E資格(2022#1)に合格しました。本記事は、受験時の勉強ノートをもとにClaudeを使って整理したものです。今回は数学編です。
内容は、線形代数・微分・確率・情報理論・最適化・パラメータ推定・評価指標です。試験直前のリファレンスとして活用いただけます。
1 線形代数
1-1 内積計算
■ 【例】内積の計算 画像引用元
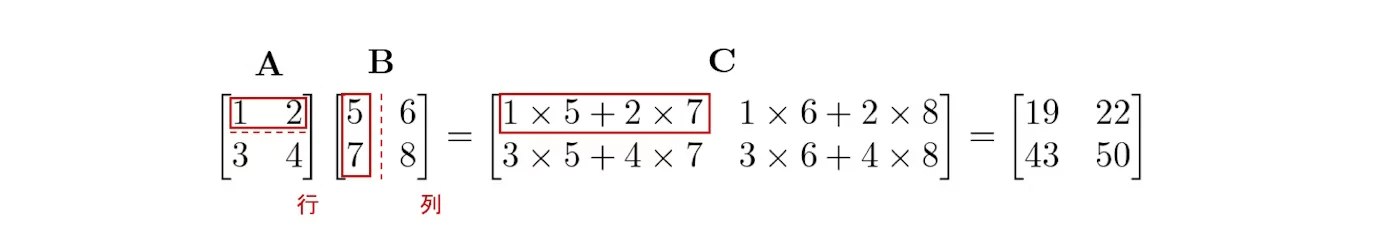
1-2 ノルム・距離
■ ノルムと距離
- ノルム:ベクトルや行列そのものの大きさ
- 距離:2つのスカラーやベクトル間の離れ具合
■ ノルムの種類
- L1ノルム:$\mathbf{x}$ の各成分の絶対値の総和
- L2ノルム:$\mathbf{x}$ の各成分の2乗和の平方根
- p-ノルム:L1・L2ノルムを一般化したもの
- ∞-ノルム:$\mathbf{x}$ の各成分の絶対値の最大値
\begin{align*}
&\text{L1ノルム} &&\quad \|\mathbf{x}\|_1 = \sum_{i=1}^{n} |x_i| \\[8mm]
&\text{L2ノルム} &&\quad \|\mathbf{x}\|_2 = \sqrt{ \sum_{i=1}^{n} x_i^2 } \\[8mm]
&\text{p-ノルム} &&\quad \|\mathbf{x}\|_p = \left( \sum_{i=1}^{n} |x_i|^p \right)^{1/p} \\[8mm]
&\text{∞-ノルム} &&\quad \|\mathbf{x}\|_\infty = \max_{i} |x_i|
\end{align*}
■ 距離の種類
- ユークリッド距離:$\mathbf{x}$ と $\mathbf{y}$ の直線距離
- マンハッタン距離:$\mathbf{x}$ と $\mathbf{y}$ の縦横の格子状に進む距離
- ミンコフスキー距離:ユークリッド・マンハッタン距離を一般化したもの
- チェビシェフ距離:$\mathbf{x}$ と $\mathbf{y}$ の各成分の差の最大値
- マハラノビス距離:$\mathbf{x}$ と平均ベクトル $\boldsymbol{\mu}$ の、分散共分散行列を考慮した距離
\begin{align*}
&\text{ユークリッド距離} &&\quad d(\mathbf{x}, \mathbf{y}) = \sqrt{ \sum_{i=1}^n (x_i - y_i)^2 } \\[8mm]
&\text{マンハッタン距離} &&\quad d(\mathbf{x}, \mathbf{y}) = \sum_{i=1}^n |x_i - y_i| \\[8mm]
&\text{ミンコフスキー距離} &&\quad d(\mathbf{x}, \mathbf{y}) = \left( \sum_{i=1}^n |x_i - y_i|^p \right)^{1/p} \\[8mm]
&\text{チェビシェフ距離} &&\quad d(\mathbf{x}, \mathbf{y}) = \max_{i} |x_i - y_i| \\[8mm]
&\text{マハラノビス距離} &&\quad d(\mathbf{x}, \boldsymbol{\mu}) = \sqrt{ (\mathbf{x} - \boldsymbol{\mu})^\top \boldsymbol{\Sigma}^{-1} (\mathbf{x} - \boldsymbol{\mu}) }
\end{align*}
■ パラメータ最適化におけるノルム(正則化)
- パラメータが大きくなりすぎるのを防ぐため、ノルムを用いた正則化項を損失関数に付加する。
- L2正則化:全ての重みをまんべんなく小さく抑える(Ridge)
- L1正則化:一部の重みを0にしやすく、特徴選択の効果がある(Lasso)
- Elastic Net:L1+L2正則化で、特徴選択と滑らかさを両立
\begin{align*}
&\text{損失関数} &&\quad L(\mathbf{w}) = \ell(\mathbf{w}) + \lambda R(\mathbf{w}) \\[8mm]
&\text{L2正則化} &&\quad R(\mathbf{w}) = \frac{1}{2} \sum_{j=1}^{d} w_j^2 \\[8mm]
&\text{L1正則化} &&\quad R(\mathbf{w}) = \sum_{j=1}^{d} |w_j| \\[8mm]
&\text{Elastic Net} &&\quad R(\mathbf{w}) = \alpha \sum_{j=1}^{d} |w_j| + \frac{1-\alpha}{2} \sum_{j=1}^{d} w_j^2
\end{align*}
- $\ell(\mathbf{w})$:経験損失(二乗誤差・交差エントロピーなど)
- $\lambda$:正則化の強さを調整するハイパーパラメータ
- $R(\mathbf{w})$:正則化項
1-3 固有値分解
■ 固有値問題
\begin{align*}
&\text{正方行列 } A \text{ について、} \\[2mm]
&A\mathbf{u} = \lambda \mathbf{u} \\[2mm]
&\text{を満たす } \lambda \text{ とベクトル } \mathbf{u} \neq \mathbf{0} \text{ が存在するとき、} \\[2mm]
&\lambda \text{ を固有値、} \mathbf{u} \text{ を固有ベクトルという。}
\end{align*}
■ 固有方程式
\begin{align*}
&\text{固有値 } \lambda \text{ と固有ベクトル } \mathbf{u} \text{ は、} \\[2mm]
&\text{固有方程式 } \det(A - \lambda I) = 0 \text{ で求めることができる。}
\end{align*}
■ 固有値分解
\begin{align*}
&\text{行列 } A \text{ を、固有ベクトルを並べた行列 } P \text{ と、} \\[2mm]
&\text{固有値を並べた対角行列 } \Lambda \text{ の積に分解すること。} \\[4mm]
&A = P \Lambda P^{-1}
\end{align*}
■ 対角化
\begin{align*}
&\text{行列 } A \text{ を、計算が簡単な「対角行列 } \Lambda \text{ 」に変形すること。} \\[4mm]
&P^{-1}AP = \Lambda = \begin{bmatrix} \lambda_1 & 0 \\ 0 & \lambda_2 \end{bmatrix}
\end{align*}
■ 【例】固有方程式の使い方
\begin{aligned}
&\text{行列 } A = \begin{bmatrix} 4 & 1 \\ -2 & 1 \end{bmatrix} \text{ の固有値と固有ベクトルを求める}
\\[16mm]
&\text{1. 固有方程式 } \det(A - \lambda I) = 0 \text{ を解く}
\\[8mm]
&\det \left( \begin{bmatrix} 4-\lambda & 1 \\ -2 & 1-\lambda \end{bmatrix} \right) = 0
\\[4mm]
&(4-\lambda)(1-\lambda) - (1 \cdot -2) = 0
\\[4mm]
&\lambda^2 - 5\lambda + 4 + 2 = 0
\\[4mm]
&\lambda^2 - 5\lambda + 6 = 0
\\[4mm]
&(\lambda - 2)(\lambda - 3) = 0
\\[4mm]
&\text{よって、固有値は } \lambda = 2,\, 3
\\[16mm]
&\text{2. 固有ベクトルを求める}
\\[8mm]
&\text{① } \lambda = 2 \text{ のとき:}
\\[4mm]
&(A - 2I)\mathbf{u} = \mathbf{0}
\quad\Rightarrow\quad
\begin{bmatrix} 2 & 1 \\ -2 & -1 \end{bmatrix} \begin{bmatrix} u_1 \\ u_2 \end{bmatrix} = \begin{bmatrix} 0 \\ 0 \end{bmatrix}
\\[4mm]
&2u_1 + u_2 = 0 \quad\Rightarrow\quad u_2 = -2u_1
\\[4mm]
&\mathbf{u} = \begin{bmatrix} 1 \\ -2 \end{bmatrix}
\\[6mm]
&\text{② } \lambda = 3 \text{ のとき:}
\\[4mm]
&(A - 3I)\mathbf{v} = \mathbf{0}
\quad\Rightarrow\quad
\begin{bmatrix} 1 & 1 \\ -2 & -2 \end{bmatrix} \begin{bmatrix} v_1 \\ v_2 \end{bmatrix} = \begin{bmatrix} 0 \\ 0 \end{bmatrix}
\\[4mm]
&v_1 + v_2 = 0 \quad\Rightarrow\quad v_2 = -v_1
\\[4mm]
&\mathbf{v} = \begin{bmatrix} 1 \\ -1 \end{bmatrix}
\end{aligned}
■ 固有値分解の応用(PCAとの接続)
- 分散共分散行列 $\boldsymbol{\Sigma}$ の固有値分解を行うと、主成分分析(PCA) に直結する。
- 固有値 $\lambda_i$ は各主成分の分散(寄与)の大きさ、固有ベクトル $\mathbf{u}_i$ は主成分の方向を表す。
- 固有値の大きい順に $k$ 個の固有ベクトルを選ぶことで、次元削減が実現できる。
\boldsymbol{\Sigma} = P \Lambda P^{-1}, \qquad
\text{寄与率} = \frac{\lambda_i}{\sum_{j} \lambda_j}, \qquad
\text{累積寄与率} = \frac{\sum_{j=1}^{k} \lambda_j}{\sum_{j} \lambda_j}
1-4 特異値分解
■ 特異値問題
\begin{align*}
&\text{一般の行列(} m \times n \text{ 行列)} A \text{ について、} \\[2mm]
&A\mathbf{v} = \sigma \mathbf{u}, \qquad A^{\top}\mathbf{u} = \sigma \mathbf{v} \\[2mm]
&\text{を満たす } \sigma \geq 0 \text{ とベクトル } \mathbf{u} \neq \mathbf{0},\, \mathbf{v} \neq \mathbf{0} \text{ が存在するとき、} \\[2mm]
&\sigma \text{ を特異値、} \mathbf{u} \text{ を左特異ベクトル、} \mathbf{v} \text{ を右特異ベクトルという。}
\end{align*}
■ 特異値の求め方
\begin{align*}
&\text{特異値 } \sigma \text{ と特異ベクトル } \mathbf{u},\, \mathbf{v} \text{ は、} \\[2mm]
&A^{\top}A \text{ の固有値 } \lambda_i \text{ から } \sigma_i = \sqrt{\lambda_i} \text{ として求めることができる。} \\[2mm]
&\text{右特異ベクトル } \mathbf{v}_i \text{ は } A^{\top}A \text{ の固有ベクトル、左特異ベクトル } \mathbf{u}_i = \dfrac{A\mathbf{v}_i}{\sigma_i}
\end{align*}
■ 特異値分解(SVD)
\begin{align*}
&\text{行列 } A \text{ を、左特異ベクトルを並べた行列 } U \text{ と、} \\[2mm]
&\text{特異値を並べた対角行列 } \Sigma \text{ と、} \\[2mm]
