はじめに
ここでは実際にSMF Explorerを使ってみて分かったことやTipsなどを記載しておきます。
関連記事
SMF Explorerによるパフォーマンス情報可視化 - (1) 概要
SMF Explorerによるパフォーマンス情報可視化 - (2) 環境セットアップ
SMF Explorerによるパフォーマンス情報可視化 - (3) SMF Explorer使用方法
SMF Explorerによるパフォーマンス情報可視化 - (4) Tipsなど
Tips
大量データのハンドリング
SMFデータはSMFの取得状況や稼働状況によってはデータサイズが非常に膨大になる場合があります。SMF Explorer経由で取得する対象のデータが大きくなる場合、z/OSMFで使用されるメモリ、ネットワーク帯域、Pythonで使用されるメモリなどがボトルネックになる可能性があります。
参考までに、ある環境でz/OSMFのメモリ制約でエラーになったケースの挙動を記載しておきます。
ケース・プロファイル
対象SMFダンプ・データセット:
- サイズ: 54958trk (≒ 31GB)
- 内容: Type99のみ 7日分
※サブタイプごとのレコード数

SMF Explorerで取得するフィールドのセット: smf_99_02_sample
- 例:
ctx.samples.smf_99_02_sample().run()
エラー状況
Pythonスクリプトで ctx.samples.smf_99_02_sample().run() によりSMFデータを取得しようとすると、以下のエラーが発生しました。
ConnectorError: Failed to fetch data for dataset 'DEV01.TYPE99.D240401.D240407' with status code 400 and message: 'Not enough RAM resources to extract '502994' records requested.
Use a filter to request fewer SMF records or increase the amount of resources the application may use'
z/OSMFのmessages.logには以下のエラーが出力されました。
[4/30/25, 11:28:31:837 GMT] 0000005c SystemOut O 2025-04-30 11:28:31.837/GMT | smf | [ERROR] | [LargeThreadPool-thread-46] smf-bridge-service - 'Not enough RAM resources to extract '502994' records requested. Required RAM: '1401434088', available for low-level call: '168684236''
[4/30/25, 11:28:31:846 GMT] 0000005c SystemOut O 2025-04-30 11:28:31.845/GMT | smf | [ERROR] | [LargeThreadPool-thread-46] exception-handler - 'uri=/zosmf/zosdg/smf/v1/smf/type/99/subtype/2: Not enough RAM resources to extract '502994' records requested. Use a filter to request fewer SMF records or increase the amount of resources the application may use'
z/OSMFのリソースが足りないのが原因でエラーになったようです。z/OSMFの実体はLiberty(Java)ですので、JVMのヒープサイズを見直す必要があります。
z/OSMF設定確認
z/OSMFはデフォルトの構成となっており、JVMヒープの最大値を確認すると1GBになっていました。
(/var/zosmf/configuration/servers/zosmfServer/jvm.optionsに-Xmx1024Mが指定されている)
また、z/OSMF起動プロシージャーを確認すると、MEMLIMITが4GBに指定されていました。
(IZUMEM変数で指定)
//IZUSVR2 PROC PARMS='zosmfServer', /* Server parms */
// ROOT='/usr/lpp/zosmf', /* z/OSMF installation root */
// WLPDIR='/usr/lpp/zosmf/liberty', /* Liberty directory */
// OUTCLS='*', /* SYSOUT class */
// USERDIR='/var/zosmf', /* Configuration directory */
// TRACE='N', /* Trace option */
// KCINDEX='Y', /* KC index rebuild flag */
// IZUPRM='02', /* Parmlib suffixes or PREV */
// SERVER='STANDALONE', /* AUTOSTART server */
// Z='0', /* Reserved for IBM */
