はじめに
- この記事はひとりNEONアドベントカレンダー2020 3日目の記事です
- 昨日はサンプルコードでお試し、な感じだったが、今日から命令を選んで紹介していく
- 今日は基本中の基本、加算命令の一部を紹介する。
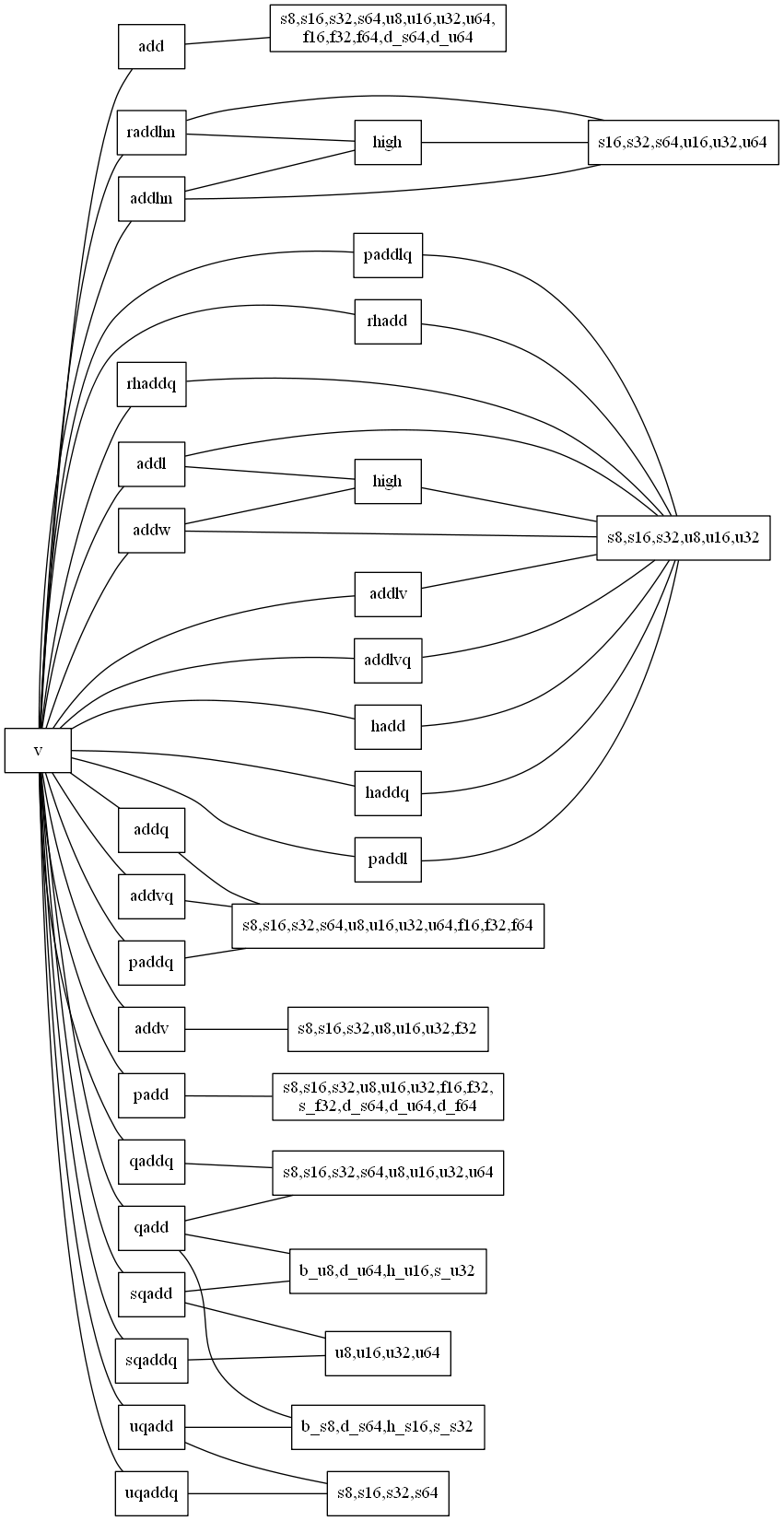
-
いきなりバカでかい図を出したが、全部列挙するとアホみたいに
add命令とその仲間たちがたくさんあるので、suffixである程度グルーピングした。 -
次のような図は、

-
以下のような命令をまとめた表記とした。
vaddq_s8
vaddq_s16
vaddq_s32
vaddq_s64
vaddq_u8
vaddq_u16
vaddq_u32
vaddq_u64
vaddq_f16
vaddq_f32
vaddq_f64
- 以下のように、
add命令は種類がたくさんある
$ grep ^v.*add /usr/lib/gcc/aarch64-linux-gnu/7.5.0/include/arm_neon.h | cut -f 1 -d _ | sort | uniq -c
11 vadd
2 vaddd
12 vaddhn
12 vaddl
6 vaddlv
6 vaddlvq
11 vaddq
7 vaddv
10 vaddvq
12 vaddw
6 vhadd
6 vhaddq
8 vpadd
3 vpaddd
6 vpaddl
6 vpaddlq
11 vpaddq
1 vpadds
8 vqadd
2 vqaddb
2 vqaddd
2 vqaddh
8 vqaddq
2 vqadds
12 vraddhn
6 vrhadd
6 vrhaddq
4 vsqadd
1 vsqaddb
1 vsqaddd
1 vsqaddh
4 vsqaddq
1 vsqadds
4 vuqadd
1 vuqaddb
1 vuqaddd
1 vuqaddh
4 vuqaddq
1 vuqadds
- 今日はこの中から、
vadd、vqadd、vaddl、vaddwを紹介する
vadd
- 2日目で触れたが、
vadd命令とvaddq命令は64bit/128bitの幅の違いだけである。 -
vadd命令は整数型、浮動小数点型どれでも加算する。- なお、
vadd_f16およびvaddq_f16命令だけはArm v8.2命令セットで追加された拡張命令で、半精度浮動小数点数のまま加算ができる命令である。
- なお、
- 次節の
vqaddで触れるが、加算結果がオーバーフローする場合はオーバーフローした分だけが格納される
vaddq.cpp
unsigned char src0[] = {200,201,202,203,204,205,206,207,208,209,210,211,212,213,214,215};
unsigned char src1[] = {100,101,102,103,104,105,106,107,108,109,110,111,112,113,114,115};
unsigned char dst [] = { 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0};
uint8x16_t s0 = vld1q_u8(src0);
uint8x16_t s1 = vld1q_u8(src1);
uint8x16_t d = vaddq_u8(s0, s1); // ここで足し算
- 演算結果
0 200 100 44
1 201 101 46
2 202 102 48
3 203 103 50
4 204 104 52
5 205 105 54
6 206 106 56
7 207 107 58
8 208 108 60
9 209 109 62
10 210 110 64
11 211 111 66
12 212 112 68
13 213 113 70
14 214 114 72
15 215 115 74
- 例えば、最初の要素は
200+100=300と、演算結果が符号なし8bit整数の最大値255を超えるが、演算結果は300 % 256 = 44が格納される - また、
vadd命令は、ベクトルでなく、単体の64bit整数を計算する命令(つまり厳密には SI M D命令ではない)vaddd_s64、vaddd_u64もあり、それぞれ符号あり/なし64bit整数を計算する
