レーシングシミュレータの実データを使って、データサイエンスの概念を実装とともに解説しています。
この記事では 特徴量スクリーニング(相関係数とRandom Forestの比較)を扱います。
こんな人に役立ちます
- 相関係数とRandom Forest の特徴量重要度がなぜ異なる順位を返すかを理解したい
- 数十〜数百のカラムから「効いている変数」を絞り込む手順を実例で見たい
- 非線形な変数間関係を散布図で発見・検証する方法を知りたい
結論
- 相関係数27位の変数が、Random Forest の重要度では1位(53.7%)
- 原因は「非線形な閾値パターン」——散布図を見れば一目瞭然
- 相関係数だけでは見落とす変数が存在する
2手法の本質的な違い:相関係数は「全体の傾向」を測り、Random Forest は「データを分ける境界」を見つける。この違いが、同じデータから全く異なるランキングを生み出します。
問い:相関係数とRandom Forest、どちらが「効く変数」を正確に見つけられるか
前の記事では104個の特徴量に対して相関係数を計算し、T1区間の通過タイムと最も強く相関する変数を探しました。しかし記事の最後でこう書きました。
「相関係数は線形な関係しか捉えられない。Random Forestを使うと非線形な関係も含めて評価できる」
今回はその続きです。同じデータで相関係数とRandom Forestの両方を計算し、2手法の結果を比べます。
相関係数では27位だった変数が、Random Forestでは1位(53.7%)になりました。どちらが間違っているのでしょうか?
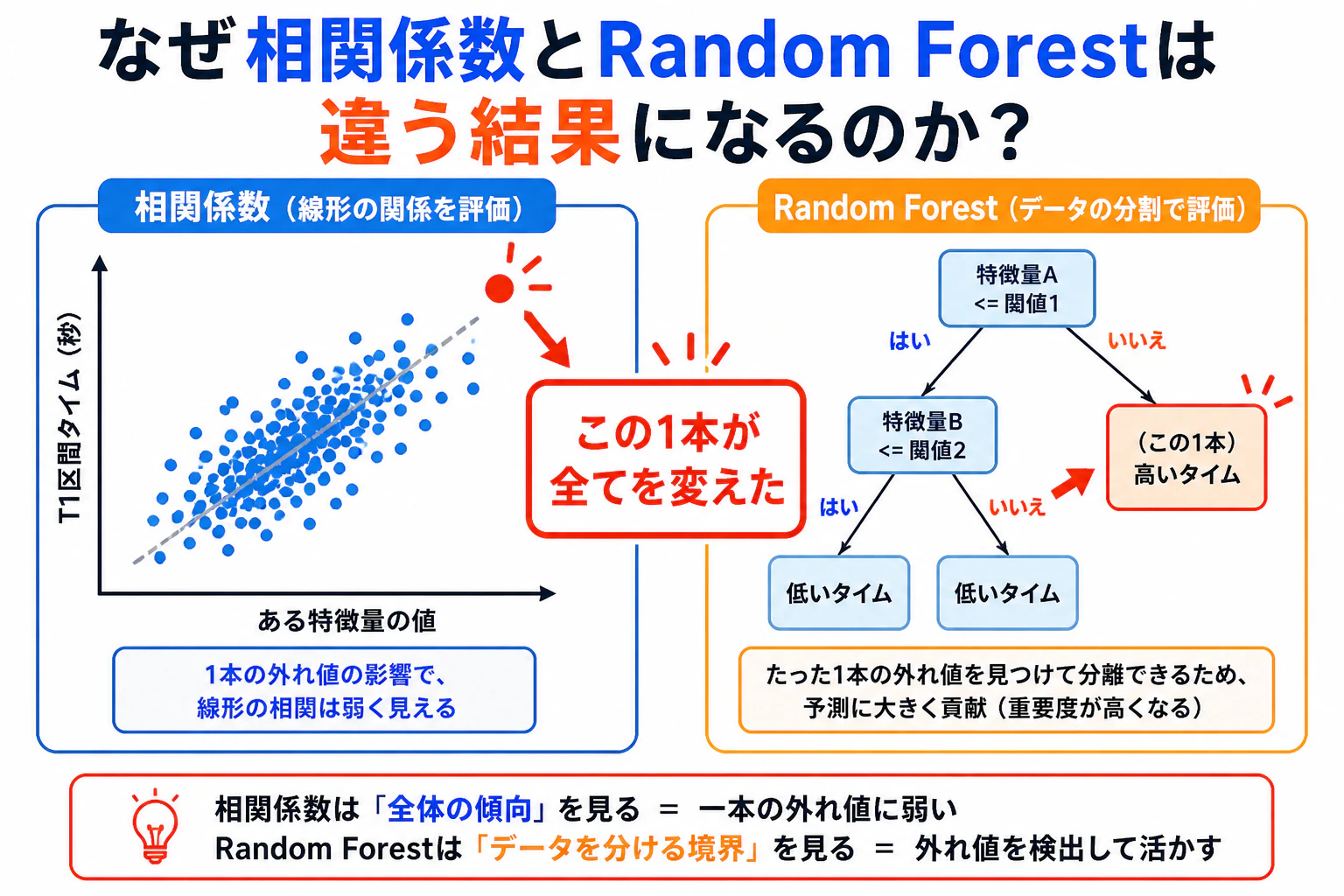
2つの手法でスクリーニングする
「効いている変数」を探す代表的な2手法を組み合わせます。
| 手法 | 何を測るか | 見落とすもの |
|---|---|---|
| 相関係数 | 線形な単調関係の強さ | 非線形関係・閾値効果・交互作用 |
| Random Forest | 予測に使われた分割の貢献度 | 変数の「方向性」(正負)・解釈のしやすさ |
相関係数は「一方が増えると他方も増える/減る」という単調な関係しか捉えられません。Random Forest は決定木の分割を繰り返すため、「閾値を超えると急に変化する」「U字型の関係」など非線形なパターンも検出できます。
