サイトマップ
概要
データ
| 学習データ | 教師データ |
|---|---|
 |
 |
| 256256321 (縦横*奥) | 256256321 (縦横*奥) |
| 外光ノイズ | 間延びノイズ |
|---|---|
 |
 |
今回扱うデータたちと、変形させたい要素一覧である。
**「外光ノイズ」と「間延びノイズ」**を取り除いて、教師データのような、まるでビーズが空中に浮いているかのようなオブジェクトを出力したい。
早い話、学習データを教師データにしたい。
3Dオブジェクトファイルのフォーマットはいろいろと種類があるようだが、それらを活用させる方法がわからないのでシンプルに3Dの行列、そこに1ch加えた4D行列で扱う(データは全てグレースケール)。
3Dファイルフォーマットの種類 - PukiWiki for PBCG Lab
http://www.slis.tsukuba.ac.jp/~fujisawa.makoto.fu/cgi-bin/wiki/index.php?3D%A5%D5%A5%A1%A5%A4%A5%EB%A5%D5%A5%A9%A1%BC%A5%DE%A5%C3%A5%C8%A4%CE%BC%EF%CE%E0
今回扱うデータを簡単に説明すると、教師データは空中に散布する発行体(とてもちいさなビーズ)で、それらをレンズ等を通して観測されたものが学習データである。
つまり、教師データは実際に観測されたものではなく、「学習データができればこう映っていてほしいよね」というノリで手作業で作成したものである。
そのため、下にも記述するが、極端にデータセット数が少ない。
根拠
なぜオートエンコーダーで可能だと考えるか。
そもそも、 この変形をオートエンコーダーですべきなのか、という問題がある。
opencvや、物体認識などのアルゴリズムを使えばいけるかもしれないが、あくまでかもしれないなので、とりあえず、3Dオートエンコーダーで試してみる。
あまりに結果が芳しくなければ、上記の方法を試していきたいと思う。
発光物体をレンズ等を通して観測すると、点広がり関数を通したようなものが観測される。
下の画像のObjectが実際の画像であるが、レンズを通して観測すると、ObjectにPSF(=点広がり関数)を畳み込みしたようなImageが観測される。
今回の目的は、ImageをObjectにすることである。どうやら、適切なフィルタを選択すれば、ImageからObjectへ逆畳み込みすることで復元が可能なようだ。
だとすれば、3Dオブジェクトであっても、ブレブレな学習データから、教師データへ逆畳み込みを行うことは可能なはず。
ただし、今回あつかう学習データは単純な点広がり関数で広がったものではない(詳細は省略)。
とはいえ、逆畳み込みを何度か行ったり、複数のフィルタを使って復元させることは不可能ではないだろう。
この過程はまさにオートエンコーダーではないか
点拡がり関数 https://ja.wikipedia.org/wiki/%E7%82%B9%E6%8B%A1%E3%81%8C%E3%82%8A%E9%96%A2%E6%95%B0 ブラインド デコンボリューション アルゴリズムを使用したイメージのブレ除去 https://jp.mathworks.com/help/images/deblurring-images-using-the-blind-deconvolution-algorithm.html?searchHighlight=PSF&s_tid=srchtitle
環境
デバイス
| 名前 | 性能 |
|---|---|
| CPU | Intel(R) Xeon(R) Bronze 3206R CPU @ 1.90GHz 1.90 GHz (2 プロセッサ) |
| GPU | NVIDIA GeForce RTX 2060 (6.0GB) |
| OS | Windows 10 |
| RAM | 32.0 GB |