vqadd
-
vqdd命令は飽和加算命令で、加算結果がオーバーフローした際、最大値もしくは最小値でクランプする
vqaddq.cpp
unsigned char src0[] = {200,201,202,203,204,205,206,207,208,209,210,211,212,213,214,215};
unsigned char src1[] = {100,101,102,103,104,105,106,107,108,109,110,111,112,113,114,115};
unsigned char dst [] = { 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0};
uint8x16_t s0 = vld1q_u8(src0);
uint8x16_t s1 = vld1q_u8(src1);
uint8x16_t d = vqaddq_u8(s0, s1); // ここで足し算
- このサンプルコードでは演算結果はすべて符号なし8bit整数の最大値
256を超えるが、vqadd命令では演算結果を255に丸める - また、符号あり型の場合は、マイナスの演算結果も最も小さい値に丸め込まれる(例:
int8_t型ならば-128) - 演算結果
0 200 100 255
1 201 101 255
2 202 102 255
3 203 103 255
4 204 104 255
5 205 105 255
6 206 106 255
7 207 107 255
8 208 108 255
9 209 109 255
10 210 110 255
11 211 111 255
12 212 112 255
13 213 113 255
14 214 114 255
15 215 115 255
- また、
vqadd命令には、8bit/16bit/32bit/64bitそれぞれの符号あり/なし整数型単体を計算する命令(つまり厳密にはSI M D命令はない)vqaddb_s8、vqaddh_s16、vqadds_s32、vqaddd_s64、vqaddb_u8、vqaddh_u16、vqadds_u32、vqaddd_u64が存在する - 多分、末尾のアルファベットはそれぞれByte、Half word、Single word、Double word を表してるのだと推察する。
- 参考までに、筆者がよく使うOpenCVでも、内部にNEON実装があり、これによれば
-
u8``s8``u16``s16では飽和加算(vqadd)命令を使う - それ以外(
s32、u32、s64、u64と浮動小数点型)では通常の加算命令(vadd)命令を使う - もともと浮動小数点数型には飽和加算命令が無いのだが、32bit/64bit整数型でもオーバーフローを気にしない実装となっている。
-
intrin_neon.hpp
OPENCV_HAL_IMPL_NEON_BIN_OP(+, v_uint8x16, vqaddq_u8) // 飽和加算命令
OPENCV_HAL_IMPL_NEON_BIN_OP(-, v_uint8x16, vqsubq_u8)
OPENCV_HAL_IMPL_NEON_BIN_OP(+, v_int8x16, vqaddq_s8) // 飽和加算命令
OPENCV_HAL_IMPL_NEON_BIN_OP(-, v_int8x16, vqsubq_s8)
OPENCV_HAL_IMPL_NEON_BIN_OP(+, v_uint16x8, vqaddq_u16) // 飽和加算命令
OPENCV_HAL_IMPL_NEON_BIN_OP(-, v_uint16x8, vqsubq_u16)
OPENCV_HAL_IMPL_NEON_BIN_OP(+, v_int16x8, vqaddq_s16) // 飽和加算命令
OPENCV_HAL_IMPL_NEON_BIN_OP(-, v_int16x8, vqsubq_s16)
OPENCV_HAL_IMPL_NEON_BIN_OP(+, v_int32x4, vaddq_s32) // 加算命令
OPENCV_HAL_IMPL_NEON_BIN_OP(-, v_int32x4, vsubq_s32)