2手法の順位を比べることで、線形スクリーニングでは見落とされた変数を発見できます。
データ準備
富士スピードウェイT1区間を対象とし、IQR法による外れ値除外後の95本を使います(閾値 13.519秒、5本のスピン・コースオフラップを除外)。使用ライブラリ:numpy、pandas、scipy、scikit-learn、matplotlib。
各チャンネルについて T1 区間内の4統計量(mean / max / min / std)を特徴量として抽出します。
import os
import pandas as pd
import numpy as np
from scipy import stats
from sklearn.ensemble import RandomForestRegressor
from sklearn.preprocessing import StandardScaler
DATA_DIR = "/path/to/TelemetryData"
T1_START_M = 500
T1_END_M = 1000
FPS = 60.0
# メタデータ・フラグ・セッション持ち越しカラムを除外
EXCLUDE_COLS = {
'packet_id', 'lap_count', 'best_lap_ms', 'last_lap_ms',
'tyre_temp_fl', 'tyre_temp_fr', 'tyre_temp_rl', 'tyre_temp_rr', # セッション持ち越し
'water_temp', 'oil_temp', 'fuel_remaining',
'pos_x', 'pos_y', 'pos_z',
'is_on_track', 'is_paused', 'car_code',
# ... (定数列・ギア比など)
}
def calc_dist(df):
dx = df['pos_x'].diff().fillna(0)
dy = df['pos_y'].diff().fillna(0)
dz = df['pos_z'].diff().fillna(0)
return np.sqrt(dx**2 + dy**2 + dz**2).cumsum()