&\text{右特異ベクトルを並べた行列 } V \text{ の積に分解すること。} \\[4mm]
&A = U \Sigma V^{\top}
\end{align*}
■ 固有値分解との対比
\begin{align*}
&\text{固有値分解} &&\quad A = P \Lambda P^{-1} \qquad \text{(正方行列のみ)} \\[4mm]
&\text{特異値分解} &&\quad A = U \Sigma V^{\top} \qquad \text{(任意の } m \times n \text{ 行列に適用可能)} \\[4mm]
& &&\quad U^{\top}U = I_m, \quad V^{\top}V = I_n \qquad \text{(} U,\, V \text{ はともに直交行列)}
\end{align*}
■ 【例】特異値分解の計算
\begin{aligned}
&\text{行列 } A = \begin{bmatrix} 3 & 0 \\ 0 & 2 \\ 0 & 0 \end{bmatrix} \text{ の特異値分解を求める}
\\[16mm]
&\text{1. } A^{\top}A \text{ を計算し、固有値を求める}
\\[8mm]
&A^{\top}A
= \begin{bmatrix} 3 & 0 & 0 \\ 0 & 2 & 0 \end{bmatrix}
\begin{bmatrix} 3 & 0 \\ 0 & 2 \\ 0 & 0 \end{bmatrix}
= \begin{bmatrix} 9 & 0 \\ 0 & 4 \end{bmatrix}
\\[4mm]
&\text{固有値は } \lambda_1 = 9,\, \lambda_2 = 4
\\[4mm]
&\text{よって、特異値は } \sigma_1 = 3,\, \sigma_2 = 2
\\[16mm]
&\text{2. 右特異ベクトル(} A^{\top}A \text{ の固有ベクトル)を求める}
\\[8mm]
&\mathbf{v}_1 = \begin{bmatrix} 1 \\ 0 \end{bmatrix}, \qquad \mathbf{v}_2 = \begin{bmatrix} 0 \\ 1 \end{bmatrix}
\\[16mm]
&\text{3. 左特異ベクトルを求める:} \mathbf{u}_i = \dfrac{A\mathbf{v}_i}{\sigma_i}
\\[8mm]
&\mathbf{u}_1 = \frac{1}{3}\begin{bmatrix} 3 \\ 0 \\ 0 \end{bmatrix} = \begin{bmatrix} 1 \\ 0 \\ 0 \end{bmatrix}, \qquad
\mathbf{u}_2 = \frac{1}{2}\begin{bmatrix} 0 \\ 2 \\ 0 \end{bmatrix} = \begin{bmatrix} 0 \\ 1 \\ 0 \end{bmatrix}
\\[16mm]
&\text{4. 特異値分解をまとめる}
\\[4mm]
&A = U \Sigma V^{\top}
= \begin{bmatrix} 1 & 0 \\ 0 & 1 \\ 0 & 0 \end{bmatrix}
\begin{bmatrix} 3 & 0 \\ 0 & 2 \end{bmatrix}
\begin{bmatrix} 1 & 0 \\ 0 & 1 \end{bmatrix}
\end{aligned}
■ 低ランク近似(情報圧縮)
- 特異値を大きい順に $k$ 個だけ残して切り捨てることで、行列 $A$ を近似できる(打ち切りSVD)。
- フロベニウスノルム意味での最良の低ランク近似であることが保証されている(Eckart–Young の定理)。
- 画像圧縮・推薦システム・自然言語処理(LSA)で広く利用される。
A \approx A_k = \sum_{i=1}^{k} \sigma_i \mathbf{u}_i \mathbf{v}_i^{\top}
= U_k \Sigma_k V_k^{\top}
\qquad (k \ll \min(m, n))
- $k$:保持する特異値の数(ランク)
- $\sigma_1 \geq \sigma_2 \geq \cdots \geq \sigma_k > 0$
- 近似誤差:$|A - A_k|F = \sqrt{\sum{i=k+1}^{\min(m,n)} \sigma_i^2}$
2 微分
2-1 連鎖率
■ 順伝播と逆伝播
\begin{align*}
&z = f(x)\qquad &&\frac{dL}{dx} = \frac{dL}{dz} \cdot \frac{dz}{dx} \\[
4mm]
&z = f(x, y)\qquad &&
\frac{\partial L}{\partial x} = \frac{\partial L}{\partial z} \cdot \frac{\partial z}{\partial x}, \qquad
\frac{\partial L}{\partial y} = \frac{\partial L}{\partial z} \cdot \frac{\partial z}{\partial y}
\end{align*}

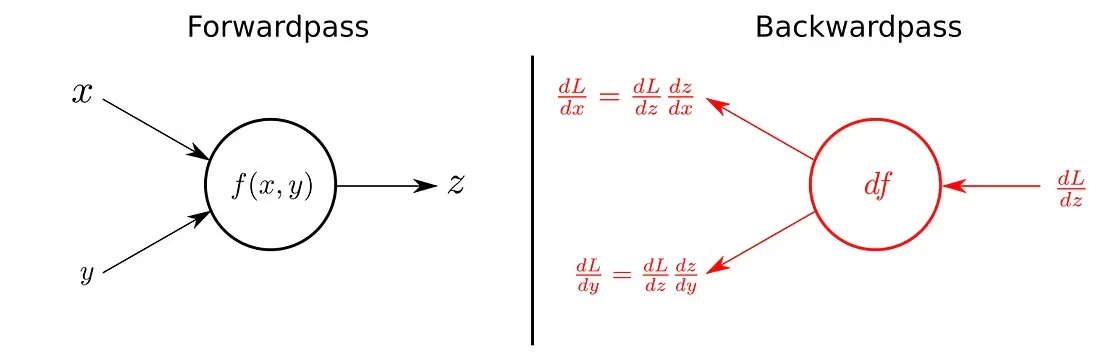
■ 加算の計算グラフ
z = x + y, \qquad \frac{\partial z}{\partial x} = 1, \qquad \frac{\partial z}{\partial y} = 1

■ 乗算の計算グラフ
z = x \cdot y, \qquad \frac{\partial z}{\partial x} = y, \qquad \frac{\partial z}{\partial y} = x

■ Affine変換の計算グラフ
\mathbf{Y} = \mathbf{X}\mathbf{W} + \mathbf{B}, \qquad
\frac{\partial L}{\partial \mathbf{X}} = \frac{\partial L}{\partial \mathbf{Y}}\mathbf{W}^{\top}, \qquad
\frac{\partial L}{\partial \mathbf{W}} = \mathbf{X}^{\top}\frac{\partial L}{\partial \mathbf{Y}}, \qquad
\frac{\partial L}{\partial \mathbf{B}} = \frac{\partial L}{\partial \mathbf{Y}}

■ ベクトルの逆伝播(ヤコビアン)
- 入力 $\mathbf{x} \in \mathbb{R}^n$、出力 $\mathbf{z} \in \mathbb{R}^m$ のとき、連鎖率はヤコビアンを用いて表される。
- ニューラルネットワークの逆伝播はこのヤコビアン転置との積として計算される。
\frac{\partial L}{\partial \mathbf{x}}
= \left(\frac{\partial \mathbf{z}}{\partial \mathbf{x}}\right)^{\top} \frac{\partial L}{\partial \mathbf{z}}, \qquad
J = \frac{\partial \mathbf{z}}{\partial \mathbf{x}} =
\begin{bmatrix}
\dfrac{\partial z_1}{\partial x_1} & \cdots & \dfrac{\partial z_1}{\partial x_n} \\
\vdots & \ddots & \vdots \\
\dfrac{\partial z_m}{\partial x_1} & \cdots & \dfrac{\partial z_m}{\partial x_n}
\end{bmatrix}
\in \mathbb{R}^{m \times n}
2-2 活性化関数と微分
■ ニューラルネットワークにおける活性化関数
- ニューラルネットワークの活性化関数 $f$ を含む層の勾配は以下のとおり。
- $f'(x) = 0$ となる領域が広いと勾配が消えて学習が停滞する(勾配消失問題)。
\frac{\partial L}{\partial x} = \frac{\partial L}{\partial f} \cdot f'(x)
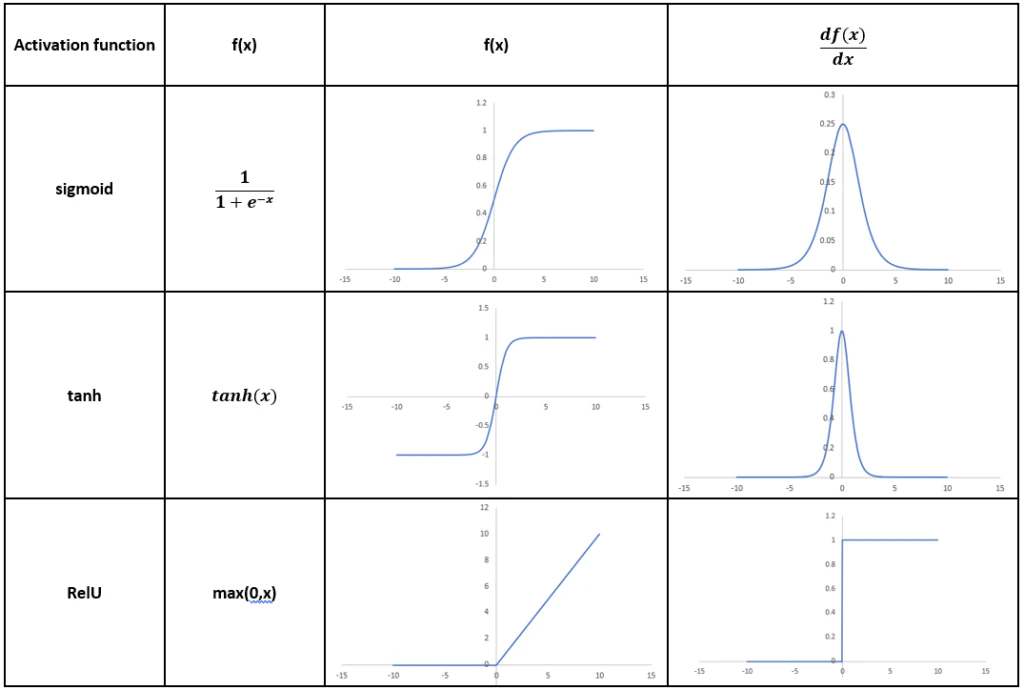
■ Sigmoid関数と勾配消失
- 値域 $f(x) \in (0,1)$、最大値は $f'(x)=0.25$($x=0$ のとき)
- 深層で逆伝播すると導関数の積が $0.25^L$ と急速に小さくなり勾配消失となる
- $x$ が大きいまたは小さいとき $f'(x)\to0$
■ Tanh関数と勾配消失
- 値域 $f(x) \in (-1,1)$、最大値は $f'(x)=1$($x=0$ のとき)
- 多層で飽和領域になると導関数の積が指数的に減少し、勾配消失となる(Sigmoid関数よりマシ)
- $x$ が大きいまたは小さいとき $f(x)\to\pm1$ で $f'(x)\to0$
■ ReLU関数と勾配消失
- $x > 0$ では $f'(x)=1$ なので、勾配が減衰しにくい
- $x \leq 0$ では $f'(x)=0$ のため勾配が消える(dying ReLU問題)
■ GELU・Swishと勾配消失
- どちらも $x \leq 0$ 側に小さな勾配が残るため dying ReLU 問題が起きにくい。
- GELU:Transformerや BERTで広く使われる。正規分布の累積分布関数 $\Phi(x)$ を利用。
- Swish(SiLU):自己ゲート型の滑らかな活性化関数。EfficientNetなどで使われる。
■ 活性化関数と微分
\begin{aligned}
&\text{Step}
&& f(x) = \begin{cases}
1 & (x > 0) \\
0 & (x \leq 0)
\end{cases}
&& f'(x) = 0\ \text{(通常定義されない)} \\[8mm]
&\text{Identity}
&& f(x) = x
&& f'(x) = 1 \\[8mm]
&\text{Sigmoid}
&& f(x) = \frac{1}{1+e^{-x}}
&& f'(x) = f(x)\left[1 - f(x)\right] \\[8mm]
&\text{Tanh}
&& f(x) = \frac{e^{x} - e^{-x}}{e^{x} + e^{-x}}
&& f'(x) = 1 - [f(x)]^2 \\[8mm]
&\text{ReLU}
&& f(x) = \max(0, x)
&& f'(x) =
\begin{cases}
1 & (x > 0) \\
0 & (x \leq 0)
\end{cases} \\[8mm]
&\text{Leaky ReLU}
&& f(x) = \max(\alpha x, x)
&& f'(x) =
\begin{cases}
1 & (x > 0) \\
\alpha & (x \leq 0)
\end{cases} \\[8mm]
&\text{ELU}
&& f(x) =
\begin{cases}
x & (x \geq 0) \\
\alpha (e^{x} - 1) & (x < 0)
\end{cases}
&& f'(x) =
\begin{cases}
1 & (x \geq 0) \\
f(x) + \alpha & (x < 0)
\end{cases} \\[8mm]
&\text{GELU}
&& f(x) = x \cdot \Phi(x)
&& f'(x) = \Phi(x) + x\,\phi(x) \\[8mm]
&\text{Swish (SiLU)}
&& f(x) = x \cdot \sigma(x)
&& f'(x) = \sigma(x)\bigl(1 + x(1-\sigma(x))\bigr) \\[8mm]
&\text{Softmax}
&& f_i(\mathbf{x}) = \frac{e^{x_i}}{\sum_j e^{x_j}}
&& \frac{\partial f_i}{\partial x_j} = f_i(\mathbf{x})\left[\delta_{ij} - f_j(\mathbf{x})\right]
