BatchNormalization(以下BN)を入れると
過学習が起きにくくなるという事は経験的にわかっていましたが
どこに入れればいいのか不明なので、簡単なCNNのモデルを作成し確認してみました
BNの細かい説明はお魚の本P.186~を参照
データセットによって動きが変わることは十分考えられますので、参考程度にお願いします
ただ、思ったよりも動きが変わって面白かったです
※△1 2018.10.7追記
上記の予想通り、データセットをcifer10に変更したところ
BNを入れた方がlossが大きくなる結果となりました
検証はこちらに掲載します
簡単にまとめると
データ数が十分に多く、モデルのパラメータが少ない
過学習が起きづらいモデルに対してBNを導入すると
lossが大きくなるようです
確認環境
python3.6.6
Tensorflow:1.10.0
Keras:2.2.2
学習データ
@God_KonaBanana様の
VGG16を転移学習させて「まどか☆マギカ」のキャラを見分ける
のデータセットを使用させていただきました
程よく難しいのか、100%カンストにならないので
実験用に最適だと思ます
モデル
某所で聞いたVGG7(勝手に命名)を実験台にします
構造は下記のとおりです
最初のconv2層をblock1
次の2層をclock2
FC層をFCとします
計算は過学習の様子を見たいので400epoch計算させました
inputs = Input(shape = model_input)
# block1
x = Conv2D(64,3,strides=(1, 1), padding='same', kernel_initializer="he_normal")(inputs)
x = Activation('relu')(x)
x = Conv2D(64,3,strides=(1, 1), padding='same', kernel_initializer="he_normal")(x)
x = Activation('relu')(x)
x = MaxPool2D(pool_size=(2,2))(x)
# block2
x = Conv2D(128,3,strides=(1, 1),padding='same', kernel_initializer="he_normal")(x)
x = Activation('relu')(x)
x = Conv2D(128,3,strides=(1, 1),padding='same', kernel_initializer="he_normal")(x)
x = Activation('relu')(x)
x = MaxPool2D(pool_size=(2,2))(x)
x = GlobalAveragePooling2D()(x)
# FC
x = Dense(1024, kernel_initializer="he_normal")(x)
x= Activation('relu')(x)
x = Dense(512, kernel_initializer="he_normal")(x)
x= Activation('relu')(x)
predictions = Dense(n_categories,activation='softmax')(x)
model = Model(inputs=inputs, outputs=predictions)
