こんにちは。「Rookと仲間たち、クラウドネイティブなストレージの Advent Calendar 2020」13日目は、前回|【ストレージ初心者向け】分散ストレージ、Cephの速度を計る(1)に引き続きましてCephの性能測定ネタを提供していきたいと思います。
思った以上に前回の記事でご反響がいただけたようで、大変嬉しい限りです。
はじめに
さて、先週の記事ではストレージの性能指標やCephのアーキテクチャ上の特性を記載しました。
今回は実際にストレージ性能の測定ツールを動かしていこうと思います。
目次
第一回は、知識ベースの話を記載しました。
第二回では実際に動かし、ベンチマークする上でのテクニックに関して記載します。
-
- ディスクIOの仕組みについてある程度理解する
- Rook/Cephのアーキテクチャについて留意しておく
-
第二回(13日目)
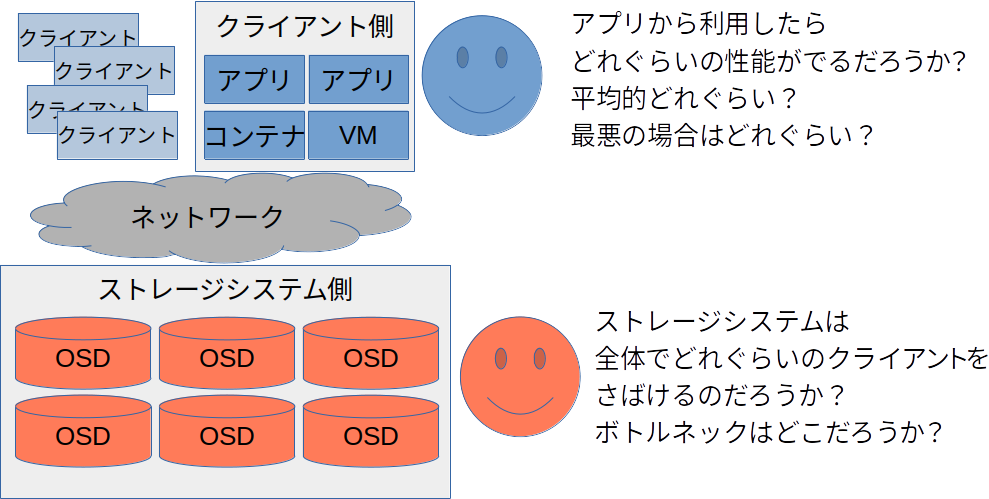
- なにを測定したいのかを明確にすること
- アプリケーションから使用する場合の性能が知りたいのか?
- ストレージシステム全体のボトルネック・性能限界を知りたいのか?
- 理論的な限界値が知りたいのか、実践的な値がしりたいのか?
- ワーストケースが知りたいのか?平均値が知りたいのか?
- 測定ツールのパラメータをある程度理解する
- 簡単な試験ならDDコマンドでも十分
- FIOというツールにはさらいいろんなパラメータを用いることが可能
- 最後に実際のCephの測定をしてみる
- アプリケーションを疑似した計測例1、2
- 結果のまとめとCephの性能の特性
- なにを測定したいのかを明確にすること
なにを測定したいのかを明確にすること
まずはじめにストレージの性能を計るうえでの注意点やポイントを整理したいと思います。
あなたが知りたい情報は何ですか?
これはストレージに限った話ではありませんが、「なに」を計るかは非常に重要なことです。
当たり前の話ですが計る対象や知りたいことによりテスト手法や準備するものも大きく異なります。
とはいえ、本当に初心者な人にとってはそもそも「自分がなにが知りたいか」を把握していないことはよくあることです。
私自身もはじめてCephというものを評価する仕事を行ったとき、いったい自分自身何を評価しなければいけないのかということに非常に迷いました。
こでは代表的な観点をいくつかピックアップし紹介したいと思います。
観点1: アドミニストレータとユーザの観点
大きな観点として、あなたが興味ある項目は、ストレージを利用するユーザ(サーバやアプリケーション)からみた観点でしょうか、それとも、ストレージを管理するアドミニストレータ(ストレージシステム全体)の観点でしょうか。
前者のイメージは、あなたがSDカードや外付けHDD/SSDを購入してきた際や、パソコンを新調した際に、ストレージの速度を計るイメージです1。
対して、後者のイメージはCephなどのストレージシステムを提供する管理者としての立場です。おそらくRook/Cephに興味のある方は、Rook/Cephを kubernetes の Persistent Volume としてや、 OpenStack の Cinder や Manila のバックエンド、あるいは Swift や S3 などのオブジェクトストレージの代替手段として利用されようとしているかと思います。
また、Rook/Cephの優れた点はこれらの異なる利用方法を単一のクラスタで実現できてしまう点です。
こういったMixされたワークロードや、複数のクライアントシステムからストレージシステムを利用された場合の最大速度やボトルネックについて知りたいといったことも考えられます。
単一のクライアントが、そのストレージシステムのすべての性能を利用することができるストレージシステム2や、小規模な環境において、これらの値はもしかしたら同一かもしれません。
また、もちろん両方の観点を評価することも(特にストレージシステムのアドミニストレータとしては)必要かもしれません。
観点2: 理論的な限界値か、実践的な値か
理論的にどれぐらい出るのかという値を知りたいというケースと、実践的なアプリケーション等を考えたときにどれぐらい出るのかといった点で評価したいというケースの二パターンがあるかと思います。
これは、「n K IOPS達成」という評価結果の前提が何なのかということになります。
例えば、これは後述しますが、Cephはアプリケーションがシングルスレッドで動いておりかつ、同期IOで動くようなアプリケーションであればCephの性能はおそらく低い値を示します。しかしながら、非同期IOを用いる場合や、マルチスレッドで動作するようなアプリケーションであれば良いパフォーマンスを示すかもしれません。
しかしながら、後者のような非同期IOやマルチスレッドでの動作というのは、アプリケーションによっては利用できないことが多くなります。またこれは、Cephに対しては有効かもしれませんが、物理ディスクやその他のストレージシステムでは同様に有効かどうかはわかりません。