// IZUMEM=4G /* Server memlimit */
//*
...
//ZOSMF EXEC PGM=BPXBATSL,REGION=0M,COND=(0,LT),
// MEMLIMIT=&IZUMEM.,TIME=NOLIMIT,
// PARM='PGM &WLPDIR./lib/native/zos/s390x/bbgzsrv --clean &PARMS'
//*
//WLPUDIR DD PATH='&USERDIR./configuration'
//*
//STDOUT DD SYSOUT=&OUTCLS
//STDERR DD SYSOUT=&OUTCLS
//*STDOUT DD PATH='&ROOT/izusvr1.stdout',
//* PATHOPTS=(OWRONLY,OCREAT,OTRUNC),
//* PATHMODE=SIRWXU
//*STDERR DD PATH='&ROOT/izusvr1.stderr',
//* PATHOPTS=(OWRONLY,OCREAT,OTRUNC),
//* PATHMODE=SIRWXU
z/OSMF設定変更
JVMヒープの最大値を増やす際は、合わせてMEMLIMITも変更する必要があります。
まず、z/OSMF起動プロシージャーにてMEMLIMITの値を4G→10Gに変更します。
(起動プロシージャーで、IZUMEM=10G に変更)
次にJVMオプションでヒープサイズの上限を指定しますが、/var/zosmf/configuration/servers/zosmfServer/jvm.optionsファイルは動的に作成されるファイルで、これを直接書き換えることはできません(起動時に上書きされてしまいます)。
JVMオプションを変更するには、上書き用の設定を別途実施する必要があります。
参考: Add or Modify JVM options in z/OSMF Liberty Server
/var/zosmf/configuration/local_override.cfgファイルを新規に作成し、以下の内容を記載します。ここで、JVMオプションを指定するファイルとしてcustom_jvm.optionsを使用することを宣言しています。
JVM_OPTIONS='-Xoptionsfile='/var/zosmf/configuration/custom_jvm.options''
上で指定した/var/zosmf/configuration/custom_jvm.optionsファイルを新規に作成し、以下の内容を記載します。
-verbose:gc
-Xverbosegclog:/var/zosmf/data/logs/zosmfServer/logs/gc.%Y%m%d.%H%M%S.txt
-Xmx8192M
ここで、JVMオプションとしてヒープサイズの上限を8GBに設定しています(-Xmx8192M)。確認用にGCログの出力をさせるためのオプションも追加しています。
これでz/OSMFを再起動すると、z/OSMFで使用できるヒープサイズが増加します。
再実行結果
z/OSMFのヒープを増やしてからPythonスクリプトからSMF Explorer経由で情報取得すると、先のエラーは回避されました。しかし、大量データの取得ということもあって、かなり時間を要しました。
- TypごとのSMFレコード件数確認
-
ctx.get_available_records()=> 約7分
-
- smf_99_02_sampleのSMF情報取得
-
ctx.samples.smf_99_02_sample().run()=> 約40分
-
2つめのリクエストで取得されたDataFrameは 626,572rows x 34cols です。
その他取得されたDataFrameの情報は以下の通りです(df.info()結果)。
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 626572 entries, 0 to 626571
Data columns (total 34 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 timestamp 626572 non-null datetime64[ns]
1 sid 626572 non-null string
2 srv_class_name 626572 non-null string
3 period_num 626572 non-null UInt8
4 period_imp 626572 non-null UInt8
5 goal_type_name 626572 non-null object
6 goal_value 626572 non-null UInt16
7 pi_local 626572 non-null Float64
8 disp_prio 626572 non-null UInt16
9 srv_cp_service 626572 non-null UInt32
10 srv_ziip_service 626572 non-null UInt32
11 srv_zaap_service 626572 non-null UInt8
12 samp_io_using 626572 non-null UInt8
13 samp_io_delay 626572 non-null UInt8
14 samp_io_disconnected 626572 non-null UInt8