\end{aligned}
- $\Phi(x)$:標準正規分布の累積分布関数、$\phi(x)$:その確率密度関数
- $\sigma(x)$:Sigmoid関数
3 確率・統計
3-1 確率の基本
■ 加法定理・乗法定理・周辺確率
\begin{aligned}
&\text{加法定理} &&\quad P(A \cup B) = P(A) + P(B) - P(A \cap B) \\[8mm]
&\text{乗法定理・同時確率} &&\quad P(A \cap B) = P(A, B) \\[8mm]
&\text{条件付き確率} &&\quad P(A \cap B) = P(A \mid B)\,P(B) = P(B \mid A)\,P(A) \\[8mm]
&\text{周辺確率(離散型)} &&\quad P(A) = \sum_{B} P(A, B) = \sum_{B} P(A \mid B)\,P(B) \\[8mm]
&\text{周辺確率(連続型)} &&\quad P(A) = \int P(A, B)\,dB = \int P(A \mid B)\,P(B)\,dB
\end{aligned}
■ 期待値・分散・共分散
\begin{array}{ll}
\text{母集団平均・分散} &
\displaystyle\quad
\mu = \frac{1}{N} \sum_{i=1}^{N} x_{i}, \qquad
\sigma^2 = \frac{1}{N} \sum_{i=1}^{N} (x_{i} - \mu)^2 \\[8mm]
\text{標本平均・分散} &
\displaystyle\quad
\bar{x} = \frac{1}{n} \sum_{i=1}^{n} x_{i}, \qquad
s^2 = \frac{1}{n} \sum_{i=1}^{n} (x_{i} - \bar{x})^2 \\[4mm] &\text{(不偏分散は } \tfrac{1}{n-1} \text{ で割る)} \\[8mm]
\text{期待値と分散} &
\displaystyle\quad
\mathbb{E}[X] = \sum_{x} x\,p(x), \qquad
\mathbb{V}[X] = \sum_{x} (x - \mathbb{E}[X])^2\,p(x) \\[8mm]
\text{分散の性質} &
\displaystyle\quad
\mathbb{V}[X] = \mathbb{E}\!\left[(X-\mathbb{E}[X])^2\right] = \mathbb{E}[X^2] - (\mathbb{E}[X])^2 \\[8mm]
\text{共分散} &
\displaystyle\quad
\sigma_{xy}
= \frac{1}{n} \sum_{i=1}^{n} (x_i - \bar{x})(y_i - \bar{y})
= \frac{1}{n} \sum_{i=1}^{n} x_{i} y_{i} - \bar{x}\,\bar{y} \\[8mm]
\text{共分散行列} &
\quad S =
\begin{pmatrix}
s_{1}^2 & s_{12} & \cdots & s_{1d} \\
s_{12} & s_{2}^2 & \cdots & s_{2d} \\
\vdots & \vdots & \ddots & \vdots \\
s_{1d} & s_{2d} & \cdots & s_{d}^2
\end{pmatrix} \\[8mm]
\text{相関係数} &
\displaystyle\quad
r = \frac{\sum_{i=1}^n (x_i-\bar{x})(y_i-\bar{y})}
{\sqrt{\sum_{i=1}^n(x_i-\bar{x})^2}\;\sqrt{\sum_{i=1}^n(y_i-\bar{y})^2}}
= \frac{\sigma_{xy}}{\sigma_x\,\sigma_y} \\[8mm]
\text{決定係数} &
\displaystyle\quad
R^2 = 1 - \frac{\sum(y_i - \hat{y}_i)^2}{\sum(y_i - \bar{y})^2} \\[8mm]
\text{条件付き期待値} &
\displaystyle\quad
\mathbb{E}[X \mid Y=y] = \sum_{i=1}^{n} x_i\,P(X=x_i \mid Y=y) \\[4mm]
& \displaystyle\quad
\mathbb{E}[X] = \sum_{j=1}^{m} \mathbb{E}[X \mid Y=y_j]\,P(Y=y_j) \\[8mm]
\text{条件付き分散} &
\displaystyle\quad
\mathbb{V}[X \mid Y] = \mathbb{E}[X^2 \mid Y] - \bigl(\mathbb{E}[X \mid Y]\bigr)^2 \\[4mm]
& \displaystyle\quad
\mathbb{V}[X] = \mathbb{E}\!\left[\mathbb{V}[X \mid Y]\right] + \mathbb{V}\!\left[\mathbb{E}[X \mid Y]\right]
\end{array}
3-2 確率分布
■ 確率分布の種類
- 正規分布 $\mathcal{N}(x \mid \mu, \sigma^2)$
- ベルヌーイ分布 $\mathrm{Ber}(x \mid p)$
- カテゴリカル分布 $\mathrm{Cat}(\mathbf{x} \mid \mathbf{p})$
- 二項分布 $\mathrm{Bin}(x \mid p, n)$
- 多項分布 $\mathrm{Mult}(\mathbf{x} \mid \mathbf{p}, n)$
- ポアソン分布 $\mathrm{Poisson}(x \mid \lambda)$
- 一様分布 $\mathrm{Unif}(x \mid a, b)$
- 指数分布 $\mathrm{Exp}(x \mid \lambda)$
■ 正規分布
\begin{aligned}
&\text{期待値と分散} &&\quad \mu,\quad \sigma^2 \\[8mm]
&\text{確率密度関数} &&\quad f(x \mid \mu, \sigma^2)
= \frac{1}{\sqrt{2\pi\sigma^2}}\,\exp\!\left(-\frac{(x-\mu)^2}{2\sigma^2}\right) \\[8mm]
&\text{尤度関数} &&\quad L(\mu, \sigma^2 \mid \mathbf{x})
= \prod_{i=1}^n \frac{1}{\sqrt{2\pi\sigma^2}}\,\exp\!\left(-\frac{(x_i-\mu)^2}{2\sigma^2}\right) \\[8mm]
&\text{対数尤度関数} &&\quad \log L(\mu, \sigma^2 \mid \mathbf{x})
= -n\log\sqrt{2\pi\sigma^2} - \frac{1}{2\sigma^2}\sum_{i=1}^n (x_i-\mu)^2
\end{aligned}
■ ベルヌーイ分布
\begin{aligned}
&\text{期待値と分散} &&\quad p,\quad p(1-p) \\[8mm]
&\text{確率質量関数} &&\quad f(x \mid p) = p^{x}(1-p)^{1-x} \\[8mm]
&\text{制約条件} &&\quad p \in [0,1],\quad x \in \{0,1\} \\[8mm]
&\text{尤度関数} &&\quad L(p \mid \mathbf{x})
= \prod_{i=1}^n p^{x_i}(1-p)^{1-x_i} \\[8mm]
&\text{対数尤度関数} &&\quad \log L(p \mid \mathbf{x})
= \sum_{i=1}^n \bigl[x_i\log p + (1-x_i)\log(1-p)\bigr]
\end{aligned}
■ カテゴリカル分布
\begin{aligned}
&\text{期待値と分散} &&\quad p_k,\quad p_k(1-p_k) \\[8mm]
&\text{確率質量関数} &&\quad f(\mathbf{x} \mid \mathbf{p}) = \prod_{k=1}^K p_k^{x_k} \\[8mm]
&\text{制約条件} &&\quad \sum_{k=1}^K p_k = 1,\quad 0 \le p_k \le 1, \\[4mm]
& &&\quad \mathbf{x} = (x_1,\ldots,x_K),\quad x_k \in \{0,1\},\quad \sum_{k=1}^K x_k = 1 \\[8mm]
&\text{尤度関数} &&\quad L(\mathbf{p} \mid \mathbf{x})
= \prod_{i=1}^n \prod_{k=1}^K p_k^{x_{ik}} \\[8mm]
&\text{負の対数尤度関数} &&\quad -\log L(\mathbf{p} \mid \mathbf{x})
= -\sum_{i=1}^n \sum_{k=1}^K x_{ik}\log p_k
\end{aligned}
■ 二項分布
\begin{aligned}
&\text{期待値と分散} &&\quad np,\quad np(1-p) \\[8mm]
&\text{確率質量関数} &&\quad f(x \mid p,n)
= \frac{n!}{x!\,(n-x)!}\,p^x(1-p)^{n-x} \\[8mm]
&\text{制約条件} &&\quad p \in [0,1],\quad x \in \{0,1,\ldots,n\},\quad n \in \mathbb{N}
\end{aligned}
■ 多項分布
\begin{aligned}
&\text{期待値と分散} &&\quad np_k,\quad np_k(1-p_k) \\[8mm]
&\text{確率質量関数} &&\quad f(\mathbf{x} \mid \mathbf{p},n)
= \frac{n!}{x_1!\,x_2!\cdots x_K!} \prod_{k=1}^K p_k^{x_k} \\[8mm]
&\text{制約条件} &&\quad \sum_{k=1}^K p_k = 1,\quad 0 \le p_k \le 1, \\[4mm]
& &&\quad x_k \in \{0,1,\ldots,n\},\quad \sum_{k=1}^K x_k = n
\end{aligned}
■ 一様分布
\begin{aligned}
&\text{期待値と分散} &&\quad \frac{a+b}{2},\quad \frac{(b-a)^2}{12} \\[8mm]
&\text{確率密度関数} &&\quad f(x \mid a,b) =
\begin{cases}
\dfrac{1}{b-a} & a \leq x \leq b \\[4mm]
0 & \text{otherwise}
\end{cases}
\end{aligned}
■ 指数分布
\begin{aligned}
&\text{期待値と分散} &&\quad \frac{1}{\lambda},\quad \frac{1}{\lambda^2} \\[8mm]
&\text{確率密度関数} &&\quad f(x \mid \lambda) = \lambda\exp(-\lambda x), \quad x \geq 0
\end{aligned}
■ ポアソン分布
\begin{aligned}
&\text{期待値と分散} &&\quad \lambda,\quad \lambda \\[8mm]
&\text{確率質量関数} &&\quad f(x \mid \lambda)
= \frac{\lambda^{x}}{x!}\,\exp(-\lambda) \\[8mm]
&\text{制約条件} &&\quad x = 0,1,2,\ldots,\qquad \lambda > 0
\end{aligned}
3-3 ベイズの定理
■ ベイズの定理