def extract_features(filepath):
df = pd.read_csv(filepath).sort_values("packet_id").reset_index(drop=True)
df['dist'] = calc_dist(df)
entry_idx = df[df['dist'] >= T1_START_M].index[0]
exit_idx = df[df['dist'] >= T1_END_M].index[0]
t1_time = (exit_idx - entry_idx) / FPS
seg = df[(df['dist'] >= T1_START_M) & (df['dist'] <= T1_END_M)].copy()
analysis_cols = [c for c in df.columns if c not in EXCLUDE_COLS and c != 'dist']
row = {'t1_time': t1_time}
for col in analysis_cols:
vals = seg[col].dropna()
if vals.nunique() <= 1: # 定数列はスキップ
continue
row[f'{col}__mean'] = vals.mean()
row[f'{col}__max'] = vals.max()
row[f'{col}__min'] = vals.min()
row[f'{col}__std'] = vals.std()
return row
抽出後の特徴量数は 144(36チャンネル × 4統計量)。IQR外れ値除外後 n=95。
まず全チャンネルで相関係数を計算する
feat_cols = [c for c in df.columns if c != 't1_time']
X = df[feat_cols].values
y = df['t1_time'].values
corr_rows = []
for i, col in enumerate(feat_cols):
r, p = stats.pearsonr(X[:, i], y)
corr_rows.append({'feature': col, 'r': r, 'abs_r': abs(r)})