15 samp_io_unit_queue 626572 non-null UInt8
16 mpl_in 626572 non-null UInt16
17 mpl_out 626572 non-null UInt16
18 mpl_av 626572 non-null UInt16
19 ready_user_av 626572 non-null UInt16
20 idle 626572 non-null UInt16
21 mpl_delay 626572 non-null UInt8
22 cross_mem_delay 626572 non-null UInt8
23 io_using 626572 non-null UInt8
24 io_delay 626572 non-null UInt8
25 cpu_using 626572 non-null UInt16
26 cpu_delay 626572 non-null UInt8
27 buffer_pool_delay 626572 non-null UInt8
28 ziip_using 626572 non-null UInt16
29 ziip_delay 626572 non-null UInt16
30 zaap_using 626572 non-null UInt8
31 zaap_delay 626572 non-null UInt8
32 cap_delay 626572 non-null UInt8
33 history_rows 626572 non-null UInt8
dtypes: Float64(1), UInt16(10), UInt32(2), UInt8(17), datetime64[ns](1), object(1), string(2)
memory usage: 68.7+ MB
今回のテスト環境はIBM Cloud上のWazi aaSというz/OSのエミュレーターを使用していますし、インターネットを経由しての情報取得になるので、パフォーマンスの目安にはなりにくいと思いますが、参考までにz/OS側のスペック情報も記載しておきます。
D M=CPU
IEE174I 12.11.27 DISPLAY M 631
PROCESSOR STATUS
ID CPU SERIAL
00 + 01A0CD8562
CPC ND = 008562.A00.IBM.C1.E34316E7A0CD
CPC SI = 8562.A00.IBM.C1.11F2E34316E7A0CD
CPC ID = 00
CPC NAME = CPC_UNKNOWN_NAME
+ ONLINE - OFFLINE . DOES NOT EXIST W WLM-MANAGED
N NOT AVAILABLE
CPC ND CENTRAL PROCESSING COMPLEX NODE DESCRIPTOR
CPC SI SYSTEM INFORMATION FROM STSI INSTRUCTION
CPC ID CENTRAL PROCESSING COMPLEX IDENTIFIER
CPC NAME CENTRAL PROCESSING COMPLEX NAME
D M=STOR
IEE174I 12.12.06 DISPLAY M 633
REAL STORAGE STATUS
ONLINE-NOT RECONFIGURABLE
0M-13710M
ONLINE-RECONFIGURABLE
NONE
ONLINE-DEDICATED MEMORY
NONE
PENDING OFFLINE
NONE
STORAGE INCREMENT SIZE IS 1M
複数SMFダンプ・データセットの取り扱い
先の例のように、SMFダンプ・データセットはサイズが大きくなりがちで、大量データを一度に扱うとパフォーマンスの問題が生じやすくなるので、SMF Explorerで扱う際はなるべく分析したい情報を細切れにして管理するのが望ましいです。
一方で、複数のSMFダンプ・データセットをまとめて扱いたい場合もあると思います。その場合は、以下のようにcontext作成時に複数データセットをリスト形式で与えることで複数データセットをまとめて扱うことができます。
DATASET = "DEV01.ZMCOC.D200220.WL1.SMF"
DATASET2 = "DEV01.SMFDUMP.TAG.D250309.V01"
ctx = smfexplorer.new_context([DATASET, DATASET2]
1:Nセクションのデータの持ち方
SMF Explorerを使用してSMFデータを扱う際には、1:Nのセクションを含む場合その構造を意識しておかないと誤った解釈や分析につながってしまうので注意が必要です。
ここでは、できるだけシンプルな例を用いて1:Nセクションが複数含まれる場合に生成されるDataFrameの結果について、Type70 Subtype1のデータの例を使用して詳しく見ていきたいと思います。
Case1 - 1:1セクションのみの場合(CPU Control Section)
1:1のセクション "CPU Control Section"を含む場合の例を見てみます。
SMF70CTL
CPU control section
There is one section per record.
req_test1 = ctx.request(
[
SMF70S1.timestamp,
SMF70S1.mod,
SMF70S1.ver
]
)
req_test1.graph()