また通常のアプリケーションではページキャッシュを用いたBuffered IOを用いる事がほとんどです。その場合はバッファーを用いない短いバイトサイズでの試験結果はあまり意味のないものかもしれません。
このように理論的な限界値を評価の基軸にすると、性能を見誤ったり、実際のワークロードに合わない可能性もあります。実際のワークロードが決まっているのならばそれを軸にするのが一番間違いがないでしょう。
もちろん、こちらもどちらのパターンも評価をしておくことは言うまでもなく重要となります。
観点3: 最良値か平均値か、最悪値か。
これも何もストレージシステムに限った話ではありませんし前述の理論的 or 実践的に近いものがあります。
例えば、最良値を知りたい場合には環境の作成や、細かなチューニングが必要になるかもしれません。
また、最悪値を計りたい場合には考えうるワーストなケースを意識したり、ノイジーネイバーを意識したりする必要があります。
しかしながら、これらの最悪値も最良値ももしかしたら、あまりにも極端な値であり、現実的なワークロードを考えた場合には意味がないものかもしれません3。
もちろん、こういった指標もすべてデータとして持っていることは設計から、トラブルシューティング時まで様々な面で助けになることに間違いがありませんので、多角的観点で評価することも重要ではあります。
しかしながら、時間は有限であり、リソースも限られるため何を重視するのかについては優先順位をつける必要あると思います。
観点のまとめ
これらの観点の中から目的がどれに近いのかを意識すれば無駄な項目をベンチマークをとったり、意味のないパラメータで評価したりする必要もなくなります4。
また、以降は上記の観点からも手法や結果を評価したいと思います。
測定ツールのパラメータをある程度理解する
アクセスパターン、シーケンシャルとランダム
これは第一回のなかで紹介すべき話題だったかもしれませんが、漏れていましたのでここで記載します。
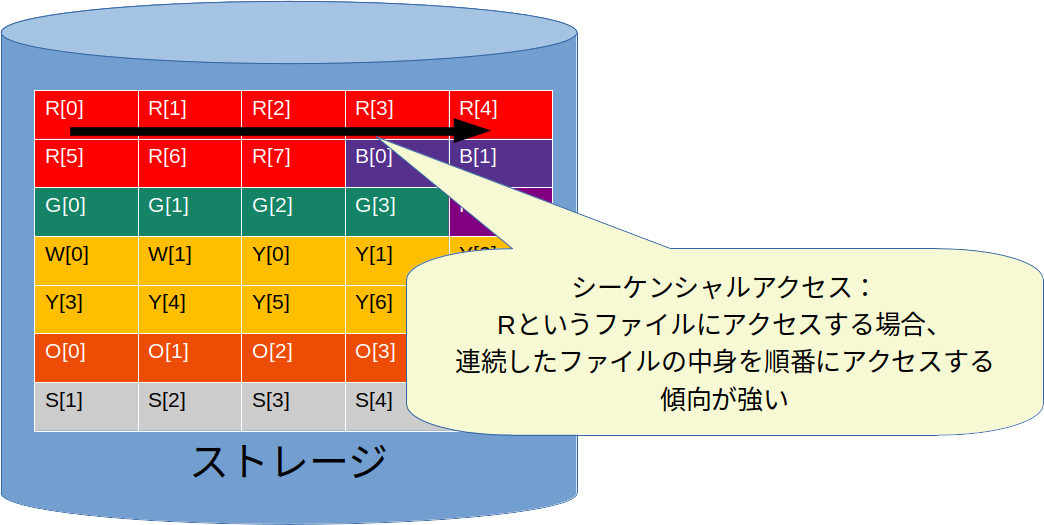
よくストレージのベンチマークにおいては、「シーケンシャルライトではxK IOPSですが、ランダムライトではyK IOPSでした」といった形で、「シーケンシャルxx」と「ランダムxx」が比較されることがあります。
これは一つのファイルはある程度の塊で連続して配置されていることが多くあるために生じる考慮事項です。
例えば、動画ファイルを例にとれば簡単に理解できると思います。
メモリが4GBしか積んでいないパソコンで巨大な動画ファイル(たとえばDVD 4.7GB分の映画)をすべてメモリにロードしてしまうとメモリ不足となり映画を見ることができません。
ですので映画をたとえば30秒単位(この数字は全くのでたらめです5)で断片的に読み込んでいけば、60秒分のデータをメモリにロードしておくだけで済みます。このようにデータには連続性があり、また次にアクセスするデータも同じ領域に近いという特性が「一般的」にはあります(とはいえ、コンピュータからみた一塊のデータが実際に物理ディスクの隣接した物理領域に常に存在しているわけではありません6)。
こういった連続したデータへのアクセスのことをシーケンシャルアクセスといいます。
シーケンシャルアクセスの場合、次に呼び出せれるデータや次に書き込むデータなどをある程度予測できるため、データへのアクセスをハードウェア的、ソフトウェア的な最適化により効率化しているケースが多々あります(ページキャッシュなどもその例です)。
対して、ワークロードによってはシーケンシャルにアクセスしないようなケースも存在します。
たとえば、小さなファイルが大量にあるようなシステムでかつ、不規則にそのファイルにアクセスする必要があればランダムなアクセスになるでしょうし、最適化されていないようなデータベースなどでも同じように散らばったデータを探す必要が出てくるかもしれません。
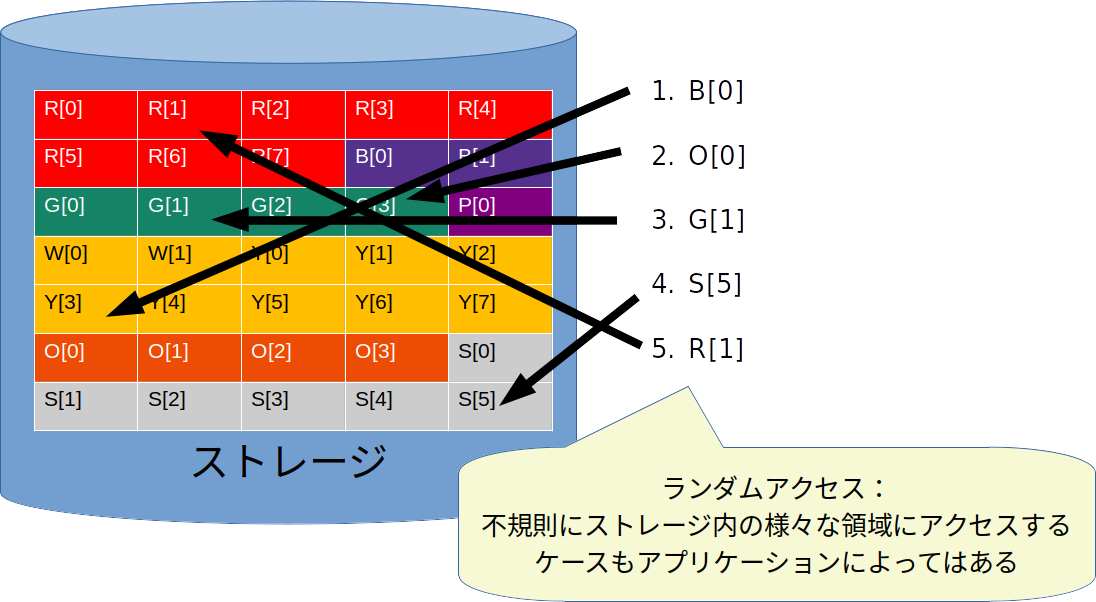
シーケンシャルアクセスに比べてランダムアクセスは次のアクセスに対する予測が難しいため、最適化による効率化が難しい側面があります。また、回転ディスクを用いるHDDでは物理的にあちこちにヘッドを移動させる必要があるため、読書きの時間が非常に低速になります7。
これらのストレージの特性から、一般的に、ランダムアクセスのほうがストレージ自身の持つオーバヘッドを顕著に表す傾向が強く、また各種の最適化の恩恵を受けない、ワーストケースを表すことが一般的にあります。
そのため、ストレージの評価に当たっては、シーケンシャルの場合と、ランダムの場合で比較して評価がなされたり、ベンチマークツールの中でそれらを指定できるようになっています。
簡単な試験ならDDコマンドでも十分
さて、では実際にストレージの試験をするうえではどういったツールを用いればよいでしょうか?
