はじめに
AWS Solutions Architect Associate を取得し、個人ポートフォリオサイトを運用していく中で、「監視」の重要性を実感するようになりました。実際の運用現場でも求められるスキルを学ぶため、監視システムの構築に挑戦してみました。
前提条件
構築前の状況
- 個人ポートフォリオサイト(AWS S3 + CloudFront + Route53)を運用中
- AWS Solutions Architect Associate 認定取得済み
- 監視経験:CloudWatch でのエラーログ確認程度
目標設定
- 実用的な監視システムの構築
- コスト効率を考慮した設計
- SRE観点での可観測性の実現
- 転職活動での技術力アピール
実装した監視システム
1. CloudWatch Alarms(基礎監視)
まずは基本的なアラームから設定しました。可用性とパフォーマンスを重視し、以下のアラームを作成:
CloudFront 4xxエラー率監視
resource "aws_cloudwatch_metric_alarm" "cloudfront_4xx_errors" {
alarm_name = "portfolio-cloudfront-4xx-errors"
comparison_operator = "GreaterThanThreshold"
evaluation_periods = "2"
threshold = "10"
metric_name = "4xxErrorRate"
namespace = "AWS/CloudFront"
period = "300"
alarm_actions = [aws_sns_topic.portfolio_alerts.arn]
}
[CloudWatch Alarms 一覧画面(3つのアラームが OK 状態で表示)]
CloudFront 5xxエラー率監視
resource "aws_cloudwatch_metric_alarm" "cloudfront_5xx_errors" {
alarm_name = "portfolio-cloudfront-5xx-errors"
threshold = "5"
# 5xxエラーはより深刻なため低い閾値に設定
}
設計上の考慮点
- 4xxと5xxで閾値を変更: 5xxエラー(サーバー側問題)の方が深刻なため、より低い閾値(5%)に設定
- evaluation_periods = 2: 一時的なスパイクによる誤報を防止
2. SNS通知システム
アラーム発生時に確実に通知を受け取るため、SNSを設定しました。
resource "aws_sns_topic" "portfolio_alerts" {
name = "portfolio-monitoring-alerts"
}
resource "aws_sns_topic_subscription" "email_alerts" {
topic_arn = aws_sns_topic.portfolio_alerts.arn
protocol = "email"
endpoint = "example@gmail.com"
}
学んだこと
- 通知システム(SNS)と監視システム(CloudWatch)を分離することで、後から通知方法を追加する際にアラーム設定を変更する必要がない
- メール通知の購読確認が必要(スパム防止のため)
3. Lambda + カスタムメトリクス(外形監視)
標準メトリクスでは把握できない、実際のユーザー体験を監視するためカスタムメトリクスを実装しました。
import boto3
import requests
from datetime import datetime
def handler(event, context):
try:
response = requests.get('https://inatom-portfolio.com', timeout=5)
