レーシングシミュレータの実データを使って、データサイエンスの概念を実装とともに解説しています。
この記事では 線形回帰・正則化(Ridge・Lasso) を扱います。
こんな人に役立ちます
- 線形回帰の係数が「何を意味するのか」を実データで理解したい
- Ridge・Lassoが「なぜ必要か」を直感的に掴みたい
- 多重共線性が実際にどんな問題を起こすか確認したい
結論
T1区間(富士スピードウェイ500〜1000m)の94ラップを対象に、24個のドライバー起因変数で線形回帰モデルを構築しました。
| モデル | 訓練R² | CV R² | CV RMSE |
|---|---|---|---|
| 線形回帰 | 0.954 | 0.861 | 0.133秒 |
| Ridge(α=1.0) | 0.953 | 0.875 | 0.128秒 |
| Ridge(α=10.0) | 0.942 | 0.886 | 0.128秒 |
| Lasso(α=0.01) | 0.939 | 0.899 | 0.118秒 |
| Random Forest | 0.979 | 0.848 | 0.149秒 |
- Lasso が CV R²=0.899 で最良(未知のラップのタイム差の約90%を説明できる精度)
- 正則化によって24変数を9変数に絞り込み
- Random Forest(CV R²=0.848)を線形モデルが上回った
throttle_pct__mean はT1区間全体でどれだけスロットルを開けられていたかを表します。単に「早く踏み始めた」だけでなく、「早く・強く・長く踏めた」ことが総合的に反映された変数であり、その影響がこれほど突出しているのは、立ち上がりからホームストレートへの加速フェーズがセクタータイムに直結しているためです。
問い
前記事で「スロットル平均が Random Forest 重要度1位」とわかりました。でも どのくらい効くのか? 横G・ブレーキ・ステアリングと比べたとき、各変数の影響を同じ単位で比較できないでしょうか。
線形回帰の「係数」がその答えになります。