この構造のフィールド・リストを取得し、特定のタイムスタンプのデータのみ抽出してみます。
df_Test1 = req_test1.run(indices=True)
df_Test1.query("timestamp == '2020-02-20 16:05:00'")
結果

1:1のセクションしか含まないので、特定タイムスタンプのデータは1行のみとなります。
まぁこれは直感的にも分かりやすい。あたりまえ。
Case2 - 1:Nのセクションを含む場合(CPU data section)
上の"CPU Contorl Section"に加えて、1:Nのセクションである"CPU Data Section"を含む場合の例を見てみます。
SMF70CPU
CPU data section
This section contains general information on CPU use during the interval. All measurements are provided on a per logical processor basis.
req_test2 = ctx.request(
[
SMF70S1.timestamp,
SMF70S1.mod,
SMF70S1.ver,
SMF70S1.cpu_id,
SMF70S1.cpu_wait_time,
]
)
req_test2.graph()

この構造のフィールド・リストを取得し、特定のタイムスタンプのデータのみ抽出してみます。
df_Test2 = req_test2.run(indices=True)
df_Test2.query("timestamp == '2020-02-20 16:05:00'")
結果

今回追加したCPU data sectionに含まれるフィールドは、logical processorごとに情報が取得されるようです。今回使用しているサンプルSMFデータでは2つのCPUがあるため、1時点で2つの情報(cpu_id:0, 1)が含まれます。従って、取得されたDataFrameとしては、特定のタイムスタンプのデータは2行となります。
ここで着目すべきなのは、1:1セクション(CPU control section)に含まれるフィールド(mod, ver)の値です。これらはCPU data section(cpu_id)に依存しない情報なので、同じ値が複数行にコピーされる形で保持されています。
※この特性を理解していないと、データフレームの値を加工する時に誤った操作や解釈をしてしまうことにつながります。
Case3 - 別の1:Nのセクションを含む場合(PR/SM partition data section)
別の1:Nのセクションである"PR/SM partition data section"を含む場合の例を見てみます。
SMF70BCT
PR/SM partition data section
This section contains a configured logical partition. There is one for each logical partition.
req_test3 = ctx.request(
[
SMF70S1.timestamp,
SMF70S1.mod,
SMF70S1.ver,
SMF70S1.lpar_name,
SMF70S1.lpar_number,
SMF70S1.lpar_cpu_count
]
)
req_test3.graph()

この構造のフィールド・リストを取得し、特定のタイムスタンプのデータのみ抽出してみます。
df_Test3 = req_test3.run(indices=True)
df_Test3.query("timestamp == '2020-02-20 16:05:00'")
結果

今回追加したPR/SM partition data sectionに含まれるフィールドは、LPARごとに情報が取得されるようです。今回使用しているサンプルSMFデータでは46のLPARがあるため、1時点で46つの情報(lpar_number:0~45)が含まれます。従って、取得されたDataFrameとしては、特定のタイムスタンプのデータは46行となります。
Case4 - 1:Nのセクションを2つ含む場合(CPU data section + PR/SM partition data section)
上で確認した、2つの1:Nセクション "CPU data section"、"PR/SM partition data section"を両方とも含む場合の例を見てみます。
req_test4 = ctx.request(
[
SMF70S1.timestamp,
SMF70S1.mod,
SMF70S1.ver,
SMF70S1.cpu_id,
SMF70S1.cpu_wait_time,
SMF70S1.lpar_name,
SMF70S1.lpar_number,
SMF70S1.lpar_cpu_count
]
)
req_test4.graph()

この構造のフィールド・リストを取得し、特定のタイムスタンプのデータのみ抽出してみます。
df_Test4 = req_test4.run(indices=True)
df_Test4.query("timestamp == '2020-02-20 16:05:00'")
結果