response_time = response.elapsed.total_seconds() * 1000
availability = 1 if 200 <= response.status_code < 300 else 0
cloudwatch = boto3.client('cloudwatch')
cloudwatch.put_metric_data(
Namespace='Portfolio/Health',
MetricData=[
{
'MetricName': 'SiteAvailability',
'Value': availability,
'Unit': 'Count'
},
{
'MetricName': 'ResponseTime',
'Value': response_time,
'Unit': 'Milliseconds'
}
]
)
except Exception as e:
# エラー時は可用性0として記録
pass
[Lambda 関数の概要画面(EventBridge トリガー設定を含む)]
コスト最適化の考慮
- 15分間隔での実行: 5分間隔から変更してコストを約60%削減
- 最小限のメトリクス: 必要な指標のみに絞って送信
4. Datadog AWS Integration
エンジニア転職市場で重要視されるDatadogの実践経験を積むため、実際に導入して学習しました。

[Datadog Integrations 画面(Amazon Web Services が "Installed" 状態)]
設定手順
- Datadog無料トライアル登録
- AWS Integration設定(CloudFormationテンプレート使用)
- メトリクス取得の確認
- ダッシュボード作成
作成したダッシュボード
- Site Traffic (Requests/min): サイトへのアクセス数
- Client Errors (4xx Rate %): クライアントエラー率
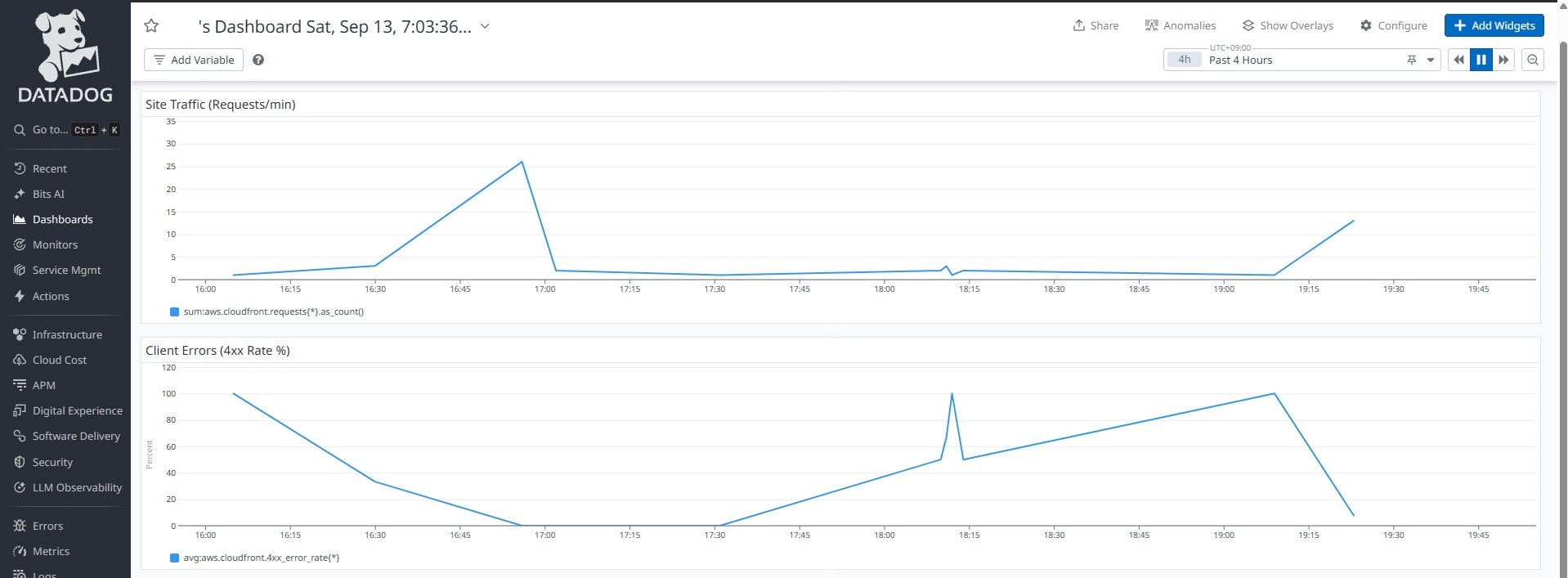
[Datadog ダッシュボード(2つのメトリクスパネルが表示された画面)]
Infrastructure as Code での管理
監視システムも含めて、全てTerraformで管理しています。
terraform/
├── main.tf
├── monitoring.tf # 今回追加
├── metrics_collector.py # Lambda関数
└── ...
手動設定ではなくコードで管理することで:
- 設定の再現性確保
- 変更履歴の追跡
- 他環境への展開容易性
実装後の気づき
監視設計の重要性
実際に設計してみて以下を学びました:
- 閾値設定の根拠: なぜその値なのかを説明できることの重要性
- 誤報との戦い: evaluation_periodsやしきい値調整の必要性
- ビジネス観点: 技術的メトリクスをビジネス価値に結びつける視点
コスト意識の実践
- 月額追加費用:約100円(CloudWatch Alarms + Lambda実行 + カスタムメトリクス)
- 個人プロジェクトでも実用的な範囲でのコスト設計
SREマインドセット
「システムが動いているから大丈夫」ではなく「システムが健全な状態を維持できているか」を継続的に監視する重要性を実感しました。
今後の計画
後編では以下に取り組む予定です:
- Docker/Kubernetes実践学習
- より高度な監視機能の追加
- オンプレミス基礎知識の習得
- SLI/SLO設定の実践
まとめ
AWS初心者でも1日で基本的な監視システムを構築できました。特に以下の学びが大きかったです:
- SREにとって監視は最重要スキルであること
- コードによるインフラ管理の重要性
- コスト効率と実用性のバランス設計
SREエンジニアとして、ユーザーが安心してサービスを利用できる環境作りに貢献していきたいです。転職活動においても、この実践経験を活かしていこうと思います。