レーシングシミュレータの実データを使って、データサイエンスの概念を実装とともに解説しています。
この記事では 「ドライバー起因変数に絞った予測モデル」 を扱います。
こんな人に役立ちます
- 特徴量を「操作」と「挙動」に分けて考える視点を持ちたい
- Random Forest 回帰モデルをクロスバリデーションで評価する手順を実例で見たい
- 「変数を減らしたら精度はどれくらい落ちるか」を確かめたい
結論
- ドライバー起因変数(直接操作+操作の即時結果)24個だけで CV R² = 0.848
- 全特徴量108個のモデルとの差は 0.071(全特徴量 CV R² = 0.919)
- 重要度は
throttle_pct__mean(59.2%)とlat_g__mean(28.0%)の2つで87%
T1タイムのばらつきは、スロットル開度の平均(どれだけ踏めているか)と横Gの平均(どれだけ攻めたラインを走れているか)によって高い精度で説明できます。
問い:「操作の結果」を除いたら、何が残るか
車体挙動を見なくても、操作だけでT1の速さをどこまで説明できるか——これが今回の問いです。
前の記事では104個の特徴量から T1通過タイムと強く相関する変数を探しました。その結果は次の通りでした。
1位 yaw_rate__mean r = +0.945 ヨーレート
2位 sus_height_rl__mean r = -0.915 左後サスペンション変位
3位 sus_height_fl__mean r = -0.852 左前サスペンション変位
これらはドライバーが直接動かす変数ではありません。操作の結果として変化する車体挙動です。
「サスペンションが沈んでいるから速い」は事実ですが、「だからどう操作を変えれば速くなるか」は答えられません。
操作を改善するには、ドライバーの操作に起因する変数——スロットル・ブレーキ・ステアリング・ギア・横G・前後G——に絞った分析が必要です。
ドライバー起因変数だけでどこまで T1タイムを予測できるのか。
このアプローチはモータースポーツに限らず、製造業やIoTなど「操作と結果の関係を分析する」多くの実務領域で使われている考え方です。「作業条件だけで品質をどこまで予測できるか」「センサを減らしても精度が出るか」——構造は同じです。
テレメトリ変数を3種類に分類する
テレメトリのカラムをドライバーとの距離感で3階層に分類します。
| 種類 | 具体例 | 特徴 |
|---|---|---|
| 直接操作 | throttle_pct, brake_pct, gear, wheel_rotation_radians | ドライバーがペダル・シフト・ステアリングを動かす変数 |
| 操作の即時結果 | lat_g, lon_g | 操作に対してほぼ即座に現れる物理量。ライン取りと荷重移動を反映 |
| 車体挙動 | sus_height, body_height, yaw_rate | 操作の積み重ねが遅延して現れる状態量 |
横G(lat_g)と前後G(lon_g)は厳密には「直接操作変数」ではなく、ステアリング・アクセル・ブレーキ操作の即時的な結果です。一方、サスペンション変位(sus_height)は荷重移動の蓄積であり、操作から数フレーム遅れて変化します。
今回は「直接操作」と「操作の即時結果」をまとめて ドライバー起因変数 として分析します。
データ準備とドライバー起因変数の抽出
データは前の記事と同じです。Supra18 RM Dry、IQR外れ値除外(閾値 13.519秒)+ヨーレート異常ラップ除外後の n=94本を使います。