corr_df = pd.DataFrame(corr_rows).sort_values('abs_r', ascending=False)
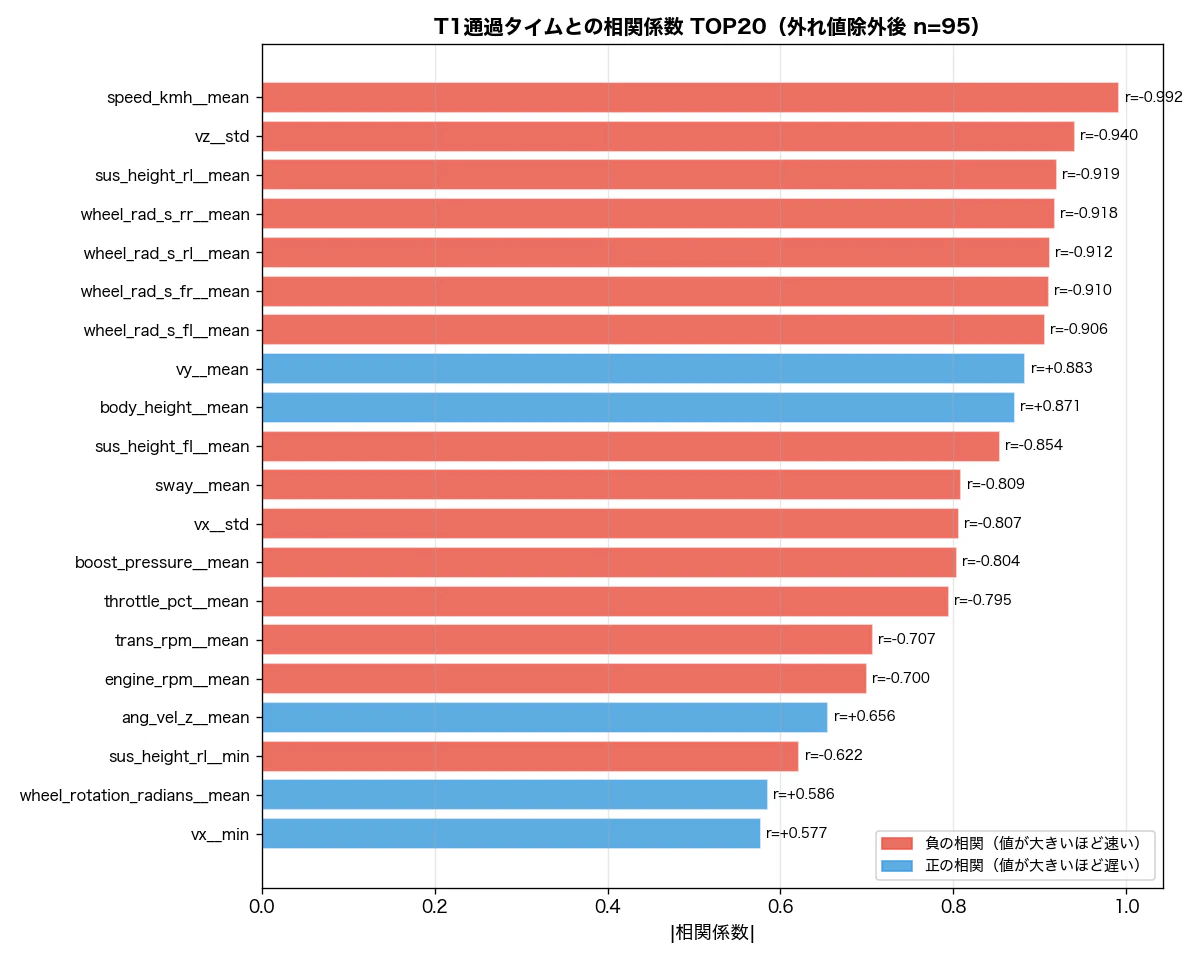
1位は speed_kmh__mean で r = -0.992。T1区間の通過タイムは実質的に「距離 ÷ 平均速度」で決まるので、数学的に必然の結果です。これは 同義反復(トートロジー)であり、「なぜ速いのか」の説明にはなりません。
これは特徴量選択における 「やってはいけない例」 の典型です。結果(速い)をそのまま原因(速度が高い)で説明しており、ドライビングの"何が違うのか"という問いには答えられません。
同様に、タイヤ回転数(wheel_rad_s_*)、ミッション回転数(trans_rpm)、速度成分(vx/vy/vz)も速度から直接導出できる量です。これらをランキングに並べても「速いラップは速い」という循環論法になります。
速度派生チャンネルを除外して再分析する
SPEED_DERIVED_PREFIXES = (
'speed_kmh__', 'wheel_rad_s_', 'trans_rpm__',
'vx__', 'vy__', 'vz__', 'wheel_rotation_radians__',
)
non_speed_cols = [
c for c in feat_cols
if not any(c.startswith(p) for p in SPEED_DERIVED_PREFIXES)
]
# 144 → 104 特徴量
相関係数ランキング(速度派生除外後)
X2 = df[non_speed_cols].values
corr2 = [{'feature': c, 'r': r, 'abs_r': abs(r)}
for c, (r, _) in zip(non_speed_cols, [stats.pearsonr(X2[:, i], y) for i in range(X2.shape[1])])]
corr2_df = pd.DataFrame(corr2).sort_values('abs_r', ascending=False)