論理CPUごとのセクション(1:2)と、LPARごとのセクション(1:46)のセクションが含まれるので、1時点での情報としては、2x46=92 つまり、DataFrameとしては特定のタイムスタンプごとに92行のデータが含まれるということになります。
例えばcpu_wait_timeに着目してみると、このフィールドは"CPU data section"に含まれるものなのでcpu_idごとに取得される情報です。しかし、今回のDataFrameには"PR/SM partition data section"のフィールドも含まれているので、LPAR単位の情報も含まれるため46LPAR分の行が追加されています。cpu_wait_timeは各LPARごとの列に同じ値がコピーされて保持されることになります。
つまり、同一時刻のcpu_wait_timeの合計を出そうと思った場合に、単純に同一タイムスタンプのcpu_wait_timeの値を合計してしまうと意図しない結果になってしまうことは容易に想像がつきます。cpu_wait_timeの値をタイムスタンプごとに集計したいのであれば、Case2のように1:Nのセクションが1つのみの状態でDataFrameを作成した状態でタイムスタンプごとの合計を取得するのがよいでしょう。
まとめ
取得されたDataFrameのどのフィールドがどのセクションに含まれていて、さらに別の1:Nセクションが含まれているかどうかを意識しておかないと、DataFrameを操作する時に意図しない結果になってしまう可能性がありますので、取得したDataFrameの構造には十分注意が必要です。
1:Nセクションを複数含む場合は、取得する行数が膨大になりがちですし、構造が複雑で操作が煩雑になりやすくなります。従って、SMFデータを取得する時点ではできるだけフィールド数を絞る(1:Nセクションはできるだけ少ない状態にする)ことが望ましいと言えます。つまり、できるだけ細切れにデータを取得するようにして、必要であればPython上で複数のDataFrameをマージするなりして加工する方が間違いが少ないと思います。
上の例のようにGraphvizの機能を使ってグラフ表示することで、取得しようとしているフィールドの構造を可視化できるので、1:Nセクションが含まれているかどうかはこれで確認することを強くおすすめします。
縦型/横型変換
DataFrameでSMFデータを扱えるということは、すなわち、表/テーブル/2次元配列 の形でデータを扱えるということになります。Excel上の表のイメージでとらえると分かりやすいと思います。
各行にはSMFレコードが取得された時刻の情報が保持され、各列にはフィールドの情報が保持されるというイメージです。
一方で、SMFレコードというのは先に示した通り、複数の可変長のセクションが含まれる可能性があり、その場合フィールド(列)の情報がレコードによって一定ではないので、そのまま表の形に保持するのは無理があります。
そこで、1レコード中に複数の塊のセクション情報が含まれる場合、それを縦型(縦持ち/Long型)のテーブルとして保持することになります。すなわちSMF1レコードの情報をDataFrame上は複数行で保持するイメージになります。
縦型/横型のデータの持ち方については以下の記事が分かりやすいと思います。
参考: 【pandas】melt, pivot:縦横変換【データフレーム処理】
例えば、以下のようなコードで、SMF72 Subtype3のCPU使用率に関するフィールドを抽出したとします。
# set request field list
req_SMF72S3_cpuBase = ctx.request(
[
SMF72S3.timestamp,
SMF72S3.class_name,
SMF72S3.is_report_class,
SMF72S3.class_period,
SMF72S3.utilization_cp,
SMF72S3.utilization_ziip,
SMF72S3.utilization_ziip_on_cp,
SMF72S3.utilization_total
]
)
# get SMF data
df_SMF72S3_cpuBase = req_SMF72S3_cpuBase.run()
# extract service class
df_SMF72S3_cpuBase = df_SMF72S3_cpuBase[~df_SMF72S3_cpuBase["is_report_class"]]
# aggregate
df_SMF72S3_cpuBase_aggregate = df_SMF72S3_cpuBase.groupby(["timestamp", "class_name"], as_index=False)[['utilization_cp', 'utilization_ziip', 'utilization_ziip_on_cp', 'utilization_total']].sum()
ここで取得されるDataFrameは以下のような結果となります。
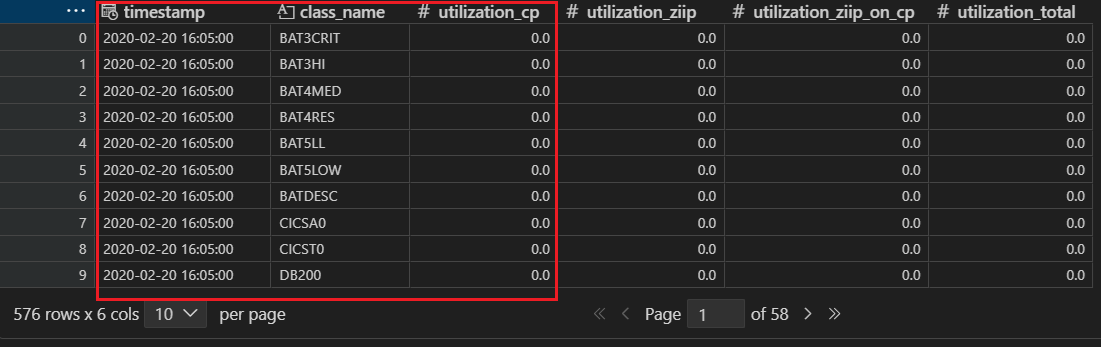
ここで、utilization_cp(GCPの使用率)のフィールドに着目し、この値について、各行にタイムスタンプ、各列にサービス・クラスを取るように表の持ち方をかえてみます。つまり、上の赤枠の部分(縦型)を、横型の持ち方に変えてみます。
df_SMF73S3_utilization_cp = df_SMF72S3_cpuBase_aggregate.pivot(
index="timestamp",
columns="class_name",
values="utilization_cp"
).reset_index()
結果