線形回帰の係数が意味すること
線形回帰はこの式で予測します:
$$\hat{y} = w_1 x_1 + w_2 x_2 + \cdots + w_p x_p + b$$
すべての変数を StandardScaler で標準化(平均0・標準偏差1)してから学習するので、係数の絶対値を直接比較できます。
- 係数が負 → その変数が大きいほど タイムが速い
- 係数が正 → その変数が大きいほど タイムが遅い
標準化後の係数は「各変数を1標準偏差変化させたときのタイム変化量(秒)」として解釈できます。変数間でスケールが異なっていても比較可能です。
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X_op) # 24個のドライバー起因変数
lr = LinearRegression().fit(X_scaled, y)
coef_df = pd.DataFrame({'feature': op_cols, 'coef': lr.coef_}
).sort_values('coef', ascending=False)
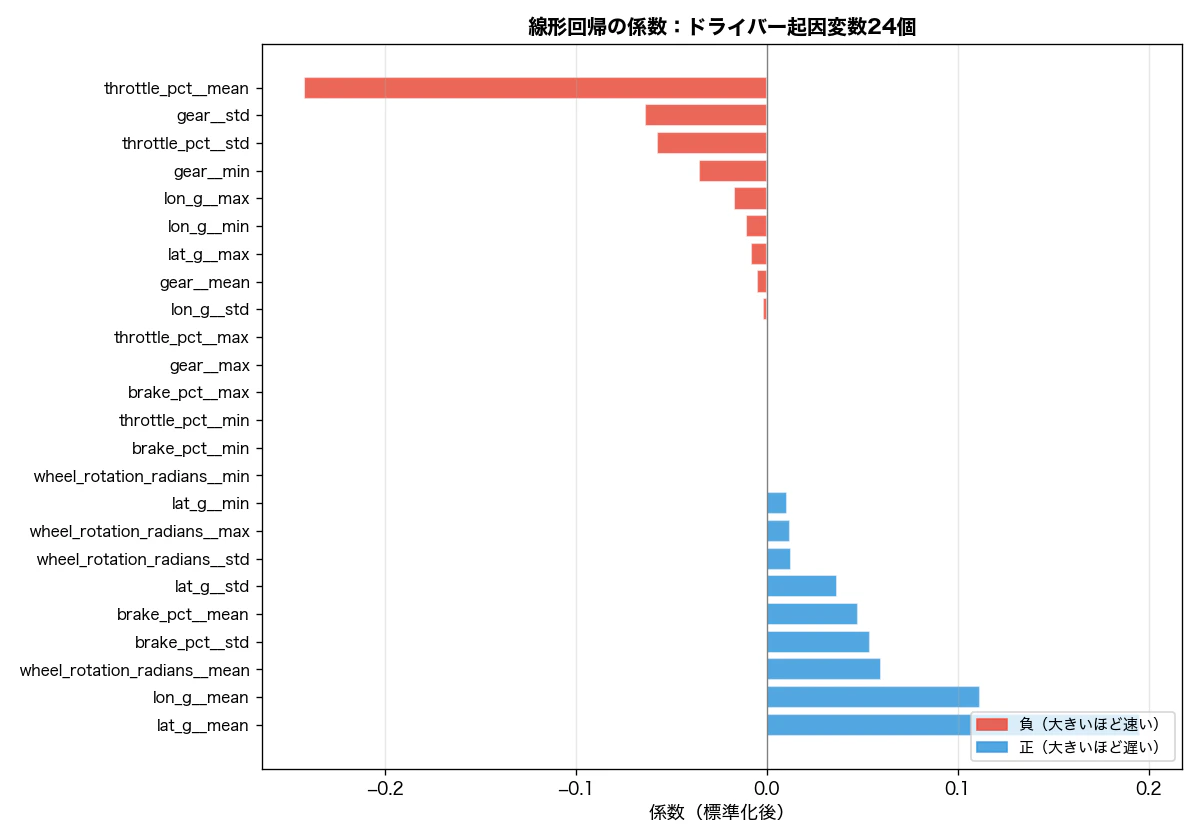
係数の大きさで見ると:
| 変数 | 係数 | 解釈 |
|---|---|---|
throttle_pct__mean |
-0.242 | スロットルを多く開けるほど速い |
lat_g__mean |
+0.195 | 横Gが弱い(旋回が浅い)ほど遅い |
lon_g__mean |
+0.112 | 前後Gの平均が大きいほど遅い |
wheel_rotation_radians__mean |
+0.060 | ステアリング角が大きいほど遅い |
gear__std |
-0.064 | ギア変動が大きいほど速い |
throttle_pct__std |
-0.057 | スロットル変動が大きいほど速い |