\overset{\text{(事後確率)}}{P(A \mid B)}
=
\frac{
\overset{\text{(尤度)}}{P(B \mid A)}
\;\;
\overset{\text{(事前確率)}}{P(A)}
}{
\underset{\text{(周辺尤度・エビデンス・正規化定数)}}{P(B)}
}
- $P(A \mid B)$:事後確率。事象 $B$ が観測されたとき、仮説 $A$ の確率
- $P(B \mid A)$:尤度。仮説 $A$ のもとで事象 $B$ が観測される確率
- $P(A)$:事前確率。事象 $B$ 観測前の仮説 $A$ の確率
- $P(B)$:周辺尤度(エビデンス)。全仮説 $A$ に関する $P(B)$ の合計。事後確率 $P(A \mid B)$ の正規化定数
■ ベイズの定理の変形式
\begin{aligned}
&\text{変形式} &&\quad P(A \mid B) = \frac{P(A \cap B)}{P(B)} \\[8mm]
&\text{恒等式} &&\quad \frac{P(A \mid B)\,P(B)}{P(B)} = \frac{P(B \mid A)\,P(A)}{P(B)} \\[8mm]
&\text{二項対立} &&\quad P(A \mid B)
= \frac{P(B \mid A)\,P(A)}{P(B \mid A)\,P(A) + P(B \mid \bar{A})\,P(\bar{A})}
\end{aligned}
■ ベイズ更新
\begin{aligned}
&P(C) = \int P(C \mid A)\,P(A \mid B)\,dA \\[8mm]
&P(A \mid B,C) = \frac{P(C \mid A)\,P(A \mid B)}{P(C)}
\end{aligned}
■ 共役事前分布
- 事前分布と事後分布が同じ分布族に属するとき、その事前分布を共役事前分布という。
- 解析的に事後分布を計算できるため、ベイズ推定が扱いやすくなる。
| 尤度 | 共役事前分布 | 事後分布 |
|---|---|---|
| ベルヌーイ分布 $\mathrm{Ber}(x \mid p)$ | ベータ分布 $\mathrm{Beta}(p \mid \alpha, \beta)$ | ベータ分布 |
| 多項分布 $\mathrm{Mult}(\mathbf{x} \mid \mathbf{p}, n)$ | ディリクレ分布 $\mathrm{Dir}(\mathbf{p} \mid \boldsymbol{\alpha})$ | ディリクレ分布 |
| 正規分布(分散既知)$\mathcal{N}(x \mid \mu, \sigma^2)$ | 正規分布 $\mathcal{N}(\mu \mid \mu_0, \tau^2)$ | 正規分布 |
| ポアソン分布 $\mathrm{Poisson}(x \mid \lambda)$ | ガンマ分布 $\mathrm{Gamma}(\lambda \mid \alpha, \beta)$ | ガンマ分布 |
\underbrace{p(\boldsymbol{\theta} \mid \mathbf{x})}_{\text{事後分布}}
\propto
\underbrace{p(\mathbf{x} \mid \boldsymbol{\theta})}_{\text{尤度}}
\underbrace{p(\boldsymbol{\theta})}_{\text{事前分布(共役)}}
\quad \Rightarrow \quad \text{事後分布} \in \text{同じ分布族}
3-4 確率過程
■ 確率過程
\{X_t\}_{t \in T}
- $T$:時刻や空間などのパラメータ
- $X_t$:各時点の確率変数
■ 確率過程の種類
- マルコフ過程:直前の状態だけで次の状態の確率が決まる過程
- マルコフ決定過程(MDP):エージェントが行動を選択し、状態遷移・報酬が確率的に決まる過程
- 階差過程:前の値に独立ノイズを加えることで値が進む過程
- ウィーナー過程:連続時間で値が確率的に変動する確率微分方程式
- ポアソン過程:一定レートでイベントが時間ごとに発生する過程
- ガウス過程:任意時点集合の値が多変量正規分布に従う過程
- 隠れマルコフ過程:観測できない隠れ状態がマルコフ過程で推移する過程
\begin{array}{ll}
\text{マルコフ過程} & P(X_{t+1} \mid X_t) \\[8mm]
\text{マルコフ決定過程(MDP)} & P(S_{t+1} \mid S_t, A_t), \quad R_{t+1} = r(S_t, A_t, S_{t+1}) \\[8mm]
\text{階差過程(ランダムウォーク)} & X_{t+1} = X_t + \varepsilon_{t+1} \quad (\varepsilon_{t+1} \sim \mathcal{N}(0, \sigma^2)) \\[8mm]
\text{ウィーナー過程(ブラウン運動)} & dX_t = \mu\,dt + \sigma\,dW_t \\[8mm]
\text{ポアソン過程} & N_t \sim \mathrm{Poisson}(\lambda t) \\[8mm]
\text{ガウス過程} & X_t \sim \mathcal{N}(m(t),\, K(s,t)) \\[8mm]
\text{隠れマルコフ過程} & P(Z_1)\displaystyle\prod_{t=1}^{T-1} P(Z_{t+1} \mid Z_t) \displaystyle\prod_{t=1}^{T} P(X_t \mid Z_t)
\end{array}
■ 【例】強化学習におけるマルコフ決定過程
\begin{array}{ll}
\text{状態遷移確率} & p(s' \mid s,a) = \mathrm{Pr}(S_{t+1}=s' \mid S_t=s,\, A_t=a) \\[8mm]
\text{方策} & \pi(a \mid s) = \mathrm{Pr}(A_t=a \mid S_t=s) \\[8mm]
\text{報酬} & R_{t+1} = r(s,a,s') \\[8mm]
\text{累積割引報酬} & G_t = \displaystyle\sum_{k=0}^\infty \gamma^k R_{t+k+1} = R_{t+1} + \gamma G_{t+1} \\[8mm]
\text{状態価値関数} & v_\pi(s) = \mathbb{E}_\pi[G_t \mid S_t=s] \\[8mm]
\text{行動価値関数} & q_\pi(s,a) = \mathbb{E}_\pi[G_t \mid S_t=s,\, A_t=a]
\end{array}
- $\mathcal{S}$:状態集合。エージェントがとりうる全ての状態
- $\mathcal{A}$:行動集合。エージェントがとりうる全ての行動
- $p(s' \mid s,a)$:状態遷移確率。状態 $s$ で行動 $a$ をとったとき、次の状態が $s'$ になる確率
- $\pi(a \mid s)$:方策。状態 $s$ で行動 $a$ をとる確率的ルール
- $R_{t+1}$:報酬。状態 $s$ で行動 $a$ をとり $s'$ へ遷移した際の即時報酬
- $G_t$:リターン(累積割引報酬)。時刻 $t$ から将来にわたって得られる累積報酬
- $\gamma \in [0,1]$:割引率。未来の報酬の現在価値を調整するハイパーパラメータ
- $v_\pi(s)$:状態価値関数。方策 $\pi$ のもとで状態 $s$ から得られる期待リターン
- $q_\pi(s, a)$:行動価値関数。方策 $\pi$ のもとで状態 $s$ で行動 $a$ をとったときの期待リターン
4 情報理論
■ 情報理論の種類
- 基本情報量:ある事象がどれだけ予想しにくいか
- エントロピー:平均情報量。ある分布全体がどれだけ予想しにくいか
- 結合エントロピー:複数の事象の同時分布がどれだけ予想しにくいか
- 条件エントロピー:ある分布を知った上で、もう一方の分布がどれだけ予想しにくいか
- 交差エントロピー:ある分布が別の分布を使って測ったときの予想しにくさ
- 相互情報量:一方の分布を知ることで、もう一方の予想しにくさがどれだけ減るか
- KLダイバージェンス:ある分布が別の分布からどれだけ離れているかを表す純粋なズレ(非対称)
- JSダイバージェンス:KLダイバージェンスを両側から対称に拡張したもの
\begin{array}{ll}
\text{基本情報量} & I(x) = -\log p(x) \\[8mm]
\text{エントロピー} & H(X) = -\displaystyle\sum_{x} p(x) \log p(x) \\[8mm]
\text{交差エントロピー} & H(P, Q) = -\displaystyle\sum_{x} P(x) \log Q(x) \\[8mm]
\text{結合エントロピー} & H(X, Y) = -\displaystyle\sum_{x}\sum_{y} p(x, y)\log p(x, y) \\[8mm]
\text{条件エントロピー} & H(X \mid Y) = -\displaystyle\sum_{x}\sum_{y} p(x, y)\log p(x \mid y) \\[8mm]
\text{相互情報量} & I(X;Y) = \displaystyle\sum_{x}\sum_{y} p(x, y)\log \frac{p(x, y)}{p(x)\,p(y)} \\[8mm]
\text{KLダイバージェンス} & D_{\mathrm{KL}}(P \| Q) = \displaystyle\sum_{x} P(x)\log \frac{P(x)}{Q(x)} \\[8mm]
\text{JSダイバージェンス} & M(x) = \dfrac{P(x) + Q(x)}{2} \\[4mm]
& D_{\mathrm{JS}}(P \| Q) = \dfrac{1}{2}\left(D_{\mathrm{KL}}(P \| M) + D_{\mathrm{KL}}(Q \| M)\right)
\end{array}
■ エントロピーの意味
エントロピーは「基本情報量の期待値」であり、分布全体の予測しにくさを表す。
\underbrace{H(X)}_{\text{分布全体の予測しにくさ}}
=
\underbrace{\mathbb{E}_{x \sim p(x)}[I(x)]}_{\text{基本情報量の期待値}}
= -\sum_{x} p(x)\log p(x)
■ 強化学習への応用
- $Y$ から $X$ が完全に予測できるとき、条件エントロピー $H(X \mid Y) = 0$。この性質は機械学習の評価指標でも利用される。
- 最大エントロピー強化学習では「報酬+エントロピー」を目的関数とする。エントロピー項は各状態 $s$ における方策 $\pi$ の不確かさであり、行動の多様性(探索)を促す。
\begin{aligned}
H(X \mid Y)
&= -\sum_{x}\sum_{y} p(x, y)\log p(x \mid y) \\[4mm]
&= -\sum_{y} p(y)\sum_{x} p(x \mid y)\log p(x \mid y) \\[8mm]
H(\pi(\cdot \mid s))
&= -\sum_{a} \pi(a \mid s)\log \pi(a \mid s)
\end{aligned}
■ 相互情報量の関係式
- $X$ と $Y$ が完全に独立なら $I(X;Y)=0$、強く依存しているほど大きな値をとる。
- 相互情報量は「$Y$ を知る前後で、$X$ の予測しにくさがどれだけ減るか」を表し、エントロピーと条件エントロピーの差として書ける。
\underbrace{I(X;Y)}_{\substack{\text{Y を知ることで減る} \\ \text{X の予測しにくさ}}}
=
\underbrace{H(X)}_{\text{X の予測しにくさ}}
-
\underbrace{H(X \mid Y)}_{\text{Y を知った後の X の予測しにくさ}}
\begin{aligned}
I(X;Y)
&= H(X) - H(X \mid Y) \\[4mm]
&= H(Y) - H(Y \mid X) \\[4mm]