シンプルなサービス・クラスごとの時系列の表になりました。
データを分析/可視化する過程で、縦型→横型への変換(あるいはその逆)を行いたい場合があります。これはSMF Explorerの操作に限った話ではなく一般的なデータ分析の話でも同様だと思いますが、この考え方を知っておくことは柔軟にSMFデータの分析、可視化を行う上で色々と応用が利くと思います。
ID/コードのマッピング
SMFデータのフィールドには、名称やIDのような情報を保持するフィールドがあります。これらのフィールドの中には、値そのものだけでは意味が分かりにくいものが含まれている場合があります。
例えば、LPAR名やシステム名、サブシステム名、サービス・クラス名など、ある程度はネーミングルールに従って命名されているとは思いますが、このようなネーミングはたくさんありますし、限られた文字数の中でのネーミングなので分かりにくいものも含まれると思います。
例えば、LPARP01, LPARP02, LPART01, LPART02,... というようなネーミングのLPARがあったとして、表記としては、本番用LPAR(1系)、本番用LPAR(2系)、テスト用LPAR(1系)、テスト用LPAR(2系)、といったような書き方の方が万人に分かりやすく、認識ミスも少ないと思います。
そのような、ID/コードの類の情報と、分かりやすい名称のマッピングを行うことは分析レポートを作成する場合などは特に有用だと思います。
その他にも、例えばSMF99 Subtype1のTrace Table Entry Sectionに、SMF99_TCODというトレース・コードが保持されるフィールドがあります。これは、コードに対して具体的なDescriptionが割り当てられていますが、コードだけだとその意味が分かりません。
SMF type 99 action codes
上の表にある情報と、SMF99_TCODのコードの情報をマッピングするコード例を以下に示します。
まず、事前に上のAction Codeとsymbol, descriptionの表をCSVファイルとして用意しておきます。
action_code,symbol,description
1,STA_RECOVERY_RETRY,Retry.
2,STA_RECOVERY_PERC,Percolation.
3,STA_RECOVERY_REDRIVE_SET,Tell WLM to set to same policy again.
10,RA_AUXP_DEC_MPL,"Resource adjustment, too much auxiliary storage paging, decrease mpl."
20,RA_AUXP_NO_ACTION,"Resource adjustment, too much auxiliary storage paging, no action."
30,RA_MP_NO_ACTION,"Resource adjustment, managed paging, no action."
40,RA_OU_DEC_MPL,"Resource adjustment, overutilized, decrease mpl."
...
上のCSVファイルを読み込んでマッピングする例
from smfexplorer.fields import SMF99S1
# set request field list
req_traceTable = ctx.request(
[
SMF99S1.timestamp,
SMF99S1.sid,
SMF99S1.tcnm,
SMF99S1.tper,
SMF99S1.tjob,
SMF99S1.trace # action code
]
)
# get SMF data
target_system_name = "VS01"
df_traceTable = req_traceTable.of_system(target_system_name).run()
# read CSV file
file_action_code_list = '.\SMF99_action_code_list.csv'
df_action_code_list = pd.read_csv(file_action_code_list)
# mapping action
df_traceTable = pd.merge(df_traceTable, df_action_code_list, left_on='trace', right_on='action_code', how='left').drop(columns='action_code')
結果

traceフィールド(action code)の値に対応するsymbol, descriptionのフィールドが追加されました。
汎用Pythonパッケージ
SMF Explorer固有の話ではありませんが、個人的に使って便利だと思った汎用Pythonパッケージを挙げておきます。
- Data Wrangler: Jupyter Notebook上でSMFデータを扱う際、途中経過や一時的なデータフレームの中身を分かりやすく表示してくれる
- plotly: インタラクティブに操作可能なグラフを描画可能
- itables: インタラクティブに操作可能な表を表示
-
Quarto: Markdown + Pythonコードで動的にレポート生成(特にHTML形式のドキュメント生成)
- memo: Quarot dashboard + Plorlyのバグ? - https://github.com/plotly/plotly.py/issues/4578