速度派生チャンネル(speed_kmh、wheel_rad_s など)を除いた104特徴量から、ドライバー起因変数に対応するカラムだけを抽出します。
OPERATION_CHANNELS = {
'throttle_pct', # スロットル開度
'brake_pct', # ブレーキ圧
'lat_g', # 横G(ステアリング操作の即時結果)
'lon_g', # 前後G(アクセル・ブレーキ操作の即時結果)
'gear', # ギア
'wheel_rotation_radians', # ステアリング角(rad)
}
op_cols = [c for c in all_cols
if any(c.startswith(ch + '__') for ch in OPERATION_CHANNELS)]
# → 24個(各チャンネルの mean / max / min / std)
抽出された24個の特徴量:各チャンネルの mean / max / min / std × 6チャンネル。
モデルを構築してクロスバリデーションで評価する
from sklearn.ensemble import RandomForestRegressor
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import cross_val_score, KFold
scaler = StandardScaler()
X_op_scaled = scaler.fit_transform(X_op) # Random Forestはスケール不変だが、線形回帰など他モデルと条件を揃えるため適用
rf_op = RandomForestRegressor(n_estimators=300, random_state=42, n_jobs=-1)
kf = KFold(n_splits=5, shuffle=True, random_state=42)
cv_r2 = cross_val_score(rf_op, X_op_scaled, y, cv=kf, scoring='r2')
print(f"CV R²(平均): {cv_r2.mean():.3f}")
# → CV R²(平均): 0.848
5分割交差検証(KFold)を使います。訓練データでモデルを学習し、未知のデータで予測精度を測ることを5回繰り返し、平均を取ります。
R² と CV R² について
R²(決定係数) は予測精度の指標で、0〜1の値を取ります。1に近いほど実測値と予測値が一致しており、0は「平均値を予測するだけ」と同等の精度を意味します。
CV R²(交差検証 R²) は、モデルが学習に使っていないデータに対してどれくらいの精度を出せるかを測ります。訓練データだけで評価した R²(訓練 R²)はモデルが訓練データを記憶した過学習の影響を受けますが、CV R² はその影響を除いた汎化性能の指標です。
CV R² = 0.848——ドライバー起因変数24個だけで、T1通過タイムの分散の84.8%を説明できています。
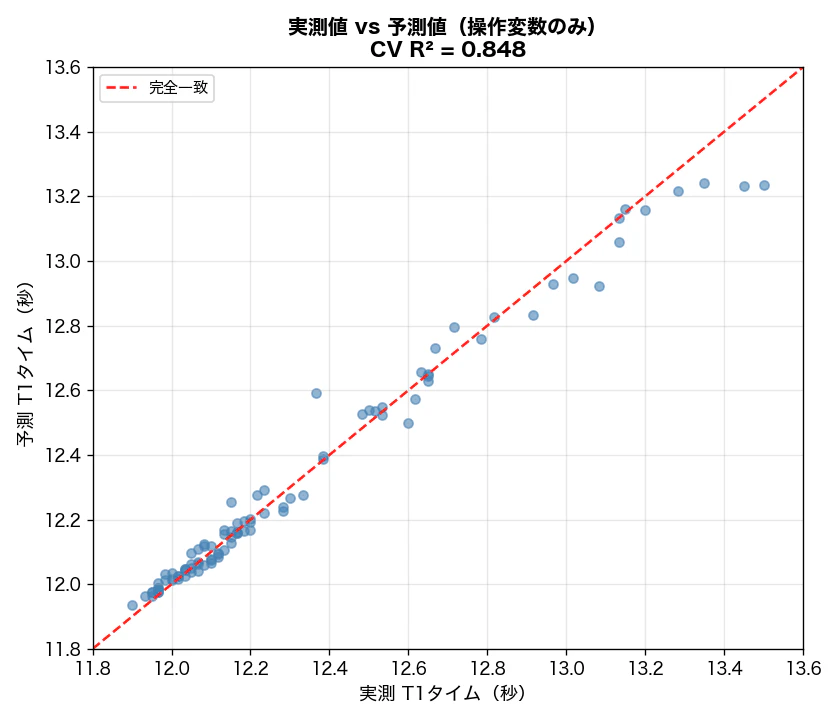
縦軸が予測値、横軸が実測値です。点が赤い破線(完全一致)に近いほど精度が高い。全体的に対角線に沿って分布しており、ドライバー起因変数だけでもタイムの傾向を捉えられています。
ドライバー起因変数の中での特徴量重要度
rf_op.fit(X_op_scaled, y)
rf_op_df = pd.DataFrame({
'feature': op_cols,
'importance': rf_op.feature_importances_
}).sort_values('importance', ascending=False)