シングルスレッドでかつ、シーケンシャルアクセスを評価するのであれば、ファイルのコピーやディスクのバックアップ・リストアや削除などにも用いられる行うことができるddコマンドというプログラムを用いることができます。
このddはどのOSディストリビューションにも入っているはずですので、どのような環境でも簡単に計測ができます。
注意
今回の例では /dev/vdb に直接書出していますが、
これは計測試験用に新たに作成した、仮想ストレージデバイスです。
また、利用している環境も試験のためだけに作成した仮想マシンを利用しています。
この内容が理解できない場合は安易なコピペだけには十分気をつけてください・・・!8
シーケンシャルライト
では実際にシーケンシャルライトの評価を行ってみます。
結論的には以下のコマンドを実行した結果を見てみます。
$ sudo dd oflag=direct if=/dev/zero of=/dev/vdb bs=4K count=256000
256000+0 records in
256000+0 records out
1048576000 bytes (1.0 GB, 1000 MiB) copied, 262.252 s, 4.0 MB/s
このコマンドの引数の意味は以下のとおりです。
-
oflag=directを指定することによりページキャッシュを経由しないで書き込みを行っている -
if=/dev/zeroを指定することにより、読出しにディスクを使用しない -
of=/dev/vdbで書込みディスクを指定、今回/dev/vdbが測定対象となる cephのRBDで作られたデバイス -
bs=4Kを指定することによりブロックサイズを4 KBに指定している -
count=256000を指定することにより、4KB * 256,000 = 1,000,000KB = 1GB分のデータ書き出しを実施
実行結果からは次のことが言えます。
- 1.0GB のファイルの書込みに 262.252秒かかった
- 1.0GB(1,000MiB = 1048MB) のファイルは 4MB/sの速度で書き込まれた(
1048MB / 262.252 = 3.996MB/s) - 256,000回のIOに262.252秒かかった、およそ1,000 IOPS(
256,000 / 262.252 = 976 IOPS)
シーケンシャルリード
同様に次はシーケンシャルリードについて確認します。
$ sudo dd oflag=direct if=/dev/vdb of=/dev/null bs=4K count=256000
sudo: unable to resolve host tb6-az-a2-ceph-test: Name or service not known
dd: failed to open '/dev/null': Invalid argument
ubuntu@tb6-az-a2-ceph-test:~$ sudo dd iflag=direct if=/dev/vdb of=/dev/null bs=4K count=256000
sudo: unable to resolve host tb6-az-a2-ceph-test: Name or service not known
256000+0 records in
256000+0 records out
1048576000 bytes (1.0 GB, 1000 MiB) copied, 127.897 s, 8.2 MB/s
このコマンドの引数の意味は以下のとおりです。
-
iflag=directを指定することによりページキャッシュを経由しないで読み込みを行っている -
if=/dev/vdbで読込みディスクを指定、今回/dev/vdbが測定対象となる ceph のディスク -
of=/dev/nullを指定することにより、書出しにディスクを使用しない -
bs=4Kを指定することによりブロックサイズを4 KBに指定している -
count=256000を指定することにより、4KB * 256,000 = 1,000,000KB = 1GB分のデータ書き出しを実施
また実行結果からは次のことが言えます。
- 1.0GB のファイルの読込みに 127.897秒かかった
- 1.0GB(1,000MiB = 1048MB) のファイルは 8.2 MB/sの速度で読込まれた(
1048MB / 127.897 = 8.19 MB/s) - 256,000回のIOに127.897秒かかった、およそ2,000 IOPS(
256,000 / 127.897 = 2002 IOPS)
ブロックサイズを変えてみる
では更にブロックサイズを変えてみて確認します。
$ sudo dd oflag=direct if=/dev/zero of=/dev/vdb bs=4M count=250
sudo: unable to resolve host tb6-az-a2-ceph-test: Name or service not known
250+0 records in
250+0 records out
1048576000 bytes (1.0 GB, 1000 MiB) copied, 5.70676 s, 184 MB/s
$ sudo dd iflag=direct if=/dev/vdb of=/dev/null bs=4M count=250
sudo: unable to resolve host tb6-az-a2-ceph-test: Name or service not known
250+0 records in
250+0 records out
1048576000 bytes (1.0 GB, 1000 MiB) copied, 3.98156 s, 263 MB/s
それぞれ、引数の差分は次のとおりです。
-
bs=4Mを指定することによりブロックサイズを1000倍である4 MBに指定している -
count=250を指定することにより、4MB * 250 = 1,000MB = 1GB分のデータを読み書き
これらの実行結果からは次のことが言えます。
- Writeは 44 IOPS(=250/5.71) / 184 MB/s
- Readは 63 IOPS(=250/3.98) / 245 MB/s
- Writeは4KBのブロックサイズのときと比較して(同じデータ量にたいして)52倍高速
- Readは4KBのブロックサイズのときと比較して29倍高速
同じ方法で以下まとめた結果です
| 読み書き | bs= | count= | IOPS | スループット | 1 GBのIO時間 | 1 I/O あたりのレイテンシ |
|---|---|---|---|---|---|---|
| Write | 4 KB | 256,000 | 976 | 4 MB/s | 262 sec | 1.02 msec |
| Write | 16 KB | 64,000 | 901 | 14.8 MB/s | 71.1 sec | 1.11 msec |
| Write | 64 KB | 16,000 | 762 | 50.0 MB/s | 21.0 sec | 1.31 msec |
| Write | 256 KB | 4,000 | 432 | 113 MB/s | 9.25 sec | 2.31 msec |
| Write | 1 MB | 1,000 | 162 | 170 MB/s | 6.18 sec | 6.18 msec |
| Write | 4 MB | 250 | 44 | 184 MB/s | 5.71 sec | 22.7 msec |
| Read | 4 KB | 256,000 | 3647 | 14.9 MB/s | 70.2 sec | 0.27 msec |