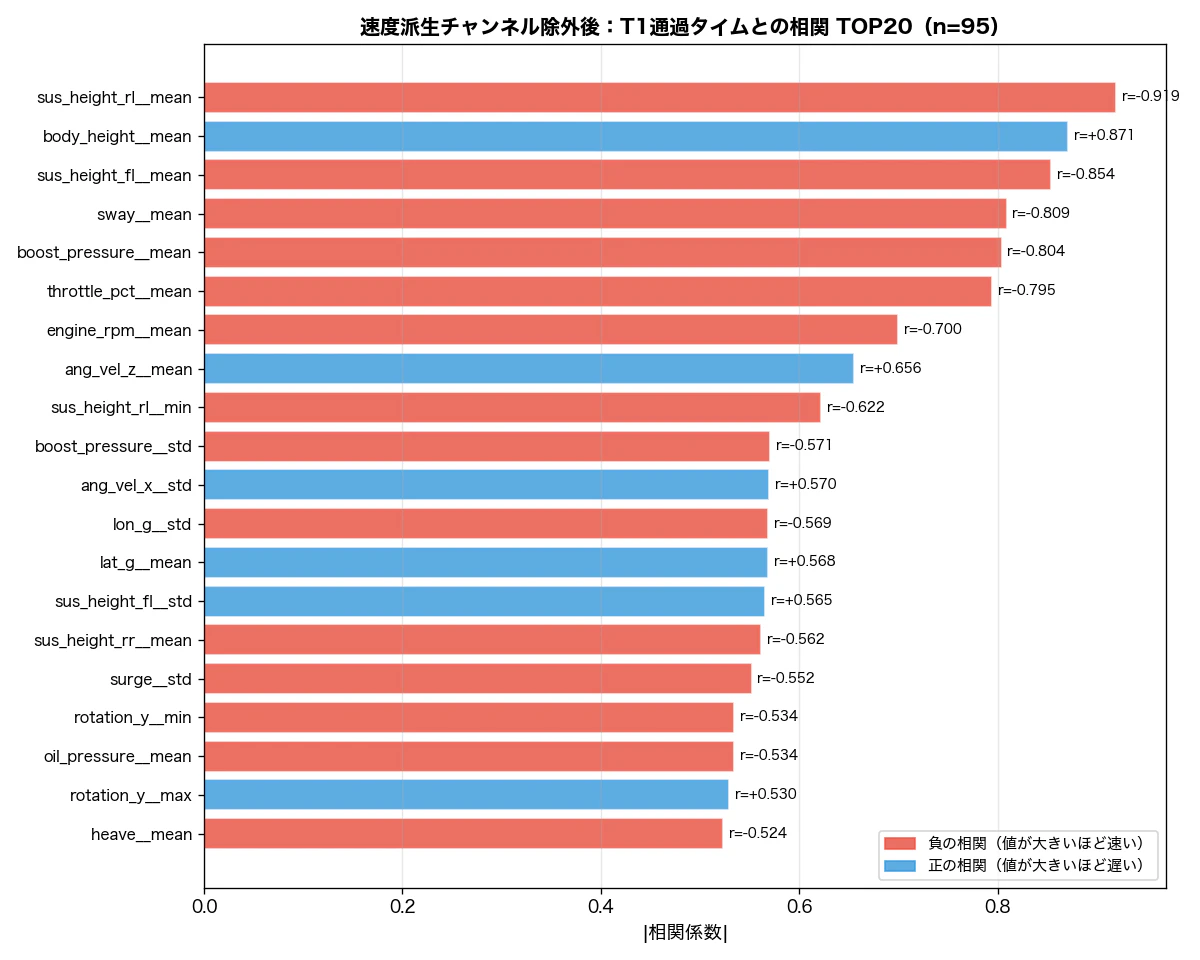
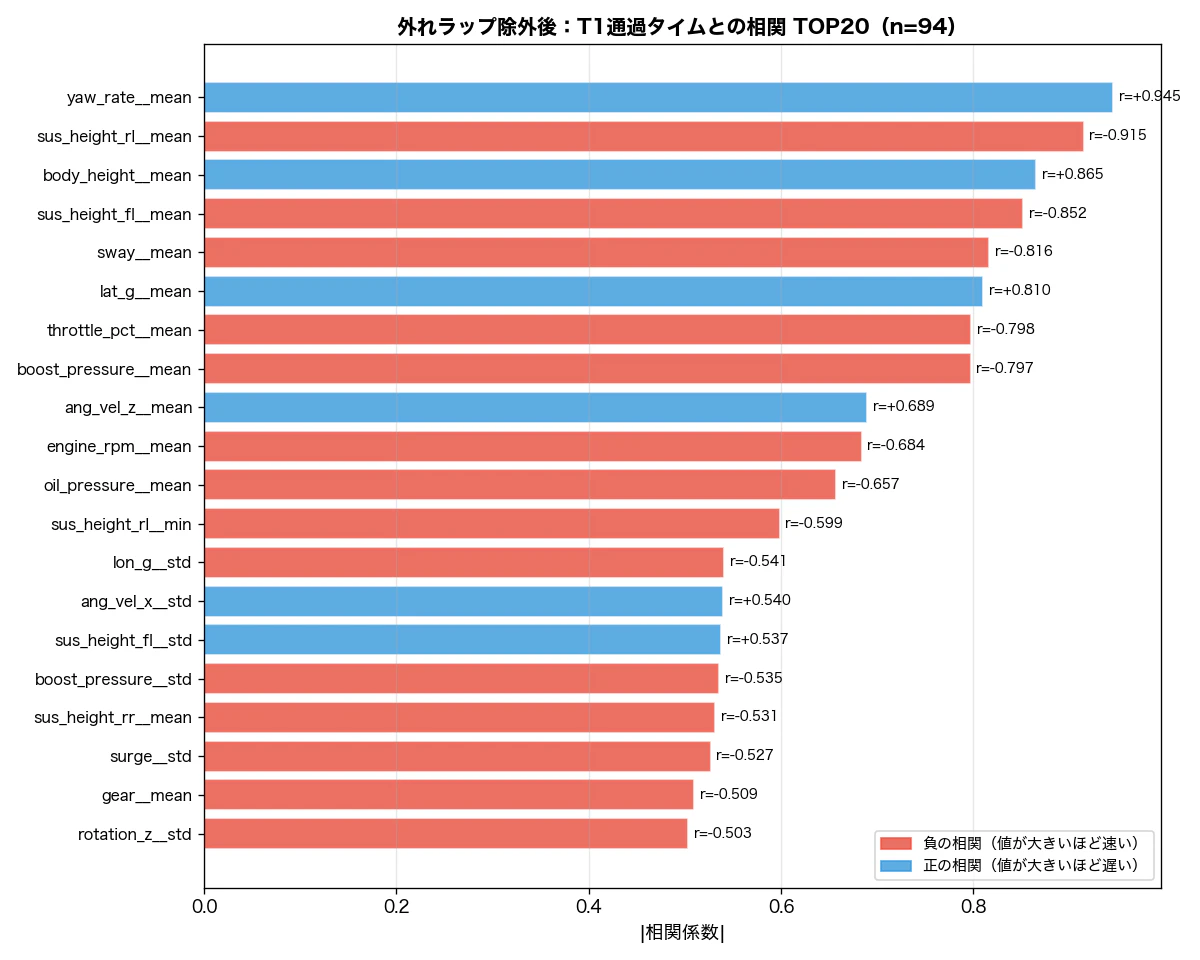
速度派生チャンネルを除くと、サスペンション変位と車体高さ が上位に浮かびます。
1位 sus_height_rl__mean r = -0.919 左後サスペンション変位(平均)
2位 body_height__mean r = +0.871 車体高さ(平均)
3位 sus_height_fl__mean r = -0.854 左前サスペンション変位(平均)
4位 sway__mean r = -0.809 横揺れ(平均)
5位 boost_pressure__mean r = -0.804 ブースト圧(平均)
6位 throttle_pct__mean r = -0.795 スロットル開度(平均)
サスペンションが沈んでいる(変位が小さい)ラップほど速い——コーナリング中の空力ダウンフォースや荷重移動が大きいラップが速い、という解釈と整合します。
Random Forest 特徴量重要度
Random Forest の特徴量重要度は、「その変数でデータを分割したときに、どれだけ予測誤差を減らせたか」を表す指標です。つまり、「どの変数が予測にどれだけ役立ったか」を示しています。
scaler = StandardScaler()
X2_scaled = scaler.fit_transform(X2)
rf = RandomForestRegressor(n_estimators=300, random_state=42, n_jobs=-1)
rf.fit(X2_scaled, y)
rf_df = pd.DataFrame({
'feature': non_speed_cols,
'importance': rf.feature_importances_
}).sort_values('importance', ascending=False)
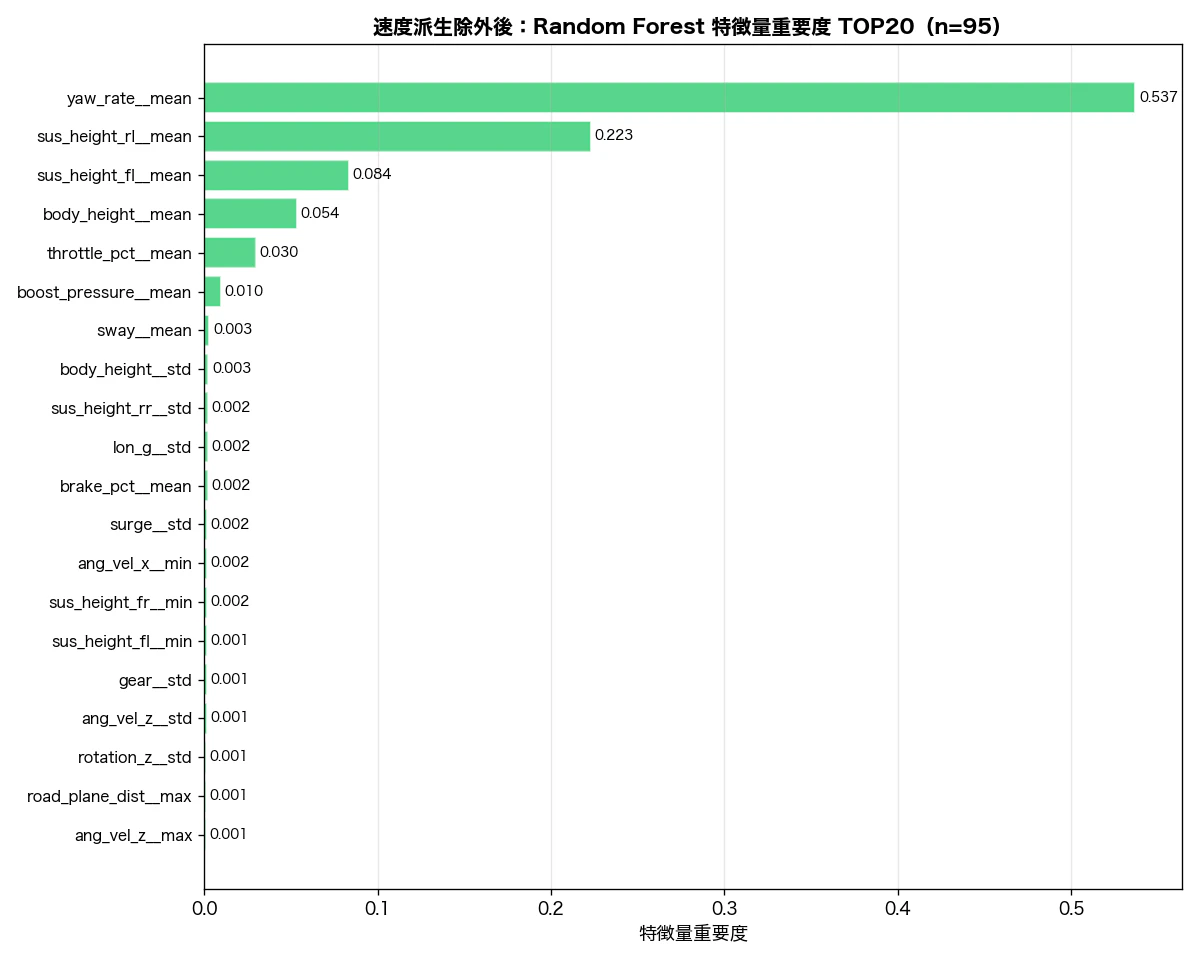
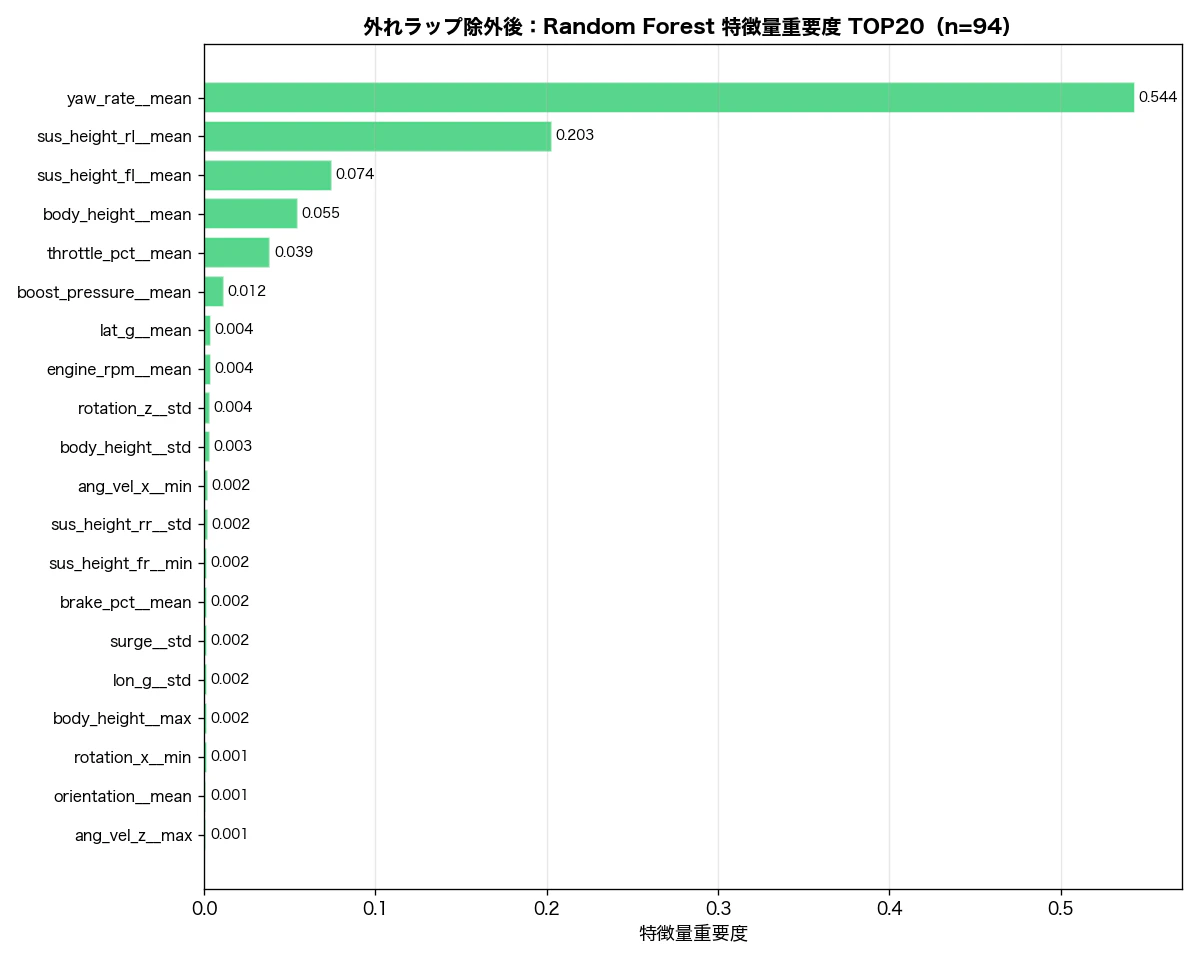
1位 yaw_rate__mean 53.7% ← 相関ランキングは27位(r = +0.452)