1位 throttle_pct__mean 59.2% スロットル開度(平均)
2位 lat_g__mean 28.0% 横G(平均)
3位 wheel_rotation_radians__mean 1.4% ステアリング角(平均)
4位 throttle_pct__std 1.3% スロットル開度のばらつき
5位 brake_pct__std 1.3% ブレーキ圧のばらつき
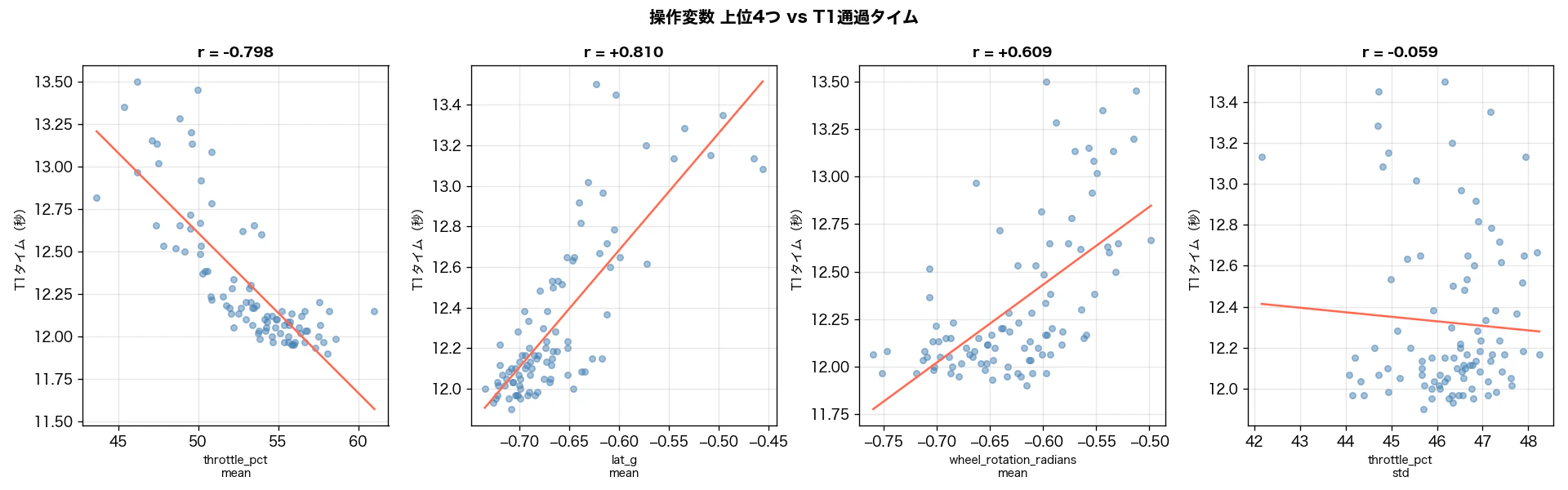
上位2変数で重要度の 87% を占めます。
スロットル開度(throttle_pct__mean):59.2%
T1区間の平均スロットル開度がドライバー起因変数の中で最重要です。相関係数は r = -0.798——スロットルを多く踏めているラップほどタイムが速い傾向があります。
ステアリング角(wheel_rotation_radians__mean):1.4%
相関係数は r = +0.609(3位)。T1は右コーナーのためステアリング角は負値(右回り)で、0に近い(切れていない)ラップほどタイムが遅い傾向があります。「コーナーへの切り込みが浅い」ラップが遅いという解釈と整合します。
T1はホームストレートエンドに位置する右コーナーです。ブレーキング後に素早くスロットルを開けられるかどうか、つまり立ち上がりのタイミング がタイムを左右します。T1の先には長いストレートが続くため、早くスロットルを開けるほどストレート後半の速度が伸び、その差がT1通過タイムに直接現れます。
横G(lat_g__mean):28.0%
T1区間の平均横Gは r = +0.810——横Gが大きいラップほど速い傾向があります。横Gはコーナリング中の遠心力の大きさを表しており、コーナリングの強さ(ライン・速度・タイヤ荷重の複合結果)の指標です。速く・深いラインを走れているラップほど横Gが大きくなります。
相関係数との比較
ドライバー起因変数内で相関係数と重要度を比べると、興味深い逆転があります。
| 変数 | 相関係数 | Random Forest 重要度 |
|---|---|---|
throttle_pct__mean |
r=-0.798(2位) | 59.2%(1位) |
lat_g__mean |
r=+0.810(1位) | 28.0%(2位) |
相関係数では横Gがわずかに上ですが、Random Forest ではスロットルが大きく上回っています。Random Forest の決定木分割は「スロットルがある閾値を超えているかどうか」でラップを分類するため、非線形なパターンや他の変数との組み合わせを含む貢献度を捉えています。
全特徴量モデルとの精度比較
ドライバー起因変数24個のモデルと全特徴量108個のモデルを比べます。

| モデル | 特徴量数 | CV R² |
|---|---|---|
| ドライバー起因変数のみ | 24 | 0.848 |
| 全特徴量 | 108 | 0.919 |
差は 0.071。全特徴量の追加で精度は上がりますが、ドライバー起因変数だけでも84.8%の説明力があります。グラフ下部の破線(R²=0)は「全ラップに対してタイムの平均値を予測するだけ」という最低限のベースラインです。両モデルともそれを大きく上回っています。
残り6.6%の差は、サスペンション変位やヨーレートなどの車体挙動変数が補っています。車体挙動変数は「操作の積み重ねが車体にどう現れるか」を捉えており、ドライバー起因変数だけでは表しきれない微細な走行の質の差を反映しています。
「ドライバー起因変数で85%説明できる」の解釈
