はじめに
ここでは具体的なSMF Explorerの使用方法、すなわち、PythonスクリプトでのSMFデータの取り扱い方法について見ていきます。主に、公開されているチュートリアルのサンプル・コードから主要な部分をピックアップして解説していきます。
関連記事
SMF Explorerによるパフォーマンス情報可視化 - (1) 概要
SMF Explorerによるパフォーマンス情報可視化 - (2) 環境セットアップ
SMF Explorerによるパフォーマンス情報可視化 - (3) SMF Explorer使用方法
SMF Explorerによるパフォーマンス情報可視化 - (4) Tipsなど
SMF Explorerを使用する上での基本的な考え方
SMFレコードの特徴
まず、前段としてSMFレコードそのものの基本構造や特徴をおさらいしておきます。
可変長セクション
SMFの1レコードの構造はSMF Typeによって異なりますが、以下のような構造になっていることが多いです。

1レコードの中に、"セクション"と呼ばれるある意味のあるまとまったデータ構造が複数含まれます。この"セクション"部分は長さや数が可変です。そのため、各セクションについてのオフセット(開始位置)、長さ、数、の情報をフィールド情報として保持しています。この3つのフィールドは"triplet fields"と呼ばれます。
素のSMFデータをハンドリングする際は、各レコードごとに各セクションの"triplet fields"の情報を参照しどの位置に何の情報があるかを判断しながら構造を解釈していく必要があります。
例えば、SMF Type 70 のヘッダーのフォーマットを見てみると...
参考: Record type 70 (X'46') — RMF processor activity - Header/self-defining section
Subtype 1 には、CPU contorol section, CPU data section, ... といったセクションが含まれることになります。
複数フィールド参照の必要性
SMFレコードとして記録される情報は、恐らく情報取得時の効率化を重視しているために、ピンポイントで期待する情報そのものを保持するフィールドが用意されていないことがあります。例えば、CPU使用率のような情報は監視したいことが多いと思われる情報ですが、そのようなフィールドは用意されておらず、関連する複数のフィールドの情報を元に複雑な計算を行って算出する必要があります(そのためこれまでも各種レポーティングのツールなどが提供されています)。
時系列情報を扱う際に重要なTimestampの情報は特徴的です。
SMFレコードでは、Date(日付)とTime(時刻)の情報が別のフィールドとして保持されており、それぞれ以下のような型で保持されています。
参考: Standard and extended SMF record headers

従って、"日時"の情報としてハンドリングするためには、上の2つのフィールドを適切に解釈して1つの情報に加工し直すということを行う必要があります。
bit単位での情報
文字列型や数値型のようなフィールドは分かりやすくハンドリングも比較的容易ですが、True/Falseを意味するフラグのような情報を1byte(=8bit)の各bitにをそれぞれ保持させる場合があります。
参考: SMF72 Subtype3 - Workload manager control section

