sortable']
# ['wikitable']
# ['nowraplinks', 'mw-collapsible', 'autocollapse', 'navbox-inner']
・table_className[0]としているのは,classNameの先頭にwikitableが来ているためです.
・また,今回の場合,HTML上で他にもwikitableと同じ名前の表が複数存在していますが,今回欲しい表は常に一番目のwikitableなので初めてif文を通過した後,すぐにbreak文を使ってループを抜ける処理を入れてます.
目的の表を取り出せたら,CSVに変換して保存する
最後に,上のプログラムにCSV保存機能をつけます.
for tab in table:
table_className = tab.get("class")
if table_className[0] == "wikitable":
# CSV保存部分
with open("test.csv", "w", encoding='utf-8') as file:
writer = csv.writer(file)
rows = tab.find_all("tr")
for row in rows:
csvRow = []
for cell in row.findAll(['td', 'th']):
csvRow.append(cell.get_text())
writer.writerow(csvRow)
break
CSV保存機能の部分は,tableタグを行方向("tr")に抜き出して更に列方向("td", "th")に取り出し,list形式にappendしてCSVで保存するというものです(tableタグまで抜き出せたら,ここはコピペで使用していいと思う).
確認のため,pandasを使ってCSVを表示してみる
import pandas as pd
pd.read_csv("test.csv")
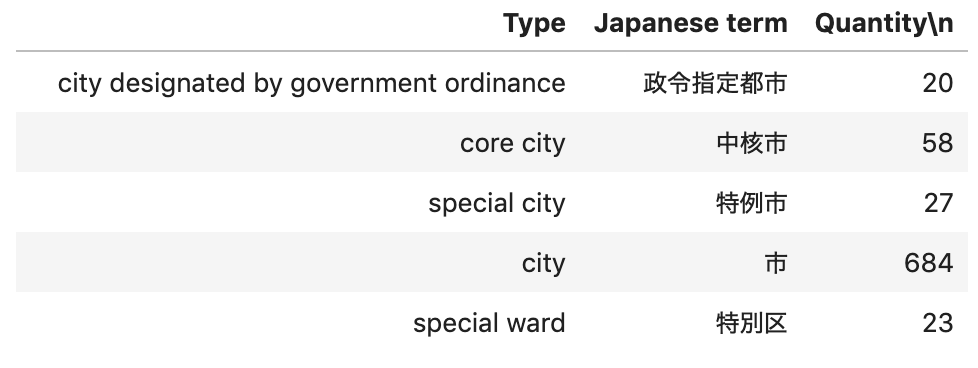
無事,csv保存したものがpandasによって表示することができました!
まとめ
スクレイピングしたいサイトにもよりますが,大体この流れで表をCSVで取得できると思います!ここまでご覧頂きありがとうございました〜!
参考文献