| Read | 16 KB | 64,000 | 2645 | 43.3 MB/s | 24.2 sec | 0.38 msec |
| Read | 64 KB | 16,000 | 1212 | 79.3 MB/s | 13.2 sec | 0.83 msec |
| Read | 256 KB | 4,000 | 484 | 127 MB/s | 8.27 sec | 2.07 msec |
| Read | 1 MB | 1,000 | 192 | 201 MB/s | 5.22 sec | 5.22 msec |
| Read | 4 MB | 250 | 63 | 263 MB/s | 3.98 sec | 15.92 msec |
第一回で紹介したように、
- ブロックサイズが大きくなるに連れて、IOPSが低下し、スループットが上昇していること
- IOあたりのレイテンシも上昇していること
ということがわかるかと思います。
さらに、レイテンシに注目いただきたいですが、ブロックサイズが小さい場合、レイテンシに大差が無いことがわかるかと思います。
特に書込みの結果で顕著にわかるかと思いますが、ブロックサイズ(1度の転送データ量)が16倍も違う、4 KBと64 KBの結果において1IOあたりの時間の差は、0.3 msecしかありません。
裏を返せば60 KB9のデータ転送におおよそ、0.3 msec程度かかっているということになります。
大雑把な計算ですが、これは0.3 [msec] / 60 [KB] = 0.005 [msec/KB] すなわち 1キロバイト当たり5 usec程度の転送率です。
この値を上記の測定結果に当てはめて考えてみましょう。
4 KB のデータには 1.02 msec かかっています。このとき 4KB のデータを送るのには 0.005 [msec] * 4 [KB] = 0.02 [msec]となる計算です。
しかし実際には 1.02 msecかかってるわけですから、 1.02 [msec] - 0.02 [msec]でオーバヘッドが1ミリ秒ほど発生していることがわかります。
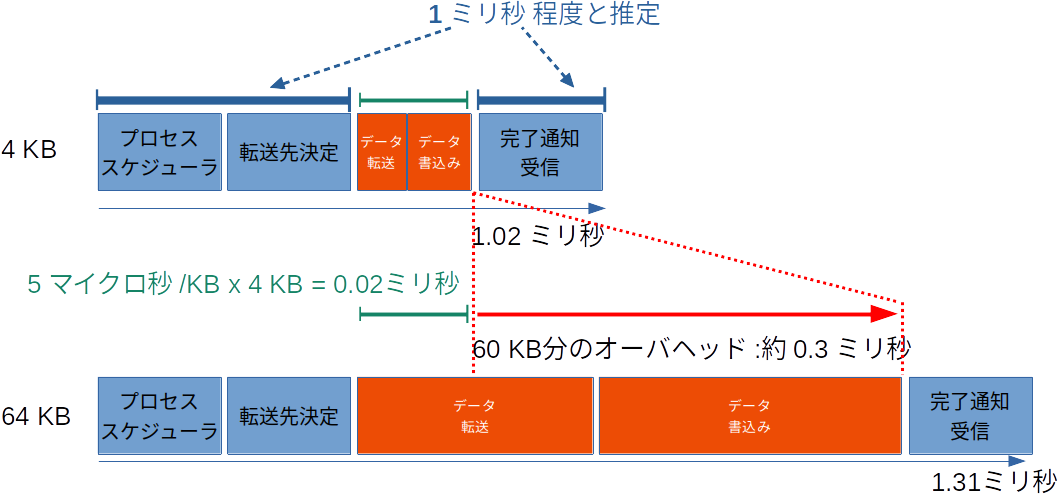
他にも256 KBの結果で見てみると、データの転送速度である0.005 msec/KBにブロックサイズの256 KBをかけ、上記の計算で導いた、オーバヘッドの1 msecを足し込むと0.005 * 256 + 1 = 2.28 [msec] と実際の2.31 msecという結果に近い値が導き出されました。
同様に、1 MBですと、0.005 * 1000 * 1 = 6 [msec]ですので、こちらも6.18 msecに近い値を導き出せています。
読込みの結果で計ってみるとオーバヘッドの値がかなりばらつきました(0.25〜0.6 msec 程度)。こちらの詳細な考察は省きますが10、これは(おそらくですが)キャッシュの影響だと考えられます。今回の測定環境では仮想マシンを用いており、ハイパーバイザではライトスルー方式のキャッシュを設定しています。書込みはライトスルーとなるため必ず実際にディスクへのアクセスが発生し、レイテンシも安定していますが、読込みについてはハイパーバイザ等でのキャッシュにヒットしてしまうことや、また、Ceph OSDノード上でのキャッシュもあるためそれらの影響からゆらぎが生じていると想定されます。
Cephのもつ多層でのキャッシュの話は前回記載していますのでご参考にしてみてください。
Flexible IO tester / fio
さて、ここまでddコマンドを用いたテスト方法を紹介してきました。
しかしながらddコマンドはもともと、ディスクのデータコピーやレストア、あるいは破壊などに使うツールとなります。
テストの用途で使用するには結果の出力が不足していたり、テストパターンも限られたりしてしまいます。
また、特に「ランダムアクセス」方式でのアプリケーションの疑似動作や「マルチスレッド」での動作、「非同期IO」といった、ディスクへの読み書き性能を向上させる技術を用いることも難しくなります。
そのため、実際のストレージの性能測定には、よりストレージの性能測定に特化したソフトウェアが広く用いられており、代表的なツールが、Flexible IO Tester / fio となります。
fio の多様なパラメータ
fioは名前にFlexibleとつくように多種多様なオプションパラメータにより、様々なストレージのワークロードを疑似する事ができます。
そのオプションの数は 2020-12-12現在で 235 のも及ぶようです11。
さすがにすべてのオプションを理解している人は少ないと思いますので、必要になってから確認すれば良いと思います。
以下に代表的な筆者がよく用いるオプションパラメータを記載します。
| 種別 | パラメータ | 設定例 | 内容 |
|---|---|---|---|
| Target file/device | filename | /dev/vdb | 測定する対象を指定します。ファイルでも良いですし、デバイスの指定でもOKです。 |
| I/O engine | ioengine | libaio | 同期IOか、非同期IOか、あるいはRBDを直接叩くか等を指定します。何も指定しなかった場合は同期IOであるsyncが指定されます。 |
| I/O type | direct | 1 | ページキャッシュを用いないでデバイスに直接書込みます。ddコマンドで用いていた oflag=directと同等の処理です。 |
| rw | randwrite | これは dd コマンドでは指定できなかった項目です。randwriteと書くことで、ランダムアクセスでの書込みをテストすることができます。またread/writeのIOを混ぜることも可能です | |
| Block size | bs | 4k | ddと同じくブロックサイズを指定できます |
| I/O size | size | 100G | テストで読み書きする領域の大きさです。ddではファイルサイズを指定するためにブロックサイズとcountによる総IO数で計算する必要がありましたが、fioではファイルサイズで指定可能です |
| Job description | numjobs | 1 | 並列に動作させるジョブ(スレッド)の数です。 fioでは複数のプロセスから同時にioを発行することが可能です。これでマルチスレッド環境やマルチプロセス環境での性能を計ることができます。ddコマンドでこれをやるためには自分自身で複数のプロセスを生成する必要がありましたがfioでは自動でやってくれます |
| loops | -1 |
size分のIOを行ったあとに何回まで繰り返すかです。runtimeオプションだけ必ずテストを実行させたい場合は-1を指定して無限ループとしておくのが良いと思います。 |
|
| name | file1 | テストに名前をつけることができます。後述の通りレポートを作成できますのでその際の分類わけに利用できます | |
| I/O depth | iodepth | 1 | これはnumjobsと非常に紛らわしく、また初心者には理解が難しいポイントかと思います(私も最近理解)。これは非同期IOなどのioengineを利用して初めて有効となるオプションです。1つの非同期IOジョブでの並列数となります。(ioengine=io_uring等)。ですので、デフォルトのioengine=syncを指定する(あるいはioengineのオプションを指定しない)場合は必要の無い(意味のない)パラメータとなります。意外とこの事を書いている記事を見たこと無いので、このパラメータの解説はここがハイライトです |