2位 sus_height_rl__mean 22.3%
3位 sus_height_fl__mean 8.4%
4位 body_height__mean 5.4%
5位 throttle_pct__mean 3.0%
yaw_rate__mean(ヨーレート平均)が全体の 53.7% を占めています。一方で相関係数は r = +0.452(27位)——この乖離の原因を掘り下げます。
相関27位 → Random Forest の重要度1位の謎
相関順位と Random Forest の順位を並べると、逆転が際立ちます。
| 特徴量 | 相関係数の順位 | Random Forest の重要度順位 |
|---|---|---|
yaw_rate__mean |
27 | 1 |
sus_height_rl__mean |
1 | 2 |
ang_vel_z__mean |
8 | 84 |
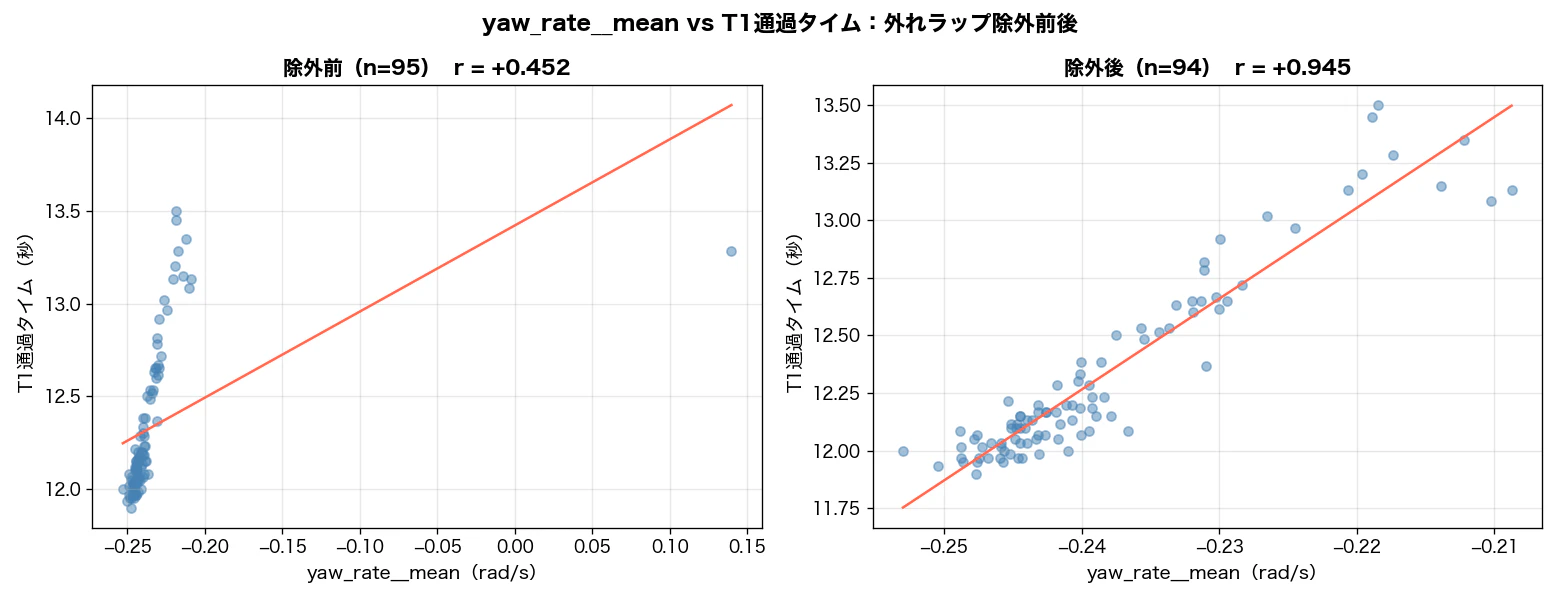
yaw_rate__mean は相関係数では r = +0.452(27位)なのに、Random Forest では重要度1位(53.7%)です。散布図で確認します。

左プロット(yaw_rate__mean)を見ると、94本の密集と1本の孤立点に分かれています。
- 密集(yaw_rate ≈ -0.25〜-0.21 rad/s):94本。T1は12.0〜13.5秒に分布。
- 孤立点(yaw_rate ≈ +0.14 rad/s):1本のみ。T1タイムが13.3秒(遅い側)。
T1は右コーナーのため、正常に旋回しているラップでは負のヨーレートになります。この1本は正のヨーレートを示しており、車が右にうまく曲がれていない——アンダーステアで外に膨らんだか、オーバーステアを修正しながら走ったラップです。Toyota Supraはリアドライブのため、T1区間でのアクセル操作ミスはオーバーステアに直結します。
決定木の分割は「yaw_rate__mean > -0.1 → 高T1タイム」というルールでこの1本を識別します。これが重要度53.7%の正体です。
一方、相関係数は全体に直線を引くため、94本が密集して1本だけ孤立する分布では傾きが緩くなり、r = 0.452 止まりになります。
