はじめに
- この記事はひとりNEONアドベントカレンダー2020 19日目の記事です
- 昨日は固定小数点演算用命令を紹介した
- 今日は
mov命令を紹介する
$ grep -e ^vmovn -e vmovun -e ^vmovl -e ^vqmov /usr/lib/gcc/aarch64-linux-gnu/7.5.0/include/arm_neon.h
vmovl_high_s8 (int8x16_t a)
vmovl_high_s16 (int16x8_t a)
vmovl_high_s32 (int32x4_t a)
vmovl_high_u8 (uint8x16_t a)
vmovl_high_u16 (uint16x8_t a)
vmovl_high_u32 (uint32x4_t a)
vmovl_s8 (int8x8_t a)
vmovl_s16 (int16x4_t a)
vmovl_s32 (int32x2_t a)
vmovl_u8 (uint8x8_t a)
vmovl_u16 (uint16x4_t a)
vmovl_u32 (uint32x2_t a)
vmovn_high_s16 (int8x8_t a, int16x8_t b)
vmovn_high_s32 (int16x4_t a, int32x4_t b)
vmovn_high_s64 (int32x2_t a, int64x2_t b)
vmovn_high_u16 (uint8x8_t a, uint16x8_t b)
vmovn_high_u32 (uint16x4_t a, uint32x4_t b)
vmovn_high_u64 (uint32x2_t a, uint64x2_t b)
vmovn_s16 (int16x8_t a)
vmovn_s32 (int32x4_t a)
vmovn_s64 (int64x2_t a)
vmovn_u16 (uint16x8_t a)
vmovn_u32 (uint32x4_t a)
vmovn_u64 (uint64x2_t a)
vqmovn_high_s16 (int8x8_t a, int16x8_t b)
vqmovn_high_s32 (int16x4_t a, int32x4_t b)
vqmovn_high_s64 (int32x2_t a, int64x2_t b)
vqmovn_high_u16 (uint8x8_t a, uint16x8_t b)
vqmovn_high_u32 (uint16x4_t a, uint32x4_t b)
vqmovn_high_u64 (uint32x2_t a, uint64x2_t b)
vqmovun_high_s16 (uint8x8_t a, int16x8_t b)
vqmovun_high_s32 (uint16x4_t a, int32x4_t b)
vqmovun_high_s64 (uint32x2_t a, int64x2_t b)
vqmovn_s16 (int16x8_t __a)
vqmovn_s32 (int32x4_t __a)
vqmovn_s64 (int64x2_t __a)
vqmovn_u16 (uint16x8_t __a)
vqmovn_u32 (uint32x4_t __a)
vqmovn_u64 (uint64x2_t __a)
vqmovnh_s16 (int16_t __a)
vqmovns_s32 (int32_t __a)
vqmovnd_s64 (int64_t __a)
vqmovnh_u16 (uint16_t __a)
vqmovns_u32 (uint32_t __a)
vqmovnd_u64 (uint64_t __a)
vqmovun_s16 (int16x8_t __a)
vqmovun_s32 (int32x4_t __a)
vqmovun_s64 (int64x2_t __a)
vqmovunh_s16 (int16_t __a)
vqmovuns_s32 (int32_t __a)
vqmovund_s64 (int64_t __a)
- 全般的に言えることなのだが、
mov命令はx86系のmov命令とは全然ちがう -
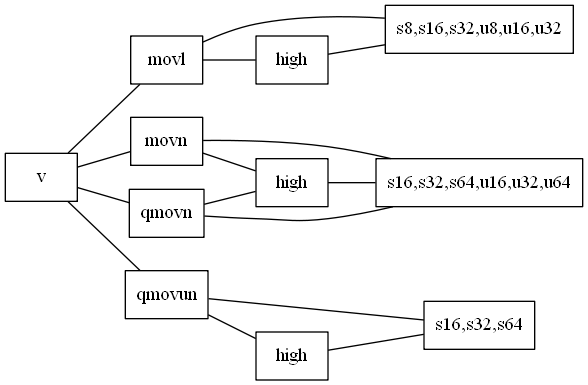
movnとmovl及びqmovnとqmovunがある - また、浮動小数点型用の命令は存在しない。全部整数型のみ
movn命令
- ベクトルの各レーンのbit幅を、半分の幅に縮める
- 要素の型で言うと、
int32_tをint16_tに、int16_tをint8_tにする
int16_t src[] = {130,256,257,103,-132,-126,-125,-124,};