| Time related parameter | runtime | 120 | ジョブの実行時間を指定します。loop=1の場合はruntimeで指定した時間より先に読み書きが終わってしまうと、runtimeより早く終わります。runtimeの時間必ずIOをかけたい(たとえば背景負荷を加えたいなど)場合はloop=-1を忘れず指定する必要があります。また逆にruntimeを指定していてもsize * loop分のデータへのアクセスがすべて終了するとテストは終了します |
| Measurements and reporting | group_reporting | - | (Flagのためパラメータ値は不要です)numjobs > 1のときに、各ジョブの結果をまとめて出力してくれます。全体で何IOPS出たか、などを見るときに使用します。逆にnumjobsは複数並列だが、個々のジョブごとのiopsなどを知りたい場合は指定する必要がありません |
| Command line options | --output-format | json | テストの実行結果のレポートを出力する機能がfioには存在します。fioの出力結果のフォーマットを何にするか指定できます(csv, json)。おすすめはjson出力で、jqをパイプして利用するのが個人的にはおすすめです |
| --status-interval | 1 | 上記のリポートは通常ジョブの終了時に出力されます。本インターバルを指定すると、指定した秒数ごとに上記フォーマットで途中経過を出力します |
代表的なパラメータ設定例
以下が、 シングルスレッド、4K、同期IOでのシーケンシャルリードの実行例です。これはddコマンドのときとほぼ同じ状況となります。
$ sudo fio --ioengine=sync --numjobs=1 --direct=1 --bs=4k --rw=read \
--size=1G --filename=/dev/vdb --name=single-thread-seq-read
single-thread-seq-read: (g=0): rw=read, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=sync, iodepth=1
fio-3.20-dirty
Starting 1 process
Jobs: 1 (f=1): [R(1)][100.0%][r=15.2MiB/s][r=3901 IOPS][eta 00m:00s]
single-thread-seq-read: (groupid=0, jobs=1): err= 0: pid=1241: Sat Dec 12 12:22:33 2020
read: IOPS=4105, BW=16.0MiB/s (16.8MB/s)(1024MiB/63852msec)
clat (usec): min=136, max=5160, avg=242.42, stdev=42.38
lat (usec): min=136, max=5160, avg=242.57, stdev=42.38
clat percentiles (usec):
| 1.00th=[ 176], 5.00th=[ 192], 10.00th=[ 200], 20.00th=[ 215],
| 30.00th=[ 227], 40.00th=[ 241], 50.00th=[ 247], 60.00th=[ 251],
| 70.00th=[ 253], 80.00th=[ 260], 90.00th=[ 277], 95.00th=[ 297],
| 99.00th=[ 351], 99.50th=[ 375], 99.90th=[ 490], 99.95th=[ 562],
| 99.99th=[ 1123]
bw ( KiB/s): min=14520, max=17712, per=100.00%, avg=16449.07, stdev=478.33, samples=127
iops : min= 3630, max= 4428, avg=4112.27, stdev=119.58, samples=127
lat (usec) : 250=58.26%, 500=41.65%, 750=0.07%, 1000=0.01%
lat (msec) : 2=0.01%, 4=0.01%, 10=0.01%
cpu : usr=1.12%, sys=3.39%, ctx=262200, majf=0, minf=13
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=262144,0,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs):
READ: bw=16.0MiB/s (16.8MB/s), 16.0MiB/s-16.0MiB/s (16.8MB/s-16.8MB/s), io=1024MiB (1074MB), run=63852-63852msec
Disk stats (read/write):
vdb: ios=261315/0, merge=0/0, ticks=61256/0, in_queue=16, util=100.00%
output-formatはデフォルトの出力です。かなりの情報量があります。
まず、ddコマンドと同じ値を確認していきます(単位系がMiB/KiBだったりしますが、だいたいの値で割愛)。
- IOPSは 最小
3630、最大4428、平均で4112.27だったことが以下の値からわかります。
iops : min= 3630, max= 4428, avg=4112.27, stdev=119.58, samples=127 - スループットについても同様に、最小
14.52 MB/s最大17.71 MB/s、平均で16.45 MB/sだったことがわかります。
bw ( KiB/s): min=14520, max=17712, per=100.00%, avg=16449.07, stdev=478.33, samples=127 - レイテンシは若干ややこしいです。というのもfioには
clat、latと 2つのレイテンシを表すメトリクスが表示されます。これはそれぞれ、Completion latency、Latencyの略です。これらはそれぞれ、計測区間が違うようです。clatはfioの内部処理を含まないIOの命令を実行してから応答があるまでの値であり、latはfioの内部処理についても含むようです12。ddと比較する上ではlatのあたいを見てみます。
レイテンシは最小136 usec = 0.136 msec、最大5160 usec = 5.16 msec、 平均で242.57 usec = 0.243 msecだったことがわかります。
lat (usec): min=136, max=5160, avg=242.57, stdev=42.38
上記の通り 4 KB のシーケンシャルリードにおいては ddコマンドの結果と近い値が出ていることがわかります。
いくつかのfioとddコマンドでのシーケンシャルアクセス、シングルスレッドの結果を記載します。
| 測定ツール | 読み書き | ブロック | IOPS | スループット | レイテンシ |
|---|---|---|---|---|---|
| dd | Read | 4 KB | 3647 | 14.9 MB/s | 0.27 msec |
| fio | Read | 4 KB | 4112 | 16.8 MB/s | 0.243 msec |
| dd | Read | 4 MB | 63 | 263 MB/s | 15.92 msec |
| fio | Read | 4 MB | 54 | 216 MB/s | 19.37 msec |
| dd | Write | 4 KB | 976 | 4 MB/s | 1.02 msec |