これらの情報を判断するためには、この1byteの情報をbit単位に分割して各bitの0/1によってbitごとの情報を読み解く必要があります。
SMF Explorerで扱えるデータの基本構造
DataFrame
PythonスクリプトからSMF Explorerを介してSMFデータを取得すると、PandasパッケージのDataFrameというオブジェクトでSMFデータが取得できます。
DataFrameはデータ分析の分野で広く一般的に利用されているライブラリの1つで、データサイエンティストにとっては当たり前のように使われているものです。
"DataFrame"という汎用的な方法でSMFデータを扱うことができる、というのがSMF Explorerの最大のメリットと言えます。
さて、先に示したように、素のSMFデータを扱う場合は構造が複雑だったり複数フィールドを加工しなければいけないので、求める情報を抽出するにはそれなりに大変な作業が必要になります。
SMF Explorerではその辺りのデータ抽出の複雑さを緩和するために、よく利用する情報についてはあらかじめ扱いやすいように加工したり、計算処理を埋め込んで扱いやすくしてくれています。
How to use Mapping and Samples Documentation
SMF ExplorerでハンドリングできるSMFデータのフィールド情報については上ののサイトから確認できますが、このガイドで示されている通り、元のSMFデータを扱えるだけでなく、複数のフィールドを計算した結果の新たなフィールドを追加したり、bit情報をBoolean型のフィールドとして提供したり、一部のフィールドについては扱いやすいような処理が施されています。
縦型テーブル
DataFrameでSMFデータを扱えるということは、すなわち、表/テーブル/2次元配列 の形でデータを扱えるということになります。Excel上の表のイメージでとらえると分かりやすいと思います。
各行にはSMFレコードが取得された時刻の情報が保持され、各列にはフィールドの情報が保持されるというイメージです。
一方で、SMFレコードというのは先に示した通り、複数の可変長のセクションが含まれる可能性があり、その場合フィールド(列)の情報がレコードによって一定ではないので、そのまま表の形に保持するのは無理があります。
そこで、1レコード中に複数の塊のセクション情報が含まれる場合、それを縦型(縦持ち/Long型)のテーブルとして保持することになります。すなわちSMF1レコードの情報をDataFrame上は複数行で保持するイメージになります。
縦型/横型のデータの持ち方については以下の記事が分かりやすいと思います。
参考: 【pandas】melt, pivot:縦横変換【データフレーム処理】
詳細については後続記事の具体例も合わせてご確認ください。
SMFダンプ・データセットへのアクセスの基本的な流れ
接続情報の設定
参考: Run SMF Explorer as a Python script
SMF Explorerを使用してSMFデータをハンドリングする際は、先の記事でも記載したようにz/OSMFのSMF RESTサービス経由でアクセスすることになります。すなわち、z/OSMFに対する接続情報(URL,ユーザー情報など)を設定する必要があります。
SMF Explorerの仕様では、z/OSMFの接続情報は環境変数として設定することになります。Pythonのコードとしては、例えば以下のようになります。
connection_string = "https://xxx:10443/zosmf/zosdg/smf"
user_name = "USERXX"
user_password = "PASSWORD"
verify_ssl = "false"
connection_info = f"mode=dgapi;url={connection_string};verify_ssl={verify_ssl};username={user_name};password={user_password}"
os.environ["SMFPY_CONNECTION_STRING"] = connection_info
SMFPY_CONNECTION_STRINGという環境変数に対して、mode=dgapi;url={connection_string};verify_ssl={verify_ssl};username={user_name};password={user_password} というフォーマットで接続情報をセットすることになります。
操作対象のSMFダンプ・データセットの指定
接続情報を環境変数にセットした状態で、smfexplorer.new_context()にて対象のSMFダンプ・データセットを指定すると、当該データセットを扱うためのContextオブジェクトが取得できます。
import smfexplorer
DATASET = "DEV01.SMFDUMP.TAG.D250309.V01"
ctx = smfexplorer.new_context(DATASET)
このContextオブジェクトに対して様々な操作を行うことで、当該SMFダンプ・データセットに含まれるSMFデータの情報を処理することができます。
SMFデータの取得
Contextオブジェクト(≒操作対象のSMFダンプ・データセット)に対して、request()関数を使って取得したいフィールドのリストを与えます(→FieldRequestオブジェクトが生成される)。さらにそのFieldRequestオブジェクトに対してrun()関数を発行することで、指定したフィールドの情報がDataFrameとして取得される、という流れになります。
具体例については次節でチュートリアルをベースに見ていきます。
チュートリアル解説
GitHubにSMF Explorer用のチュートリアルが提供されていますので、そちらのコードを追いながら、どういう操作をするとどういうことができるのかを見ていきたいと思います。ここでは、チュートリアル中の主要なコードについて一部ピックアップして解説していきます。
Tutorial 1 - Basics
Tutorial 1 はSMF Explorerの基本機能についての紹介が中心です。
SMF Explorerのバージョン確認
利用しているSMF Explorerのバージョンを確認します。
smfexplorer.__version__
'1.1.12'
SMFダンプ・データセットの状況確認
指定したSFMダンプ・データセットが有効かどうかをチェックします。
DATASET = "DEV01.ZMCOC.D200220.WL2.SMF"
ctx = smfexplorer.new_context(DATASET)
print(smfexplorer.check_dataset(DATASET))
print(smfexplorer.check_dataset("WRONG.SMF.DATA"))
True
False
この例では、WRONG.SMF.DATAという存在しないデータセットについては、check_dataset()関数の結果がFalseとなっており、無効であることが分かります。
SMFデータセットに含まれるSMFデータの確認
対象のSMFデータセットに含まれるSMF typeとレコード数を確認できます。
# get available types
ctx.get_available_types()
結果例

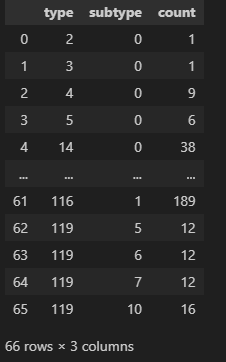
サブタイプごとの情報も取得可能です。
# get a complete SMF record overview
ctx.get_available_records()
結果例
より詳細な情報確認
desc = ctx.get_dataset_description()
dataset_desc = desc[DATASET]
dataset_desc['type_info']
結果例

フィールド情報確認
SMFType + SubTypeごとにモジュールが提供されているので、まずは扱いたいサブタイプのモジュールをインポートします。
from smfexplorer.fields import SMF70S1
上の例はSMF Type70 SubType1のモジュールをインポートしている例です。
各フィールド情報はSMF Explorerのマニュアルにも記述があります。例えばlpar_nameに関してはこちら。
SMF70S1 - lpar_name
Pythonスクリプトから '?'を使用してヘルプを確認することもできます。
?SMF70S1.lpar_name
Type: Field
String form: lpar_name
Length: 0
File: c:\y\vscode_workspace\smfexplorer\iseconf2025_smfexplroer_work01\venv311_test01\lib\site-packages\smfexplorer\core\field.py
Docstring:
Logical partition name
SMF Info
--------
Field: `SMF70LPM`
Record: `SMF70S1`
Map: `SMF70BCT`
Logical partition name
Class docstring: `Field` holds information about a SMF field or a virtual field.
フィールド指定でのSMF情報取得
ようやく本丸部分のSMFデータ取得部分です。
取得したいフィールドのリストを指定し(request()関数)、情報取得のリクエストを発行することで(run()関数)、当該SMFデータセットに含まれる情報がPandas DataFrameのオブジェクトとして取得できます。
ctx.request(
[
SMF70S1.timestamp,
SMF70S1.sid,
SMF70S1.lpar_name,
SMF70S1.system_name,
SMF70S1.sysplex_name,
SMF70S1.lpar_system_name,
SMF70S1.lpar_number,
SMF70S1.lpar_cpu_count,
]
).run()
結果例