throttle_pct__mean の係数は最大で、「T1でスロットルを多く開けるほど速い」という前回の結果と一致します。gear__std が負(速い方向)なのは、T1通過後の加速でシフトアップ操作が行われるラップほど速いことを示しています。
lat_g__mean の係数が正なのは直感に反して見えます。T1(右コーナー)では lat_g__mean は負の値をとるため、係数が正 = lat_g__mean が 0 に近いほど遅い、つまり 横Gが弱い(コーナーを攻め切れていない)ほど遅い ということです。
問題:多重共線性
スクリプト実行時に大量の警告が出ました:
RuntimeWarning: divide by zero encountered in matmul
RuntimeWarning: overflow encountered in matmul
数値計算が不安定になっているサインです。原因は 多重共線性(Multicollinearity) です。たとえば throttle_pct__mean と throttle_pct__std は相関が高く、どちらか一方で説明できる情報が重複しています。変数間の相関が強いと、最小二乗法の計算が不安定になり係数が発散します。
訓練R²=0.954に対してCV R²=0.861と差があるのも 過学習(訓練データには高精度でフィットするが、未知データへの汎化性能が低い状態)の兆候で、通常の線形回帰だけでは係数の解釈が不安定になる可能性があります。
多重共線性への対処:Ridge と Lasso
正則化はコスト関数にペナルティ項を加え、係数が極端に大きくなるのを抑える手法です。
Ridge(L2正則化) — ペナルティに係数の二乗和を使う:
$$\text{minimize} \quad \sum_{i=1}^n (y_i - \hat{y}i)^2 + \alpha \sum{j=1}^p w_j^2$$
すべての係数をゼロに向けて縮小します。α が大きいほど縮小が強くなります。
Lasso(L1正則化) — ペナルティに係数の絶対値の和を使う:
$$\text{minimize} \quad \sum_{i=1}^n (y_i - \hat{y}i)^2 + \alpha \sum{j=1}^p |w_j|$$