| fio | Write | 4 KB | 973 | 3.89 MB/s | 1.03 msec |
| dd | Write | 4 MB | 44 | 184 MB/s | 22.7 msec |
| fio | Write | 4 MB | 47 | 189 MB/s | 22.1 msec |
シングルスレッド、シーケンシャルアクセスの結果においては、ddコマンドと同じような結果を出力している事がわかります。
同期IOと非同期IO
ちょうどLinux Advent Calendar 2020 6日目に解説が上がっていました、Linuxにおける非同期IOの実装についてこちらのポストが大変詳しいですし、勉強になります。
簡単に噛み砕いて説明すると同期IOにおいては一つのスレッドでIOしている間、後続のIOはブロックされます。
これはwriteやreadといったPOSIX システムコールが書込み完了をまって帰ってくるためです。
そのため、同期IOにおいてはどうしてもIO中の待ち時間が発生します。
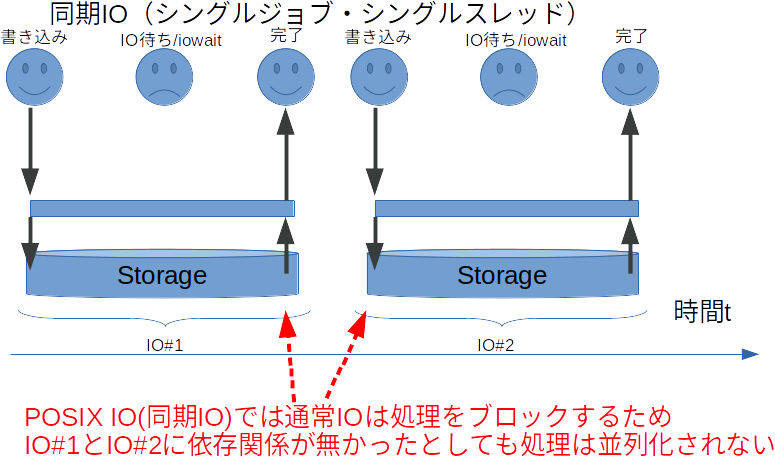
この待ち時間を解決するためには、ユーザは通常スレッドを使用したりするなどアプリケーションの実装を工夫する必要があります。
ただし、後述もしますが、スレッドの利用は性能面でのコストが高い上に、アプリごとに実装する必要がでてきてしまいます。
この問題を解決をするために非同期IO方式のシステムコールをOSの側に用意しているのが、非同期IO方式です。上記のQiitaのポストでも紹介されているlinux aioやio_uringがそれに当たります。
非同期IO方式はもともと、IOの待ち時間中に別のタスクを処理可能という点が有利な点ですが、昨今のストレージデバイスは高速化しており、また物理的なキューサイズ等も増えていることもあるため、非同期IOを複数走らせることによる読み書き性能の向上についても期待できるため、fioにおいてはそれらの非同期IOをioエンジンにして多数のIO負荷をかけることができます。このときにfioに非同期IOを指定するのがioengine=io_uringオプションやioengine=libaioです。また、図中にあるように何本のIOを同時に走らせるのかをiodepth=32等で指定します。
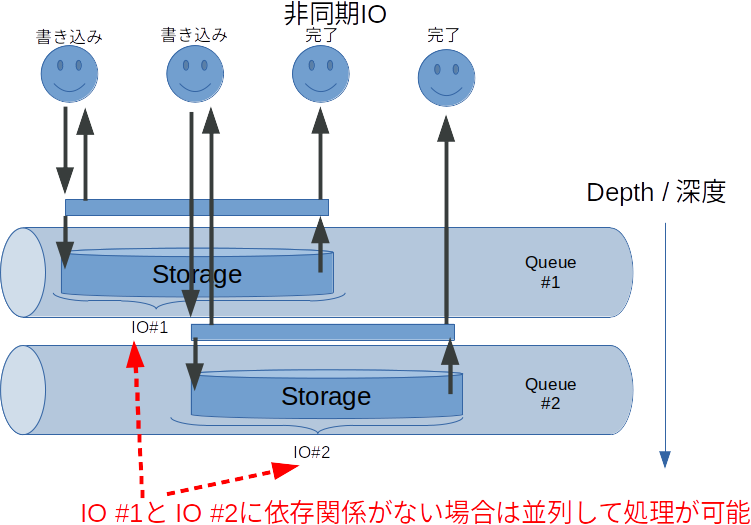
fio上でこの非同期IOと似たようなことができるのがnumjobsオプションです。
これは単純に規定したジョブをいくつ同時で動かすかを指定します。プロセスが増えるだけですので潤沢にCPUがあれば同じ効果が得られます。
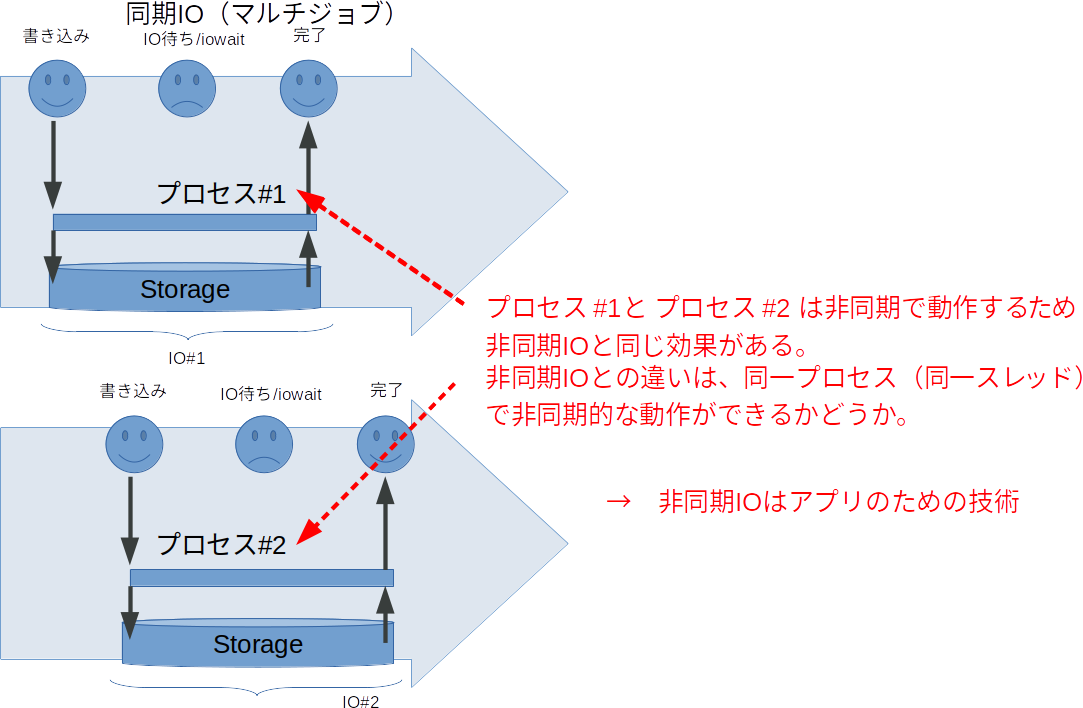
とはいえ、マルチジョブではスレッド数やプロセス数が増えるため、スケジューラ等でのOSのオーバヘッドが増えてしまうため、非同期IOに比べてスケールしにくいのは事実です(なのでCPUが潤沢にあればと記載してます)。ですので利用できる環境であるのならば、io_uring等の非同期IOエンジンを使用したほうがベンチマークのスコアも良くなるかと思います。
最後に実際のCephの測定をしてみる
またまた、思っていた以上に前置きが長くなってしまいました・・・。すみません。
最後に実際にCephを実際に計測して評価してみたいと思います。
上で記載したの観点1,観点2、観点3でそれぞれ結果や手順や結果を紹介したかったところですが、残念ながら書き始めたら他にもいっぱい書くことがあったことにより縮小してお送りします。
今回はCephの利用ユーザの観点から、「Cephは遅い」と言われる点と、「いやCephだって使い方次第でそこそこ速いよ」という2つの側面を示す例を紹介したいと思います。
評価1:シングルスレッドでのIO性能
まずは、Cephのシングルスレッド・同期IOの性能を見てみたいと思います。
これは上記の ddコマンドやfioのシングルスレッドの結果からある程度想像できるかと思いますが、改めてfioを用いて確認してみます。
fioのパラメータ
$ sudo fio --ioengine=sync --numjobs=1 --direct=1 --bs=$BS --rw=$RW \
--size=1G --filename=/dev/vdb --name=single-thread-$RW-$BS \
--output-format=json
このパラメータを基本として、$RWにシーケンシャルリードであるread、ランダムリードであるrandread、シーケンシャルライトであるwrite、ランダムライトであるrandwriteの評価を行います。また$BSに4k 16k 64k 256k 1m 4mを与えていきそれぞれの値を表示していきたいと思います。
実行
実際のシェルスクリプト含めて以下の形で実行します。--output-format=jsonを指定して、かつ、jqを用いて必要な要素だけをパースします。
以下のスクリプトを見ていただければ解ると思いますが、このforループでは、4k ライト、 4k リード、 4k ランダムライト、 4k ランダムリード、8k ライト、 8k リード、 8k ランダムライト、 8k ランダムリード・・・と進んでいくことがわかるかと思います。
このRWとブロックサイズの与え方には実は意図があります。
というのも今回の試験環境では仮想マシン環境を用いていますので、仮に4k リード、 8k リード、 16k リード・・・と連続して与えた場合、
リードが連続してしまうと高確率でキャッシュにヒットしてしまうため若干歪んだグラフとなってしまいます。
もちろん、リードの前に一旦ディスクを書いたり、キャッシュをフラッシュするようなスクリプトを実行すればイイのですが、めんどくさかったのでこのようにライトのあとにリードが来るように試験パターンを工夫してます。
for BS in 4k 16k 64k 256k 1m 4m
do
for RW in write read randwrite randread
do
sudo fio --ioengine=sync --numjobs=1 --direct=1 --bs=$BS --rw=$RW \
--size=1G --filename=/dev/vdb --name=single-thread-$RW-$BS \
--runtime=30 -output-format=json | \
jq -cr '[."global options".bs, ."global options".rw,
.jobs[0].read.iops, .jobs[0].write.iops,
.jobs[0].read.bw, .jobs[0].write.bw]|@csv'
done
done
実行結果
実行しますと以下のようなCSVを出力するので、LibreOffice Calc13を用いてグラフ化します。
"4k","write",0,972.40092,0,3889
"4k","read",3236.192127,0,12944,0
"4k","randwrite",0,776.174128,0,3104
"4k","randread",2303.556548,0,9214,0
"16k","write",0,869.737675,0,13915
"16k","read",2067.19776,0,33075,0
"16k","randwrite",0,715.509483,0,11448
"16k","randread",1981.267291,0,31700,0
"64k","write",0,673.102995,0,43078
"64k","read",620.277126,0,39697,0
"64k","randwrite",0,586.924593,0,37563
"64k","randread",570.314676,0,36500,0