非常にシンプルにDataFrameとして必要なSMFデータが取得できます!
注意が必要なのは、基本的にサブタイプごとにしか情報はDataFrame化できないということです。
以下の例は、SMF Type70 SubType1 と SubType3のフィールドをまとめて取得要求を出していますが、これはエラーになります。
ctx.request([
SMF70S1.timestamp,
SMF70S1.sid,
SMF72S3.utilization_total
]).run()
結果例(エラー)
---------------------------------------------------------------------------
RGError Traceback (most recent call last)
Cell In[19], line 3
1 from smfexplorer.fields import SMF72S3
----> 3 ctx.request([
4 SMF70S1.timestamp,
5 SMF70S1.sid,
6 SMF72S3.utilization_total
7 ]).run()
File c:\y\VSCode_workspace\SMFExplorer\ISEConf2025_SMFExplroer_Work01\venv311_test01\Lib\site-packages\smfexplorer\core\context.py:270, in Context.request(self, fields)
251 """Start a new `Request`.
252
253 Parameters
(...) 267 >>> ctx.request([COMMON.timestamp, SMF99S1.cp_util, SMF99S1.ziip_util])
268 """
269 _LOG.debug("New FieldRequest with fields: %s", fields)
--> 270 return se_request.FieldRequest(fields, self)
File c:\y\VSCode_workspace\SMFExplorer\ISEConf2025_SMFExplroer_Work01\venv311_test01\Lib\site-packages\smfexplorer\core\request.py:143, in FieldRequest.__init__(self, fields, context, _id, _subid, start_time, end_time, system_name)
139 self.fields: Set[Field] = set()
141 self._graph: reqgraph.RequestGraph = reqgraph.RequestGraph()
--> 143 self.add_fields(fields)
144 self.limit_option = None
145 self.start_time = start_time
File c:\y\VSCode_workspace\SMFExplorer\ISEConf2025_SMFExplroer_Work01\venv311_test01\Lib\site-packages\smfexplorer\core\request.py:207, in FieldRequest.add_fields(self, fields, show_fields)
197 """Add a `list` of fields to a request.
198
199 Parameters
(...) 204 if `False` the fields will be fetched but not shown in result, by default True
205 """
206 for field in fields:
--> 207 self.add_field(field, show_fields)
File c:\y\VSCode_workspace\SMFExplorer\ISEConf2025_SMFExplroer_Work01\venv311_test01\Lib\site-packages\smfexplorer\error.py:119, in wrap_exception.<locals>.decorator.<locals>.wrapper(*args, **kwargs)
116 @functools.wraps(func)
117 def wrapper(*args, **kwargs):
118 try:
--> 119 return func(*args, **kwargs)
120 except SmfExplorerError as ex:
121 logger.debug(msg, exc_info=ex)
File c:\y\VSCode_workspace\SMFExplorer\ISEConf2025_SMFExplroer_Work01\venv311_test01\Lib\site-packages\smfexplorer\core\request.py:192, in FieldRequest.add_field(self, field, show_field)
189 if field in self.fields:
190 return
--> 192 reqgraph.insert_node_into_tree(self._graph, field_node)
194 self.fields.add(field)
File c:\y\VSCode_workspace\SMFExplorer\ISEConf2025_SMFExplroer_Work01\venv311_test01\Lib\site-packages\smfexplorer\core\request_graph.py:235, in insert_node_into_tree(tree, node, prev)
233 if node.node_type == RGNodeType.FIELD and node.field.virtual:
234 for parent in list(node.parents):
--> 235 parent_node = insert_node_into_tree(tree, parent, node)
236 if node.parent == parent:
237 node.parent = parent_node
File c:\y\VSCode_workspace\SMFExplorer\ISEConf2025_SMFExplroer_Work01\venv311_test01\Lib\site-packages\smfexplorer\core\request_graph.py:241, in insert_node_into_tree(tree, node, prev)
239 node.parents[parent_node] = parent_node
240 else:
--> 241 parent_node = insert_node_into_tree(tree, node.parent, node)
242 node.parent = parent_node
243 tree.nodes[node] = node
File c:\y\VSCode_workspace\SMFExplorer\ISEConf2025_SMFExplroer_Work01\venv311_test01\Lib\site-packages\smfexplorer\core\request_graph.py:241, in insert_node_into_tree(tree, node, prev)
239 node.parents[parent_node] = parent_node
240 else:
--> 241 parent_node = insert_node_into_tree(tree, node.parent, node)
242 node.parent = parent_node
243 tree.nodes[node] = node
File c:\y\VSCode_workspace\SMFExplorer\ISEConf2025_SMFExplroer_Work01\venv311_test01\Lib\site-packages\smfexplorer\core\request_graph.py:218, in insert_node_into_tree(tree, node, prev)
216 return tree.root_node
217 else:
--> 218 raise error.RGError(
219 f"Tried to add record {node.record} while record {tree.root_node.record} is already present"
220 )
221 if tree.root_node:
222 tree.root_node.record = node.record
RGError: Tried to add record <Record:72-3> while record <Record:70-1> is already present
事前定義のフィールド・リストのSMF情報取得
先の例のように、取得したいフィールドのリストを明示指定して、そのフィールドの情報を取得することもできますが、いくつかの関連性のあるフィールドのリストを事前定義されたサンプルとして提供してくれているものがあるので、それを使用してSMF情報を取得することも可能です。
例えば、SMF Type72 SubType1に含まれているフィールドで、プロセッサーに関連するフィールドのリストを、"processor_information"として用意してくれています。
このサンプルに含まれるフィールドのリストは以下に記載があります。
Sample - processor_information
ctx.samples.processor_information().run()
結果例