外れラップの発見:t1_time の除外だけでは不十分だった
ここで立ち止まります。この1本は IQR法による外れ値除外 をくぐり抜けています。t1_time = 13.28秒で、閾値(13.519秒)以内に収まっていたためです。
目的変数(t1_time)の外れ値だけを除外しても、特徴量レベルの異常ラップは残る——これがデータクレンジングの盲点です。
この1本は「正常なコーナリングラップ」ではなく、「操作ミスで車が正しく向かなかったラップ」です。「速いラップと遅いラップで何が違うか」を分析したいなら、このようなラップは除外する方が正しいです。
# yaw_rate__mean が正(右コーナーで逆方向)のラップを除外
df_clean = df[df['yaw_rate__mean'] < 0].copy()
# 95本 → 94本(1本除外)
外れラップを除外して再分析する
除外後に相関係数と Random Forest の重要度を再計算します。
除外前後の yaw_rate の変化:
| 相関係数(r) | Random Forest 重要度 | |
|---|---|---|
| 除外前(n=95) | +0.452(27位) | 53.7%(1位) |
| 除外後(n=94) | +0.945(1位) | 54.4%(1位) |
たった1本です。
95本中の、たった1本を除いただけで、相関係数が 0.452 から 0.945 に跳ね上がりました。
つまり、yaw_rate は最初から強力な予測変数でした。それが相関27位に見えていたのは、1本の異常ラップが直線の傾きを押し下げていたためです。除外後の散布図(右)では、94本の正常ラップの中で「ヨーレートが0に近いほど(旋回が弱いほど)タイムが遅い」という明確な線形傾向が現れています。
教訓:外れ値除外は目的変数だけでは不十分
- 目的変数(t1_time)のIQR除外 → タイムが異常に遅い「スピン・コースオフ」ラップを除外
- 特徴量(yaw_rate)の確認 → 「操作ミスで車が正しく向かなかった」ラップを発見・除外
IQR除外は「t1_timeの値が極端かどうか」しか見ていません。今回の異常ラップはt1_time = 13.28秒と閾値(13.519秒)より速く、タイム的には「普通のラップ」でした。挙動は異常でも結果が正常範囲に収まることはあります。