&= H(X) + H(Y) - H(X, Y)
\end{aligned}
■ KLダイバージェンスの非対称性
- $D_{\mathrm{KL}}(P | Q) \neq D_{\mathrm{KL}}(Q | P)$。$P$ と $Q$ のどちらを「基準」にするかで値が変わる。
- $P(x) \approx 0$ の領域は $P(x)$ で重み付けされるため、そこでの $Q(x)$ の乖離は $D_{\mathrm{KL}}(P | Q)$ にほとんど影響しない。
\begin{aligned}
D_{\mathrm{KL}}(P \| Q)
&= \sum_{x} P(x)\log \frac{P(x)}{Q(x)} \\[4mm]
&= -\sum_{x} P(x)\log \frac{Q(x)}{P(x)}
\end{aligned}
■ KLダイバージェンスと交差エントロピーの関係
- KLダイバージェンスは「交差エントロピー($Q$ で $P$ を測った予測しにくさ)」から「エントロピー($P$ 自身の予測しにくさ)」を引いたもの。
- $H(P)$ は $Q$ に依存しない定数のため、$Q$ に関して KLダイバージェンスを最小化することと、交差エントロピーを最小化することは等価な問題になる。
\underbrace{H(P, Q)}_{\substack{\text{Q を使って P を測ったときの} \\ \text{予測しにくさ(ズレを含む)}}}
\ -\
\underbrace{H(P)}_{\substack{\text{P 自身の} \\ \text{予測しにくさ}}}
\ =\
\underbrace{D_{\mathrm{KL}}(P \| Q)}_{\text{P と Q の純粋なズレ}}
\begin{aligned}
D_{\mathrm{KL}}(P \| Q)
&= \sum_{x} P(x)\bigl(\log P(x) - \log Q(x)\bigr) \\[4mm]
&= -H(P) + H(P, Q)
\end{aligned}
5 最適化理論
5-1 最適化問題
■ 制約付き最適化問題
\begin{aligned}
&\min_{x \in \mathbb{R}^n} \; f(x) \\[4mm]
&\text{subject to} \quad g_i(x) \leq 0, \quad i = 1,\ldots,m \\[4mm]
&\phantom{\text{subject to}} \quad h_j(x) = 0, \quad j = 1,\ldots,p
\end{aligned}
■ 最適化問題の種類
-
線形計画法
- 双対法:主問題と双対問題を扱う理論
- 内点法:凸集合内部を通る経路で最適解を探すアルゴリズム
-
非線形計画法
- ラグランジュ法:ラグランジュ乗数で制約を目的関数へ組み込む
- KKT条件:最適性の必要十分条件(主に凸問題で)
- 数値的最適化:勾配法・ニュートン法・座標降下法・遺伝的アルゴリズム等
-
凸最適化
- 双対法・内点法・KKT条件:凸問題に特有の理論とアルゴリズム
- 二次計画法(QP):目的関数が二次式・制約が線形の凸最適化の特殊ケース。SVMの双対問題がこれに該当
-
整数計画法
- 分枝限定法・カット平面法:離散空間の最適化アルゴリズム
-
動的計画法
- ベルマン方程式:価値関数を再帰的に記述し全体最適を達成
- 再帰的解析:時系列(段階)ごとに価値を伝播させて最適解へ
5-2 数値的最適化
■ アルゴリズムの種類
- 勾配降下法:関数の傾きを利用して目的値を少しずつ減らす手法
- ニュートン法:2階微分(ヘッセ行列)も用いて、より高速な収束を目指す手法
- 確率的勾配降下法(SGD):データからランダムに1つ選びながら都度パラメータを更新する手法
- ミニバッチ勾配降下法:データを小規模なグループ(ミニバッチ)ごとに使って更新する手法
\begin{aligned}
&\text{勾配降下法} &&\quad
w^{(j+1)} = w^{(j)} - \eta\left.\frac{dL}{dw}\right|_{w=w^{(j)}} \\[8mm]
&\text{ニュートン法(1変数)} &&\quad
w^{(j+1)} = w^{(j)} - \left[\left.\frac{d^2L}{dw^2}\right|_{w=w^{(j)}}\right]^{-1} \left.\frac{dL}{dw}\right|_{w=w^{(j)}} \\[8mm]
&\text{ニュートン法(多変数)} &&\quad
\mathbf{w}^{(j+1)} = \mathbf{w}^{(j)} - H^{-1}\nabla L(\mathbf{w}^{(j)}) \\[8mm]
&\text{確率的勾配降下法(SGD)} &&\quad
w^{(j+1)} = w^{(j)} - \eta\left.\frac{dL_i}{dw}\right|_{w=w^{(j)}} \\[8mm]
&\text{ミニバッチ勾配降下法} &&\quad
w^{(j+1)} = w^{(j)} - \eta\left.\frac{1}{|B|}\sum_{i \in B}\frac{dL_i}{dw}\right|_{w=w^{(j)}}
\end{aligned}
■ 最適化アルゴリズムの種類
- SGD ランダムに選んだ1サンプルごとにパラメータを更新する基本手法
- Momentum 勾配の流れを考慮し、収束を加速・安定させる手法
- AdaGrad パラメータごとに学習率を自動調整し、動きが激しい部分を抑制
- RMSprop 最近の勾配情報で学習率を動的調整し、AdaGradの欠点を解消
- Adam Momentum+RMSpropのハイブリッドで学習率や方向を自動調整する
\begin{array}{lll}
\text{SGD}
&\theta_{t+1} = \theta_t - \eta \dfrac{\partial L}{\partial \theta_t}\\[16mm]
\text{Momentum}
&v_{t+1} = \alpha v_t - \eta \dfrac{\partial L}{\partial \theta_t} \\[4mm]
&\theta_{t+1} = \theta_t + v_{t+1}\\[16mm]
\text{AdaGrad}
&h_{t+1} = h_t + \dfrac{\partial L}{\partial \theta_t} \odot \dfrac{\partial L}{\partial \theta_t}\\[4mm]
&\theta_{t+1} = \theta_t - \eta \dfrac{1}{\epsilon + \sqrt{h_{t+1}}} \odot \dfrac{\partial L}{\partial \theta_t}\\[16mm]
\text{RMSprop}
&h_{t+1} = \rho h_t + (1-\rho)\dfrac{\partial L}{\partial \theta_t} \odot \dfrac{\partial L}{\partial \theta_t}\\[4mm]
&\theta_{t+1} = \theta_t - \eta \dfrac{1}{\sqrt{h_{t+1} + \epsilon}} \odot \dfrac{\partial L}{\partial \theta_t}\\[16mm]
\text{Adam}
&m_{t+1} = \rho_1 m_t + (1-\rho_1) \dfrac{\partial L}{\partial \theta_t}\\[4mm]
&v_{t+1} = \rho_2 v_t + (1-\rho_2) \dfrac{\partial L}{\partial \theta_t} \odot \dfrac{\partial L}{\partial \theta_t}\\[4mm]
&\hat{m}_{t+1} = \dfrac{m_{t+1}}{1-\rho_1^t}\\[4mm]
&\hat{v}_{t+1} = \dfrac{v_{t+1}}{1-\rho_2^t}\\[4mm]
&\theta_{t+1} = \theta_t - \eta \dfrac{1}{\sqrt{\hat{v}_{t+1}} + \epsilon} \odot \hat{m}_{t+1}
\end{array}
5-3 凸最適化
■ 計算フロー
- 主問題:凸関数+正則性条件のもとで制約付き最適化問題を定式化
- ラグランジュ関数:ラグランジュ未定乗数法で制約を目的関数へ組み込む
- 双対関数:ラグランジュ関数を $x$ について極小化(inf)
- 双対問題:双対関数をラグランジュ乗数 $\lambda,\nu$ で極大化(max)
- KKT条件:KKT条件を満たす点が主問題の最適解に一致する(強双対性が成立する場合の必要十分条件)
- 最適解:双対問題とKKT条件から $x, \lambda, \nu$ を求める
\begin{aligned}
&\text{主問題}
&&\min_{x \in \mathbb{R}^n} \; f(x) \\[4mm]
&&&\text{subject to} \quad g_i(x) \leq 0, \quad i=1,\ldots,m \\[4mm]
&&&\phantom{\text{subject to}} \quad h_j(x) = 0, \quad j=1,\ldots,p \\[8mm]
&\text{ラグランジュ関数}
&&\mathcal{L}(x, \lambda, \nu)
= f(x)
+ \sum_{i=1}^m \lambda_i g_i(x)
+ \sum_{j=1}^p \nu_j h_j(x) \\[8mm]
&\text{双対関数}
&&d(\lambda, \nu) = \inf_{x \in \mathbb{R}^n} \mathcal{L}(x, \lambda, \nu) \\[8mm]
&\text{双対問題}
&&\max_{\lambda \geq 0,\, \nu}\; d(\lambda, \nu)
= \max_{\lambda \geq 0,\, \nu}\; \inf_{x \in \mathbb{R}^n} \mathcal{L}(x, \lambda, \nu) \\[8mm]
&\text{KKT条件}
&&\nabla_x f(x^*) + \sum_{i=1}^m \lambda_i^* \nabla_x g_i(x^*) + \sum_{j=1}^p \nu_j^* \nabla_x h_j(x^*) = 0 \\[4mm]
&&&g_i(x^*) \leq 0, \quad h_j(x^*) = 0 \\[4mm]
&&&\lambda_i^* \geq 0, \quad \lambda_i^* g_i(x^*) = 0 \quad \text{(相補スラック性)}
\end{aligned}
■ 【例】SVMにおける凸最適化
\begin{aligned}
&\text{主問題}
&&\min_{w,\, b,\, \xi^{(i)}} \quad \frac{1}{2}\|w\|^2 + C\sum_{i=1}^{M} \xi^{(i)} \\[4mm]
&&&\text{subject to} \quad y^{(i)}(x^{(i)\top} w + b) \geq 1 - \xi^{(i)}, \\[2mm]
&&&\phantom{\text{subject to}} \quad \xi^{(i)} \geq 0 \quad (i=1,2,\ldots,M) \\[8mm]
&\text{ラグランジュ関数}
&&\mathcal{L}(w, b, \xi, \alpha, \mu)
= \frac{1}{2}\|w\|^2 + C\sum_{i=1}^{M} \xi^{(i)} \\[2mm]
&&&\phantom{\mathcal{L}(w, b, \xi, \alpha, \mu)}
- \sum_{i=1}^{M} \alpha^{(i)}\bigl[y^{(i)}(x^{(i)\top} w + b) - 1 + \xi^{(i)}\bigr] \\[2mm]
&&&\phantom{\mathcal{L}(w, b, \xi, \alpha, \mu)}
- \sum_{i=1}^{M} \mu^{(i)} \xi^{(i)} \\[8mm]
&\text{双対問題}