このように一つ一つフィールドを指定しなくても、プロセッサー関連のフィールドの情報を取得することができます。
Tutorial 2 - Filtering and Sorting with Expressions
Tutorial 2はSMF Explorerで提供されているフィルタリングやソートの機能についてのチュートリアルです。
SMFデータはSMFの取得状況や稼働状況によってはデータサイズが膨大になる可能性があります。そのため、実際の操作では分析/可視化の対象をある程度絞って取得することが求められます。
特に、SMF Explorerの仕組みとしてはz/OSMF、および、ネットワークを介してデータをPC上に都度転送することになりますので、大量データを扱うにはホスト側/PC側のメモリやネットワーク帯域などがボトルネックになり得ます。
取得するフィールドを限定するだけでなく、特定の条件に合致した情報を絞り込んで取得することは、効率的な分析をする際には重要となります。
特定のシステムIDでの絞り込み
SMFデータには複数システムの情報が混在している場合がありますが、システムIDを指定して特定のシステムの情報のみ取得することができます。
# fetching data from a specific system
df_filtered = ctx.samples.lpar_information().of_system('MCOC').run()
display(df_filtered)
結果例
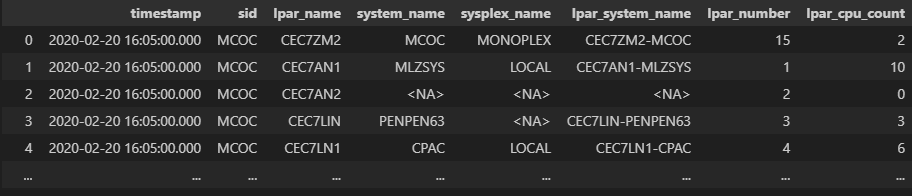
特定のsidの情報のみ取得されます。
特定の期間での絞り込み
日時を指定して特定の期間内の情報のみ取得することができます。
datetime_from = pd.to_datetime('2020-02-20 16:10:00.000')
datetime_to = pd.to_datetime('2020-02-20 16:15:00.000')
df_filtered_time = ctx.samples.lpar_information().in_time(datetime_from, datetime_to).run()
display(df_filtered_time)
結果例