これは実務でも頻繁に起きます。製造では「部品寸法は規格内だが製造温度が異常」、金融では「取引金額は正常だが時刻・場所の組み合わせが異常」(クレジットカード不正の典型)など、目的変数だけ見ると正常、特徴量を見ると異常というパターンです。
「Random Forest の重要度が高いのに相関が低い」という乖離を見つけたら散布図で確認する——この習慣がデータ品質問題の発見につながります。
まとめ
| 特徴量 | 相関順位(除外後) | Random Forest 重要度順位(除外後) | 解釈 |
|---|---|---|---|
yaw_rate__mean |
1(r=0.945) | 1(54.4%) | 両手法一致。ヨーレートが0に近いほど(旋回が弱いほど)遅い |
sus_height_rl__mean |
2(r=-0.915) | 2(20.3%) | 両手法一致:サスペンション沈み込み |
throttle_pct__mean |
7(r=-0.798) | 5(3.9%) | 両手法一致:スロットル開度 |
相関係数は「線形な関係の強さ」、Random Forest は「予測への貢献度」を測ります。今回は2手法の順位比較が「調査すべき変数」を浮かび上がらせ、散布図がその原因(1本の異常ラップ)を教えてくれました。散布図で確認し、除外して再分析することで、初めて正しい結果が得られます。
特徴量スクリーニングは手法を組み合わせ、散布図で必ず目視確認することが重要です。
特徴量スクリーニングのチェックリスト
- 相関係数と Random Forest の順位を比較したか
- 順位が大きく乖離する変数を散布図で確認したか
- 外れ値を目的変数だけでなく特徴量レベルでも確認したか
- 速度・回転数など「結果と同義の変数」を除外したか
関連記事
- どんなデータを記録しているのか — テレメトリデータのスキーマ詳細(note)
- 1コーナーの通過タイムは100本でどれくらいバラつくのか — 外れ値除外(IQR法)の詳細
- 104個の特徴量を作ったのに、効いていたのは数個だけだった — EDA・相関係数ランキング
- 富士スピードウェイの1コーナーを、データサイエンスで分析する — T1区間の解説(note)