係数を 完全にゼロ化 する特性があります。不要な変数を自動で除外する特徴量選択の効果があります。
from sklearn.linear_model import Ridge, Lasso
from sklearn.model_selection import cross_val_score, KFold
kf = KFold(n_splits=5, shuffle=True, random_state=42)
models = {
'線形回帰': LinearRegression(),
'Ridge(α=10.0)': Ridge(alpha=10.0),
'Lasso(α=0.01)': Lasso(alpha=0.01, max_iter=10000),
}
for name, model in models.items():
cv_r2 = cross_val_score(model, X_scaled, y, cv=kf, scoring='r2')
print(f"{name}: CV R² = {cv_r2.mean():.3f}")
Ridge と Lasso の使い分け
| Ridge | Lasso | |
|---|---|---|
| 変数選択 | しない(全変数を残す) | する(不要な変数をゼロに) |
| 向いている場面 | 多くの変数が少しずつ効いている | 一部の変数だけが効いている |
| 係数の解釈 | 縮小されるが全変数に値がある | 残った変数だけを読めばよい |
今回のデータでは Lasso(CV R²=0.899)が Ridge(0.886)を上回り、24変数を9変数に絞り込みました。これは「T1タイムに効いているのは一部の変数だけ」という構造を示しています。変数の数が多く、重要なものが少数に絞られると予想できる場合は Lasso が出発点として有効です。
係数の変化を比較する
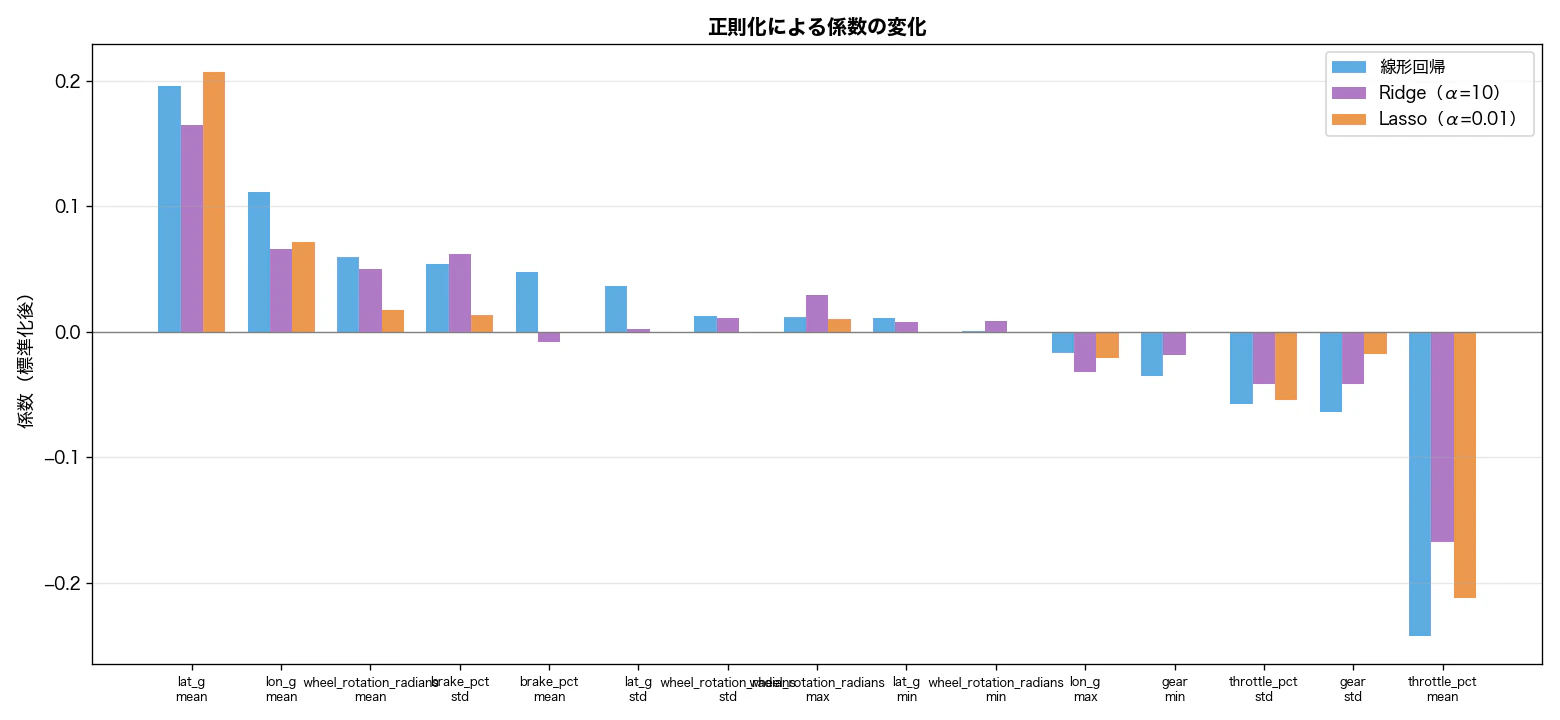