"256k","write",0,337.369245,0,86366
"256k","read",496.785931,0,127177,0
"256k","randwrite",0,313.677439,0,80301
"256k","randread",470.534176,0,120456,0
"1m","write",0,118.299445,0,121138
"1m","read",156.83872,0,160602,0
"1m","randwrite",0,115.185602,0,117950
"1m","randread",153.776843,0,157467,0
"4m","write",0,33.04505,0,135352
"4m","read",47.424972,0,194252,0
"4m","randwrite",0,33.298647,0,136391
"4m","randread",46.334842,0,189787,0
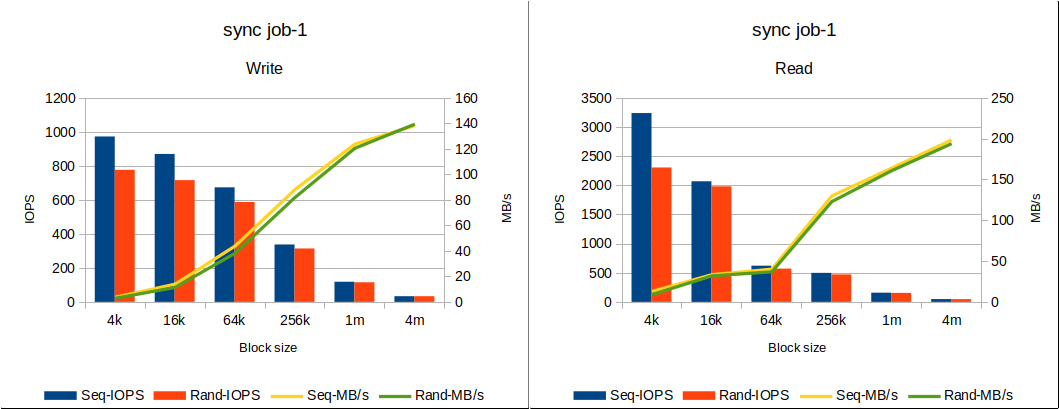
結果を見てみると、シーケンシャルアクセスでは先程のddコマンドでの結果と変わらない結果が見て取れます。シーケンシャルライトで1000 IOPS弱、シーケンシャルリードで3000 IOPS程度出ています。
また、ddコマンドでは計れなかったランダムアクセスの結果についてもfioでは確認できます。シーケンシャルアクセスと比較して、2割ほど性能が劣化しているようです。
評価2:非同期IOでのIO性能
次に、評価1と同様に、「ユーザの観点」から、Cephのシングルスレッド・非同期IOの性能を見てみたいと思います。
非同期IOにはioengine=io_uringを指定し、並列数であるiodepthの値を16 32 64 128 と増やして試験します。
fioのパラメータ
$ sudo fio --ioengine=io_uring --numjobs=1 --iodepth=$DEPTH --direct=1 --bs=$BS --rw=$RW \
--size=1G --filename=/dev/vdb --name=io_uring-$DEPTH-$RW-$BS \
--runtime=30 --iodepth=$DEPTH --output-format=json
実行
RW BS については先程の試験1と同じ考え方です。iodepthについては16から倍々していき、128まで増やしてみます。
for DEPTH in 16 32 64 128
do
for BS in 4k 16k 64k 256k 1m 4m
do
for RW in write read randwrite randread
do
sudo fio --ioengine=io_uring --numjobs=1 --direct=1 --bs=$BS --rw=$RW \
--size=1G --filename=/dev/vdb --name=io_uring-$DEPTH-$RW-$BS \
--runtime=30 --iodepth=$DEPTH --output-format=json | \
jq -cr '[.jobs[0]."job options".iodepth,
."global options".bs, ."global options".rw,
.jobs[0].read.iops, .jobs[0].write.iops,
.jobs[0].read.bw, .jobs[0].write.bw]|@csv'
done
done
done
実行結果(書込み)
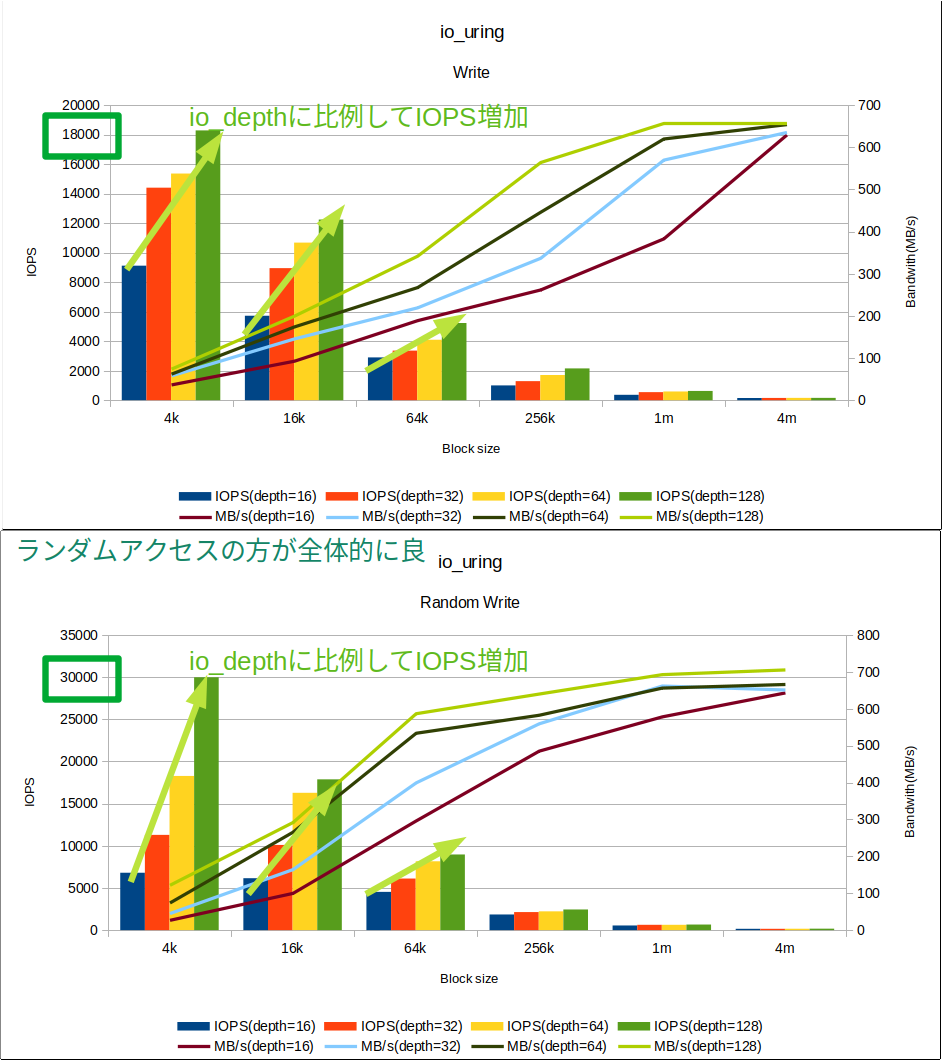
実行結果を見てみると、シングルスレッド・同期IOとは比較にならない数字が出ていることがわかります(もちろん同じVMから計測して、同じRBDデバイスを使っています!)。最大で29,976 IOPS = 30 KIOPSの性能がました。またスループットでも 706MB/s、5Gbps程度で転送できています。IOPSについてはiodepthの増加に対してリニアに伸びていることがわかります。今回の例ではさらなる負荷をかけていませんが、iodepthを更に増加させてみても良いかもしれません。
またグラフからぱっとみてわかるとおり、ランダムアクセスのほうがシーケンシャルアクセスに比べて性能が良い結果が出ています。
これは上記の同期IOとは異なる特性であり、一見すると不思議に思われます。ただ、これがCephの特徴であるとも言えます。
前回の記事で紹介したとおりCephは4MBのオブジェクトに対してプレースメントグループ=OSDのペアやトリオが決定されます。オブジェクトサイズに満たないブロックサイズのシーケンシャルアクセスでは同一のオブジェクトに対して連続してアクセスが集中することがわかります。
対して、ランダムアクセスではPGのアクセスについても同様に分散されることがわかります。そのため、非同期IOでIO処理を並列化した際にはIOが互いに干渉することなく処理できるためランダムアクセスのほうが性能が良い結果となっていると考察できます。

グラフ化する前の数値については以下のとおりです。
|Write|IOPS(depth=16)|IOPS(depth=32)|IOPS(depth=64)|IOPS(depth=128)|MB/s(depth=16)|MB/s(depth=32)|MB/s(depth=64)|MB/s(depth=128)|
|--:|--:|--:|--:|--:|--:|--:|--:|--:|--:|
|4k|9,115.52|14,402.73|15,358.80|18,280.61|37.34|58.99|62.91|74.88|
|16k|5,720.67|8,948.12|10,682.31|12,240.57|93.73|146.61|175.02|200.55|
|64k|2,896.75|3,360.82|4,092.93|5,231.16|189.84|220.25|268.23|342.83|
|256k|1,001.96|1,288.46|1,705.25|2,154.66|262.66|337.76|447.02|564.83|
|1m|365.98|544.10|591.91|627.45|383.75|570.53|620.66|657.93|
|4m|150.23|151.66|156.10|156.86|630.13|636.10|654.72|657.93|
|randWrite|IOPS(depth=16)|IOPS(depth=32)|IOPS(depth=64)|IOPS(depth=128)|MB/s(depth=16)|MB/s(depth=32)|MB/s(depth=64)|MB/s(depth=128)|
|--:|--:|--:|--:|--:|--:|--:|--:|--:|--:|
|4k|6,804.41|11,286.18|18,278.06|29,976.44|27.87|46.23|74.87|122.78|
|16k|6,155.93|10,096.44|16,278.19|17,876.70|100.86|165.42|266.70|292.89|
|64k|4,533.48|6,108.87|8,159.36|8,967.71|297.11|400.35|534.73|587.71|
|256k|1,855.07|2,137.79|2,226.09|2,445.37|486.30|560.41|583.56|641.04|
|1m|552.32|632.10|626.68|661.50|579.15|662.80|657.12|693.63|
|4m|153.57|155.43|159.01|168.42|644.12|651.94|666.92|706.41|
実行結果(読込み)