OPENCV_HAL_IMPL_NEON_BIN_OP(*, v_int32x4, vmulq_s32)
OPENCV_HAL_IMPL_NEON_BIN_OP(+, v_uint32x4, vaddq_u32) // 加算命令
OPENCV_HAL_IMPL_NEON_BIN_OP(-, v_uint32x4, vsubq_u32)
OPENCV_HAL_IMPL_NEON_BIN_OP(*, v_uint32x4, vmulq_u32)
OPENCV_HAL_IMPL_NEON_BIN_OP(+, v_float32x4, vaddq_f32) // 加算命令
OPENCV_HAL_IMPL_NEON_BIN_OP(-, v_float32x4, vsubq_f32)
OPENCV_HAL_IMPL_NEON_BIN_OP(*, v_float32x4, vmulq_f32)
OPENCV_HAL_IMPL_NEON_BIN_OP(+, v_int64x2, vaddq_s64) // 加算命令
OPENCV_HAL_IMPL_NEON_BIN_OP(-, v_int64x2, vsubq_s64)
OPENCV_HAL_IMPL_NEON_BIN_OP(+, v_uint64x2, vaddq_u64) // 加算命令
OPENCV_HAL_IMPL_NEON_BIN_OP(-, v_uint64x2, vsubq_u64)
vaddl
-
vaddl命令は、64bit幅のレジスタ2つを引数に取り、128bitレジスタを結果として返す - 加算結果がオーバーフローしないように、出力結果の各要素は、入力レジスタの各要素の倍の幅を持つ
- 結果、取りうる引数は符号あり/なしの整数型の8、16、32bitの合計6種類
addl.cpp
int8_t src0[] = {100,101,102,103,-127,-126,-125,-124,};
int8_t src1[] = { 50, 50, 50, 50, -10, -10, -10, -10,};
int8x8_t vsrc0 = vld1_s8(src0);
int8x8_t vsrc1 = vld1_s8(src1);
int16x8_t vdst = vaddl_s8(vsrc0, vsrc1);
- 演算結果
0 100 50 150
1 101 50 151
2 102 50 152
3 103 50 153
4 -127 -10 -137
5 -126 -10 -136
6 -125 -10 -135
7 -124 -10 -134
- 入力は符号あり8bit整数型だが、計算結果はその範囲を超えている
- しかし、演算の結果、各要素は16bit整数型に変わったため、演算結果にオーバーフローの影響は出ていない
vaddw
-
vaddl命令に非常によく似ているが、引数2つの型が最初から違うのが特徴
arm_neon.h
int16x8_t
vaddw_s8 (int16x8_t __a, int8x8_t __b)
- こういう具合に、第1引数は16bit整数型8個で128bitのレジスタ、第2引数は8bit整数型8個で64bitのレジスタ、戻り値は第1引数と同じ128bitのレジスタ
- Accumulatorみたいに、ベクトルをどんどん足し合わせる際に、積み上がっていく結果をもともと128bit幅で用意しておけば、結果がオーバーフローしないという配慮がなされている。
- また、
vaddwには、highが末尾に付いた命令も存在する
arm_neon.h
int16x8_t
vaddw_high_s8 (int16x8_t __a, int8x16_t __b)
- こちらは、第2引数も128bit幅になっているが、この内使われるのは上位64bitのみ
- 上位というのは、8bit整数ならば、8番目から15番目、の具合に、後方の64bitレジスタのみ使われる。
- もともと、
NEONは、64bitレジスタが基本で使われていた歴史的背景があり、こうやって64bit幅レジスタで使う方法が多数サポートされている。 - また、引数の幅が64bit/128bitで食い違う場合、
vaddw_high命令のように、highが末尾に付いた命令が提供される
おわりに
-
add命令だけで力尽きそうなので、3日目はここで終了。 - 明日も引き続き筆者の執筆で、水平加算系の命令を紹介する予定