2プロセッサあるらしい
機械学習での活用方法がわからぬ(救援求ム)。
バージョン(主なもの)
| 名前 | バージョン | 備考 |
|---|---|---|
| python | 3.6 | |
| tensorflow | 2.0.0 | |
| keras | 2.3.1 | |
| scipy | 1.5.2 | ファイルを.matファイル(Matlab)で保存しているので、その読み込み用 |
| opencv | 3.3.1 | 今回あまり使っていない。ゆくゆくは活用していきたい |
| 詳しくはこちら |
データセット
| 名前 | データ数 | 備考 |
|---|---|---|
| 学習データ | 4 | |
| 検証データ | 1 | |
| テストデータ | (5) | 学習データ・検証データを使いまわす |
| 少なすぎて困る。 | ||
| 過学習が懸念されるが、学習データは背景にのせたようなものばかりで、バリエーションが少ないので、今回の学習に限っては、過学習は存在しない。学習してくれたらそれだけ嬉しいのだ。 |
学習方法
あんまり本記事のような学習を行っている人は少ないらしく、文献が見当たらなかった。
近しいことをやってらっしゃる先駆者を載せておきます。
Vox2Vox: 3D-GAN for Brain Tumour Segmentation
https://arxiv.org/abs/2003.13653
ボクセルデータをつかって類似形状検索をやってみる
https://qiita.com/hiram/items/00212e75e94af3077200
3D-CNNを用いたAutoencoderによる動画像の再構成
https://qiita.com/satolab/items/09a90d4006f46e4e959b
モデル
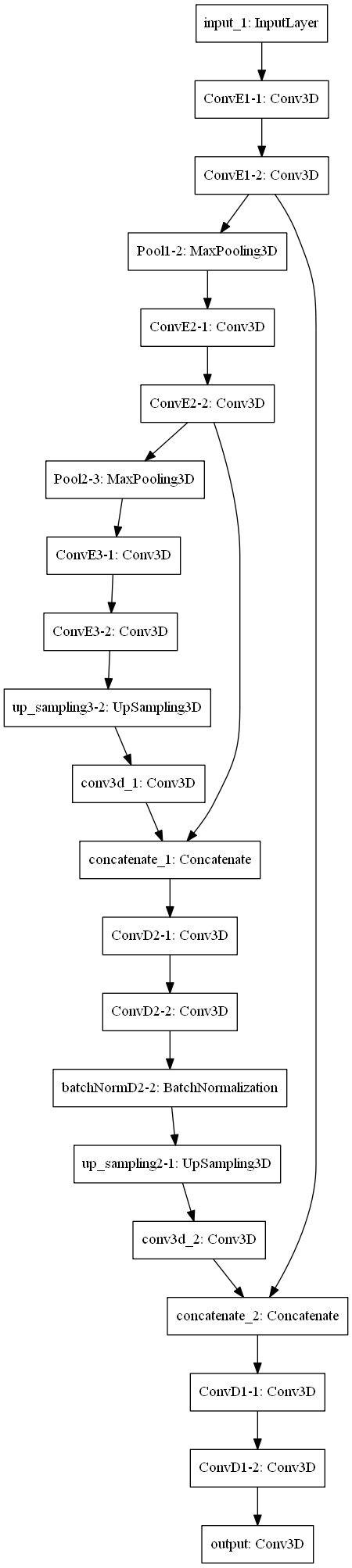
2つのモデルを作成し、微調整を行いながら検証した。主に以下の二つ
| U-Net ベース | シンプル CNN |
|---|---|
 |
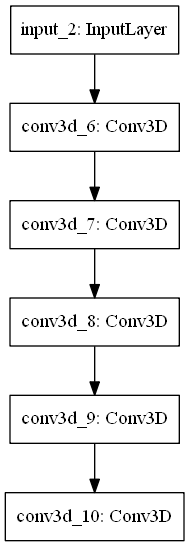 |
| U-Netをベースとしたモデル。本家は2Dデータに対するものだが、それを3D用に適用させた。本家は最上層が64ch、5層あるが、3Dでそれを行うとメモリが足りるわけもないので、最上層を8ch、3層で行った。 結果は芳しくなかった。 | シンプルなCNN。メモリが不足しがちなことから、試しにこちらのモデルでやってみた。なんとなくで組んだ割にはまあまあの結果が出た。 カーネルサイズは[16, 16, 8] |
U-Net: Convolutional Networks for Biomedical Image Segmentation
https://arxiv.org/abs/1505.04597
パラメーター
| 名前 | 値 | 備考 |
|---|---|---|
| エポック | 1000 | lossが収束するまで、おおよそこれくらい |
| バッチ | 4 | = 学習データ数 |
| 学習関数 | Adam(lr=1e-4, beta_1=0.5) |
損失関数
以下の損失関数で試した。
| 損失関数名 | 概要 | 参考 |
|---|---|---|
| MSE | 二乗平均誤差 | |
| imbalanced_loss(自作) | 不均衡データ用関数 | ソースコード(記事のGithub) |
| 今回扱うデータはほとんど黒く(=0データ)で、行列内のデータの偏りがかなり大きい、**不均衡データ**と呼ばれるものである。 | ||
| 一般的な解決法として、DownsamplingやUpsamplingなどがあるが、今回のデータでは適用できない。 | ||
| そこで、「教師データで1に該当するデータの損失を大きくする」という基本理念のもとで、imbalanced_loss関数を自作した。 | ||