指定した期間内の情報のみ取得されます。
フィールドの値による条件指定
where()関数にて、特定のフィールドの値に条件指定をして、その条件に合致した情報のみ取得することができます。
以下の例ではlpar_cpu_countが1以上のレコードの情報のみ抽出します。
# fetching reduced data
df_filtered = ctx.samples.lpar_information().where(SMF70S1.lpar_cpu_count >= 1).run()
display(df_filtered)
以下の例ではlpar_nameとsystem_nameが一致するレコードの情報のみ抽出します。
# fetching reduced data based on field comparison
df_fields = (
ctx.samples.lpar_information().where(SMF70S1.lpar_name == SMF70S1.system_name).run()
)
display(df_fields)
複数の条件を組み合わせて指定することもできます。以下の例は、lpar_nameがsystem_nameと一致し、かつ、lpar_cpu_countが5より大きいレコードの情報のみ抽出します。
# use AND expression instead of where() chaining
ctx.samples.lpar_information().where(
(SMF70S1.lpar_name == SMF70S1.system_name) & (SMF70S1.lpar_cpu_count > 5)
).run()
条件の組み合わせには以下の論理演算子が利用できます。
AND: &
OR: |
NOT: ~
フィールドの値によるソート
sort()関数にて、特定のフィールドの値について、昇順/降順でソートした結果を取得することができます。
from smfexplorer import ASC, DESC
# sort from the lowest value to the highest value of lpar_cpu_count
# head() function prints first 5 rows of the table
display(ctx.samples.lpar_information().sort(ASC(SMF70S1.lpar_cpu_count)).run().head())
# sort from the highest value to the lowest value of lpar_number
display(ctx.samples.lpar_information().sort(DESC(SMF70S1.lpar_number)).run().head())
# sort records ascendingly by lpar_cpu_count and then descendingly by lpar_number
display(
ctx.samples.lpar_information()
.sort(ASC(SMF70S1.lpar_cpu_count), DESC(SMF70S1.lpar_number))
.run()
.head(5)
)
結果例
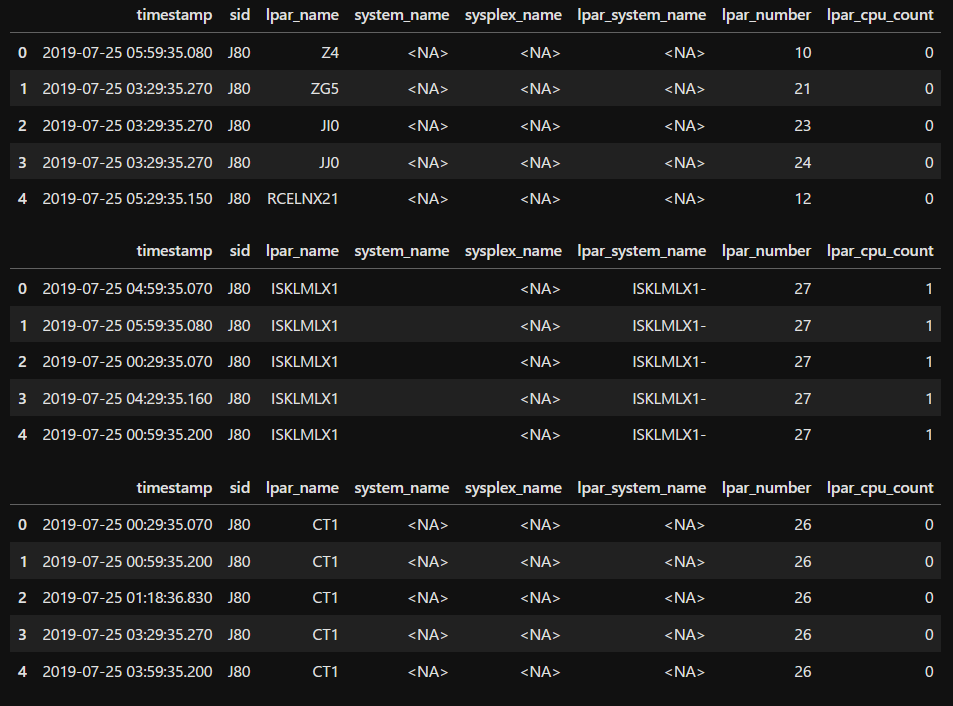
3つ目の例のように、複数フィールドについてソート条件を指定することもできます(lpar_cpu_countを昇順にソートし、lpar_cpu_countが同一の場合lpar_numberで降順ソートする)。
Tutorial 3 - Working with Data
Tutorial 3は取得したSMFデータの加工(主にDataFrameとしての操作)に関するチュートリアルです。Tutorial 3の前半部分はPandas DataFrameそのものの操作例の話なのでここでは割愛します。
列名の取得
SMFデータは、各フィールド情報を列に保持するDataFrameとして取得されます。基本的にはフィールド名が列名になりますが、列名を取得するためのnames()関数が用意されています。
df = ctx.samples.lpar_information().run()
# create a subset of data
lpar_count = df[
names(SMF70S1.timestamp, SMF70S1.lpar_system_name, SMF70S1.lpar_cpu_count)
]
lpar_count
結果例