正則化前後で係数がどう変化するかを主要変数で比較すると、Ridge は係数を縮小しつつ形状を維持します。Lasso は不要な変数をゼロに落とし、残った変数の係数を明確にします。
Lassoの変数選択効果
Lasso(α=0.01)で24変数中 9変数 が残りました:
Lasso(α=0.01)係数(非ゼロ: 9個)
throttle_pct__mean -0.212 ← 最も速さに効く
lat_g__mean +0.207 ← 横Gが弱いほど遅い
throttle_pct__std -0.054
lon_g__mean +0.071
lon_g__max -0.021
gear__std -0.018
wheel_rotation_radians__mean +0.017
brake_pct__std +0.013
wheel_rotation_radians__max +0.010
throttle_pct__mean と lat_g__mean が突出しています。この2変数が、T1タイム差を説明するうえで中心的な役割を持っていることをLassoが示しています。
Lassoでゼロになった変数が「完全に不要」とは限りません。相関の高い変数同士では、代表として片方だけが残ることがあります。Lassoの結果は「候補を絞るための手がかり」として読むのが安全です。
モデル比較:線形 vs 非線形
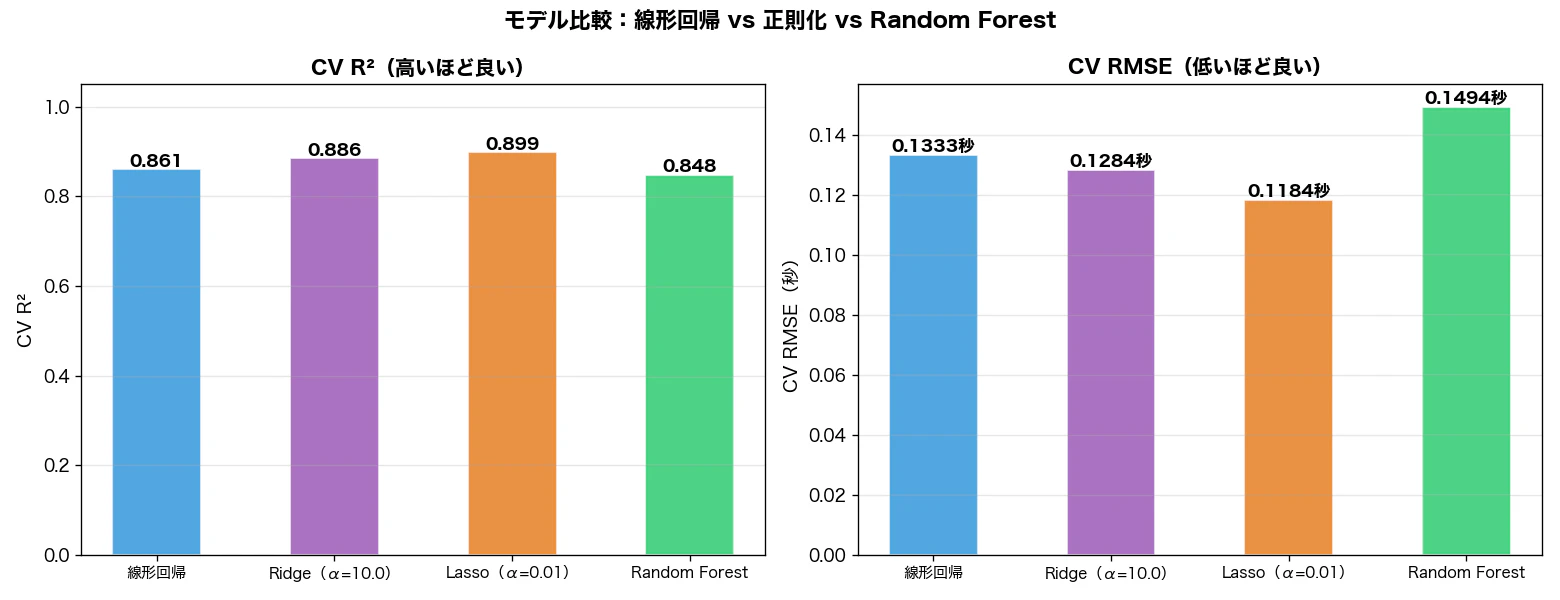
注目すべきは Random Forest(CV R²=0.848)が線形モデルを下回った点です。Random Forest は「データの細かいパターンまで学習できる」複雑なモデルのため、サンプル数が少ない(n=94)と訓練データのノイズまで覚えてしまいます。これが過学習の原因です。
T1は「ブレーキ→旋回→加速」という単一イベントで、スロットル開度とセクタータイムの関係はほぼ比例しています。非線形な相互作用が少ない問題ではシンプルな線形モデルが強さを発揮します。少なくとも今回の特徴量設計と94ラップの範囲では、 線形回帰で十分な構造 があると言えます。