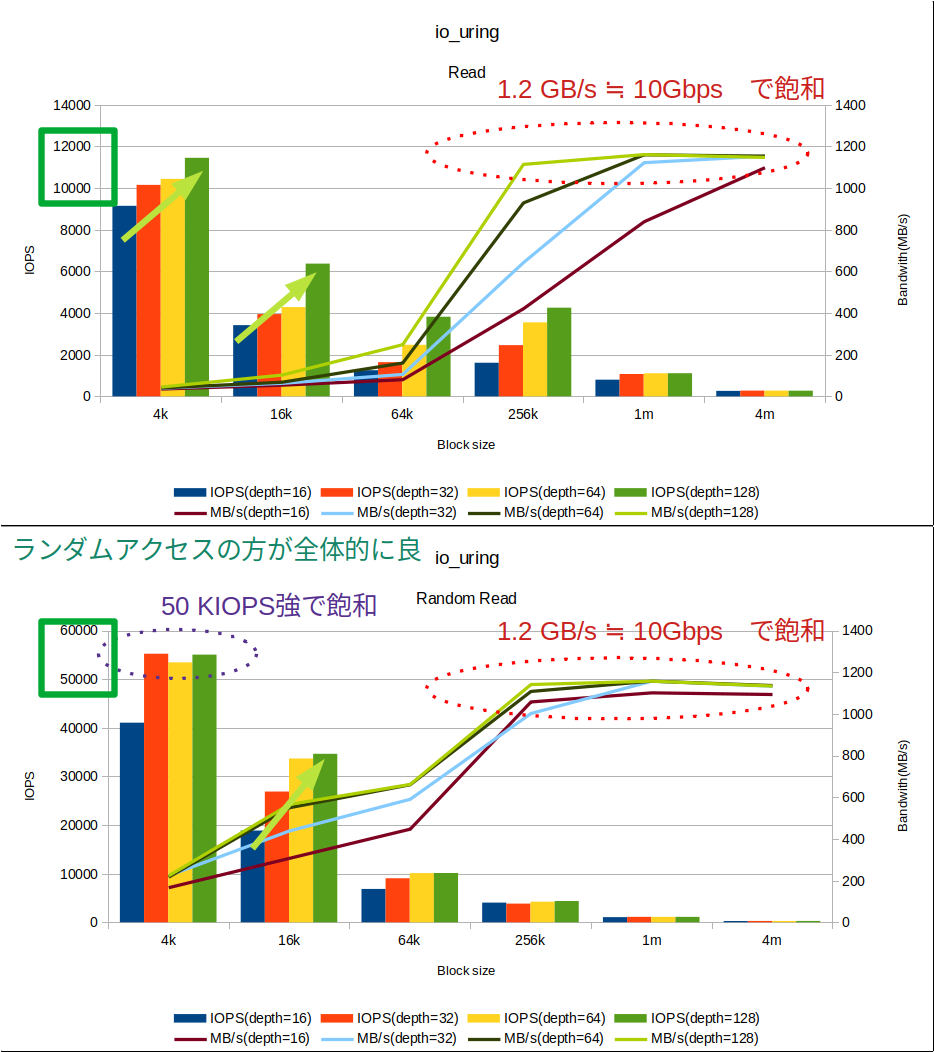
続いて、リードの結果ですリードもライト同様同期IOとは比べ物にならないくらいの性能が出ています。またランダムリードのほうが性能がよいという性能特性については概ねライトのとき同様です。特筆すべきはサチュレーションが見られる点です。
まず帯域が、今回の結果では256KB以上のブロックサイズで発生しています。VMのホストしているサーバの物理IFが10Gbpsですので、おおよそ10Gbps=1.25GB/s程度の値となっています。また、ランダムリードではIOPSについてもサチュレーションしています。おおよそ50 KIOPS強で頭打ちになっていることがわかります。
|Read|IOPS(depth=16)|IOPS(depth=32)|IOPS(depth=64)|IOPS(depth=128)|MB/s(depth=16)|MB/s(depth=32)|MB/s(depth=64)|MB/s(depth=128)|
|--:|--:|--:|--:|--:|--:|--:|--:|--:|--:|
|4k|9,148.28|10,155.11|10,440.24|11,452.34|37.47|41.59|42.76|46.91|
|16k|3,418.85|3,949.14|4,284.52|6,371.38|56.01|64.70|70.20|104.39|
|64k|1,255.86|1,641.85|2,474.55|3,821.79|82.30|107.60|162.17|250.46|
|256k|1,613.23|2,458.58|3,552.47|4,257.80|422.90|644.50|931.26|1,116.15|
|1m|801.88|1,072.25|1,108.23|1,109.43|840.83|1,124.34|1,162.06|1,163.32|
|4m|262.30|275.57|275.57|274.09|1,100.14|1,155.80|1,155.80|1,149.62|
|RandRead|IOPS(depth=16)|IOPS(depth=32)|IOPS(depth=64)|IOPS(depth=128)|MB/s(depth=16)|MB/s(depth=32)|MB/s(depth=64)|MB/s(depth=128)|
|--:|--:|--:|--:|--:|--:|--:|--:|--:|--:|
|4k|41,069.09|55,234.72|53,466.04|55,060.70|168.22|226.24|219.00|225.53|
|16k|18,864.71|26,892.08|33,694.60|34,656.80|309.08|440.60|552.05|567.82|
|64k|6,855.23|9,041.94|10,107.34|10,132.34|449.26|592.57|662.39|664.03|
|256k|4,043.44|3,831.62|4,235.78|4,362.09|1,059.96|1,004.44|1,110.38|1,143.49|
|1m|1,052.42|1,105.83|1,105.83|1,105.83|1,103.54|1,159.55|1,159.55|1,159.55|
|4m|261.22|270.61|271.47|270.90|1,095.65|1,135.03|1,138.64|1,136.23|
評価結果のまとめ
評価1と評価2の内容を考察すると、前回「Cephは遅いはYesでもありNoでもある」と記載した理由がわかっていただけたかと思います。Cephは分散ストレージであり、優れたスケーラビリティを持ちます。
一つのwriteシステムコールに対してはお世辞にもあまり速いとは言えませんが、非同期的なIOや、複数のプロセスからの書込みなどに対しては互いに分散してアクセスすることが可能なため、高速に処理することができることがわかります。
CephのIOの特性を知ることは、Cephを正しく理解し、どういったワークロードにCephが向いているのか、あるいはアプリケーションの設定もCephに合わせてどのようなパラメータを設定すべきかといったことを理解することができると思います。
第二回(アドベントカレンダー13日目)まとめ
毎度蛇足的に、補足する内容を差し込んだところ、非常に記事が長くなってしまいました・・・(更に記事を分割しても良かったかもしれませんね・・・)。
また、Cephのベンチマーク自体をもっと見たかった、というご意見もあったかもしれません。当初は記載しようとしていた、ベンチマークの観点で記載したシステムアドミニストレータの観点の試験については上記の評価2のio_uringによる非同期IOを複数のVMや複数のコンテナなどから実行してみれば良いと思います。
また、ioengine=rbdというIOエンジンもfioには用意されているため、VMやコンテナなどのオーバヘッドを取り払って、ネイティブマシンからRBDを直接計測することもできます。こういった試験も一緒にご紹介したかったのですが、残念ながら力尽きてしまいました。またどこかで機会があれば記載してみたいと思います。
以上で二回に渡って書かさせていただいた「【ストレージ初心者向け】分散ストレージ、Cephの速度を計る」は終了としたいと思います。
私がCephでストレージに入門したときに躓いたり悩んだりしたポイントを中心に記載しましたが、思い立って記載したこと、締切りに追われて記載したこともあり、理論の飛躍やいや、そこ飛ばすなよみたいなポイントももしかしたらあったかもしれません。
アドベントカレンダーの参加ということもあり、13日中の投稿はMUSTかなとはおもいますので、一部甘い部分があるかと思いますが、その点はご容赦いただければと思いますしまた必要に応じて加筆訂正させていただこうかと思います。
最後に、Cephには(過去の障害事例とかもあって・・・)拒否反応を示されることも多々ありますが、非常に面白いストレージシステムだと思っています。
ぜひ、みなさんもRook/Cephをつかって、これからも盛り上げていきましょう!
-
Windows PCでのベンチマークではCrystalDiskMarkなどが有名ですね。 ↩
-
Cephはそうではありません。また、そんなストレージシステムがこの世にあるのかを私は知りません・・・ ↩
-
バースト的にそういった最悪値のトラフィックが発生することがあってもそれが定常的になるのであればそもそもその設計容量等に問題があるのは明白です。 ↩
-
私は本当にここに書いてあることをはじめに理解していなかったため、かなり遠回りな評価をやってしまいました。 ↩
-
全く関係ないプチ情報:電話は20 msecごとに音声データを分割してパケットを運んでいることが多いです!(私の正体は電話屋) ↩
-
いまどきの若い人には通じないネタかもしれませんが、Windowsを高速させるための「デフラグ」とはこの一つのファイルを連続した領域に集めなおす作業でした。 ↩
-
ヘッドのシーク時間等の計算を基本情報技術者試験や応用情報技術者試験で勉強された方も多いと思います ↩
-
間違ってもルートディスクになっている
/dev/vdaや/dev/sdaに書き込まないでくださいね・・ ↩ -
64 [KB] - 4 [KB]↩ -
というか、時間もなくちゃんと中身追いきれてませんので、読込み時のバラツキの考察については若干外しているかもしれません・・・。 ↩
-
fioのリポジトリをCloneして、masterブランチにおいて
egrep ' \.name[^=]+=' options.c |grep -v NULL |wc -lで集計。 ↩ -
私も現状ちゃんと理解できていないです・・。 ↩
-
UbuntuのクライアントPCを用いてるので、Officeじゃないんです・・・ ↩