&&\max_{\alpha} \left\{
\sum_{i=1}^{M} \alpha^{(i)}
- \frac{1}{2}\sum_{i=1}^{M}\sum_{j=1}^{M} \alpha^{(i)} \alpha^{(j)} y^{(i)} y^{(j)} (x^{(i)\top} x^{(j)})
\right\} \\[4mm]
&&&\text{subject to} \quad 0 \leq \alpha^{(i)} \leq C, \quad \sum_{i=1}^{M} \alpha^{(i)} y^{(i)} = 0 \\[8mm]
&\text{KKT条件}
&&\frac{\partial \mathcal{L}}{\partial w} = 0 \quad\Rightarrow\quad w = \sum_{i=1}^{M} \alpha^{(i)} y^{(i)} x^{(i)} \\[4mm]
&&&\frac{\partial \mathcal{L}}{\partial b} = 0 \quad\Rightarrow\quad \sum_{i=1}^{M} \alpha^{(i)} y^{(i)} = 0 \\[4mm]
&&&\frac{\partial \mathcal{L}}{\partial \xi^{(i)}} = 0 \quad\Rightarrow\quad \alpha^{(i)} + \mu^{(i)} = C \\[4mm]
&&&\alpha^{(i)} \geq 0, \quad \mu^{(i)} \geq 0, \quad \xi^{(i)} \geq 0 \\[4mm]
&&&\alpha^{(i)}\bigl[y^{(i)}(x^{(i)\top} w + b) - 1 + \xi^{(i)}\bigr] = 0 \\[4mm]
&&&\mu^{(i)} \xi^{(i)} = 0 \\[4mm]
&&&y^{(i)}(x^{(i)\top} w + b) - 1 + \xi^{(i)} \geq 0
\end{aligned}
5-4 動的計画法
\begin{aligned}
&\text{ベルマン方程式} &&\quad
V(x) = \min_{u \in \mathcal{U}} \left\{ c(x, u) + V(T(x, u)) \right\} \\[8mm]
&\text{再帰的解析} &&\quad
V_t(x) = \min_{u \in \mathcal{U}} \left\{ c_t(x, u) + V_{t+1}(T(x, u)) \right\}
\end{aligned}
- $x$:状態
- $u$:行動
- $T(x, u)$:状態遷移関数
- $V(x)$:状態 $x$ の価値(時刻非依存/定常型)
- $V_t(x)$:時刻 $t$ での状態 $x$ の価値(時刻依存/有限ホライズン型)
6 パラメータ推定
■ パラメータ推定の種類
- 最尤推定(MLE):尤度 $\mathcal{L}_{\mathbf{x}}(\boldsymbol{\theta})$ を最大にするパラメータ $\boldsymbol{\theta}$ を求める。正則化なし・事前分布なし。
- 最大事後確率推定(MAP):事後確率 $p(\boldsymbol{\theta} \mid \mathbf{x})$ を最大にするパラメータ $\boldsymbol{\theta}$ を求める。事前分布=正則化に相当。
- ベイズ推定:パラメータ $\boldsymbol{\theta}$ の事後分布 $p(\boldsymbol{\theta} \mid \mathbf{x})$ 全体を求める。不確かさも含めて推論する。
■ 最尤推定(MLE)
\begin{aligned}
&\text{尤度} &&\quad
\mathcal{L}_{\mathbf{x}}(\boldsymbol{\theta}) = \prod_{i=1}^N f(x_i \mid \boldsymbol{\theta}) \\[8mm]
&\text{最大値推定} &&\quad
\hat{\boldsymbol{\theta}}_{\mathrm{MLE}}
= \mathop{\mathrm{argmax}}_{\boldsymbol{\theta}}\; \prod_{i=1}^N f(x_i \mid \boldsymbol{\theta}) \\[8mm]
&\text{対数化} &&\quad
\hat{\boldsymbol{\theta}}_{\mathrm{MLE}}
= \mathop{\mathrm{argmax}}_{\boldsymbol{\theta}}\; \sum_{i=1}^N \log f(x_i \mid \boldsymbol{\theta}) \\[8mm]
&\text{最適化問題} &&\quad
\hat{\boldsymbol{\theta}}_{\mathrm{MLE}}
= \mathop{\mathrm{argmin}}_{\boldsymbol{\theta}} \left\{ -\sum_{i=1}^N \log f(x_i \mid \boldsymbol{\theta}) \right\}
\end{aligned}
■ 最大事後確率推定(MAP)
- 分母 $p(\mathbf{x})$ は $\boldsymbol{\theta}$ に依存しないため最大化に影響しない(省略可能)。
- 対数化により、MLE の損失関数+事前分布の対数項=正則化付き損失関数に対応する。
- 事前分布が一様分布の場合、MAP=MLE。
\begin{aligned}
&\text{事後確率} &&\quad
p(\boldsymbol{\theta} \mid \mathbf{x})
= \frac{p(\mathbf{x} \mid \boldsymbol{\theta})\,p(\boldsymbol{\theta})}{p(\mathbf{x})} \\[8mm]
&\text{最大値推定} &&\quad
\hat{\boldsymbol{\theta}}_{\mathrm{MAP}}
\propto \mathop{\mathrm{argmax}}_{\boldsymbol{\theta}}\; p(\mathbf{x} \mid \boldsymbol{\theta})\,p(\boldsymbol{\theta}) \\[8mm]
&\text{対数化} &&\quad
\hat{\boldsymbol{\theta}}_{\mathrm{MAP}}
= \mathop{\mathrm{argmax}}_{\boldsymbol{\theta}}\left\{ \log p(\mathbf{x} \mid \boldsymbol{\theta}) + \log p(\boldsymbol{\theta}) \right\} \\[8mm]
&\text{最適化問題} &&\quad
\hat{\boldsymbol{\theta}}_{\mathrm{MAP}}
= \mathop{\mathrm{argmin}}_{\boldsymbol{\theta}}\left\{ -\log p(\mathbf{x} \mid \boldsymbol{\theta}) - \log p(\boldsymbol{\theta}) \right\}
\end{aligned}
■ ベイズ推定
\begin{aligned}
&\text{事後確率} &&\quad
p(\boldsymbol{\theta} \mid \mathbf{x})
= \frac{p(\mathbf{x} \mid \boldsymbol{\theta})\,p(\boldsymbol{\theta})}{p(\mathbf{x})} \\[8mm]
&\text{分布推定} &&\quad
\text{事後分布 } p(\boldsymbol{\theta} \mid \mathbf{x}) \text{ そのものを利用する} \\[8mm]
&\text{対数化} &&\quad
\log p(\boldsymbol{\theta} \mid \mathbf{x})
= \log p(\mathbf{x} \mid \boldsymbol{\theta}) + \log p(\boldsymbol{\theta}) - \log p(\mathbf{x}) \\[8mm]
&\text{例:期待値評価} &&\quad
\mathbb{E}[\boldsymbol{\theta} \mid \mathbf{x}]
= \int \boldsymbol{\theta}\; p(\boldsymbol{\theta} \mid \mathbf{x})\; d\boldsymbol{\theta}
\end{aligned}
■ 線形回帰におけるMLE
連続値予測($y \in \mathbb{R}$)において誤差が正規分布 $\mathcal{N}(0, \sigma^2)$ に従うと仮定し、パラメータ $\theta$ を最尤推定する。
\begin{aligned}
&\text{推論} &&\quad \hat{y} = \theta^\top x \\[8mm]
&\text{損失関数} &&\quad \mathcal{L}(\theta) = \frac{1}{2} \| y - X\theta \|^2 \\[8mm]
&\text{勾配} &&\quad \frac{\partial \mathcal{L}}{\partial \theta} = X^\top X\theta - X^\top y \\[8mm]
&\text{正規方程式} &&\quad X^\top X\,\theta = X^\top y \quad\Longrightarrow\quad \hat{\theta} = (X^\top X)^{-1} X^\top y
\end{aligned}
■ ロジスティック回帰におけるMLE
二値分類($y \in {0, 1}$)において、パラメータ $\theta$ を最尤推定する。シグモイド関数 $\sigma$ を用いてクラス確率をモデル化し、ベルヌーイ分布として尤度を構成する。
\begin{aligned}
&\text{推論} &&\quad \hat{p} = \sigma(\theta^\top x) = \frac{1}{1 + \exp(-\theta^\top x)} \\[8mm]
&\text{損失関数} &&\quad
\mathcal{L}(\theta) = -\sum_{i=1}^{M}
\left[ y^{(i)} \log \hat{p}^{(i)} + (1 - y^{(i)}) \log(1 - \hat{p}^{(i)}) \right] \\[8mm]
&\text{勾配} &&\quad \frac{\partial \mathcal{L}}{\partial \theta} = X^\top (\hat{p} - y) \\[8mm]
&\text{更新式} &&\quad \theta \leftarrow \theta - \eta\, X^\top (\hat{p} - y)
\end{aligned}
■ ニューラルネットワークにおけるMLE(回帰)
連続値予測($y \in \mathbb{R}$)において誤差が正規分布 $\mathcal{N}(0, \sigma^2)$ に従うと仮定し、パラメータ $\theta$ を最尤推定する。
\begin{aligned}
&\text{推論} &&\quad \hat{y} = f_\theta(x) \\[8mm]
&\text{損失関数} &&\quad \mathcal{L}(\theta) = \frac{1}{2} \| y - \hat{y} \|^2 \\[8mm]
&\text{勾配} &&\quad
\frac{\partial \mathcal{L}}{\partial \theta}
= -(\hat{y} - y)^\top \frac{\partial \hat{y}}{\partial \theta} \\[8mm]
&\text{更新式} &&\quad \theta \leftarrow \theta - \eta\,\frac{\partial \mathcal{L}}{\partial \theta}
\end{aligned}
- $f_\theta$ は多層ニューラルネットワークによる非線形写像。
- 線形回帰との違いは $f_\theta$ の非線形性のみであり、損失関数の形(MSE)は同一。