DataFrameの操作として指定した列名の情報のみ抽出していますが、この時names()関数を使用して列名を指定しています。
以下のコードでも同じ結果が得られますが、このように列名を文字列で与えるのではなく、上の例のようにnames()関数を使用するのが推奨です。
lpar_count_without_names = df[["timestamp", "lpar_system_name", "lpar_cpu_count"]]
lpar_count_without_names
リクエストするフィールド情報の構造を可視化
graph()関数にて、取得しようとしているフィールド情報の構造を可視化することができます。
※この機能を使用するためには、Graphvizというツールを別途インストールしておく必要があります。
例えばSMF70関連のlpar_informationというサンプルで提供されているフィールド・リストの構造を図示してみます。
# If graphviz is available, this will show the structure of the request.
ctx.samples.lpar_information().graph()
結果例
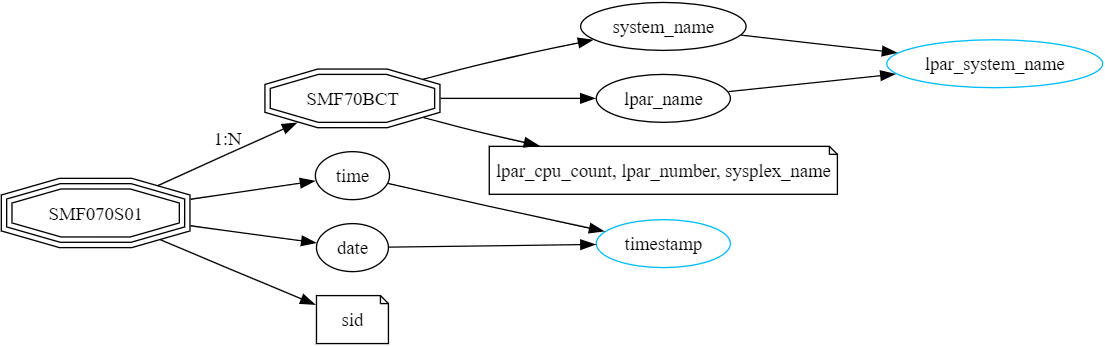
図の補足
- 3重の八角形: SMFレコード
- 2重の八角形:親のレコードに関連するセクション
- 四角形: 子供の要素を持たないフィールドのリスト
-
楕円: 子供の要素を持つフィールド
- 青い楕円: Virtualフィールド
上の例では、SMF70BCTというセクションが含まれ、このセクションは1:Nの関係、すなわち、1レコードに対して複数のデータのまとまりが含まれることになります。これはOuter Left Join(左外部結合)されて1つのDataFrameとして作成されるため、1レコードに対して複数の行を保持することになります(いわゆる縦型のデータ)。
取得しようとしているフィールドの構造として、1:Nの関係をもつセクションが複数含まれている場合、1レコードがNの数だけ掛け算で増えていくことになりますので、DataFrameの行数が膨れ上がる傾向にありますし、取り扱いも複雑になります。できるだけ分析/可視化に必要なフィールドのみを抽出するのが望ましいため、フィールド・リストの構造を理解しておくというのは重要です。graph()関数は取得するフィールド・リストの構造を理解するのに非常に有用です。
このフィールドのリスト(lpar_information)をrun()関数で取得する際にindices=Trueオプションを指定してみます。
# Request LPAR information with all index fields
ctx.samples.lpar_information().run(indices=True)
# This would result in the same table as the above call but explicitly adds the index fields.
# ctx.samples.lpar_information().run(display=[SMF70S1.record.index, SMF70S1.SMF70BCT.index])
結果例

親のレコードとセクション部分のそれぞれのindex列が追加される形でDataFrameが作成されます。1:NのセクションSMF70BCTは、以下の説明書きがあるように、パーティション単位に作成されています。
PR/SM PARTITION DATA SECTION There is one section per configured partition. It is referred to as a partition data entry.
今回使用しているSMFデータでは2つのパーティション情報が含まれているため(1:2)、各レコードごとに2行の情報が保持されたDataFrameとして作成されていることが分かります。
Tutorial 4 - Visualization
Tutorial 4は取得したSMFデータを可視化する例を示しています。このチュートリアルではPlotlyというモジュールを使用してインタラクティブに操作可能なグラフを出力しています。
可視化のためのデータ準備
このチュートリアルでは、SMF Type72 Subtype3で取得できるCPU使用率に関するグラフを出力することを目的にしています。
※このチュートリアルに含まれるコードはかなり無駄があるのと、あまりよろしくないコードになっているので、少し説明しやすいようにカスタマイズして解説します。
まず、CPU使用率に関連するフィールド情報を抽出します。
# data fetching
ctx = smfexplorer.new_context(DATASET)
req2 = ctx.request([
SMF72S3.timestamp,
SMF72S3.sid,
SMF72S3.is_report_class,
SMF72S3.class_name,
SMF72S3.class_period,
SMF72S3.utilization_cp,
SMF72S3.utilization_ziip,
SMF72S3.utilization_zaap,
SMF72S3.utilization_ziip_on_cp,
SMF72S3.utilization_total
])
df2=req2.run()
SMF Type72 Subtyp3の情報はサービス・クラス/レポート・クラスの情報が混在して取得されています。is_report_classの情報を判定することで、当該レコードがサービス・クラスに関するものかレポート・クラスに関するものか判別することができます。is_report_classがTrueの場合レポート・クラス、Falseの場合はサービス・クラスということになります。
ここでは、サービス・クラスに関する情報を抽出したいので、以下のコードでサービス・クラスのみの情報を抽出したDataFrameを作成しています。
df2 = df2[~df2["is_report_class"]]
補足:
-
df2["is_report_class"]: is_report_class列の情報(booleanのリスト)を抽出- 結果イメージ:
[True, True, False, ...]
- 結果イメージ:
-
~df2["is_report_class"]: is_report_class列の情報(booleanのリスト)のTrue/Falseを反転- 結果イメージ:
[False, False, Ture, ...]
- 結果イメージ:
-
df2[~df2["is_report_class"]]: Trueの行のみ抽出、すなわち元々is_report_classがFalseの行(サービス・クラスの行)のみ抽出
ここで一旦立ち戻って、最初にSMFデータから抽出したフィールド・リストの構造を見ておきます。
req2.graph()
結果例