この結果は「スロットルと横Gを測るだけでタイムの85%を予測できる」という意味ではありません。「スロットルと横Gの統計量が、94本のラップ間のタイム差の85%を統計的に説明する」という意味です。予測モデルはあくまで相関関係を学習しており、因果関係を保証するものではありません。
まとめ
| 変数 | 種別 | Random Forest 重要度 | 相関係数 |
|---|---|---|---|
throttle_pct__mean |
直接操作(スロットル) | 59.2%(1位) | r=-0.798 |
lat_g__mean |
操作の即時結果(横G) | 28.0%(2位) | r=+0.810 |
wheel_rotation_radians__mean |
直接操作(ステアリング) | 1.4%(3位) | r=+0.609 |
ドライバー起因変数24個だけで CV R² = 0.848 を達成しました。全特徴量との差は 0.071 であり、「ドライバー起因変数だけでもタイムの傾向を十分に予測できる」と言えます。
T1の速さは throttle_pct__mean と lat_g__mean の2変数で87%が説明されます。「T1区間でどれだけスロットルを踏めているか」と「どれだけ攻めたラインを走れているか」がタイムを決める2大要素です。
特徴量を「直接操作」「操作の即時結果」「車体挙動」の3種類に分けることで、「速いラップと何が違うか」だけでなく「何を改善すれば速くなるか」 という問いに近づけます。
この分析の応用
「特徴量ベースの予測モデル+CV評価」はデータサイエンスの標準パターンです。今回はレーシングデータで実装しましたが、同じ構造が複数の領域で使われています。
| 領域 | 「操作」に相当するもの | 「結果」に相当するもの |
|---|---|---|
| モータースポーツ | スロットル・ブレーキ・ステアリング | ラップタイム |
| 製造業 | 温度・圧力・作業条件 | 品質・不良率 |
| IoT・設備管理 | 運転パラメータ | 消費電力・異常発生 |
| EC・マーケティング | クリック・閲覧行動 | 購買・離脱 |
構造はどれも同じです。「操作(入力)だけでどこまで結果を説明できるか」「どの操作変数が最も効くか」を明らかにすることで、改善ポイントを特定できます。
① ドライバーコーチング
モデルの重要度が「スロットルが足りない」「横Gが小さい(ラインが浅い)」を数値で示します。「何を変えれば速くなるか」を定量的に伝えられます。
② センサ・特徴量の削減
「108個から24個に削減しても CV R² = 0.848」という結果は、本質的な情報だけを残した軽量モデルが作れることを示しています。実務ではセンサコスト削減や計算軽量化(リアルタイム処理)への応用につながります。
③ 操作で改善できる領域 vs 構造に依存する領域
ドライバー起因変数(CV R² = 0.848)と全特徴量(0.919)の差 0.071 が「車体挙動でしか説明できない領域」です。「操作で改善できる余地」と「セッティング・車両特性に属する領域」の 責任分界点 が見えます。製造業では「作業条件で改善できる部分」と「設備や材料に起因する部分」の分離に対応します。
関連記事
- 時系列データから特徴量を作る — 特徴量エンジニアリングの詳細
- 104個の特徴量を作ったのに、効いていたのは数個だけだった — EDA・相関係数ランキング
- 相関係数27位 → Random Forest 1位。その原因は「95本中たった1本のラップ」だった — 特徴量スクリーニング
- 富士スピードウェイの1コーナーを、データサイエンスで分析する — T1区間の解説(note)