■ ニューラルネットワークにおけるMLE(分類)
多クラス分類($y \in {1, \ldots, K}$)において、パラメータ $\theta$ を最尤推定する。ソフトマックス関数を用いてクラス確率をモデル化し、カテゴリカル分布として尤度を構成する。
\begin{aligned}
&\text{順伝播} &&\quad
z^{(l)} = W^{(l)} a^{(l-1)} + b^{(l)}, \quad a^{(l)} = f(z^{(l)}) \\[8mm]
&\text{確率変換} &&\quad
\hat{p}_k = \frac{\exp(z^{(L)}_k)}{\sum_{j=1}^{K} \exp(z^{(L)}_j)} \\[8mm]
&\text{損失関数} &&\quad L = -\log \hat{p}_y \\[8mm]
&\text{勾配} &&\quad \frac{\partial L}{\partial z} = \hat{p} - y \\[8mm]
&\text{更新式} &&\quad W^{(l)} \leftarrow W^{(l)} - \eta\,\frac{\partial L}{\partial W^{(l)}}
\end{aligned}
- $y$ は正解クラスに対応する one-hot ベクトル(正解クラスのみ1、それ以外は0)。
- 勾配 $\hat{p} - y$ は予測確率と正解ラベルの残差という直感的な形になる。
- 損失関数は交差エントロピー損失であり、ロジスティック回帰($K=2$)の場合と一致する。
■ 【例】ナイーブベイズにおけるMAP
クラスの事後確率 $P(C_k \mid x_1, \ldots, x_N)$ が最大のクラス $C_k$ を予測ラベル $\hat{C}$ とする。特徴 $x_n$ 同士が条件付き独立と仮定することで計算を単純化する(「ナイーブ」の由来)。
\begin{aligned}
&\text{事後確率} &&\quad
P(C_k \mid x_1,\ldots,x_N)
= \frac{P(C_k)\,P(x_1,\ldots,x_N \mid C_k)}{P(x_1,\ldots,x_N)} \\[8mm]
&\text{条件独立性仮定} &&\quad
P(C_k \mid x_1,\ldots,x_N)
\propto P(C_k)\prod_{n=1}^N P(x_n \mid C_k) \\[8mm]
&\text{対数化} &&\quad
\log P(C_k \mid x_1,\ldots,x_N)
\propto \log P(C_k) + \sum_{n=1}^N \log P(x_n \mid C_k) \\[8mm]
&\text{最適化問題} &&\quad
\hat{C} = \mathop{\mathrm{argmax}}_{k \in \{1,\ldots,K\}}
\left( P(C_k)\prod_{n=1}^N P(x_n \mid C_k) \right)
\end{aligned}
- $(x_1, \ldots, x_N)$:$N$ 個の入力特徴
- $C_k$:予測するクラス($k \in {1,\ldots,K}$)
■ 生成モデルにおけるベイズ推定
クラスの事後確率をベイズの定理で分解し、$P(x \mid \mathcal{C})$ と $P(\mathcal{C})$ をそれぞれモデリングするか、同時確率 $P(x, \mathcal{C})$ を直接モデリングすることで $\mathop{\mathrm{argmax}}_{\mathcal{C}} P(\mathcal{C} \mid x)$ を解くアプローチ。
P(\mathcal{C} \mid x)
= \frac{P(x \mid \mathcal{C})\,P(\mathcal{C})}{P(x)}
= \frac{P(x,\mathcal{C})}{P(x)}
生成モデルに基づくアプローチで得たモデルを用いて
P(x) = \sum_{\mathcal{C}} P(x \mid \mathcal{C})\,P(\mathcal{C})
と周辺化することで、入力 $x$ が従う分布 $P(x)$ を求めることが可能である。そのため、予測のみならず欠損値の補完やデータ拡張への応用が期待できる。
連続の場合、規格化定数 $P(x)$ は積分によって算出できるが、一般に解析的に計算することができないため、マルコフ連鎖モンテカルロ法(MCMC)や変分推論等によって近似する。
P(x) = \int P(x \mid \mathcal{C})\,P(\mathcal{C})\; d\mathcal{C}
7 評価指標
7-1 オッズ比
■ オッズ比
- ある特徴量が1単位増加したとき、事象が発生するオッズ(確率の比)がどれだけ変わるかを表す。
- ロジスティック回帰における確率をオッズに変換することで、回帰係数を解釈できる。
\mathrm{Odds} = \frac{p}{1-p}, \qquad 0 < \mathrm{Odds} < \infty, \qquad
\frac{p}{1-p} = \exp(\mathbf{w}^\top \mathbf{x})
■ ロジット関数
- オッズ($0 < \mathrm{Odds} < \infty$)を対数化したもの。
- 対数化により $-\infty < \mathrm{Logit} < \infty$ となり、線形回帰と同じ形で扱える。
- $\mathbf{x}^\top \mathbf{w}$ が1単位増えるとオッズは $e \approx 2.718$ 倍になる。
- 回帰係数の $\exp$ がオッズ比に一致する。
\mathrm{Logit}(p) = \log \frac{p}{1-p}, \qquad -\infty < \mathrm{Logit} < \infty, \qquad
\log \frac{p}{1-p} = \mathbf{x}^\top \mathbf{w}
■ ロジスティック関数(シグモイド関数)
- ロジット関数の逆関数。
- 任意の実数値を $0$ ~ $1$ の確率に変換する。
\mathrm{Logistic}(x) = \frac{1}{1+e^{-x}}, \qquad 0 < \mathrm{Logistic} < 1, \qquad
p = \frac{1}{1 + \exp(-\mathbf{x}^\top \mathbf{w})}
■ オッズ比の導出
\begin{aligned}
o &= \frac{P(y=1 \mid \mathbf{x})}{P(y=0 \mid \mathbf{x})}
= \frac{\hat{y}}{1-\hat{y}}
= \frac{\sigma(\mathbf{w}^\top \mathbf{x})}{1 - \sigma(\mathbf{w}^\top \mathbf{x})}
= \frac{(1 + e^{-\mathbf{w}^\top \mathbf{x}})^{-1}}{1 - (1 + e^{-\mathbf{w}^\top \mathbf{x}})^{-1}}
= \frac{1}{e^{-\mathbf{w}^\top \mathbf{x}}}
= e^{\mathbf{w}^\top \mathbf{x}}
\end{aligned}
7-2 損失関数
■ 損失関数の種類
- MAE:実値と予測値の絶対誤差の平均。外れ値に頑健
- MSE:実値と予測値の二乗誤差の平均。大きい誤差を強調
- RMSE:MSEの平方根。誤差を元の単位で解釈できる
- Huber損失:小さい誤差にはMSE、大きい誤差にはMAE的な挙動をする。外れ値に頑健で微分可能
- Smooth L1:Huber損失の $\delta=1$ 版。物体検出(SSD など)でよく使われる
\begin{aligned}
&\mathrm{MAE} = \frac{1}{N}\sum_{i=1}^{N} |y_i - \hat{y}_i| \\[8mm]
&\mathrm{MSE} = \frac{1}{N}\sum_{i=1}^{N} (y_i - \hat{y}_i)^2 \\[8mm]
&\mathrm{RMSE} = \sqrt{\frac{1}{N}\sum_{i=1}^{N}(y_i - \hat{y}_i)^2} \\[8mm]
&\mathrm{Huber}(x) =
\begin{cases}
\dfrac{1}{2}\,x^2 & (|x| < \delta) \\[4mm]
\delta\!\left(|x| - \dfrac{1}{2}\delta\right) & (|x| \geq \delta)
\end{cases} \\[8mm]
&L_1^{\mathrm{smooth}}(x) =
\begin{cases}
\dfrac{1}{2}\,x^2 & (|x| < 1) \\[4mm]
|x| - \dfrac{1}{2} & (|x| \geq 1)
\end{cases}
\end{aligned}
7-3 情報量基準
■ 情報量基準の種類
- AIC:モデル選択向け。予測精度+複雑さのペナルティ(パラメータ数 $k$ に比例)
- BIC:真のモデル特定向け。AICよりデータ数 $n$ に応じてペナルティが大きくなる
- DIC:ベイズ推定との組み合わせに適した指標。MCMCが必要
- WAIC:ベイズの新定番。未来データ予測精度を重視し、特異モデルにも適用可能
\begin{aligned}
&\mathrm{AIC} = -2\log L + 2k \\[8mm]
&\mathrm{BIC} = -2\log L + k\log n \\[8mm]
&\mathrm{DIC} = -2\log p(y \mid \hat{\theta}) + 2p_D \\[8mm]
&\mathrm{WAIC} = -2\sum_{i=1}^{n}\log \mathbb{E}[p(y_i \mid \theta)] + 2\mathbb{V}[\log p(y \mid \theta)]
\end{aligned}
7-4 分類評価指標
■ 混同行列
| 実際ポジティブ(P) | 実際ネガティブ(N) | |
|---|---|---|
| 予測ポジティブ(P) | TP(真陽性) | FP(偽陽性) |
| 予測ネガティブ(N) | FN(偽陰性) | TN(真陰性) |
■ 指標の種類
- Accuracy(正解率):全体のうち正しく分類された割合
- Precision(適合率):ポジティブと予測したもののうち、実際にポジティブだった割合
- Recall(再現率・TPR):実際にポジティブだったもののうち、正しくポジティブと予測した割合
- FPR(偽陽性率):実際にネガティブだったもののうち、誤ってポジティブと予測した割合
- F1-score:PrecisionとRecallの調和平均。両者のバランスを評価する
\begin{aligned}
&\text{Accuracy} &&\quad \frac{TP + TN}{TP + TN + FP + FN} \\[8mm]
&\text{Precision} &&\quad \frac{TP}{TP + FP} \\[8mm]
&\text{Recall (TPR)} &&\quad \frac{TP}{TP + FN} \\[8mm]
&\text{FPR} &&\quad \frac{FP}{FP + TN} \\[8mm]
&\text{F1-score} &&\quad \frac{2TP}{2TP + FP + FN}
\end{aligned}
■ 【例】迷惑メール判定の混同行列
| 迷惑なメールだった(P) | 普通のメールだった(N) | |
|---|---|---|
| 迷惑メールに分類(P) | 的中(TP) | 誤認(FP) |
| 普通メールに分類(N) | 見逃し(FN) | 的中(TN) |
7-5 ROC曲線・PR曲線
- ROC曲線:真陽性率(TPR)と偽陽性率(FPR)の関係を描画。クラス不均衡の影響を受けにくく、モデルの総合的な識別力を評価する。
- PR曲線:Precision と Recall の関係を描画。正例が少ない不均衡データや異常検知に適した評価手法。
■ 【例】迷惑メール判定におけるROC曲線・PR曲線描画
- 予測モデルが迷惑メールと判定する際のスコア順に並べる
- 各しきい値で「迷惑メール=1」「普通メール=0」に分類する