SMF072S03(SMF Type72 SubType3)のレコード自体はサービス・クラス単位にレコードが取得されます。さらにR723SCS(Service/report class period data section)はClass Period単位にセクション情報が取得されます。
参考:
Record type 72 (X'48') — Workload activity, storage data, and serialization delay
Subtype 3: Workload Activity — is written for each service class and active report class in the active service policy. A report class becomes active as soon as work has been assigned to that report class.
Service/report class period data section
There is one section per service or report class period.
図の中の1:Nと表記されている部分が、service class単位に複数の情報を保持するということを意味しています。
この構造をふまえたうえで、取得されたDataFrameの結果を見てみます。分かりやすいように特定のService Class "TSO3"を例にとって見てみます。
df2[df2[names(SMF72S3.class_name)] == "TSO3"]
結果例

timestamp + class_name が同じ行が3つずつ含まれていることが確認できます。各行はclass_periodが異なります。すなわち、1レコードがclass_period単位に分割されて取得されています。class_periodの情報は今回は考慮せずにCPU使用率のみ抽出したいので、timestampとsidでグループ化して各utilizationはclass_periodごとの値の合計値を取ることにします。
参考:
groupby()
sum()
df2 = df2.groupby(["timestamp", "sid"], as_index=False)[['utilization_cp', 'utilization_ziip', 'utilization_ziip_on_cp', 'utilization_total']].sum()
df2
結果例

これで、各システムにおける時系列での各CPU使用率データのベースができあがりましたが、もう少し加工を加えます。
情報を見やすくするために、小数点以下1位までに数値をまるめます。
df2 = df2.round(1)
※DataFrameのround()関数は四捨五入ではなく偶数まるめ(偶数になるように五捨五入)となるようです。
各CPU使用率関連のフィールドについて、合計の数値が0より大きいもの(すなわちCPUの利用が観測されたもの)のみを表示対象のフィールドとして抽出します。
utilization_fields = [
SMF72S3.utilization_cp,
SMF72S3.utilization_ziip,
SMF72S3.utilization_zaap,
SMF72S3.utilization_ziip_on_cp,
SMF72S3.utilization_total,
]
display_fields2 = []
for field in utilization_fields:
if df[names(field)].sum() > 0:
display_fields2.append(field)
可視化
ここまでで、グラフを描くためのデータの準備が整ったので、Plotlyモジュールを使ってグラフを描きます。
from plotly import express as px
plot = px.line(
df, x=names(SMF72S3.timestamp), y=names(display_fields), title="System Utilization"
)
display(plot)
補足:
-
px.line(): 折れ線グラフを描画します。(Line Charts in Python)-
df: 折れ線グラフの元データを含むDataFrame -
x=names(SMF72S3.timestamp): timestamp列をx軸として指定 -
y=names(display_fields): 先に生成したCPU使用率関連の列のリスト(合計値が0以外のもの)をy軸に表示するデータ列として指定 -
title="System Utilization: グラフタイトルを指定
-
結果例:

これで、SMFデータを取得してCPU使用率に関する時系列折れ線グラフを描画する、という流れを確認できました。
あとはグラフ描画の細かいカスタマイズあたりがチュートリアルでは紹介されていますが、そこは純粋に使用しているPythonモジュールの使い方の範疇なのでここでは割愛します。
Tutorial 5 - Interactive Notebooks (Advanced)
Tutorial 5 では、インタラクティブに操作可能なWidgetを利用してデータ分析を行う例を示しています。
SMF Explorerでは smfexplorer.util.jupyter というモジュールを提供しています。これは、IPythonやJupyter Widgets(ipywidgets)等のモジュールをベースに実装されており、これによりインタラクティブに操作可能なWidgetを使ったコーディングがやりやすくなっています
データセットの初期化
import smfexplorer
from smfexplorer.fields import SMF70S1
from smfexplorer import names
from smfexplorer.util import jupyter
# text field with predefined dataset name
# ctx = smfexplorer.new_context('YOUR.SMF.DATA')
ctx = smfexplorer.new_context()
config_widget = jupyter.ConfigWidget(ctx)
display(config_widget)
上のようにsmfexplorer.util.jupyter.ConfigWidgetクラスのインスタンスを作成します。これがインタラクティブに操作可能なWidgetを扱うためのベースとなります。
上のコードを実行すると、操作対象のSMFダンプ・データセットを入力するためのWidgetが表示されます。

データセットを入力すると、そのデータセットの存在確認が自動で行われ、チェックがOKだと、以下のように「Dataset(s) found」というメッセージが出力されます。