| ロジック自体は簡単だが、説明がややこしいので、ソースコードのdocsを参照してほしい。 |
【ML Tech RPT. 】第4回 不均衡データ学習 (Learning from Imbalanced Data) を学ぶ(1)
https://buildersbox.corp-sansan.com/entry/2019/03/05/110000
学習結果
今回、モデルと損失関数の組み合わせ方でいろいろなパターンが考えられるが、以下の組み合わせの結果を示す。
| 名前 | 値 |
|---|---|
| モデル | シンプルCNN |
| 損失関数 | imbalanced_loss |
出力
| 学習データ | 教師データ | 出力 |
|---|---|---|
|
|
 |
| 256256321 (縦横*奥) | 256256321 (縦横*奥) | 256256321 (縦横*奥) |
| あともうちょっと・・・て感じ |
特に、 境界に近いデータが曖昧になる。ゼロパディングかつ、カーネルサイズが[16, 16, 8]であるので、境界付近だとどうしてもデータ数が足りなくなり、精度が落ちる。
奥行きが32しかないので、そもそも十分に畳み込みをできているz軸の範囲が8~24しかない。
カールを小さくすると問題解消するかもしれないが、そうすると出力の精度が落ちる(考察参照)。
学習過程
| MSE | Imbalanced loss |
|---|---|
 |
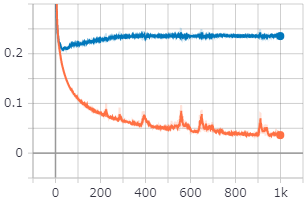 |
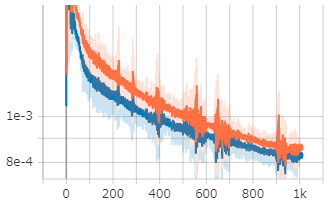
| 橙色がtrainで、青がvalidationである。 | |
| データセットの数が少なすぎるので、MSEではvalidationの方が評価が良かったりしている。 | |
| そういった点では、学習に用いていないvalidationデータは評価が低くなっているImbaranced lossは優れているのかもしれない。 | |
| それにしてもtrainとvalidationが乖離しすぎ...? |
考察
カーネルサイズは大きいほうがよい
[4, 4, 2], [6, 6, 3], [16, 16, 8]といった具合に、カーネルサイズを変更して学習を行い比較した。
結果、カーネルサイズが大きいほうがよい結果が得られた。
今回扱うデータは、一般的な写真のようにデータが細かいわけではない(特にz軸)。
なので、小さなカーネルサイズだと、大きな物体の認識が困難になるのではないだろうか。
本来はプーリング等がそれらを担うはずだが、メモリの問題でフィルター数をケチったのが問題?
サンプル数はそこまで多く必要じゃない
今回の結果からみて、それなりの生成物ができている。
学習サンプルは4つという、極端に少ないサンプル数だが、学習データにバリエーションが少ないことで、今回はどうにか学習が進んでいる。
とはいえ、多いに越したことはないのだが。
損失関数は重要
当初、損失関数はMSEで行っていたが、やはり不均衡データのせいで真っ黒な出力へと偏ってしまう。
Imbalanced lossを適用させると、その偏りがそれなりに収まった。
ソースコード
今回のプログラムはGithubにて公開しています。
ご参考までに
https://github.com/oura-hideyoshi/3D-autoencoder
ご意見について
今回、kerasや機械学習を1年ほどしか勉強していない者が記事を作成しているため、不備が多々あると思います。
ご意見を頂ければ記事に反映し、活かしていくつもりです。
特に、以下の意見についてはぜひとも参考にさせて頂きます。
- ボクセルデータに対する不均衡データ用損失関数について
- 3DConvを使ったモデル設計について
- 記事と同様な試行をしている記事について