実測値 vs 予測値のプロットで確認できます:
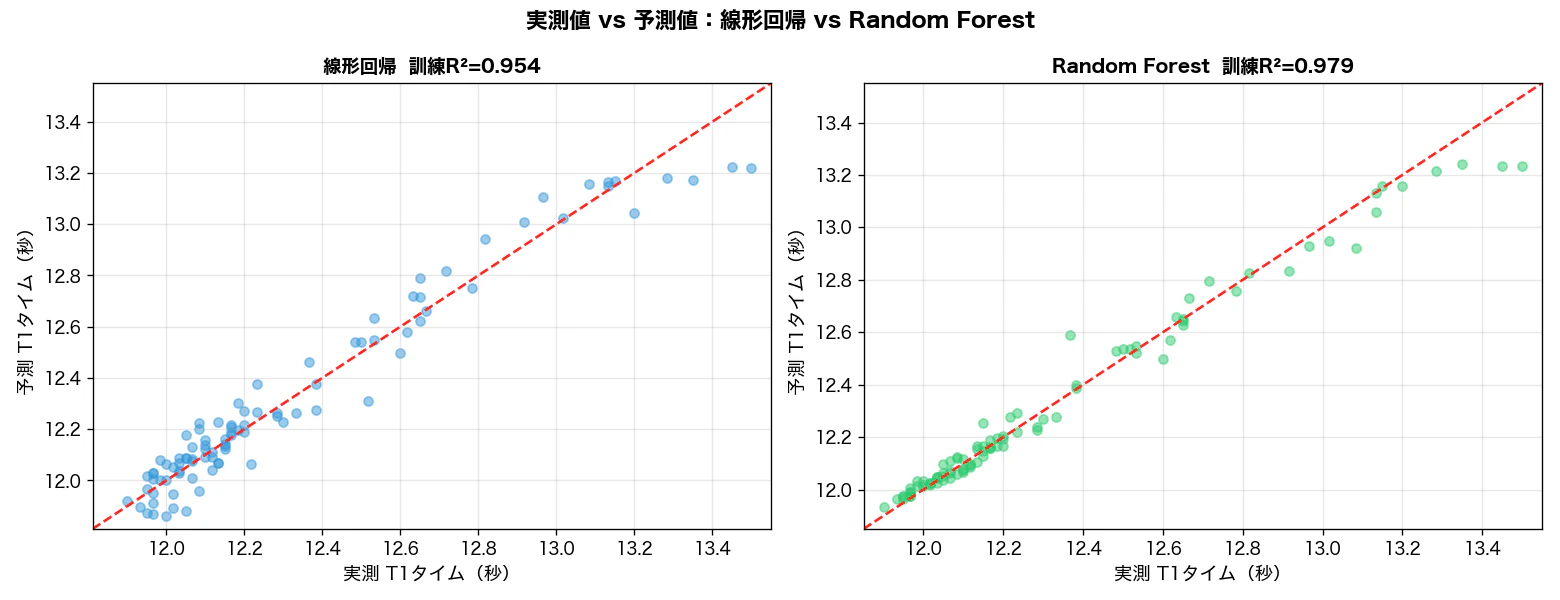
線形回帰でも Random Forest でも予測点は対角線に沿っており、構造的なバイアスはありません。ただし Random Forest は訓練R²=0.979(過学習)に対してCV R²=0.848と差が大きいです。
まとめ
| ポイント | 内容 |
|---|---|
| 最も速さに効く変数 |
throttle_pct__mean(係数 -0.242)。T1区間でどれだけスロットルを開けられたかが直結 |
| 多重共線性の問題 | 線形回帰の係数が不安定になる |
| Ridge の効果 | 係数を縮小し安定化(CV R²: 0.861→0.886) |
| Lasso の効果 | 24変数→9変数に絞り込み(CV R²: 0.899が最良) |
| Random Forest との比較 | 線形モデルが上回った(T1は線形関係が支配的) |
「T1で何が速さを決めるか」は線形回帰の係数で明快に読めます。正則化はその係数をより信頼できるものにし、Lassoは「本当に効いている変数」を9個に絞り込みました。
この手法が使える場面
「操作(入力)が結果(出力)にどれくらい効くか」を数値化したい場面に広く使えます。
| 領域 | 操作(入力変数) | 結果(目的変数) |
|---|---|---|
| モータースポーツ | スロットル・ブレーキ・ステアリング | セクタータイム |
| 製造業 | 温度・圧力・送り速度 | 製品品質・不良率 |
| IoT・設備管理 | 運転条件・稼働パターン | 消費電力・摩耗量 |
| EC・マーケティング | 広告費・配信時間帯・クリエイティブ | CVR・売上 |
正則化(Ridge・Lasso)は特に 変数が多く、互いに相関している 場面で効果を発揮します。Lasso は「本当に効いている変数を絞り込む」用途に向いており、説明変数の選択と係数の解釈を同時に行えます。