その後、Initボタンを押すことでInitializeが行われ、後続で解説するWidgetに結果が動的に反映されて動的に出力内容が更新されることになります。
関数登録例(1): データセット名表示
動的に実行される関数を登録する例です。
@config_widget.register_output()
def give_me_dsn(dsn, **kwds):
print(dsn)
@config_widget.register_output() で、後続のgive_me_dsn()という関数を登録しています。これにより、先のconfig_widgetに指定されたSMFダンプ・データセット名が変更されると、その都度この関数が実行されることになります。
この関数は、サンプルとしてデータセット名(dsn)を出力させるだけの単純なロジックを含むものなので、結果としては、指定したデータセット名がそのまま出力されるだけとなります。

先のWidgetで別のSMFダンプ・データセット名に変更してInitボタンを押すと、この出力も動的に変更されます。
関数登録例(2): SMFデータ取得(データフレーム作成)
SMFデータを取得しデータフレームを作成する関数を登録する例です。
@config_widget.register_output(name="df")
def fetch_df(dsn, **kwds):
df = ctx.samples.lpar_information().run()
return df
@fetch_df.register_output()
def working_with_df(df, **kwds):
display(df.head())
1つめのコードブロックでsamples.lpar_information()で定義されたフィールドを取得してデータフレームを作成する関数を登録しています。register_outputにname=dfを引数として指定することで、ここで取得されるデータ府🄬-無を後続の処理でdfとして扱えるようになります。
2つめのコードブロックでは、@fetch_df.register_outputを使用してworking_with_df()というSMFデータを格納したデータフレームを扱う関数を登録しています。ここではサンプルのためデータフレームの先頭部分をhead()関数で出力するだけの単純な関数定義となっています。
結果としては以下のようになります。

先頭のSMFデータセット名を変更してInitボタンを押せば、この出力もSMFデータセットの内容に応じて動的に変更されることになります。
関数登録例(3): Widgetの利用
上で定義したfetch_dfをさらに拡張して、取得したデータフレームに含まれるデータを元にWidgetを利用する例です。
import ipywidgets as widgets
selection_widget = widgets.ToggleButtons()
@fetch_df.register_output(name="df", name_selected=selection_widget)
def select_name(df, **kwds):
lpar_system_name = df[names(SMF70S1.lpar_system_name)].unique().dropna()
selection_widget.options = lpar_system_name
display(selection_widget)
selection_widget.value = lpar_system_name[0]
return df
@select_name.register_output()
def filter_df(df, name_selected, **kwds):
# The best practice is to guard against calls, where df is None or to check the input for validity in general.
# Returning early from the function will clear the output.
if df is None:
return
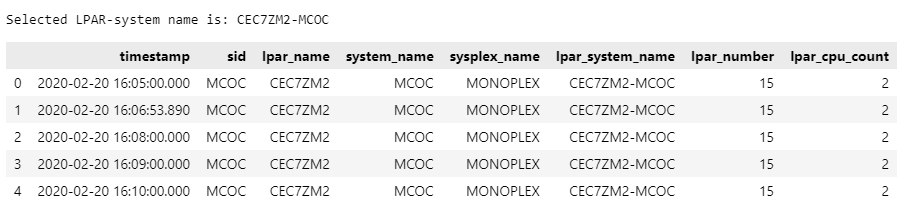
print("Selected LPAR-system name is: " + name_selected)
df = df[df[names(SMF70S1.lpar_system_name)] == name_selected].reset_index(drop=True)
display(df.head())
1つ目のコードブロックでは、fetch_df()で取得されたデータフレームから、SMF70S1.lpar_system_nameフィールドに含まれる値のリストを抽出し、それをJupyter WidgetのToggleButtonsというWidgetで選択できるようにしています。
この関数が実行された結果として、以下のようなToggleButtonが動的に生成されます。

先頭のSMFデータセット名を変更してInitボタンを押せば、このToggleButtonsもSMFデータセットの内容に応じて動的に変更されることになります。
2つ目のコードブロックでは、fetch_df()で取得されたデータフレーム(df)のうち、select_name()のToggleButtonsで選択されたlpar_system_name(name_selected)のみ抽出して、その先頭部分を出力させるためのfilter_df()という関数を登録しています。
例えばToggleButtonsでCEC72M2-MCOCを選択した状態だと以下のような表示結果となります。
ToggleButtonsで別のlpar_system_nameを選択すると、それに応じて動的にこの出力結果も変わることになります。
CEC7AN1-MLZSYSを選択した状態だと以下のような表示結果となります。

このように、Jupyter Widgetと組み合わせることで、インタラクティブにSMFデータを操作しやすくなるため、柔軟な分析/可視化を行うことができます。
参考: Jupyter Widget - Widget List
おわりに
当記事では、SMF Explorerを使用してSMFデータを分析/可視化する際の具体的な操作方法を見てきました。
当然のことながら、まずはどのSMFデータをどういう観点で分析/可視化したいのか、というのをきちんと把握しておく必要があり、そのためには取り扱う対象のSMFデータがどういう意味を持つのかを理解しておくことが必要です。
その先の、SMFデータを分析/可視化するための具体的な操作については、z/OS固有の技術やツール(例えばJCLやICETOOLなど...)ではなく、Python, DataFrame, Plotlyといった広く一般的に利用されている技術やライブラリを活用することができる、というのが重要なポイントです。