int16x8_t vsrc = vld1q_s16(src);
int8x8_t vdst0 = vmovn_s16(vsrc);
- 演算結果
0:-126
1:0
2:1
3:103
4:124
5:-126
6:-125
7:-124
- レーン数はそのまま、要素のbit幅だけ縮めるので、結果的に引数が単体の128bit幅ベクトル、戻り値が64bit幅ベクトルとなる
- bit幅を縮めてオーバーフローする場合は、
add命令のように単純に出力幅分のbitだけ、LSBからマスキングして出力される- 例1:先程のベクトルの要素0番は
130、16進数表記で0x0082である。符号あり8bitの正の最大値127を超えているが、結果は下位8bit0x82を符号あり8bit整数型として扱って、-126となっている - 例2:先程のベクトルの要素1番は
256、16進数表記で0x0100である。符号あり8bitの正の最大値127を超えているが、結果は下位8bit0x00を符号あり8bit整数型として扱って、0となっている - 例3:先程のベクトルの要素4番は
-132、16進数表記で0xff7cである。符号あり8bitの負の最大値-128を超えているが、結果は下位8bit0x7cを符号あり8bit整数型として扱って、-124となっている
- 例1:先程のベクトルの要素0番は
qmovn命令
-
add命令のときと同じく、命令の先頭にqが付くと飽和演算になる - 先程の
movn命令は単純に下位nbitを抽出して狭い型の整数型として解釈していたが、qmovnは入力値が結果のbit幅で結果がオーバーフローする際、最大値もしくは最小値でクランプする
qmovn.cpp
int16_t src[] = {130,256,257,103,-132,-126,-125,-124,};
int16x8_t vsrc = vld1q_s16(src);
int8x8_t vdst1 = vqmovn_s16(vsrc);
- 演算結果
0:127
1:127
2:127
3:103
4:-128
5:-126
6:-125
7:-124
- 要素の
0番、1番、2番はそれぞれ127に、4番は-128にクランプされている
movn_high命令、qmovn_high命令
- おなじみ、後ろに
highが付く派生形 - 引数を2つ取り、第1引数は64bit幅ベクトル、第2引数が128bit幅ベクトル
- 第2引数を狭めて64bit幅ベクトルを生成し、第1引数と連結して128bit幅ベクトルを返す
- 縮める演算は
highがついてない基本形と全く同じ
movl命令
- 狭める命令があれば、広げる命令もある。それが
movl命令 - 引数が64bit幅ベクトルで出力が128bit幅ベクトル
- 符号あり整数型を引数に取る場合は、負数のbit拡張をちゃんとやってくれる
- 8bitの
-1(0xff)を16bitの-1(0xffff)にしてくれる
- 8bitの
- 符号のありなしは引数と戻り値で共通
movl_high命令
- 128bit幅ベクトルを取り、128bit幅ベクトルを返す
- ただし、演算に使われるのは、入力ベクトルの後半、上位64bit分だけ
qmovun命令
-
qmovn命令に近いが、符号あり整数型を、符号なし整数型に縮める-
int64x2_t型をuint32x2_t型に、int32x4_tをuint16x4_t型に、int16x8_t型をuint8x8_t型に変換する
-
- 引数は128bit幅ベクトル、戻り値は64bit幅ベクトル
qmovun.cpp
int16_t src[] = {130,256,257,103,-132,-126,-125,-124,};
int16x8_t vsrc = vld1q_s16(src);
int8x8_t vdst2 = vqmovun_s16(vsrc);
- 演算結果
0:130
1:255
2:255
3:103
4:0
5:0
6:0
7:0
- 負数は全て
0に、256以上の数字は255に丸められている - なお、やはり
highが末尾につく派生形もある
早見表
| 拡張/収縮 | 飽和演算 | 符号無し飽和演算 | 命令 |
|---|---|---|---|
| 拡張 | - | - | movl |
| 収縮 | N |
- | movn |
| 収縮 | Y |
N |
qmovn |
| 収縮 | Y |
Y |
qmovun |
その他
- 図では省略したが、単体用の命令もある
- 単体の要素を取る
mov_n、mov_n_high命令は、調べた限りではdup_n、dup_n_high命令のエイリアス
おわりに
- 整数型のbit幅を変換する命令
movn、movlとその仲間たちを紹介した。 - 明日も手島の担当で、Arm v8.2の内積命令を紹介する予定