- しきい値ごとに TPR・FPR・Precision・Recall を計算する
| ランキング | 実際のメール | FPR | TPR=Recall | Precision |
|---|---|---|---|---|
| 1 | 1 | 0.000 | 0.333 | 1.000 |
| 2 | 0 | 0.250 | 0.333 | 0.500 |
| 3 | 1 | 0.250 | 0.666 | 0.666 |
| 4 | 1 | 0.250 | 1.000 | 0.750 |
| 5 | 0 | 0.250 | 1.000 | 0.600 |
| 6 | 0 | 0.250 | 1.000 | 0.500 |
| 7 | 0 | 0.250 | 1.000 | 0.286 |


7-6 物体検出指標
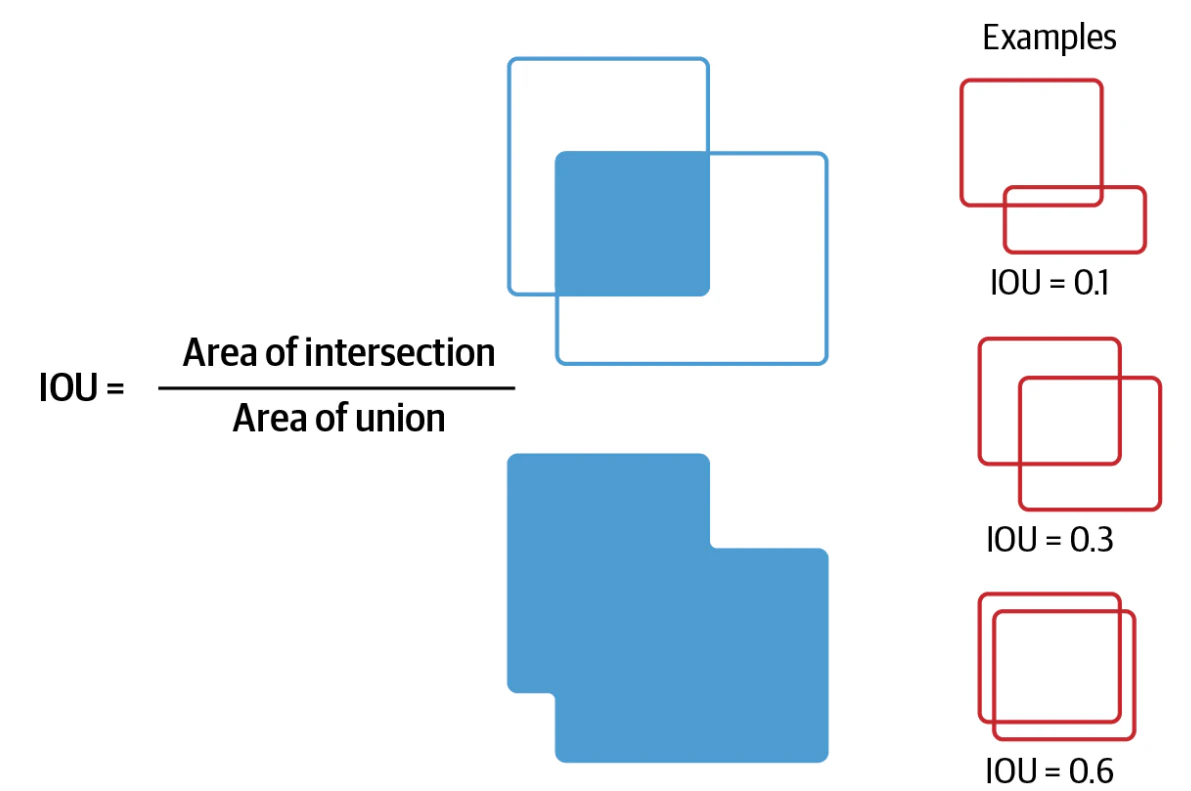
■ 指標の種類
- Jaccard係数(IoU):予測と正解の重なりを「全体の和集合」で割る。物体検出の基本指標
- Dice係数:重なりを「両集合の合計」で割る。医療画像セグメンテーションでよく使われる
- Simpson係数:重なりを「小さいほうの集合のサイズ」で割る。完全包含時に1になる
- AP(Average Precision):PR曲線の下側の面積。異なるしきい値でのPrecision/Recallを統合評価する
- mAP(mean Average Precision):各クラスのAPを平均。モデルの総合的な検出性能の指標
\begin{aligned}
&\text{Jaccard係数(IoU)} &&\quad
\frac{TP}{TP + FP + FN}
= \frac{|S_{\mathrm{true}} \cap S_{\mathrm{pred}}|}{|S_{\mathrm{true}} \cup S_{\mathrm{pred}}|} \\[8mm]
&\text{Dice係数} &&\quad
\frac{2TP}{2TP + FP + FN}
= \frac{2|S_{\mathrm{true}} \cap S_{\mathrm{pred}}|}{|S_{\mathrm{true}}| + |S_{\mathrm{pred}}|} \\[8mm]
&\text{Simpson係数} &&\quad
\frac{|S_{\mathrm{true}} \cap S_{\mathrm{pred}}|}{\min(|S_{\mathrm{true}}|,\, |S_{\mathrm{pred}}|)} \\[8mm]
&\text{AP} &&\quad
\mathrm{AP} = \int_0^1 p(r)\, dr
\end{aligned}
■ 【例】オブジェクト検出における混同行列と評価
| IoU ≥ 0.5(P) | IoU < 0.5(N) | |
|---|---|---|
| Predicted BBoxに対してGround-truth BBoxが(P) | 十分に重なっている(TP) | 重ならなかった Prediction BBoxの数(FP) |
| Ground-truth BBoxに対してPredicted BBoxが(N) | 該当なし | 重ならなかった GT BBoxの数(TN) |
■ 【例】オブジェクト検出におけるPR曲線の作成
- 予測モデルが物体検出する際のスコア順に並べる
- 各しきい値で検出できたかどうか(True or False)を分類する
- しきい値ごとに Recall・Precision を計算する
| Sorted Number | Confidence Score (%) | Correct? | Recall | Precision |
|---|---|---|---|---|
| #1 | 96 | True | 1/5 = 0.200 | 1/1 = 1.000 |
| #2 | 92 | True | 2/5 = 0.400 | 2/2 = 1.000 |
| #3 | 89 | False | 2/5 = 0.400 | 2/3 = 0.667 |
| #4 | 88 | False | 2/5 = 0.400 | 2/4 = 0.500 |
| #5 | 84 | False | 2/5 = 0.400 | 2/5 = 0.400 |
| #6 | 83 | True | 3/5 = 0.600 | 3/6 = 0.500 |
| #7 | 80 | True | 4/5 = 0.800 | 4/7 = 0.571 |
| #8 | 78 | False | 4/5 = 0.800 | 4/8 = 0.500 |
| #9 | 74 | False | 4/5 = 0.800 | 4/9 = 0.444 |
| #10 | 72 | True | 5/5 = 1.000 | 5/10 = 0.500 |
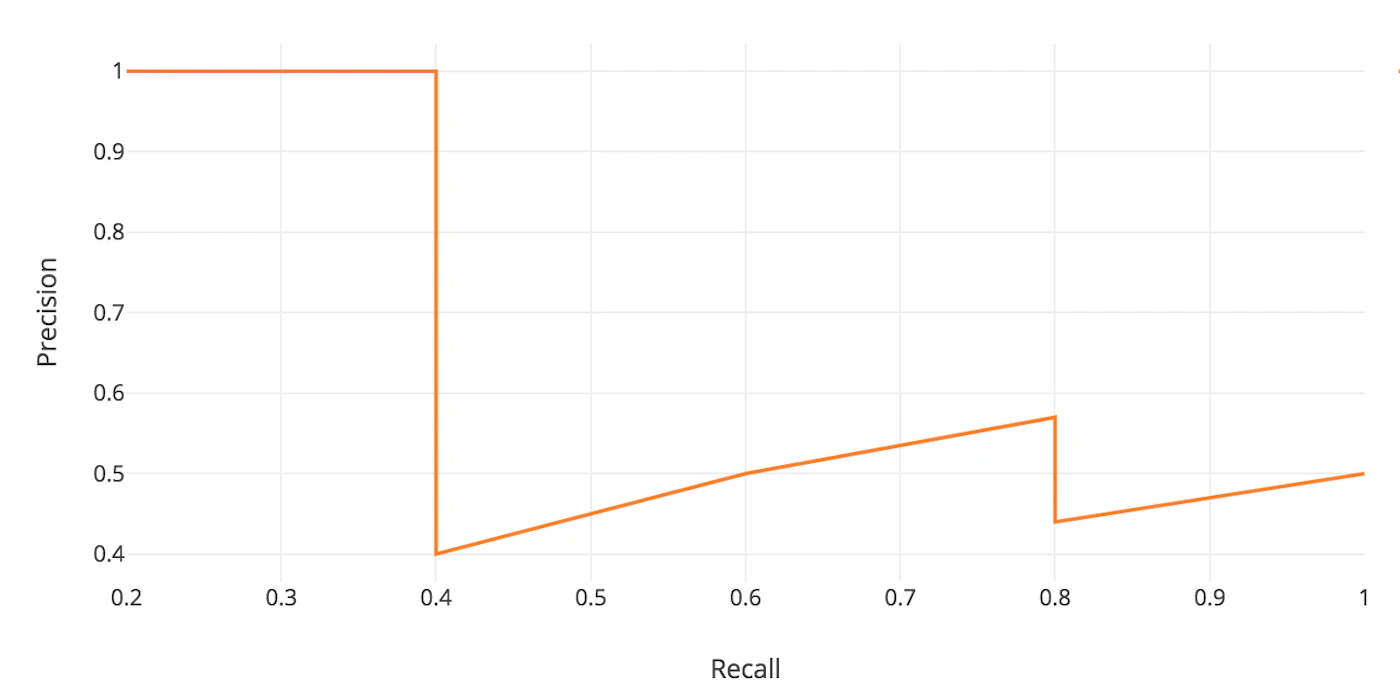
■ 【例】APを計算
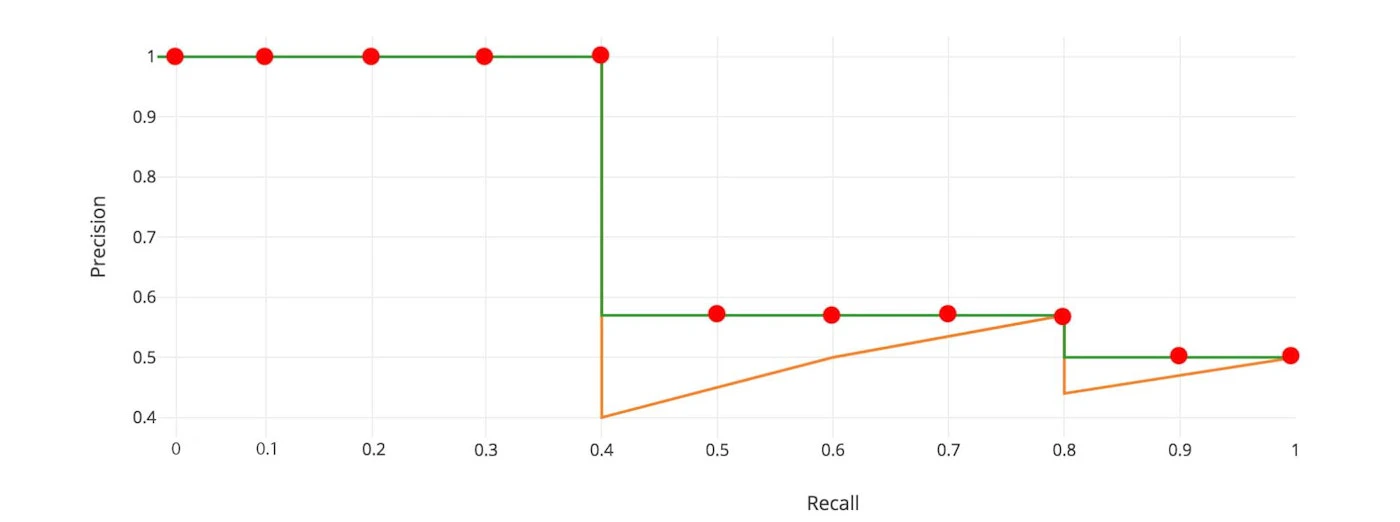
\begin{aligned}
\mathrm{AP}
&= \int_0^1 p(r)\, dr \\[4mm]
&= \frac{1}{11}\bigl(p(0) + p(0.1) + \cdots + p(1.0)\bigr) \\[4mm]
&= \frac{1}{11}(1.0 \times 5 + 0.571 \times 4 + 0.5 \times 2)
= \frac{1}{11} \times 8.284
= 0.753
\end{aligned}
■ 【例】mAPを計算
\begin{aligned}
&\mathrm{AP}_{\text{StopSign}} = 0.753, \quad
\mathrm{AP}_{\text{TrafficLight}} = 0.990, \quad
\mathrm{AP}_{\text{Car}} = 0.683 \qquad \text{のとき} \\[4mm]
&\mathrm{mAP} = \frac{1}{3}(0.753 + 0.990 + 0.683) = 0.809
\end{aligned}
7-7 生成評価指標
■ 生成評価指標の種類
| 指標 | 何を測るか | ベース |
|---|---|---|
| コサイン類似度 | 2つのベクトルの方向の近さ | 内積・L2ノルム |
| Perplexity | 次の単語の予測しにくさ | 確率(対数尤度) |
| BLEU | 生成文と参照文の n-gram 一致率 | Precision(適合率) |
| ROUGE | 参照文の n-gram がどれだけ生成文に含まれるか | Recall(再現率) |
| METEOR | 単語一致+語順・類義語・語幹を考慮した F 値 | F値(Recall重視) |
使い分けのポイント
- テキスト・画像の埋め込みベクトル同士の意味的な近さを測りたい → コサイン類似度
- 言語モデル自体の良し悪しを測りたい → Perplexity
- 翻訳の精度を手軽に測りたい → BLEU(業界標準。ただし語順・類義語は考慮しない)
- 語順のズレや類義語の置き換えも評価したい → METEOR
- 要約の網羅性(大事な内容をどれだけカバーしているか)を測りたい → ROUGE
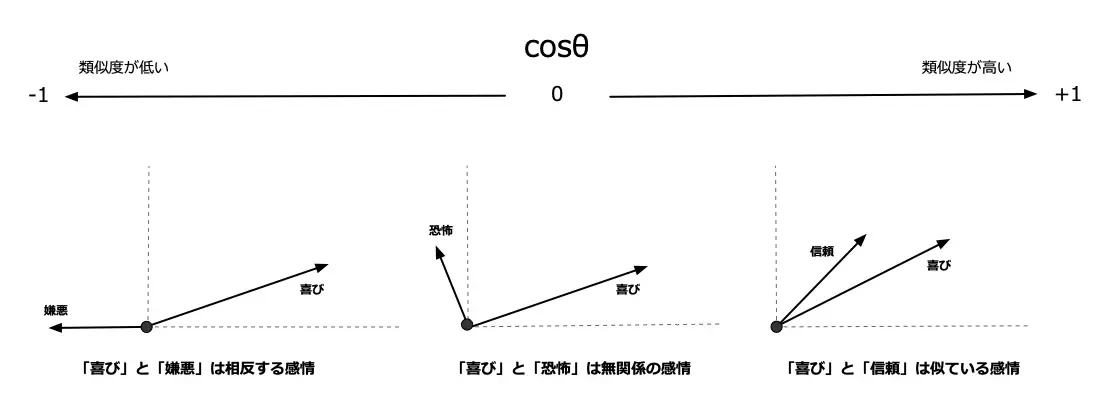
■ コサイン類似度
- ベクトルの大きさではなく方向の近さを $-1$〜$1$ で表す。
- テキストや画像の埋め込みベクトル同士の類似度計算に広く使われる。
\cos\theta
= \frac{\mathbf{x} \cdot \mathbf{y}}{\|\mathbf{x}\|\,\|\mathbf{y}\|}
= \frac{\sum_{i=1}^n x_i y_i}
{\sqrt{\sum_{i=1}^n x_i^2}\;\sqrt{\sum_{i=1}^n y_i^2}}
■ Perplexity(パープレキシティ)
モデルがテスト文 $y_1, y_2, \ldots, y_N$ の各単語を「どれだけ驚かずに予測できるか」を表す。対数尤度の平均(=クロスエントロピー)を指数化したもの。
\mathrm{Perplexity}
= \exp\!\left(-\frac{1}{N}\sum_{n=1}^{N}\log p_{\mathrm{model}}(y_n)\right)
■ BLEU(ブルー)
- BiLingual Evaluation Understudy。
- 生成文が参照文の n-gram をどれだけ含んでいるか(Precision ベース)を測る。
- 短すぎる生成文への不当な高評価を防ぐため、Brevity Penalty(BP)をかける。
- 右の項は 1-gram〜N-gram の精度($p_1, p_2, \ldots, p_N$)の幾何平均。短い文の場合に高 Precision となるのを左の BP が抑制する。
\mathrm{BLEU}
= \underbrace{\min\!\left(1,\,\exp\!\left(1-\frac{r}{c}\right)\right)}_{\text{Brevity Penalty(BP)}}
\times
\underbrace{\left(\prod_{n=1}^{N} p_n\right)^{1/N}}_{\text{n-gram 精度の幾何平均}}
\mathrm{BP} =
\begin{cases}
1 & (c > r \text{:生成文が参照文より長い場合、ペナルティなし}) \\[2mm]
\exp\!\left(1-\dfrac{r}{c}\right) & (c \leq r \text{:生成文が短いほど BP が小さくなる})
\end{cases}
- $c$:生成文の長さ(candidate)
- $r$:参照文の長さ(reference)
- $p_n$:n-gram 精度(生成文中で参照文と一致した n-gram の割合)
- $N$:最大 n-gram 長(通常 $N=4$)
■ ROUGE(ルージュ)
- Recall-Oriented Understudy for Gisting Evaluation。
- 参照文の n-gram が生成文にどれだけ含まれるか(Recall ベース)を測る。
- BLEU が「生成文の精度」を測るのに対し、ROUGE は「参照文の内容をどれだけカバーしているか」を重視する。
\mathrm{ROUGE\text{-}N}
= \frac{\text{生成文と参照文で一致した n-gram 数}}{\text{参照文中の n-gram 総数}}
= \frac{\sum_{\text{n-gram} \in \text{共通}} \mathrm{Count}_{\mathrm{match}}}
{\sum_{\text{n-gram} \in \text{reference}} \mathrm{Count}_{\mathrm{ref}}}
\mathrm{ROUGE\text{-}L}
= \frac{\text{最長共通部分列(LCS)の長さ}}{\text{参照文の長さ}}
ROUGE-N vs ROUGE-L:ROUGE-N は連続した n-gram の一致を数える。ROUGE-L は順序を保ちつつ連続していなくてもよい最長共通部分列(LCS)で一致を測るため、語順のズレに対して柔軟。
■ METEOR(ミーティア)
- Metric for Evaluation of Translation with Explicit Ordering.
- BLEU が見落としがちな**語順・類義語・ステミング(語幹一致)**を考慮した F 値ベースの指標。
- Recall を Precision より重視した調和平均($F_{\mathrm{mean}}$)から語順ペナルティを引く形をとる。
F_{\mathrm{mean}} = \frac{10 \cdot P \cdot R}{9 \cdot P + R}
\qquad \text{(Recall を Precision の約10倍重視した調和平均)}
\mathrm{METEOR} = F_{\mathrm{mean}} \cdot (1 - \mathrm{Penalty})
- $P$:Precision(生成文中で参照文と一致した単語の割合)
- $R$:Recall(参照文中で生成文と一致した単語の割合)
- Penalty:語順の乱れ(連続する一致のかたまり=chunk が少ないほど大きくなる)に応じた減点。$0$〜$1$