model.summary()
# optimizer選択
opt = optimizers.Adam(lr=0.0002, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False)
# model compile
model.compile(optimizer=opt,
loss='categorical_crossentropy',
metrics=['accuracy'])
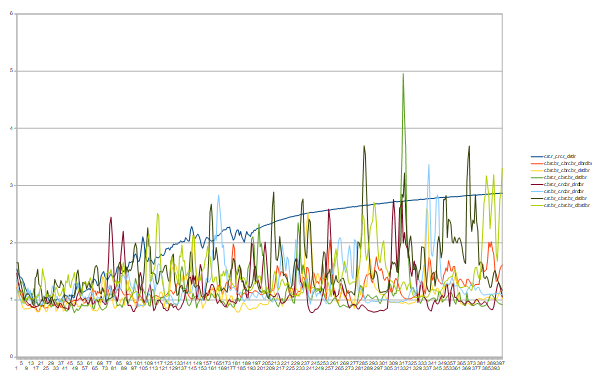
block1にBNを入れる(block2とFCは変更なし)
val_lossをグラフにすると下記のようになります
凡例のcはconv、rはRelu、BがBNです
何も入れていないcrcrはTHE 過学習といった感じのプロットです
BNをいれると過学習の傾向が抑えられていることがわかります
ただし、2層両方にBN入れたloss>どちらか1層にBN入れたlossなので
沢山入れればいいというものでもなさそうです
1層目or2層目のどちらにBNをいれるのか?は
lossが跳ね上がることが少ない1層目にBNの方が計算が安定してそうな感じでしょうか・・・
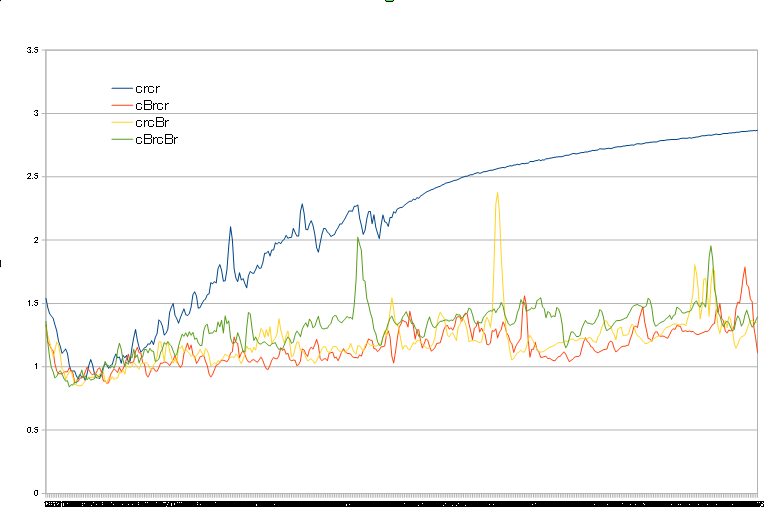
block2にBNを入れる(block1とFCは変更なし)
先ほど同様にBNを入れると学習が進んでもval_lossが増加する
過学習の傾向が抑えられています
こちらは2層両方にいれたものが最も早くlossが低下しています
ただ、その後でlossが急に大きくなる挙動が散見されるのと
最終的なlossにほとんど差がないこと
後述のFC層の挙動から等々の理由から
今回のデータでは無くても良いのではないかと判断します
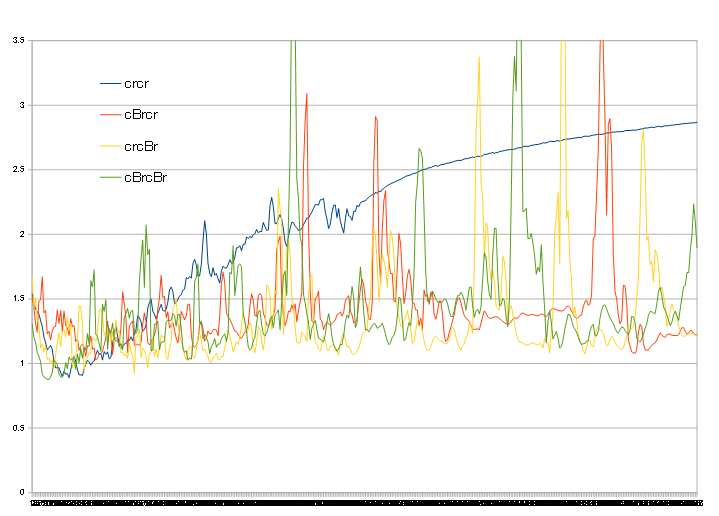
FCにBNを入れる(block1とblock2は変更なし)
凡例のdはdense、rはRelu、BがBNです
先ほどと動きが変わって、学習初期はBN無しよりもlossが高いという結果になります
しかし、その後はlossが低下して下がりきったところからはlossが上昇しなくなります
(たまにlossが跳ね上がる挙動はありますが)
学習を進めていった際の過学習の抑制には一番効果があるように感じます
BNを入れた中で最も悪いのは1層目にBNを入れたパターンで
次点が2層両方にBN、最も良いのが2層目にBNという結果となりました
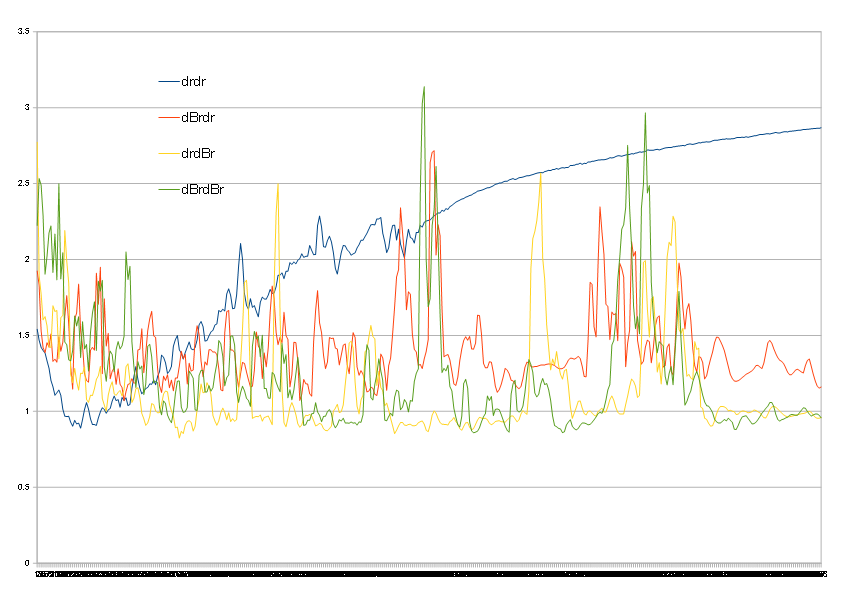
まとめ
以上の結果を雑にまとめると(今回のデータでは)
block1の1層目にBN
block2は何もしない
FCの2層目にBN
が良さそう!!
というわけで上記のモデルを検証しました
凡例は暗号のようですが、先ほど同様でモデル全体を表しています
狙ったように前半のlossの低下が早く、過学習も抑えるという結果になりました
入り口で正規化して、softmax渡す前に正規化したらよくなったという
まぁ、言われてみればそうかな?という結果でした
おまけ
ほかのパターンでもっといいのがあるかもしれないのに
ぱっと決めた1パターンだけで検証終了かよと言われそうですが・・・
一応全部計算しております()
↓(一部描画)